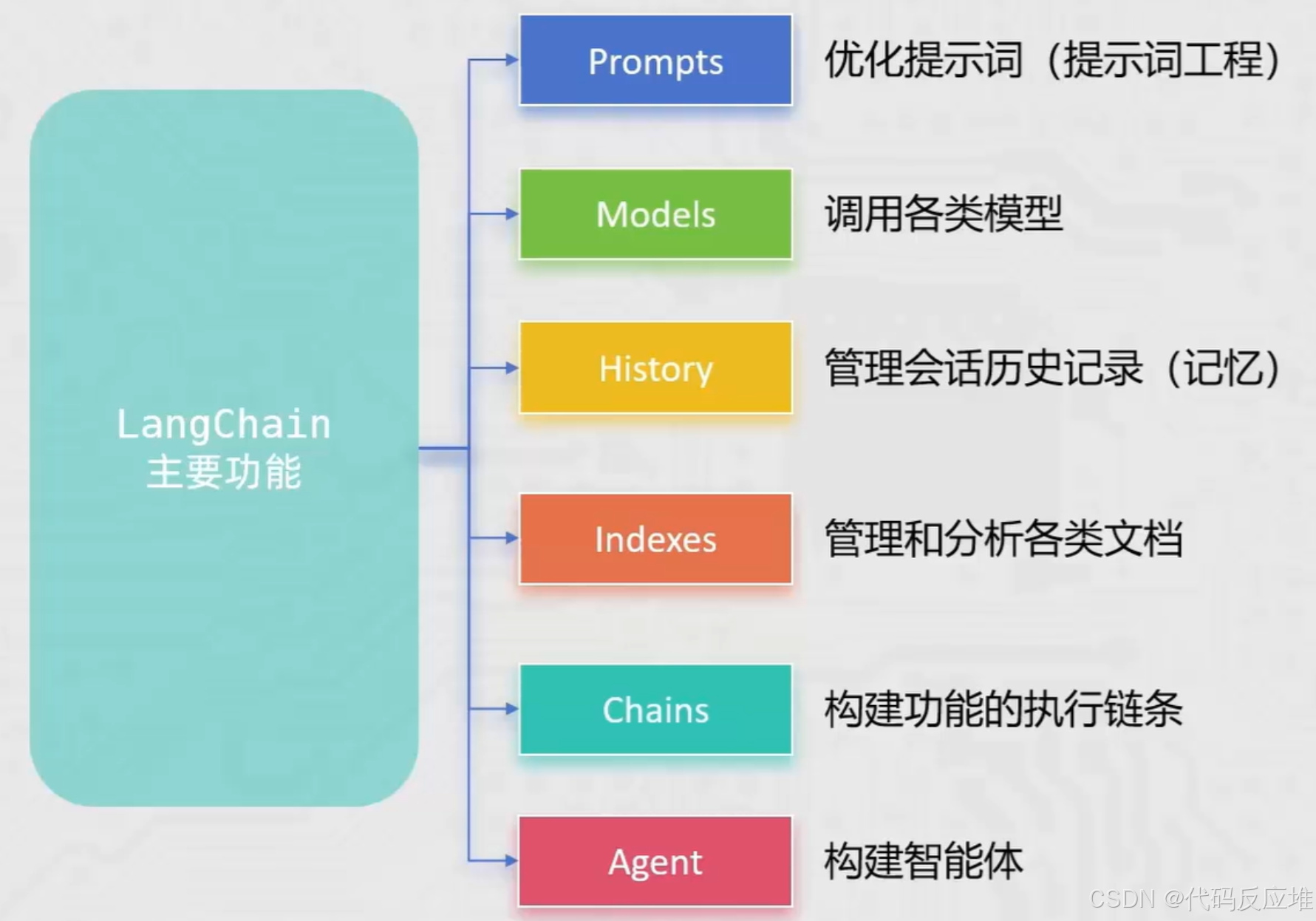
LangChain介绍
2022年10月LangChain由 Lson Chase 创建,LangChain围绕 LLMs(大语言模型)建立,为各种 LLMs 实现通用接口,简化 LLMs 相关开发,方便开发者快速构建复杂的 LLMs 应用。
LangChain 是一个用于开发大语言模型(LLM)相关应用的 Python 第三方库 ,它是一个 集大成者/主力框架 ,提供了构建复杂LLM应用所需的各种功能组件和API。核心目标是让开发者能够便捷地调用 LLM 的全部能力 。后续学习与开发 RAG(检索增强生成) 应用的主力框架 。
环境设置
shell
pip install langchain langchain-community langchain-ollama dashscope chromadb -i https://pypi.tuna.tsinghua.edu.cn/simplelangchain:LangChain 框架的核心主包,提供了基础架构和核心组件。- langchain-community: 社区支持包,集成了大量第三方模型、工具和功能,极大地扩展了 LangChain 的能力
langchain-ollama: 专门用于支持调用 Ollama 框架托管部署的本地大语言模型dashscope: 阿里云 通义千问 大模型的官方 Python SDK。用于通过 LangChain 调用阿里云的模型服务。- chromadb: LangChain 兼容多种向量数据库如chromadb,用于实现文档的存储、检索与分析,这是构建 RAG 应用的关键组件
RAG介绍
RAG主要针对大语言模型固有的以下四个关键问题:
- 领域知识缺乏:LLM的训练数据主要来自公开的互联网和开源数据集,缺乏特定领域(如企业、专业)的私有知识。
- 知识过时:模型训练完成后知识即固化,无法自动更新,导致信息滞后。
- 幻觉问题:模型可能生成看似合理但实际错误或虚构的信息。
- 安全与可控性:难以控制模型生成内容的范围和准确性。
RAG通过引入外部知识检索,RAG能够:
-
补充领域知识和私有数据
-
整合实时数据
-
减少生成的不确定性(缓解幻觉)
-
增强数据安全与可控性
-
无需重新训练模型,相比微调(Fine-tuning),RAG只需更新知识库,成本更低,效率更高
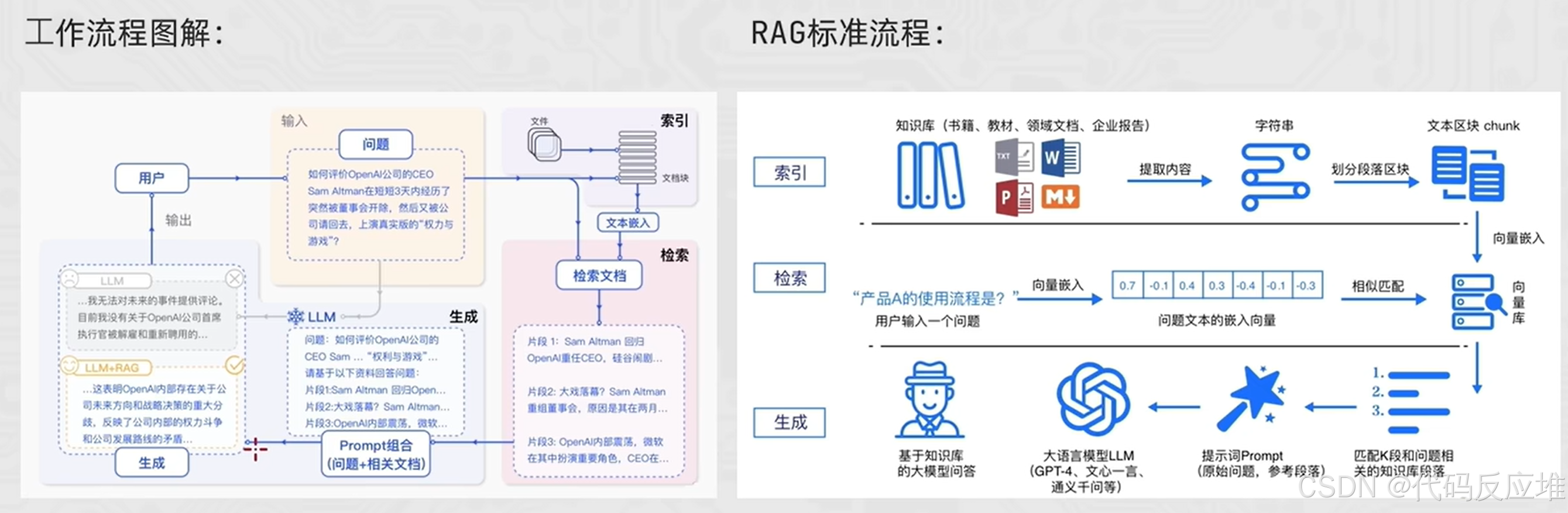
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
-
索引阶段
,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
- 加载文件
- 内容提取
- 文本分割,形成 chunk
- 文本向量化
- 存向量数据库
-
检索阶段
用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- query 向量化
- 在文本向量中匹配出与问句向量相似的 top_k 个
-
生成阶段
,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
- 匹配出的文本作为上下文和问题一起添加到 prompt 中
- 提交给 LLM 生成答案:
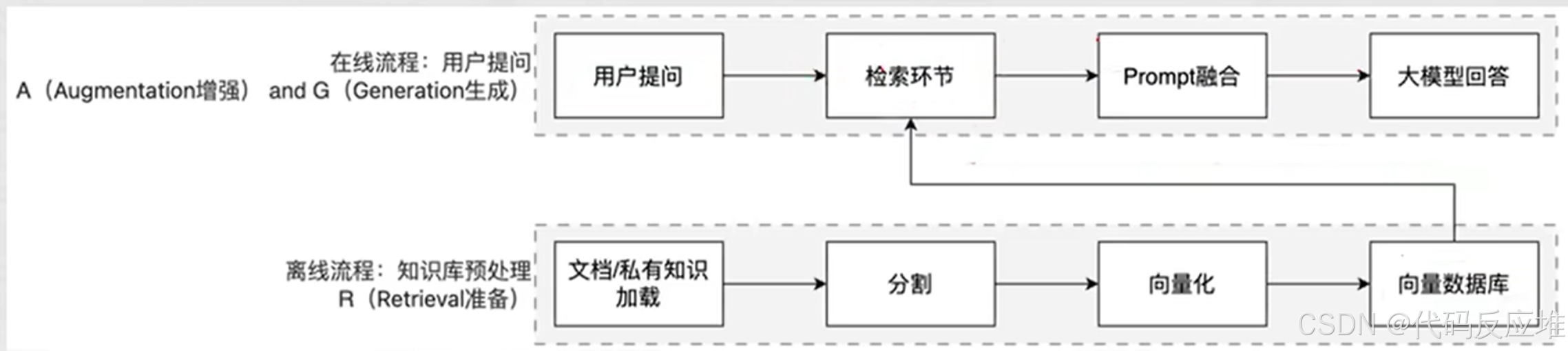
简单来说,RAG分两条线:离线流程、在线流程
基础调用阿里云通义千问大模型
1、介绍
LangChain模型组件集成了多种模型,并为所有模型提供统一的精简接口。目前支持以下三类模型:
- LLMs(大语言模型):技术范畴统称,基于大参数量、海量文本训练的Transformer架构模型。主要理解和生成自然语言。服务于文本生成场景。
- Chat Models(聊天模型):专为对话场景优化的LLMs。模拟人类对话的轮次交互。主要服务于聊天场景。
- Text Embeddings Models(文本嵌入模型):接收文本输入,输出文本的向量表示。
阿里云通义千问系列主要来源于langchain_community包。
- 常用大模型下载库:
- Hugging Face: https://huggingface.co/models
- ModelScope: https://modelscope.cn/models
2、调用LLMs示例
LangChain 调用阿里云通义千问示例
python
from langchain_community.llms.tongyi import Tongyi
# 实例化模型
llm = Tongyi(model='qwen-max')
# 模型推理
res = llm.invoke("帮我讲个笑话吧")
print(res)通过 langchain_ollama 包导入 OllamaLLM 类,即可调用本地已启动的 Ollama 模型。
(确保 Ollama 服务已启动。已提前通过 Ollama 下载好需要使用的模型。)
python
from langchain_ollama import OllamaLLM
# 实例化模型,指定模型名称(例如:"qwen3:4b")
model = OllamaLLM(model="qwen3:4b")
# 通过 invoke 方法调用模型
res = model.invoke(input="你是谁呀能做什么?")
print(res)3、调用聊天模型示例
在聊天模型中,消息通常分为以下三种类型,使用时需按约定传入对应的值:
| 消息类型 | 说明 | 对应 OpenAI 库中的角色 |
|---|---|---|
| AIMessage | AI 输出的消息,即模型对问题的回答或生成的响应。 | assistant 角色 |
| HumanMessage | 用户向模型发送的提示信息,例如问题、指令等。 | user 角色 |
| SystemMessage | 用于设定模型的上下文环境、角色或任务背景,如系统指令、角色扮演设定、输出格式要求等。 | system 角色 |
通义千问示例
python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 使用聊天模型
model = ChatTongyi(model="qwen3-max")
messages = [
SystemMessage(content="你是一个边塞诗人"),
HumanMessage(content="写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照你上一个回复的格式,在写一首唐诗")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="",flush=True)ollama本地调用示例
python
from langchain_community.chat_models.ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 使用聊天模型
model = ChatOllama(model="qwen3:4b")
messages = [
SystemMessage(content="你是一个边塞诗人"),
HumanMessage(content="写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照你上一个回复的格式,在写一首唐诗")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="",flush=True)4、调用文本嵌入模型
Embeddings Models 嵌入模型的特点:将字符串作为输入,返回一个浮点数的列表(向量)。
在 NLP 中,Embedding 的作用就是将数据进行文本向量化。
调用阿里
from langchain_community.embeddings import DashScopeEmbeddings
# 通过阿里的DashScopeEmbeddings默认使用text-embeddings-v1 文本嵌入模型
model = DashScopeEmbeddings()
# 文本向量化
print(model.embed_query("在哪里"))
# 批量文本向量化
print(model.embed_documents(["你好","吃什么饭"]))调用本地Ollama
from langchain_ollama import OllamaEmbeddings
# 通过阿里的DashScopeEmbeddings默认使用text-embeddings-v1 文本嵌入模型
model = OllamaEmbeddings(model="qwen3-embedding:0.6b")
# 文本向量化
print(model.embed_query("在哪里"))
# 批量文本向量化
print(model.embed_documents(["你好","吃什么饭"]))提示词prompt
1、zero-shot的提示词
提示词优化在模型应用中非常重要,LangChain提供了PromptTemplate类,用来协助优化提示词。
PromptTemplate 表示提示词模板,可以构建一个自定义的基础提示词模板,支持变量的注入,最终生成所需的提示词。
python
from langchain_community.llms.tongyi import Tongyi
from langchain_core.prompts import PromptTemplate
# 没有任何提示,即zero-shot思想
prompt_template = PromptTemplate.from_template(
"我到邻居姓{lastname},刚生了{gender},你帮我起个名字"
)
# 因为Tongyi属于llms包下的需要使用大语言模型,不能用其他类型模型如聊天模型qwen3-max
model = Tongyi(model="qwen-max")
# 填充提示词模板,像LLM模型提问
# template_format = prompt_template.format(lastname="张", gender="女儿")
# res = model.invoke(input=template_format)
# print(res)
# 通过框架里的链式写法,(注意:字符串无法加入链式写法)
chain = prompt_template | model
res = chain.invoke({"lastname": "张", "gender": "女儿"})
print(res)2、few-shot的提示词
FewShotPromptTemplate: 支持基于模板注入任意数量的示例信息。
python
from langchain_community.llms.tongyi import Tongyi
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
# 示例的模板
example_template = PromptTemplate.from_template("单词: {word},反义词: {antonym}")
# 示例的动态数据注入,要求是list内部套字典
examples_data = [
{"word": "大", "antonym": "小"},
{"word": "上", "antonym": "下"}
]
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template, # 示例数据的模板
examples=examples_data, # 示例的数据(用来注入动态数据的),list内套字典
prefix="告知我单词的反义词,我提供如下的示例:", # 示例之前的提示词
suffix="基于前面的示例告知我,{input_word}的反义词是?", # 示例之后的提示词
input_variables=['input_word'] # 声明在前缀或后缀中所需注入的变量名
)
# 生成最终提示词
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string()
print(prompt_text)
tongyi = Tongyi(model="qwen-max")
print(tongyi.invoke(input(prompt_text)))3、历史会话的提示词
ChatPromptTemplate: 支持注入任意数量的历史会话信息。
python
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 获取历史提示词
history_chat = [
("human", "请来一首唐诗"),
("ai", "白日依山尽,黄河入海流。欲穷千里目,更上一层楼。"),
("human", "请再来一首唐诗"),
("ai", "锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
]
chat_message = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人,可以作诗"),
MessagesPlaceholder("history_chat"),
("human", "请再来一首唐诗"),
]
)
prompt_txt = chat_message.invoke({"history_chat": history_chat}).to_string()
# 提问AI
tongyi = ChatTongyi(model="qwen3-max")
res = tongyi.invoke(prompt_txt)
print(res.content)Chain链式调用
「将组件串联,上一个组件的输出作为下一个组件的输入」是 LangChain 链(尤其是 | 管道链)的核心工作原理,这也是链式调用的核心价值:实现数据的自动化流转与组件的协同工作,如下。
chain = prompt_template | model
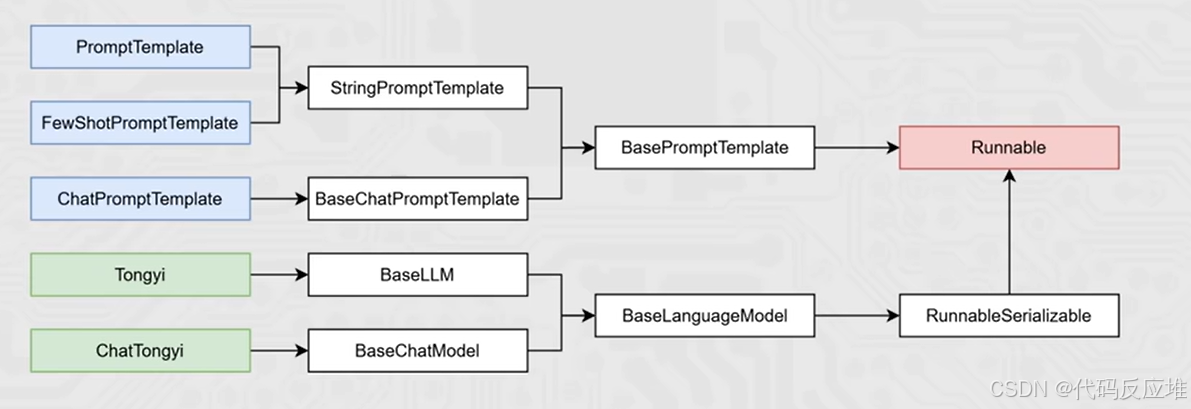
核心前提:即Runnable子类对象才能入链(以及Callable、Mapping接口子类对象也可加入(后续了解用的不多))。我们目前所学习到的组件,均是Runnable接口的子类,如下类的继承关系:
python
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableSerializable
chat_prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个边塞诗人,可以作诗。"),
MessagesPlaceholder("history"),
("human", "请再来一首唐诗"),
])
history_data = [
("human", "你来写一个唐诗"),
("ai", "床前明月光,疑是地上霜。举头望明月,低头思故乡"),
("human", "好诗再来一个"),
("ai", "锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦")
]
model = ChatTongyi(model="qwen3-max")
# 组成链,要求每一个组件都是Runnable接口的子类
chain: RunnableSerializable = chat_prompt_template | model
# 通过链去调用invoke或stream
# res = chain.invoke({"history": history_data})
# print(res.content)
for chunk in chain.stream({"history": history_data}):
print(chunk.content,end="",flush= True)- 通过 | 链接提示词模板对象和模型对象
- 返回值 chain 对象是 RunnableSerializable对象
- 是 Runnable接口的直接子类
- 也是绝大多数组件的父类
- 通过 invoke或stream进行阻塞执行或流式执行
组成的链在执行上有 | 上一个组件的输出作为下一个组件的输入的特性。
所以有如下执行流程:
