当数据集膨胀到数百万甚至数十亿量级的向量时,怎么让搜索在这种规模下依然又快又准就成了一个实实在在的工程难题。这篇文章要聊的就是向量搜索系统的三个核心优化方向------性能调优、混合搜索和可扩展架构。
传统搜索的问题
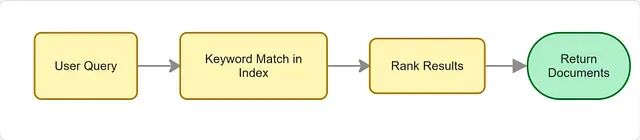
传统搜索系统做的事情本质上是词法匹配:找文档里有没有出现查询中的关键词。至于查询背后的意思?它不管。同义词、上下文、用户意图、概念层面的相似性,统统不在考虑范围内。
比如说用户查询
cheap car,文档里写的是
affordable vehicle。意思完全一样,但传统搜索直接判定不匹配------因为没有一个词是相同的。
Elasticsearch 这类系统引入了 BM25 排序算法,根据词频和重要性给文档打分。但再怎么优化打分策略,底层逻辑还是关键词重叠。换个说法表达同一个意思,排名可能就掉下去了。传统词法搜索在同义词、改述、深层语义理解面前,始终力不从心。
用一段 Python 代码直观感受一下传统关键词匹配的局限:
documents = [
"Affordable vehicle for students",
"Best gaming laptop",
"Budget friendly smartphone"
]
def traditional_search(query, docs):
results = []
query_words = query.lower().split()
for doc in docs:
doc_lower = doc.lower()
if all(word in doc_lower for word in query_words):
results.append(doc)
return results
# Query
query = "cheap car"
print(traditional_search(query, documents))输出:
[]空的。"Affordable vehicle" 和 "cheap car" 语义上几乎等价,但关键词匹配毫无办法。要解决这个问题就得换一种思路------向量搜索。
什么是向量搜索
不再比较字面上的词而是比较含义。把文档和查询都转换成数值向量(Embedding),这些向量编码了语义信息。即使两段文本用词完全不同,只要意思相近,它们的向量在空间中就会彼此靠近。
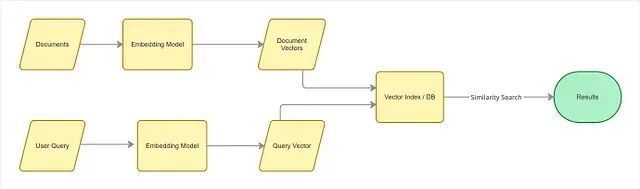
整个流程拆开来看分四步。
第一步是文档处理,属于离线的索引阶段。所有文档经过一个 Embedding 模型,转换为向量表示,然后存入向量索引或向量数据库。
第二步是查询处理,在线阶段。用户提交查询后,同一个 Embedding 模型把查询也转成向量,发送给向量索引。
第三步是相似性搜索。在向量索引内部,系统拿查询向量和所有文档向量做比较,用余弦相似度之类的距离度量找出最接近的那些向量。
第四步是返回结果。距离最近的文档就是语义上最相关的结果,哪怕它们和查询没有任何共同关键词。
下面动手搭一个小型语义搜索引擎,看看向量搜索在实践中是什么样的。
步骤1:将文本转换为 Embedding
用 Sentence Transformers 的
all-MiniLM-L6-v2模型:
from sentence_transformers import SentenceTransformer
documents = [
"Affordable vehicle for students",
"Best gaming laptop",
"Budget friendly smartphone"
]
model = SentenceTransformer("all-MiniLM-L6-v2")
doc_embeddings = model.encode(documents)
print(doc_embeddings.shape)输出:
(3, 384)每个句子变成了一个 384 维的向量。
步骤2:引入相似性概念
similarities = model.similarity(doc_embeddings, doc_embeddings)
print(similarities)输出:
tensor([[1.0000, 0.1679, 0.3233],
[0.1679, 1.0000, 0.2726],
[0.3233, 0.2726, 1.0000]])这是一个成对余弦相似度矩阵。单元格 (i, j) 表示句子 i 和句子 j 的语义相似程度。对角线上都是
1.0000,因为每个句子和自身当然完全相似。可以看到 "Affordable vehicle for students" 和 "Budget friendly smartphone" 之间的相似度(0.3233)比它和 "Best gaming laptop"(0.1679)更高,这符合直觉------前两者都带有"经济实惠"的语义。
