2026.2.8 周报
文献阅读
题目信息
题目:《Quantum Long Short-Term Memory》
期刊: IEEE
作者: Samuel Yen-Chi Chen, Shinjae Yoo, and Yao-Lung L. Fang
发表时间: 2020
文章链接: https://arxiv.org/pdf/2009.01783
摘要
本文提出了一种混合量子-经典模型 QLSTM,通过使用变分量子电路替换经典LSTM单元中的神经网络层,成功将架构扩展到了量子领域。实验表明,在参数数量相似的情况下,QLSTM在学习多种时间序列数据时,比经典模型收敛速度更快,所需的训练轮次更少,且收敛过程更加稳定。由于采用变分方法,该模型对量子比特数和电路深度的要求较低,非常适合在当前的含噪中等规模量子设备上实现。
创新点
作者首创将变分量子电路引入 LSTM 架构,替代了经典单元中遗忘门、输入门、更新层和输出门里的线性变换层,从而利用量子纠缠特性增强模型的表达能力。在数据处理上,作者提出了一种基于反正切函数的量子编码方案。这种设计不仅能适应任意实数域输入,还通过引入平方项 x 2 x^2 x2 增加了高阶非线性特征。此外,作者还Parameter-shift 规则实现了混合架构下的解析梯度计算,使得量子电路可以像经典神经网络一样通过反向传播算法进行高效训练。从实验效果来看,QLSTM 展现出了显著的收敛性与稳定性优势。即便在参数量相当甚至更少的情况下,模型在训练初期就能提取到更多有效信息,且损失函数下降曲线平滑,没有出现经典 LSTM 常见的尖峰波动。
网络框架
模型的核心在于用变分量子电路 VQC 替换了原有的矩阵乘法操作。
变分量子电路模块
VQC 是模型的基本构建块,由三个部分串联而成:
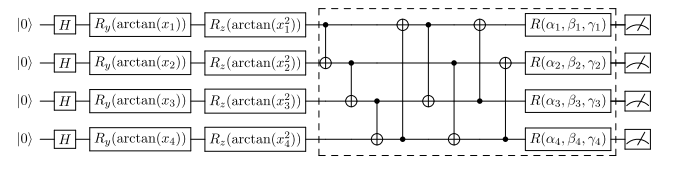
- 数据编码层,将经典输入向量 v ⃗ \vec{v} v 编码为量子态。使用 H 门制备叠加态后,通过旋转门 R y R_y Ry 和 R z R_z Rz 进行编码,角度由输入数据及其平方值的反正切函数决定。
- 变分层,由一系列用于产生纠缠的 CNOT 门和单量子比特旋转门组成,其中的旋转角度即为网络的可训练参数。
- 量子测量层,通过测量量子比特在计算基下的期望值,将量子态转换回经典标量,供后续的非线性激活函数使用。
QLSTM 单元架构
QLSTM 单元通过堆叠多个 VQC 构建而成。如下图所示,黄框部分为单元主体,蓝色小块即为上述的 VQC 模块。
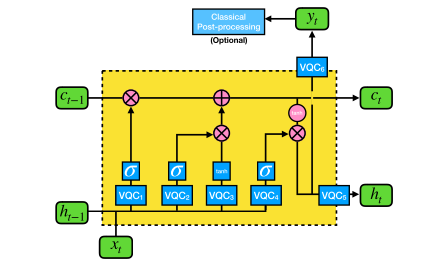
输入向量 v t v_t vt 由上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1 和当前输入 x t x_t xt 拼接而成。
单元内部的流程如下:
- 遗忘门 f t f_t ft 通过 V Q C 1 VQC_1 VQC1 处理,决定保留多少旧的细胞状态 c t − 1 c_{t-1} ct−1;
- 输入门 i t i_t it 通过 V Q C 2 VQC_2 VQC2 处理,决定更新哪些新信息;3
- 候选态 C ~ t \tilde{C}_t C~t 由 V Q C 3 VQC_3 VQC3 生成新的候选记忆;
- 细胞状态 c t c_t ct 结合遗忘门和输入门的结果进行更新;
- 输出门 o t o_t ot 由 V Q C 4 VQC_4 VQC4 控制;
最终输出 为了匹配维度,作者额外增加了 V Q C 5 VQC_5 VQC5 和 V Q C 6 VQC_6 VQC6 分别生成隐藏状态 h t h_t ht 和最终输出 y t y_t yt。
实验结果
作者构建了参数量相近的经典 LSTM与 QLSTM进行对比。
正弦函数的学习表现
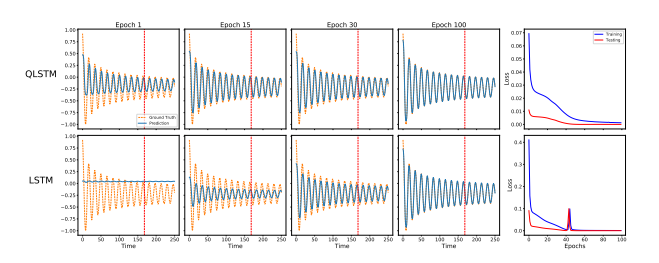
在学习正弦函数 y = sin ( x ) y=\sin(x) y=sin(x) 的任务中,QLSTM 在第1个 Epoch 就展现了极佳的拟合效果,学到的信息显著多于经典模型。到第15个 Epoch 时,其训练 Loss 明显更低,且收敛曲线非常平滑,没有出现经典模型中常见的震荡。
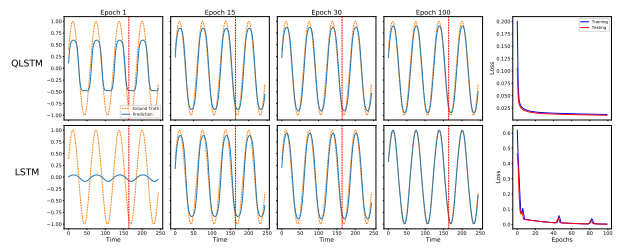
预测阻尼谐振子角速度
在预测阻尼谐振子角速度的任务中,QLSTM 不仅收敛更快,而且在极值点处的拟合更加温和精准,避免了经典 LSTM 容易出现的过冲现象。
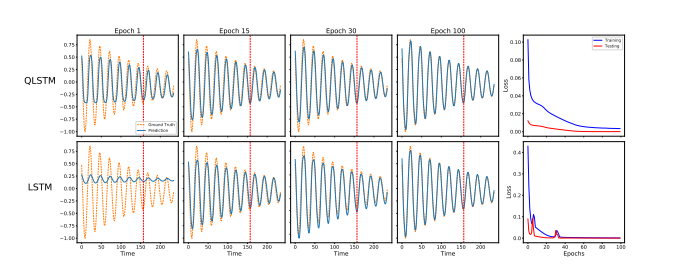
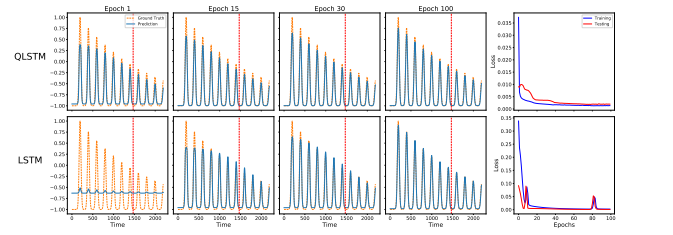
复杂函数的预测
针对非指数衰减的复杂函数 J 2 ( x ) J_2(x) J2(x),经典 LSTM 在训练初期几乎失效,预测结果呈平直线;而 QLSTM 迅速捕捉到了复杂的震荡模式,展现了强大的非线性学习能力。
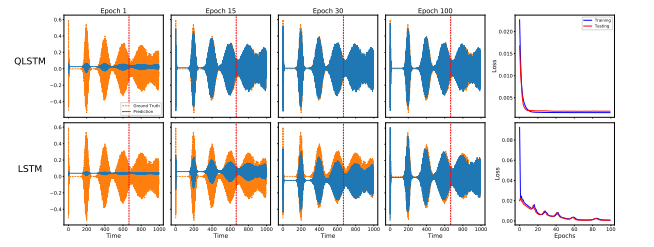
预测延迟量子控制和种群反转任务
在这个任务中,QLSTM 同样表现出色。特别是在种群反转任务中,当系统处于基态激发态平衡( D = 0 D=0 D=0)时,经典 LSTM 难以学习到零偏置特征,产生了较大误差,而 QLSTM 则能准确预测这一物理现象。
结论
本文证明了 QLSTM 在处理时间序列数据上具有比经典 LSTM 更高的数据效率和稳定性 。在同等参数规模下,它不仅收敛更快,而且能够更敏锐地捕捉数据的局部特征,尤其是在复杂的非线性动力学系统中表现优异。
不足与展望
作者首先提出了这个模型的算力瓶颈,由于采用 Parameter-shift 方法计算梯度,每次更新需要大量的量子电路评估,导致在经典计算机上模拟训练极其耗时,难以扩展到大规模数据集。其次当前的实验均在无噪声的模拟环境下进行,未充分考虑真实量子硬件中的退相干和读取误差对记忆单元的影响。编码方式相对固定,使用了固定的旋转门编码,未来可以探索振幅编码等更节省资源的方案。后续研究可以尝试针对特定任务优化量子电路结构。
实验
本周对上周的量子网络的实验进行了进一步的优化,目的是深入研究量子在经典的深度学习网络架构在时间序列预测任务中的应用到底提供了什么贡献。
上周实现的iQTransformer模型将量子自注意力机制集成到iTransformer框架中,目的是为了利用量子纠缠和干涉特性捕获变量间的复杂依赖关系,但是上周由于没能调好参数和数据集较少,模型复杂的原因,导致实验的结果有所偏差,所以这周尝试调参并改进。
量子自注意力层核心代码结构:
python
# 量子注意力电路
def quantum_attention_circuit(inputs, weights):
n_qubits = len(inputs)
n_layers = weights.shape[0]
# 特征编码层
for i in range(n_qubits):
qml.RY(inputs[i], wires=i)
# 变分层(纠缠和旋转)
for l in range(n_layers):
for i in range(n_qubits - 1):
qml.CNOT(wires=[i, i + 1])
for i in range(n_qubits):
qml.Rot(*weights[l, i], wires=i)
# 测量层
return [qml.expval(qml.PauliZ(wires=i)) for i in range(n_qubits)]首先,对原来的旧配置增加了量子特化损失函数和增加了更多的qbit,更强表达能力、获取更丰富信息,让其更高效训练。新旧配置如下:
python
# 旧配置
n_qubits: 4
n_q_layers: 3
n_qsann_blocks: 2
learning_rate: 5e-4
batch_size: 32
# 新配置
n_qubits: 10 # 更多量子比特
n_q_layers: 5
n_qsann_blocks: 1
learning_rate: 1e-4
batch_size: 128
use_quantum_loss: True # 新增量子损失因为考虑到模型的复杂度,后面我将数据集换成了分钟级别的分辨率,让模型能有更多的输入。
实验结果
改进后的。量子损失与经典iTransformer性能相当,量子损失提供额外梯度信号,收敛更平稳,证明量子损失的有效帮助模型在量子态空间保持良好的分布特性。
| 型版本 | 验证集 MAE | 验证集 RMSE | 训练轮数 | 最终 Val Loss |
|---|---|---|---|---|
| iTransformer Baseline | 0.572 | 0.747 | 100 | 0.555 |
| iQTransformer Original | 0.58 | 0.75 | 100 | 0.56 |
| iQTransformer 改进 | 0.556 | 0.741 | 100 | 0.555 |
实验存在的问题
量子电路中还是存在梯度消失现象,影响训练效果。此外,量子计算成本高,限制了大规模参数搜索,可能就是由于这个原因,导致模型的性能其实并不比原来的好多说。
实验发现复杂的量子核函数导致收敛速度慢于经典点积注意力,后续需要优化量子电路设计,减少梯度消失。
量子计算学习笔记
相位估计问题的引入
在量子计算中,我们经常需要处理酉算子 的特征值和特征向量问题。对于一个给定的酉算子 U U U,其特征值可以表示为 e 2 π i φ e^{2\pi i \varphi} e2πiφ 的形式,其中 φ ∈ [ 0 , 1 ) \varphi \in [0,1) φ∈[0,1) 是相位。
假如给定酉算子 U U U 和其特征向量 ∣ u ⟩ |u\rangle ∣u⟩,如何高效地估计相位 φ \varphi φ
设 U U U 是一个 n × n n \times n n×n 的酉算子, ∣ u ⟩ |u\rangle ∣u⟩ 是其特征向量:
U ∣ u ⟩ = e 2 π i φ ∣ u ⟩ U|u\rangle = e^{2\pi i \varphi}|u\rangle U∣u⟩=e2πiφ∣u⟩
其中: U U U:已知的酉算子; ∣ u ⟩ |u\rangle ∣u⟩:已知的特征向量; φ ∈ [ 0 , 1 ) \varphi \in [0,1) φ∈[0,1):未知的相位参数
目的是以高概率估计出 φ \varphi φ 的近似值 φ ~ \tilde{\varphi} φ~,使得:
∣ φ − φ ~ ∣ ≤ ε |\varphi - \tilde{\varphi}| \leq \varepsilon ∣φ−φ~∣≤ε
其中 ε \varepsilon ε 是允许的误差精度。
量子相位估计算法
量子相位估计算法的核心思想是利用量子傅里叶变换 的逆变换来提取相位信息。相位 φ \varphi φ 的二进制展开可以通过受控的 U U U 幂次操作编码到量子态的振幅中。
相位估计算法使用两组量子比特:
第一寄存器 : t t t 个量子比特,用于存储相位的估计值
第二寄存器 : n n n 个量子比特,用于初始化特征向量 ∣ u ⟩ |u\rangle ∣u⟩
初始状态:
∣ 0 ⟩ ⊗ t ∣ u ⟩ |0\rangle^{\otimes t}|u\rangle ∣0⟩⊗t∣u⟩
算法流程如下
初始化和叠加态准备
首先对第一寄存器应用Hadamard门:
1 2 t ∑ j = 0 2 t − 1 ∣ j ⟩ ∣ u ⟩ \frac{1}{\sqrt{2^t}}\sum_{j=0}^{2^t-1}|j\rangle|u\rangle 2t 1j=0∑2t−1∣j⟩∣u⟩
受控幂次操作
对第一寄存器的第 k k k 个量子比特(从0开始编号),应用受控的 U 2 k U^{2^k} U2k 操作:
1 2 t ∑ j = 0 2 t − 1 ∣ j ⟩ U j ∣ u ⟩ \frac{1}{\sqrt{2^t}}\sum_{j=0}^{2^t-1}|j\rangle U^j|u\rangle 2t 1j=0∑2t−1∣j⟩Uj∣u⟩
由于 ∣ u ⟩ |u\rangle ∣u⟩ 是特征向量:
U j ∣ u ⟩ = e 2 π i φ j ∣ u ⟩ U^j|u\rangle = e^{2\pi i \varphi j}|u\rangle Uj∣u⟩=e2πiφj∣u⟩
因此状态变为:
1 2 t ∑ j = 0 2 t − 1 e 2 π i φ j ∣ j ⟩ ∣ u ⟩ \frac{1}{\sqrt{2^t}}\sum_{j=0}^{2^t-1}e^{2\pi i \varphi j}|j\rangle|u\rangle 2t 1j=0∑2t−1e2πiφj∣j⟩∣u⟩
逆量子傅里叶变换
对第一寄存器应用逆量子傅里叶变换 Q F T † QFT^\dagger QFT†:
Q F T † 1 2 t ∑ j = 0 2 t − 1 e 2 π i φ j ∣ j ⟩ QFT^\dagger\left\\frac{1}{\\sqrt{2\^t}}\\sum_{j=0}\^{2\^t-1}e\^{2\\pi i \\varphi j}\|j\\rangle\\right QFT† 2t 1j=0∑2t−1e2πiφj∣j⟩
回忆量子傅里叶变换的定义:
Q F T ∣ x ⟩ = 1 N ∑ y = 0 N − 1 e 2 π i x y / N ∣ y ⟩ QFT|x\rangle = \frac{1}{\sqrt{N}}\sum_{y=0}^{N-1}e^{2\pi i xy/N}|y\rangle QFT∣x⟩=N 1y=0∑N−1e2πixy/N∣y⟩
