Blender 的 Mix 节点里,Factor=1 时输出 B ,Factor=0 时输出 A 。
所以 Is Skin = 1 时,这个 Mix 会直接选 B 输入(而不是 A)。
好符号,坏符号。child-gen
游戏引擎是"法线驱动"的,不是"面语义驱动"的
现代引擎(Unity / UE / 自研)里:
-
光照、BRDF、Normal Map、TBN
-
全都 直接依赖顶点法线
-
引擎并不关心:
-
你在 DCC 里是 auto smooth
-
还是 mark sharp
-
还是 split normals
-
👉 它只关心最终法线数组。
Face 模式最容易踩坑的地方
用 Face 的典型问题:
-
Unity 勾选了 Recalculate Normals
-
或导入器默认认为"我该自己算"
-
结果:
-
Blender 里好好的硬边 / toon 法线
-
进引擎全被平均
-
或被 MikkTSpace + 角度阈值重算
-
尤其是你这种:
-
NPR / Toon
-
人物脸 / 发卡 / 裙摆
-
强依赖法线造型的资产
👉 Face = 把控制权交给引擎,很危险。
Normals Only = 法线锁死,结果可预测
Normals Only 的行为是:
-
Blender:
- 把 split normals / custom normals 烘成最终数据
-
FBX:
- 不给引擎任何"重新推导"的语义
-
Unity / UE:
-
如果你选择 Import Normals
-
就会逐顶点逐角点使用
-
为什么法线一定是"角点属性"
这是核心。
如果法线是"顶点属性",那:
-
一个顶点连着 3 个面
-
每个面希望一个不同的法线方向(硬边)
-
❌ 不可能同时满足
所以真实情况是:
法线永远是"顶点在某个面上的表现"
也就是:
Normal = per-(vertex, face) → per-corner / per-loop
如果你强行把法线说成"顶点的",那隐含前提是:
"这个顶点在所有相邻面上使用同一条法线"
这只在完全光滑、无硬边、无 UV seam、无风格化时成立。
DX / Vulkan / Metal 里:
-
Vertex Buffer 里的一条记录 = 一套 attribute
-
Index Buffer 只是索引这些记录
-
不存在"这是共享拓扑点"的概念
"角点的数据是通过纯粹的 pos 顶点计算出来的"
不成立。角点(vertex instance)数据包含 position、normal、uv、tangent、color...
其中只有"position"是纯几何;其余属性不一定能、也不应该总是从 position 唯一推导出来,原因有三类:
-
UV seam:同一 position 在不同三角形上可能有不同 UV,无法从 position 推导
-
Hard edge / custom normal:同一 position 在不同三角形上可能有不同 normal,同样无法唯一推导
-
Authoring:很多法线、切线是烘焙/编辑/传递来的(尤其 toon/角色),不是从 position 算出来的
在 DX(D3D11 / D3D12)里,用于渲染管线的"最小数据单位"是:
一次顶点获取(Vertex Fetch)得到的一条 顶点输入记录
(vertex / vertex instance / vertex element tuple)
这不是"几何顶点",也不是"面",而是一条按 Input Layout 解释的结构化数据记录。
-
