一、线程池
通过ThreadPoolExecutor类创建线程池时7个核心参数:
- corePoolSize:线程池的核心线程数,即即使线程池中的线程处于空闲状态,这些线程也不会被终止,除非设置了allowCoreThreadTimeOut为true。
- maximumPoolSize:线程池允许的最大线程数。当线程池中的线程数达到corePoolSize后,如果继续提交任务,线程池会尝试复用已有的线程执行新任务。如果已有的线程都在执行任务,则会创建新的线程,直到总线程数达到maximumPoolSize。
- keepAliveTime:当线程池中的线程数超过corePoolSize时,多余的空闲线程在等待新任务的时间超过keepAliveTime后会被终止。
- unit:keepAliveTime参数的时间单位,如秒、分钟等,通常使用TimeUnit枚举值表示。
- workQueue:用于保存待处理任务的阻塞队列。常见的阻塞队列实现包括ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue等。
- threadFactory:用于设置创建线程的工厂,可以通过自定义线程工厂来设置线程名称、优先级等属性。
- handler:拒绝策略,当线程池和队列都满时,如何处理新提交的任务。常见的拒绝策略包括AbortPolicy(抛出异常;默认)、CallerRunsPolicy(由调用线程执行任务)、DiscardPolicy(丢弃任务)和DiscardOldestPolicy(丢弃队列中最老的任务)。
二、nginx
Nginx中有几类配置文件,它们的作用不同:
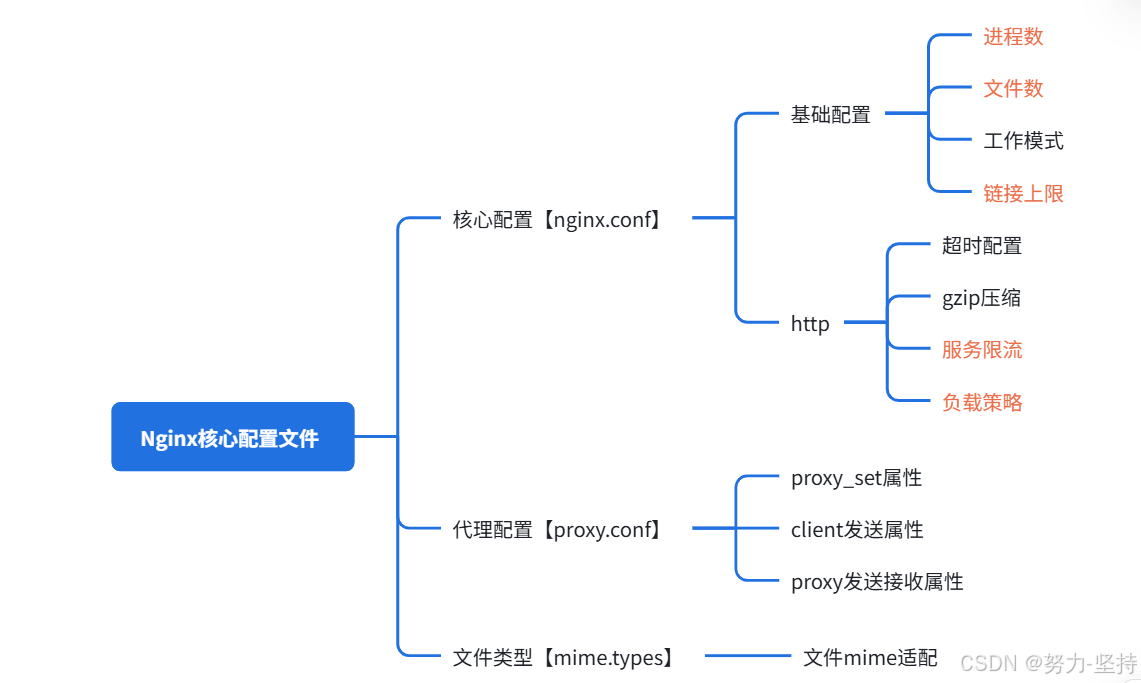
而我们一般对于Nginx的配置、调优都是在 nginx.conf文件中进行的。
页面静态化实现技术有:velocity、freemarker、Thymeleaf。
2.1 基于IP限流
基于IP限流可以限制特定IP地址在单位时间内的请求频率。这有助于防止单个IP地址对服务器发起过多的请求,导致服务器过载。
配置项:
| 配置项 | 说明 |
|---|---|
| limit_req_zone | 用于定义限流区域和相关参数。这个区域用于存储客户端IP地址的请求计数信息,并根据定义的速率限制来处理请求。例如,limit_req_zone binaryremoteaddrzone=mylimit:10mrate=1r/s;这里,binary_remote_addr zone=mylimit:10m rate=1r/s; 这里,binaryremoteaddrzone=mylimit:10mrate=1r/s;这里,binary_remote_addr是客户端的IP地址(二进制格式),mylimit是区域名称,10m是分配给该区域的共享内存大小,1r/s表示每秒只允许一个请求。 |
| limit_req | 在需要限流的 nginx.conf中的http中的location 中使用,引用之前定义的限流区域。当客户端的请求频率超过指定的限制时,Nginx会采取相应的措施,如延迟请求或拒绝请求。例如,limit_req zone=mylimit burst=5 nodelay; 这里,mylimit是之前定义的限流区域名称,burst=5表示在超过速率限制时,还可以处理额外的5个请求,而nodelay表示立即拒绝超出限制的请求,而不是将它们放入队列中等待处理。 |
示例:如果限制每个IP地址每秒只能发送一个请求到/api路径的话;可以如下配置:
Nginx
http {
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s;
server {
listen 80;
location /api {
limit_req zone=mylimit burst=5 nodelay;
# 其他配置...
}
}
}说明:如果某个IP地址在1秒内发送了超过一个请求到/api路径,Nginx将根据burst参数的值来决定如何处理这些额外的请求。上面的示例中,由于设置了burst=5,所以Nginx会允许额外的5个请求,但会立即拒绝超出这个限制的请求(由于nodelay参数的存在)。
2.2 基于连接数限流
连接数限流可以限制单个IP地址或特定key的并发连接数。这有助于防止单个IP地址或客户端建立过多的连接,耗尽服务器资源。
配置项:
| 配置项 | 说明 |
|---|---|
| limit_conn_zone | 用于定义一个共享内存区域,这个区域用于存储每个客户端的连接数信息。例如,limit_conn_zone binaryremoteaddrzone=addr:10m;这行代码定义了一个名为addr、大小为10MB的共享内存区域,用于根据客户端的IP地址(binary_remote_addr zone=addr:10m; 这行代码定义了一个名为addr、大小为10MB的共享内存区域,用于根据客户端的IP地址(binaryremoteaddrzone=addr:10m;这行代码定义了一个名为addr、大小为10MB的共享内存区域,用于根据客户端的IP地址(binary_remote_addr)来限制连接数。 |
| limit_conn | 用于在指定的位置限制客户端的连接数。它引用之前通过limit_conn_zone定义的共享内存区域和key,当连接数达到限制时,新的连接将被拒绝。例如,location / { limit_conn addr 10; } 这行代码表示,对于IP地址为key的连接,最大并发连接数为10。如果某个IP地址的并发连接数超过了这个限制,新的连接请求将被Nginx拒绝。 |
示例:
Nginx
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
listen 80;
server_name example.com;
location / {
limit_conn addr 10;
