目录
[核心 3 大功能](#核心 3 大功能)
[哨兵选举的 2 个核心阶段](#哨兵选举的 2 个核心阶段)
[阶段 1:判定主库真宕机(客观下线)](#阶段 1:判定主库真宕机(客观下线))
[阶段 2:选举(2 层选举,先选哨兵 leader,再选新主库)](#阶段 2:选举(2 层选举,先选哨兵 leader,再选新主库))
[① 选举哨兵领导者(负责执行故障切换)](#① 选举哨兵领导者(负责执行故障切换))
[② 选举新主库(从存活的从库中选)](#② 选举新主库(从存活的从库中选))
1.主从复制
持久化保证了即使redis服务重启也不会丢失数据,因为redis服务重启后会将硬盘上持久化的数据恢复到内存中,但是当redis服务器的硬盘损坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障,如下图:
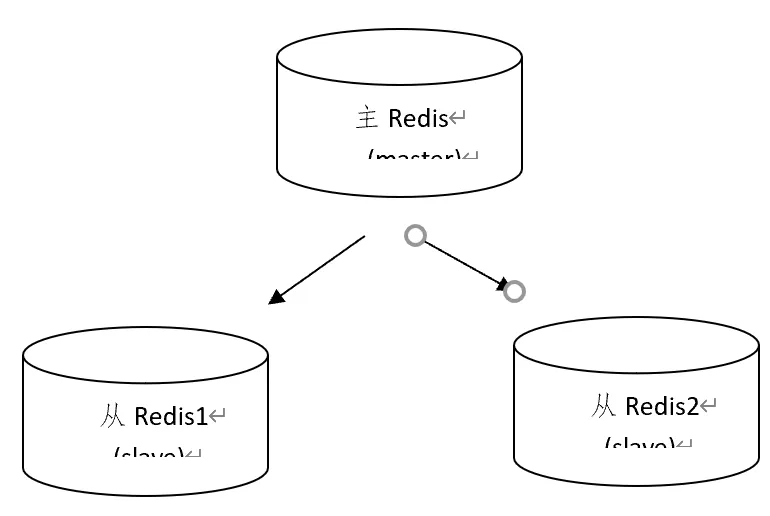
说明:
1.主redis中的数据有两个副本(replication)即从redis1和从redis2,即使一台redis服务器宕机其它两台redis服务也可以继续提供服务。
2.主redis中的数据和从redis上的数据保持实时同步,当主redis写入数据时通过主从复制机制会复制到两个从redis服务上。
3.只有一个主redis,可以有多个从redis。
4.主从复制不会阻塞master,在同步数据时,master 可以继续处理client 请求
5.一个redis可以即是主又是从,如下图:
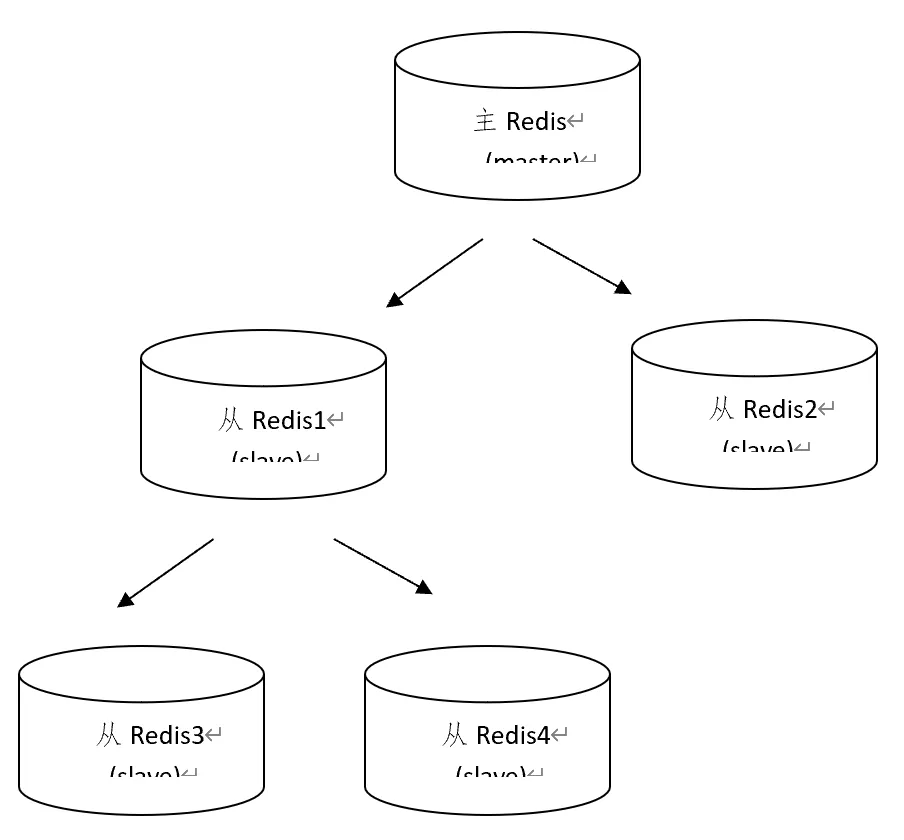
(1)复制实例
把redis的bin目录和配置文件复制到另外一个目录下面作为另外一个redis实例:
其中6379作为主库,其他两个是从库

