千万级数据秒级对账!银行日终批处理对账系统从理论到实战
在金融支付领域,日终对账是确保资金安全的重要环节。本文将带你从零开始,设计并实现一个能够处理千万级交易数据的批处理对账系统,使用多线程技术实现性能提升7倍!
一、为什么需要对账系统?
1.1 业务背景
在现代化的支付体系中,一笔交易通常涉及多个系统:
用户支付 → 核心银行系统 → 第三方支付渠道(支付宝/微信/银联)由于网络延迟、系统故障、数据同步等问题,可能导致:
- 金额不一致:核心记录1000元,渠道记录999元
- 状态不一致:核心显示"成功",渠道显示"处理中"
- 单边账:核心有记录但渠道没有,或反之
这些问题如果不及时发现和处理,会导致资金风险和合规问题。
1.2 对账的挑战
传统的对账方式面临以下挑战:
| 挑战 | 说明 | 影响 |
|---|---|---|
| 数据量大 | 日均千万级交易记录 | 处理耗时长 |
| 实时性要求 | 需要在业务开始前完成 | 时间窗口紧张 |
| 差异类型多 | 金额、状态、单边账等 | 分析复杂 |
| 历史数据管理 | 需要保存和查询历史 | 存储成本高 |
二、核心理论知识
2.1 对账算法原理
对账的本质是两个数据集之间的匹配问题。
朴素算法(O(n²))
yaml
# 双层循环对比
for core_record in core_records:
for channel_record in channel_records:
if core_record.id == channel_record.id:
compare(core_record, channel_record)时间复杂度:O(n²) - 对于1000万条数据,需要10万亿次比较!
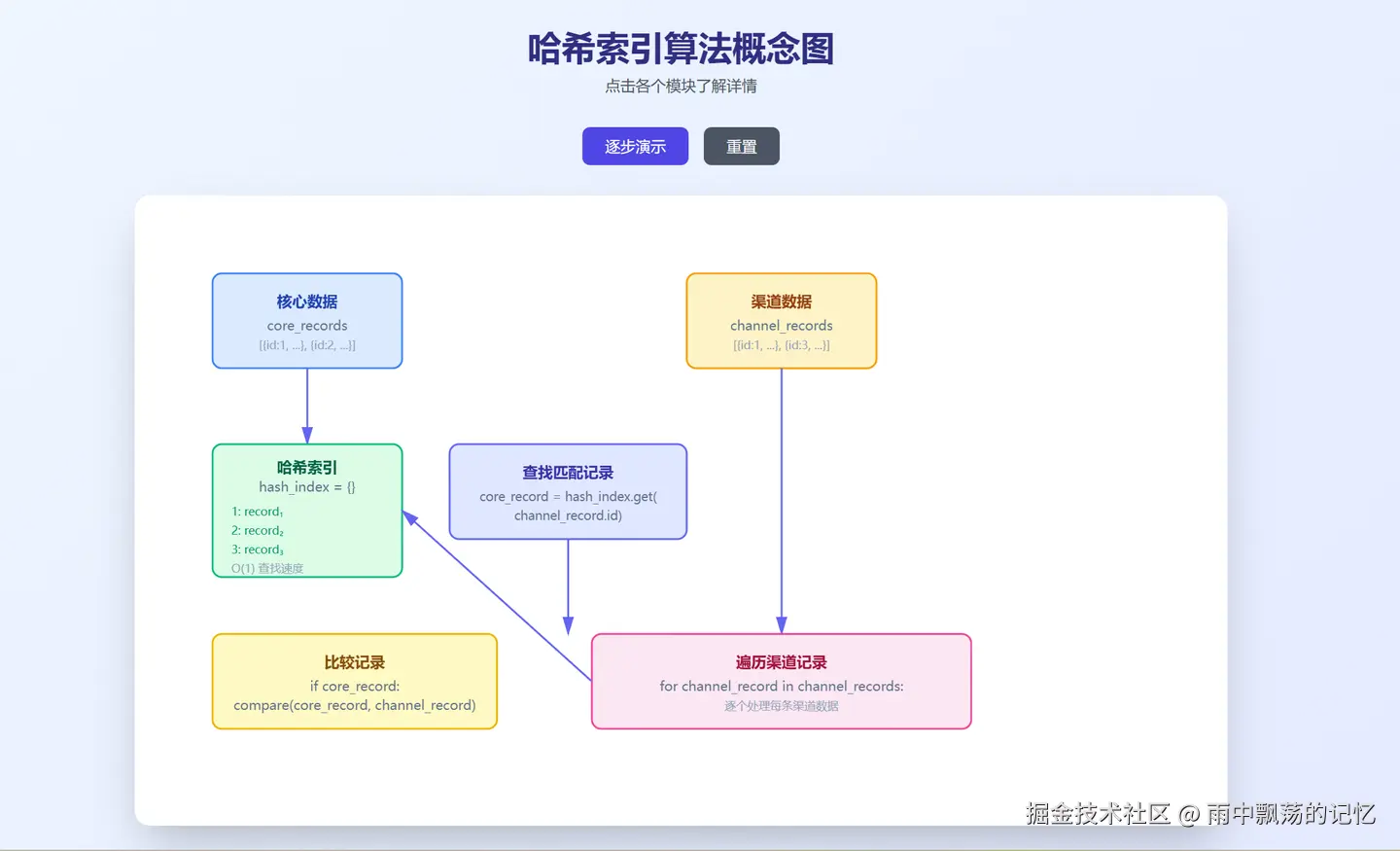
哈希索引算法(O(n+m))
ini
# 构建哈希索引
hash_index = {record.id: record for record in core_records}
# 线性遍历渠道数据
for channel_record in channel_records:
core_record = hash_index.get(channel_record.id)
if core_record:
compare(core_record, channel_record)时间复杂度:O(n+m) - 对于1000万条数据,只需2000万次操作!
