现在信创推进得越来越快,金融、政务、能源这些关键行业,都在忙着把核心系统的数据库,从Oracle、MySQL这些国外的换成金仓(KingbaseES)。说句实在的,整个替换过程中,最关键也最容易出岔子的,就是数据迁移------它就相当于源库和目标库之间的一座桥,桥要是出问题,后面所有业务都没法正常跑。迁移的时候,最核心的就是把控好数据的完整性和一致性,简单说就是数据不能丢、不能坏、格式要对,而且源库和金仓里的数据得一模一样。要是这两点没抓好,业务中断、合规不过关都是常有的事。结合我这些年做过的十几个金仓迁移项目,踩过不少坑,今天就把最常见的四大风险整理出来,跟大家说说这些坑是怎么来的,还有具体怎么规避,希望能帮大家少走弯路,顺利完成替换。

金仓数据库(KingbaseES)官网链接:https://www.kingbase.com.cn/,作为国产数据库领军者,以全栈可控、高性能、高兼容的核心优势,成为超九成央企及千行百业的数字化转型首选,为关键业务筑牢数据根基。
一、字符集/时区/精度丢失:最隐蔽的隐性数据失真风险
做过金仓迁移的同行应该都有体会,源库和金仓在字符集、时区、数据精度上的那些差异,特别容易造成隐性的数据失真。这种问题最让人头疼的地方在于,迁移的时候全程没任何报错,日志看着全是正常的,可等业务上线了,查数据、做统计的时候,各种问题才冒出来,而且排查起来特别费时间,有时候查好几天都找不到根源。尤其是从Oracle迁到金仓,时间精度丢了、特殊字符乱码这两个问题,出现的次数最多,对业务的影响也最直接,一点都不能马虎。
1.1 风险规避方案
这类隐性风险,其实不用怕,只要抓好"迁移前统一配置、迁移中精准映射、迁移后校验"这三步,基本都能规避,具体操作我跟大家说清楚,都是实操中能用得上的:
-
统一环境配置:迁移前,一定要先排查源库的字符集、时区配置,确保金仓目标库的对应参数和源库完全对齐。如果源库是GBK编码,金仓直接配置成UTF8就行,UTF8完全兼容GBK,能有效避免特殊字符丢失;时区建议统一改成Asia/Shanghai,贴合国内业务场景,要是源库是UTC时区,记得在迁移工具里设置好时区转换规则。另外,一定要重点检查金仓的datetime_precision参数,按照源库Oracle的时间精度,把这个参数设成对应数值,避免出现精度截断的问题。
-
精准类型映射:这里给大家一个省时间的建议,别手动写映射脚本,太费时间还容易出错,优先用金仓自带的KDTS工具来配置映射,这个工具里已经内置了Oracle和金仓的常用类型映射关系,直接用就行,核心的映射关系我整理在下面了,大家可以直接参考。
-
特殊字符预处理:要是源库里有特殊字符、生僻字,迁移前一定要提前处理,这一步特别关键,能避免后期排查乱码浪费大量时间。很多人图省事,跳过这一步,后期出了问题再返工,反而更费时间。
Oracle与金仓核心类型映射表:
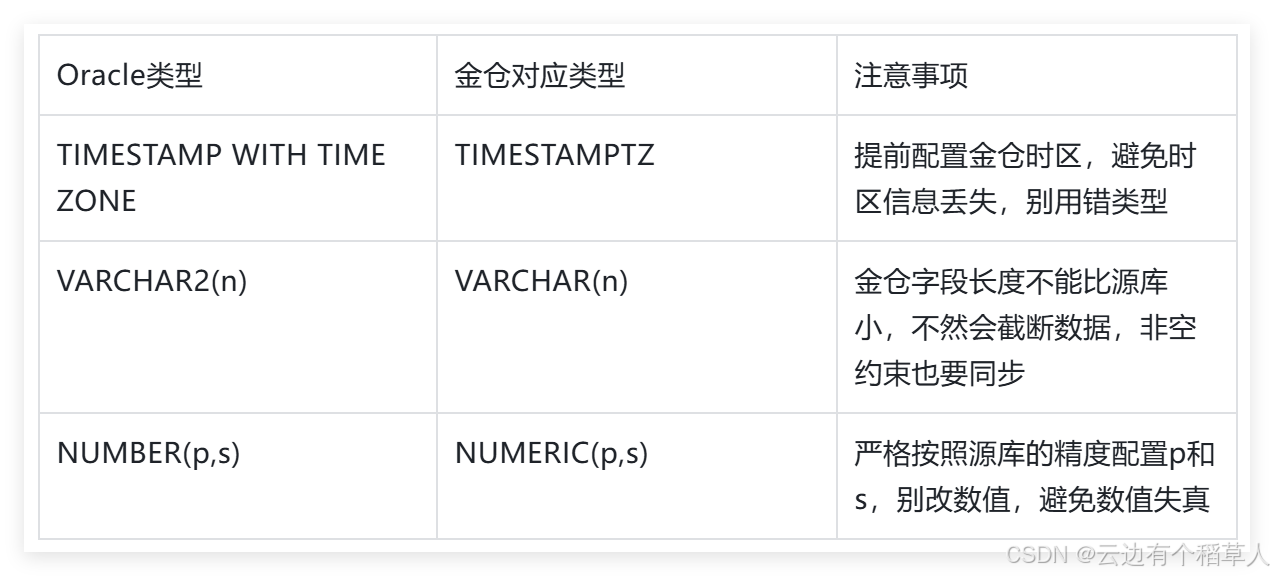
1.2 迁移后校验:
迁移完别着急进入下一环,一定要做校验,这几句SQL我平时实操经常用,直接复制,替换成自己的表名和字段名就能执行,特别方便:
sql
-- 校验TIMESTAMPTZ精度(6代表微秒级,需与源库Oracle的TSTZ精度一致)
-- 查询结果DATETIME_PRECISION小于源库,需及时调整金仓参数
SELECT COLUMN_NAME, DATA_TYPE, DATETIME_PRECISION FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = '目标表名' AND DATA_TYPE = 'timestamptz';
-- 校验时区一致性(源库UTC时间对应金仓Asia/Shanghai时间,不一致需校准)
SELECT ID, 时间字段 FROM 目标表名