每一个库里面的文件如图所示:
 bin目录:
bin目录:
赋予文件可执行权限的命令:
bash
chmod +x [文件名](2)修改配置文件
主库
找到如下配置项并且修改它们:
bash
bind 0.0.0.0监听所有IPv4接口,允许外部连接
也可以指定特定的IP
bash
requirepass [客户端连接密码]客户端连接的密码
bash
protected-mode yes开启保护模式

bash
daemonize yes开启守护进程模式**,**redis在后台运行
如果是no的话,redis就会在前台运行
从库6380(6381的操作也一样)
修改配置文件
我用的是redis5.0.4版本
挂载命令用的不是slaveof
bash
replicaof [主库ip] [主库端口]
#让这个实例运行到6380端口(6381的话就改成6381)
port 6380
pidfile /var/run/redis_6380.pid
requirepass [连接密码]
#如果配置了主库密码,从库需要配置主库的密码
masterauth [主库密码](3)验证配置
我们可以使用我们本地windows的Redis远程连接工具连接
连接主库和从库之后,在主库上面添加数据,从库上面也能查询到
Host是运行6381实例的主机ip(我们现在是三个redis实例都在一个主机上,所以填相同的ip就行了)
AUTH是密码,就是上面配置好的
填写完之后点击Test Connection
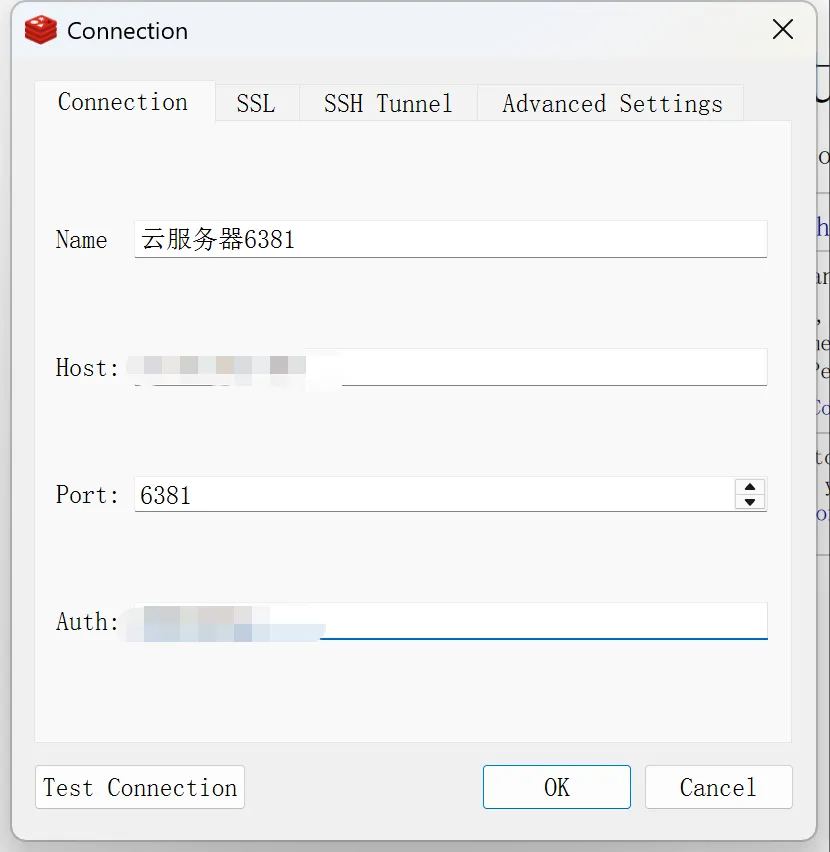
看到连接成功就可以点ok了
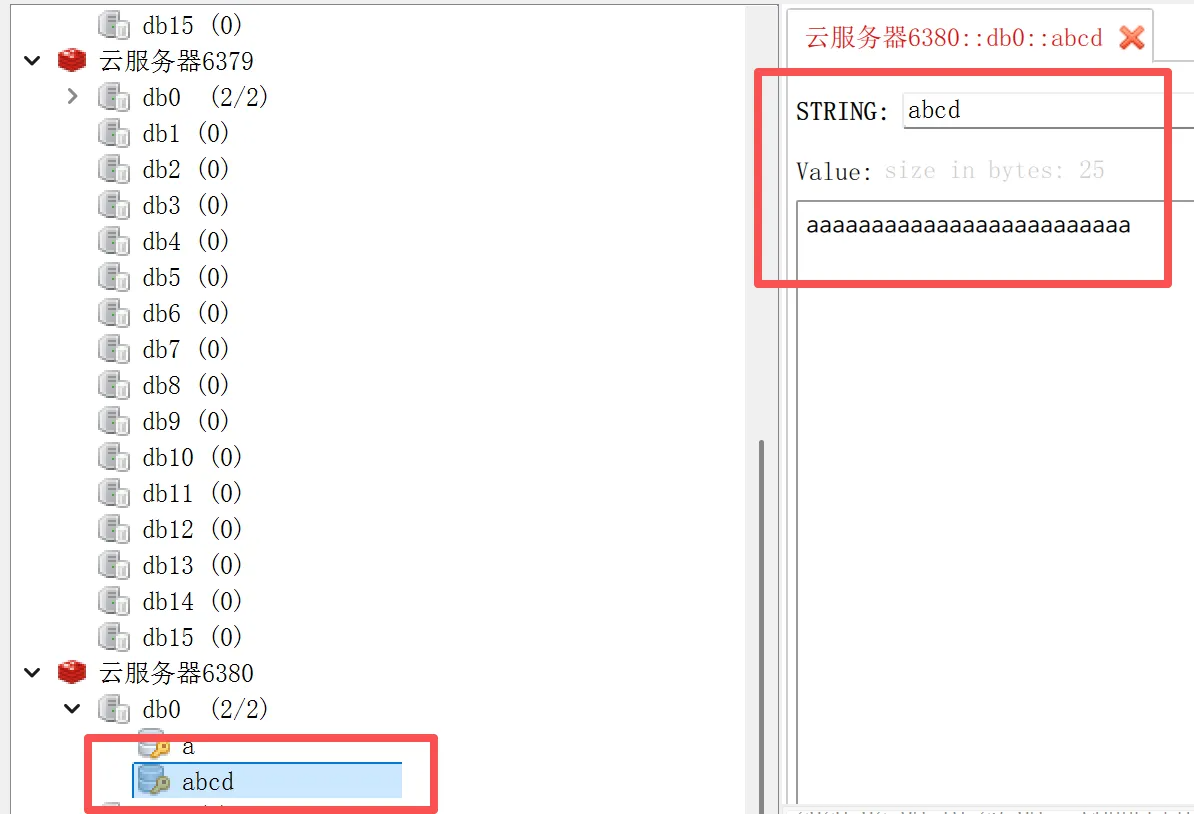
然后在6379端口的主库添加键:

然后在另外两个库里面查看:

2.哨兵机制
哨兵是 Redis 主从架构的 "监控 + 自动故障恢复" 组件,核心解决主库宕机后手动切换主从的问题,保证集群高可用。
核心 3 大功能
1.监控:持续检查主库、从库是否存活;
2.故障自动切换:主库宕机后,从哨兵选举新主库,让其他从库同步新主库;
3.通知:把故障和切换结果告知客户端 / 运维。
哨兵选举的 2 个核心阶段
哨兵的选举分 "判定主库宕机" 和 "选举新主库 + 哨兵领导者" 两步,缺一不可:
阶段 1:判定主库真宕机(客观下线)
- 单个哨兵发现主库无响应 → 标记为 "主观下线"(自己认为宕机);
- 该哨兵向集群中其他哨兵发 "确认请求";
- 超过 quorum (配置文件中 monitor 后的数字)个哨兵确认主库宕机 → 标记为 "客观下线"(集群公认宕机)。
阶段 2:选举(2 层选举,先选哨兵 leader,再选新主库)
① 选举哨兵领导者(负责执行故障切换)
所有哨兵通过 "Raft 协议" 投票:每个哨兵都能参选,先到先得,获得半数以上选票的哨兵成为 leader;
只有 leader 会执行后续的 "选新主库、切换主从" 操作,其他哨兵仅待命。
② 选举新主库(从存活的从库中选)
哨兵 leader 按以下优先级选新主库(从上到下筛选):
- 排除宕机、网络不通的从库;
- 选 replica-priority (从库优先级)值更小的(默认 100,0 表示无参选资格);
- 选复制偏移量更大的(数据和旧主库更同步);
- 选运行 ID 更小的(最终兜底规则)。
关键细节
- 哨兵集群要求:至少部署 3 个哨兵(奇数),避免投票平局; quorum 建议设为哨兵数量的半数 + 1(如 3 个哨兵设 2);
- 切换后动作:新主库会被关闭只读( replica-read-only no ),其他从库会被修改 replicaof 指向新主库;
- 客户端适配:客户端需连接哨兵获取主库地址,而非直接连固定 IP: 端口(否则切换后连不上新主库)。
| 核心环节 | 关键逻辑 |
|---|---|
| 哨兵作用 | 监控主从 + 自动故障切换 + 通知 |
| 宕机判定 | 主观下线 → 超过 quorum 确认 → 客观下线 |
| 选举流程 | 先选哨兵 leader(Raft 协议)→ 再选新主库(优先级 + 偏移量 + 运行 ID) |
| 核心保障 | 3 个以上哨兵 + 奇数部署,避免脑裂 / 投票平局 |
(1)配置哨兵
我们使用多配置文件方式创建三个哨兵
在6379主库目录下创建3个哨兵配置文件 sentinel_26379.conf 、 sentinel_26380.conf 、 sentinel_26381.conf

配置文件如图:
bash
# 哨兵自身端口
port 26379
# 守护进程模式
daemonize yes
# pid文件路径
pidfile /var/run/redis-sentinel-26379.pid
# 日志文件路径
logfile "/var/log/redis/sentinel_26379.log"
# 工作目录
dir /tmp
# 核心监控配置:监控主库master 127.0.0.1:6379 quorum=2
# 格式:sentinel monitor <主库名称> <主库IP> <主库端口> <quorum值>
sentinel monitor master 127.0.0.1 6379 2
# 主库密码(若主库有requirepass,必须配置!无密码则注释这行)
sentinel auth-pass master 主库密码
# 主库无响应超时时间(30秒)
sentinel down-after-milliseconds master 30000
# 故障切换超时时间(180秒)
sentinel failover-timeout master 180000
# 并行同步从库数(1个,避免主库压力大)
sentinel parallel-syncs master 1剩下两个哨兵也这样配,只需要改端口就行了
改完端口之后,创建好日志目录
bash
mkdir -p /var/log/redis然后启动哨兵:
没权限的话先给权限
bash
chmod +x redis-sentinel进入6379的bin目录,运行如下命令:
bash
./redis-sentinel ../sentinel_26379.conf
./redis-sentinel ../sentinel_26380.conf
./redis-sentinel ../sentinel_26381.conf我们可以用命令确认是否启动
bash
ps -ef | grep redis-sentinel登录哨兵,可以看到如下信息:
bash
./redis-cli -p 26379我们重点看
name(主库名称):master
ip(主库ip):127.0.0.1
port(主库端口):6379
num-slaves(识别到2个从库6380/6381):2
num-other-sentinels(识别到其他的2个哨兵):2
bash
127.0.0.1:26379> sentinel master master
1) "name"
2) "master"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "f3507f05bcf0b74f9f1bc02963e84b0c6e9e446d"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "390"
19) "last-ping-reply"
20) "390"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "1785"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "272743"
29) "config-epoch"
30) "0"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"(2)模拟主库宕机
我们先把主库停掉

然后等待30秒(对应配置的 down-after-milliseconds 30000 )
这里我们看到master主库已经变成了6380

然后我们恢复6379,在26379哨兵当中查看:
bash
sentinel get-master-addr-by-name master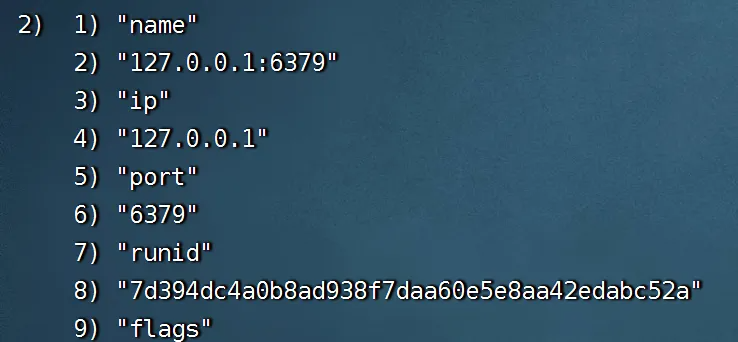
6379出现在从库列表当中
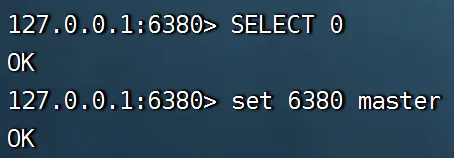
(3)新主库的值修改
我们在恢复6379之前,6380作为新的主库也能够进行正常的读写操作:
然后在6381处查看: