基础IO
- 1.回顾C文件接口
-
- 1-1用fopen打开文件
- 1-2用fwrite写文件
- 1-3将信息输出到显示器(标准输出)的三种常见方法
- [1-4stdin & stdout & stderr](#1-4stdin & stdout & stderr)
- 2.系统文件I/O
- 3.缓冲区
1.回顾C文件接口
1-1用fopen打开文件
c
#include <stdio.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
}
fclose(fp);
return 0;
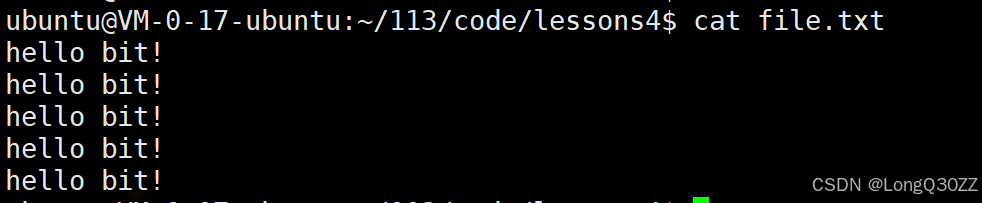
}1-2用fwrite写文件
c
#include <stdio.h>
#include <string.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
}
const char *msg = "hello bit!\n";
int count = 5;
while(count--){
fwrite(msg, strlen(msg), 1, fp);
}
fclose(fp);
return 0;
}
1-3将信息输出到显示器(标准输出)的三种常见方法
c
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg = "hello fwrite\n";
fwrite(msg, strlen(msg), 1, stdout);
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
return 0;
}
fwrite函数
c
const char *msg = "hello fwrite\n";
fwrite(msg, strlen(msg), 1, stdout);- 这是二进制写入方式,将数据块直接写入标准输出流 stdout。
- 优点:适合输出任意二进制数据,不限于文本。
printf函数
c
printf("hello printf\n");- 这是格式化输出函数,是最常用的输出方式。
- 优点 :支持
%d、%s、%f等格式占位符,方便格式化各种类型数据。 - 本质 :printf 内部会将格式化后的字符串输出到 stdout。
fprintf函数
c
fprintf(stdout, "hello fprintf\n");- 这是文件流格式化输出函数,可以指定输出到任意文件流。
- 当指定为
stdout时,效果与printf完全相同。 - 优点:灵活性高,也可用于向文件、
stderr等其他流输出。
1-4stdin & stdout & stderr
stdin标准输入:从键盘(终端输入)
程序从这里读取用户输入或管道传递的数据。
cpp
char buf[100];
fgets(buf, sizeof(buf), stdin); // 从标准输入读取一行stdout标准输出:显示器(终端输出)
用于输出程序的正常运行结果和日志。
cpp
printf("Hello, stdout!\n"); // 等价于 fprintf(stdout, ...)stderr标准错误:从显示器(终端输出)
用于专门输出错误信息和诊断信息,与正常输出分离,方便重定向和日志收集
cpp
fprintf(stderr, "Error: file not found!\n");2.系统文件I/O
2-1传递多个标志位的经典方法
cpp
#include <stdio.h>
// 注意:这里用八进制写法,等价于二进制 0001、0010、0100
#define ONE 0001 // 二进制:0000 0001
#define TWO 0002 // 二进制:0000 0010
#define THREE 0004 // 二进制:0000 0100
void func(int flags) {
// 按位与 & 检查对应位是否被设置(非0则表示设置了该标志)
if (flags & ONE) {
printf("flags has ONE! ");
}
if (flags & TWO) {
printf("flags has TWO! ");
}
if (flags & THREE) {
printf("flags has THREE! ");
}
printf("\n");
}
int main() {
// 单独传递单个标志
func(ONE);
func(THREE);
// 用按位或 | 组合多个标志传递
func(ONE | TWO);
func(ONE | THREE | TWO);
return 0;
}1.宏定义解析
cpp
#define ONE 0001 // 二进制 0000 0001
#define TWO 0002 // 二进制 0000 0010
#define THREE 0004 // 二进制 0000 0100- 这样设计的目的是:可以用按位或
|把多个标志 "打包" 到一个整数里,用按位与&来 "解包" 检查。
2.func函数
cpp
void func(int flags) {
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}- 按位与 & 的作用:flags & ONE 会将 flags 中除了第 0 位之外的所有位都清零。如果结果非零,说明第 0 位是 1,即 ONE 标志被设置。
3.main函数
cpp
int main() {
func(ONE);
func(THREE);
func(ONE | TWO);
func(ONE | THREE | TWO);
return 0;
}- 单个标志 :直接传入 ONE 或 THREE。
- 组合标志 :使用 | 运算符。例如 ONE | TWO 的计算过程是:
ONE = 0000 0001
TWO = 0000 0010
ONE | TWO = 0000 0011 (十进制 3),这个值同时包含了 ONE 和 TWO 两个标志的信息。
程序的完整输出

这样设计的好处:
- 高效紧凑:一个
int变量(通常 32 位)就可以传递 32 个独立的布尔标志,大大节省了函数参数的数量和内存开销。 - 灵活组合:可以任意组合标志,而不需要为每种组合定义新的函数或数据结构。
- 广泛应用:这是系统编程中的经典模式,例如:
- Linux 系统调用
open()的 mode 参数。
许多库函数(如fopen()的模式参数)
2-2用系统接口来进行文件访问
2-3写文件
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
int fd = open("file.txt", O_WRONLY|O_CREAT, 0644);
if(fd < 0){
perror("open");
return 1;
}
int count = 5;
const char *msg = "hello bit!\n";
int len = strlen(msg);
while(count--){
write(fd, msg, len);
}
close(fd);
return 0;
}1.头文件引入
cpp
#include <stdio.h> // 标准输入输出(用于 perror 函数)
#include <sys/types.h> // 系统类型定义(如 mode_t、pid_t 等)
#include <sys/stat.h> // 文件状态/权限相关(如 O_CREAT、0644 等宏)
#include <fcntl.h> // 文件控制相关(open 函数、文件打开标志)
#include <unistd.h> // 系统调用(write、close、umask 等)
#include <string.h> // 字符串操作(strlen 函数)umask (0) // 重置文件创建掩码为0,确保 open 的权限设置生效
umask :Linux 中创建文件时,实际权限 = open 指定权限 - umask 值。
默认 umask 可能是 0022,若不设为 0,0644 权限会变成 0644 & ~0022 = 0640;设为 0 则完全按 0644 生效。
open是 Linux 系统调用,返回文件描述符**(fd)(非负整数)**,失败返回 -1。
cpp
int fd = open("file.txt", O_WRONLY|O_CREAT, 0644);其中file.txt要创建 / 打开的文件名
O_WRONLY|O_CREAT:打开标志
O_WRONLY:只写模式打开;
O_CREAT:文件不存在则创建;
0644:文件权限(八进制):
所有者(u):读 + 写(6=4+2);
同组用户(g):只读(4);
其他用户(o):只读(4)。

write系统调用

int fd:文件描述符(File Descriptor),它是一个整数,代表要写入的目标。这个目标可以是一个普通文件、标准输出(stdout,值为 1)
const void *buf:指向缓冲区的指针,该缓冲区存放着要写入的数据。const 表示这个函数不会修改缓冲区的内容;void * 表示它可以接受任何类型的数据指针(如 char*、int* 等),因为 write 操作的是字节流。
size_t count:无符号整数,表示期望从缓冲区 buf 中写入的最大字节数。
2-4系统调用和库函数
fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
⽽ open close read write lseek 都属于系统提供的接⼝,称之为系统调用接口
| 概念 | 本质 | 运行层级 | 调用方式 |
|---|---|---|---|
| 系统调用 | 内核提供的、用户程序请求内核服务的唯一接口(如 open/write/close) | 内核态 | 软中断 / syscall 指令触发 |
| 库函数 | 封装系统调用/实现通用功能的用户态函数(如 fopen/fwrite/printf) | 用户态 | 直接函数调用(最终可能调用系统调用) |
通俗比喻:
系统调用 是你直接跟内核 "喊话",嗓门大但费力气。
库函数是你找了个 "翻译兼助理",他帮你喊话,还顺便把事情办得更漂亮。
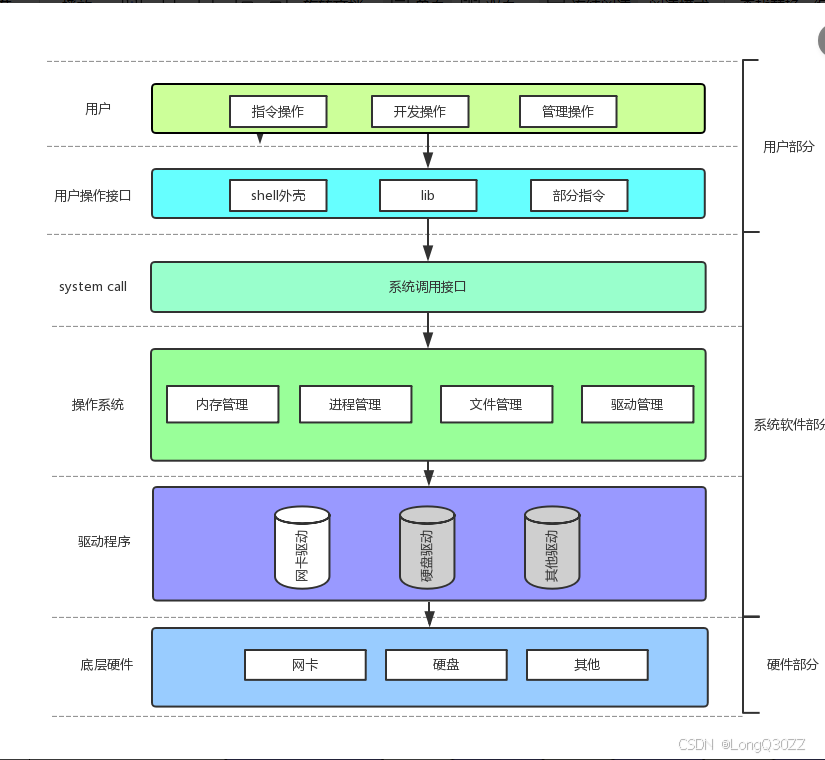
所以,可以认为, f# 系列的函数,都是对系统调用的封装,方便二次开发。
2-5文件描述符fd
文件描述符(File Descriptor)
是进程 在用户态 用来标识一个已打开的文件 / IO 对象的非负整数。
本质:
- 它不是文件本身
- 它不是文件路径
- 它是进程与内核之间的 "索引 / 句柄"
- 所有 IO 操作(read/write/close...)都只认 fd,不认路径
在OS接口层面,只认fd
cpp
int fd = open("file.txt", O_RDONLY);
char buf[1024];
read(fd, buf, 1024);
printf("file:fd=%d\n",fd);
close(fd); 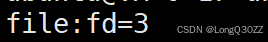
默认的文件描述符是3
因为在进程启动时,默认就打开 3 个:
| fd | 名称 | 含义 | 对应设备 |
|---|---|---|---|
| 0 | stdin | 标准输入 | 键盘 |
| 1 | stdout | 标准输出 | 屏幕 |
| 2 | stderr | 标准错误 | 屏幕 |
所以你自己 open 的文件,一般从 fd=3 开始。
2-6内核中的fd
1)进程级:文件描述符表(File Descriptor Table)
每个进程独立一张,内核在 task_struct(进程描述符)里管理。
可以理解成内核里的数组:
cpp
// 内核伪代码,每个进程都有这么一张表
struct file *fd_table[NR_OPEN_DEFAULT];fd 就是这个数组的下标!
2)系统全局:打开文件对象(struct file)
fd_table[i] 指向的是内核全局的 struct file(打开文件表项)。
它保存的是打开状态,不是文件内容:
cpp
// 内核伪代码:真正的 struct file 简化版
struct file {
struct inode *f_inode; // 指向真正的文件(inode)
loff_t f_pos; // 文件偏移量(读到哪了)
unsigned int f_flags; // 打开标志 O_RDONLY, O_APPEND...
fmode_t f_mode; // 读写模式
struct file_operations *f_op; // 读写函数指针(read/write)
// ... 引用计数、锁、私有数据等
};多个 fd 可以指向同一个 struct file
3)文件系统级:inode(struct inode)
struct file 里的 f_inode 指向磁盘文件的元数据:
cpp
struct inode {
dev_t i_dev; // 哪个设备
ino_t i_ino; // inode 号
umode_t i_mode; // 文件类型、权限
loff_t i_size; // 文件大小
struct super_block *i_sb;
struct address_space *i_mapping; // 数据在磁盘/缓存的位置
// ...