WHERE 时间字段 = TO_TIMESTAMPTZ('2026-02-07 17:30:00.123456', 'YYYY-MM-DD HH24:MI:SS.FF TZR');1.3 特殊字符预处理细节
这部分细节很多人容易忽略,我跟大家说清楚实操步骤,都是踩过坑总结出来的:
-
工具预处理:不用找第三方工具,直接用金仓自带的kbconv工具,把源库GBK编码的生僻字、特殊符号批量转换成UTF8格式,这个工具适配性很好,大部分特殊字符都能处理,省不少事。
-
预迁移测试:别一上来就大批量迁移,先选一部分包含特殊字符的样本数据,做一次小规模预迁移,验证一下字符转换的效果,提前排查乱码、截断问题,要是有问题,早处理早省心,避免大批量迁移后再返工。
-
异常兜底:要是遇到个别无法正常转换的特殊字符,别慌,先把这些字符梳理成清单,制定一个合理的替换规则,比如保留原始编码,或者替换成业务能识别的兼容字符,别因为单个字符,导致整个迁移任务中断,得不偿失。
二、大对象(LOB)迁移失败:最容易造成业务损失的风险
在所有金仓迁移的环节里,LOB字段迁移绝对是难度最高、最容易出问题的一个,没有之一。LOB字段主要存两类数据:一类是BLOB二进制文件,比如医疗影像、金融电子合同、工程图纸这些;另一类是CLOB长文本,比如系统日志详情、政务审批材料。这类数据最麻烦的就是体积大,单条就能达到GB级,迁移的时候特别耗服务器资源,不管是内存还是带宽,稍微没配置好,就会出现数据损坏、传输中断、迁移失败的情况,而这些数据又都是核心业务数据,一旦出问题,业务直接受影响,损失不小。
2.1 核心风险成因
我结合自己踩过的坑,跟大家说说LOB迁移失败的主要原因,大家可以对照着排查,提前规避:
-
内存溢出:这是最常见的问题,很多人图省事,还用传统的exp/imp这类导出导入工具来迁移LOB数据,这些工具根本没针对LOB大对象做内存优化,读写GB级的数据时,会占用大量的JVM内存,要是服务器内存不够,或者工具的内存参数没配置好,很容易出现OOM异常,迁移任务直接终止。更麻烦的是,已经迁移的LOB数据,可能会出现片段丢失、格式损坏的情况,而且中断后没法断点续传,只能重新迁移,特别费时间。
-
格式不兼容:Oracle和金仓的LOB存储格式、编码方式本身就不一样,尤其是CLOB长文本字段,要是迁移前不做编码转换,迁移后很可能出现乱码、解析失败的情况;二进制文件(BLOB)也可能没法被业务系统识别,导致数据没法正常使用。另外,要是Oracle里的LOB字段做了压缩、加密处理,迁移前没解密、解压缩,也会导致数据损坏。
-
并发/参数不当:这个主要是操作不规范导致的。比如迁移的时候,没暂停源库的业务,源库的LOB字段还在被持续写入、修改,这时候迁移,很容易出现数据传输冲突,导致数据丢失、重复写入;还有就是没根据LOB数据的规模,调整迁移工具的读写并发度、读取批次等参数,不仅传输效率低,还容易出现传输断片,尤其是单条LOB超过1GB时,出问题的概率会大大增加。
2.2 风险规避方案
LOB迁移其实有个核心思路,就是不用传统工具,用金仓KDTS专用工具,迁移前优化参数,迁移后做好校验,这三步做好了,基本能避开所有坑,具体步骤我跟大家说清楚,亲测有效:
- 迁移前参数优化(重点规避内存溢出)
迁移LOB数据前,一定要优化KDTS工具的核心参数,重点规避内存溢出的问题,下面这些配置,直接复制到kdts-xxx.yml文件里就能用,不用自己摸索参数:
sql
# kdts-xxx.yml LOB迁移专用配置,规避内存溢出
table-with-large-object-fetch-size: 5 # LOB<1GB表,读取记录数设为5,别设太大
large-table-split-threshold-rows: 5000000 # 大表拆分阈值,超过500万行自动分块迁移,减轻服务器压力
