吴恩达机器学习
前言
- 课程已经学了将近一半才想起来记笔记 学的时候总以为自己能记得住 就光想着偷懒 但是事实说明 不手动敲一下实时的学习体会是不行的 事实上我已经忘了上个星期学了啥... 这个月争取补上(尽量 话不能说太满...)
- 题外话:
今天刚刚看了马斯克最新的一期访谈 就聊到了 AI AGI 机器人的一些发展 加上最近几天 千问 元宝大模型的突然爆火 这才刚刚开年 像阿里 字节这些大厂就豪掷这么多亿 摆明了让我们薅这个羊毛 那为啥呢 资本也不傻呀对吧 具体原因咱小老百姓也不晓得 不过每天薅一杯奶茶还是舒服的- 说来也巧 我前段时间看了对于目前国内大厂财报的分析 目前国内的局势总体来说就是四大金刚+五小龙 在过去的一年 豆包毫无疑问是国内的TOP1 给字节带来的受益也是非常可观的 我想大部分人现在有问题都不会去搜百度而是选择豆包 这也是目前百度在5小龙垫底的原因之一把 好了就说到这吧 其余大家感兴趣也可以搜来看看 兴许可以拿来吹吹牛X?
其实 我觉得这门课学起来 还是相当有趣 我时不时就回想起一句话 在现在这个时代即便你不学计算机 仍然需要去了解 机器学习及其相关的知识 因为可能十年之后AI真的是会重塑各行各业 就拿最近写的一些行测题目举例子 也都会出现AI和当前生产生活的一些跨界融合作为题干
特征缩放
- 对于特征缩放这个概念我们引入一个老生常谈的模型 对于给定的一些特征对房产进行估值 这里跟前面不同的是 这里的重点不在于估值而是在于参数的合适选取
- 其实下面这张图想要告诉我们的事情很简单 对于一个范围比较大的变量 x1 这里指代的是房屋面积 我们规定它的取值范围是300-2000
- 如果这里我直接告诉你 x1前面的系数w1 选取必须要谨慎 这是不太好的 因为凡事往往都有一个对比 那么这个时候我们聚焦于x2它指代的是卧室的数量 我们将它的范围限定为0-5 那么如果他前面的系数w2 突然增大10 对于整体的价格 也仅仅最多变动50
- 而w1就不一样了 假如此时的房子是2000平米的 w1每每变动 对于价格的影响都是2000正负 这对于x2 它的影响就相当大了

-
因此 往往一个优秀的模型对于这种范围比较大的 参数 它前面的系数会选取的格外谨慎
-
下面 上部分的两张图就是我们 特征 到 成本函数的等高线图 不难发现的是 对于范围较大的x1前的参数w1 它只要变化一点 对于整体的影响就非常大 这也符合我们前面的分析 从图像上来看是一个椭圆
-
这其实非常像概率论中的二维随机变量的图 不知道有没有联系...
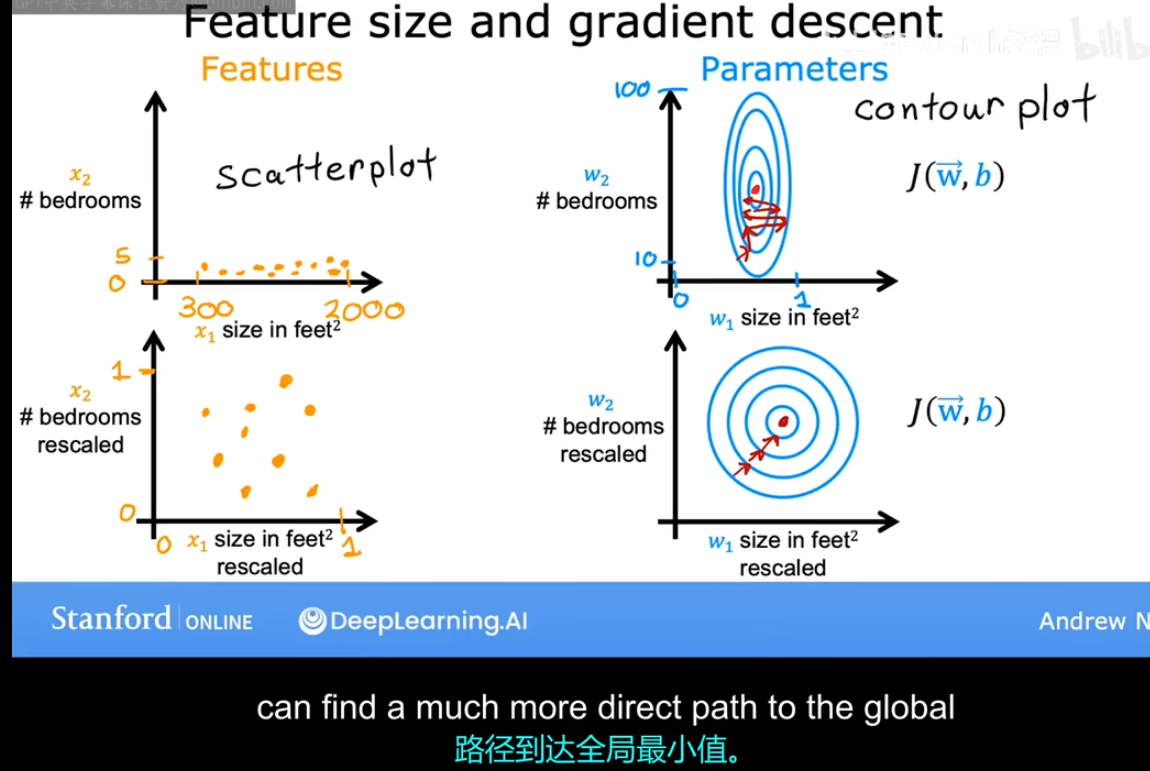 - 下部分的两张图是对特征进行变换之后 使得 我们的曲线图趋向于一个圆 这是下面要介绍的内容 也就是本小节的重点------特征缩放
- 下部分的两张图是对特征进行变换之后 使得 我们的曲线图趋向于一个圆 这是下面要介绍的内容 也就是本小节的重点------特征缩放 -
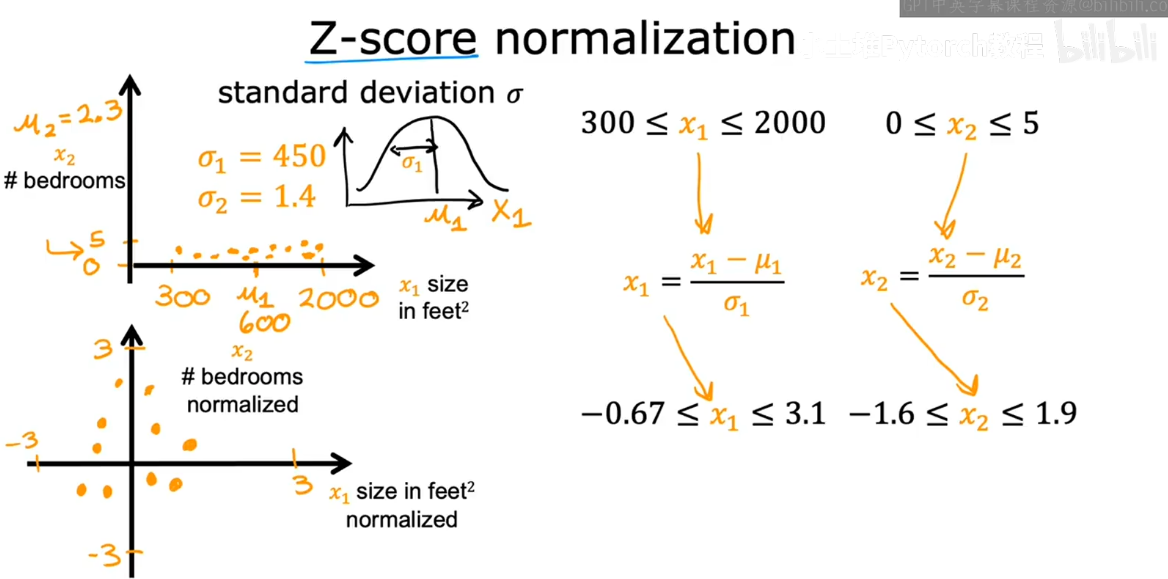
基于平均值的归一化

-
基于正态分布的归一化 那么学过正态分布的朋友肯定知道 要想进行下面的这种标准化 那么就必须计算出均值u以及标准差σ对吧 然后这个新的变量就服从标准正态分布 相应的 对于这两个新变量的范围就成功被我们规格化了
-
进行合适的特征缩放往往是可以加快梯度下降的速度的

梯度下降是否收敛
- 梯度下降的目的是找到参数 w 和 b 使得能够最小化 代价函数 j
- 下面的这张曲线图就展示了 梯度下降运行良好时 随着我们参数更新迭代的次数越来越多 代价函数就逐渐趋于一个稳定值了 这个时候我们就可以说 此时梯度下降是收敛的 这条曲线我们称之为学习曲线
- 当然还有一种是依赖于自动收敛测试 大概的思路就是设置一个阈值 比如说此时代价函数的变化已经小于这个阈值 我们就可以说 此时收敛了

学习率的选取
结语
上个月浪费不少时间在纠结是否能进复试上 一方面确实今年发挥真的一般 小池子不知道会不会爆炸 -另一方面有时候很难一直保持理性对待一些 啥软引流贴 明明知道自己已经花了大功夫搜集资料 理性分析过了 心里大概有数了 但还是有些难绷 在做相关事情的时候难免被影响心态~- 2月份 3个小目标 :
- 1 python过一遍基础(以前听老师说过python是比较好入门的 加上有C基础也了解过一些 应该学起来不难 )
- 2 机器学习+深度学习 前部分章节争取学完
- 3 省考试一试 平时没事写一写题 记得第一次做行测就蒙了60多 希望真考试也有好运气 万一以后想考公也已经知道怎么学了~
- 平时别吓自己 少看社交平台引流帖 等月底成绩出来 如果意料之中 就抓紧准备后续就行
