
目录
[一、先搞懂:什么是目标文件?------ 编译后的 "半成品"](#一、先搞懂:什么是目标文件?—— 编译后的 “半成品”)
[1.1 目标文件的本质:ELF 格式的 "最小单元"](#1.1 目标文件的本质:ELF 格式的 “最小单元”)
[步骤 1:写两个源码文件](#步骤 1:写两个源码文件)
[步骤 2:编译生成目标文件](#步骤 2:编译生成目标文件)
[步骤 3:查看目标文件类型](#步骤 3:查看目标文件类型)
[1.2 为什么需要目标文件?------ 模块化开发的核心](#1.2 为什么需要目标文件?—— 模块化开发的核心)
[二、ELF 文件全景解析:4 种类型 + 4 大核心结构](#二、ELF 文件全景解析:4 种类型 + 4 大核心结构)
[2.1 核心结构 1:ELF 头(ELF Header)------ 文件的 "总目录"](#2.1 核心结构 1:ELF 头(ELF Header)—— 文件的 “总目录”)
[用readelf -h查看 ELF 头](#用readelf -h查看 ELF 头)
[内核中的 ELF 头数据结构](#内核中的 ELF 头数据结构)
[2.2 核心结构 2:节(Section)------ ELF 文件的 "数据容器"](#2.2 核心结构 2:节(Section)—— ELF 文件的 “数据容器”)
[用readelf -S查看所有节](#用readelf -S查看所有节)
[2.3 核心结构 3:节头表(Section Header Table)------ 节的 "索引表"](#2.3 核心结构 3:节头表(Section Header Table)—— 节的 “索引表”)
[2.4 核心结构 4:程序头表(Program Header Table)------ 加载的 "说明书"](#2.4 核心结构 4:程序头表(Program Header Table)—— 加载的 “说明书”)
[用readelf -l查看程序头表](#用readelf -l查看程序头表)
[三、ELF 的生命周期:从源码到加载的完整流程](#三、ELF 的生命周期:从源码到加载的完整流程)
[3.1 阶段 1:ELF 形成可执行文件 ------ 目标文件的 "合并与重定位"](#3.1 阶段 1:ELF 形成可执行文件 —— 目标文件的 “合并与重定位”)
[步骤 1:目标文件的节合并](#步骤 1:目标文件的节合并)
[步骤 2:符号解析](#步骤 2:符号解析)
[步骤 3:地址重定位](#步骤 3:地址重定位)
[3.2 阶段 2:ELF 可执行文件加载 ------ 从磁盘到内存的 "变身"](#3.2 阶段 2:ELF 可执行文件加载 —— 从磁盘到内存的 “变身”)
[3.2.1 加载的核心原则:Section 合并为 Segment](#3.2.1 加载的核心原则:Section 合并为 Segment)
[3.2.2 加载的完整流程](#3.2.2 加载的完整流程)
[3.2.3 虚拟地址空间与 ELF 加载的关系](#3.2.3 虚拟地址空间与 ELF 加载的关系)
[3.2.4 加载后的内存布局](#3.2.4 加载后的内存布局)
[四、实战:用工具分析 ELF 文件 ------ 亲手拆解 ELF 黑盒](#四、实战:用工具分析 ELF 文件 —— 亲手拆解 ELF 黑盒)
[4.1 常用工具清单](#4.1 常用工具清单)
[4.2 实战 1:分析目标文件的重定位信息](#4.2 实战 1:分析目标文件的重定位信息)
[4.3 实战 2:分析可执行文件的节合并与地址重定位](#4.3 实战 2:分析可执行文件的节合并与地址重定位)
[4.4 实战 3:分析动态库的 ELF 结构](#4.4 实战 3:分析动态库的 ELF 结构)
[五、ELF 文件的核心作用 ------ 为什么它能成为 Linux 的 "标准"?](#五、ELF 文件的核心作用 —— 为什么它能成为 Linux 的 “标准”?)
前言
在 Linux/Unix 系统中,ELF(Executable and Linkable Format)是绝对的 "核心玩家"------ 无论是我们写的 C/C++ 代码编译后的目标文件(.o)、可执行程序,还是动态库(.so),本质上都是 ELF 格式文件。你每天运行的
ls、gcc,甚至系统内核的部分模块,背后都藏着 ELF 的身影。但 ELF 文件就像一个精密的 "黑盒子":它内部如何组织代码和数据?目标文件如何合并成可执行程序?程序加载到内存时又发生了什么?今天我们就亲手拆解这个黑盒子,从底层原理到实战操作,带你彻底搞懂 ELF 文件的方方面面。下面就让我们正式开始吧!