large-table-split-max-chunk-num: 5 # 最大拆分块数,和迁移线程数匹配就行
# 单条LOB≥1GB专用配置,进一步降低内存占用
table-with-big-large-object-fetch-size: 3 # 读取记录数设为3,避免内存溢出- 专用工具迁移(两种方式,按需选择)
根据LOB数据的量,选择对应的迁移方式,少量和大量的处理方式不一样,这样效率更高,也更稳定:
sql
-- 单一BLOB导入(金仓端,少量文件适用,比如几条核心电子合同)
-- 注意:文件路径必须是金仓服务器能访问到的本地路径,不然会报错
INSERT INTO 目标表名 (ID, FILE_BLOB, FILE_NAME, UPLOAD_TIME)
VALUES (1, lo_import('/home/kingbase/blob_files/test.pdf'), 'test.pdf', NOW());
-- KDTS批量迁移(大量LOB适用,比如批量医疗影像、电子合同)
-- 重点:开启large-object-handle=true,工具会自动识别LOB字段,处理格式转换和分块传输
kdtscli migrate --source-type oracle --source-url jdbc:oracle:thin:@//192.168.1.100:1521/ORCL \
--source-username scott --source-password tiger --target-type kingbase \
--target-url jdbc:kingbase8://192.168.1.200:54321/TEST --target-username system \
--target-password kingbase --tables "SCOTT.TEST_LOB" --large-object-handle true- 迁移后校验(关键步骤,不能省略)
LOB数据迁移完,校验环节绝对不能省,一旦省略,数据损坏、丢失的问题没法发现,后期业务上线就麻烦了。主要用两种方式校验,MD5比对(最精准)和长度比对(辅助),结合起来用,确保数据完整无损坏:
sql
-- BLOB完整性校验(MD5比对,最精准,判断数据是否损坏)
-- 金仓端计算BLOB的MD5值,和Oracle源库的MD5值逐一比对,一致就没问题
SELECT ID, FILE_NAME, MD5(FILE_BLOB::bytea) AS BLOB_MD5 FROM 目标表名;
-- CLOB完整性校验(双重验证,排查截断、乱码)
-- 先看长度和源库是否一致,再看前100个字符样本,避免乱码、解析失败
SELECT ID, LENGTH(CLOB_FIELD) AS CLOB_LENGTH, SUBSTR(CLOB_FIELD, 1, 100) AS CLOB_SAMPLE FROM 目标表名;三、增量同步断点不准:容易被忽略,但影响极大的风险
对于那些数据量特别大的核心系统,比如金融核心系统、政务服务平台,数据量能达到TB级甚至PB级,这类系统根本没法长时间暂停业务来做全量迁移,一旦暂停业务,损失太大。所以大多数时候,我们都会用"全量迁移+增量同步"的模式,先把源库的基础数据全迁到金仓,然后用增量同步工具,捕获源库后续的新增、修改、删除操作,实时同步到金仓,确保两端数据一致,等测试通过了再切换业务。这个模式虽然好,但有个很容易被忽略的风险------断点不准,一旦断点出问题,麻烦就大了,不仅排查费劲,还会影响业务切换。
3.1 核心风险与成因
先跟大家说说断点不准的核心风险,再讲成因,提前规避:
断点不准主要有三大风险,对业务影响都很大:
- 一是增量数据丢失,源库新增的核心业务数据,比如金融交易记录、政务办理数据,没同步到金仓,导致两端数据不一致,切换业务后会出现数据缺失;