# 其他配置...
}
}
}说明:在上述示例中,limit_conn_zone定义了一个名为addr的连接数限流区域,该区域使用IP地址作为key,并设置了10MB的共享内存区域来存储状态信息。在location块中,limit_conn指令引用了连接数限流区域,并设置了10作为单个IP地址的最大并发连接数。如果某个IP地址的并发连接数超过了这个限制,Nginx将拒绝新的连接请求。
2.3 IP限流和连接数限流区别
一个连接中可以发起多个请求。这就是最核心的区别。
- 关注点不同:IP限流关注的是请求的频率,而连接数限流关注的是同时建立的连接数量。
- 应用场景不同:IP限流更适用于防止密码暴力破解等场景,因为它关注的是请求的频率;而连接数限流更适用于防止资源耗尽的场景,因为它关注的是连接的数量。
- 效果不同:IP限流可能会允许某个IP地址在短时间内建立多个连接,但会限制它的请求频率;而连接数限流则会限制某个IP地址同时建立的连接数量,不论请求频率如何。
三、spring cache
3.1 spring cache 简介
Spring Cache是Spring框架提供的一种缓存抽象机制,或者说缓存框架,主要简化应用中的缓存操作。它通过将方法的返回值缓存起来,当下次调用同一方法时,如果传入的参数与之前的调用相同,就可以直接从缓存中获取结果,而不需要再执行方法体中的代码。这种方式可以显著提高系统的性能和响应速度。
Spring Cache的主要特点包括:
- 声明式缓存:通过在方法上添加注解,如@Cacheable、@CachePut、@CacheEvict等,来声明缓存的行为,无需手动编写缓存代码。这使得缓存功能更加易于集成和使用。
- 多种缓存支持:Spring Cache提供了对多种缓存框架的支持,包括Redis、EhCache、Guava Cache、Caffeine等。这意味着你可以根据项目的需要选择合适的缓存实现。
- 基于AOP的缓存:Spring Cache利用了面向切面编程(AOP)的技术,实现了基于注解的缓存功能。这使得业务代码无需关心底层使用了什么缓存框架,只需简单地添加注解即可实现缓存功能,降低了对代码的侵入性。
- 动态指定缓存Key和条件:Spring Cache还支持使用SpEL(Spring Expression Language)表达式来动态地指定缓存的Key和条件等。这使得缓存的配置更加灵活和强大。