一、先搞懂:什么是目标文件?------ 编译后的 "半成品"
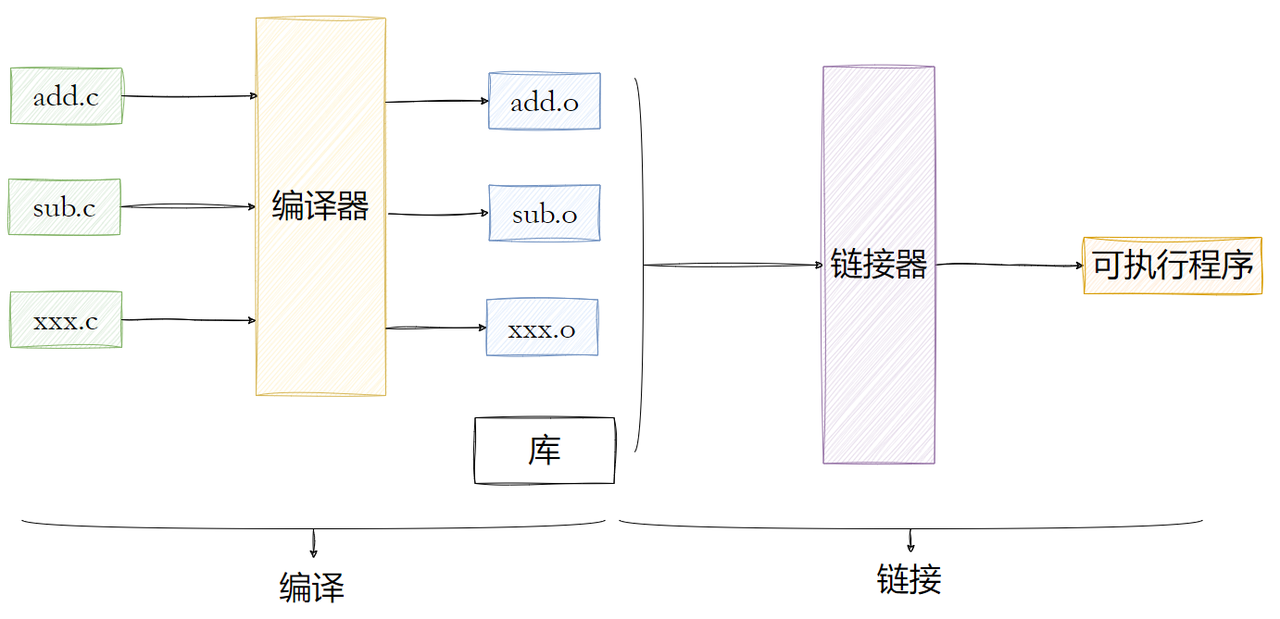
在聊 ELF 之前,我们得先明白 "目标文件"(.o 文件)的角色。写过 C/C++ 的同学都知道,程序从源码到可执行文件要经过 "编译→链接" 两步:
- 编译 :编译器(如 gcc)将单个
.c/.cpp源码翻译成 CPU 能识别的机器码,生成目标文件(.o)。- 链接:链接器(如 ld)将多个目标文件 + 依赖的库文件合并,修正函数 / 变量的地址,最终生成可执行程序。
1.1 目标文件的本质:ELF 格式的 "最小单元"
目标文件是 ELF 文件的一种(可重定位文件),它是源码编译后的 "半成品"------ 包含了编译后的机器码、数据,以及链接时需要的重定位信息、符号表等。
我们用一个简单的例子直观感受:
步骤 1:写两个源码文件
cpp
// hello.c
#include<stdio.h>
void run(); // 声明在code.c中定义的函数
int main() {
printf("hello world!\n");
run();
return 0;
}
cpp
// code.c
#include<stdio.h>
void run() {
printf("running...\n");
}步骤 2:编译生成目标文件
用gcc -c命令只编译不链接,生成.o文件:
bash
gcc -c hello.c # 生成hello.o
gcc -c code.c # 生成code.o
ls -l
# 输出:
# -rw-rw-r-- 1 user user 62 10月 31 15:36 code.c
# -rw-rw-r-- 1 user user 1672 10月 31 15:46 code.o
# -rw-rw-r-- 1 user user 103 10月 31 15:36 hello.c
# -rw-rw-r-- 1 user user 1744 10月 31 15:46 hello.o步骤 3:查看目标文件类型
用file命令可以验证目标文件的格式:
bash
file hello.o
# 输出:hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
ELF 64-bit:64 位 ELF 文件relocatable:可重定位文件(目标文件的类型)not stripped:保留了符号表等调试信息
1.2 为什么需要目标文件?------ 模块化开发的核心
目标文件的存在让大型项目的开发变得高效:
- 独立编译 :修改一个源码文件后,只需重新编译对应的
.o文件,无需编译整个项目,节省时间。- 模块复用 :多个项目可以共用同一个
.o文件,避免重复编译。- 链接灵活 :可以通过链接不同的
.o文件和库,组合出不同功能的可执行程序。
比如一个游戏项目,渲染模块、物理引擎模块、网络模块可以分别编译成.o文件,最后通过链接器合并成完整的游戏程序。
二、ELF 文件全景解析:4 种类型 + 4 大核心结构
ELF 文件不只是目标文件,它是一个 "家族",包含 4 种核心类型,每种类型都有特定的用途:
| ELF 文件类型 | 后缀 | 用途 | 示例 |
|---|---|---|---|
| 可重定位文件 | .o | 编译后的目标文件,用于链接成可执行程序或动态库 | hello.o、code.o |
| 可执行文件 | 无后缀 | 可以直接运行的程序 | /bin/ls、a.out |
| 共享目标文件 | .so | 动态库,可被多个程序共享使用 | libc.so.6、libmystdio.so |
| 内核转储文件 | core | 进程崩溃时的内存快照,用于调试 | core.12345 |
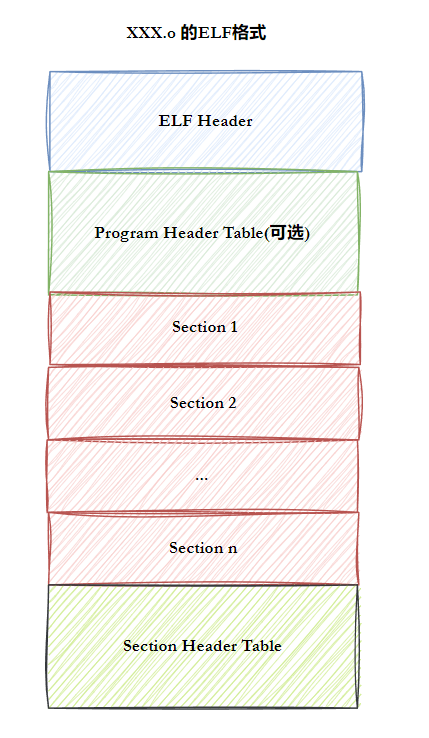
无论哪种 ELF 文件,内部结构都遵循统一的规范,核心由 4 部分组成:
- ELF 头(ELF Header):文件的 "身份证",描述文件的基本信息(类型、架构、大小、各个部分的偏移量等)。
- 程序头表(Program Header Table):告诉操作系统如何加载文件到内存(仅可执行文件和动态库有)。
- 节头表(Section Header Table):描述文件中的 "节"(Section)信息,是链接器的主要操作对象。
- 节(Section):ELF 文件的基本组成单位,存储代码、数据、符号表等具体内容。
我们可以用一张图直观理解 ELF 文件的结构:
2.1 核心结构 1:ELF 头(ELF Header)------ 文件的 "总目录"
ELF 头位于文件的最开始,是整个 ELF 文件的 "总目录",操作系统和工具(如链接器、调试器)首先读取 ELF 头,才能找到其他部分的位置。
用readelf -h查看 ELF 头
以目标文件hello.o为例:
bash
readelf -h hello.o输出结果详解(关键字段):
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 # 魔数:ELF文件标识
Class: ELF64 # 64位架构
Data: 2's complement, little endian # 小端序
Version: 1 (current) # 版本
OS/ABI: UNIX - System V # 目标操作系统
ABI Version: 0
Type: REL (Relocatable file) # 类型:可重定位文件
Machine: Advanced Micro Devices X86-64 # 目标CPU架构
Version: 0x1
Entry point address: 0x0 # 入口地址:目标文件无入口,可执行文件有
Start of program headers: 0 (bytes into file) # 程序头表偏移:目标文件无
Start of section headers: 728 (bytes into file) # 节头表偏移
Flags: 0x0
Size of this header: 64 (bytes) # ELF头大小
Size of program headers: 0 (bytes) # 程序头表条目大小:目标文件无
Number of program headers: 0 # 程序头表条目数:目标文件无
Size of section headers: 64 (bytes) # 节头表条目大小
Number of section headers: 13 # 节的数量
Section header string table index: 12 # 节名称字符串表的索引内核中的 ELF 头数据结构
操作系统内核通过解析 ELF 头来识别和加载 ELF 文件,内核中定义了对应的结构体(/linux/include/elf.h):
cpp
// 64位ELF头结构体
typedef struct elf64_hdr {
unsigned char e_ident[EI_NIDENT]; // 魔数和相关属性
Elf64_Half e_type; // ELF文件类型(REL、EXEC、DYN等)
Elf64_Half e_machine; // 目标CPU架构
Elf64_Word e_version; // 文件版本
Elf64_Addr e_entry; // 程序入口虚拟地址(可执行文件)
Elf64_Off e_phoff; // 程序头表在文件中的偏移量
Elf64_Off e_shoff; // 节头表在文件中的偏移量
Elf64_Word e_flags; // 处理器特定标志
Elf64_Half e_ehsize; // ELF头大小
Elf64_Half e_phentsize; // 每个程序头表条目的大小
Elf64_Half e_phnum; // 程序头表条目数量
Elf64_Half e_shentsize; // 每个节头表条目的大小
Elf64_Half e_shnum; // 节头表条目数量(节的总数)
Elf64_Half e_shstrndx; // 节名称字符串表的索引
} Elf64_Ehdr;2.2 核心结构 2:节(Section)------ ELF 文件的 "数据容器"
节是 ELF 文件存储数据和代码的基本单元,不同类型的节负责不同的功能。我们最常用的节有以下几种:
| 节名称 | 类型 | 用途 |
|---|---|---|
| .text | 代码节 | 存储编译后的机器指令(程序的执行代码) |
| .data | 数据节 | 存储已初始化的全局变量和局部静态变量 |
| .bss | 未初始化数据节 | 为未初始化的全局变量和局部静态变量预留空间(文件中不占空间,加载到内存后分配空间并清零) |
| .rodata | 只读数据节 | 存储只读数据(如字符串常量、const 变量) |
| .symtab | 符号表 | 存储函数名、变量名与对应地址的映射关系 |
| .rel.text | 重定位表 | 存储.text 节中需要重定位的符号信息(如未解析的函数调用) |
| .shstrtab | 节名称字符串表 | 存储所有节的名称 |
| .strtab | 字符串表 | 存储符号名称等字符串 |
用readelf -S查看所有节
以hello.o为例:
bash
readelf -S hello.o输出结果(关键节):
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000024 0000000000000000 AX 0 0 1 # 代码节(AX:可执行)
[ 2] .data PROGBITS 0000000000000000 00000064
0000000000000000 0000000000000000 WA 0 0 1 # 数据节(WA:可写)
[ 3] .bss NOBITS 0000000000000000 00000064
0000000000000000 0000000000000000 WA 0 0 1 # 未初始化数据节
[ 4] .rodata PROGBITS 0000000000000000 00000064
000000000000000d 0000000000000000 A 0 0 1 # 只读数据节(字符串"hello world!\n")
[ 5] .rel.text RELA 0000000000000000 00000078
0000000000000030 0000000000000018 I 9 1 8 # 重定位表(.text节的重定位信息)
[ 9] .symtab SYMTAB 0000000000000000 000000a8
0000000000000170 0000000000000018 10 12 8 # 符号表
[10] .strtab STRTAB 0000000000000000 00000218
000000000000005c 0000000000000000 0 0 1 # 字符串表
[12] .shstrtab STRTAB 0000000000000000 00000274
000000000000004f 0000000000000000 0 0 1 # 节名称字符串表关键节详解
- .text 节 :存储机器指令用objdump -d反汇编
.text节,查看编译后的机器码:
bash
objdump -d hello.o输出:
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f <main+0xf>
f: e8 00 00 00 00 callq 14 <main+0x14> # 调用printf(地址暂为0,需重定位)
14: b8 00 00 00 00 mov $0x0,%eax
19: e8 00 00 00 00 callq 1e <main+0x1e> # 调用run(地址暂为0,需重定位)
1e: b8 00 00 00 00 mov $0x0,%eax
23: 5d pop %rbp
24: c3 retq可以看到,printf和run的调用地址都是00 00 00 00,这是因为编译时编译器不知道这两个函数的实际地址,需要在链接时通过重定位表修正。
(1).symtab 节(符号表) :存储符号信息符号表记录了函数、变量的名称、类型、地址等信息,用readelf -s查看:
bash
readelf -s hello.o输出中关键条目:
Symbol table '.symtab' contains 14 entries:
Num: Value Size Type Bind Vis Ndx Name
6: 0000000000000000 37 FUNC GLOBAL DEFAULT 1 main # 全局函数main,位于.text节(Ndx=1)
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts # 未定义符号puts(printf的实现)
13: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run # 未定义符号runNdx=UND:表示该符号在当前目标文件中未定义,需要从其他目标文件或库中查找(重定位的对象)。
(2).rel.text 节(重定位表) :记录需要修正的地址重定位表存储了.text节中需要重定位的符号位置,用readelf -r查看:
bash
readelf -r hello.o输出:
Relocation section '.rel.text' at offset 0x78 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
0000000000000010 00000c0200000004 R_X86_64_PLT32 0000000000000000 puts - 4
000000000000001a 00000d0200000004 R_X86_64_PLT32 0000000000000000 run - 4这表示:
- 在
.text节偏移0x10处,需要重定位符号**puts** - 在
.text节偏移0x1a处,需要重定位符号**run链接器会根据这些信息,找到puts(来自 C 标准库)和run**(来自code.o)的实际地址,替换掉原来的00 00 00 00。
2.3 核心结构 3:节头表(Section Header Table)------ 节的 "索引表"
节头表是所有节的 "索引表",每个条目对应一个节,记录了该节的名称、类型、大小、偏移量、标志等信息。链接器(如 ld)主要通过节头表来操作各个节(如合并、重定位)。
节头表的位置由 ELF 头中的**e_shoff字段指定,每个条目的大小由e_shentsize**指定,条目数量由e_shnum指定。
内核中的节头表结构体:
cpp
typedef struct elf64_shdr {
Elf64_Word sh_name; // 节名称在.shstrtab中的索引
Elf64_Word sh_type; // 节类型(如PROGBITS、SYMTAB等)
Elf64_Xword sh_flags; // 节标志(如可执行、可写、只读)
Elf64_Addr sh_addr; // 节在内存中的虚拟地址(加载后)
Elf64_Off sh_offset; // 节在文件中的偏移量
Elf64_Xword sh_size; // 节的大小(字节)
Elf64_Word sh_link; // 关联的其他节的索引(如重定位表关联符号表)
Elf64_Word sh_info; // 额外信息(如重定位表关联的节索引)
Elf64_Xword sh_addralign; // 节在内存中的对齐方式(如8字节对齐)
Elf64_Xword sh_entsize; // 节中每个条目的大小(如符号表条目大小)
} Elf64_Shdr;2.4 核心结构 4:程序头表(Program Header Table)------ 加载的 "说明书"
程序头表仅存在于可执行文件 和动态库 中,它是操作系统加载 ELF 文件的 "说明书"------ 描述了如何将 ELF 文件的内容加载到内存中,分成哪些段(Segment),每个段的权限(可读、可写、可执行)等。
用readelf -l查看程序头表
以可执行文件a.out(由hello.o和code.o链接生成)为例:
bash
# 先链接生成可执行文件
gcc hello.o code.o -o a.out
# 查看程序头表
readelf -l a.out输出结果(关键字段):
Elf file type is EXEC (Executable file)
Entry point 0x4004e0 # 程序入口地址
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2] # 动态链接器路径
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000744 0x0000000000000744 R E 200000 # 代码段(R E:只读、可执行)
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000218 0x0000000000000220 RW 200000 # 数据段(RW:可读写)
DYNAMIC 0x0000000000000e28 0x0000000000600e28 0x0000000000600e28
0x00000000000001d0 0x00000000000001d0 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x00000000000005a0 0x00000000004005a0 0x00000000004005a0
0x000000000000004c 0x000000000000004c R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got 关键字段详解
-
Type(段类型):
LOAD:需要加载到内存的段(最核心的类型)。INTERP:指定动态链接器的路径(如/lib64/ld-linux-x86-64.so.2)。DYNAMIC:动态链接相关的信息(如依赖的动态库、重定位信息)。GNU_STACK:栈的权限设置(RW 表示栈可读写)。
-
Flags(段权限):
R:只读(如代码段、只读数据段)。W:可写(如数据段、栈段)。E:可执行(如代码段)。
-
Section to Segment mapping:显示每个段由哪些节合并而成。例如:
- 第一个
LOAD段(R E)由.text、.rodata等节合并而成,是程序的代码和只读数据部分。 - 第二个
LOAD段(RW)由.data、.bss、.got等节合并而成,是程序的可读写数据部分。
- 第一个
三、ELF 的生命周期:从源码到加载的完整流程
理解了 ELF 的核心结构后,我们再来看 ELF 文件的完整生命周期:源码 → 目标文件 → 可执行文件 → 加载到内存运行。
3.1 阶段 1:ELF 形成可执行文件 ------ 目标文件的 "合并与重定位"
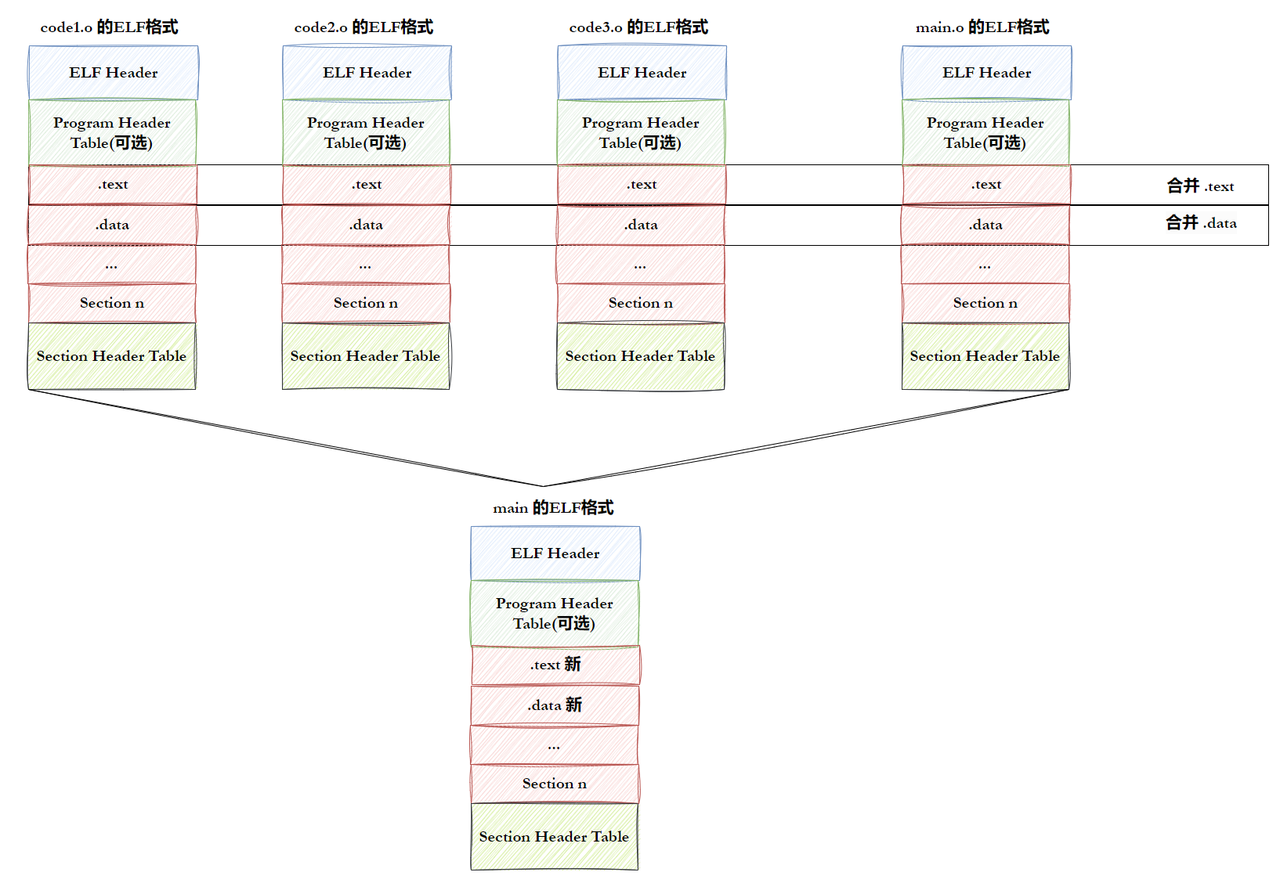
将多个目标文件(.o)和库文件合并成可执行文件,主要完成 3 件事:节合并 、符号解析 、地址重定位。
