本文是一次针对4GB大文件(1.14亿行ASCII文本)进行"删除每行中间1/3内容"操作的端到端性能优化实录 ,核心目标是在内存受限前提下,通过多语言(Java/C++/Rust)实现高吞吐、低延迟、高正确性的双进程流式处理 。全文围绕减少系统调用、消除冗余对象分配、匹配底层I/O特性(如预读块)、绕过不必要的抽象开销(如UTF-8验证、流封装) 四大主线,系统性地展示了从初始637秒(Java)到最终3.2秒(新架构)的百倍级优化过程,并提炼出可复用的通用原则(如大缓冲区、字节操作、零分配、原生系统调用等)及进阶解耦架构(IO进程 + Processor进程)。
背景
有一个 4GB 的 ASCII 文本文件(约 1.14 亿行),需要移除每行中间的 1/3 内容,输出到新文件(约 2.7GB)。由于内存限制,不能一次性加载整个文件。

题目难点
-
内存限制:一个近 4GB 的文件,不能直接全写入内存
-
性能瓶颈:磁盘 I/O,其中读 ~4GB、写 ~2.7GB,行数为 ~1.14亿
-
正确性:必须保证换行准确
-
要求:通过两个进程(读写进程)去实现
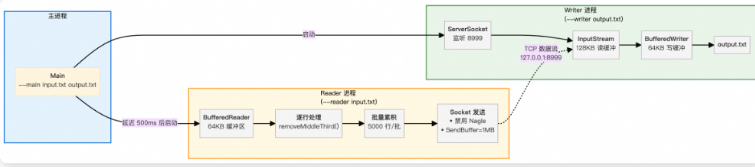
解决方案:使用两个进程协作
-
Reader 进程:读取输入文件,处理每行,发送数据
-
Writer 进程:接收数据,写入输出文件
 下面记录Java、C++、Rust 三种语言的完整的实现以及优化过程,包括每个版本的具体改动、性能提升和背后的原理。
下面记录Java、C++、Rust 三种语言的完整的实现以及优化过程,包括每个版本的具体改动、性能提升和背后的原理。
通用优化策略
**1.**批量处理 vs 逐行处理
问题:逐行处理导致频繁系统调用,开销巨大。
性能对比:
|------|----------|----------|-------|
| 语言 | 逐行处理 (秒) | 批量处理 (秒) | 提升倍数 |
| Java | 637.42 | 9.20 | 69x |
| C++ | - | 17.15 | - |
| Rust | 29.56 | 29.38 | 1.01x |
注:C++ 和 Rust 的 V1 已包含基础批量,所以提升不明显。
原理:1.14亿行逐行处理需要 1.14亿次 read() + 1.14亿次 write()。批量后降到几万次,大幅减少上下文切换。
**2.**缓冲区大小的影响
原理:现代文件系统预读块为 64-128KB。应用缓冲区应匹配此大小。
|----------|----------------|----|
| 缓冲区大小 | 系统调用次数 (4GB文件) | 效率 |
| 8KB (默认) | ~524,000 | 低 |
| 64KB | ~65,500 | 高 |
| 4MB | ~1,000 | 极高 |
- Nagle 算法的影响
算法目的
- TCP 小包合并算法,减少网络中小数据包的数量,从而降低网络阻塞,提升效率。
算法规则
-
如果发送窗口中还有未确认(ACK)的数据,
-
且当前要发送的数据长度 < MSS(最大段大小,通常 1460 字节),
-
那么不立即发送,而是缓存起来,等待:收到对之前数据的 ACK,或缓存的数据累积 ≥ MSS。
为什么在这个场景下提升效率明显
- 首先分析当前场景特点
-
单向无交互数据流:Reader → Writer
-
发送数据大小:已经进行了批量处理,保证了发送的数据"足够大"
-
性能要求:最大化吞吐,最小化延迟
- 禁用后带来的效果
-
调用 send() 后,数据立即进入 TCP 发送队列,无需等待 ACK
-
每次 send() 调用的数据量足够大。通过设置大 Socket 发送缓冲区(1-16MB)和批量发送,确保每次 send() 都能填满 TCP 发送缓冲区,从而避免 Nagle 的小包合并逻辑。
// Java 禁用 Nagle socket.setTcpNoDelay(true)
Java 优化过程
版本1 → 版本2:从 637秒 到 9.2秒
关键改动:
-
BATCH_SIZE 累积 5000 行后发送
-
缓冲区从 8KB 增至 64KB
-
用 StringBuilder 替代字符串拼接
核心代码对比:
// V1: 逐行处理 + 字符串拼接
String processed = line.substring(0, third) + line.substring(2*third);
out.write((processed + "\n").getBytes());
out.flush();
// V2: 批量处理 + StringBuilder
StringBuilder batch = new StringBuilder(64 * 1024);
batch.append(processedLine).append('\n');