步骤3:创建 FAISS 索引
import faiss
import numpy as np
doc_embeddings = np.array(doc_embeddings).astype("float32")
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings)FAISS 索引在高维空间里做 K 近邻搜索,用 L2 距离作为度量,能快速找到和查询向量最接近的 top-k 个 Embedding。
步骤4:搜索查询
文档 Embedding 已经入库,现在可以做语义搜索了。
query = "cheap car"
query_embedding = model.encode([query]).astype("float32")
distances, indices = index.search(query_embedding, k=1)
print(documents[indices[0][0]])输出:
Affordable vehicle for students查询被编码为 384 维向量,FAISS 计算它和每个文档向量的 L2 距离,返回距离最小的那个。"cheap car" 成功匹配到了 "Affordable vehicle for students",这里关键词没有任何重叠,但语义搜索抓住了含义。
这个小演示只处理三条文档,跑起来毫无压力。但现实场景动辄百万、十亿级别的 Embedding,
IndexFlatL2这种暴力全量比较的方式就扛不住了。搜索延迟飙升,内存吃紧,扩展性成问题。接下来要聊的就是怎么优化。
性能调优
IndexFlatL2对每个查询都遍历全部向量做比较。数据量小的时候没问题,数据量一上去就是灾难。性能调优围绕三件事展开:压缩搜索时间、降低内存消耗、同时尽量不牺牲检索精度。
精确搜索 vs 近似最近邻(ANN)
前面演示用的是:
faiss.IndexFlatL2(dimension)这是精确最近邻搜索,查询和每一个向量都比一遍。精度有保证,但面对百万级 Embedding 就跑不动了。
替代方案是近似最近邻(ANN)。ANN 放弃一点点精度换来数量级的速度提升,FAISS 里常用的 ANN 索引比如 IndexIVFFlat 和 IndexHNSWFlat,都是通过减少实际参与比较的向量数量来加速检索。
倒排文件索引(IVF)
IVF 的思路是把向量先聚类,查询时只在最相关的几个聚类里搜索,而不是扫描全部数据。对大数据集来说,延迟直接降一个量级。
quantizer=faiss.IndexFlatL2(dimension)
index=faiss.IndexIVFFlat(quantizer, dimension, nlist=100)
nlist是聚类数量。聚类越多,精度越高,但计算开销也越大。这里面有个平衡点需要根据实际场景调。
HNSW(基于图的搜索)
HNSW(Hierarchical Navigable Small World)是另外一个方向:不做聚类而是构建一个图结构。每个向量和它最近的邻居相连,搜索时沿着图的边进行导航。搜索速度快,召回率高,可扩展性也不错,是现代向量数据库中非常主流的索引方式。
向量压缩(Product Quantization)
数据量大了之后光是把向量存在内存里就是个问题,Product Quantization 对向量做有损压缩,减小内存占用的同时还能加速搜索。百万、十亿级 Embedding 的场景下,这个技术基本是标配。
硬件加速(GPU 支持)
FAISS 支持 GPU 加速,把向量计算并行化之后延迟大幅降低,适合对实时性要求高的场景,比如推荐系统和大型搜索平台。
混合搜索
实际的搜索系统很少只用关键词匹配或者只用向量相似性,更常见的做法是两者结合。
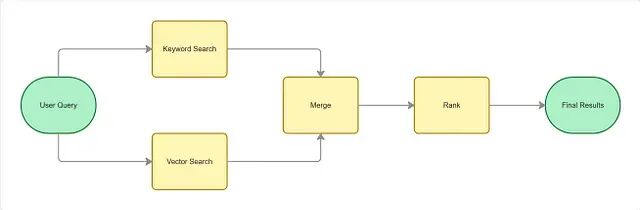
用户查询进来后,关键词搜索和向量搜索并行执行。关键词搜索产出一个词法相关性分数(比如 BM25),向量搜索产出一个语义相似度分数(比如余弦相似度),两路分数再融合成一个统一的排名分数。
评分公式(分数融合)
常见的加权融合公式长这样:
FinalScore(d)=α⋅KeywordScore(d)+(1−α)⋅VectorScore(d)
# 其中,
d = document
𝛼 ∈ [0,1] 控制关键词精确度的重要性这个分数不代表"正确性",只是用来给文档排序。系统按
FinalScore从高到低排列,排在前面的就是最终结果。
混合搜索伪代码
# Step 1: Keyword Search
keyword_results = bm25.search(query)
# Step 2: Vector Search
query_embedding = embed(query)
vector_results = vector_db.search(query_embedding)