其中 N = 2 t N = 2^t N=2t。
测量
对第一寄存器进行测量,得到状态 ∣ φ ~ ⟩ |\tilde{\varphi}\rangle ∣φ~⟩,其对应的二进制表示即为相位的估计值。
量子相位估计算法分析
当相位 φ \varphi φ 可以精确表示为 t t t 位二进制分数时:
φ = 0. φ 1 φ 2 ... φ t = ∑ k = 1 t φ k 2 − k \varphi = 0.\varphi_1\varphi_2\ldots\varphi_t = \sum_{k=1}^{t}\varphi_k 2^{-k} φ=0.φ1φ2...φt=k=1∑tφk2−k
在这种情况下,算法将以概率1得到精确结果:
φ ~ = φ \tilde{\varphi} = \varphi φ~=φ
一般情况下,当 φ \varphi φ 不能精确表示为 t t t 位二进制分数时,设其最佳 t t t 位近似为:
a = ⌊ 2 t φ ⌉ / 2 t a = \lfloor 2^t \varphi \rceil / 2^t a=⌊2tφ⌉/2t
其中 ⌊ ⋅ ⌉ \lfloor \cdot \rceil ⌊⋅⌉ 表示四舍五入。
测量结果为 a a a 的概率至少为 4 / π 2 ≈ 0.405 4/\pi^2 \approx 0.405 4/π2≈0.405。
更精确地,对于任意整数 c c c,测量结果为 a + c a+c a+c 的概率为:
P ( a + c ) = { 1 2 2 t ∣ 1 − e 2 π i 2 t ( φ − ( a + c ) / 2 t ) 1 − e 2 π i ( φ − ( a + c ) / 2 t ) ∣ 2 if φ ≠ ( a + c ) / 2 t 1 2 2 t if φ = ( a + c ) / 2 t P(a+c) = \begin{cases} \frac{1}{2^{2t}}\left|\frac{1 - e^{2\pi i 2^t(\varphi - (a+c)/2^t)}}{1 - e^{2\pi i (\varphi - (a+c)/2^t)}}\right|^2 & \text{if } \varphi \neq (a+c)/2^t \\ \frac{1}{2^{2t}} & \text{if } \varphi = (a+c)/2^t \end{cases} P(a+c)=⎩ ⎨ ⎧22t1 1−e2πi(φ−(a+c)/2t)1−e2πi2t(φ−(a+c)/2t) 222t1if φ=(a+c)/2tif φ=(a+c)/2t
使用 t t t 个量子比特时,估计误差满足:
∣ φ − φ ~ ∣ ≤ 1 2 t + 1 |\varphi - \tilde{\varphi}| \leq \frac{1}{2^{t+1}} ∣φ−φ~∣≤2t+11
因此要达到精度 ε \varepsilon ε,需要的量子比特数为:
t = ⌈ log 2 ( 1 / ε ) ⌉ + 1 t = \lceil \log_2(1/\varepsilon) \rceil + 1 t=⌈log2(1/ε)⌉+1
最后,通过增幅 技术或重复采样,可以将成功概率提升到接近1。