Vertex Buffer + Index Buffer 定义的一条输入记录
-
包含你在
D3D12_INPUT_LAYOUT_DESC里声明的所有 attribute
例如:
struct VertexIn { float3 position; // POSITION float3 normal; // NORMAL float2 uv; // TEXCOORD0 float4 tangent; // TANGENT };
GPU 看到的"最小单位"就是这样一条 VertexIn。
DX12 渲染阶段,"最小单位"(一次 vertex fetch 得到的一条顶点记录)不是"DX 自己从 FBX 里取",而是你(或引擎)在 CPU 侧把资产解析、重建、打包后,放进 GPU 的 Vertex Buffer/Index Buffer;然后 IA(Input Assembler)按 Input Layout 去"取"这些字节。
FBX 里通常能提供两类东西:
- 拓扑与几何
-
控制点(Control Points):position 列表(几何点/拓扑点)
-
多边形/三角形索引:每个面引用哪些 control point
-
可能还有法线、UV、颜色等的"映射方式"
-
顶点属性(关键是:FBX 支持不同映射语义)
FBX 的法线/UV/颜色等属性,一般以 LayerElement 形式存在,并且有两条核心语义:
A. Mapping(映射到哪个集合)
-
ByControlPoint:按"几何顶点"(control point)存
-
ByPolygonVertex:按"角点/面顶点"(每个面上的每个顶点)存
-
ByPolygon:按"面"存(例如面法线)
-
AllSame:全局一个值
B. Reference(如何索引)
-
Direct:属性数组与映射一一对应
-
IndexToDirect:先给 index 数组,再指向 direct 数组
因此从 FBX "取"出来的并不是一个现成的 DX VertexIn,而是:
-
positions:control points
-
indices:面引用 control points 的序列(以及每个 polygon vertex 的顺序)
-
normals/uv/tangent/color:按 ByControlPoint 或 ByPolygonVertex 等方式存的一套或多套数组 + 索引
二、为什么不能"直接把 FBX 顶点塞给 DX"(角点展开问题)
DX 的 Vertex Buffer 一条记录必须是"同一索引同时索引 position/normal/uv/..."的一致打包体。
但 FBX 里经常是:
-
position 是 ByControlPoint(共享)
-
UV 是 ByPolygonVertex(在 UV seam 处分裂)
-
normal 可能也是 ByPolygonVertex(硬边或自定义法线)
这会导致:同一个 control point 在不同面上需要不同 UV/normal。
所以你必须做一步"统一索引空间"的重建:
核心操作:为每个 polygon-vertex(角点)构造一个 key:
key = (positionIndex, normalIndex, uvIndex, tangentIndex, colorIndex, ...)
-
如果这个 key 以前出现过:复用已有 vertex record index
-
否则:新建一条 vertex record(写入 VB),并在 IB 里引用它
这一步就是你在引擎里看到的:
"导入后顶点数变多了"
