作者:香菇🍄&张师傅,排名不分先后
当前的大模型计算革命中,市场存在一种普遍现象:绝大多数所谓的 "AI-Native" 应用,本质上仍是传统软件外挂了一个 LLM 对话框。业界的讨论多集中于模型能力边界,而忽视了承载智能的架构形态。
这种错位导致了"伪 AI 应用"的泛滥------交互看似智能,但系统内核依然是硬编码的 If-Else 逻辑,无法自主进化,也缺乏安全边界。对此,我们需要明确一个核心判断标准:
判断一个应用是否为 AI-Native应用,只看一点:内核是逻辑控制,还是 AI 控制?
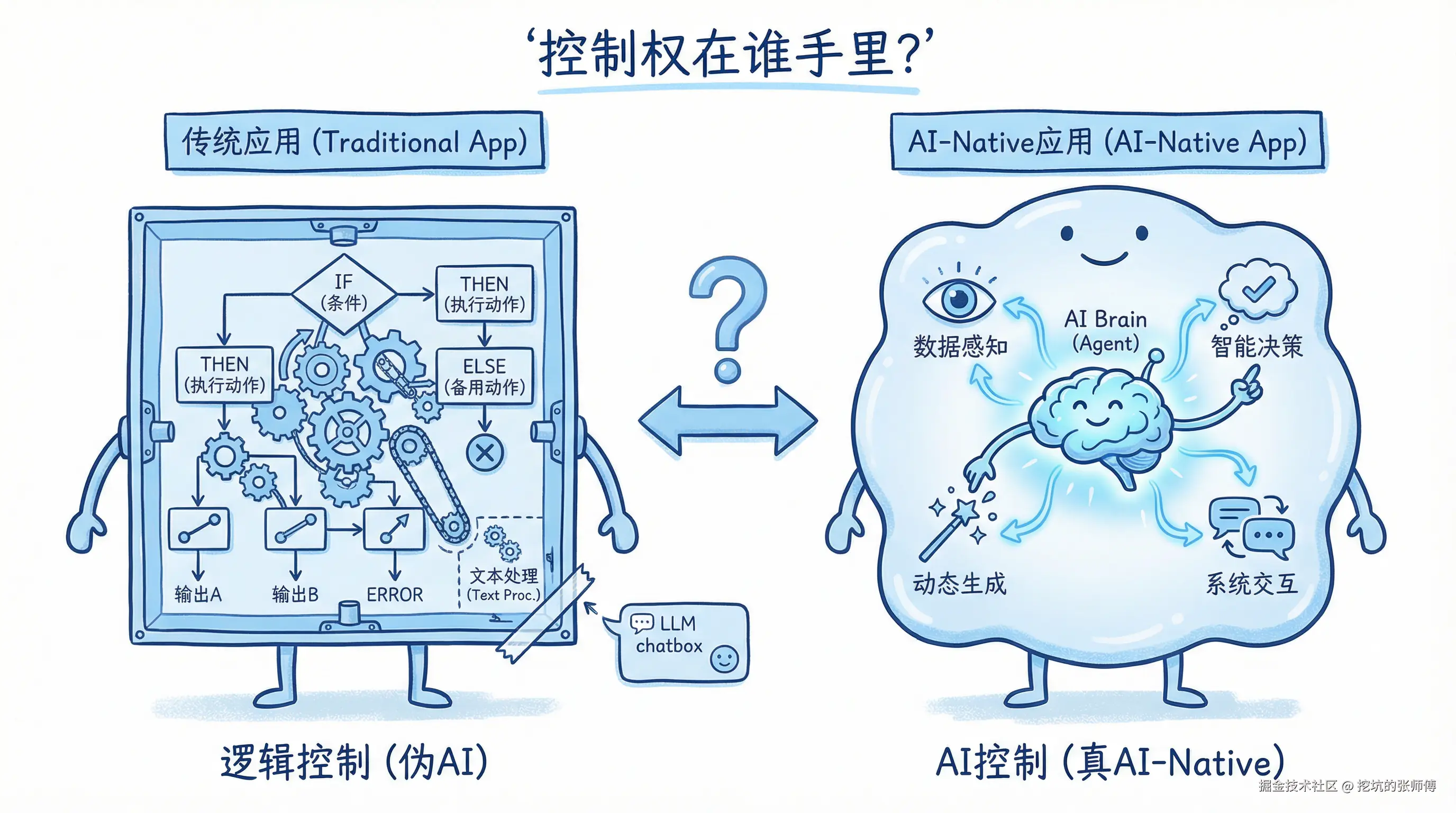
若架构不改,AI 仅作为插件存在,系统必然面临维护困境。真正的 AI-Native,是将系统的控制权从硬编码移交给具备推理能力的 Agent。
1. 核心认知:Coding Agent 即通用 Agent
理解架构变革,首先要更新认知:Coding Agent 不仅是编程辅助工具,更是通用 Agent 的最佳形态。人类从使用天然工具 到制造工具是进化的分水岭,AI 亦然。
这一质变体现在三个维度:
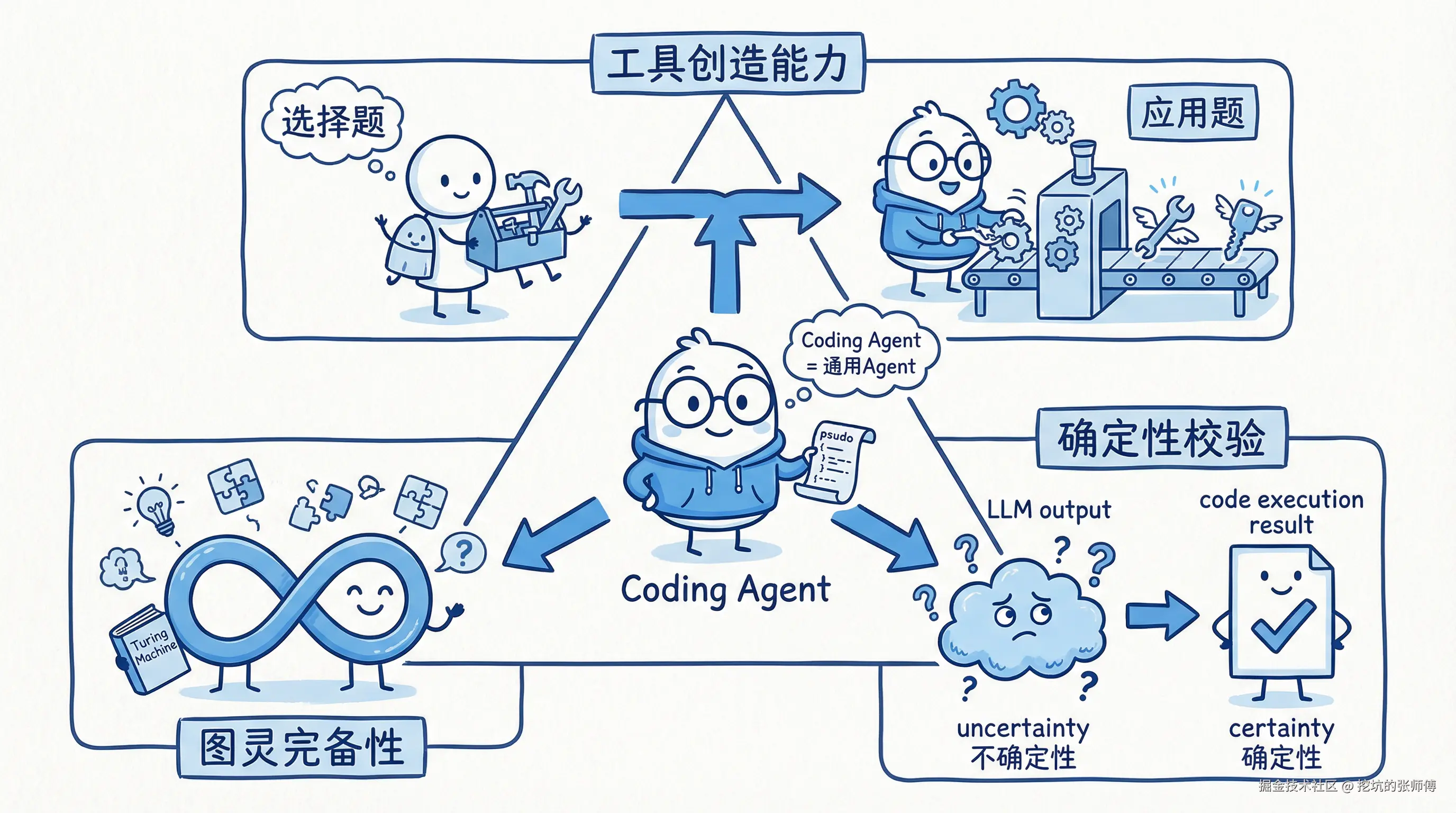
- **工具创造能力:**传统Agent使用预设工具集,能力边界固定。Coding Agent能动态生成代码以创建新工具,将问题求解从"选择题"转变为"应用题"。
- **图灵完备性:**编程语言的图灵完备性,使Agent理论上具备解决任何可计算问题的能力,从而能够应对开放和未知的任务。
- **确定性校验:**LLM的输出是概率性的,存在"幻觉"风险。代码执行结果是确定性的,为Agent的推理提供了可靠的验证和反馈闭环。
代码是 AI 能力的延伸。掌握编程能力的Agent,是从工具使用者向工具创造者的转变。
2. 落地瓶颈:在"破坏力"与"注意力"之间走钢丝
Coding Agent 的落地面临两个看似矛盾的挑战:能力的无限性(破坏力)与模型的有限性(注意力)。
2.1 如何限制"无限的破坏力"?
Coding Agent 本质具备图灵完备的破坏力(如删库风险)。沙箱(Sandbox)不仅是隔离环境,更是 AI-Native 的物理安全边界,主要承担四项职能:
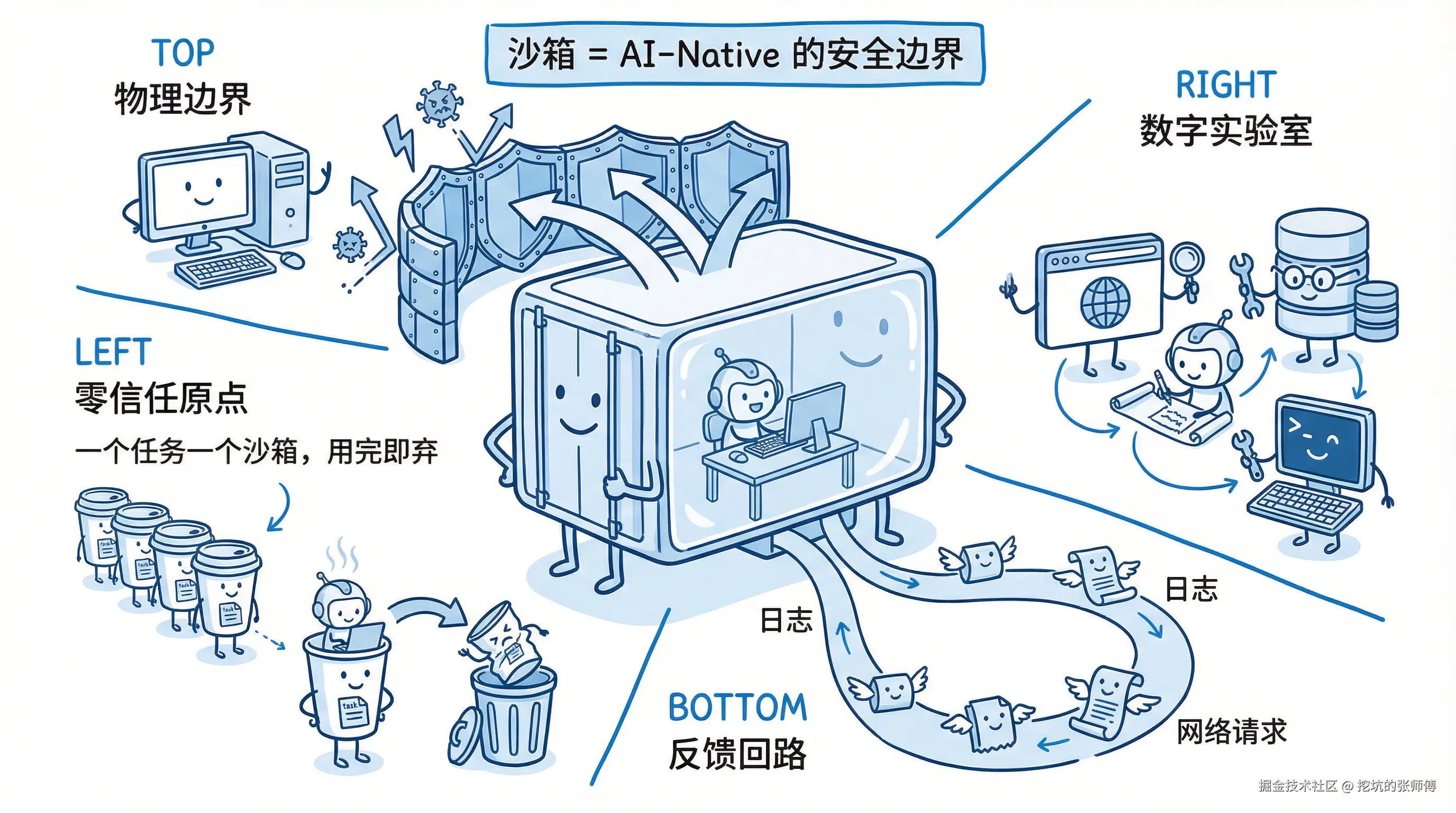
- 物理边界: 提供强隔离虚拟环境,限制逻辑自由,防止破坏力溢出至宿主系统。
- 零信任原点: "一事一沙箱"机制,为每个任务提供即用即弃的独立环境,确保可重复与可审计。
- 数字实验室: 将 Agent 能力延伸至沙箱内预装的工具集(浏览器、数据库等),实现从推理到行动的转化。
- 反馈回路: 记录 Stdout/Stderr、网络请求等交互痕迹,作为 Agent 自我证伪和进化的事实基础。
2.2 如何利用"有限的注意力"?
业界的工程实践(如 Manus 和 TRAE)表明:上下文窗口 ≠ 有效上下文窗口。即便拥有 1M Token 窗口,有效利用率往往仅为 10-15%。超过阈值后,成本剧增且智能下降。
这源于 Transformer 架构的注意力机制缺陷:
- 注意力稀释(Attention Dilution): 关键信息权重被海量无关信息稀释。
- 中间迷失(Lost-in-the-Middle): 模型对首尾信息敏感,但极易遗忘中间段落。
解决之道在于上下文工程,即从"信息投喂"转向"注意力管理":
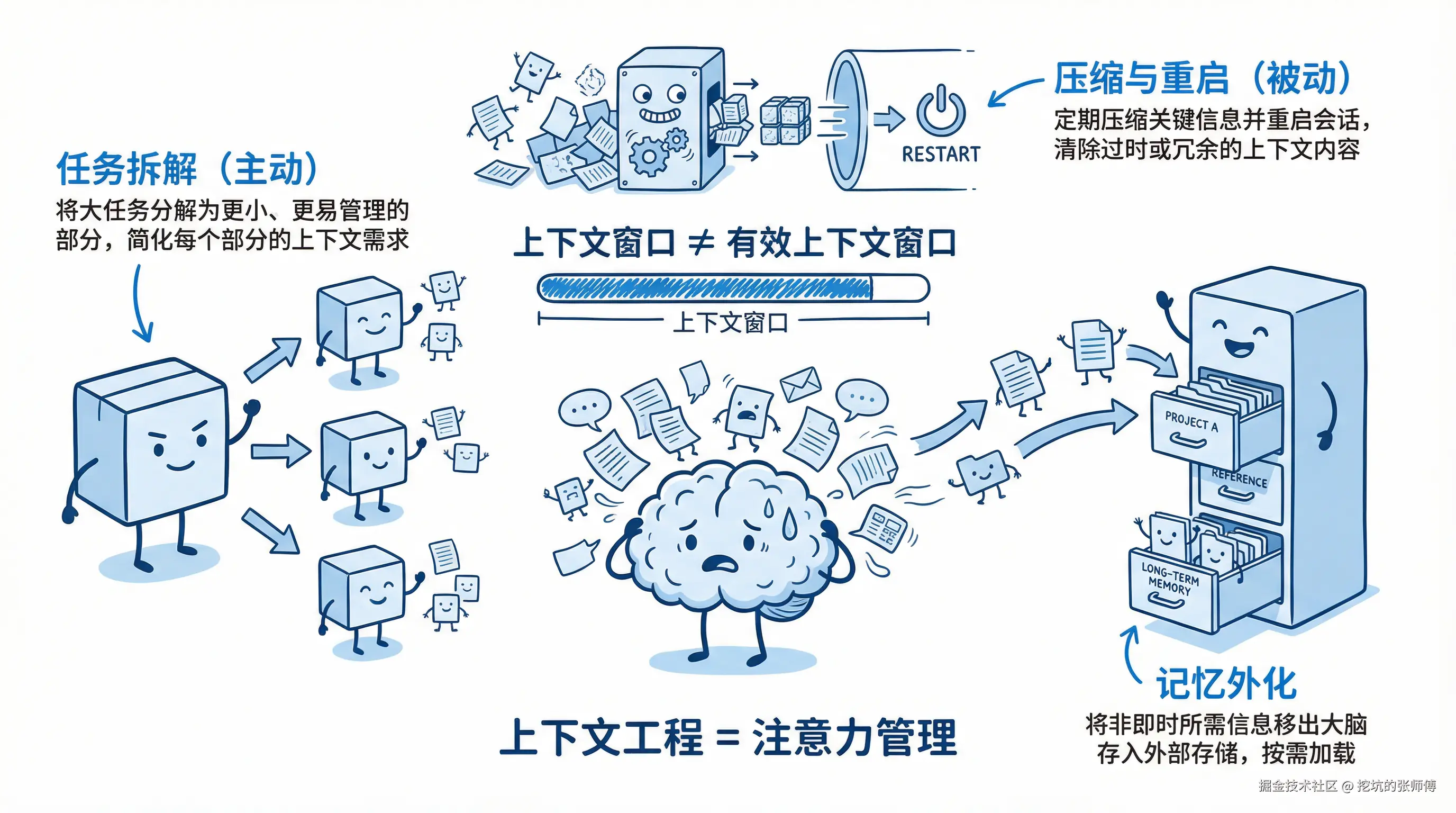
- 任务拆解(主动): 引入分而治之思想,将任务拆解为独立子任务,提供精简的独立上下文。
- 压缩与重启(被动): 监测上下文阈值,主动中断任务,清洗并压缩信息后重启会话。
- 记忆外化: 将记忆从 Context 移至文件系统,按需加载,对抗注意力漂移。
3. 架构实践:Core 与 Scope 的双层解耦架构
3.1 架构设计原则
在构建垂域专家(如 Data Agent)时,我们应该遵循一个简单公式:

试图从零构建一个"全知全能"的Agent是低效的。正确的路径是站在巨人的肩膀上,采用"内核 (Core) - 外壳 (Scope)"的双层解耦架构。
3.2 架构层次详解
这种架构将 Agent 系统解耦为两个层次:
- Core 层(推理内核): 负责纯粹的推理决策。它接收精简的上下文,基于 Coding Agent 的能力生成执行计划(代码、指令)。Core 层不关心用户来源、工具如何执行,只专注于"如何解决问题"。
- Scope 层(环境外壳): 负责环境管理和能力扩展。它管理用户会话、动态加载领域 Skills、维护沙箱执行环境、处理上下文压缩与记忆外化。Scope 层为 Core 屏蔽了现实世界的复杂性。
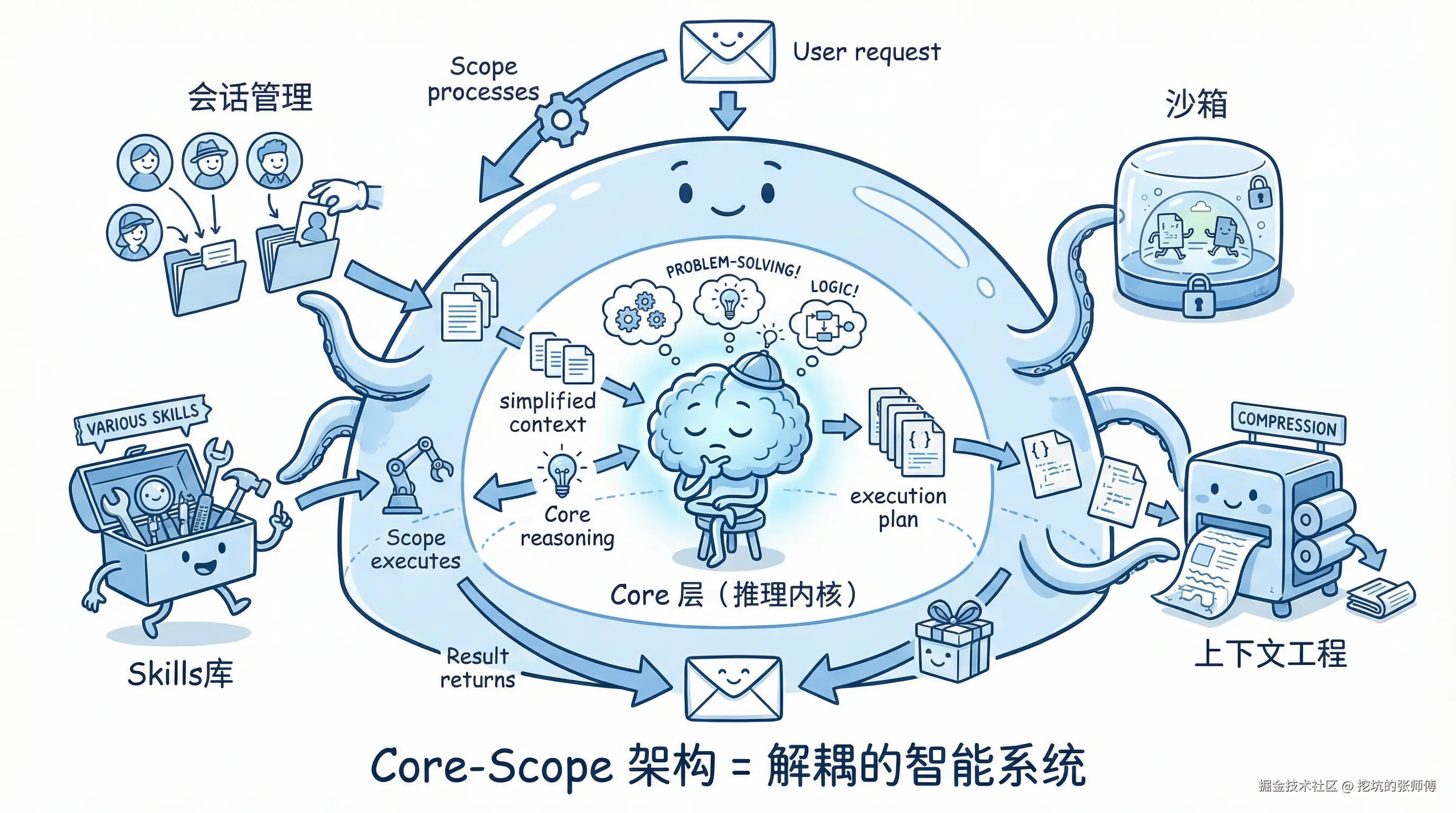
两层协作机制体现了前文提到的核心技术:
- 沙箱隔离: Scope 层为每个会话分配独立沙箱,确保 Core 生成的代码在安全边界内执行。
- 上下文工程: Scope 层负责任务拆解、上下文压缩、记忆外化,为 Core 提供精简的输入。
- Skills 扩展: 通过 Scope 层动态加载领域知识,Core 无需重新训练即可获得垂域能力。
这种架构的价值在于:将 Agent 的能力边界从"模型参数"转移到了"生态丰富度"上。 我们无需重新训练模型,只需丰富 Skills 库。
3.3 实践案例:DataAgent
DataAgent 是基于 Core-Scope 架构构建的数据分析领域专家,用于解决"让不懂 SQL 的用户能用自然语言查询复杂数据库"的问题。

Skills 体系:DataAgent 通过 5 个领域 Skills 扩展能力。
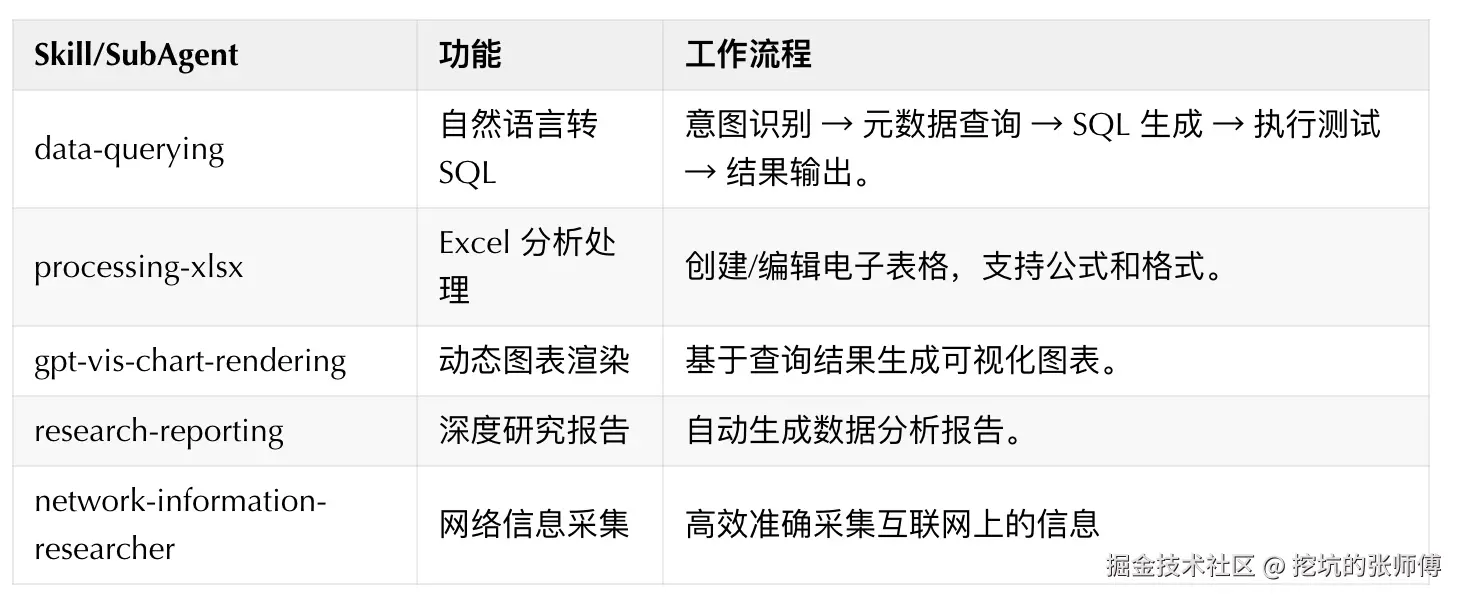
实际效果:相比通用 Coding Agent,DataAgent 在数据分析场景的优势显著:
- 自适应流程: Claude 自主决定执行轮数。简单查询快速响应,复杂查询自动多轮优化。
- 领域知识内置: 内置数据库 schema 和 业务术语字典,减少 SQL 生成的幻觉。
- 安全可控: 通过MCP权限控制,保障数据安全,动态注入行级权限,防止越权访问。
- 端到端能力: 从自然语言查询到 SQL 执行、数据可视化、报告生成,一站式完成。
这个案例展示了 Core-Scope 架构的核心价值:即仅通过 Scope 层的 Skills 和SubAgent扩展,通用 Coding Agent 可以快速转化为垂域专家,而无需重新训练模型和开发Agent,让我们更聚焦于我们的核心能力。
4. 从单 Agent 到多 Agent 生态
上述架构解决了单个 Agent 的能力扩展和垂域适配问题。但在实际工程实践中,我们往往面临更复杂的场景:
- 多 Agent 协作: 不同厂商的 Agent 各有优势(Claude 擅长代码理解,GPT 擅长架构规划,Gemini 擅长长上下文)。
- 动态路由: 根据任务类型选择最适合的 Agent。
- 异构集成: 每个 Agent 都是独立的二进制工具,接口各不相同。
这带来了新的工程挑战:如何统一管理这些异构的 Agent?如何让应用无需关心底层 Agent 的差异?
解决这个问题,需要构建一个统一的 Agent 运行协议层。
5. 工程实践:统一的 Agent 运行通信协议

5.1 多 Agent 集成的挑战
一年前,我们还在通过 Prompt Engineering、ReAct 循环来"手搓" Agent。今天,Claude Code、OpenAI Codex、Gemini CLI 等官方工具展现出惊人的端到端能力,手搓时代正在落幕,集成成为主流。下一代 IDE 比如 conductor、zen-flow、智谱的 ZCode 都采用了这种模式。
现在,"用 Agent"意味着启动一个二进制文件。以 Claude Code 为例,社区的最佳实践是集成官方 SDK(如 claude-agent-sdk-python),而这个 SDK 的底层直接依赖 Claude Code 的二进制可执行文件。模型厂商正在将 Agent 能力封装为黑盒。
这带来了新的挑战:
- 协作编排:如何让多个 Agent 协同工作?
- 模型路由:如何动态选择最适合的模型?
- 生命周期管理:如何保持会话状态、处理崩溃恢复?
我们的角色,正在从 Agent 的创造者 转变为 Agent 的编排者。
5.2 通信方式选择
集成"二进制 Agent"的本质是跨进程通信(IPC)。常见方案各有取舍:
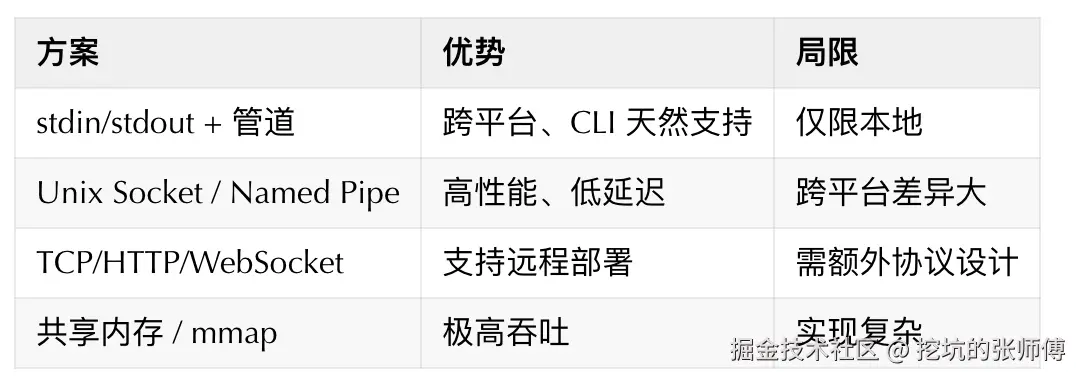
对于 Claude Code 这类「黑盒 CLI」,stdin/stdout + JSON 流是最务实的选择:
- 零侵入:无需修改二进制,以子进程方式启动并接管 I/O
- 天然流式:模型"边想边输出",stdout 天生就是流
- 完全可观测:所有交互可记录、回放、审计
架构模型如下:
arduino
┌──────────────────────┐ ┌──────────────────────┐
│ Your Application │ │ Claude Code CLI │
│ (Adapter Layer) │ │ (binary process) │
└──────────┬───────────┘ └──────────┬───────────┘
│ │
│ spawn process + args │
├────────────────────────────────────>
│ stdin: JSON Commands │
├────────────────────────────────────>
│ stdout: JSON/NDJSON (stream) │
<────────────────────────────────────┤
│ [process exits] │
<────────────────────────────────────┘本质上,我们要做的是 fork 一个进程执行 Agent,然后接管它的 stdin 和 stdout。例如,发送一个初始化请求(Control Request):
json
{
"type": "control_request",
"request_id": "req_1_b6216654-1830-4e89-b088-21631681cbc9",
"request": {
"subtype": "initialize",
"hooks": {}
}
}会得到如下响应(Control Response):
json
{
"type": "control_response",
"response": {
"subtype": "success",
"request_id": "req_1_b6216654-1830-4e89-b088-21631681cbc9",
"response": {
"commands": [
{ "name": "compact", "description": "Clear conversation history..." },
{ "name": "init", "description": "Initialize a new CLAUDE.md file..." }
],
"models": [
{ "value": "opus", "displayName": "Opus" }
],
"account": { "tokenSource": "ANTHROPIC_AUTH_TOKEN" }
}
}
}OpenAI Codex app-server 也提供了类似机制(JSON-RPC 2.0 风格 over stdio):
json
{ "method": "thread/start", "id": 10, "params": { "model": "gpt-5.1-codex" } }
{ "id": 10, "error": { "code": 123, "message": "Something went wrong" } }5.3 ACP on websocket 协议设计
为了统一异构的 Agent 接口,我们需要一个标准协议。经过调研,我们选择基于 ACP(Agent Control Protocol) 作为通信协议的基础,基于 ACP 来扩展我们需要的能力:
ACP 由 IDE 公司 Zed 出品,设计初衷是为代码编辑器服务。回想 IDE 发展史:曾经每个语言都需要为每个编辑器编写专属插件,直到 LSP 出现,彻底解耦了编辑器与语言服务。ACP 正是 Coding Agent 领域的类似尝试。
ACP 解决的是 Agent 与 IDE 之间的"N × M"适配问题。没有协议层,适配工作量是 O(N×M);有了 ACP,降为 O(N+M)。
我们为什么自己重做一个 adapter 层
目前 ACP 的实现较为碎片化------各家 Agent 使用不同语言构建各自的适配层:Claude Code 用 TypeScript,Codex 用 Rust,Kimi 用 Python。这种"各自为政"的现状带来了两个问题:
- 环境依赖复杂:云端沙箱和客户端都需要预装多种语言运行时
- 缺乏远程支持:ACP 官方尚未提供 WebSocket/HTTP 等远程连接方式
为了解决这些问题,我们需要深入 ACP 协议细节,构建统一的适配层。下面简要介绍 ACP 的核心概念。
设计原则
- 灵活传输层:本地通过 stdio 直连,未来支持远程 HTTP/WebSocket
- 精简方法集 :仅保留
session/new、session/prompt、session/update等 5 个核心指令
核心流程
会话建立 :Client 发送 session/new,携带 cwd 和 mcpServers;Agent 初始化环境,返回唯一的 sessionId。
多轮交互 :Client 发送 session/prompt,Agent 通过 session/update 持续推送 message_chunk、tool_call、plan 等事件,直到返回 stopReason。
完整交互示例(NDJSON):
json
{"jsonrpc":"2.0","id":"req_1","method":"session/new","params":{"cwd":"/repo"}}
{"jsonrpc":"2.0","id":"req_1","result":{"sessionId":"sess_01","capabilities":{"stream":true}}}
{"jsonrpc":"2.0","id":"req_2","method":"session/prompt","params":{"sessionId":"sess_01","input":{"text":"Refactor README"}}}
{"jsonrpc":"2.0","method":"session/update","params":{"sessionId":"sess_01","type":"message_chunk","text":"Sure, I will..."}}
{"jsonrpc":"2.0","method":"session/update","params":{"sessionId":"sess_01","type":"tool_call","tool":"read_file","args":{"path":"README.md"}}}
{"jsonrpc":"2.0","id":"req_2","result":{"stopReason":"end_turn"}}因为官方 ACP 尚未支持远程协议,我们现在做的就是将 ACP 暴露为 WebSocket,使 Agent 可以运行在本地或云端,但对外提供标准协议。
5.4 Adapter 层的价值
生命周期管理
CLI 工具是重状态的,你需要处理:进程启动与保活、会话上下文维护、崩溃检测与优雅终止、资源清理与泄漏预防。直接调用意味着这些逻辑散落在业务代码各处。
接口统一
Claude、Codex、Gemini 的输入输出格式截然不同。前端直接对接多个 Agent,业务逻辑将沦为胶水代码的沼泽。
可靠性保障
- 心跳与重连:双向 Ping/Pong 探活,应对网络波动
- 状态恢复:当 Agent 进程意外崩溃时,基于持久化的 Session History 重启进程并重放上下文,实现"无感恢复"
- 会话漂移:通过序列化会话状态,支持 Agent 会话在不同容器或服务器间迁移
可观测性
- 分布式追踪:Agent 的行为往往跨越多个进程和服务(Client → Server → Adapter → CLI Process),没有 Trace ID,排查问题无异于大海捞针
兼容性扩展
- 历史格式转换:支持不同 Agent 间的历史会话格式互转,例如用 Codex 接手 Claude Code 的会话
- API 协议桥接 :很多 Coding Agent 原生绑定 Anthropic API,但企业大概率是使用基于 OpenAI 接口的按量付费。Adapter 可充当中间层,将 OpenAI 请求实时转换为 Agent 指令,对外暴露 OpenAI Compatible 接口
部署便捷性
- Portable Packaging :
- 比如使用
bun compile将 TS 编写的 Adapter 打包为单文件,去掉 node 环境依赖 - 目标:零依赖部署,无需预装 Node.js 或 Python 运行时
- 比如使用
展望
回看编程工具发展史,IDE 曾深陷语言插件碎片化的泥潭,直到 LSP 一统江湖。Coding Agent 正处于"前 LSP 时代"的混沌期。
ACP 的愿景是打破孤岛。 未来的 Agent 应该是遵循 ACP 标准的通用服务,无论 Claude、Codex 还是开源模型,即使不是编程的 Agent,只要实现了 ACP,就能即插即用地接入我们的产品中来。
这才是 Agent 真正的"LSP 时刻"。为 Agent 打造舒适的运行时,可能是接下来最重要的事情。
6. 结语
AI-Native 架构的艺术,在于在不确定性的LLM之上,构建确定性的业务价值。
这不仅是技术的升级,更是思维的跃迁。未来的软件工程师,将不再是代码的搬运工 ,而是智能的编排者、系统的教育者和概率的牧羊人。
(致敬每一个在 AGI 路上探索的同伴,Respect🫡)