一、CrewAI 是什么?能解决什么问题?
1.1 核心定位
CrewAI 是一款专为 多智能体协作 设计的 Python 框架,它允许你像 "组建团队" 一样,创建不同角色的 AI 智能体(Agent),并为每个智能体分配专属任务(Task),最终让多个智能体协作完成复杂任务。
1.2 核心优势
- 角色分工:模拟真实团队协作,不同 Agent 承担不同角色(如研究员、作家、分析师);
- 任务编排:支持串行 / 并行执行任务,后序任务可复用前序任务的结果;
- 低代码开发:无需复杂配置,几行代码即可搭建多智能体协作流程;
- 兼容多模型:支持本地大模型(如 Ollama 部署的 Gemma、Qwen)、云端 API(如 OpenAI、DeepSeek)。
1.3 适用场景
- 技术文档 / 博客自动生成(如本文案例);
- 数据分析 + 报告撰写全流程自动化;
- 多步骤的复杂知识问答;
- 项目需求分析 + 方案设计 + 代码开发。
1.4 名词概念解释
Agents(智能体):自主可控单元,可执行任务、做决定、与其他Agent协作,类比团队成员,具备特定技能。
核心属性:
-
role(角色):定义其在团队中的功能定位
-
goal(目标):明确Agent需实现的核心目的
-
backstory(背景信息):为Agent提供上下文,辅助其贴合角色输出
**Tasks(任务):**分配给Agent的具体工作,包含执行所需全部细节。
核心属性:
-
description(任务描述):简明说明任务要求
-
agent(分配的Agent):指定负责执行该任务的Agent
-
expected_output(期望输出):详细描述任务完成标准
-
Tools(工具列表):为Agent提供执行任务可使用的工具
-
output_json(输出json):指定输出格式为单一json对象
-
output_file(输出文件):将任务结果保存至文件,并指定格式
-
context(上下文):指定前置任务,其输出作为当前任务的上下文
**Processes(流程):**协调Agent执行任务的机制,类比项目经理,确保任务执行效率与计划一致,核心有两种模式:
-
sequential(顺序流程):按预定义任务列表顺序执行,前置任务输出作为后置任务上下文
-
hierarchical(分层流程):指定管理Agent,负责计划、授权、验证任务;不预先分配任务,根据Agent能力分配并审查产出
Crews(团队):
一组Agent的集合,协作完成一系列任务,定义任务执行策略、Agent协作方式及整体流程。
核心属性:Tasks(任务列表)、Agents(Agent列表)、Process(执行流程)、manager_llm(分层模式下的大模型)、language(使用语言)、language_file(语言文件)。
**Pipleline(流水线):**结构化工作流程,允许多个Crew顺序或并行执行,用于组织多阶段复杂流程,前置阶段输出作为后置阶段输入。
关键术语:
-
Stage(阶段):流水线的独立部分,可为顺序或并行Crews
-
Run(运行):流水线处理的单个实例
-
Branch(分支):Stage内的并行执行逻辑
-
Trace(轨迹):单个输入在整个流水线中的运行路径及转换记录
二、测试环境搭建
2.1 安装依赖
首先安装 CrewAI 核心库和必要依赖:
bash
pip install crewai
pip install langchain
pip install openai2.2 获取大模型API接口
这里以Ollama本地所部署模型gemma3:1b为例。
python
model="gemma3:1b"
api_key="test"
api_base="http://localhost:11434/v1"2.3 案例目标
创建两个智能体:
- 技术研究员:研究 "Python 读取各类文件的方法",输出带代码的研究报告;
- 技术博客作家:基于研究报告,撰写入门级中文技术博客。
python
from crewai import Agent, Task, Crew, Process
from crewai.llm import LLM
# =====================================================
# LLM 配置(添加中文输出强制约束)
# =====================================================
llm = LLM(
model="gemma3:1b",
api_key="test",
api_base="http://localhost:11434/v1",
temperature=0.7,
)
# =====================================================
# Agents(优化角色描述,强化中文输出要求)
# =====================================================
researcher = Agent(
role="Python技术研究员",
goal="系统梳理Python读取各类文件的方法,提供准确、可运行的代码示例和使用场景说明。",
backstory="精通Python文件操作,擅长总结不同场景下的最优文件读取方案,注重示例的可复现性。",
llm=llm,
verbose=True,
allow_delegation=False,
# Agent级别强化中文输出
system_prompt="你的所有研究成果必须用中文呈现,代码注释也需为中文,技术术语需给出中文解释。"
)
writer = Agent(
role="Python入门教程作家",
goal="将技术研究成果转化为通俗易懂的中文教程,适合Python初学者理解和实践。",
backstory="擅长把复杂的技术知识点拆解为简单步骤,用中文清晰讲解,示例贴近新手实际使用场景。",
llm=llm,
verbose=True,
allow_delegation=False,
# Agent级别强化中文输出
system_prompt="你撰写的教程必须全程使用中文,语言简洁易懂,代码注释为中文,避免专业术语堆砌。"
)
# =====================================================
# Tasks(替换为"Python读取文件"相关任务,逻辑匹配)
# =====================================================
research_task = Task(
description=(
"深入研究:Python读取各类文件的方法。\n"
"重点包括:\n"
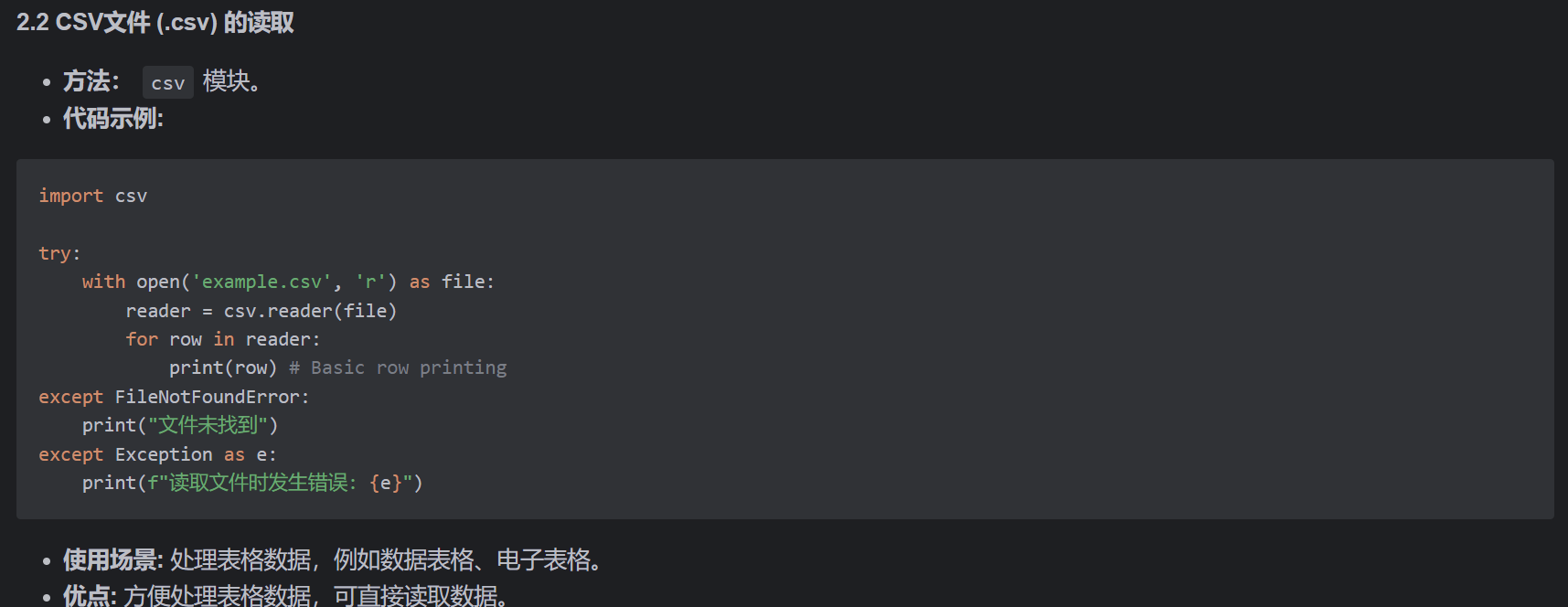
"1. 文本文件(.txt)的读取(基础方法、按行读取、编码处理);\n"
"2. CSV文件(.csv)的读取(内置csv模块、pandas库);\n"
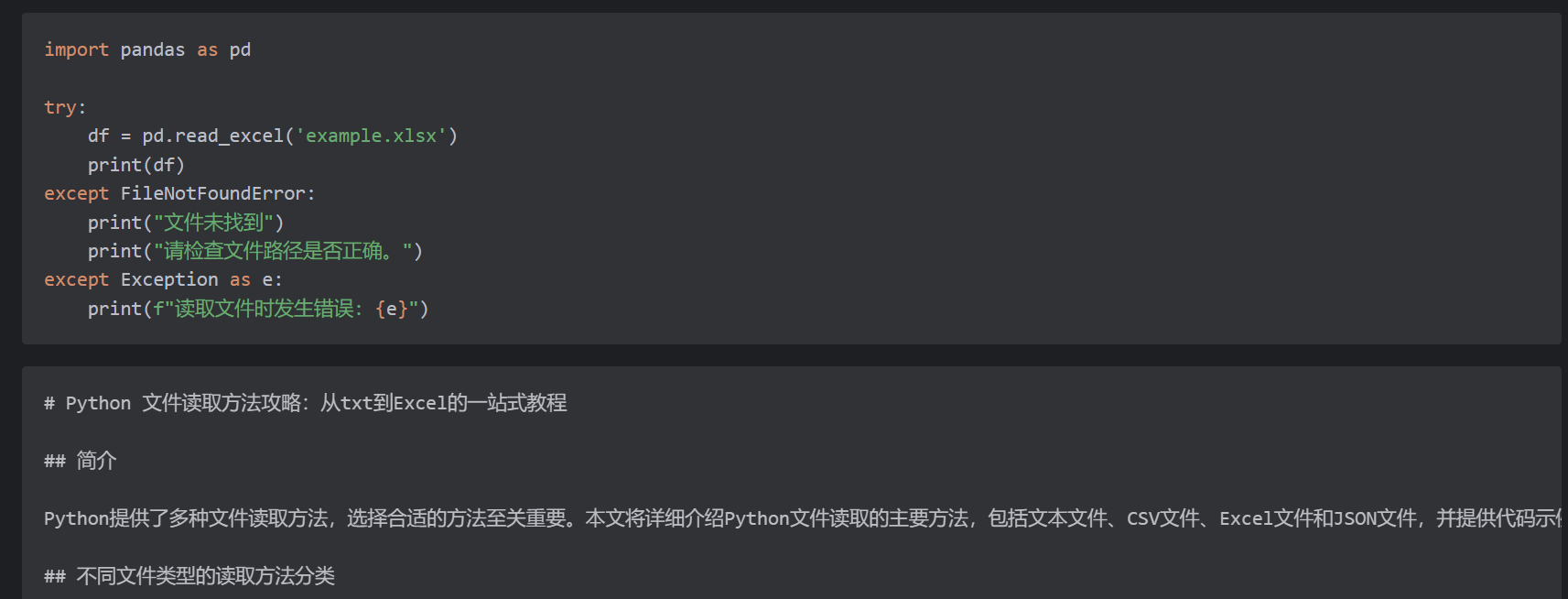
"3. Excel文件(.xlsx/.xls)的读取(pandas库);\n"
"4. JSON文件(.json)的读取(内置json模块);\n"
"5. 常见问题处理(文件路径、编码错误、空文件、大文件读取优化)。\n"
"要求:必须提供完整、可运行的中文注释代码示例,注明每种方法的适用场景和优缺点。"
),
agent=researcher,
expected_output=(
"一份中文研究报告,包含:\n"
"1. 不同文件类型的读取方法分类;\n"
"2. 每种方法的完整代码示例(中文注释);\n"
"3. 常见问题及解决方案;\n"
"4. 各方法的适用场景和性能对比。"
),
)
write_task = Task(
description=(
"基于研究报告,撰写入门级中文技术博客。\n"
"标题:《Python读取文件全攻略:从txt到Excel的一站式教程》。\n"
"要求:\n"
"1. 全文不少于500字,纯中文撰写,无任何英文;\n"
"2. 结构清晰,分章节讲解不同文件类型的读取方法;\n"
"3. 代码示例附带详细中文注释,新手可直接复制运行;\n"
"4. 加入新手常见坑点和避坑建议;\n"
"5. 格式为Markdown,包含标题、小标题、代码块、注意事项等。"
),
agent=writer,
context=[research_task],
expected_output="大约500字的纯中文Markdown技术博客,包含清晰的章节划分、可运行的中文注释代码示例、新手避坑指南。",
)
# =====================================================
# Crew
# =====================================================
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential,
verbose=True,
)
# =====================================================
# Run
# =====================================================
if __name__ == "__main__":
print("开始执行Python文件读取方法研究与博客撰写任务...")
result = crew.kickoff()
output = result.raw
with open("python_file_reading_guide.md", "w", encoding="utf-8") as f:
f.write(output)
print("任务完成!博客已保存至 python_file_reading_guide.md")2.4 组件说明
| 核心组件 | 作用说明 |
|---|---|
LLM() |
配置大模型连接(支持本地 / Ollama / 云端 API),是所有智能体的 "大脑"; |
Agent() |
定义智能体角色,包含 role(角色)、goal(目标)、backstory(背景)三大核心参数; |
Task() |
定义具体任务,description 是任务要求,context 可指定依赖的前置任务; |
Crew() |
组建智能体团队,process 指定任务执行方式(sequential 串行 /hierarchical 分层); |
crew.kickoff() |
启动团队任务执行,返回所有任务的最终结果。 |
2.5 运行结果展示