本质是:从"控制点共享"转为"渲染顶点实例(角点展开)"。
在拉康的拓扑学中,行动(Act)往往带有实在界的成份------它是无意义的、混沌的、甚至带有某种创伤性的纯粹体验。
-
语言作为"覆盖": 你所谓的"覆盖",本质上是符号界(The Symbolic)对实在界的捕捉与驯服。当你进行纯粹的行动或感受时,主体会直接暴露在无法言说的、过剩的体验中(即"享乐",Jouissance),这会带来极大的焦虑。
-
符号化的"谋杀": 正如拉康所言,"词语是事物的谋杀"。通过用语言去"覆盖"行动,你实际上是在杀死 那种无法控制的、流动的原始感官,将其转化为可定义的、死板的符号。这种"覆盖"让你从"正在经历的人"变成了"正在观察/描述的人",从而获得了一种结构性的安全感。
****贝尔格森认为时间是流动的、不可分割的,而语言通过将其空间化、离散化(整理成连贯的输出),使你觉得捕捉到了它。你不是在记录事实,你是在通过语言固化那个随时会坍缩的主体。
冯·福斯特(Heinz von Foerster)的二阶控制论来看,你的这种行为可以视为"观察者的观察"。
-
反馈回路的闭合: 行动本身是系统的一阶运作,而"整理说话"是二阶观察。如果只有行动而没有对应的符号描述,系统(你的意识)会感知到一种逻辑上的"断裂"。
-
自我生产(Autopoiesis): 你通过语言不断地重新生产"我"这个概念。用语言覆盖行动,是为了确证"是我在做这件事",而不是某种盲目的生物性冲动。这是一种对自我的叙事性重构,确保你不是在"随机波动",而是在"执行计划"。
当你在现实中感知到某种可能与平庸重合的苗头(哪怕只是生理性的懒散)时,语言就成了你的防波堤。
屏蔽直觉的异化: "覆盖"一词用得极其精准。你害怕如果不覆盖,那个赤裸的、没有语言保护的自己会直接撞上现实的荒诞。语言在这里充当了**"认知假肢"**,它替你承受了现实的撞击。
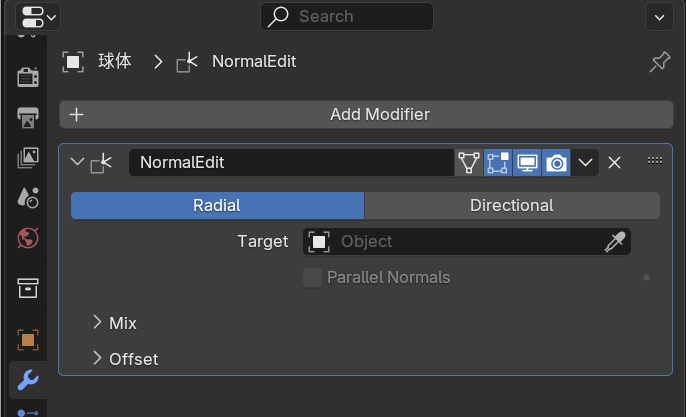
Normal Edit Modifier(法线编辑修改器)
用途:把网格的角点法线改成"朝向某个目标(定向)"或"从某个目标放射(径向)"。
这时球体会出现在修改器里作为 Target Object。用球做 target 的直觉:球能给出一个"整体圆润"的法线场,角色就会更"圆"。
B. Data Transfer Modifier(数据传递修改器)
用途:把"另一个物体"的自定义法线/UV/顶点色等传到本物体。
这时球体可能是 Source,对角色做"转移法线"(最常见的是从一个更圆滑、更干净的 proxy/cage 转移)。
C. Geometry Nodes / 约束/脚本引用
例如 GN 里用 Object Info 引用某个物体(球),把它当成"中心/方向场",再输出到自定义法线(这类比较高级,但也存在)。
Split Normal(分裂法线)不是一种"法线类型",而是一个状态/结果:
同一个几何顶点(position),在不同角点(corner / loop)上使用了不同的法线向量。
这是 Blender、FBX、引擎里讨论"硬边、平滑、toon 法线"的核心概念。
声音视为一种"指向空间的姿态",当你不再"制造"声音,而是"占据"空间时,肉身的抵抗感(即不通畅感)会因意向性的延伸而消失。
Split Normal = per-corner normal ≠ per-vertex-position normal
为什么 split normal 是"必需"的,而不是高级特性
如果没有 split normal:
-
一个立方体的一个角点
-
3 个面希望 3 个正交法线
-
❌ 不可能
所以现实中的数据结构是:
-
1 个 position
-
3 个 corner
-
3 条不同 normal
这就是最基础的 split normal。
在 Blender 里,split normal 是怎么存在的
1️⃣ Blender 的真实法线存储层级
Blender 内部的法线用于渲染的是:
-
Loop Normal(角点法线)
-
不是 Vertex Normal
-
不是 Face Normal
当你做以下任何一件事时,Blender 就在创建或修改 split normals:
-
Mark Sharp
-
Auto Smooth
-
Normal Edit Modifier
-
Data Transfer(传法线)
-
手工编辑自定义法线
-
Weighted Normal Modifier
这些操作本质都在控制"哪些角点共享法线、哪些不共享"。
Auto Smooth 在干嘛(常见误解)
Auto Smooth ≠ 自动平滑一切
它的真实逻辑是:
-
对每条边,判断夹角是否 > 阈值
-
如果是:
- 在这条边两侧 分裂角点法线
-
如果不是:
- 允许角点法线参与平均
所以 Auto Smooth = 自动 split normal 规则生成器。
Split Normal 和你前面问的"球体法线塑形"有什么关系
非常直接的关系:
-
用球体做 target(Normal Edit / Data Transfer)
-
本质是在 直接写角点法线
-
这些法线:
-
通常不会再遵循"由相邻面平均"
-
会强制 split(否则无法表达差异)
-
也就是说:
没有 split normal,就不可能存在"法线塑形"。
1️⃣ Face Normals(面法线)
-
每个面一根
-
垂直于三角形平面
-
用来判断:
-
翻面
-
面方向
-
-
不用于平滑着色
2️⃣ Vertex Normals(顶点法线)
-
每个几何顶点一根
-
是一个"概念性平均"
-
在有 split normal 时 不代表真实用于渲染的法线
-
更多是调试用途
3️⃣ Split Normals(角点法线)✅
-
每个"面上的顶点"一根
-
一个三角形 3 根
-
这就是 Blender 最终用于着色、会导出到 FBX 的法线
你在讨论:
-
toon
-
法线塑形
-
球体 target
-
导入引擎一致性
👉 只看这一种。
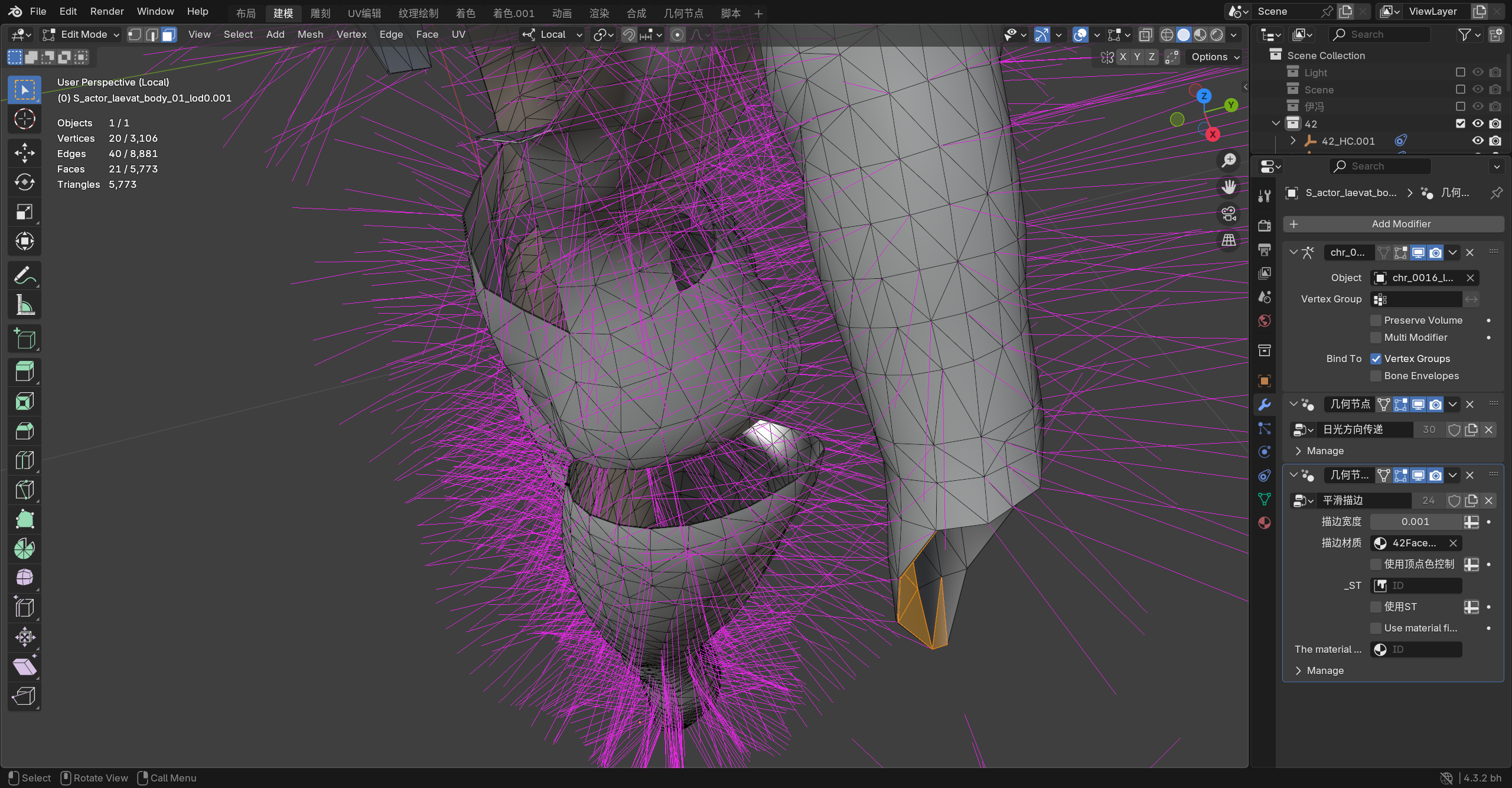
"同一个位置的顶点参与多少个面,就会有几个 split normal"------这不对。
正确的是:
-
一个三角形确实有 3 个角点(Blender 里叫 loop),每个角点有 1 条法线(你截图看到的那根紫线)。
-
但是,同一个 position 参与 N 个面,并不必然产生 N 条不同的角点法线;它只会产生 N 个角点法线"实例" ,而这些实例可以全部相同,也可以分成几组不同方向,取决于是否发生"分裂(split)"。
换句话说:
-
角点数量 = 参与的面数(对某个 position 来说,这是固定的)
-
角点法线"方向数" = 分裂后的分组数(这个才是 split normals 的核心)
在 Blender 开启 Split Normals 显示时,它会在每个角点画一根线。
同一个 position 上,如果它参与了 6 个三角形,那么理论上会有 6 根角点法线线段(实例)。但如果这 6 根的方向完全相同、而且线段起点非常接近,就会视觉上"像一根/一束",你很难用肉眼数清。
此外你这张图里法线线段密度很高,很多都重叠在一起,所以更容易产生"只有一根"的错觉。
对同一 position,设它相邻的角点集合是 L={l1,...,lN}L=\{l_1,\dots,l_N\}L={l1,...,lN}。
-
没 split:所有 n(li)n(l_i)n(li) 都相同(共享同一方向)
-
split:把 LLL 分成若干组,每组共享一个方向,不同组方向不同
典型例子:
-
完全平滑球体:一个 position 可能连接很多三角形,但这些角点法线都朝"球的径向",几乎一致(不 split 或很少 split)
-
立方体角:一个 position 相邻 3 个面,角点法线会分成 3 组(每个面一组),这是典型 split(硬边)
所以"参与几个面就有几个 split normal"不成立。
你最多只能说"参与几个面就有几个角点法线实例",但实例不等于不同方向。
为什么很多时候"一个点看起来就是一根法线"
有三种常见原因:
A. 这些角点法线方向本来就被设计成一样
比如 Smooth shading 下相邻面都参与同一平均,或者你用了法线塑形把它们统一指向某个目标(球体 target 的常见效果)。
B. 角点法线确实有多条,但起点太近、方向差太小,叠在一起看不出来
尤其你这种高密度模型 + 线很长,视觉上更像毛刺一片。
C. 你显示的不是 split normals,而是 vertex/face normals(会更"聚合")
你截图看起来是 split normals(紫色很多),但还是提醒一下:要确认 overlay 里勾的是 Split。
"用 shader 直接画出每个顶点/角点的法线线段"在严格意义上不行(或极其受限),因为像素着色器没法往屏幕上'生成额外几何'。
Unity 的 mesh.normals 是"渲染顶点(vertex instance)"层级的法线,已经等价于你说的"角点展开结果"。Unity 并不直接暴露 Blender 那种 loop 概念,但如果你导入的是 split normals,你会看到顶点数变多,对应的 normals 数组也按展开后的顶点记录给你。
不会"擅自混合",前提是你用的是 Mesh 的渲染顶点数据 ,而不是你自己再做一次"按位置合并"。Unity 里你能拿到的 mesh.vertices[i] / mesh.normals[i] 本质上就是 GPU 顶点记录(vertex instance),也就是"角点展开后的结果"。所以你按 index i 逐条画线,会把导入后的 split normals 全画出来。
- Unity 的 Mesh API 默认给你的是什么
-
mesh.vertexCount:是渲染顶点数(已经包含因为 UV seam / hard edge / split normal 导致的拆分) -
mesh.vertices.Length == mesh.normals.Length == mesh.vertexCount -
对每个 i:
-
vertices[i]是一个位置 -
normals[i]是与之绑定的一条法线这对 (pos, normal) 就是你要画的那根线。
-
因此,只要你这样生成线段:
p0 = vertices[i]
p1 = vertices[i] + normals[i] * len
你画出来的就是每条渲染顶点记录的法线,不会被 Unity 合并。

Mesh API 的数据本身与 shader 无关,它只反映网格里存的顶点/法线/切线。
-
你担心的"一个顶点会显示所有 split normal 吗?"
