文章目录
- [1. 一些关于 Jupter Notebook 的设置](#1. 一些关于 Jupter Notebook 的设置)
-
- [1.1 安装 Anaconda](#1.1 安装 Anaconda)
- [1.2 修改 Jupter Notebook 默认启动目录](#1.2 修改 Jupter Notebook 默认启动目录)
- [1.3 Jupter Notebook kernel 切换](#1.3 Jupter Notebook kernel 切换)
-
- [1.3.1 安装 ipykernel](#1.3.1 安装 ipykernel)
- [1.3.2 使用 ipykernel 将环境注册到 Jupter 中](#1.3.2 使用 ipykernel 将环境注册到 Jupter 中)
- [1.3.3 在 Jupyter 中 选择使用该环境](#1.3.3 在 Jupyter 中 选择使用该环境)
- [2. 准备工作](#2. 准备工作)
-
- [2.1 理论知识](#2.1 理论知识)
- [2.2 检查网页内容](#2.2 检查网页内容)
- [2.3 所需库](#2.3 所需库)
- [3. 代码实现](#3. 代码实现)
-
- [3.1 数据爬取(爬虫)](#3.1 数据爬取(爬虫))
-
- [3.1.1 爬取 URL](#3.1.1 爬取 URL)
- [3.1.2 爬取详细信息](#3.1.2 爬取详细信息)
- [3.1.3 整合数据](#3.1.3 整合数据)
- [3.2 数据分析](#3.2 数据分析)
-
- [3.2.1 假设1](#3.2.1 假设1)
- [3.2.2 假设2](#3.2.2 假设2)
- [3.2.3 假设3](#3.2.3 假设3)
- [3.2.4 总结](#3.2.4 总结)
- [4. 反思](#4. 反思)
1. 一些关于 Jupter Notebook 的设置
可以直接看这里的关于 Jupter Notebook 的教程Jupter Notebook 教程。
1.1 安装 Anaconda
Jupter Notebook 一般用 Anaconda 就可以方便使用和管理,我们安装 Anaconda 就可以使用 Jupter Notebook。当然我们也可以使用我们平时用的 Python ide 来进行爬虫。这里是因为作业要求所以我们使用 Jupter Notebook。
这里不在赘述如何安装 Anaconda,可以参考这篇文章:Anaconda安装 。
1.2 修改 Jupter Notebook 默认启动目录
这一点看自己是否需要,因为 Jupter默认启动目录是 C 盘,而且无法切换到更上一级目录,因此比如我们想访问的文件是在 D 盘,那么我们就无法从这里跳转到指定目录处。
因此如果比如你想把相关的文件放在 C 盘之外的盘你需要进行这一步操作,否则不需要修改。
我们先打开 Anaconda Prompt。
然后输入。
bash
jupyter notebook --generate-config
回车后起就会生成 Jupter Notebook 的配置文件。
像我这里由于已经有配置文件了,我回车后会选择是否覆盖,按 N 或 Enter 会保持原文件不变。按 Y 会用默认配置文件覆盖你的现有配置。
因此如果你的配置文件被你修改出了大问题,你可以通过这种方式生成一个新的从而忽略掉以前的问题。
这个文件的默认位置一般是C:\Users\你的用户名.jupyter\jupyter_notebook_config.py。
用记事本或 VS Code 打开该文件,搜索 c.ServerApp.root_dir,找到这一行。如果找不到可以尝试搜索 c.NotebookApp.notebook_dir 或者 c.ServerApp.notebook_dir,这些都是曾经使用的版本,甚至最原始的 c.NotebookApp.notebook_dir 依旧在我的文件上保留,后面的操作类似。
python
# c.ServerApp.root_dir = ''将其改为
python
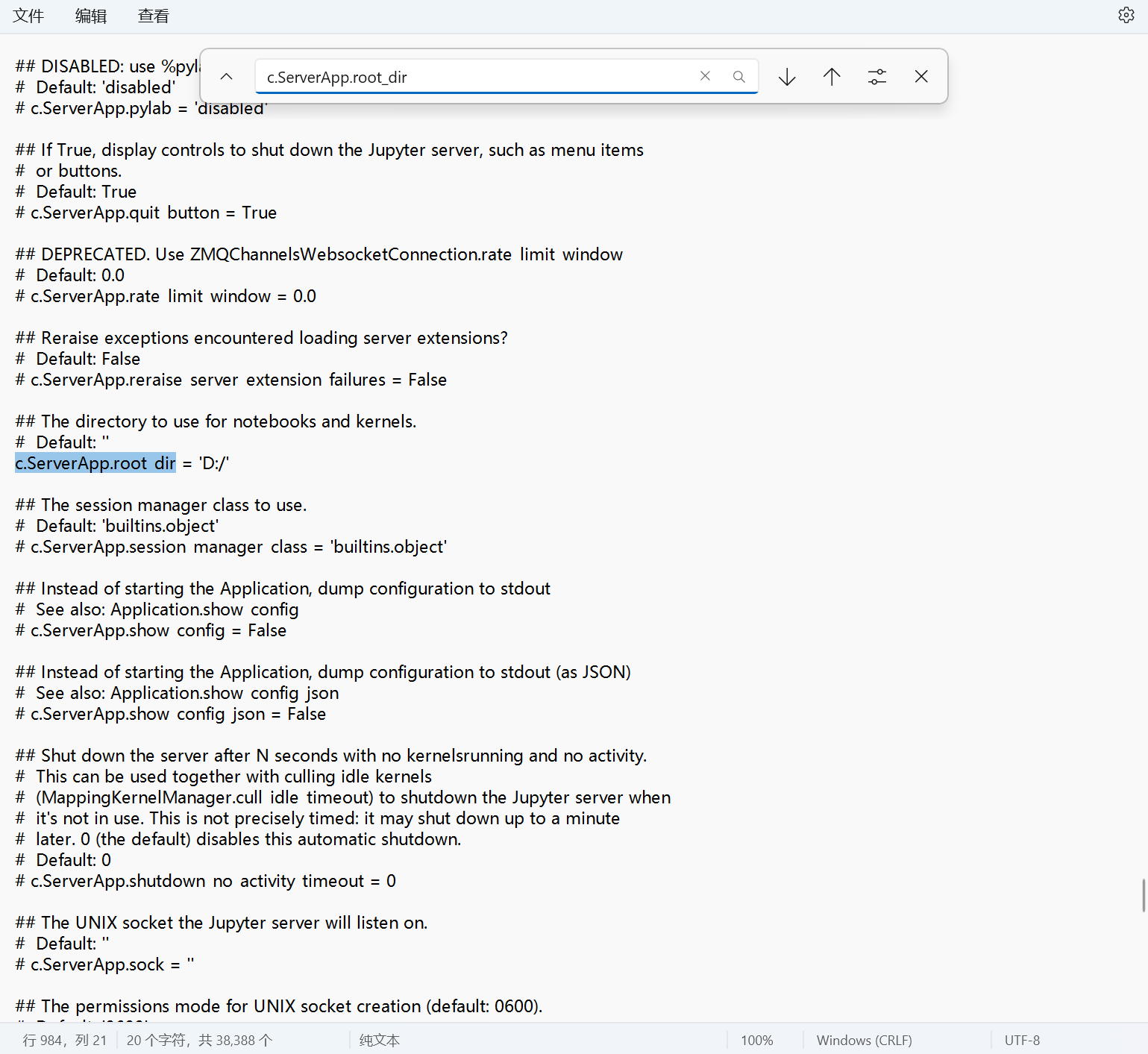
c.ServerApp.root_dir = 'D:/'注意去掉前面的 # ,因为这个文件是 python 文件,所以如果加上注释,那么其就无法被运行。然后后面加上想要设置的启动目录,这里我想以 D 盘为启动目录,因此是这样,可以按照自己的需求改成其他盘或者 D 盘下指定的文件夹, 这里给出一个参考。
python
c.ServerApp.root_dir = 'D:/jupyter'下图给出了参考。
因为其是 python 文件,所以其当然可以使用任何 ide 打开,这样可能更方便操作,下图给出 VS Code的示例。
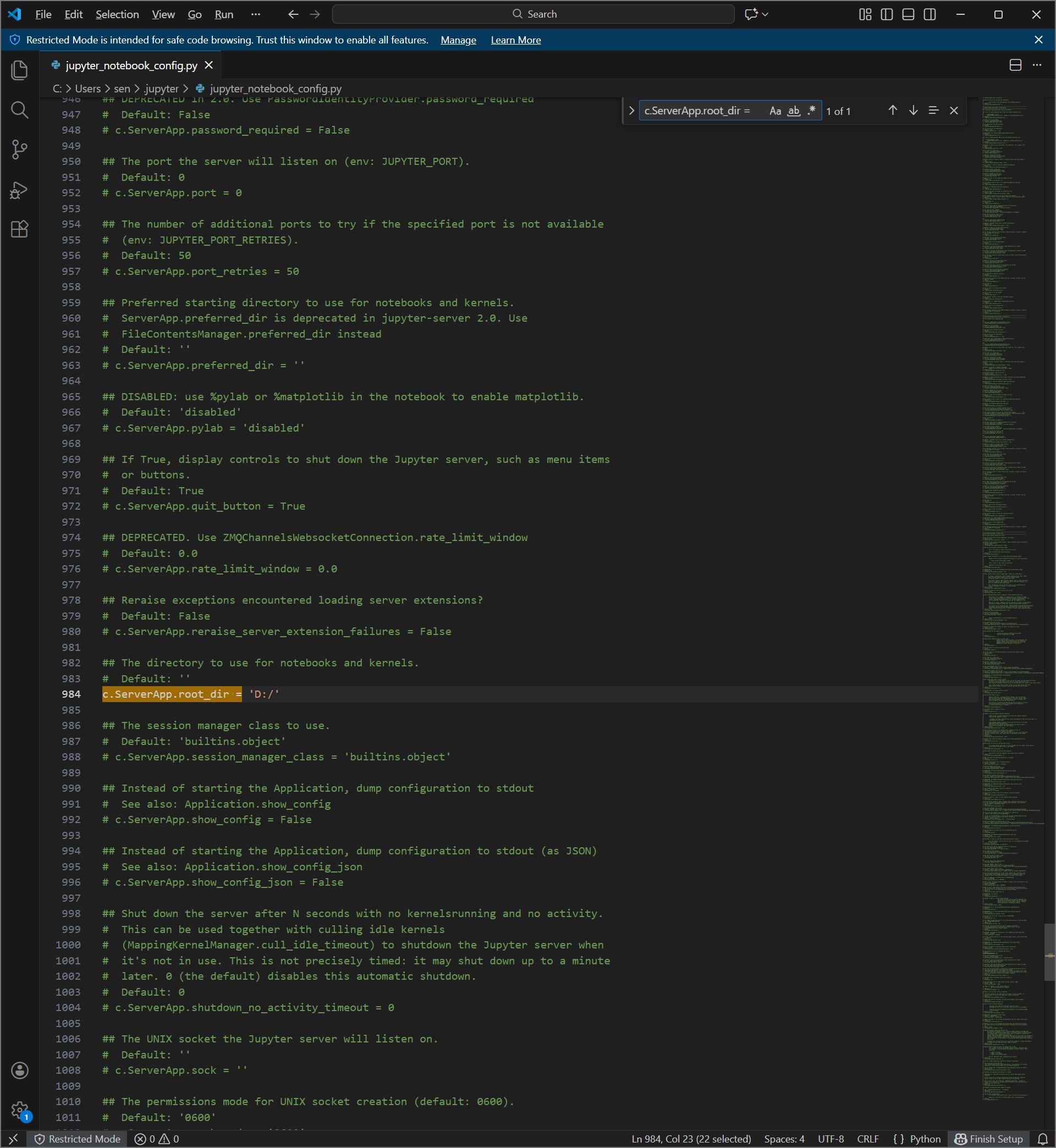
这样我们打开 Jupter Notebook 后就是我们刚刚设置的目录了。
1.3 Jupter Notebook kernel 切换
如果你有多个虚拟环境需要使用不同的虚拟环境去操作,那么你需要进行这里的操作,否则不需要修改。
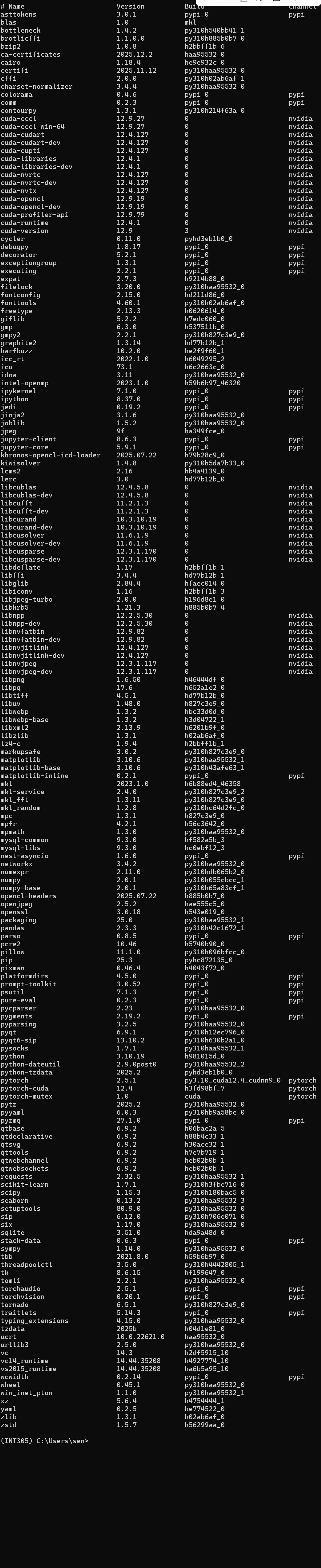
以这学期的课为例,这学期的课的 INT303 和 INT305 其实可以使用相同的环境去解决,但是和之前 INT104 的环境稍微有些差异。我们可以创建专门的 INT305 环境去解决这两门课,然后安装对应的库,下图展示了我这个虚拟环境使用了哪些库。
这里实现在 Jupter Notebook 中切换 kernel 操作的正是 ipykernel 库。
1.3.1 安装 ipykernel
我们需要在我们想使用的环境下安装 ipykernel。
首先我们打开 Anaconda prompt 切换到我们想要使用的环境。
bash
conda activate 环境名然后我们输入以下命令回车后进行安装。
bash
conda install ipykernel它会询问你是否确认安装,输入 y 然后回车后就开始下载安装。
1.3.2 使用 ipykernel 将环境注册到 Jupter 中
我们使用下列命令将这个环境注册到 Jupter 中。
bash
python -m ipykernel install --user --name=环境名 --display-name="显示的环境名"我以这里我的 INT303 环境为例子,这一步的操作如下图所示。

1.3.3 在 Jupyter 中 选择使用该环境
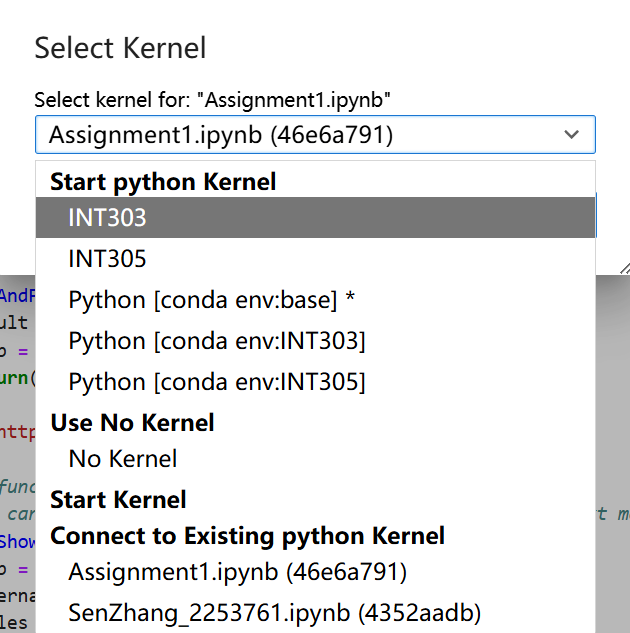
然后我们在我们的 Jupter 文件中就可以看到右上角有这样的 kernel 选择。

我们点开就可以看到我们刚刚注册的名为 INT303 的 kernel 在这里。
2. 准备工作
2.1 理论知识
关于数据爬取的理论知识参考这里数据爬取讲解。
这里不再详细赘述,只将一些关键步骤。
2.2 检查网页内容
其实数据抓取之前我们需要检查网页内容,这一步包含我们先了解网页文件的大致情况,包括网页的图片等资源,以及相关的对于是否允许爬虫的说明。
我们可以通过按下 F12 打开开发者工具来检查网页元素,下面还列举了一些浏览器打开开发者工具的方式。
Chrome/Edge浏览器:可以通过按下 Ctrl + Shift + I(Windows/Linux)或 Cmd + Option + I(Mac)来打开开发者工具。
Safari浏览器:可以通过按下 Cmd + Option + I 来打开开发者工具。
比如我们想要获取一些网页的 Logo 我们就可以通过浏览器的开发者工具去解决。
比如这里我们想获取百度的 Logo ,我们可以打开百度的网页然后按 F12 进入开发者模式。
然后找到 img 目录,该目录下一般是网页的所有图像,然后找到百度 Logo,我们打开然后保存图像即可。
这就是手动操作,我们的爬虫程序就是要将这一个操作进行重复化和自动化。因为我们不可能手动进行大量数据的操作。
所以我们回到这次作业的问题上,这次作业要求我们从电视剧网站上抓取前 200 部电视剧的信息,包括标题、播出时间、完播时间、评分、类型、状态、流媒体平台、摘要。
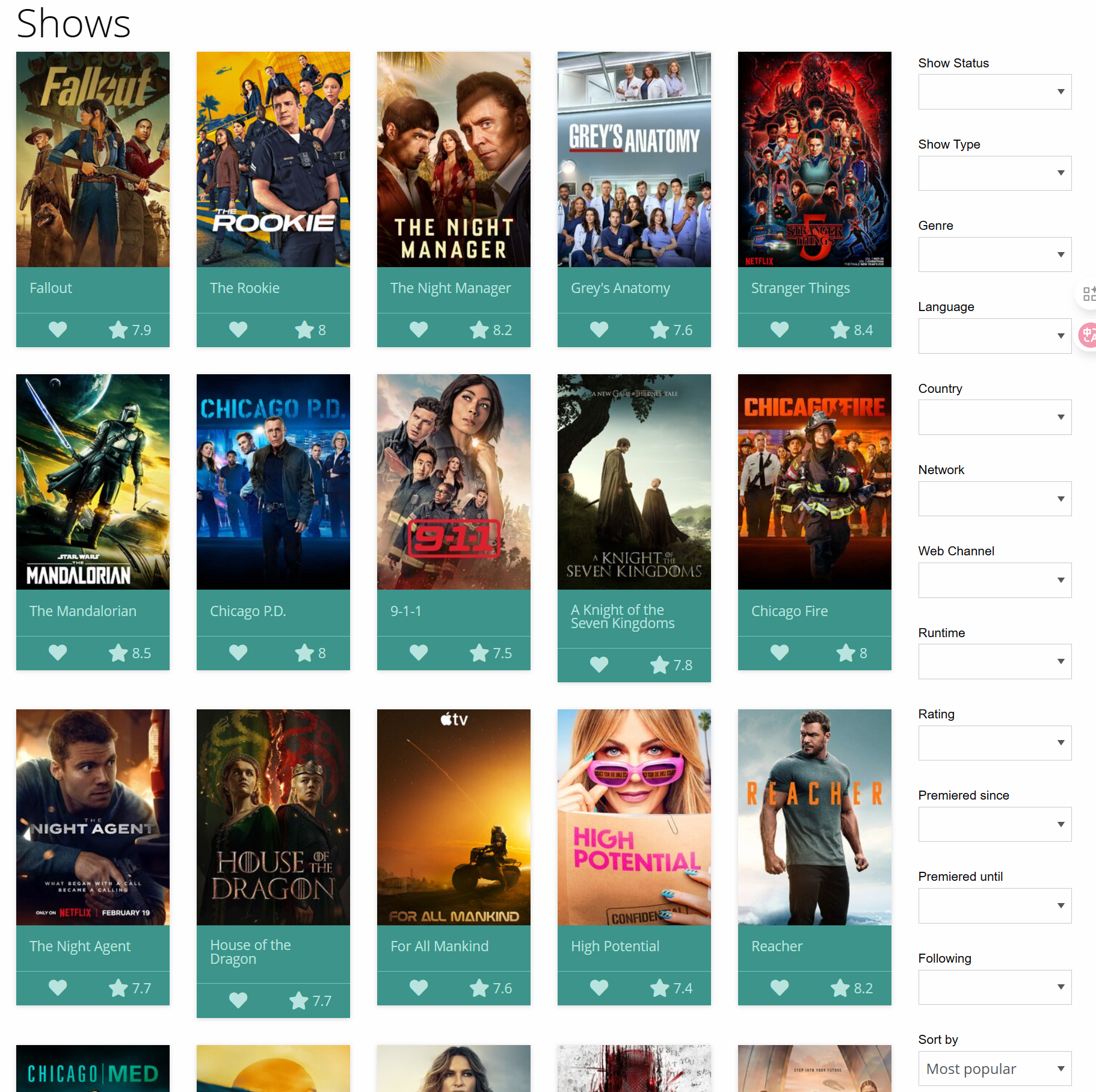
这里每天呈现的结果不一样,所以如果你发现结果与我不一致不用担心。
我们这边随便点开一个,可以发现我们想要的信息其实是在这个点击后跳转的网页中的,我们无法就从刚刚的网页中获得我们想要的所有信息。
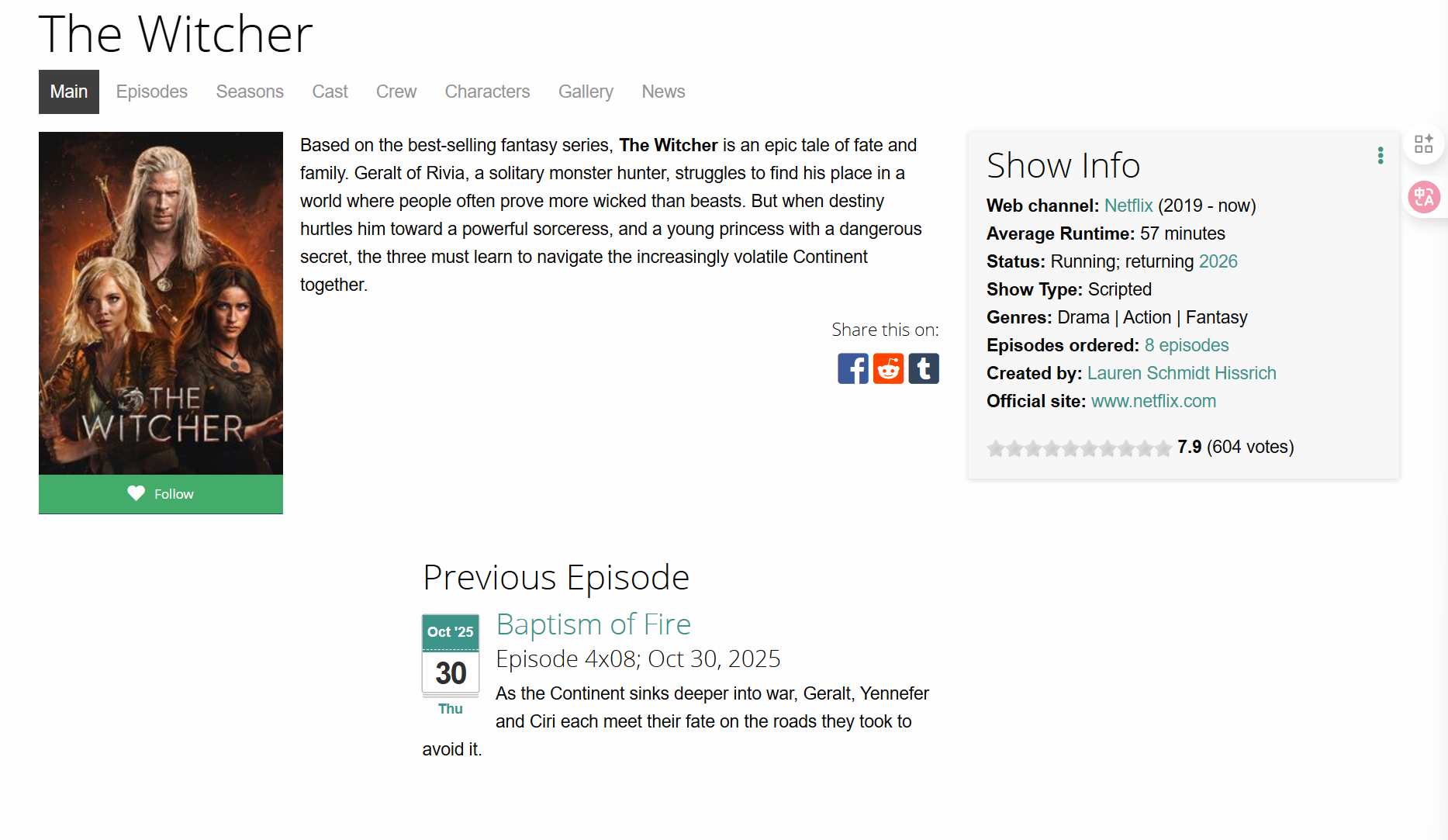
因此我们需要通过刚刚的网页获取对应的 200 个剧的详细页面,然后再从这 200 个网页上进行爬虫。
我们还发现刚刚网页一页其实就 25 个电视剧,因此我们需要让他在获取这些网页的时候记得自动换到这个网站的下一页从而继续操作。这里我们可以尝试到第二页看看是否这些页之间有所域名(网站名)之间的联系。
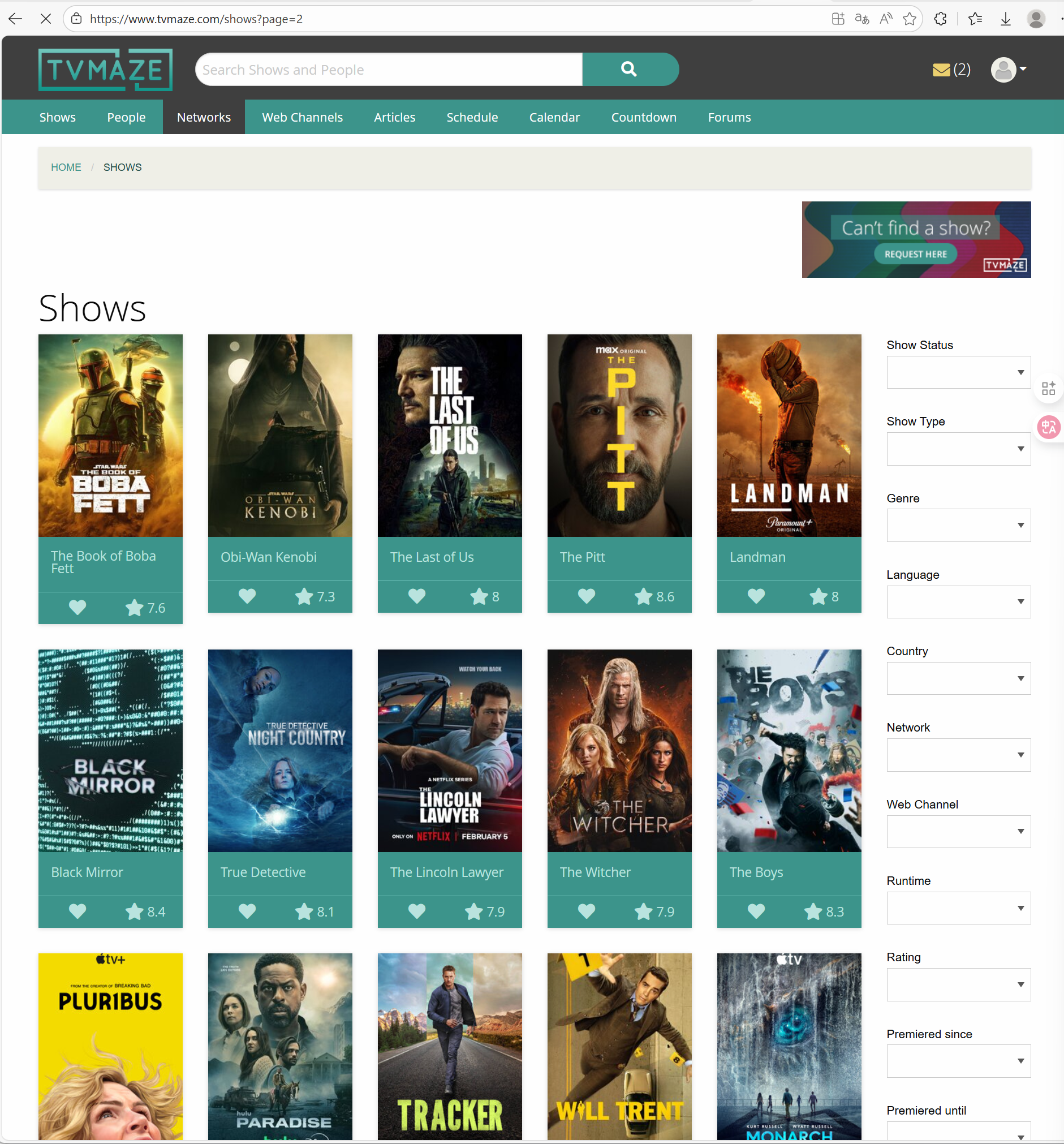
我们可以发现这个第二页会在这个网站后面多出 ?page=2 的一段。我们可以猜想我们这里将 2 的值改为 3,是否可以直接到达第三页呢?
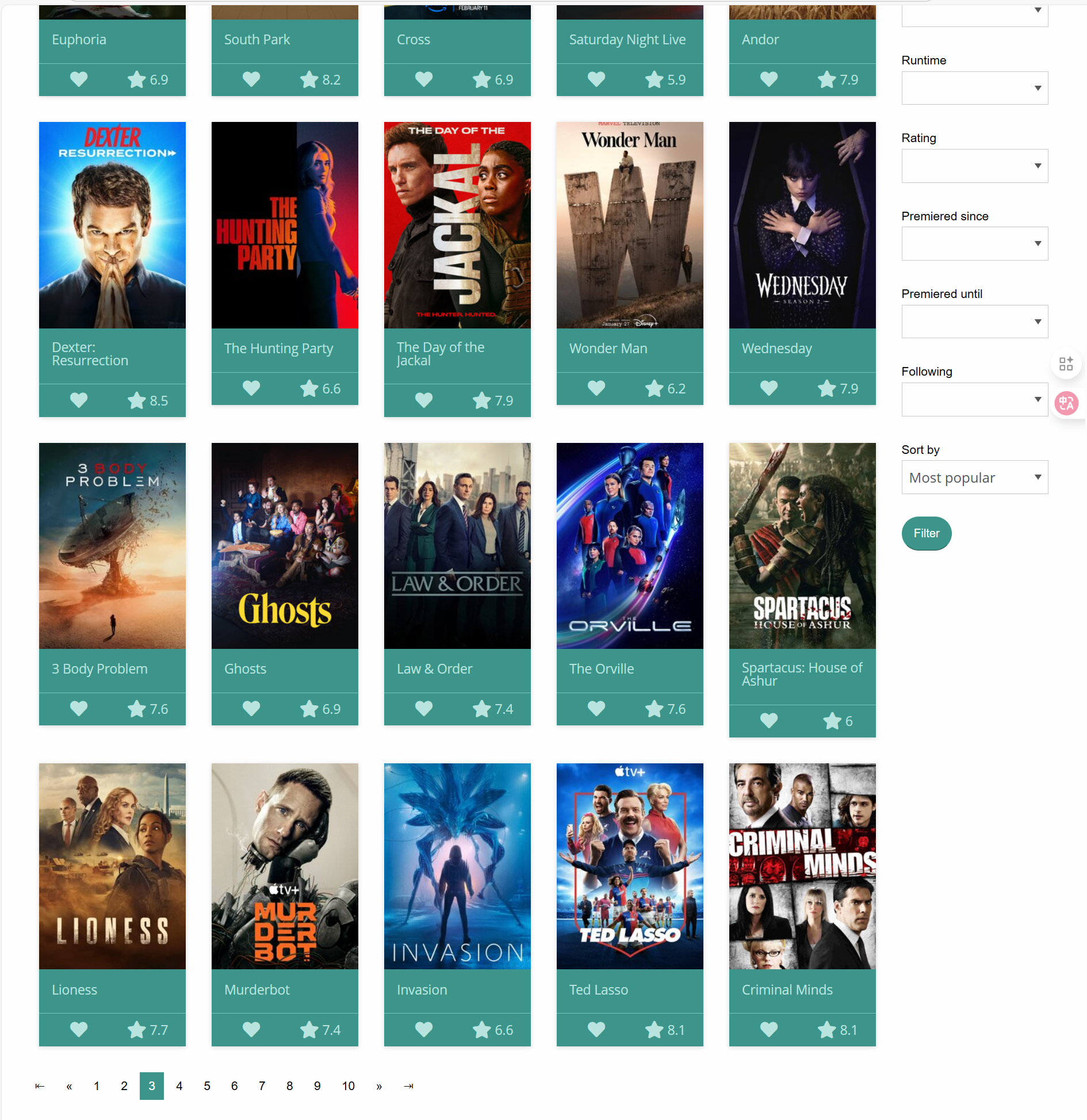
我们修改成 3 后按下回车可以发现网页真的来到了第三页。那么第一页是不是也可以通过 page=1 来获取呢?
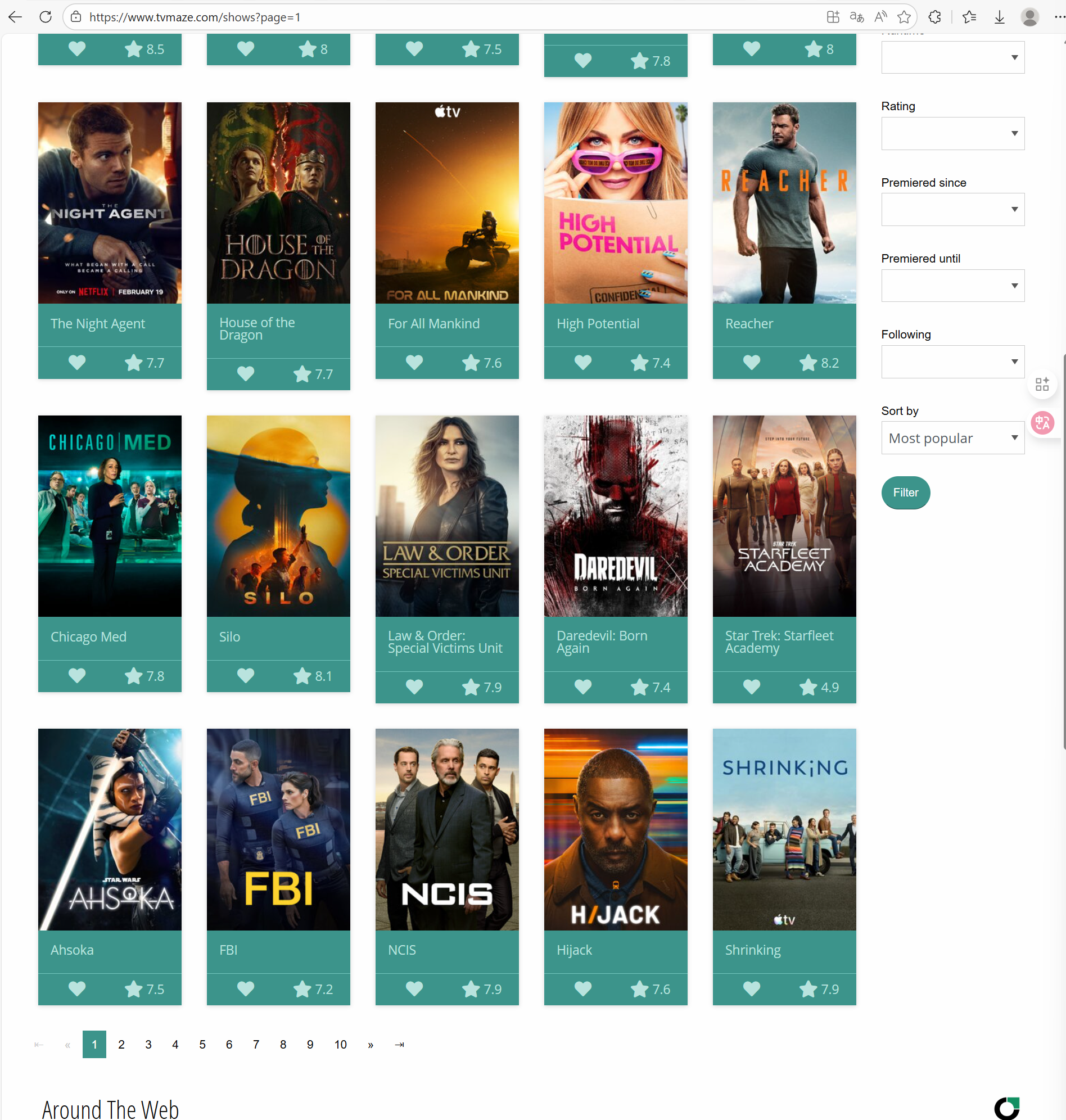
事实证明这也是可行的。
因此我们现在有了整个作业中爬虫(数据抓取)这部分的思路。
我们先通过爬虫(数据抓取)获取这 200 个电视剧详情的网页储存在列表,然后我们再读取这个列表的值从而在每个网页上读取这些剧集中我们需要的信息。
这便是我们解决问题的核心思路。
2.3 所需库
由于 Jupter 可以分段运行代码,因此我们可以一步一步进行操作,这样可以避免我们每次运行整个代码而花费大量时间(因为这里需要访问 200 多个网页,因此需要花上一定的时间),然后最后成功后我们可以重启核以生成一个完整的作业,这样的整体观感更好。
我们先从所需的库开始,这也是准备工作中的一环。
python
from IPython.display import HTML
import numpy as np
import urllib.request
import bs4
from bs4 import BeautifulSoup
import requests
from pandas import Series
import pandas as pd
from pandas import DataFrame
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("talk")
sns.set_style("white")
import re我们这里前面都是用于爬虫和数据分析的一些库,后面的 seaborn 和 matplotlib 是常用的数据可视化库。最后我们还添加 re 正则表达式从而方便我们进行文本模式匹配和提取。
3. 代码实现
这里作业要求除了数据爬取之外还要进行数据分析。我们这里为了美观,当然可以发挥 Jupter 的特点从而将每一部分的结果分开呈现(如后面数据分析时可视化的图都分别作为一个 cell)。我们可以将前面没有结果的地方也分开,为了美观我们甚至可以将我们这里的一些操作写成方法进行调用。
3.1 数据爬取(爬虫)
3.1.1 爬取 URL
就像我们前面所说,我们这里的方法可以是一个非常基础的获取网页解析其 HTML。这也是我们前面理论知识中最基础的数据爬取(爬虫)操作。
python
# This function can get and parse the specific url
# It will be called by the next method
def getAndParseURL(url):
result = requests.get(url)
soup = BeautifulSoup(result.text, "html.parser")
return(soup)
url = "https://www.tvmaze.com/shows"然后我们可以通过这个方法访问我们刚刚说的那个网站上的数据了,但是我们想要找到每个剧的链接,我们需要回到刚刚的开发者模式稍微确认一下这里的链接的情况。
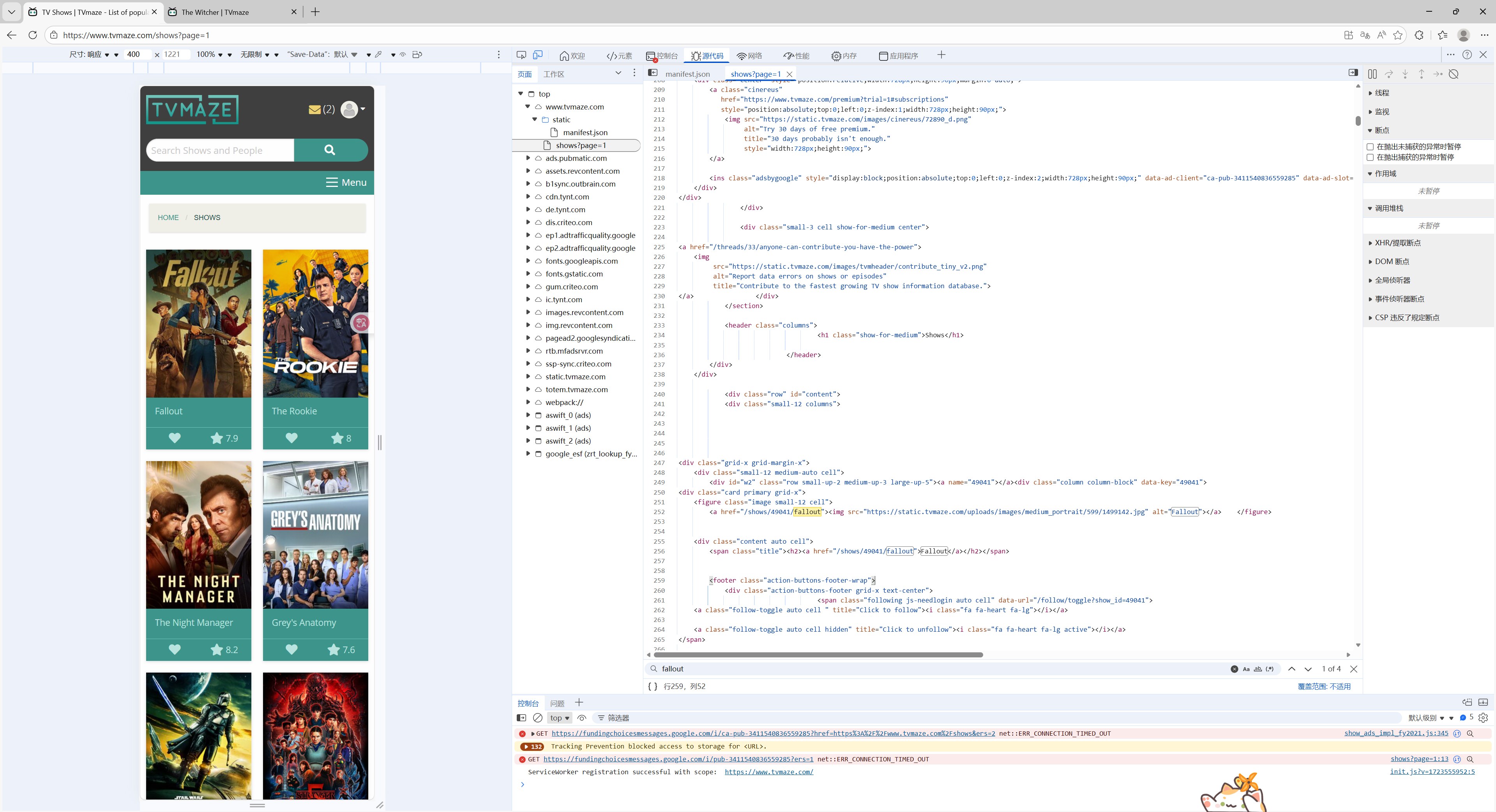
这些链接都是 span class="title"标签下标签为 a 的 href 属性。
如下所示。
html
<span class="title"><h2><a href="/shows/49041/fallout">Fallout</a></h2></span>因此我们获取的第一个剧集的完整 URL 为 https://www.tvmaze.com/shows/49041/fallout。
即从原来的网站上添加49041/fallout即可获得对应的URL。
所以我们获得一页所有剧集的 URL 的方法如下。
python
# This function can get shows' URLs but only for one page
# So it cannot solve our needs, but it can be called by the next method to solve our needs
def getShowsURLs(url):
soup = getAndParseURL(url)
external_links = []
titles = soup.find_all("span", class_="title")
for title in titles:
a_tag = title.find('a')
if a_tag:
href = a_tag.get('href')
external_links.append("https://www.tvmaze.com" + href)
return external_links这里将这些都储存在了列表中。
但是我们刚刚说了一页只有 25 个,因此如果我们需要 200 个,我们需要进行一个循环,也就是前面的方法需要调用 8 次,这里可以再用一个方法将这个操作封装起来。
python
# This function can get more than a specified number of shows URLs
# It calculates how many times should the getShowsURLs will be called and call the method
def getCountedShowsURLs(url, max_elements):
soup = getAndParseURL(url)
external_links = []
titles = soup.find_all("span", class_="title")
for title in titles:
a_tag = title.find('a')
if a_tag:
href = a_tag.get('href')
external_links.append("https://www.tvmaze.com" + href)
if len(external_links) < max_elements:
left_elements = max_elements - len(external_links)
times_needed = 0
while left_elements > 0:
times_needed += 1
left_elements -= len(external_links)
for i in range(times_needed):
tempurl = url + "?page=" + str(i+2)
external_links.extend(getShowsURLs(tempurl))
return external_links因此当我们运行以下代码后,我们就可以获得前 200 个剧集的所有 URL。
python
showsURLs = getCountedShowsURLs(url, 200)现在我们要做的就是对于这个列表里的每个元素进行访问,从而分别从这些网页上获取标题、播出时间、完播时间、评分、类型、状态、流媒体平台、摘要等信息。'
3.1.2 爬取详细信息
我们对于每个网页我们需要调用前面第一个方法从而访问其 HTML 文件,然后再通过从开发者模式中看到的每个需要的信息所在的大致情况从而确定对应的方法。
例如下图所示。
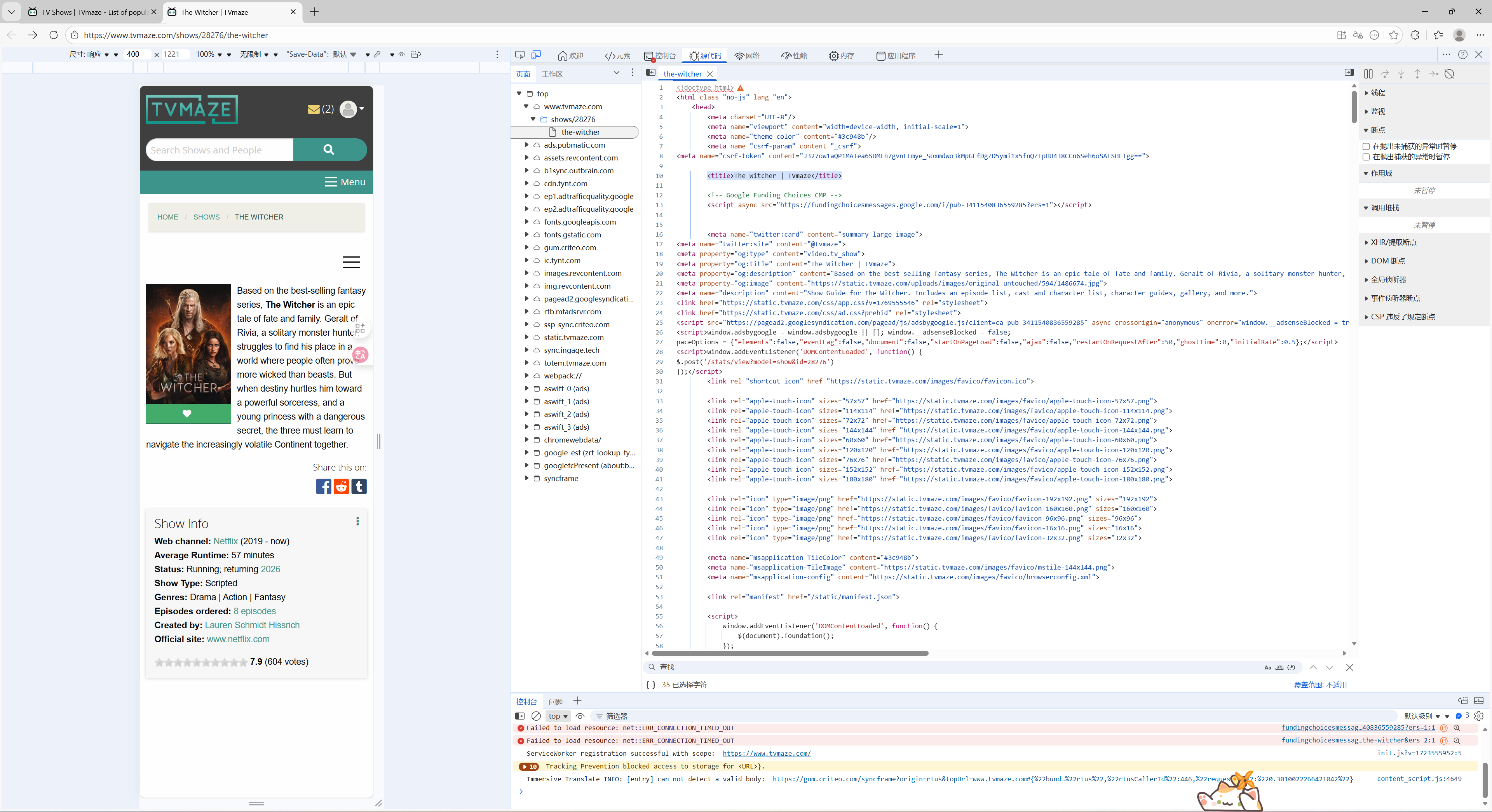
剧名在 title 标签下但是其多了一点。
html
<title>The Witcher | TVmaze</title>因此我们还需要去掉多余部分。
对应的代码如下。
python
# scrape the title
title_tag = show.find('title')
if title_tag:
full_title = title_tag.text.strip()
clean_title = full_title.replace(" | TVmaze", "").strip()
titles.append(clean_title)
else:
titles.append("")我们可以用这样的方法解决其他的信息问题,这里抓取日期稍微难一点,因为我们观察一下或者尝试以下可以发现有的完播时间是 now。
如这里的是。
html
<span id="year">(2019 - now)</span>因此我们这里最好使用正则表达式去匹配,匹配 4 位数字然后是带空格的 - ,然后再是 4 位数字或者 now。
因此方法如下。
python
# scrape the start_date and end_date
year_span = show.find('span', id='year')
text = year_span.text.strip()
m = re.search(r'\((\d{4})\s*-\s*(\d{4}|now)\)', text)
if m:
start_date, end_date = m.group(1), m.group(2)
first_air_dates.append(start_date)
end_dates.append(end_date)
else:
first_air_dates.append("")
end_dates.append("")评分比较简单,就不再过多赘述。
python
# scrape the rating
rating_tag = show.find('b', itemprop='ratingValue')
if rating_tag:
rating = rating_tag.text
ratings.append(rating)
else:
ratings.append("")下一个类型有些难度,因为一部剧可能有多个类型。
对应的 HTML 如下。
html
<div>
<strong>Genres:</strong>
<span class="divider">
<span>Drama</span><span>Action</span><span>Fantasy</span>
</span>
</div>我的想法是将这里的所有字符先提取下来,然后再将里面的大写字母前面添加逗号以分割。但是这里发现了一个问题,那就是对于科幻类型(Science-Fiction),这里会错误地将其分开,但是 F 开头的类型还有 Fantasy。所以我们不能单独排除 F 大写的字母,我想的是再多一个判断看 F 后的字母是不是 i。
因此我的代码如下。
python
# scrape the genres
strong = show.find('strong', string='Genres:')
if strong:
for span in strong.find_next_siblings('span'):
text = span.get_text(strip=True).strip("")
if text:
processed_text = re.sub(r'(?<!^)(?=[A-Z])(?!(F)(?=i))', ', ', text)
genres.append(processed_text)
else:
genres.append("")
else:
genres.append("")关于状态的 HTML 如下。
html
<div>
<strong>Status:</strong> Running; returning <a href="...">2026</a>
</div>我们需要把这里的多余的 Status:删掉。
python
# scrape the status
strong = show.find('strong', string='Status:')
if strong:
full_text = strong.parent.get_text(strip=True)
status_info = full_text.replace('Status:', '').strip()
status_info = status_info.replace('returning', 'returning ')
statuses.append(status_info)
else:
statuses.append("") 下一个是网络流媒体平台,需要注意的是可能是没有。
python
# scrape the network
strong = show.find('strong', string='Web channel: ')
if strong:
a_tag = strong.next_sibling.next_sibling
if a_tag:
network = a_tag.text.strip()
networks.append(network)
else:
networks.append("")
else:
networks.append("") 对于故事摘要也很简单,不再过多赘述。
python
# scrape the summary
meta_desc = show.find('meta', property='og:description')
if meta_desc and meta_desc.get('content'):
summary = meta_desc['content'].strip()
summaries.append(summary)
else:
summaries.append("")因此这里完整操作的代码如下。
python
titles = []
first_air_dates = []
end_dates = []
ratings = []
genres = []
statuses = []
networks = []
summaries = []
for showURL in showsURLs:
show = getAndParseURL(showURL)
# scrape the title
title_tag = show.find('title')
if title_tag:
full_title = title_tag.text.strip()
clean_title = full_title.replace(" | TVmaze", "").strip()
titles.append(clean_title)
else:
titles.append("")
# scrape the start_date and end_date
year_span = show.find('span', id='year')
text = year_span.text.strip()
m = re.search(r'\((\d{4})\s*-\s*(\d{4}|now)\)', text)
if m:
start_date, end_date = m.group(1), m.group(2)
first_air_dates.append(start_date)
end_dates.append(end_date)
else:
first_air_dates.append("")
end_dates.append("")
# scrape the rating
rating_tag = show.find('b', itemprop='ratingValue')
if rating_tag:
rating = rating_tag.text
ratings.append(rating)
else:
ratings.append("")
# scrape the genres
strong = show.find('strong', string='Genres:')
if strong:
for span in strong.find_next_siblings('span'):
text = span.get_text(strip=True).strip("")
if text:
processed_text = re.sub(r'(?<!^)(?=[A-Z])(?!(F)(?=i))', ', ', text)
genres.append(processed_text)
else:
genres.append("")
else:
genres.append("")
# scrape the status
strong = show.find('strong', string='Status:')
if strong:
full_text = strong.parent.get_text(strip=True)
status_info = full_text.replace('Status:', '').strip()
status_info = status_info.replace('returning', 'returning ')
statuses.append(status_info)
else:
statuses.append("")
# scrape the network
strong = show.find('strong', string='Web channel: ')
if strong:
a_tag = strong.next_sibling.next_sibling
if a_tag:
network = a_tag.text.strip()
networks.append(network)
else:
networks.append("")
else:
networks.append("")
# scrape the summary
meta_desc = show.find('meta', property='og:description')
if meta_desc and meta_desc.get('content'):
summary = meta_desc['content'].strip()
summaries.append(summary)
else:
summaries.append("")需要注意的是这里操作需要花费的时间会很多,因为是对 200 个网页进行操作,当我们运行完后我们可以发现旁边 cell 一直没有显示数字就说明其还在运行。
3.1.3 整合数据
我们知识用列表将这些信息存储了起来,我们需要现在将这些信息转换为一个完整的表格。
具体的操作如下。
python
scraped_data = pd.DataFrame({'Title': titles, 'First_air_date': first_air_dates, 'End_date': end_dates, "Rating": ratings, "Genre": genres, "Status": statuses, "Network": networks, "Summary": summaries})我们可以用下面的代码查看情况。
python
scraped_data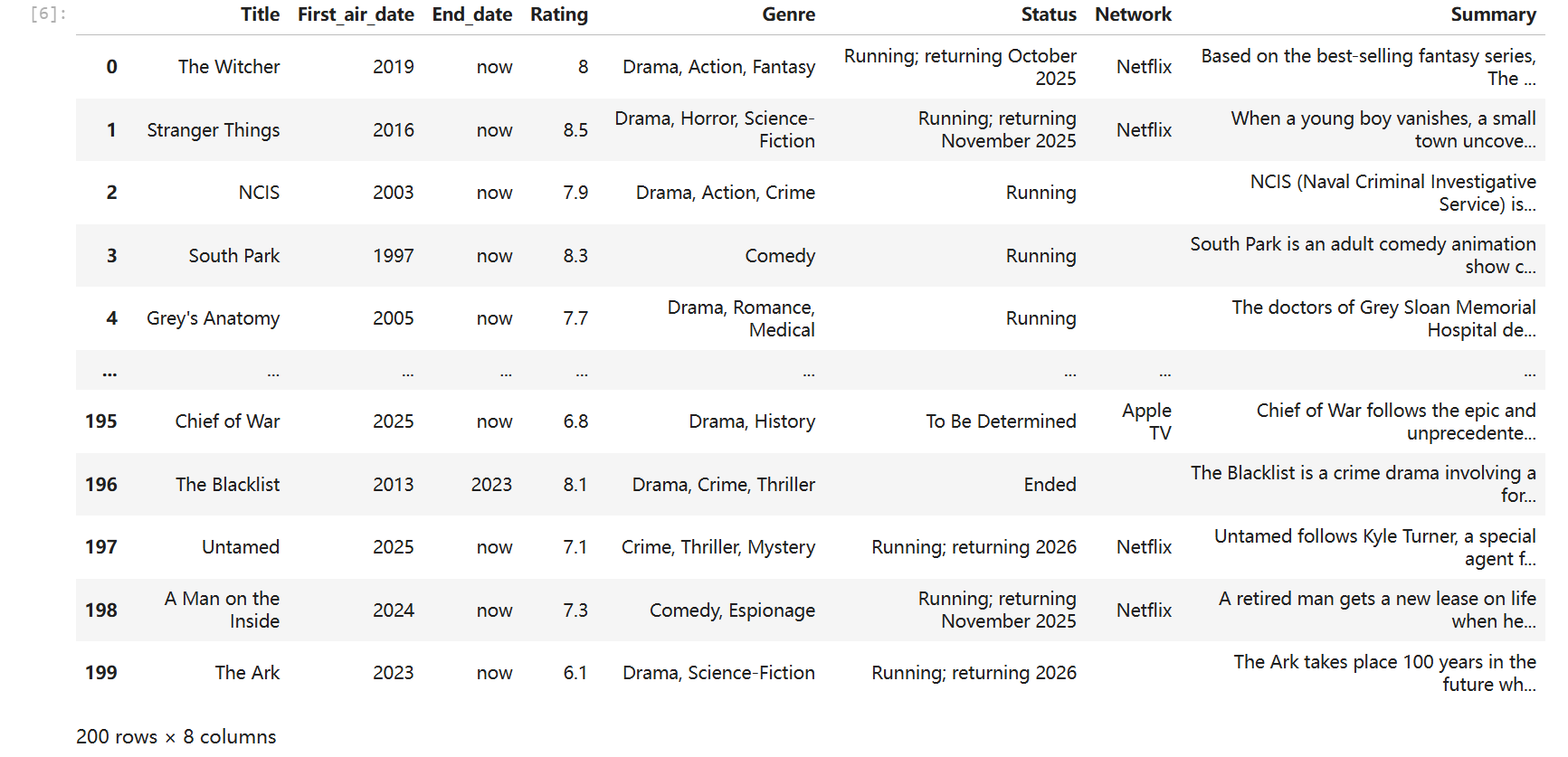
我们这两步操作在我们进行上一个操作的时候其实需要运行从而检查上面抓取的信息是否存在问题,比如我刚刚提到的关于类型的问题正是在这里查看发现的。
我们将最后的结果单独存储在 csv 文件下。
python
scraped_data.to_csv('SenZhang_2253761.csv', index=False, encoding='utf-8')我们就完成了作业的第一部分。
3.2 数据分析
第二部分需要我们对数据进行分析,这一部分更多是前面一些知识的综合,我们需要对数据进行预处理以及可视化从而进行分析。
但在此之前我们需要稍微了解数据的情况,可以肉眼观察也可以通过下面的代码。
python
scraped_data.info()但其实我们这里数据是我们抓取获得的,我们为了防止出问题,在没有的数值上自动加上了空白从而弥补了缺失,但是这些值还是应该进行处理。
比如我们这里的流媒体平台,如果没有那就说明是传统电视行业,我们可以再添加回来。
在这里我其实最想知道的是为什么这些剧是这样排的。因为很明显这里不是按字母排列的。当我们尝试看每一个的分数,也排除了分数。我觉得这里应该是一个特殊的计算公式,我猜测这跟这里的分数、播放时间都有关。
因此这里的数据本来应该是数值型的都应该改回来。
python
scraped_data['Rating'] = pd.to_numeric(scraped_data['Rating'], errors='coerce')
scraped_data['First_air_date'] = pd.to_numeric(
scraped_data['First_air_date'], errors='coerce'
)
scraped_data['End_date'] = scraped_data['End_date'].replace('now', str(2025))
scraped_data['End_date'] = pd.to_numeric(scraped_data['End_date'], errors='coerce')除此之外,我还添加了一个更加可能有关的数据,那就是通过开播时间和结束时间计算的播出持续时段。
python
scraped_data['Show_duration'] = scraped_data['End_date'] - scraped_data['First_air_date']我的第二个假设是关于观众是否会看一些固定类型的。比如人们就不太愿意选择恐怖类型的去观看。因此我认为人们可能会因为类型去选择。
这里只需要数一下每个类型出现的次数。
python
genre_counts = scraped_data['Genre'].str.split(', ').explode().value_counts()第三个假设是我想比较一下现在到底各个平台的市场份额。正如前文所说,对于空白的我们需要添加为传统电视。然后我们再计算一下他们出现的次数。
python
scraped_data['Network_processed'] = scraped_data['Network'].apply(
lambda x: 'Traditional TV' if x == '' or pd.isna(x) else x
)
network_counts = scraped_data['Network_processed'].value_counts()3.2.1 假设1
我们的第一个假设是节目按照与持续时间、结束时间和评级相关的综合得分进行排序。
我们可以先通过一个 Boxplot 查看整体的评分情况,因为如果我们这里没有低分的话,那说明这个排序跟评分强相关(因为我们只有前 200 个电视剧的信息,如果低分的不应该包含在我们这里)。
python
plt.figure(figsize=(8, 6))
plt.boxplot(scraped_data['Rating'].dropna(), tick_labels=['Overall'])
plt.title('Distribution of TV Shows Ratings')
plt.ylabel('Rating')
plt.grid(True, alpha=0.3)
plt.show()如图所示。
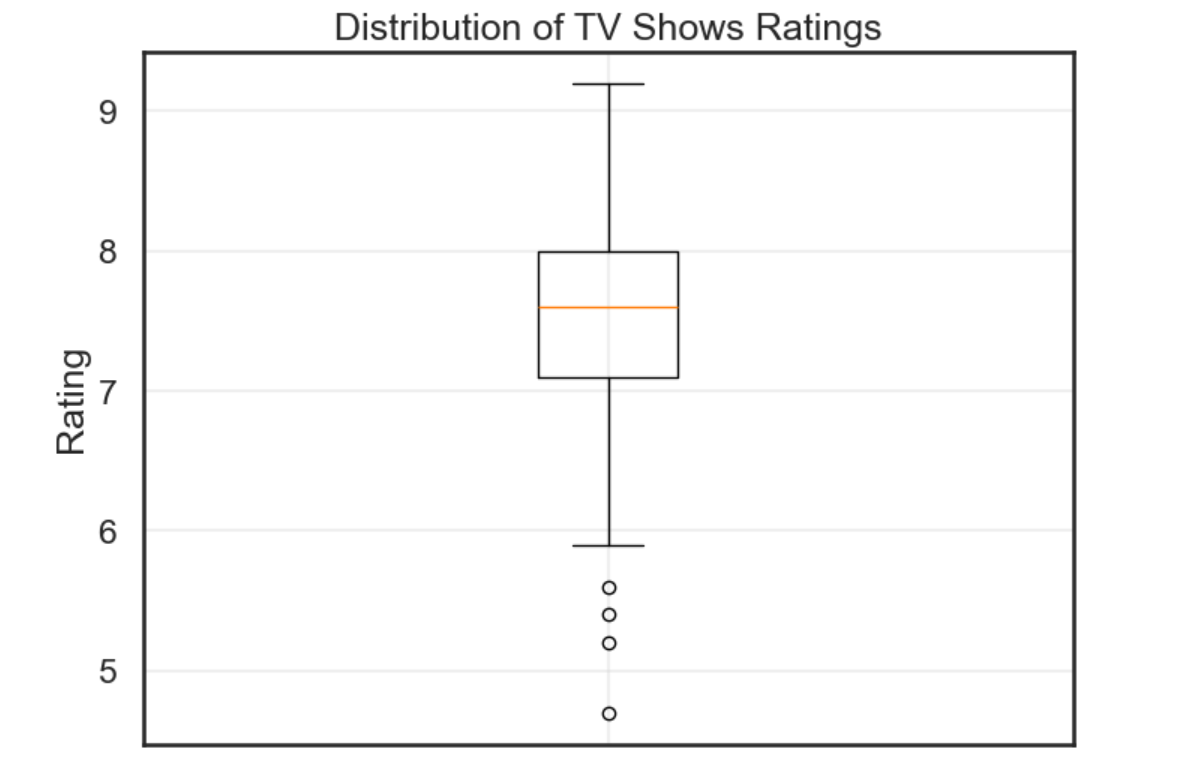
可以发现还是有一些特例的,但是大部分都集中在 7-8 分,这个分数相当可观了。因此我们的假设这一部分可能是成立的。
我们可以再将这前200分成两部分。
python
plt.figure(figsize=(10, 6))
top_100 = scraped_data.head(100)['Rating'].dropna()
bottom_100 = scraped_data.tail(100)['Rating'].dropna()
plt.boxplot([top_100, bottom_100],
tick_labels=['Top 100', 'Bottom 100'])
plt.title('Rating Distribution: Top 100 vs Bottom 100 TV Shows')
plt.ylabel('Rating')
plt.grid(True, alpha=0.3)
plt.show()结果如下。
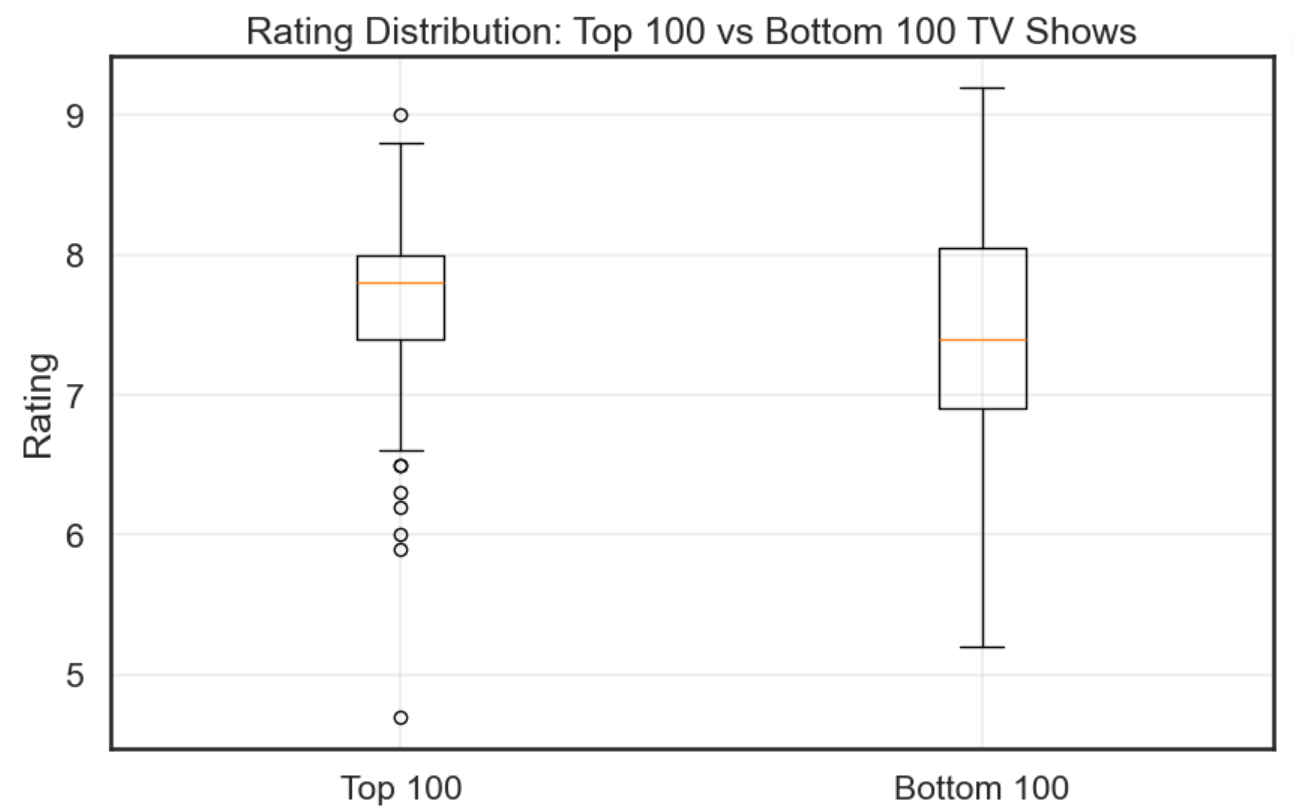
我们似乎可以这么说,但是我们发现最低分的作品其实出现在头 100 个,所以这里分数的占比应该不是主导地位。
我们可以再考虑一下播出时间。
python
top_100_duration = scraped_data.head(100)['Show_duration'].dropna()
bottom_100_duration = scraped_data.tail(100)['Show_duration'].dropna()
duration_data = pd.DataFrame({
'Duration': pd.concat([top_100_duration, bottom_100_duration]),
'Group': ['Top 100'] * len(top_100_duration) + ['Bottom 100'] * len(bottom_100_duration)
})
plt.figure(figsize=(12, 8))
sns.violinplot(data=duration_data, x='Group', y='Duration', inner='box')
plt.title('Show Duration Distribution: Violin Plot')
plt.ylabel('Duration (Years)')
plt.show()如图所示。
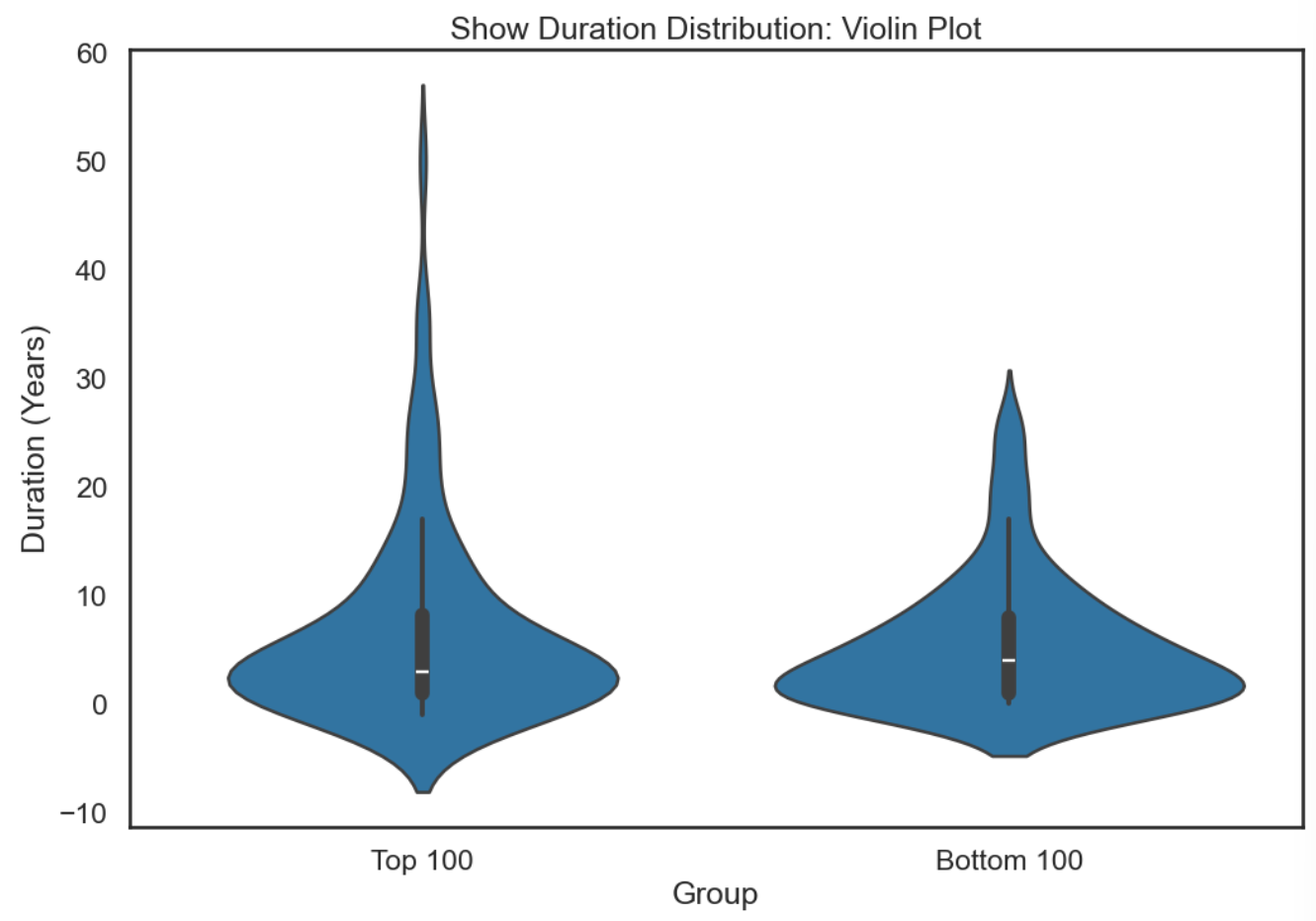
我们可以发现前 100 的剧播出时间更长一些。
因此这里我提出了一个计算公式计算这个排名分数 P = α R + β D E P=\alpha R + \beta DE P=αR+βDE。
我这里还引入了播出时间然后将其作为一个简单的多项式尝试去拟合。
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scraped_data['EndTime_std'] = scaler.fit_transform(scraped_data[['End_date']])
coefficient_sets = [
(0.9, 0.1),
(0.8, 0.2),
(0.7, 0.3),
(0.6, 0.4),
(0.5, 0.5),
(0.4, 0.6),
(0.3, 0.7),
(0.2, 0.8),
(0.1, 0.9),
]
popularity_columns = []
for i, (alpha, beta) in enumerate(coefficient_sets, 1):
col_name = f'Popularity{i}'
scraped_data[col_name] = (
alpha * scraped_data['Rating'] +
beta * scraped_data['Show_duration'] * scraped_data['EndTime_std']
)
popularity_columns.append(col_name)
rank_columns = []
for pop_col in popularity_columns:
rank_col = f'{pop_col}_Rank'
scraped_data[rank_col] = scraped_data[pop_col].rank(ascending=False, method='min') - 1
rank_columns.append(rank_col)
scraped_data['Original_Index_Rank'] = range(len(scraped_data))
plt.figure(figsize=(12, 10))
correlation_data = scraped_data[rank_columns + ['Original_Index_Rank']]
correlation_matrix = correlation_data.corr()
sns.heatmap(correlation_matrix,
annot=True,
cmap='RdBu_r',
center=0,
square=True,
fmt='.3f',
cbar_kws={'label': 'Correlation Coefficient'})
plt.title('Full Correlation Matrix: Popularity Rankings vs Original Index Ranking',
fontsize=14, fontweight='bold', pad=20)
plt.tight_layout()
plt.show()
std_correlations = []
for rank_col in rank_columns:
corr = scraped_data[rank_col].corr(scraped_data['Original_Index_Rank'])
std_correlations.append(corr)
std_avg_correlation = np.mean(std_correlations)这里需要注意的是我们需要将结束时间进行标准化,否则这里的值都是四位数会成为公式的主导因素。然后我们还要注意我们这里节目得分越高,它的排名值应该越小。
然后这里使用相关性来检验这个公式是否准确。
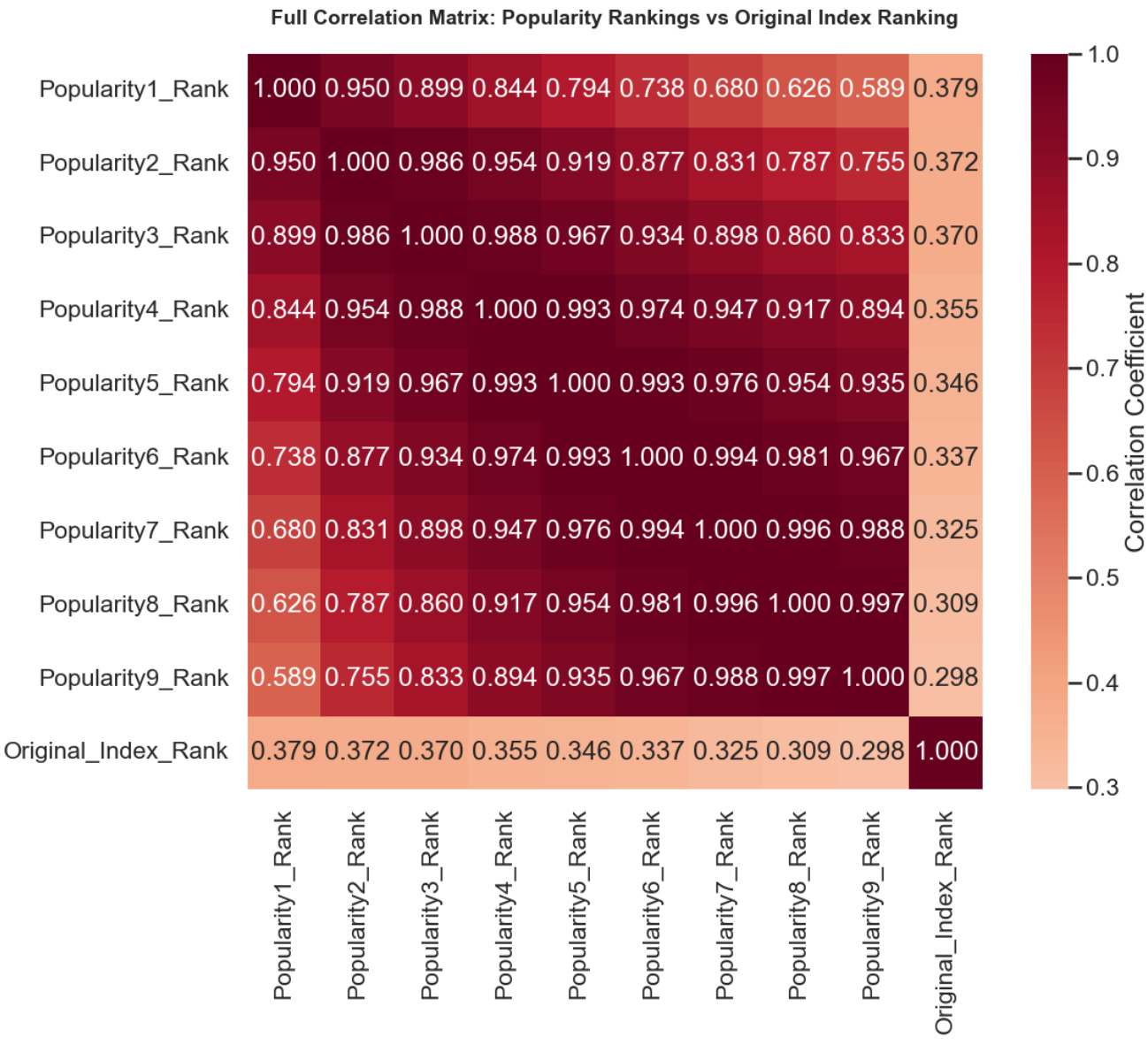
我们这里发现结果其实不好(只看最后一行和最后一列),说明不是这么计算的。
但我们还是可以获得有用的信息,随着分数占比越高,其相关性越高,说明的确是分数在发挥作用。
当然我们这里没有对结束年份的数据做归一化,可能是因为这一点导致的,所以我们再试试。
python
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scraped_data['EndTime_norm'] = scaler.fit_transform(scraped_data[['End_date']])
coefficient_sets = [
(0.9, 0.1),
(0.8, 0.2),
(0.7, 0.3),
(0.6, 0.4),
(0.5, 0.5),
(0.4, 0.6),
(0.3, 0.7),
(0.2, 0.8),
(0.1, 0.9),
]
popularity_columns = []
for i, (alpha, beta) in enumerate(coefficient_sets, 1):
col_name = f'Popularity{i}'
scraped_data[col_name] = (
alpha * scraped_data['Rating'] +
beta * scraped_data['Show_duration'] * scraped_data['EndTime_norm']
)
popularity_columns.append(col_name)
rank_columns = []
for pop_col in popularity_columns:
rank_col = f'{pop_col}_Rank'
scraped_data[rank_col] = scraped_data[pop_col].rank(ascending=False, method='min') - 1
rank_columns.append(rank_col)
scraped_data['Original_Index_Rank'] = range(len(scraped_data))
plt.figure(figsize=(12, 10))
correlation_data = scraped_data[rank_columns + ['Original_Index_Rank']]
correlation_matrix = correlation_data.corr()
sns.heatmap(correlation_matrix,
annot=True,
cmap='RdBu_r',
center=0,
square=True,
fmt='.3f',
cbar_kws={'label': 'Correlation Coefficient'})
plt.title('Full Correlation Matrix: Popularity Rankings vs Original Index Ranking (MinMax Normalization)',
fontsize=14, fontweight='bold', pad=20)
plt.tight_layout()
plt.show()
norm_correlations = []
for rank_col in rank_columns:
corr = scraped_data[rank_col].corr(scraped_data['Original_Index_Rank'])
norm_correlations.append(corr)
norm_avg_correlation = np.mean(norm_correlations)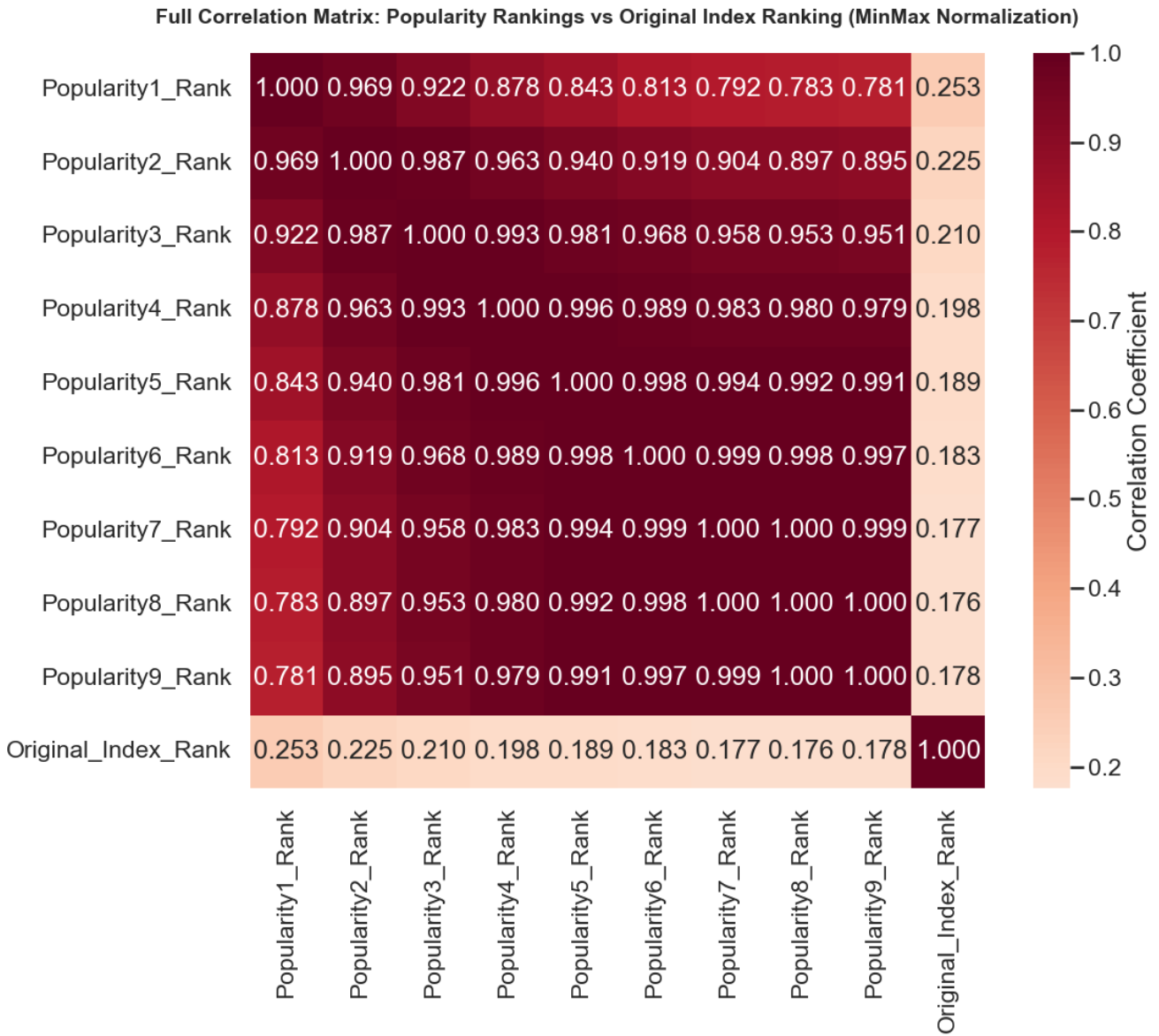
说明不是这个原因,但我们刚刚得到的排名跟分数有关的结论还是成立的。
那我们认为的跟播出时间和截止时间有关是否成立呢?
我们可以将现在得出的排名和单纯靠分数排名做一个对比。
python
scraped_data['Rating_Rank'] = scraped_data['Rating'].rank(ascending=False, method='min') - 1
rating_correlation = scraped_data['Rating_Rank'].corr(scraped_data['Original_Index_Rank'])
methods = ['Only ratings', 'Standardization']
correlations = [rating_correlation, std_avg_correlation]
plt.figure(figsize=(10, 6))
bars = plt.bar(methods, correlations, color=['lightgreen', 'skyblue'])
plt.axhline(y=rating_correlation, color='green', linestyle='--', alpha=0.7, label='Rating')
plt.grid(True, alpha=0.3, axis='y')
plt.title('Comparison', fontsize=14, fontweight='bold')
plt.ylabel('Correlations')
plt.ylim(0, max(correlations) * 1.15)
for bar, corr in zip(bars, correlations):
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height + 0.01,
f'{corr:.4f}', ha='center', va='bottom', fontweight='bold', fontsize=11)
rating_improvement_std = (std_avg_correlation - rating_correlation) / rating_correlation * 100
plt.text(1, std_avg_correlation + 0.02, f'+{rating_improvement_std:.1f}%',
ha='center', va='bottom', fontweight='bold', color='blue')
plt.legend()
plt.tight_layout()
plt.show()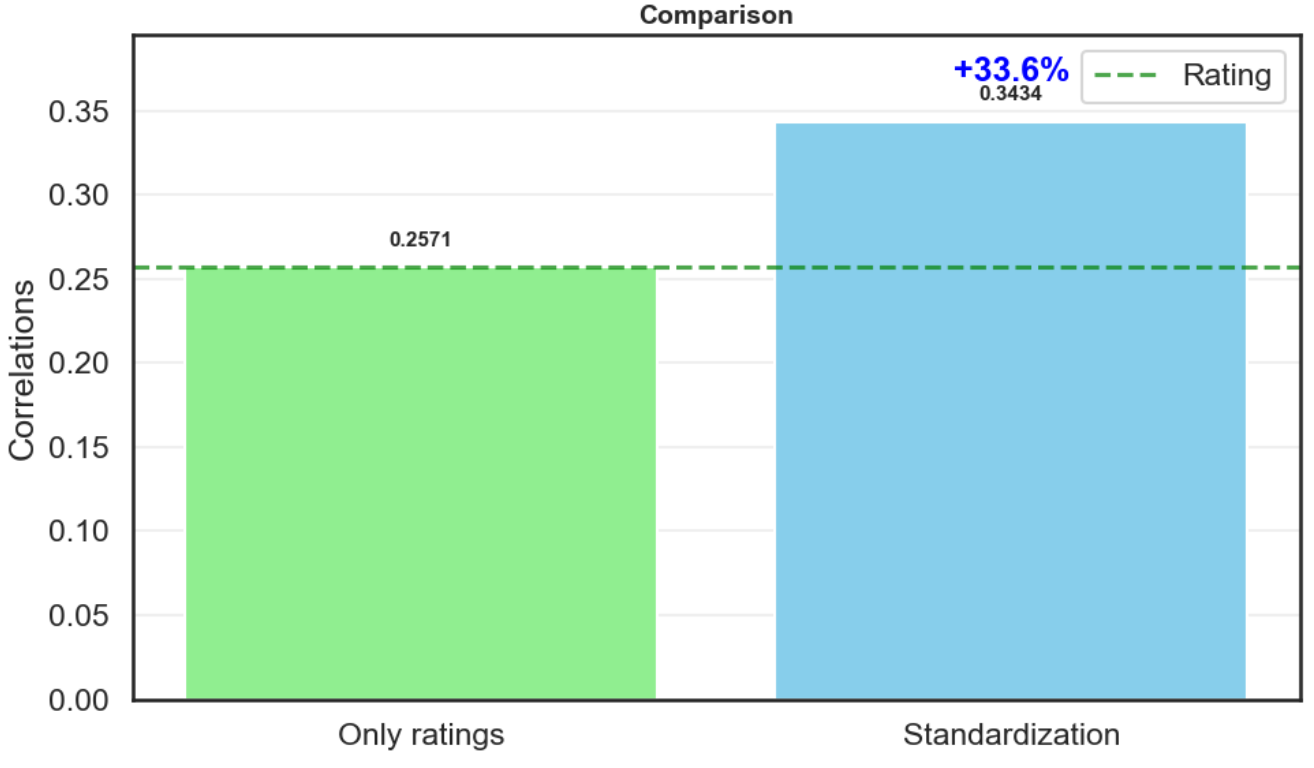
可以看出我们的指标更有说服力,因此我们的假设是成立的,但是我们得出的公式存在问题,可能其考虑了更多的因素,或者我们的公式过于简单,这些都可以是未来改进的点。
3.2.2 假设2
我们的假设2是 Drama 类是最受欢迎的。
我们现在要做的就是将这些类别出现的次数统计一下就好。
python
top_10_genres = genre_counts.head(10)
plt.figure(figsize=(12, 8))
bars = plt.barh(range(len(top_10_genres)), top_10_genres.values,
color=['#1f77b4' if genre != 'Drama' else '#ff7f0e' for genre in top_10_genres.index])
plt.gca().patches[list(top_10_genres.index).index('Drama')].set_color('#ff7f0e')
plt.yticks(range(len(top_10_genres)), top_10_genres.index)
plt.gca().invert_yaxis()
plt.xlabel('Number', fontsize=12)
plt.title('Top 10 Most Common TV Show Genres', fontsize=14, fontweight='bold')
for i, (genre, count) in enumerate(top_10_genres.items()):
plt.text(count + 1, i, f'{count}', va='center', fontweight='bold' if genre == 'Drama' else 'normal')
drama_count = genre_counts['Drama']
plt.text(0.5, 0.95, f'Drama appears in {drama_count} shows ({drama_count/len(scraped_data)*100:.1f}% of all 200 shows)',
transform=plt.gca().transAxes, fontsize=12, fontweight='bold',
bbox=dict(boxstyle='round', facecolor='gold', alpha=0.3))
plt.tight_layout()
plt.show()这里当然也将结果可视化出来了。
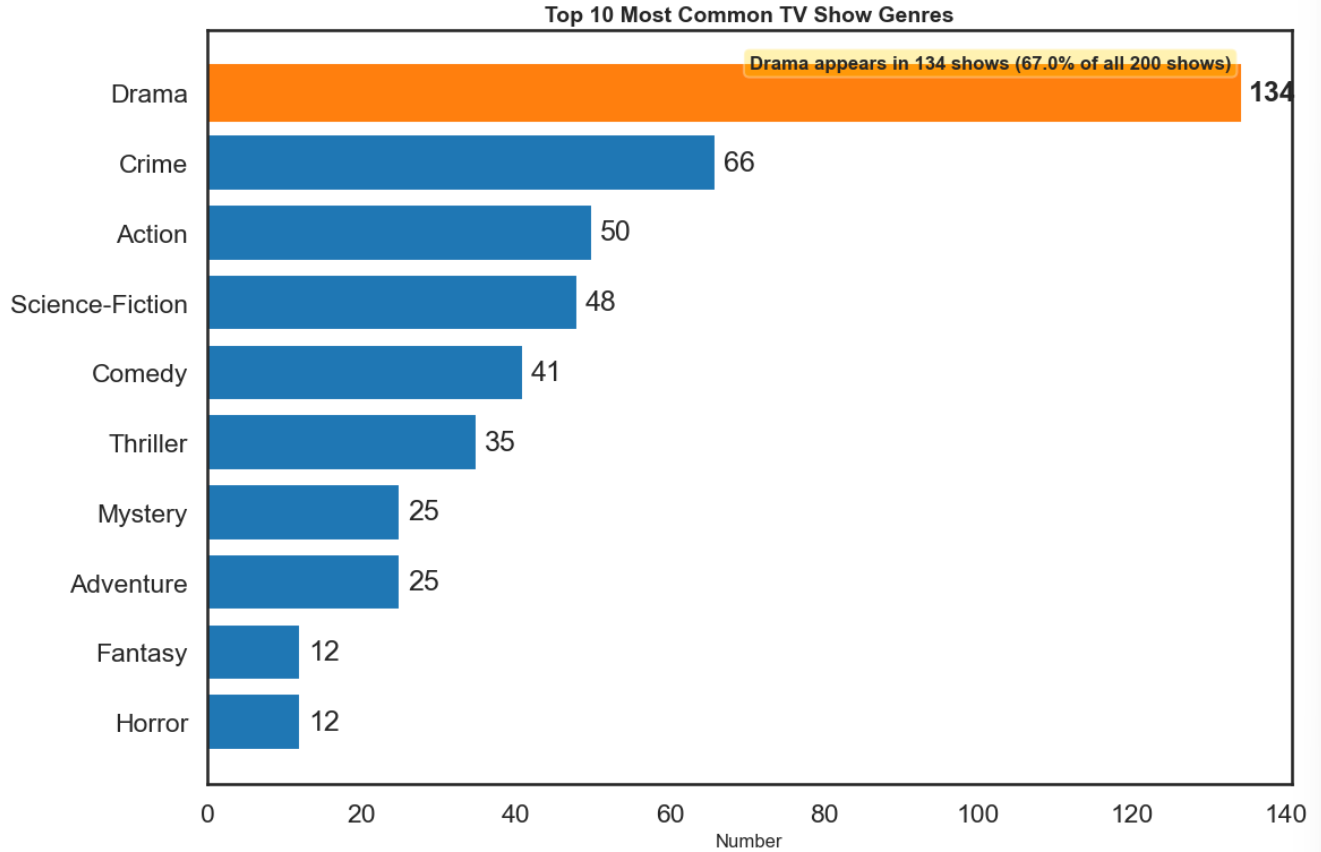
Drama 出现的次数确实是最多的,在我们的数据中有百分之67都是,因此我们可以说 Drama 类是最受欢迎的。
3.2.3 假设3
假设3是分析传统电视和现在流媒体的市场份额,我们可以这里先假设 Netflix 是最热门的。
我们可以先查看一下我们之前次数的结果。
python
print(network_counts)
我们可以发现这里的 Disney+,HBO Max,Now的数量太少,我们后续如果使用饼状图它们的份额就会很小无法看见,而且会影响美观。
因此我们这里可以做一个额外的数据处理,将这些合并为其他平台,这样也可以包含一些更加小众的平台。
然后我们将这里的结果做成饼状图。
python
network_counts_filtered = network_counts[network_counts >= 10]
other_count = network_counts[network_counts < 10].sum()
if other_count > 0:
pie_data = list(network_counts_filtered.values) + [other_count]
pie_labels = list(network_counts_filtered.index) + ['Other Platforms']
else:
pie_data = network_counts_filtered.values
pie_labels = network_counts_filtered.index
plt.figure(figsize=(12, 8))
wedges, texts, autotexts = plt.pie(pie_data,
labels=pie_labels,
autopct='%1.1f%%',
startangle=90,
colors=plt.cm.Set3(np.linspace(0, 1, len(pie_data))))
for autotext in autotexts:
autotext.set_color('black')
autotext.set_fontweight('bold')
plt.title('TV Show Platform Market Share\n(Platforms with <10 shows merged as "Other")',
fontsize=14, fontweight='bold', pad=20)
plt.show()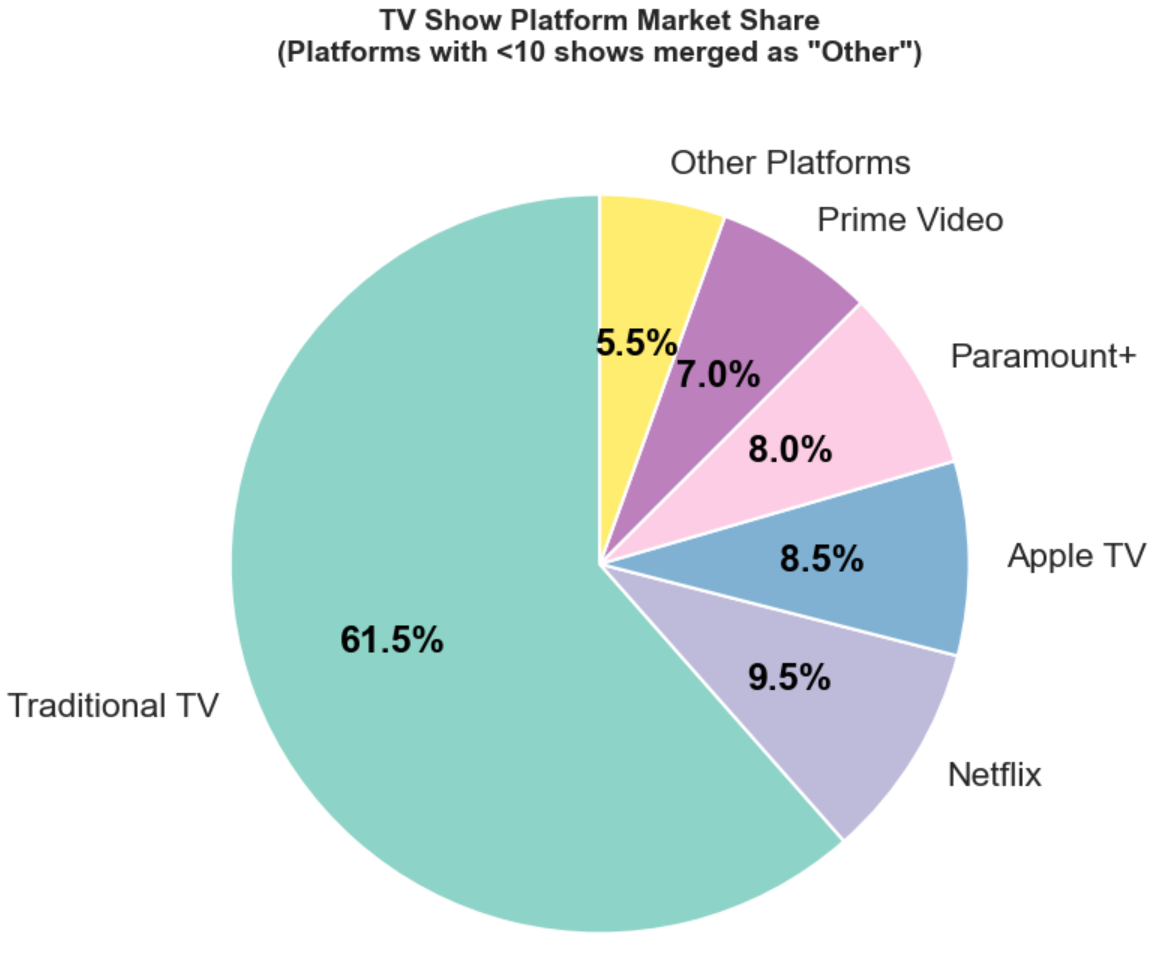
我们这里发现我们之前的假设出错了,最热门的其实还是传统电视行业。
但是我们这里可以进一步延申,如果排除了传统电视行业,只看流媒体平台,那么 Netflix 是不是市场份额最大的呢?
这里同样的是进行数据处理,去掉传统电视行业,而之前的其他平台的操作不用变化,因为它们不是我们要关注的重点,我们现在关注的是谁的份额是最多的。
python
network_filtered = network_counts[network_counts.index != 'Traditional TV']
network_main = network_filtered[network_filtered >= 10]
other_count = network_filtered[network_filtered < 10].sum()
if other_count > 0:
pie_data = list(network_main.values) + [other_count]
pie_labels = list(network_main.index) + ['Other Platforms']
else:
pie_data = network_main.values
pie_labels = network_main.index
explode = [0.1 if label == 'Netflix' else 0 for label in pie_labels]
plt.figure(figsize=(12, 8))
wedges, texts, autotexts = plt.pie(pie_data,
labels=pie_labels,
autopct='%1.1f%%',
startangle=90,
colors=plt.cm.Set3(np.linspace(0, 1, len(pie_data))),
explode=explode)
for autotext in autotexts:
autotext.set_color('black')
autotext.set_fontweight('bold')
plt.title('Streaming Platform Market Share\n(Platforms with <10 shows merged as "Other")',
fontsize=14, fontweight='bold', pad=20)
plt.show()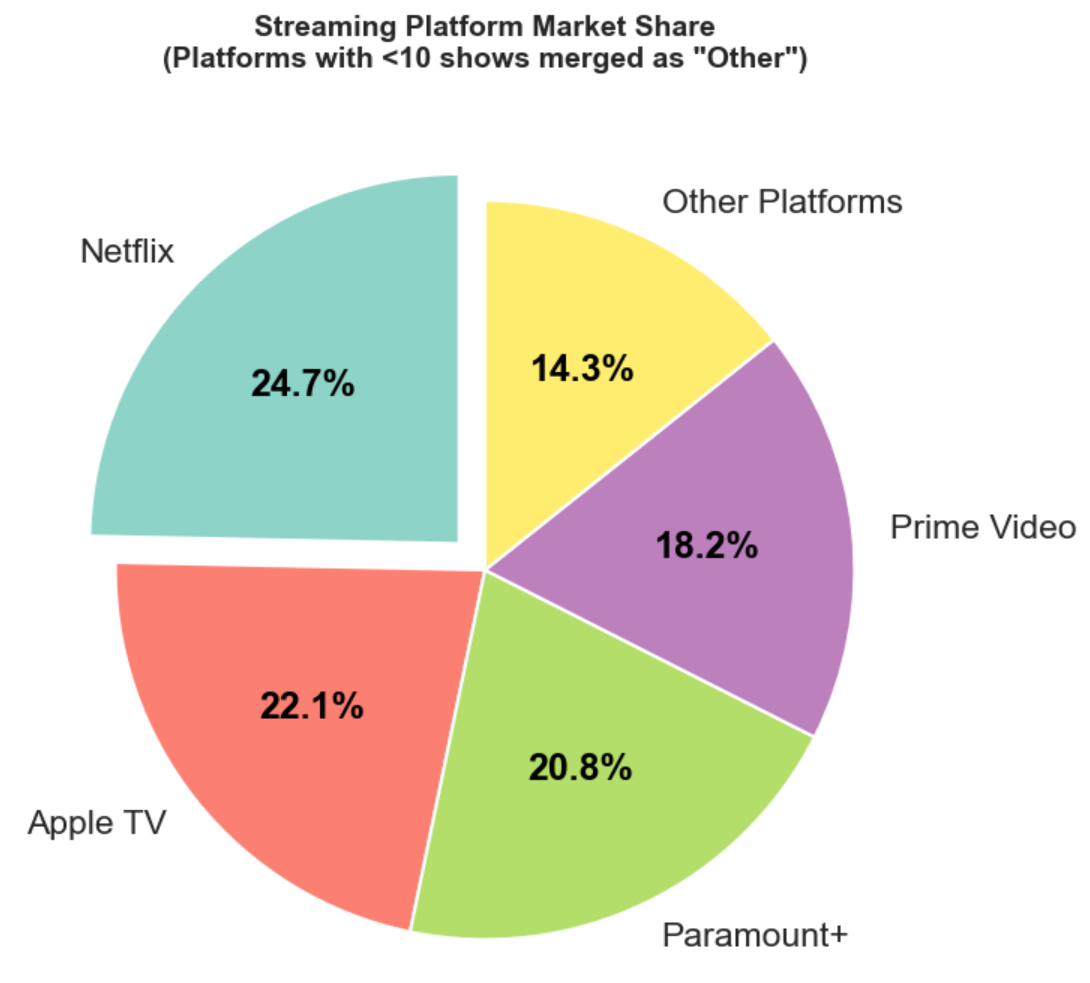
图片说明了在流媒体平台上的确 Netflix 是份额最高的。
3.2.4 总结
我们需要对数据分析进行一个总结,也就是强调一下我们之前的三个发现。
- 网站上对电视剧的排序的算法是与分数、播出时间、结束时间有关的一个较为复杂的算法。我们提出了一个计算公式,但其拟合效果不好。
- 人们最感兴趣的电视剧类型是 Drama。
- 传统电视行业仍是电视剧中份额最多的,而在流媒体平台中 Netflix 是最多的。
4. 反思
正如前文所说,我们假设1假设的计算公式过于潦草,其实可以使用更复杂的模型去预测或者使用后面的一些神经网络去尝试预测,这些都是可以改进的点。
假设2其实也不严谨,因为最受欢迎的意思到底是什么呢?是这个排名就是按照人气排名的吗?
当然可以进行数据分析的也不止这些,这里的假设2和假设3跟假设1相比就有些粗糙。