# Step 3: Merge + Weighted Ranking
def merge_and_rank(keyword_results, vector_results, alpha=0.6):
keyword_dict = {doc.id: doc.score for doc in keyword_results}
vector_dict = {doc.id: doc.score for doc in vector_results}
all_doc_ids = set(keyword_dict.keys()) | set(vector_dict.keys())
# Normalize scores (important in real systems)
def normalize(scores):
if not scores:
return {}
min_s = min(scores.values())
max_s = max(scores.values())
return {
doc: (score - min_s) / (max_s - min_s + 1e-9)
for doc, score in scores.items()
}
keyword_dict = normalize(keyword_dict)
vector_dict = normalize(vector_dict)
final_scores = {}
for doc_id in all_doc_ids:
kw_score = keyword_dict.get(doc_id, 0)
vec_score = vector_dict.get(doc_id, 0)
final_scores[doc_id] = (
alpha * kw_score +
(1 - alpha) * vec_score
)
ranked_docs = sorted(
final_scores.items(),
key=lambda x: x[1]S,
reverse=True
)
return ranked_docs
final_results = merge_and_rank(
keyword_results,
vector_results,
alpha=0.6
)
return final_results这里有个细节值得注意:归一化。BM25 的分数是无界的,余弦相似度则在 -1 到 1 之间。不做归一化直接加权,某一路的分数可能把另一路完全压过去,排名就失真了。所以实际系统在融合之前一定要先归一化。
扩展向量搜索
小数据集上向量搜索跑得很漂亮。但从几千个向量涨到几百万、几十亿的时候,单机就扛不住了。生产环境下的扩展策略主要三个:Sharding、分布式搜索、缓存。
Sharding(水平扩展)
Sharding 就是把向量分散存储到多台机器上。比如 3000 万个向量,机器 1 存前 1000 万,机器 2 存中间 1000 万,机器 3 存最后 1000 万。
查询来了之后,系统先生成查询 Embedding,然后把它发给所有分片。每个分片各自返回 top-K 结果,最后汇总在一起重新排名。想加容量?加机器就行,这就是水平扩展的好处。
分布式搜索(并行查询处理)
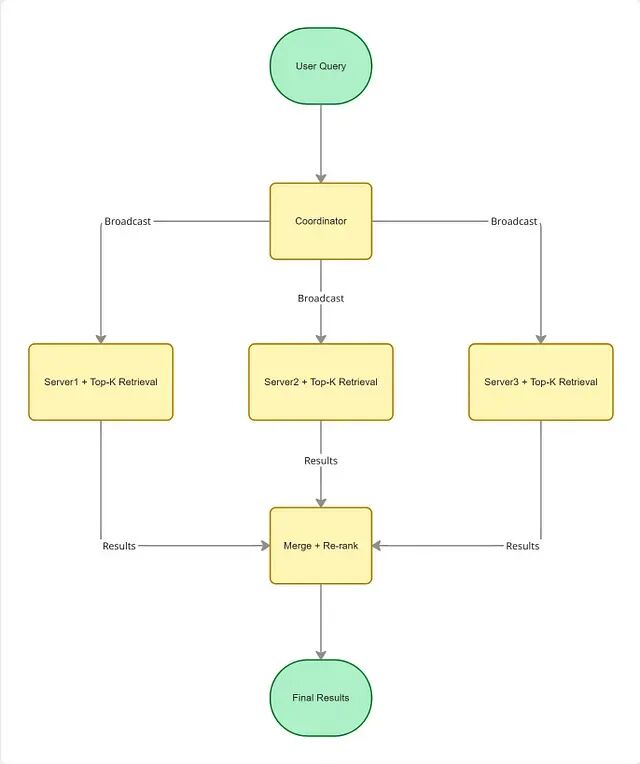
一台服务器扫 1 亿个向量太慢,那就拆成 10 台,每台扫 1000 万,并行跑。工作量分摊了,搜索同步进行,结果最终在协调器节点汇合。这是分布式搜索引擎和现代向量数据库的标准架构。
缓存(速度优化)
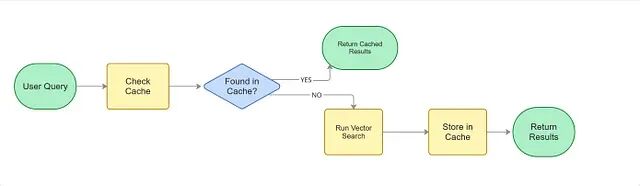
逻辑很简单:
If we have already answered this question before, don't compute again.没有缓存的情况下,每次查询都要走完整流程------生成 Embedding、发请求到所有分片、算相似度、合并结果、返回 top-K。哪怕5秒前刚有人搜过一模一样的东西,全套流程照跑一遍。这就是纯粹的浪费。
有了缓存就不一样了。热门查询再来的时候系统先查缓存:
Have we seen this query before?命中的话直接返回存好的结果,Embedding 生成和分布式搜索全部跳过。
想想 "iPhone 15 price" 或 "Weather today" 这种查询,每天成千上万人在搜。算一次就够了,后面全部复用。缓存同时砍掉了延迟和基础设施成本。
总结
向量搜索把信息检索从字面匹配带进了语义理解的时代。但光有 Embedding 还不够,真正让系统在生产环境中跑起来的是背后的工程优化------混合搜索把词法和语义两条路打通,ANN 和压缩技术解决性能瓶颈,分布式架构和缓存撑起大规模部署。
本文代码:
https://avoid.overfit.cn/post/f8461443473745e6bd7ea21a5b43f44c
by Pawan