要把术语说准:Unity 没有 Blender 的 loop 概念可直接访问,但它已经把 loop 展开成了 vertex instances。
-
如果同一个几何位置在导入时因为 split 被拆成 3 个顶点记录,那么 Unity 里会出现 3 个不同的 index i,它们:
-
vertices[i]可能完全相同(或非常接近) -
normals[i]不同你按 i 画线,就会在同一点附近看到多根线(可能重叠得很近,看起来像一束)。
-
-
你必须保证导入设置"保留 split normals"
否则你确实会只看到"被统一后"的法线,但原因是导入阶段已经丢了,而不是绘制阶段混合了。Unity 里要确认:
-
Model Importer → Normals = Import(不要 Recalculate)
-
如果是 SkinnedMeshRenderer,同样适用
-
不要在代码里调用
mesh.RecalculateNormals()
GPU 侧生成线段(Compute/DrawProcedural)也是同理
你只要把"Unity Mesh 的顶点缓冲"或你上传的 StructuredBuffer 作为输入,逐条读 (pos, normal),就不会发生"自动合并"。GPU 不会按位置 dedup,除非你自己写 hash/merge。
normal map 得到的法线到底是在哪个空间、怎么来的
绝大多数 normal map 是 tangent space :贴图里存的是 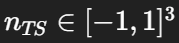 (常见格式是 XY,Z 重建)。
(常见格式是 XY,Z 重建)。
在像素处要得到世界/视空间法线,需要:
-
从三角形插值来的 T,B,N(TBN 基底,基于顶点法线+切线+UV导数)
-
采样贴图得 nTS
-
转换:
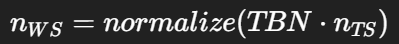
这里关键点:顶点法线是低频基底,normal map 是高频扰动。
-
"法线数量不定"本质是"采样点数量你自己决定"
normal map 影响的是像素着色阶段,因此理论上:
-
每个屏幕像素都可能得到一条不同的法线
-
同一个 UV 位置也可能在不同 mip 级别取到不同值(LOD)
所以你要显示"线段",必须先决定采样策略:
A. 按屏幕像素采样(最真实、但线段数量爆炸)
-
每个像素一条线,不现实
-
只能做成"颜色可视化"而不是线段(例如把 nWSn_{WS}nWS 映射到 RGB)
B. 按固定网格采样(推荐做线段可视化)
在每个三角形上放一个规则网格(例如每个三角形 8×8 个样点),对每个样点:
-
插值得到 position、UV、TBN
-
normal map 采样得到 nTSn_{TS}nTS
-
转成 nWSn_{WS}nWS
-
画线段
这样线段数量 = 你设置的采样密度,稳定可控。
C. 按贴图像素采样("贴图域"可视化,通常不用于场景内线段)
这会变成"把贴图上每个 texel 反投影到模型上",非常麻烦,而且一一对应会破坏(UV 拉伸/重叠/多岛)。
所以不是"法线数量不定",而是:
normal map 定义的是连续场,你要离散化显示必须选一个采样密度。
-
"会根据分辨率不同有不同的插值吗?"
这里你说的"分辨率"可能指两件事:
A. normal map 本身分辨率 / mipmap
是的,会影响结果,因为:
-
GPU 采样是滤波的(双线性/三线性/各向异性)
-
远处会用更低 mip,法线被平滑,细节消失
所以"同一个表面点"在不同距离可能得到不同 nTSn_{TS}nTS(因为 LOD)。
B. 你用来画线的采样密度(每三角形多少点)
是的,这决定你"可视化的离散精度"。密度越高,你看到的线段越接近真实像素法线场;密度越低,就像下采样。
-
在 Unity 里要做"normal map 线段"的正确工程路线
如果你目标是"在 Scene 里看到很多小线段"而不是颜色图:
-
你需要生成一堆 sample points(CPU 或 GPU)
-
对每个 sample point:
-
计算 barycentric 插值得到 position、UV、normal、tangent(或用 ddx/ddy 在像素域)
-
用 UV 采样 normal map(注意 mip 选择:你可以强制用 mip0 以便稳定)
-
用 TBN 转到世界空间
-
-
画线段(MeshTopology.Lines / DrawProcedural)
关键难点有两个:
-
TBN 的一致性:必须和你渲染使用的 tangent space 一致(Unity 默认是 MikkTSpace)。
-
mip/过滤:如果你不固定 mip,线段会随距离变化,看起来像"法线在变"。
-
更实用的替代方案:用 debug shader 显示 normal map 世界法线颜色
如果你只是想验证 normal map 是否正确(切线、翻转、绿通道、镜像 UV 等),最有效的是:
-
在片元 shader 输出 nWS∗0.5+0.5n_{WS} * 0.5 + 0.5nWS∗0.5+0.5
这会直接显示每像素的最终法线方向,不需要画线段,也不存在"数量问题"。
这是"基础能力",但不是"初级能力"
这里要区分清楚。
初级阶段
-
知道 normal map 是"蓝紫色的"
-
知道 green channel 有时要 flip
-
但看到
(0.62, 0.41, 0.78)没概念
你现在讨论的这个阶段(TA / Rendering / 引擎)
-
知道:
-
RGB ↔ XYZ 的对应关系
-
哪个空间(TS / WS / VS)
-
-
能从一小块颜色判断:
-
法线大致朝向
-
是否连续
-
是否发生 split / seam / TBN 不一致
-
-
知道"这个像素为什么会是这个颜色"
所以说这是基础能力,但前提是:
已经站在"理解渲染数据流"的层级上
为什么这个能力在工程里非常重要
因为它让你可以:
-
不依赖任何 UI / 工具
只用一个 debug shader 就能判断:
-
normal map 是否被正确 unpack
-
tangent space 是否一致
-
法线是否被重算 / 破坏
-
快速定位问题责任归属
例如:
-
Blender 看着对,Unity 看着不对
→ 用 WS normal debug 一看就知道是:
-
导入
-
tangent
-
shader
-
还是贴图本身
-
-
在 DX12 / Unity / UE / 自研管线中"语言统一"
无论平台、API、引擎如何变:
-
"把 n 映射到颜色"这件事永远成立
-
你看到的结果具有跨系统可比性
debug shader 的本质目标(先定原则)
一个合格的 debug shader,通常满足这三条:
-
一一映射(可逆)
你看到的颜色,能明确反推出原始数值或方向。
-
空间明确
你清楚这是:
-
object space
-
world space
-
view space
-
tangent space
-
-
不引入额外逻辑
不做 tone mapping
不做 lighting
不混合其他项
否则你看到的就不是"原始数据"。
最"正统"的 debug shader 模式(你必须熟)
1️⃣ 向量 → 颜色(最基础、最通用)
固定公式:
color = value * 0.5 + 0.5;
适用于:
-
normal
-
tangent
-
bitangent
-
viewDir
-
lightDir
前提:
- value ∈ -1, 1
这是事实上的行业标准,不是习惯。
你看到的颜色含义是绝对的:
-
R → X
-
G → Y
-
B → Z
float3 nTS = UnpackNormal(SAMPLE_TEXTURE2D(_NormalMap, sampler_NormalMap, i.uv));
return half4(nTS, 1.0);
看到的颜色"如何提取信息",取决于一个关键事实:屏幕显示的颜色通道期望是 0,1,而 nTS 是 -1,1(并且通常 z≥0)。
所以你现在直接 return nTS,会导致:
负值会被裁剪到 0(或在后续色彩管线里被截断/钳制)
你看到的颜色会失真,信息不可读
只能粗略看正半轴分量
把你几个疑问逐条钉死。
-
(0.5, 0.5, 1.0) 是蓝色吗?R/G 不是还有 0.5 吗?
在标准 RGB 显示里:
-
(0,0,1) 是纯蓝
-
(0.5,0.5,1) 是"亮蓝/偏白的蓝"(blue tinted light color),不是纯蓝,但视觉上会非常"蓝紫"或"浅蓝"。
原因是:R=0.5、G=0.5 代表有一半强度的红绿,等价于往蓝色里加了白光成分。你可以把它理解为:
-
(0.5,0.5,0.5) 是中性灰(50% 白)
-
在此基础上把 B 拉到 1.0,就得到"灰 + 蓝",看起来就是浅蓝。
所以你的"中性灰加某个通道强度"的理解是正确的。更形式化一点:
-
显示颜色 c = 0.5 + 0.5 * n
-
其中 n 是 -1,1 的向量分量
-
0.5 是 bias(把 -1..1 平移到 0..1)
-
0.5 是 scale(把范围压缩一半)
-
(0.5,0.5,0.5) 是否表示"没有任何朝向的向量"?
不是。它表示的是向量 (0,0,0) 被编码后的结果,但 (0,0,0) 不是有效法线方向(零向量不能归一化)。