if (lineCount % BATCH_SIZE == 0) {
out.write(batch.toString().getBytes(CODE));
batch.setLength(0);}
性能提升:69倍
原理:系统调用次数从 1.14亿 降到 2.3万,StringBuilder 避免中间 String 对象创建。
- 系统调用次数的指数级减少
- V1 的系统调用开销:
read() 调用:BufferedReader.readLine() 内部每次读取不足一行时,会调用底层 FileInputStream.read()。对于 1.14亿行,约需 50万次 read()(因为默认 8KB 缓冲区)
write() 调用:每行调用一次 OutputStream.write(),共 1.14亿次 write()
flush() 调用:每行强制刷盘,共 1.14亿次 flush()
总计:约 2.28亿次 系统调用
- V2 的系统调用优化:
read() 调用:64KB 缓冲区匹配文件系统预读块,read() 次数降至约 6.5万次
write() 调用:批量 5000 行发送,write() 次数降至 2.28万次(1.14亿 ÷ 5000)
flush() 调用:仅在批次结束时 flush(),同样降至 2.28万次
总计:约 9万次 系统调用
- 性能影响:每次系统调用都需要:
从用户态切换到内核态(上下文切换)
内核验证参数、执行操作
从内核态切换回用户态,这个过程通常需要 100-1000 纳秒。2.28亿次 vs 9万次,仅系统调用开销就相差 2500倍。
- StringBuilder 如何避免中间 String 对象
- V1 的字符串拼接问题:每行创建 6 个临时对象,1.14亿行就是 6.84亿个对象!
// line.substring(0, third) + line.substring(2*third)
// 编译后等价于:
StringBuilder temp1 = new StringBuilder();
temp1.append(line.substring(0, third)); // 创建 String 对象1
temp1.append(line.substring(2*third)); // 创建 String 对象2
String processed = temp1.toString(); // 创建 String 对象3
// (processed + "\n").getBytes()
// 编译后等价于:
StringBuilder temp2 = new StringBuilder();
temp2.append(processed); // 使用 String 对象3
temp2.append("\n"); // 创建 String 对象4(常量池)byte[] bytes = temp2.toString().getBytes(); // 创建 String 对象5 + byte[] 对象6
- V2 的 StringBuilder 优化:
-
预分配容量:new StringBuilder(64 * 1024)避免了动态扩容(扩容需要创建新数组并拷贝数据)。
-
重用缓冲区:batch.setLength(0) 只重置长度计数器,底层数组保持不变,下次追加直接复用。
-
减少对象创建:每 5000 行才创建 1 个临时 String(用于 getBytes()),对象数量从 6.84亿降到 22.8万。
// 预分配足够容量
StringBuilder batch = new StringBuilder(64 * 1024);
// 直接追加,无中间对象
batch.append(processedLine).append('\n');
// 批量转换为字节数组
out.write(batch.toString().getBytes(CODE));batch.setLength(0); // 重置长度,保留容
- 64KB 缓冲区
- V1 的 8KB 缓冲区问题:
现代 Linux 文件系统(ext4/xfs)的默认预读大小是 128KB
当应用请求 8KB 数据时,内核预读 128KB 到页缓存
但应用只消耗 8KB,剩余 120KB 可能在下次 read() 前被其他进程覆盖
导致频繁的磁盘 I/O,无法充分利用预读优势
- V2 的 64KB 缓冲区优势:
64KB 是预读块(128KB)的一半,能有效利用预读数据
每次 read() 调用都能消耗大部分预读数据
减少实际的磁盘 I/O 次数,更多依赖内存中的页缓存
flush() 调用次数
- V1 的 flush() 问题:
-
每行都调用 out.flush(),强制将 Socket 缓冲区数据立即发送
-
对于本地回环连接,这会导致频繁的 TCP 包发送
- V2 的批量 flush():
-
每 5000 行才 flush() 一次