};inode 才是文件本体,存储在文件系统。
一句话串起来:fd = 进程私有数组下标 → 找到 struct file(打开状态) → 找到 inode(真实文件)
用 open 完整走一遍内核流程
cpp
int fd = open("file.txt", O_RDONLY);内核做了什么:
- 查找 file.txt ,拿到对应的 inode
- 新建 / 找到一个
struct file,指向 inode,初始化偏移 = 0 - 在当前进程的 fd_table 里找最小未使用下标 (文件描述符的分配规则:在
files_struct数组当中,找到当前没有被使用的最小的⼀个下标,作为新的文件描述符。) fd_table[3]= 指向那个struct file- 返回 3 给用户态
之后使用read
cpp
read(fd, buf, 100);内核:
- 拿 fd=3
- 找
current->fd_table[3]得到struct file - 用
f_pos知道从哪读 - 通过
f_inode找到文件数据 - 读完后
f_pos +=读的长度
2-7重定向和dup2
重定向本质:重定向 = 把进程文件描述符表中某个下标(比如 1、2)的指针,强行改成指向另一个 struct file(文件 / 管道 /socket)。
就是数组下标不变,只是更改文件描述表的指针指向
它的内核本质只有三步:
- 打开目标文件(得到一个新 fd,比如 3)
- 把
fd_table [1]的指针 替换成fd_table [3]的指针 - 关闭多余的 fd(3)
dup2 是实现重定向的「内核级核心工具」 ------ 所有 Shell 里的 >、<、2>&1 等重定向语法,底层都是通过调用 dup2 系统调用来完成的。
dup2 的函数原型(Linux/Unix)
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);dup2 的核心作用
把 newfd 这个文件描述符,"替换" 成指向 oldfd 对应的那个 struct file(内核打开文件对象)。
假设进程当前的 fd 表是这样的:
| fd 编号 | 指向的 struct file | 对应资源 |
|---|---|---|
| 0 | A | 键盘(stdin) |
| 1 | B | 屏幕(stdout) |
| 2 | C | 屏幕(stderr) |
| 3 | D | test.txt 文件 |
执行 dup2(3, 1) 后,fd 表变成:
| fd 编号 | 指向的 struct file | 对应资源 |
|---|---|---|
| 0 | A | 键盘(stdin) |
| 1 | D | test.txt 文件 |
| 2 | C | 屏幕(stderr) |
| 3 | D | test.txt 文件 |
newfd=1 原本指向 B(屏幕),现在被强制改成指向 D(文件);
oldfd=3 不受影响,依然指向 D;
如果 newfd 原本是打开状态,dup2 会先自动关闭它,再替换。
代码演示
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <string.h>
int main() {
// 1. 打开目标文件
// O_WRONLY: 只写模式
// O_CREAT: 文件不存在则创建
// O_TRUNC: 文件存在则清空原有内容
// 0644: 文件权限(所有者可读可写,其他用户只读)
int file_fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (file_fd == -1) { // 检查打开是否失败
perror("open output.txt failed"); // 打印错误原因
exit(EXIT_FAILURE);
}
// 2. 核心:dup2 重定向
// 把 stdout(fd=1)的指向替换为 file_fd 对应的文件
// 执行后,所有写 fd=1 的操作都会写到 output.txt
int ret = dup2(file_fd, 1);
if (ret == -1) {
perror("dup2 failed");
exit(EXIT_FAILURE);
}
// 3. 关闭多余的 file_fd(fd=1 已经指向该文件,无需保留 file_fd)
close(file_fd);
// 4. 测试输出:原本写屏幕的内容,现在写入文件
printf("这是标准输出,会写到 output.txt\n");
const char* msg = "直接用 write 写 fd=1,也会写到文件\n";
write(1, msg, strlen(msg)); // 系统调用级别的写操作
// 标准错误(fd=2)未重定向,仍输出到屏幕
fprintf(stderr, "这是标准错误,依然输出到屏幕\n");
return 0;
}
3.缓冲区
3-1什么是缓冲区
缓冲区(Buffer)是内存中一块临时存储数据的区域,作用是「攒够数据再一次性读写」,减少慢速 IO(磁盘 / 网络 / 终端)的调用次数,提升整体效率。
简单类比:
你去倒垃圾:
无缓冲区 :扔一张废纸就跑一趟垃圾桶(低效,频繁 IO);
有缓冲区 :把废纸攒满垃圾袋,再一次性倒(高效,减少 IO 次数)。
垃圾袋 = 缓冲区,垃圾桶 = 磁盘 / 终端,扔垃圾 = 系统调用(read/write)。
c
// 库函数
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
const char *s = "hello fwrite\n";
fwrite(s, strlen(s), 1, stdout);
// 系统调用
const char *ss = "hello write\n";
write(1, ss, strlen(ss));
fork();输出的结果为
c
hello printf
hello fprintf
hello fwrite
hello write原因:
- 当
stdout指向终端时,默认是行缓冲,遇到\n就会立即刷新缓冲区。 printf、fprintf、fwrite都带有\n,所以数据立刻输出到屏幕,缓冲区为空。write是系统调用,无用户态缓冲,数据也立刻输出。fork()时,缓冲区已经是空的,所以父子进程退出时没有重复输出

重定向到文件(stdout 变为全缓冲)
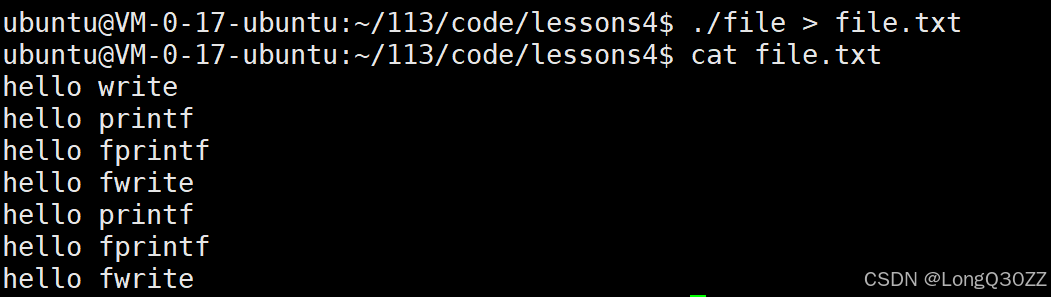
原因:
- 当
stdout指向文件时,默认是全缓冲,只有缓冲区满或程序退出时才会刷新。 printf、fprintf、fwrite的数据都留在了用户态缓冲区中,没有立即写入文件。write是系统调用,数据直接写入内核,因此只出现一次。接调用内核接口,数据立刻进入内核,因此最先输出;fork()时,子进程复制了父进程的缓冲区。
父子进程先后退出时,各自刷新缓冲区,导致缓冲区中的 3 行数据被输出了两次。
3-2缓冲类型
| 类型 | 刷新条件 | 典型场景 | 特点 |
|---|---|---|---|
| 全缓冲 (Full Buffering) | 1. 缓冲区满 2. 手动调用 fflush() 3. 程序正常退出 | 磁盘文件(fopen 打开的普通文件) | 效率最高,攒够数据再一次性 IO;实时性差 |
| 行缓冲 (Line Buffering) | 1. 遇到换行符 \n 2. 缓冲区满 3. 手动 fflush() 4. 程序退出 | 标准输入/输出(stdin、stdout)连接到终端时 | 兼顾效率和交互性,适合终端输出 |
| 无缓冲 (Unbuffered) | 无缓冲,数据直接写入,不攒数据 | 标准错误流 stderr | 实时性最高,确保错误信息立即输出;频繁 IO 会降低效率 |
除了上述列举的默认刷新方式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时;
- 执行flush语句;
- 进程结束