🏗️ 摘要 :本文通俗解读了论文《Deep Sparse Representation-based Classification》的核心思想。该算法将深度学习的特征提取能力与稀疏表示分类(SRC)的鲁棒性相结合。本文重点剖析了 DeepSRC 如何通过非线性映射解决传统 SRC 线性假设失效的问题,并对网络结构及三大核心损失函数公式进行了详细拆解。
目录
[🎯一、深度解析:DeepSRC 究竟解决了什么?](#🎯一、深度解析:DeepSRC 究竟解决了什么?)
[1.1 传统 SRC 的本质痛点:线性假设的失效](#1.1 传统 SRC 的本质痛点:线性假设的失效)
[1.2 DeepSRC 的核心洞察:非线性映射 -> 线性空间](#1.2 DeepSRC 的核心洞察:非线性映射 -> 线性空间)
[2.1 DeepSRC 的总损失函数](#2.1 DeepSRC 的总损失函数)
[Part 1: 重构损失 (Reconstruction Loss)](#Part 1: 重构损失 (Reconstruction Loss))
[Part 2: 预测/表示误差 (Prediction Error) ------ 最关键的一项](#Part 2: 预测/表示误差 (Prediction Error) —— 最关键的一项)
[Part 3: 稀疏约束 (Sparsity Constraint)](#Part 3: 稀疏约束 (Sparsity Constraint))
[✨三、 算法工作流程](#✨三、 算法工作流程)
🎯一、深度解析:DeepSRC 究竟解决了什么?
在人脸识别和图像分类领域,稀疏表示分类 (SRC) 曾经是红极一时的算法。但随着研究深入,人们发现它在处理复杂真实数据时存在理论上的局限性。
1.1 传统 SRC 的本质痛点:线性假设的失效
你可能会听到 SRC 的缺点是"对光照、遮挡敏感",但这只是表象。其根本的理论缺陷 在于对数据的线性假设。
-
SRC 的数学前提 :SRC 假设同一类的样本位于一个低维线性子空间 (Linear Subspace) 中。
-
公式
本质上是在说:测试样本
-
直观理解:如果我能用"张三"的几张旧照片拼出这张新照片,那这张照片大概率就是张三。
-
-
现实的残酷 :真实世界的高维图像数据(如人脸),通常分布在一个高度弯曲的非线性流形 (Non-linear Manifold) 上。
-
例子:一个人的侧脸(姿态变化)或者从亮变暗(非线性光照模型),很难简单地通过几张正脸照片"加加减减"(线性组合)拼出来。
-
结论:当数据分布是非线性的,而你强行用线性模型(SRC)去拟合,误差自然会很大。
-
1.2 DeepSRC 的核心洞察:非线性映射 -> 线性空间
DeepSRC 并没有抛弃 SRC 的线性组合思想,而是通过引入深度学习来拯救这个假设。
DeepSRC 提出:如果原始数据是非线性的,那我们就造一个空间,让它变线性!
它设计了一个端到端(End-to-End)的神经网络,结构类似于一个"三明治":
-
编码器 (Encoder) ------ "流形展开":
-
它的作用不仅仅是提取特征,更是将位于非线性流形上的原始图片,映射到一个新的潜在空间。
-
关键点 :在这个新空间里,特征变得更加"平坦",使得线性组合
-
-
稀疏编码层 (Sparse Coding Layer) ------ "线性重构":
- 在这个经过编码器"矫正"过的空间里,放心大胆地使用 SRC 逻辑进行拼凑。
-
解码器 (Decoder) ------ "信息保真":
- 确保在这个映射过程中,没有丢失能够区分个体身份的关键信息。
💡二、核心公式详解 (数学原理)
DeepSRC 的精髓在于它的损失函数设计。理解了它的 Loss Function,就理解了它如何强制网络学习到一个"线性"的特征空间。
论文将优化目标拆解为三部分,由于深度学习通常进行批量(Batch)训练,而在论文中是进行矩阵的运算,所以这里的误差项使用 Frobenius 范数。
【补充】:F 是 Frobenius范数 的下标,‖·‖_F 表示矩阵的 Frobenius 范数。我详细解释一下:

例子:

2.1 DeepSRC 的总损失函数
DeepSRC 引入了神经网络编码器 ,将图片映射为特征
。其训练的总损失函数
如下:
我逐项解释:
Part 1: 重构损失 (Reconstruction Loss)
-
含义 :别把图片"学坏了"。
-
作用 :这部分本质上是一个 AutoEncoder (自编码器) 的损失。它保证了编码器
Part 2: 预测/表示误差 (Prediction Error) ------ 最关键的一项
-
含义 :强迫特征空间满足线性假设。
-
深度解读:
-
-
这个公式强制要求:虽然原始图片
-
这正是 DeepSRC 解决"线性假设失效"手段的数学体现。它倒逼编码器去寻找那样一种映射,使得输出的特征符合线性关系。
-
Part 3: 稀疏约束 (Sparsity Constraint)
-
含义 :用的样本越少越好。
-
作用:这是 SRC 的灵魂。它约束系数矩阵 c 必须是稀疏的(L1 范数),确保分类的判别性(Discriminative),即只用同类样本来表示测试样本。
✨三、 算法工作流程
当模型训练好之后,在测试阶段的流程如下:
-
特征提取 : 输入一张待测图片
-
稀疏求解 : 利用训练好的字典
-
残差分类: 计算每个类别的重构残差。
-
比如,只保留系数
-
哪个类别还原得最好(残差最小),图片就属于哪一类。
-
**💎**四、实验结果:小样本下的王者
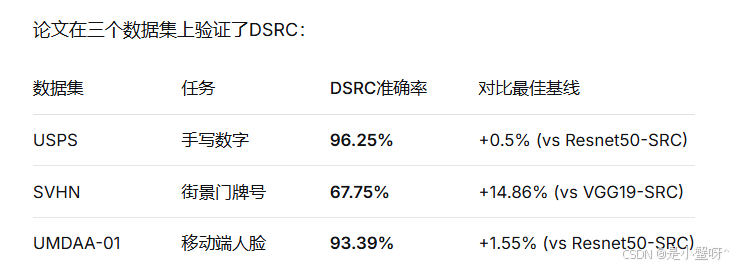
核心发现:
-
小样本优势明显:当训练数据有限时,DSRC显著优于直接使用预训练网络
-
非线性捕捉能力强:对SVHN这种复杂数据提升最大
-
特征学习与稀疏编码协同:编码器学会的特征特别适合稀疏表示
一句话总结: DeepSRC 并不是推翻了 SRC,而是拯救了 SRC。它通过深度神经网络将复杂的、非线性的真实数据,"熨平"到了一个适合 SRC 发挥作用的线性特征空间中。
🚀五、总结
下面这段话,个人感觉写的很好,送给看到这里的每一位志同道合的人。
DSRC的研究向我们展示了一个令人兴奋的方向:不是用深度学习取代传统算法,而是用深度学习实现和增强传统算法的核心思想。
在追求SOTA(state-of-the-art)的竞赛中,我们有时会忘记:最好的创新往往不是完全抛弃过去,而是在理解深刻原理的基础上,用新技术赋予它新生。
稀疏表示的思想诞生于信号处理,兴盛于压缩感知,现在在深度学习的框架下找到了新的表达形式。这或许提醒我们:在AI研究的道路上,既要仰望星空(探索新架构),也要脚踏实地(理解基础原理)。