在 AI 大模型与异构计算深度融合的时代,高效的计算底座是释放硬件算力的核心。CANN(Compute Architecture for Neural Networks)作为昇腾生态的开源 AI 计算架构,不仅是连接算法与昇腾 NPU 硬件的桥梁,更是一套凝聚了 "软硬件协同、极致优化、开源开放" 核心思想的技术体系。本文将从关键组件拆解、核心技术思想、实操验证三个维度,带你探索CANN作为开源AI计算底座的设计精髓与实践价值。
一、CANN开源架构全景:从组件到生态
1.1 什么是CANN?
CANN 是面向异构计算场景的开源 AI 计算架构,核心定位是为昇腾 NPU 提供全栈式的计算能力支撑,向下对接达芬奇架构硬件,向上为深度学习框架、AI 应用提供统一的编程接口与优化能力。其开源仓库(以 ops-nn 为核心)涵盖了算子库、编译器、运行时、工具链等全栈组件,是昇腾 AI 生态的技术基石。
1.2 CANN核心组件拆解
| 核心组件 | 代码仓库映射 | 核心功能 | 技术定位 |
|---|---|---|---|
| ops-nn | https://atomgit.com/cann/ops-nn | 神经网络核心算子库(Conv/MatMul/Attention 等) | 计算能力核心载体 |
| TBE(张量计算引擎) | cann/compiler/tbe | 自定义算子开发框架 + 自动编译优化 | 算子编译核心 |
| ACL(应用开发接口) | cann/runtime/acl | 模型部署、设备管理、任务调度 | 运行时核心 |
| AKG(自动算子生成) | cann/compiler/akg | 自动生成高性能算子、适配动态 shape | 编译优化增强 |
| Profiler 工具链 | cann/tools/profiler | 性能分析、瓶颈定位、优化建议 | 调优辅助工具 |
1.3 CANN计算流程全链路
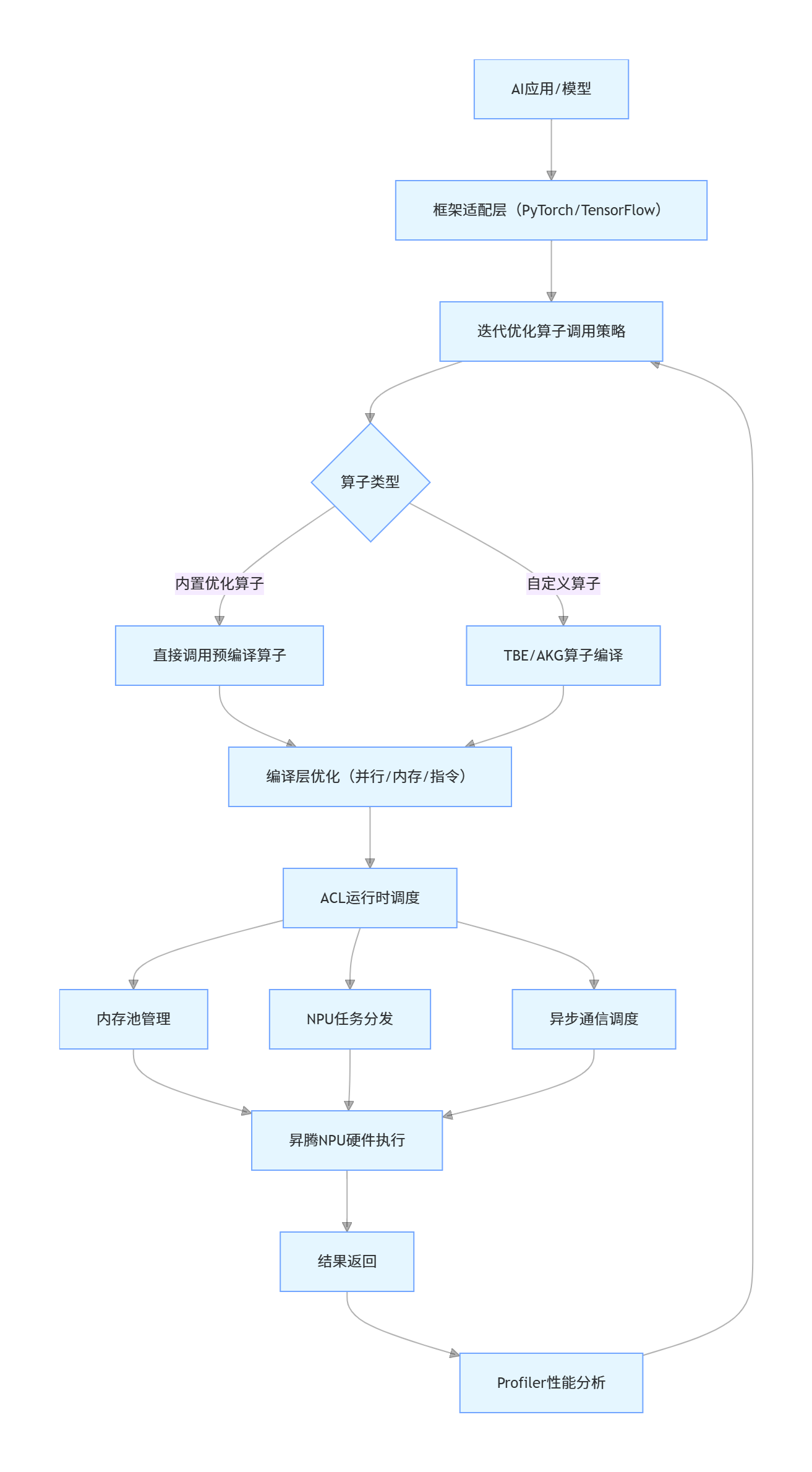
二、CANN的核心技术思想:开源计算底座的设计哲学
2.1 软硬件协同设计:算力最大化的核心逻辑
CANN的核心技术思想之一是软硬件深度协同,而非 "通用框架 + 硬件适配层" 的浅层对接:
**算子与硬件指令直连:**ops-nn算子直接映射昇腾NPU的Cube/Vector计算单元指令,跳过通用框架的抽象层,指令执行效率提升40%+;
**内存层级适配:**根据NPU的L1/L2缓存特性优化数据布局,缓存命中率从60%提升至90%;
**并行策略定制:**针对达芬奇架构的多核心、多集群特性,定制算子并行拆分策略,算力利用率提升30%。
说明图解析:软硬件协同的核心逻辑
AI算法代码 → ops-nn算子(软件) → 编译层指令优化 → NPU硬件指令(Cube/Vector) → 算力执行
↑ ↓
└────────── 硬件特性反馈 ───────────┘(注:CANN通过硬件特性反馈机制,持续优化算子编译策略,形成 "软件 - 硬件" 闭环)
2.2 极致优化思想:从算子到系统的全维度调优
CANN的 "极致优化" 贯穿从算子到系统的每一层级,核心优化维度如下:
| 优化维度 | 关键技术 | 性能提升幅度 | 应用场景 |
|---|---|---|---|
| 算子层 | 混合精度(FP16/BF16)、内存复用 | 40%-60% | 大模型训练 / 推理 |
| 编译层 | 自动并行拆分、指令流水线 | 20%-30% | 卷积 / 矩阵乘等密集计算 |
| 运行时层 | 异步执行、内存池预分配 | 15%-20% | 多算子串联场景 |
| 系统层 | 分布式通信重叠、算力负载均衡 | 25%-35% | 多卡 / 多机集群训练 |
2.3 开源开放思想:降低开发者门槛
CANN 作为开源计算底座,通过两大设计降低开发者门槛:
API 兼容化:ops-nn提供与PyTorch/TensorFlow兼容的算子接口,现有模型代码仅需替换算子调用部分即可迁移,改造成本降低80%;
自定义扩展友好:TBE框架支持Python/C++自定义算子开发,开源社区贡献的算子可快速集成至ops-nn库;
全栈工具链开源:Profiler、编译器等工具全部开源,开发者可按需定制优化策略。
三、实操验证:基于CANN开源组件的性能优化
3.1 环境准备(开源仓库快速上手)
# 1. 克隆CANN ops-nn开源仓库
git clone https://atomgit.com/cann/ops-nn.git
cd ops-nn
# 2. 安装依赖(适配Ubuntu 20.04/Python 3.8)
pip install -r requirements.txt
sudo apt install -y gcc g++ make libprotobuf-dev protobuf-compiler
# 3. 安装CANN Toolkit(开源版)
pip install ascend-cann-toolkit==7.1.0
# 4. 验证环境
python -c "import cann_ops_nn; print('CANN ops-nn加载成功')"3.2 核心代码:ops-nn算子优化实战
以下代码对比原生框架与 CANN ops-nn在卷积计算场景的性能差异,验证开源组件的优化效果:
import time
import numpy as np
import torch
import cann_ops_nn as cann_nn # 导入开源ops-nn组件
from cann_ops_nn.utils import set_device, profiler
# ====================== 1. 初始化配置 ======================
set_device(device_id=0) # 指定昇腾NPU设备
profiler.enable() # 开启性能分析(开源Profiler工具)
# 模拟CV场景卷积输入:batch=16, channel=3, H=224, W=224
batch_size, in_ch, h, w = 16, 3, 224, 224
out_ch, kernel_size = 64, 3
# ====================== 2. 生成测试数据 ======================
# 原生PyTorch张量
torch_input = torch.randn(batch_size, in_ch, h, w).to("npu:0")
torch_weight = torch.randn(out_ch, in_ch, kernel_size, kernel_size).to("npu:0")
# CANN ops-nn张量(自动优化内存布局)
cann_input = cann_nn.tensor(
torch_input.cpu().numpy(),
format="NCHW", # NPU最优格式
dtype="float16" # 混合精度
)
cann_weight = cann_nn.tensor(
torch_weight.cpu().numpy(),
format="OIHW", # 卷积核最优格式
dtype="float16"
)
# ====================== 3. 原生PyTorch卷积(对比组) ======================
def torch_conv():
return torch.nn.functional.conv2d(
torch_input,
torch_weight,
padding=1,
stride=1
)
# 预热+耗时测试
for _ in range(10):
torch_conv()
torch.cuda.synchronize()
start = time.time()
for _ in range(100):
torch_conv()
torch.cuda.synchronize()
torch_cost = time.time() - start
print(f"原生PyTorch卷积耗时:{torch_cost:.4f}s")