- 二是重复同步,同一笔数据多次写入金仓,引发业务逻辑异常,比如金融系统的重复记账,这个问题特别严重;
- 三是同步中断,增量同步任务终止后,没法快速恢复断点,只能重新做全量迁移,延误业务切换周期,增加项目成本。
再说说常见成因,结合实操经验,主要有四种,大家可以对照排查:一是Oracle归档日志被手动清理,或者被系统自动轮转覆盖,导致增量工具没法获取完整的变更日志,出现SCN断层,没法准确捕获断点;二是要是源库是Oracle RAC环境,多个节点间的SCN跳跃,增量工具没正确捕获,导致断点记录偏差;三是工具的断点机制不合理,只记录单一SCN,没考虑未提交的事务,一旦事务回滚,断点就会错乱;四是网络抖动、服务器宕机,导致源库日志解析中断,断点记录没及时更新,出现断点丢失。
3.2 风险规避方案
断点不准的问题,核心解决思路就是用金仓KFS增量同步工具,开启双断点记录,优化配置、做好监控,具体从三方面入手,实操可落地:
- 优化同步配置(提前规避断点偏差)
想要提前规避断点偏差,就要启用SCN一致性校验,排查源库的SCN是否连续,同时开启LSN缓存,防止网络抖动导致断点丢失,命令和配置如下,直接复制执行、修改就行:
sql
# SCN一致性校验,排查源库SCN连续性,避免出现断层
# 执行后会生成校验报告,有断层就先修复归档日志,再做增量同步
kfs_check_scn_consistency --source-url jdbc:oracle:thin:@//192.168.1.100:1521/ORCL \
--source-username scott --source-password tiger --output /home/kingbase/kfs/scn_check_report.txt
# 开启LSN缓存(修改kfs_config.yml配置文件),避免网络抖动丢失断点
# 缓存会保存最新断点,就算同步中断,重启工具也能快速恢复,不用重新开始
lsn_cache: {enable: true, cache_path: /home/kingbase/kfs/lsn_cache, cache_expire: 3600}- 断点恢复与监控
就算出现断点不准、同步中断的问题,也不用慌,用增量补迁就能修复,同时做好实时监控,及时发现异常,具体命令和SQL如下,直接复制修改就能用:
sql
# 增量补迁(基于时间戳区间,规避SCN偏差,避免重迁、漏迁)
# 根据同步中断的时间,设置补迁区间,精准补全缺失数据,还能避免重复同步
kdtscli incremental --source-type oracle --target-type kingbase \
--source-url jdbc:oracle:thin:@//192.168.1.100:1521/ORCL --target-url jdbc:kingbase8://192.168.1.200:54321/TEST \
--source-username scott --source-password tiger --target-username system --target-password kingbase \
--start-time "2026-02-07 00:00:00" --end-time "2026-02-07 18:00:00" --enable-conflict-check true
# 监控断点状态(金仓端SQL),实时查看同步进度和断点一致性
# 要是SOURCE_SCN和TARGET_SCN偏差超过1000,就要及时排查异常(比如网络、日志问题)
SELECT SYNC_TASK_ID, SOURCE_SCN, TARGET_SCN, SYNC_STATUS, LAST_SYNC_TIME FROM KFS_SYNC_BREAKPOINT;- 额外注意事项(实操避坑关键)
这三点细节都是实操中避坑的关键,能有效减少断点不准的问题:
-
日志留存:千万不要手动清理Oracle归档日志,同时要合理配置日志轮转周期,至少保留迁移期间,以及迁移完成后7天的日志,确保增量工具能获取完整的变更日志,避免SCN断层。
-
RAC环境适配:要是源库是Oracle RAC环境,一定要启用KFS工具的RAC节点自适应功能,这个功能能自动识别RAC集群的多个节点,捕获节点间的SCN跳跃,避免断点记录偏差。
-
异常预案:提前制定好增量同步中断的应急预案,明确断点恢复的流程、责任人、操作步骤,一旦出现同步中断,能快速响应、及时解决,减少对业务的影响。
四、校验手段缺失:过不了合规审计,还会留下业务隐患
在实际迁移项目中,我发现很多企业都有一个共性的误区------"重迁移、轻校验",觉得只要迁移任务执行完成,表行数对得上,就说明迁移成功了。其实这种想法大错特错,仅比对表行数,根本没法发现那些隐性的偏差,比如时间精度截断、个别特殊字符乱码、数值精度失真这些问题。这些隐性偏差,不仅会影响后续业务的正常开展,更重要的是,对于金融、医疗、政务这些对合规要求严格的行业,要是没有完整的校验记录和校验报告,根本过不了合规审计,业务没法正常上线,反而会带来更大的麻烦。
4.1 核心风险(实操中常见的隐患)
-
隐性偏差难发现:表行数对得上,但行内的数据可能存在各种问题,比如时间精度降级、个别字符乱码、数值精度丢失,这些问题通过行数比对根本察觉不到,只有后续业务使用时才会暴露,到时候再排查,不仅耗时耗力,还可能影响业务正常开展。
-
合规验收受阻:金融、医疗、政务这些行业,在数据库替换项目的合规审计中,明确要求提供完整的数据一致性校验报告,证明源库和金仓的数据完全一致。要是没有完善的校验手段,没法提供完整的校验记录和报告,就过不了合规验收,业务没法正常上线,延误项目周期。
-
增量校验缺失:很多企业只重视全量迁移数据的校验,忽略了增量同步数据的实时校验。这样一来,源库和金仓的数据会慢慢脱节,比如源库新增、修改的数据,没同步到金仓,或者同步出现偏差,等到业务切换时才发现数据不一致,只能重新同步、排查问题,延误上线周期。
4.2 风险规避方案(建立全流程校验体系,实操可落地)
想要规避这类风险,核心就是要改变"重迁移、轻校验"的观念,建立一套覆盖迁移全流程的校验体系,采用"工具+脚本"双保障的方式,既保证数据一致性,又能满足合规审计的要求,具体实施步骤如下,实操可落地:
- 全流程校验体系(从迁移前到增量同步,全程覆盖)
校验不是只在迁移后做,而是要贯穿整个迁移过程,覆盖四个阶段,每个阶段的校验重点不一样,大家对照执行就行,不用自己摸索:
-
迁移前预校验:重点核查源库和金仓的环境兼容性,比如字符集、时区、数据库版本是否一致;同时全面核查表结构一致性,比如字段类型、长度、约束、索引是否对应,提前排除基础偏差,避免迁移后出现大规模数据问题。
-
迁移中实时校验:迁移过程中,要实时监控数据迁移进度,关注异常数据的占比,建议设置一个异常阈值(比如异常数据占比超过0.1%,就立即终止迁移);尤其是LOB、大表这些高危数据,要实时抽查迁移完整性,发现问题及时排查。
-
迁移后全量校验:迁移完成后,要做全方位的校验,包括表级(行数、字段约束)、行级(单条数据比对)、校验和级(MD5比对),杜绝隐性偏差,确保源库和金仓的数据完全一致。
-
增量实时校验:增量同步期间,要实时校验增量操作的同步准确性,比如新增、修改、删除的数据,是否准确同步到金仓,避免两端数据脱节,为后续业务切换做好准备。
- 工具与脚本校验(双保障,既高效又精准)
实操中,建议采用"专用工具校验+自定义脚本校验"的双保障模式,这样既能保证校验效率,又能确保校验准确性,兜底核心业务数据的风险:
-
专业工具校验:用金仓KDTS工具做自动化全量校验,这个工具能自动比对源库和金仓的数据,还能生成HTML或PDF格式的校验报告,不用手动整理,直接用于合规审计,特别方便。
-
自定义脚本校验:对于那些核心业务表,比如金融交易表、政务审批表,建议编写行级校验脚本,精准比对单条数据,兜底风险,避免工具校验出现遗漏。
sql
# KDTS全量校验(生成HTML/PDF报告,用于合规审计)
# 替换成自己的源库、目标库参数和表名,执行后会自动生成校验报告
kdtscli validate --source-type oracle --target-type kingbase \
--source-url jdbc:oracle:thin:@//192.168.1.100:1521/ORCL --target-url jdbc:kingbase8://192.168.1.200:54321/TEST \
--source-username scott --source-password tiger --target-username system --target-password kingbase \
--tables "SCOTT.TEST1,SCOTT.TEST2" --validate-level "table,row,checksum" \
--report-path /home/kingbase/validate_report --report-format "HTML"
# 核心表行级校验SQL(金仓端,精准比对单条数据,兜底核心表风险)
CREATE VIEW 目标表校验视图 AS
SELECT ID, MD5(CONCAT(COL1, COL2, TIMESTAMPTZ_COL::TEXT)) AS ROW_CHECKSUM FROM 目标表名;
SELECT s.ID, s.ROW_CHECKSUM AS 源库校验和, t.ROW_CHECKSUM AS 金仓校验和
FROM 源表校验视图@ORACLE_LINK s
LEFT JOIN 目标表校验视图 t ON s.ID = t.ID
WHERE s.ROW_CHECKSUM != t.ROW_CHECKSUM OR t.ROW_CHECKSUM IS NULL;五、总结与核心建议(结合实操经验,干货汇总)
其实金仓迁移的四大核心风险,并没有大家想象的那么难规避,总结下来就是一句话:提前规划、工具赋能、精准配置、全量校验。只要抓好这十六个字,结合金仓KDTS、KFS专用工具,再按照上面说的实操步骤来做,就能平稳完成数据库替换,避免业务损失,少走很多弯路。
5.1 四大核心实施建议
下面这四点,是我结合多年实操经验,总结的核心建议,都是干货,大家对照执行,基本能避开所有常见坑:
-
迁移前:一定要统一源库和金仓的环境配置,梳理好数据类型映射规则,提前预处理特殊字符、生僻字,并且做一次小规模的预迁移测试,提前排查基础问题。
-
迁移中:别用传统工具,优先用金仓KDTS、KFS专用工具,根据数据规模优化好核心参数,控制好读写并发度,实时监控迁移进度,发现异常及时终止、排查,别硬撑。
-
迁移后:一定要做全量+增量双重校验,不仅要比对表行数,还要做行级、校验和级比对,留存好校验报告,及时修复发现的异常数据,确保数据一致性。
-
全流程:建立完善的监控机制,实时关注迁移和同步进度,提前制定好异常应急预案,不管是迁移中断、断点不准,还是数据异常,都能快速响应、及时解决。
5.2 迁移后收尾关键动作
迁移完成后,还有两个关键动作,很多人容易忽略,但对后续的合规审计、后续系统替换,都很重要,一定要做好:
-
资料留存:把迁移过程中的所有日志、配置文件、校验报告,都妥善留存好,一方面用于后续问题溯源,另一方面也能应对合规审计,避免后期需要的时候找不到。
-
经验沉淀:把迁移过程中遇到的问题、解决方案,都梳理总结一下,形成一套标准化的迁移流程,后续再做其他系统的金仓替换,就能直接复用,节省项目时间和成本。