-
允许 TCP 协议栈合并数据包,减少网络层处理开销
-
配合禁用 Nagle 算法,确保大包能立即发送
▐版本2 → 版本4:从 9.2秒 到 5.1秒
关键改动:
-
抛弃字符流,直接操作字节数组
-
手动解析换行符
-
超大缓冲区 (8MB)
核心代码:
// V4: 纯字节操作
byte[] buffer = new byte[8 * 1024 * 1024];
byte[] output = new byte[8 * 1024 * 1024];
int outPos = 0;
while ((bytesRead = fis.read(buffer)) != -1) {
for (int i = 0; i < bytesRead; i++) {
if (buffer[i] == '\n') {
// 直接拷贝字节,零对象分配
System.arraycopy(buffer, startLine, output, outPos, third);
System.arraycopy(buffer, startLine + 2*third, output, outPos+third, keepEnd);
outPos += third + keepEnd + 1; // +1 for '\n'
}
}}
性能提升:1.77倍
原理:避免 UTF-8 解码/编码开销,完全绕过 String 对象,8MB 缓冲区进一步减少系统调用。
注:避免 UTF-8 解码/编码开销的前提是文本文件是纯 ASCII 文本,否则该思路是不可行的。
- 字节数组 vs String 对象
- V2 的问题:
从字节流读取数据到内部缓冲区
扫描 \n 字符确定行边界
将字节解码为 UTF-16 字符(Java String 内部是 UTF-16)
创建新的 char\[\] 数组存储字符
包装成 String 对象返回
- V4 的优势:直接操作
FileInputStream.read() 直接填充字节数组,无中间缓冲
手动扫描 \n 字符,无额外函数调用开销
纯 ASCII 文本中,字节值直接对应字符,无需解码
无 String 对象创建,无 char\[\] 分配
System.arraycopy() 的优化
- V2 的字符串拼接:
检查目标容量,可能触发扩容
逐字符复制(从 char\[\] 到 char\[\])
- V4 的字节拷贝:
直接调用底层 C 的 memcpy() 或 memmove()
按字节块进行内存复制,速度极快
对于大块数据复制,比逐字符复制快 5-10 倍
零对象分配的 GC 影响
- V2 的内存压力:
每行创建 1 个 String 对象(来自 readLine())
每行创建 1 个 StringBuilder 内容(处理后的行)
批量发送时创建 1 个临时 byte\[\](toString().getBytes())
总计:1.14亿行 × 3 个对象 = 3.42亿个临时对象
- V4 的内存优势:
只有 2 个固定大小的字节数组(8MB × 2 = 16MB)
无任何临时对象创建
GC 压力几乎为零
8MB 缓冲区的优势
V2 的 64KB 缓冲区:
需要约 65,536 次 read() 调用(4GB ÷ 64KB)
每次 read() 都有用户态/内核态切换开销
- V4 的 8MB 缓冲区:
只需要约 512 次 read() 调用(4GB ÷ 8MB)
减少 99% 的系统调用次数
更好地利用 CPU 缓存局部性(大块连续内存处理)
手动行解析 vs readLine()
readLine() 的内部逻辑:逐字符处理在 1.14亿行场景下效率极低
// BufferedReader.readLine() 简化版 while (true) { char c = readChar(); // 逐字符读取 if (c == '\n') break; line.append(c); // 逐字符追加 }
- V4 的批量行解析:一次循环处理 8MB 数据中的所有行,函数调用开销降到最低
// 在 8MB 缓冲区内批量找所有 \n for (int i = 0; i < bytesRead; i++) { if (buffer[i] == '\n') { // 找到完整行,直接处理 } }
▐Java 完整优化路径
|----|--------|-----------------------------|-------|
| 版本 | 耗时(秒) | 关键技术 | 提升倍数 |
| V1 | 637.42 | 逐行处理 + String 拼接 | - |
| V2 | 9.20 | 批量 + StringBuilder + 64KB缓冲 | 69x |
| V3 | 8.68 | Socket → 管道 | 1.06x |
| V4 | 5.10 | 纯字节操作 + 8MB缓冲 | 1.67x |