步骤 1:目标文件的节合并
链接器会将所有输入目标文件的同名节合并成一个新的节:
- 所有
.text节合并成一个新的.text节(存储所有代码)。- 所有
.data节合并成一个新的.data节(存储所有已初始化数据)。- 所有
.bss节合并成一个新的.bss节(存储所有未初始化数据)。
合并过程示意图:
步骤 2:符号解析
链接器会收集所有目标文件和库文件中的符号(函数名、变量名),建立全局符号表,然后解析每个未定义符号(Ndx=UND):
- 对于用户定义的符号(如
run函数):从其他目标文件中查找对应的定义。- 对于库符号(如
puts函数) :从依赖的库(如 C 标准库libc.so)中查找对应的定义。
步骤 3:地址重定位
这是链接过程的核心 ------ 修正所有未定义符号的地址。以hello.o中的callq run为例:
- 合并后,
run函数在新的.text节中的地址是0x400529(假设)。- 链接器根据
.rel.text重定位表的信息,找到callq run指令的位置(偏移0x1a)。- 将原来的
00 00 00 00替换为run函数的实际地址(相对偏移)。
重定位后的机器码:
bash
objdump -d a.out | grep -A 10 "<main>"输出:
0000000000400506 <main>:
400506: f3 0f 1e fa endbr64
40050a: 55 push %rbp
40050b: 48 89 e5 mov %rsp,%rbp
40050e: 48 8d 3d 0f 00 00 00 lea 0xf(%rip),%rdi # 400524 <main+0x1e>
400515: e8 0a 00 00 00 callq 400524 <puts@plt> # puts的实际地址
40051a: b8 00 00 00 00 mov $0x0,%eax
40051f: e8 05 00 00 00 callq 400529 <run> # run的实际地址
400524: b8 00 00 00 00 mov $0x0,%eax
400529: 5d pop %rbp
40052a: c3 retq可以看到,callq指令的地址已经被修正为实际的函数地址。
3.2 阶段 2:ELF 可执行文件加载 ------ 从磁盘到内存的 "变身"
可执行文件生成后,双击或在终端运行时,操作系统会将其加载到内存中并执行。这个过程的核心是将 ELF 文件的段(Segment)加载到进程的虚拟地址空间,并完成初始化。
3.2.1 加载的核心原则:Section 合并为 Segment
ELF 文件中的**"节"(Section)** 是链接器的操作单位,而**"段"(Segment)** 是操作系统加载的操作单位。加载时,操作系统会根据程序头表的描述,将属性相同的节合并成一个 Segment,然后加载到内存中。
合并原则:
- 可读 + 可执行(R E):如
.text、.rodata等节合并成代码段。- 可读 + 可写(RW):如
.data、.bss、.got等节合并成数据段。
这样做的目的是:
- 减少内存碎片 :内存分配的基本单位是页(通常 4KB),合并后可以减少占用的内存页数。例如:
.text节 4097 字节 +.init节 512 字节 = 4609 字节,合并后占用 2 个页(8KB);如果不合并,会占用 3 个页(12KB)。- 统一权限管理:同一 Segment 的所有内容拥有相同的访问权限,方便操作系统进行内存保护(如代码段只读,防止被篡改)。
3.2.2 加载的完整流程
以a.out的加载为例,完整流程如下:
- 创建进程 :操作系统创建一个新的进程(分配 PID、进程控制块
task_struct等)。 - 分配虚拟地址空间:为进程分配虚拟地址空间,划分出代码区、数据区、堆区、栈区、共享库区等。
- 读取 ELF 头和程序头表 :操作系统读取
a.out的 ELF 头,找到程序头表的位置,解析每个LOAD段的信息。 - 加载 Segment 到内存 :
- 对于代码段(R E):将文件中对应的内容读取到虚拟地址空间的代码区,设置权限为 "只读 + 可执行"。
- 对于数据段(RW) :将文件中对应的内容读取到虚拟地址空间的数据区,设置权限为 "可读 + 可写";对于
.bss节,分配内存并清零(.bss在文件中不占空间)。
- 初始化动态链接 :如果可执行文件依赖动态库(如
libc.so),操作系统会启动动态链接器(ld-linux.so),加载依赖的动态库,完成符号解析和重定位。 - 设置程序入口 :将 CPU 的程序计数器(PC)指向 ELF 头中
e_entry字段指定的入口地址(如0x4004e0),程序开始执行。
3.2.3 虚拟地址空间与 ELF 加载的关系
现代操作系统采用 "虚拟地址空间" 机制,每个进程都有独立的虚拟地址空间,与物理内存通过页表映射。ELF 文件在编译时就已经进行了 "统一编址"------ 即文件中的代码和数据已经分配了虚拟地址,加载时只需将这些虚拟地址映射到物理内存即可。
例如,a.out的代码段虚拟地址是0x400000,加载时操作系统会将这个虚拟地址范围映射到物理内存的某个区域,进程执行时直接使用0x400000开始的虚拟地址访问代码。
用readelf -h查看可执行文件的入口地址:
bash
readelf -h a.out | grep "Entry point"
# 输出:Entry point address: 0x4004e0这个地址就是程序开始执行的虚拟地址,对应**_start函数(C 运行时库的入口函数),_start**函数会初始化栈、调用动态链接器、最终调用main函数。
3.2.4 加载后的内存布局
以 64 位 Linux 系统为例,a.out加载后的虚拟地址空间布局大致如下:
高地址
+------------------------+
| 内核空间(内核代码/数据) |
+------------------------+
| 命令行参数/环境变量 |
+------------------------+
| 栈区(向下增长) |
+------------------------+
| 共享库区 | # 动态库(如libc.so)加载区域
+------------------------+
| 堆区(向上增长) |
+------------------------+
| 数据段(.data、.bss等) | # 虚拟地址:0x600000左右
+------------------------+
| 代码段(.text等) | # 虚拟地址:0x400000左右
+------------------------+
| 只读数据段(.rodata等) |
+------------------------+
低地址四、实战:用工具分析 ELF 文件 ------ 亲手拆解 ELF 黑盒
掌握了 ELF 的理论后,我们用常用工具实战分析 ELF 文件,加深理解。
4.1 常用工具清单
| 工具 | 功能 | 常用命令 |
|---|---|---|
| readelf | 查看 ELF 文件的详细信息(ELF 头、节、程序头表等) | readelf -h(ELF 头)、readelf -S(节)、readelf -l(程序头表)、readelf -s(符号表) |
| objdump | 反汇编 ELF 文件,查看机器码 | objdump -d(反汇编.text 节)、objdump -s(查看节内容) |
| file | 查看文件类型 | file a.out |
| ldd | 查看可执行文件依赖的动态库 | ldd a.out |
| size | 查看 ELF 文件各节的大小 | size a.out |
4.2 实战 1:分析目标文件的重定位信息
以hello.o为例,查看重定位表和符号表,理解重定位的必要性:
bash
# 1. 查看符号表,找到未定义符号
readelf -s hello.o | grep "UND"
# 输出:
# 12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
# 13: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run
# 2. 查看重定位表,找到需要修正的地址
readelf -r hello.o
# 输出:
# Relocation section '.rel.text' at offset 0x78 contains 2 entries:
# Offset Info Type Sym. Value Sym. Name + Addend
# 0000000000000010 00000c0200000004 R_X86_64_PLT32 0000000000000000 puts - 4
# 000000000000001a 00000d0200000004 R_X86_64_PLT32 0000000000000000 run - 4
# 3. 反汇编查看未重定位的机器码
objdump -d hello.o | grep -A 5 "callq"
# 输出:
# f: e8 00 00 00 00 callq 14 <main+0x14> # puts的调用地址为0
# 14: b8 00 00 00 00 mov $0x0,%eax
# 19: e8 00 00 00 00 callq 1e <main+0x1e> # run的调用地址为04.3 实战 2:分析可执行文件的节合并与地址重定位
链接生成a.out后,查看合并后的节和重定位后的地址:
bash
# 1. 查看合并后的.text节大小
readelf -S a.out | grep -A 1 ".text"
# 输出:
# [11] .text PROGBITS 00000000004004e0 000004e0
# 0000000000000056 0000000000000000 AX 0 0 1
# 2. 查看符号表中已定义的符号地址
readelf -s a.out | grep -E "main|run|puts"
# 输出:
# 59: 0000000000400506 37 FUNC GLOBAL DEFAULT 11 main
# 60: 0000000000400529 6 FUNC GLOBAL DEFAULT 11 run
# 61: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@GLIBC_2.2.5 (2)
# 3. 反汇编查看重定位后的机器码
objdump -d a.out | grep -A 10 "<main>"
# 输出:
# 0000000000400506 <main>:
# 400506: f3 0f 1e fa endbr64
# 40050a: 55 push %rbp
# 40050b: 48 89 e5 mov %rsp,%rbp
# 40050e: 48 8d 3d 0f 00 00 00 lea 0xf(%rip),%rdi # 400524 <main+0x1e>
# 400515: e8 0a 00 00 00 callq 400524 <puts@plt> # puts的实际地址
# 40051a: b8 00 00 00 00 mov $0x0,%eax
# 40051f: e8 05 00 00 00 callq 400529 <run> # run的实际地址可以看到,**main和run的地址已经被分配(0x400506和0x400529),callq**指令的地址也被修正为实际地址。
4.4 实战 3:分析动态库的 ELF 结构
动态库(.so)也是 ELF 文件,类型为DYN(共享目标文件),我们以 C 标准库libc.so.6为例:
bash
# 1. 查看动态库的ELF类型
file /lib/x86_64-linux-gnu/libc.so.6
# 输出:/lib/x86_64-linux-gnu/libc.so.6: ELF 64-bit LSB shared object, x86-64, version 1 (GNU/Linux), dynamically linked
# 2. 查看动态库的程序头表
readelf -l /lib/x86_64-linux-gnu/libc.so.6 | grep "LOAD"
# 输出:
# LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
# 0x00000000001e68d8 0x00000000001e68d8 R E 1000
# LOAD 0x00000000001e74e0 0x00000000003e74e0 0x00000000003e74e0
# 0x0000000000008f48 0x000000000000b3e8 RW 1000
# 3. 查看动态库中的符号(如printf)
readelf -s /lib/x86_64-linux-gnu/libc.so.6 | grep -E "printf$"
# 输出:
# 1731: 000000000005f860 61 FUNC GLOBAL DEFAULT 13 printf五、ELF 文件的核心作用 ------ 为什么它能成为 Linux 的 "标准"?
ELF 文件之所以能成为 Linux/Unix 系统的标准可执行文件格式,核心在于它的灵活性 和统一性:
- 统一格式:目标文件、可执行文件、动态库、核心转储文件都采用 ELF 格式,工具(如 readelf、objdump)可以统一处理,降低开发和维护成本。
- 跨平台兼容:ELF 支持 32 位 / 64 位架构、不同 CPU(x86、ARM、RISC-V 等),只需编译时指定目标架构,即可生成对应的 ELF 文件。
- 支持动态链接:ELF 的程序头表、GOT(全局偏移表)、PLT(过程链接表)等结构,完美支持动态链接,实现了代码共享和模块化复用。
- 调试友好:ELF 保留了符号表、重定位表等调试信息,调试器(如 gdb)可以通过这些信息实现断点调试、变量查看等功能。
总结
ELF 文件看似复杂,但只要抓住 "结构→流程→工具" 三个核心,就能逐步拆解它的神秘面纱。希望这篇文章能帮助你从 "会用" 到 "懂原理",在 C/C++ 开发和 Linux 系统学习的道路上更上一层楼。
如果你在实际操作中遇到了 ELF 相关的问题(如链接错误、动态库加载失败),欢迎在评论区交流~ 也可以尝试用本文介绍的工具分析自己的程序,加深对 ELF 原理的理解!