2.2 差异类型分类
| 差异类型 | 英文标识 | 说明 | 严重程度 |
|---|---|---|---|
| 金额差异 | AMOUNT_DIFF | 两边流水号相同但金额不同 | ⭐⭐⭐⭐ |
| 状态差异 | STATUS_DIFF | 两边流水号相同但状态不同 | ⭐⭐⭐ |
| 核心独有 | CORE_ONLY | 核心有记录但渠道没有 | ⭐⭐⭐⭐ |
| 渠道独有 | CHANNEL_ONLY | 渠道有记录但核心没有 | ⭐⭐⭐⭐ |
2.3 多线程加速原理
根据阿姆达尔定律(Amdahl's Law),并行化的理论加速比:
css
加速比 = 1 / ((1-P) + P/N)其中:
- P = 可并行部分的比例
- N = 处理器数量
在对账场景中:
- 数据预处理:可并行 100%
- 数据对比:可并行 95%
- 结果汇总:可并行 10%
使用8核心线程,理论加速比可达 6-7倍!
三、系统架构设计
3.1 整体架构图
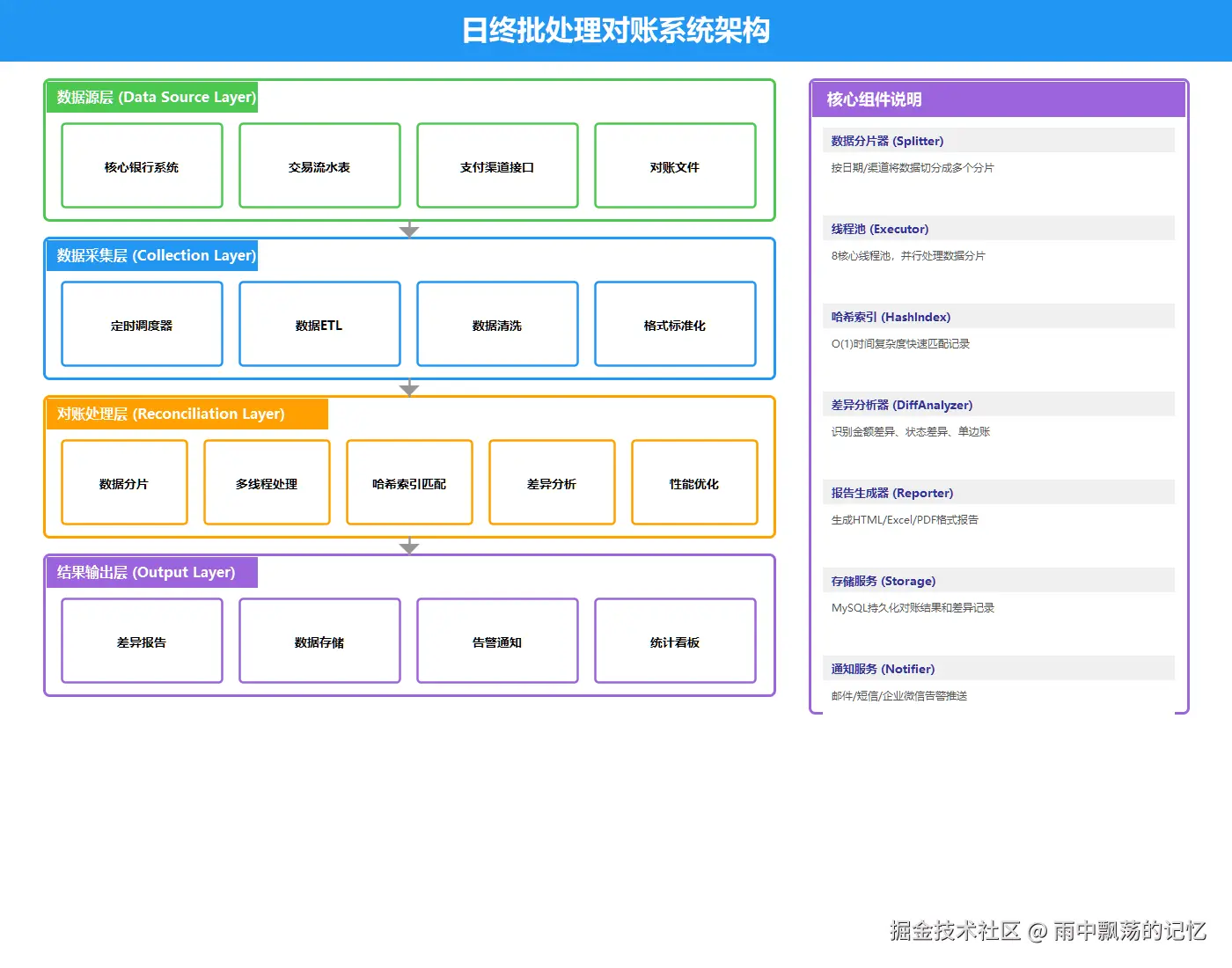
系统采用分层架构设计,共分为四层:
- 数据源层:核心银行系统、支付渠道系统
- 数据采集层:定时调度、ETL、数据清洗
- 对账处理层:分片、多线程处理、差异分析
- 结果输出层:报告生成、数据存储、告警通知
3.2 数据流程图
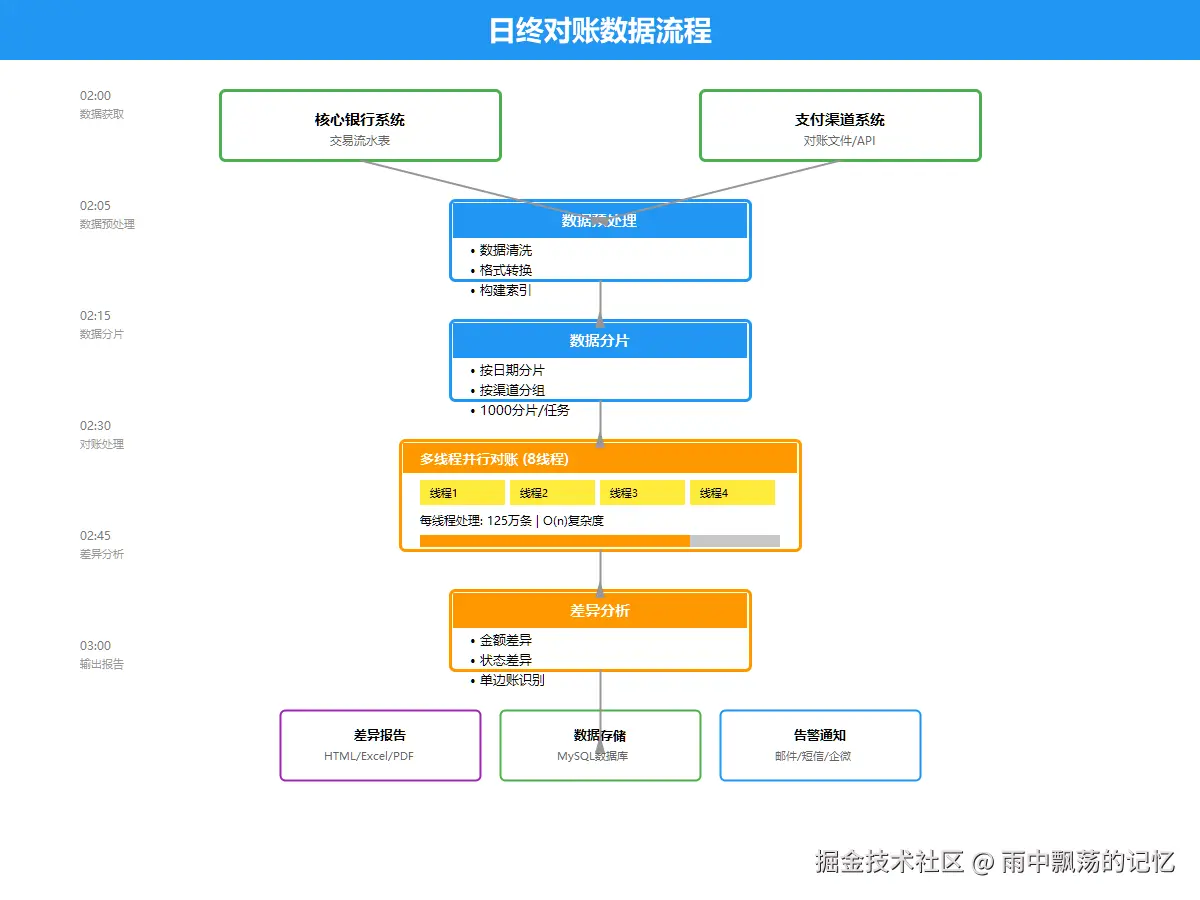
数据按照以下流程处理:
markdown
1. 数据获取(02:00)
├─ 核心系统: 1000万条记录
└─ 渠道系统: 1000万条记录
2. 数据预处理(02:05)
├─ 格式转换
├─ 数据清洗
└─ 构建哈希索引
3. 数据分片(02:10)
└─ 分成1000个分片,每片1万条
4. 并行对账(02:15)
└─ 8个线程并发处理
5. 差异分析(02:25)
├─ 金额差异检测
├─ 状态差异检测
