GUI智能体如何应对环境变化?------首个GUI持续学习框架GUI-AiF详解
在当今数字化时代,GUI智能体(Graphical User Interface Agents)能够通过自然语言指令在各类数字应用中执行操作,为用户提供极大便利。然而,现实世界的数字环境是不断变化的------新的操作系统版本发布、平台间切换、设备升级带来分辨率变化等。这些变化会导致在静态环境中训练的智能体性能显著下降。本文介绍的GUI-AiF框架是首个针对GUI智能体的持续学习框架,通过创新性的奖励机制使智能体能够在动态变化的GUI环境中保持稳定性能,为解决这一关键问题提供了突破性方案。
论文标题 :Continual GUI Agents
来源 :arXiv:2601.20732v2 cs.LG 29 Jan 2026 + https://arxiv.org/abs/2601.20732
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景:
随着深度学习技术的发展,GUI智能体在自动化数字交互方面取得了显著进展。这类智能体的核心能力是grounding,即将自然语言指令映射到GUI界面上的精确像素坐标。目前主流的训练方法包括监督微调(Supervised Fine-Tuning, SFT)和强化微调(Reinforcement Fine-Tuning, RFT),它们通常在固定的数据集上进行训练,涵盖多种用户界面应用和交互类型。然而,现实世界的数字环境是动态变化的------操作系统更新、平台间迁移(如从移动端到Web端)、设备升级带来分辨率变化(如从1080p到4K)等。这些变化会导致UI交互点的位置和元素尺度发生显著变化,使得在静态环境中训练的智能体难以保持稳定的grounding能力。如Figure 1所示,Continual GUI Agents需要在两种动态场景下工作:域迁移(如从移动OS到Web OS)和分辨率变化(如从1080p扩展到4K)。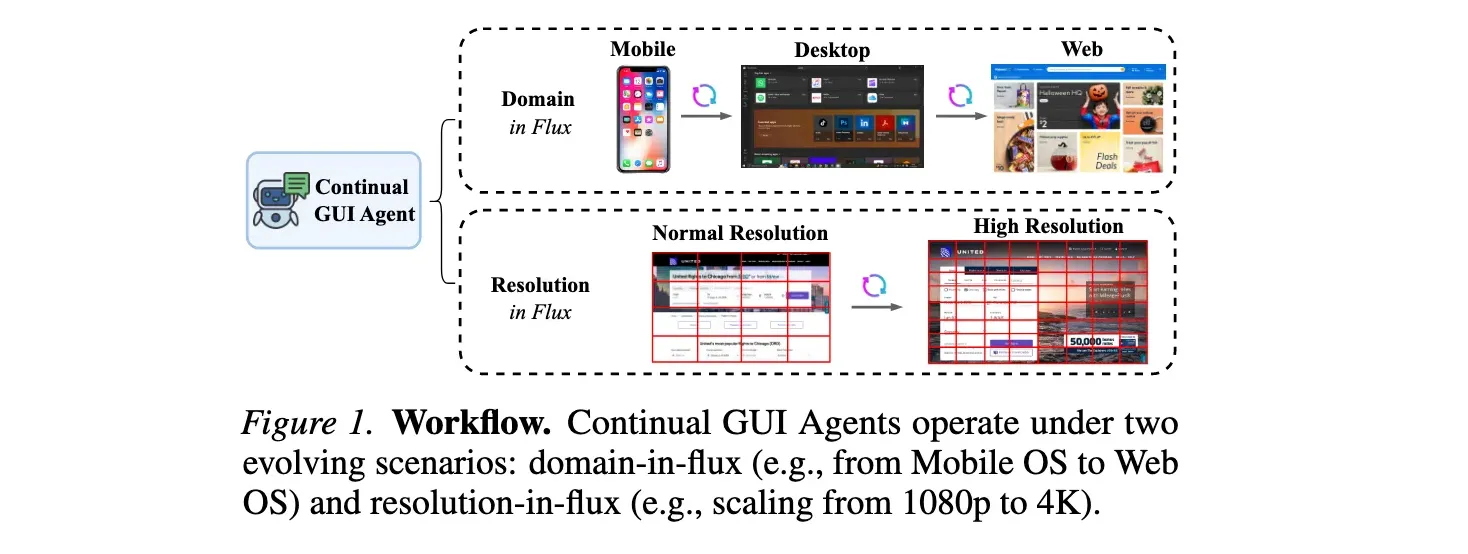
研究问题:
- 动态环境适应性问题:现有方法在GUI分布随时间变化时,难以保持稳定的grounding能力,因为动态场景中UI交互点和区域的多样性导致了性能下降。
- 过度适应静态任务:现有的奖励策略倾向于过度适应静态的grounding线索(如固定坐标或元素尺度),导致智能体在面对新的GUI环境时泛化能力不足。
- 缺乏持续学习框架:目前尚无针对GUI智能体的持续学习框架,无法有效处理域迁移和分辨率变化等动态场景。
主要贡献:
- 首次提出Continual GUI Agents任务:建立了GUI智能体持续学习的新任务设置,提出了两种新颖的持续学习场景------域迁移(Mobile→Desktop→Web)和分辨率变化(Normal→High Resolution),为GUI智能体的持续学习研究奠定了基础。
- 提出GUI-AiF框架:创新性地提出了GUI-Anchoring in Flux (GUI-AiF)框架,在RFT范式下优化grounding策略,通过两个新颖的奖励模块------APR-iF(锚定点奖励)和ARR-iF(锚定区域奖励)来缓解策略在单一任务上的过度适应,增强智能体在迁移UI任务中的持续能力。
- 实现SOTA性能:在ScreenSpot-V1、ScreenSpot-V2和ScreenSpot-Pro三个基准测试上取得了最先进性能,显著超越了现有基线方法,验证了GUI-AiF框架的有效性。
方法论精要
GUI-AiF框架在强化微调(RFT)范式下,通过设计新颖的奖励机制来优化grounding策略,使智能体在动态变化的GUI环境中保持稳定交互能力。框架包含问题建模、双重奖励机制和集成优化三个关键组件。如Figure 2所示,GUI-AiF在Continual GUI Agents流程中推进RFT范式,通过塑造grounding奖励来优化策略:APR-iF鼓励多样化交互点,ARR-iF细化元素区域,两者共同使智能体更好地适应变化的交互位置和元素尺度。
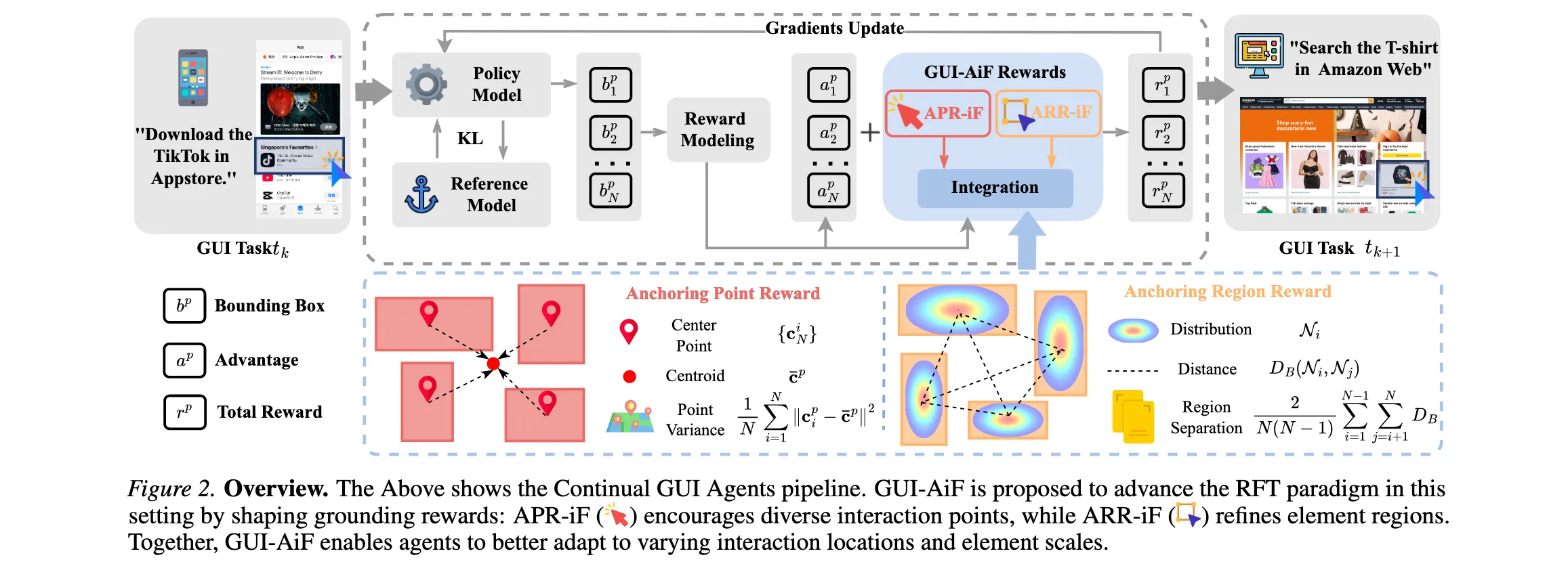
问题建模 :GUI groundings将自然语言指令与图形界面上的交互元素进行像素级对齐。给定界面 s 和指令 和指令 和指令 i , 模型预测边界框 ,模型预测边界框 ,模型预测边界框 b_p = \[x_1\^p, y_1\^p, x_2\^p, y_2\^p\] 。持续 G U I 任务定义为域迁移任务序列 。持续GUI任务定义为域迁移任务序列 。持续GUI任务定义为域迁移任务序列 T_D 或分辨率变化任务序列 或分辨率变化任务序列 或分辨率变化任务序列 T_R , 其中 ,其中 ,其中 T_D = {t_{d1}, t_{d2}, ..., t_{dn}} , , , T_R = {t_{r1}, t_{r2}, ..., t_{rn}} ,要求智能体持续适应GUI任务的动态变化,防止过度适应单一任务。
标准RFT策略 :标准RFT通过比较预测与ground truth计算奖励分数 r_i , 获得一组奖励分数 ,获得一组奖励分数 ,获得一组奖励分数 {r_1, r_2, ..., r_N} ,采用GRPO方法计算相对策略优势: A_i = \\frac{r_i - \\text{Mean}({r_1, r_2, ..., r_N})}{\\text{Std}({r_1, r_2, ..., r_N})} 。这种策略专注于优化当前任务,倾向于在特定GUI布局的坐标和尺度上过度适应,无法有效处理动态环境。
Anchoring Point Reward in Flux (APR-iF) :APR-iF增强智能体泛化交互位置的能力,避免在单一任务的特定坐标上过度适应。对于 N 个预测边界框 个预测边界框 个预测边界框 {b_{p1}, b_{p2}, ..., b_{pN}} , A P R − i F 计算其中心点 ,APR-iF计算其中心点 ,APR−iF计算其中心点 {c_{p1}, c_{p2}, ..., c_{pN}} , 其中每个中心点 ,其中每个中心点 ,其中每个中心点 c_{pi} = \\left(\\frac{x_{1,i}\^p + x_{2,i}\^p}{2}, \\frac{y_{1,i}\^p + y_{2,i}\^p}{2}\\right) , 然后计算质心 ,然后计算质心 ,然后计算质心 \\bar{c}*p = \\frac{1}{N}\\sum* {j=1}\^N c_{pj} , 空间方差 ,空间方差 ,空间方差 R_p = \\frac{1}{N}\\sum_{i=1}\^N \|c_{pi} - \\bar{c}_p\|\^2 。较高的方差表明中心点分布更广,有助于智能体适应不同的交互位置。
Anchoring Region Reward in Flux (ARR-iF) :ARR-iF通过奖励预测边界框之间的空间分离来适应变化的元素尺度。每个预测边界框被建模为高斯分布 N_i(\\mu_i, \\Sigma_i) , 通过 B h a t t a c h a r y y a 距离 ,通过Bhattacharyya距离 ,通过Bhattacharyya距离 D_B 量化两个预测区域之间的分离: D_B(N_i, N_j) = \\frac{1}{8}(\\mu_i - \\mu_j)\^T \\Sigma_{avg}\^{-1}(\\mu_i - \\mu_j) + \\frac{1}{2}\\ln\\frac{\\det(\\Sigma_{avg})}{\\sqrt{\\det(\\Sigma_i)\\det(\\Sigma_j)}} , 其中 ,其中 ,其中 \\Sigma_{avg} = \\frac{\\Sigma_i + \\Sigma_j}{2} 。总区域分离 。总区域分离 。总区域分离 R_r = \\frac{2}{N(N-1)}\\sum_{i=1}^N\\sum_{j=i+1}^N D_B(N_i, N_j) 定义为所有预测对的平均DB距离,激励智能体生成空间上不同的预测区域。
集成奖励和优化 :APR-iF和ARR-iF集成为 R_{AiF} = \\alpha \\cdot R_p + \\gamma \\cdot R_r , 其中 ,其中 ,其中 \\alpha 和 和 和 \\gamma 控制探索强度。目标函数为 控制探索强度。目标函数为 控制探索强度。目标函数为 J(\\theta) = \\mathbb{E}*{\\tau \\sim \\pi* \\theta}\[r_t(\\theta)(A_t + R_{AiF}) - \\beta \\cdot D_{KL}\[\\pi_{ref}(\\cdot\|s_t)\|\|\\pi_\\theta(\\cdot\|s_t)\]\] , 其中 ,其中 ,其中 r_t(\\theta) = \\frac{\\pi_\\theta(a_t\|s_t)}{\\pi_{ref}(a_t\|s_t)} 是当前和参考策略的概率比 , 是当前和参考策略的概率比, 是当前和参考策略的概率比, \\beta 是控制 K L 散度项强度的超参数。 K L 散度项通过测量当前策略 是控制KL散度项强度的超参数。KL散度项通过测量当前策略 是控制KL散度项强度的超参数。KL散度项通过测量当前策略 \\pi_\\theta 与参考策略 与参考策略 与参考策略 \\pi_{ref} 之间的分歧来正则化策略更新 , 之间的分歧来正则化策略更新, 之间的分歧来正则化策略更新, R_{AiF} 作为平衡,鼓励探索多样化的交互点和元素区域,为未来环境波动保留持续学习能力。
实验洞察
研究者在三个主流基准测试上评估GUI-AiF:ScreenSpot-V1(SSv1)、ScreenSpot-V2(SSv2)涵盖移动端、桌面端和Web任务的持续域评估,ScreenSpot-Pro(SSPro)包含6个高分辨率软件界面用于评估持续分辨率性能。Table 1对比了典型GUI Agent和Continual GUI Agent的区别,展示了两种持续学习场景的定义。
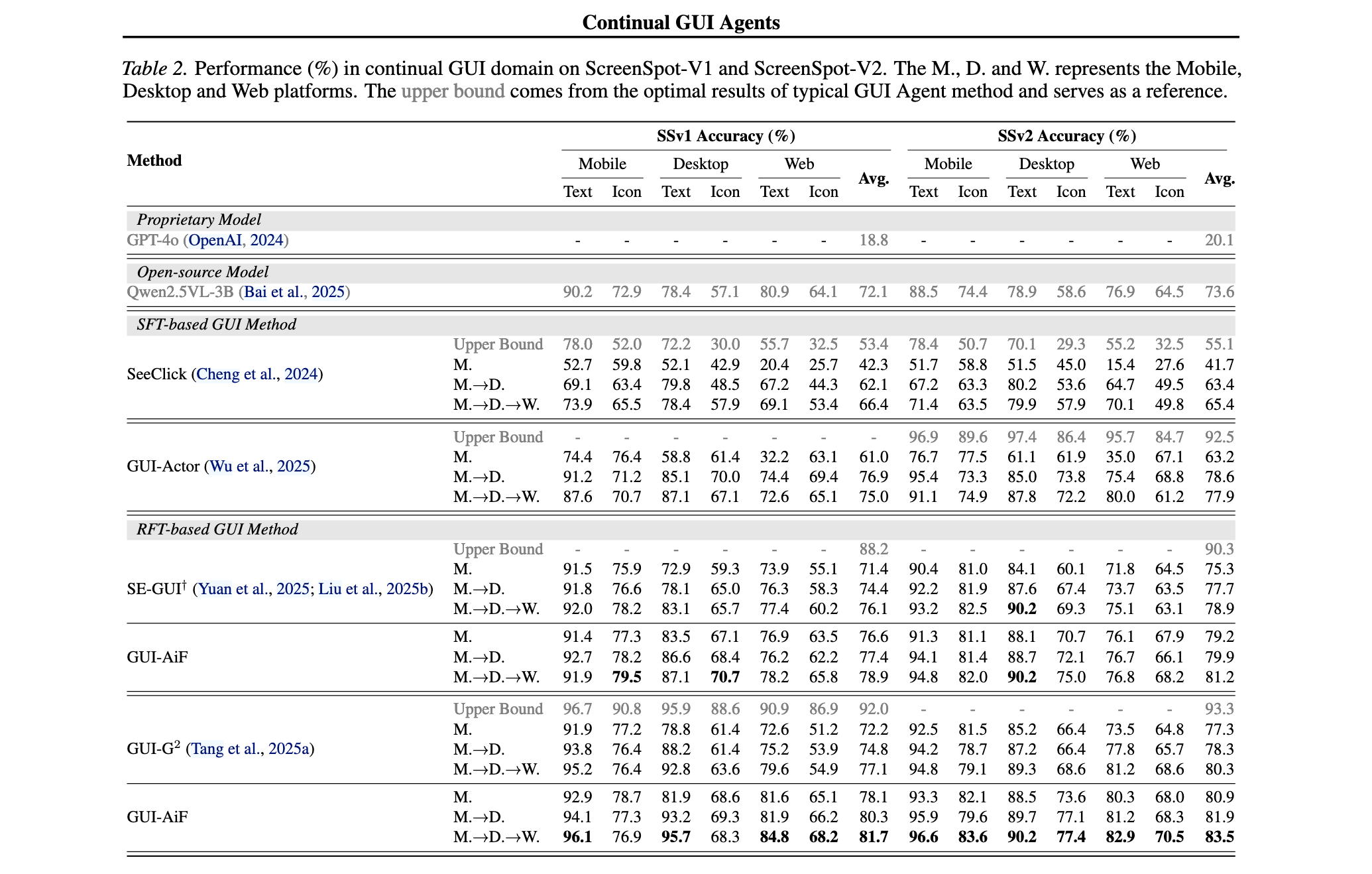
持续域迁移性能 :如Table 2所示,在SSv1和SSv2上,GUI-AiF在域迁移场景下表现出色。专有模型(如GPT-4o)在GUI任务中表现挣扎,SFT方法(SeeClick和GUI-Actor)性能普遍较差,验证了其在单一GUI任务中的过度适应倾向。RFT基线方法(如SE-GUI和GUI-G2)显示出一定适应能力,但GUI-AiF进一步提升了持续性能,增强了智能体面对域迁移时的适应能力。每个任务训练后单域性能增加,表明GUI-AiF能够从已学习任务中累积知识。
持续分辨率迁移性能 :如Table 3所示,在SSPro上,当面对正常到高分辨率迁移时,SFT和RFT基线方法获得完全相同的最终平均准确率,表明现有范式无法固有地处理分辨率变化。GUI-AiF通过促进在元素尺度和位置方面的泛化,增强了智能体应对这一挑战的性能。
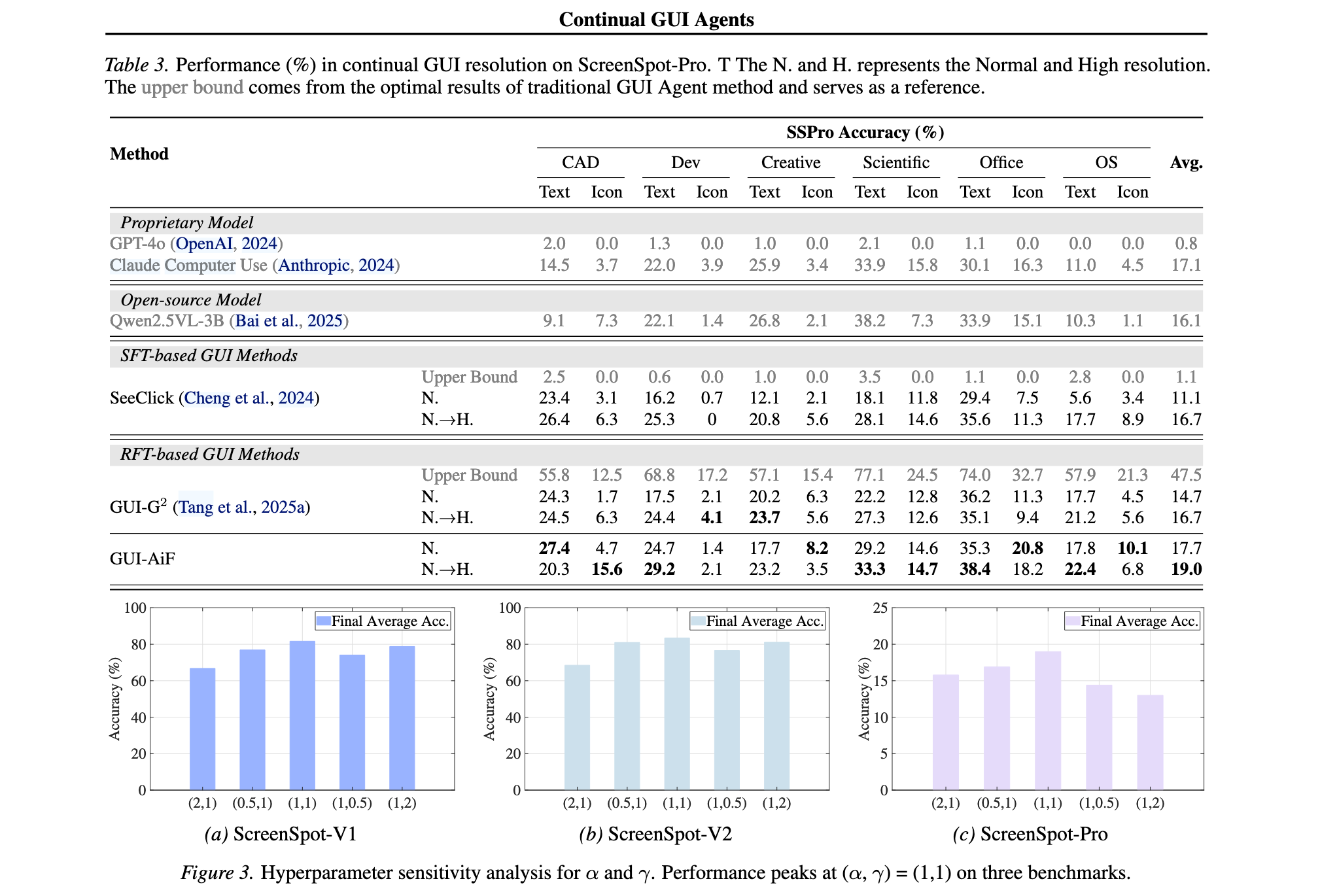
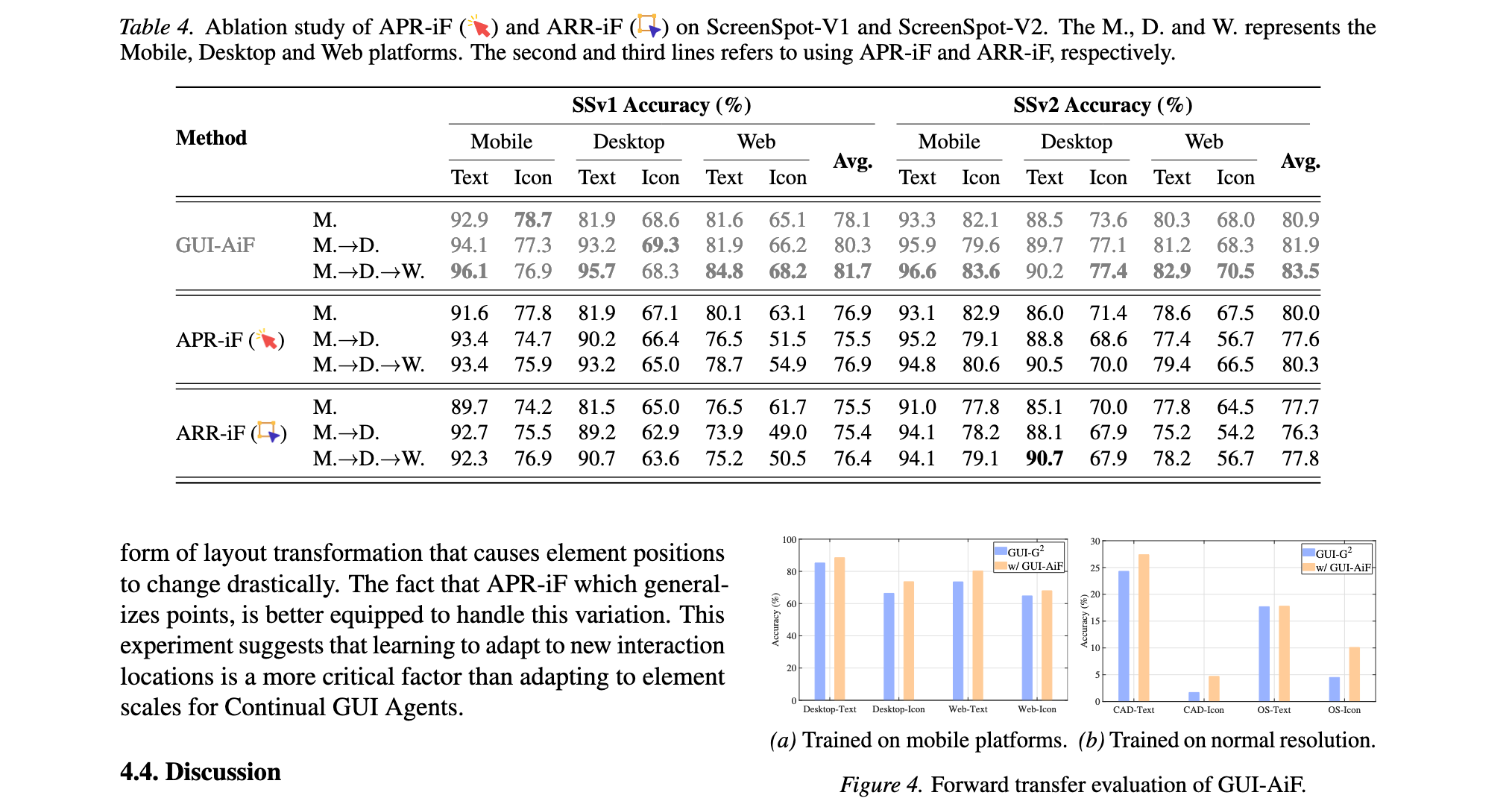
奖励模块消融实验 :如Table 4所示,完整GUI-AiF奖励实现最佳性能,显著超越单独的APR-iF或ARR-iF。APR-iF在SSv1和SSv2上的最终平均准确率优于ARR-iF,表明APR-iF奖励对性能有更显著积极影响。实验表明,学习适应新的交互位置是Continual GUI Agents中比适应元素尺度更关键的因素。
超参数敏感性分析:如Figure 3所示,与APR-iF相关的α在持续GUI域场景中对性能有更大影响,因为域波动更多地体现在对GUI交互点的影响上。在持续GUI分辨率下,γ的变化表达更明显的影响,这是由于更高分辨率导致GUI元素尺度的多样性。
KL散度正则化作用:如Table 5所示,移除KL项会降低GUI智能体的持续学习性能,表明仅追求多样化解决方案是不够的。KL项提供了稳定基础,确保GUI-AiF是grounded的,帮助智能体适应动态GUI任务。
前向迁移评估 :如Figure 4所示,GUI-AiF增强了智能体的前向迁移能力,使其能够利用从先前任务中学到的知识泛化到后续任务。在移动平台训练后,GUI-AiF在后续桌面和Web平台上的性能超过相应基线,类似改进也出现在分辨率迁移场景中。
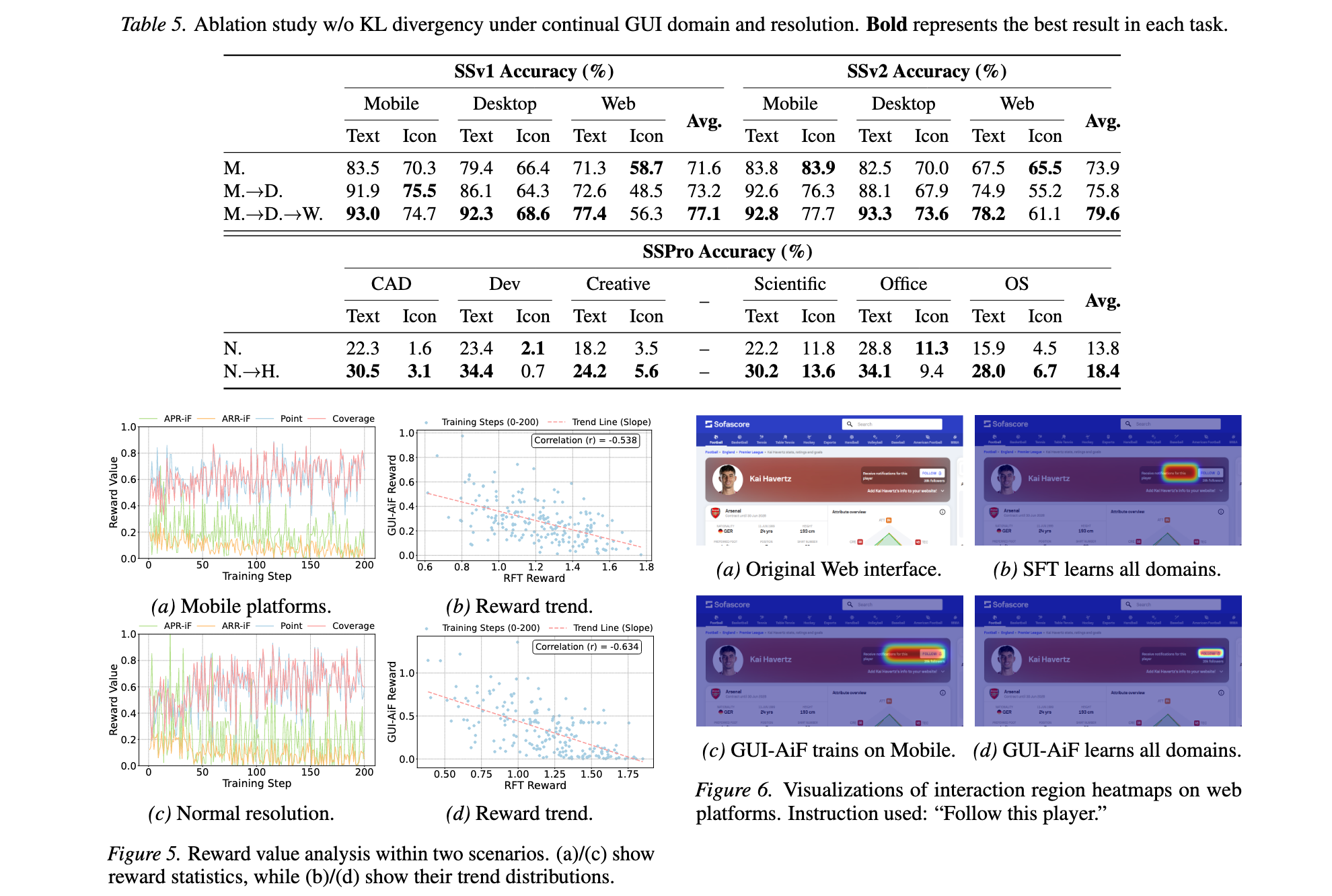
奖励对比分析:如Figure 5所示,APR-iF在每个任务内的波动比ARR-iF更显著,表明交互点的探索起更关键作用。GUI-AiF的奖励值与RFT的奖励值之间存在反比关系,旨在促进泛化的奖励和专注于优化当前任务性能的奖励相互冲突。
可视化对比:如Figure 6所示,Web界面指令"Follow this player"的热力图显示,SFT基线未能定位正确交互区域,而GUI-AiF通过持续学习能够根据指令准确定位区域,展示了精炼grounding的能力。
文本与图标交互偏差:如Figure 7所示,实验结果显示GUI智能体在基于文本的交互上存在偏差,基于文本的任务性能始终高于基于图标的任务。这是由于智能体视觉分支默认为强大的OCR能力进行文本理解,而图标在语义上模糊且缺乏直接的文本grounding。