告别云端 API,语音识别也能跑在树莓派上?
还在为语音识别的高延迟、隐私泄露、API 调用费用发愁吗?来自 Moonshine AI 的开源项目 Moonshine Voice 给出了一个令人惊艳的答案 ------ 一个完全运行在本地设备上的实时语音识别工具包,无需联网、无需 API Key、无需账号注册,开箱即用。
项目地址: github.com/moonshine-a...
Star 数: 6.6K | Fork 数:307 | 协议:MIT(核心代码)
项目亮点速览
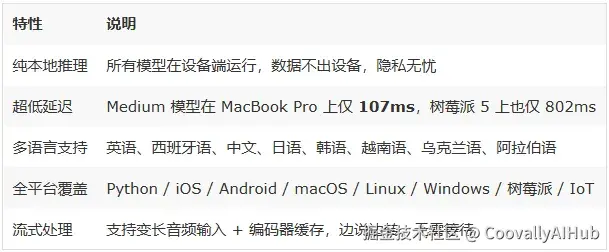
为什么说它是 Whisper 的强力替代?
Moonshine 直击 OpenAI Whisper 的四大痛点:
- 告别 30 秒固定窗口
Whisper 要求 30 秒音频块输入,短音频需要大量填充浪费算力。Moonshine 支持任意长度音频,短句识别零浪费。
- 智能缓存机制
Whisper 流式场景下反复处理相同音频片段,Moonshine 通过编码器输出缓存实现增量处理,效率飙升。
- 专精优于泛化
Whisper 号称支持 82 种语言,但非英语准确率大幅下降。Moonshine 采用单语专精模型策略,每种语言都有针对性优化。
- 统一跨平台体验
不再为每个平台单独适配,Moonshine 提供一套 API 通吃全平台。
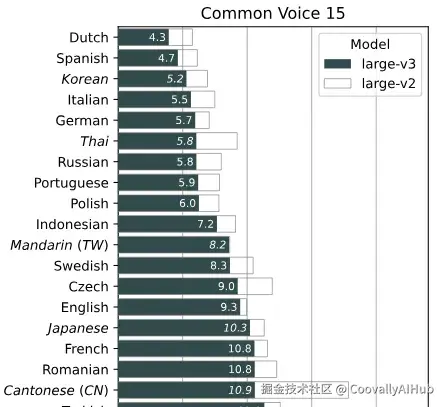
性能实测:数据说话

关键数据:
- 准确率更高: Medium 模型 WER 6.65%,优于 Whisper Large v3 的 7.44%
- 速度快 100 倍: 107ms vs 11,286ms,差距超过两个数量级
- 模型小 6 倍: 245M vs 1.5B 参数,轻松部署到边缘设备
- Tiny 模型仅 26MB,树莓派上也能做到 237ms 实时响应
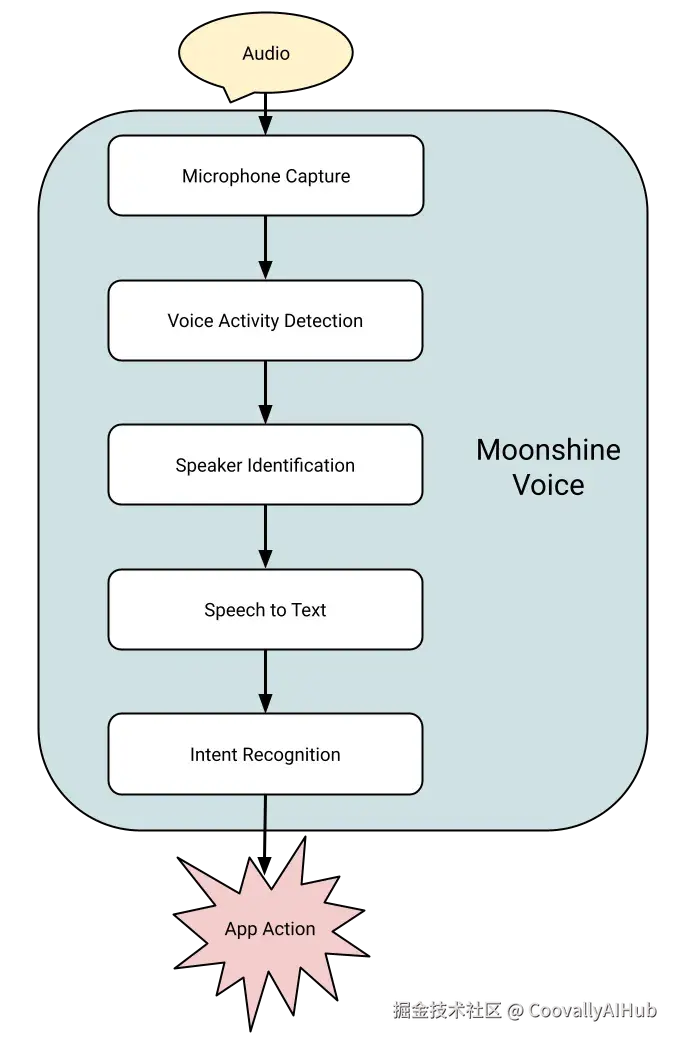
核心架构:不止于语音转文字
Moonshine 不只是一个 ASR 引擎,它是一个完整的语音应用开发套件,集成了:
- VAD(语音活动检测): 自动判断用户是否在说话
- Speech-to-Text: 核心语音转文字能力
- Speaker ID(说话人识别): 区分不同说话者
- Intent Recognition(意图识别): 语义级别的指令匹配
开发者通过事件驱动的方式使用:
bash
# 创建转录器 → 监听事件 → 响应回调
pip install moonshine-voice
python -m moonshine_voice.mic_transcriber --language en三行命令即可启动实时麦克风转录,开发体验极其流畅。
适用场景
- 智能硬件 / IoT: 树莓派、智能音箱、车载设备等算力有限场景
- 隐私敏感应用: 医疗记录、法律咨询、企业内部会议纪要
- 实时交互: 语音助手、实时字幕、语音指令控制
- 离线环境: 无网络覆盖的工厂、野外作业场景
- 移动端应用: iOS / Android 原生集成,适合移动开发者
快速上手
Python 环境一键体验:
bash
# 安装
pip install moonshine-voice
# 启动实时麦克风转录
python -m moonshine_voice.mic_transcriber --language en
# 启动意图识别
python -m moonshine_voice.intent_recognizer移动端 & 桌面端: 项目提供 iOS、Android、macOS、Windows、树莓派的预编译示例,支持原生包管理器安装。
许可证说明

核心能力完全 MIT 开源,商业落地无顾虑。
写在最后
Moonshine 的出现,让我们看到了端侧 AI 语音识别的真正潜力 ------ 不是简单地把云端模型压缩到设备上,而是从架构层面重新思考了边缘场景下的语音处理该怎么做。比 Whisper Large v3 更准、快 100 倍、小 6 倍,还能跑在树莓派上,这组数据足以让任何做语音应用的开发者心动。
如果你正在寻找一个低延迟、高精度、全平台、保隐私的语音识别方案,Moonshine 绝对值得一试。
项目地址: github.com/moonshine-a...
社区支持:Discord 社区