一、什么是索引
在没有索引的情况下,为什么查询的速度会比较慢呢??
因为数据都是存储在磁盘上的,那么再执行sql语句的时候,一定会去磁盘上读取相关的数据,那就会产生磁盘IO。如果没有索引,那么会进行多次磁盘的IO操作,比较耗费时间。
为什么要使用索引?
其目的就是为了减少磁盘的IO操作,这样就可以提高查询数据的速度。
索引本质是什么?
索引的本质就是一种数据结构。也就是说你创建了一个索引,其实mysql的数据库会帮你创建一个数据结构,然后使用该数据结构来存储数据到本地磁盘,该数据结构就是索引。
二、索引的底层原理
1.二叉查找树
特点:它的左子节点的值比父节点的值要小,右节点的值要比父节点的大。
二叉树的优点:可以优化磁盘IO的次数。节点存在有顺序,可以进行范围的查询。
二叉树的缺点:插入数据的速度会比较慢,因为会更改数据结构。不平衡的问题,会产生倾斜的二叉树。如果是递增数据插入,就会出现只有一个子树的二叉树,那就和全表查询一样了。
2.平衡查找二叉树
缺点:插入数据会平衡,但是插入的时候会改变树的结构。插入的数据的时候比较慢。而且一个节点放一个数据,数据越多,树的层级会变高,会增加磁盘IO的次数。
优点 :二叉树是有顺序的,范围查找都是支持的。
3.B树和B+树
一个节点可以存储多个数据,相对于完全平衡二叉树的高度肯定会低,那么就会降低磁盘IO的次数。
两者的区别:
1.B树的非叶子节点存储完整数据,B+树的非叶子节点是只存储索引的,相比于B树可以存储更多的索引,层数更低,IO次数更少,性能很好
2.B+树的叶子结点有双向指针,有利于顺序查找,只要在叶子节点顺序向后遍历即可。
三、索引是怎么存储数据的
mysql中Innodb和myisam存储引擎默认都是使用B+树数据结构做索引的,存储的数据结构如下:
Innodb聚簇索引,叶子结点存储索引和数据,这里的数据指的是表里面的一行记录:
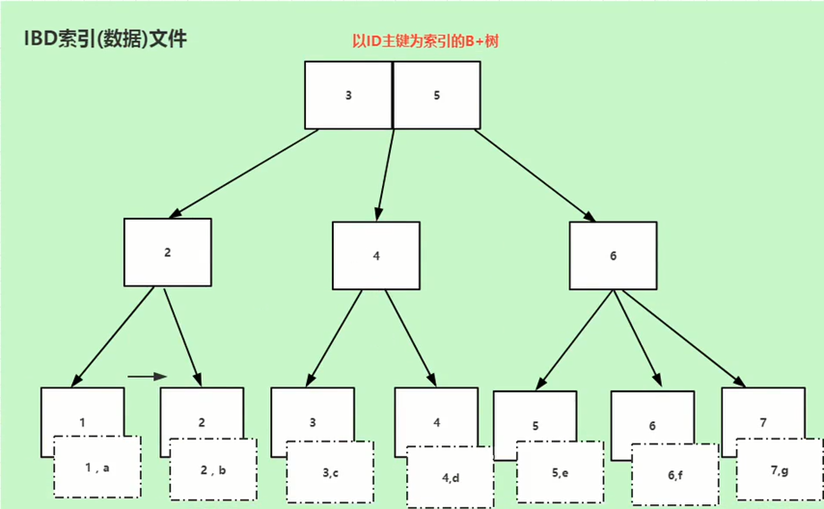
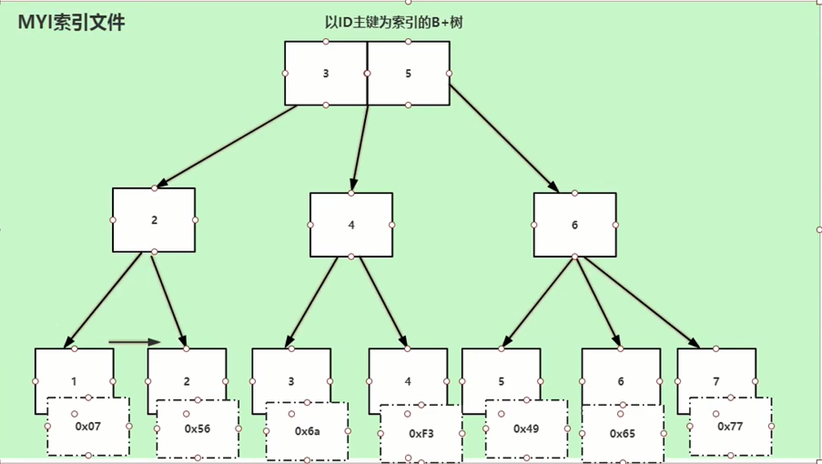
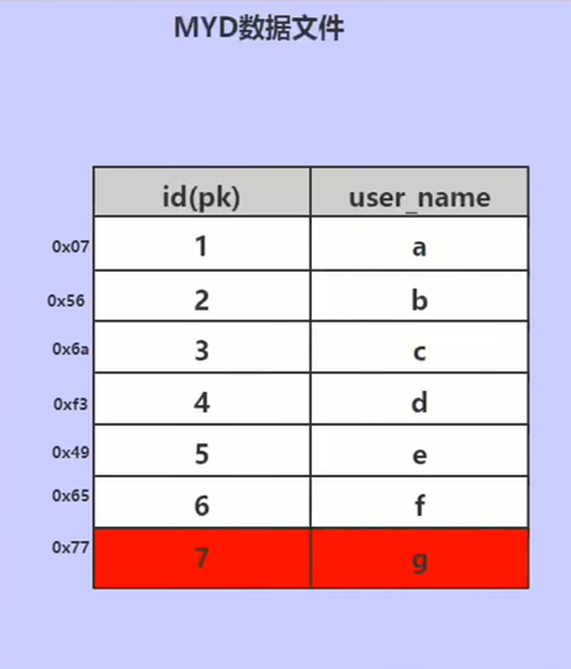
myisam非聚簇索引,叶子结点只存储索引和磁盘地址,还需要根据地址进一步找到具体的数据:
索引文件:
数据文件:
四、索引实战
1.聚集索引
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id 作为聚集索引;每次查询只能从根节点开始遍历,去查找符合where条件的数据
2.散列度
问题:为什么有的字段建立索引,查询速度反而变慢了呢?
现在有一列字段,假如列的名称是 sex性别,存储的值是 男或者女,表中有500w条数据,现在执行sql:select * from t_user where sex = '男' 查询花费的时间2秒多,现在对sex 列建立了索引,再执行之前的sql语句,但是花费的时间变成了 20多秒,建立索引后没有变快,反而变慢了,这是为啥呢???
当数据有很多相同时,就需要加载很多节点,还要回表去找真实的数据,速度很慢
3.联合索引
联合索引,最左匹配原则。先按照第一个索引查询,第一个索引相同,才会按照第二个索引查找。
必须从联合索引的第一个字段开始,不能跳过,不能中断。
两个字段一般是同时出现的,推荐建立联合索引,例如高考成绩查询:身份证号+考号,如果两个字段没有关系,不建议建立联合索引。
4.回表和覆盖索引
回表的概念:通过二级索引(辅助索引)树查询索引数据,然后再通过聚集索引树查询完整数据的过程称为回表。
覆盖索引的概念:select字段已经包含在用到的索引中的时候称为覆盖索引。覆盖索引,查找的索引树就有想要的数据,不需要回表。
5.索引使用总结
5.1在什么字段上创建索引
- where、join、 order by 、group by去建立索引。
- 索引个数不要过度。
- 散列度低的字段,不要建立索引。
- 随机无序或频繁更新的值,不适合作为主键,推荐使用递增的ID作为主键索引:因为如果你是递增的话,在叶子结点上放数据直接按顺序往后面放就行,但是如果你是无序的就可能会出现数据页的分裂和合并
- 使用整型:是因为,整型比较大小要比字符串快
- 创建联合索引避免冗余索引
5.2索引失效总结
1.索引列上使用函数、表达式、运算符。
2.出现类型隐式转换,例如:字符串忘记编写引号。
EXPLAIN select * from t_user where name = 122
3.like条件字符前面带% (最左前缀)(不一定)
负向查询<> != NOT IN (不一定)