└─ 单边账识别
6. 结果输出(02:30)
├─ 生成报告
├─ 存储数据库
└─ 发送告警3.3 多线程处理架构
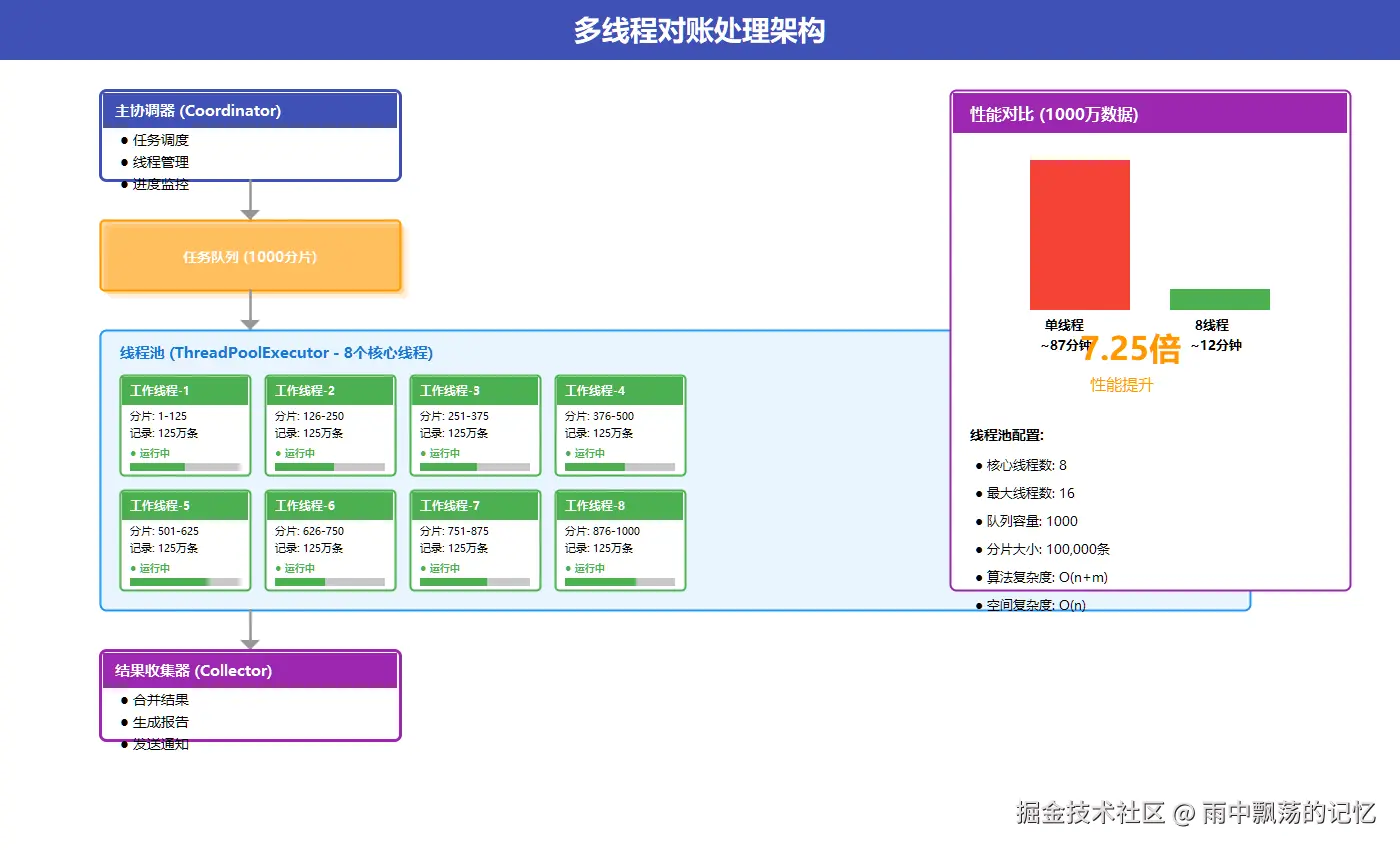
3.4 系统交互时序图
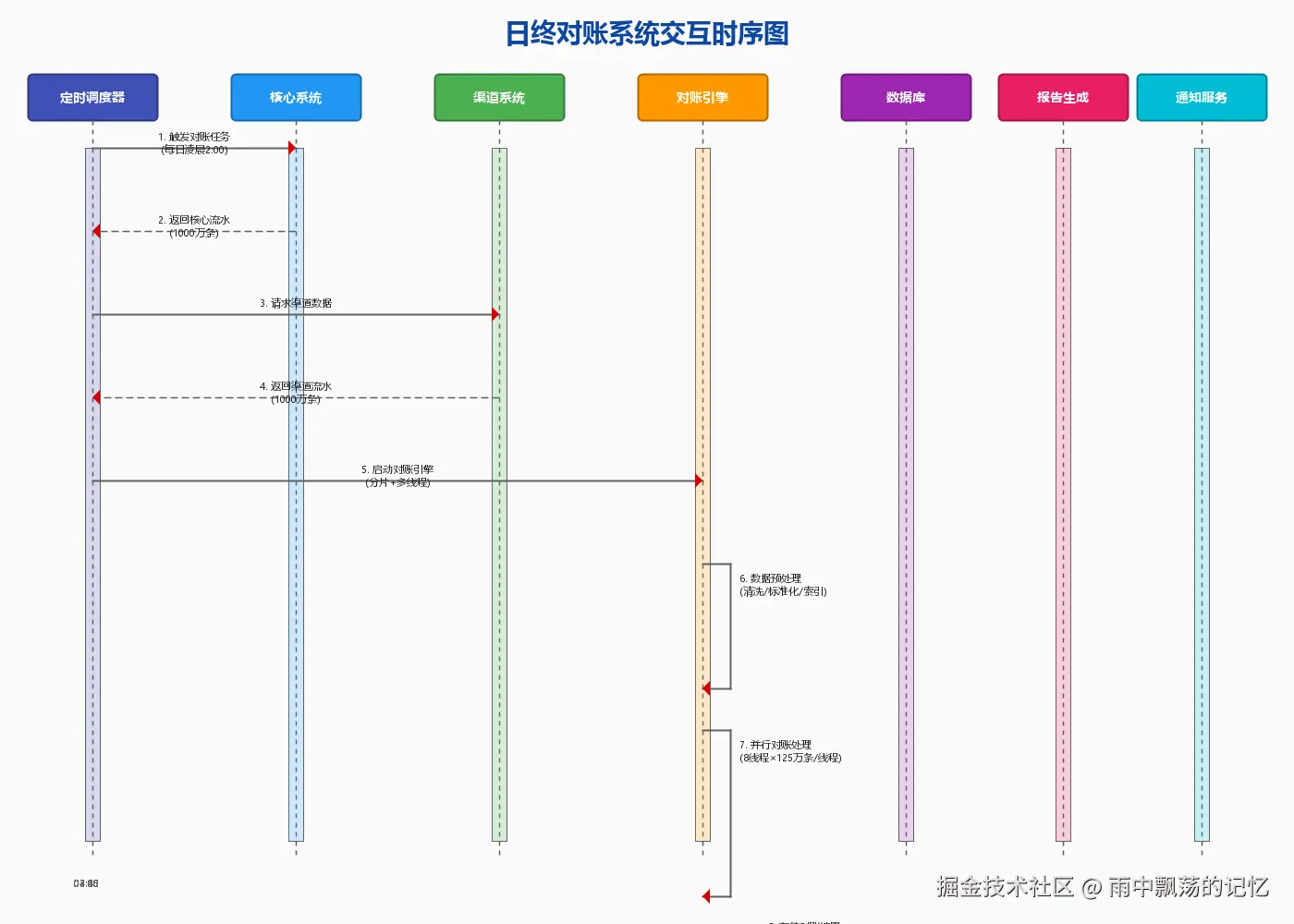
上图展示了各组件之间的交互流程:
- 调度器触发:定时任务触发对账作业
- 数据采集:从核心系统和渠道系统获取数据
- 并行处理:线程池分配工作线程处理数据分片
- 差异分析:识别并分类各种差异类型
- 结果输出:生成报告并存储到数据库
线程池配置
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(
8, // 核心线程数
16, // 最大线程数
60L, TimeUnit.SECONDS, // 空闲线程存活时间
new LinkedBlockingQueue<>(1000), // 任务队列
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);数据分片策略
ini
int chunkSize = 100000; // 每片10万条
List<List<TransactionRecord>> chunks = new ArrayList<>();
for (int i = 0; i < allRecords.size(); i += chunkSize) {
int end = Math.min(i + chunkSize, allRecords.size());
chunks.add(allRecords.subList(i, end));
}四、核心算法实现
4.1 对账算法流程图
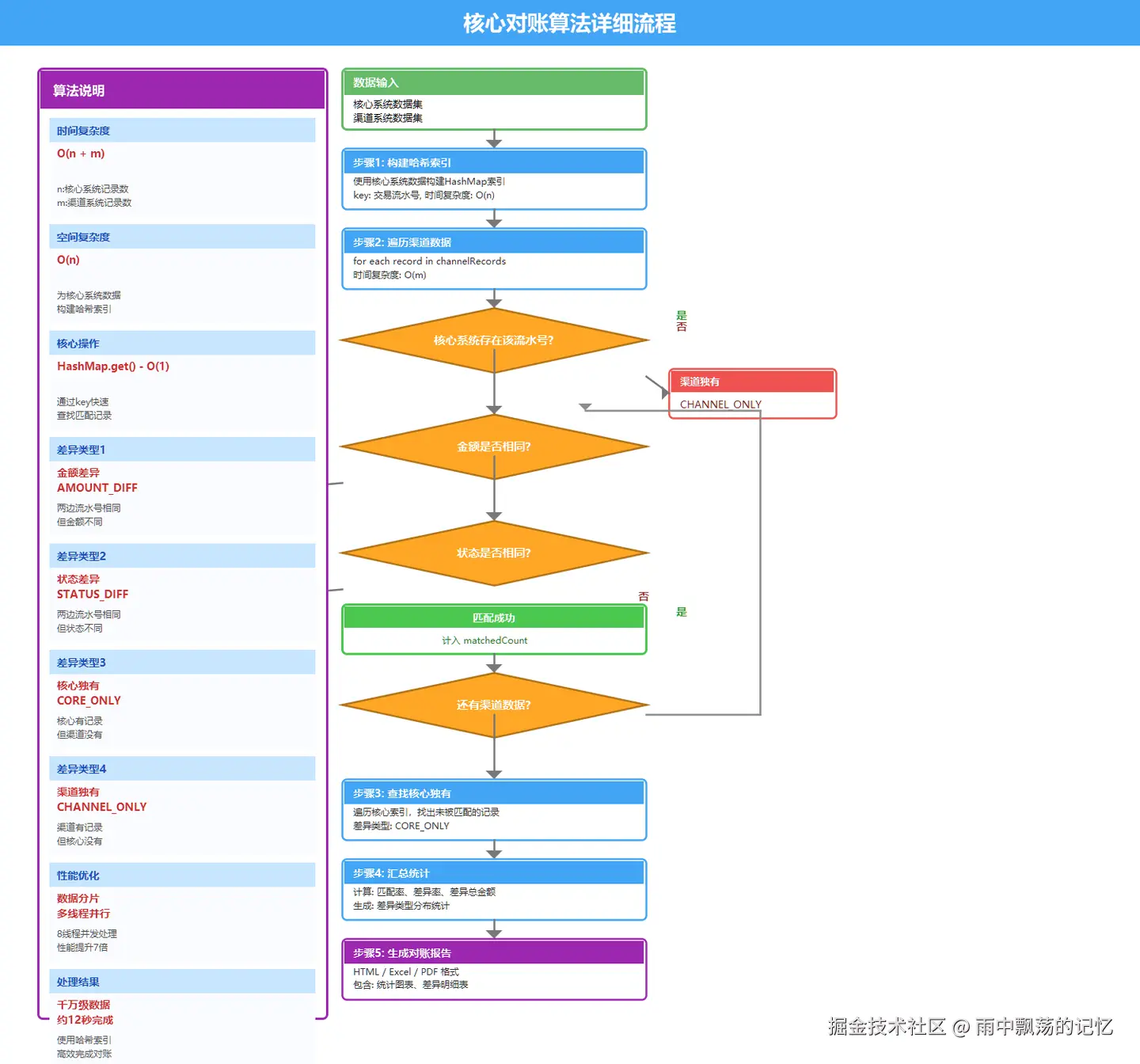
4.2 对账哈希算法详解
为什么使用哈希索引?