Spring Cache主要是通过CacheManager接口来统一不同的缓存技术。CacheManager是Spring提供的各种缓存技术抽象接口;Spring Cache 的具体架构如下:
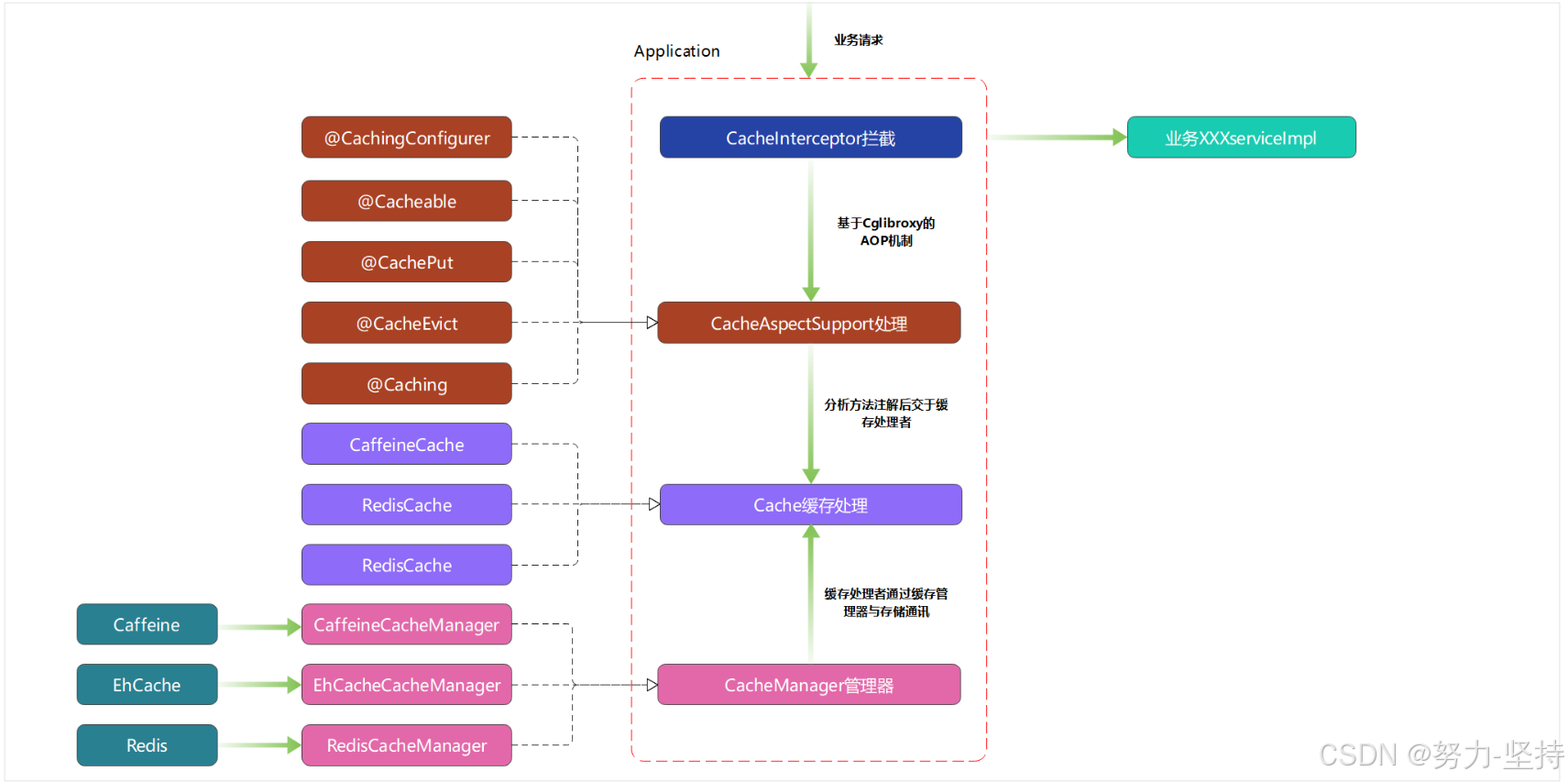
- CacheInterceptor缓存拦截器是Spring AOP(面向切面编程)中的一个拦截器,实现了MethodInterceptor接口。当一个方法被带有缓存注解(如@Cacheable、@CachePut、@CacheEvict等)标记时,CacheInterceptor会拦截这个方法的调用。拦截后,CacheInterceptor会根据注解的指示,检查缓存、从缓存中获取数据、将数据存入缓存或删除缓存中的数据。
- CacheAspectSupport缓存切面支持 是CacheInterceptor的基类,提供了缓存操作的核心实现。它封装了缓存操作的逻辑,如计算缓存键、检查缓存、从缓存中获取数据、将数据存入缓存或删除缓存中的数据等。当CacheInterceptor拦截到一个方法调用时,它会委托给CacheAspectSupport来处理实际的缓存操作。
- CacheManager 缓存管理器 是Spring提供的缓存管理器接口,它维护着多个Cache。不同的缓存技术需要实现不同的Cache接口。当应用程序需要缓存数据时,它会先通过CacheManager获得某个Cache,然后使用该Cache的API进行数据的存取。
3.2 常用注解
在Spring Cache中,常见的缓存注解主要有@EnableCaching 、 @Caching、@Cacheable、@CachePut、@CacheEvict和@CacheConfig。
在不同的业务操作时;一般的缓存操作大概如下:
- 新增:删除分页、列表的缓存,再将当前这条数据存缓存。
- 修改:删除分页、列表和当前这条数据的缓存。
- 删除:删除分页、列表和id对应的那些缓存。
- 查询:不会修改数据;所以只做存储缓存。将本次查询条件或者分页条件对应的查询结果缓存到缓存中。
若不在上述的操作中且缓存逻辑不定,可以全部缓存删除,保持数据一致。
3.3 使用spring cache
step1.引入依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!--cache底层的实现不同引入不一样-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>step2.配置缓存:
step3.使用缓存: