Transformer 详解
by @Laizhuocheng GitHub项目:AI-From-Zero
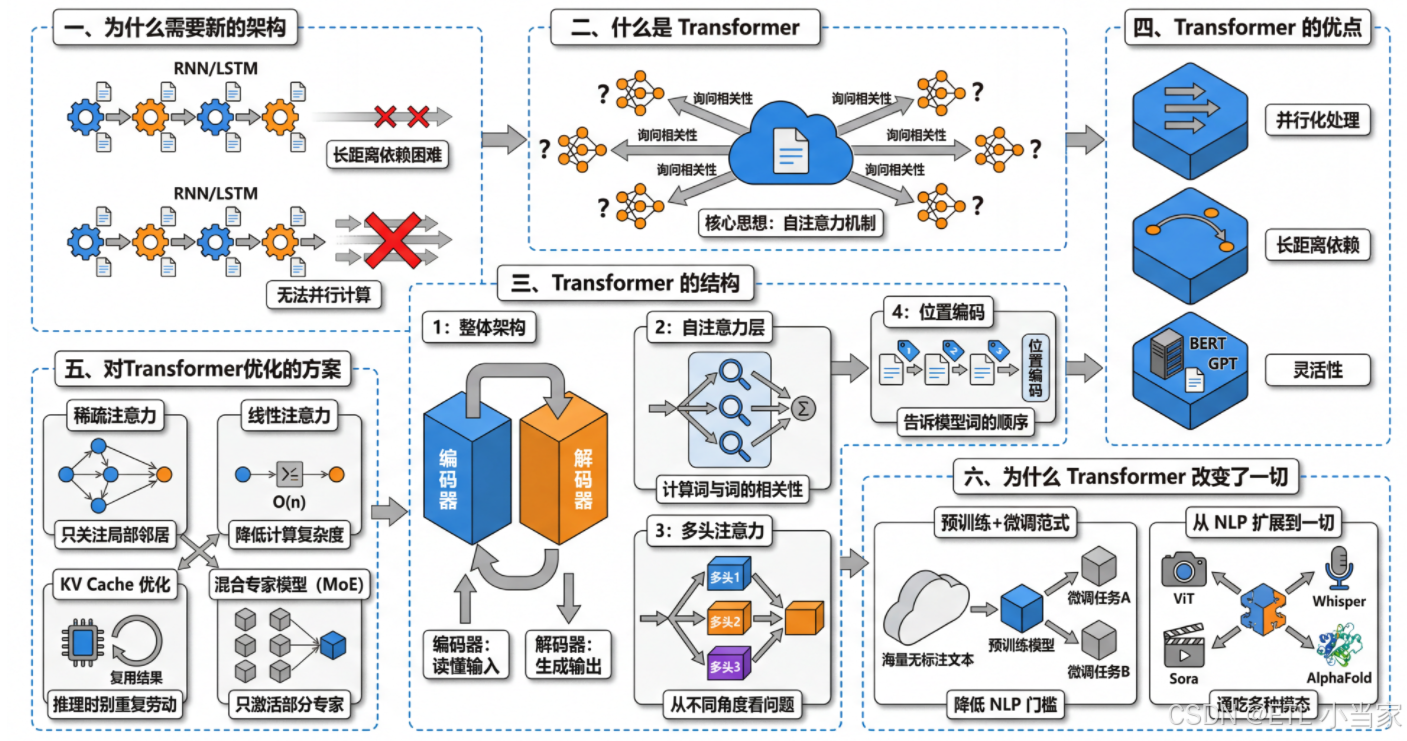
一、为什么需要新的架构
在 Transformer 出现之前,处理文本的主流方法是 RNN 及其改进版 LSTM。它们有几个比较头疼的问题。
第一是长距离依赖的困难。 RNN 像是一个传话游戏------信息从句子开头一个词一个词往后传,传到后面的时候,前面的内容可能已经模糊了。虽然 LSTM 通过"门控"机制缓解了这个问题,但面对很长的文本时,开头的信息依然容易被稀释。比如一篇文章第一段提到的人名,到了第十段模型可能已经"记不太清"了。
第二是无法并行计算。 RNN 必须按顺序处理,处理完第一个词才能处理第二个,处理完第二个才能处理第三个。这意味着不管你有多少块 GPU,都没办法同时计算整个句子,训练速度被严重限制。
二、什么是 Transformer
Transformer 是一种处理序列数据(比如文本)的神经网络架构,2017 年由 Google 提出,现在几乎所有大语言模型都基于它。
它的核心思想其实很直观:当模型在理解一个词的时候,需要知道这个词和句子里其他词的关系。比如"苹果很好吃"和"苹果发布新手机"里的"苹果"意思完全不同,模型需要看上下文才能判断。
Transformer 用一种叫"自注意力"的机制来做这件事------它让句子里的每个词都去"询问"其他所有词:"你和我有多相关?"然后根据相关程度来汇总信息。这样,无论两个词相隔多远,都能直接建立联系。
三、Transformer 的结构
3.1 整体架构:编码器-解码器
Transformer 分为两大块:编码器 负责"读懂"输入,解码器负责"生成"输出。
假设我们要把"我喜欢猫"翻译成英文。编码器先把"我/喜欢/猫"这三个词读一遍,理解整句话的意思,形成一组"理解向量";然后解码器根据这组向量,一个词一个词地生成"I like cats"。
3.2 自注意力层:理解词与词的关系(计算相关性)
这是 Transformer 的核心。编码器在处理每个词时,会计算它与句中所有词的相关性。
比如处理"喜欢"这个词时,模型会问:"我"和"喜欢"有多相关?"猫"和"喜欢"有多相关?然后把相关的信息汇总起来,形成对"喜欢"更丰富的理解------它知道了是"我"在喜欢,喜欢的对象是"猫"。
3.3 多头注意力:从不同角度看问题
单一的注意力可能只捕捉一种关系,所以 Transformer 用"多头"机制,同时跑多组注意力计算。
可以想象成几个人同时阅读同一句话:一个人专注于语法关系(谁是主语、谁是宾语),另一个人专注于语义关系(动作和对象的搭配),还有人关注指代关系。最后把他们的理解综合起来,得到更全面的结果。
3.4 位置编码:告诉模型词的顺序
自注意力机制本身不知道词的先后顺序------"猫喜欢我"和"我喜欢猫"在它眼里是一样的。所以 Transformer 在输入时给每个词加上一个"位置编码",相当于给每个词贴上座位号,这样模型就知道谁在前谁在后了。
四、Transformer 的优点
| 优点 | 说明 |
|---|---|
| 并行化处理 | 与 RNN 不同,Transformer 不需要按顺序处理数据,因此可以更好地利用 GPU 进行并行计算,提高训练速度 |
| 长距离依赖 | 自注意力机制使得 Transformer 能够有效捕捉序列中远距离的依赖关系 |
| 灵活性 | Transformer 可以很容易地扩展到更大的模型(如 BERT、GPT 等),并在多种 NLP 任务中表现出色 |
五、目前有什么对 Transformer 优化的方案?
Transformer 虽然强大,但也有一个明显的瓶颈:自注意力的计算量和序列长度的平方成正比。句子有 1000 个词,就要算 100 万次注意力;如果是 10000 个词,就变成 1 亿次。处理长文本时,计算和内存消耗都会爆炸。
针对这个问题,主流优化方向有以下几种:
5.1 稀疏注意力:不是每个词都要看所有词
Longformer、BigBird 等模型的思路是:大部分词只关注局部邻居,只有少数"全局词"才关注整个序列。就像开会时,普通员工只和邻座交流,只有主持人需要关注全场。这样计算量从平方级降到接近线性。
5.2 线性注意力:换一种数学方式算
通过改变注意力分数的计算方式,把复杂度从 O(n²) 降到 O(n)。代价是表达能力可能略有下降,但对于很长的序列来说是值得的权衡。
5.3 KV Cache 优化:推理时别重复劳动
生成文本时,模型是逐词输出的。如果每生成一个新词都重新算一遍前面所有词的 Key 和 Value,太浪费了。KV Cache 把之前算过的结果存起来复用,大幅加速推理。
5.4 混合专家模型(MoE):不是所有参数都要参与
把模型拆成很多"专家"模块,每次只激活其中一部分。比如模型有 1000 亿参数,但每个词只用到其中 100 亿。这样既保持了大模型的能力,又控制了实际计算量。
六、为什么 Transformer 改变了一切
6.1 "预训练+微调"范式的确立
BERT 和 GPT 系列证明了一条路:先用海量无标注文本预训练,让模型学会语言的通用规律,然后用少量标注数据微调到具体任务。这意味着不再需要为每个任务从头训练,极大降低了 NLP 应用的门槛。Transformer 的强大表示能力是这条路能走通的基础。
6.2 从 NLP 扩展到一切
Transformer 的影响早已超越文本:
| 领域 | 应用 | 说明 |
|---|---|---|
| 计算机视觉 | Vision Transformer (ViT) | 把图片切成小块当作"词"来处理,在图像分类上媲美甚至超越了 CNN |
| 语音识别 | Whisper | 基于 Transformer 架构的语音识别模型 |
| 视频生成 | Sora | 用 Transformer 处理时空序列 |
| 生物科学 | AlphaFold | 蛋白质结构预测采用 Transformer 架构 |
一种架构通吃多种模态,这在深度学习历史上是第一次。