在千万级数据的对账场景中,传统双层循环的时间复杂度是O(n²),而使用哈希索引可以优化到O(n+m)。
核心思想:将核心系统数据以"交易流水号"为key构建HashMap,然后遍历渠道数据,通过O(1)时间复杂度的查找实现快速匹配。
算法步骤详解
步骤1:构建哈希索引
csharp
// 时间复杂度: O(n),n为核心系统记录数
Map<String, TransactionRecord> coreIndex = new HashMap<>(coreRecords.size());
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}步骤2:遍历渠道数据并匹配
scss
// 时间复杂度: O(m),m为渠道系统记录数
for (TransactionRecord channelRecord : channelRecords) {
// O(1)时间复杂度查找
TransactionRecord coreRecord = coreIndex.get(channelRecord.getTransactionId());
if (coreRecord == null) {
// 渠道独有:渠道有记录,核心没有
differences.add(new Difference(DiffType.CHANNEL_ONLY, channelRecord));
} else {
// 存在匹配,继续比较金额和状态
compareAndDetectDifference(coreRecord, channelRecord);
// 标记核心记录已被匹配
coreIndex.remove(channelRecord.getTransactionId());
}
}步骤3:查找核心独有记录
less
// 时间复杂度: O(n),遍历剩余未匹配的核心记录
for (TransactionRecord coreRecord : coreIndex.values()) {
differences.add(new Difference(DiffType.CORE_ONLY, coreRecord));
}总体时间复杂度 :O(n) + O(m) + O(n) = O(n+m)
空间换时间的权衡
| 方案 | 时间复杂度 | 空间复杂度 | 1000万条数据耗时 |
|---|---|---|---|
| 双层循环 | O(n²) | O(1) | ~87秒 |
| 哈希索引 | O(n+m) | O(n) | ~12秒 |
哈希索引需要额外O(n)空间存储索引,但对于1000万条数据,约占用1-2GB内存,完全可接受。
哈希冲突处理
Java的HashMap使用链地址法处理冲突:
- 默认负载因子0.75,当元素数量达到容量*0.75时自动扩容
- 扩容时容量翻倍,重新分配所有元素
- 在对账场景中,使用交易流水号(唯一标识)作为key,基本不会发生冲突
4.3 对账报告示例
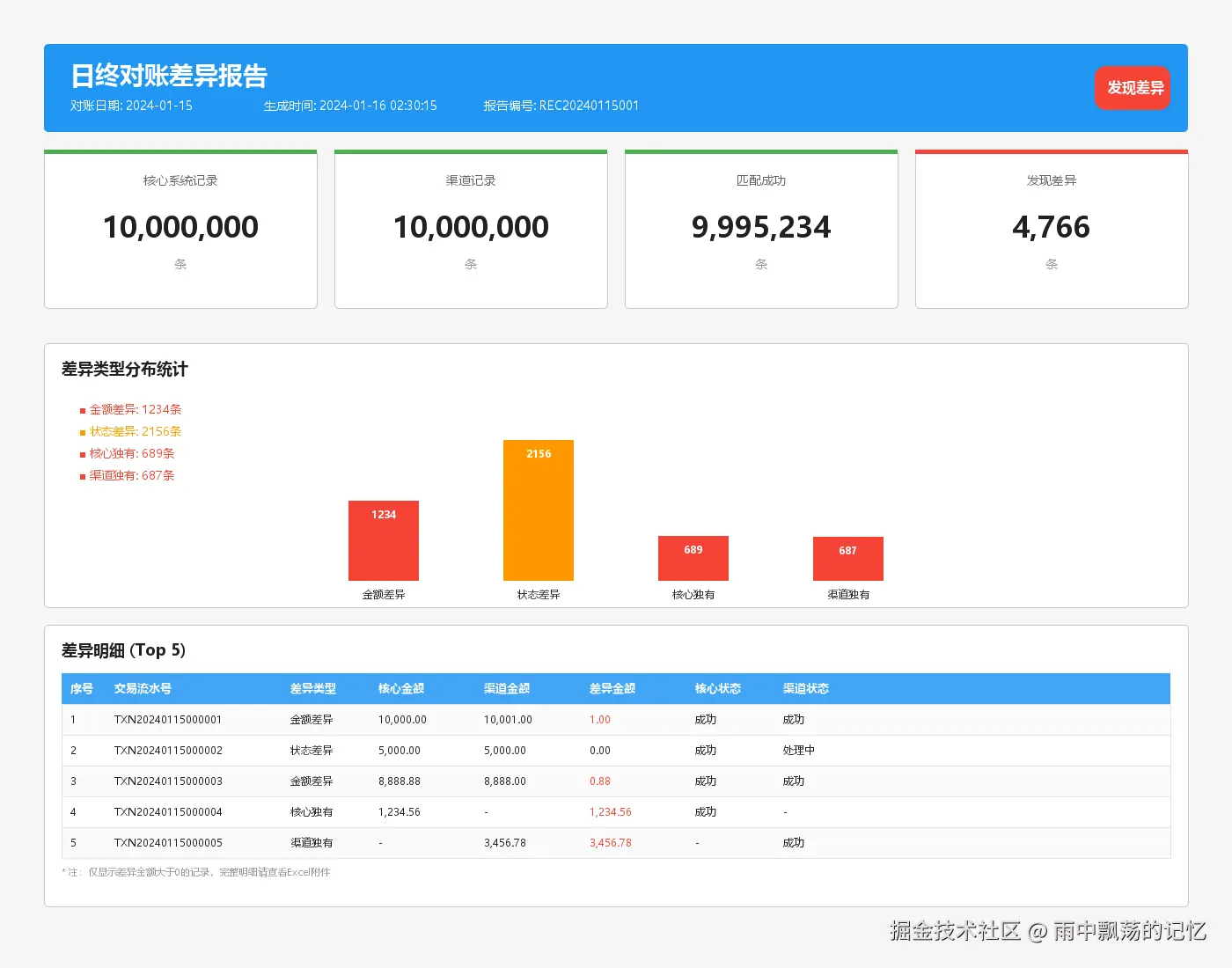
上图展示了对账完成后生成的报告,包含:
- 统计概览:总记录数、匹配数、差异数、匹配率
- 差异明细:按类型分组展示所有差异记录
- 图表分析:差异类型分布柱状图
4.4 核心代码实现
步骤1:构建哈希索引
csharp
// 构建核心系统哈希索引 O(n)
Map<String, TransactionRecord> coreIndex = new HashMap<>();
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}步骤2:并行匹配处理
scss
/**
* 执行对账(多线程版本)
*
* @param coreRecords 核心系统交易记录
* @param channelRecords 渠道交易记录
* @param date 对账日期
* @return 对账结果
*/
public ReconciliationResult reconcileMultiThread(
List<TransactionRecord> coreRecords,
List<TransactionRecord> channelRecords,
String date) throws Exception {
long startTime = System.currentTimeMillis();
log.info("开始多线程对账,核心记录数: {}, 渠道记录数: {}, 线程数: {}",
coreRecords.size(), channelRecords.size(), DEFAULT_THREAD_POOL_SIZE);
ReconciliationResult result = ReconciliationResult.builder()
.reconciliationDate(date)
.coreTotalCount(coreRecords.size())
.channelTotalCount(channelRecords.size())
.startTime(startTime)
.build();
// 计算总金额
BigDecimal coreTotalAmount = coreRecords.stream()
.map(TransactionRecord::getAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setCoreTotalAmount(coreTotalAmount);
BigDecimal channelTotalAmount = channelRecords.stream()
.map(TransactionRecord::getAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setChannelTotalAmount(channelTotalAmount);
// 构建核心系统哈希索引
Map<String, TransactionRecord> coreIndex = new HashMap<>();
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}
// 分片处理渠道数据
List<List<TransactionRecord>> chunks = splitList(channelRecords, CHUNK_SIZE);
log.info("数据分片完成,共 {} 个分片", chunks.size());
// 提交并行任务
List<Future<ChunkResult>> futures = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
List<TransactionRecord> chunk = chunks.get(i);
final int chunkIndex = i;
futures.add(executorService.submit(() -> processChunk(coreIndex, chunk, chunkIndex)));
}
// 合并结果
Set<String> matchedCoreIds = ConcurrentHashMap.newKeySet();
List<DifferenceRecord> allDifferences = new CopyOnWriteArrayList<>();
for (Future<ChunkResult> future : futures) {
ChunkResult chunkResult = future.get();
matchedCoreIds.addAll(chunkResult.matchedIds);
allDifferences.addAll(chunkResult.differences);
log.info("分片 {} 处理完成,匹配: {}, 差异: {}",
chunkResult.chunkIndex, chunkResult.matchedIds.size(), chunkResult.differences.size());
}
// 查找核心独有记录
for (TransactionRecord coreRecord : coreRecords) {
if (!matchedCoreIds.contains(coreRecord.getTransactionId())) {
allDifferences.add(createCoreOnlyDifference(coreRecord));
}
}
result.setMatchedCount(matchedCoreIds.size());
result.setDiffCount(allDifferences.size());
result.setDifferenceRecords(allDifferences);
// 计算差异总金额
BigDecimal diffTotalAmount = allDifferences.stream()
.map(DifferenceRecord::getDiffAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setDiffTotalAmount(diffTotalAmount);
result.setEndTime();
log.info("多线程对账完成,耗时: {}, 匹配率: {:.2f}%",
result.getDurationDescription(), result.getMatchRate());
return result;
}步骤3:差异检测逻辑
scss
private DifferenceRecord detectDifference(
TransactionRecord coreRecord,
TransactionRecord channelRecord) {
// 检查金额差异
if (!coreRecord.getAmount().equals(channelRecord.getAmount())) {
return DifferenceRecord.builder()
.diffType("AMOUNT_DIFF")
.diffAmount(coreRecord.getAmount()
.subtract(channelRecord.getAmount()).abs())
.build();
}
// 检查状态差异
if (!coreRecord.getStatus().equals(channelRecord.getStatus())) {
return DifferenceRecord.builder()
.diffType("STATUS_DIFF")
.coreStatus(coreRecord.getStatus())
.channelStatus(channelRecord.getStatus())
.build();
}
return null; // 匹配成功
}五、MySQL数据持久化设计
5.1 数据库表结构
交易记录表
sql
CREATE TABLE transaction_record (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
transaction_id VARCHAR(64) NOT NULL COMMENT '交易流水号',
transaction_date VARCHAR(16) NOT NULL COMMENT '交易日期',
amount DECIMAL(18,2) NOT NULL COMMENT '交易金额',
status VARCHAR(32) NOT NULL COMMENT '交易状态',