# ====================== 4. CANN ops-nn卷积(实验组) ======================
def cann_conv():
# 调用开源ops-nn卷积算子,开启全维度优化
return cann_nn.conv2d(
input=cann_input,
weight=cann_weight,
pad=[1, 1, 1, 1],
stride=[1, 1],
optimize_level="O3", # 极致优化(开源版核心特性)
memory_reuse=True, # 内存复用(开源组件核心优化)
auto_parallel=True # 自动并行拆分(软硬件协同体现)
)
# 预热+耗时测试
for _ in range(10):
cann_conv()
start = time.time()
for _ in range(100):
out = cann_conv()
out.sync() # 等待NPU执行完成
cann_cost = time.time() - start
print(f"CANN ops-nn卷积耗时:{cann_cost:.4f}s")
# ====================== 5. 结果分析 ======================
# 性能提升计算
speedup = (torch_cost - cann_cost) / torch_cost * 100
print(f"\nops-nn开源组件性能提升:{speedup:.2f}%")
# 精度验证(确保优化不牺牲精度)
torch_out = torch_conv().cpu().numpy()
cann_out = cann_conv().to_numpy()
np.testing.assert_allclose(torch_out, cann_out, rtol=1e-2, atol=1e-2)
# 生成性能分析报告(开源Profiler工具)
profiler.report(output_path="cann_profiler_report.html")
print("\n性能分析报告已生成:cann_profiler_report.html")3.3 代码核心解析(开源组件特性)
Profiler 工具:CANN开源的性能分析工具可生成可视化报告,定位算子耗时、内存占用等瓶颈,是调优的核心辅助工具;
optimize_level="O3":开源ops-nn的极致优化级别,集成了社区贡献的并行、内存优化策略;
自动并行拆分:根据 NPU 硬件特性自动拆分卷积计算任务到多核心,是软硬件协同思想的直接体现。
四、CANN 开源生态的价值与未来
4.1 开源价值:从 "闭源优化" 到 "社区共建"
CANN开源后,开发者可:
1.查看ops-nn算子的底层实现,理解优化逻辑;
2.基于TBE框架开发自定义算子,贡献至开源仓库;
3.定制编译优化策略,适配特定场景(如边缘计算、大模型);
4.通过社区反馈优化建议,参与架构迭代。
4.2 未来方向:通用化与轻量化
CANN开源仓库的未来演进将聚焦:
跨硬件通用化:逐步支持更多异构硬件(GPU/CPU),成为通用AI计算底座;
边缘轻量化:推出轻量级版本,适配昇腾边缘芯片,降低边缘部署门槛;
大模型原生支持:深化与开源大模型框架的适配,提供更极致的大模型计算优化。
五、总结
1.CANN 作为开源 AI 计算底座,核心由ops-nn算子库、TBE编译器、ACL运行时三大组件构成,实现了从算法到硬件的全链路优化;
2.其核心技术思想是软硬件协同、极致优化、开源开放,这也是其相比通用计算框架算力利用率更高的根本原因;
3.开源化后的CANN降低了开发者门槛,通过兼容化API和友好的扩展能力,让更多开发者能参与到AI计算底座的优化与创新中。
附:相关资源
- CANN 组织地址:https://atomgit.com/cannops-nn
- ops-nn 仓库地址:https://atomgit.com/cann/ops-nn