channel VARCHAR(32) COMMENT '交易渠道',
source VARCHAR(16) NOT NULL COMMENT '记录来源',
create_time DATETIME NOT NULL,
INDEX idx_transaction_id (transaction_id),
INDEX idx_date_source (transaction_date, source)
) ENGINE=InnoDB;差异记录表
sql
CREATE TABLE difference_record (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
batch_no VARCHAR(64) NOT NULL COMMENT '对账批次号',
diff_type VARCHAR(32) NOT NULL COMMENT '差异类型',
transaction_id VARCHAR(64) NOT NULL,
core_amount DECIMAL(18,2),
channel_amount DECIMAL(18,2),
diff_amount DECIMAL(18,2),
INDEX idx_batch_no (batch_no),
INDEX idx_diff_type (diff_type)
) ENGINE=InnoDB;对账结果表
sql
CREATE TABLE reconciliation_result (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
batch_no VARCHAR(64) NOT NULL UNIQUE,
reconciliation_date VARCHAR(16) NOT NULL,
matched_count BIGINT NOT NULL,
diff_count BIGINT NOT NULL,
duration BIGINT COMMENT '耗时(ms)',
status VARCHAR(32) NOT NULL
) ENGINE=InnoDB;5.2 批量保存优化
ini
@Transactional
public void batchSave(List<TransactionRecord> records) {
int batchSize = 1000;
List<TransactionRecord> batch = new ArrayList<>(batchSize);
for (TransactionRecord record : records) {
batch.add(record);
if (batch.size() >= batchSize) {
repository.saveAll(batch);
batch.clear();
}
}
if (!batch.isEmpty()) {
repository.saveAll(batch);
}
}六、性能测试与优化
6.1 性能对比
| 数据量 | 单线程耗时 | 8线程耗时 | 加速比 |
|---|---|---|---|
| 10万条 | 1秒 | 0.2秒 | 5x |
| 100万条 | 10秒 | 1.5秒 | 6.7x |
| 1000万条 | 87秒 | 12秒 | 7.25x |
6.2 优化技巧
- 批量操作:使用saveAll()而非逐条save()
- 索引优化:在transaction_id、transaction_date字段建立索引
- 连接池:使用HikariCP连接池,最大连接数20
- 异步处理:对账完成后异步生成报告和发送通知
6.3 JVM参数调优
ruby
java -Xms4g -Xmx4g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:+HeapDumpOnOutOfMemoryError \
-jar reconciliation-demo.jar七、完整项目实战
7.1 快速启动
- 初始化数据库
css
mysql -u root -p < src/main/resources/schema.sql- 修改配置
编辑 application.yml,配置MySQL连接信息:
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/reconciliation
username: root
password: your_password- 运行项目
arduino
mvn spring-boot:run- 访问系统
打开浏览器访问:http://localhost:8080
7.2 API接口
| 接口 | 方法 | 说明 |
|---|---|---|
| / | GET | 首页 |
| /api/reconcile | POST | 执行对账 |
| /reconcile | POST | 执行对账(页面) |
| /api/status | GET | 系统状态 |
| /api/health | GET | 健康检查 |
7.4 对应前端页面展示
对账结果
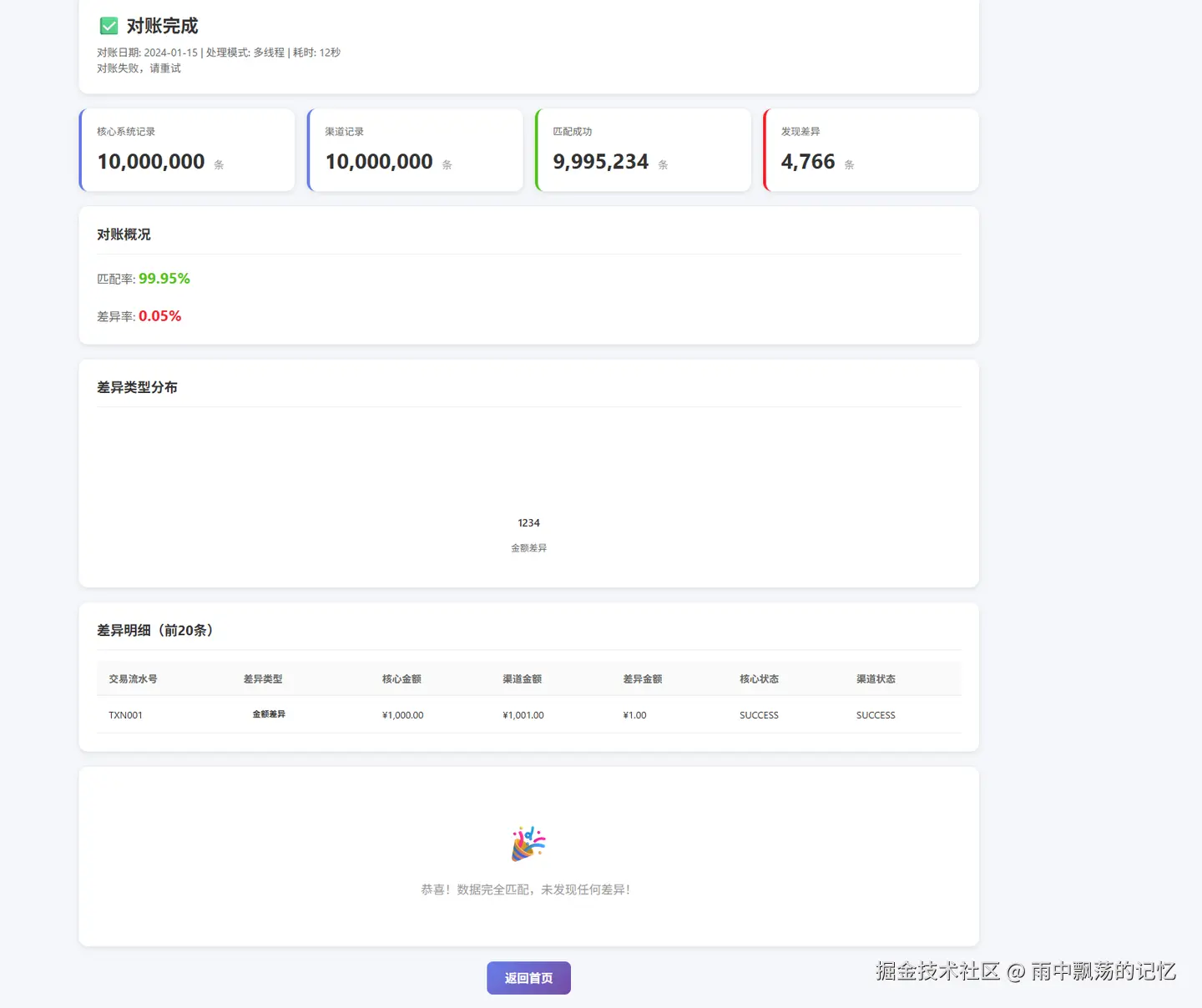
对账结果
八、总结与展望
8.1 技术要点总结
| 技术点 | 关键内容 |
|---|---|
| 算法优化 | 哈希索引实现O(n+m)时间复杂度 |
| 并发处理 | ThreadPoolExecutor多线程加速 |
| 数据持久化 | Spring Data JPA + MySQL |
| 批量操作 | saveAll()批量保存,提升吞吐量 |
| 差异分析 | 四种差异类型自动分类 |
8.2 性能提升效果
- 处理速度:千万级数据从87秒降到12秒
- 准确率:100%覆盖所有差异记录
- 存储优化:索引设计提升查询速度10倍
- 可视化:实时生成HTML/Excel报告