在大型项目中,如果项目出现性能瓶颈,我们该如何快速从内存泄露、CPU、IO、锁、网络几个层面来突破
内存泄露排查
如何导致内存泄露
僵尸进程
子进程退出后父进程不回收且没有设置子进程SIGCHILD为SIG_IGN让子进程自己被操作系统回收,就会一直处于僵尸进程,导致PCB内存一直占用导致内存泄露。
这个内存泄露和其他的比较特别,我直接在这里讲解怎么排查:我们直接用ps搜索即可,通过下面两条指令可以查看僵尸进程数量,如果数量迟迟很高,那么说明有问题。
bash
# 1. 查看所有僵尸进程
ps aux | awk '$8=="Z" {print $0}'
# 2. 统计僵尸进程数量
ps -eo stat | grep -c "^Z"文件描述符泄露
这个也比较特别,文件开了没有关,导致文件描述符被占满,最后导致后续申请文件描述符没有多的了。出现内存泄露。更多出现在网络编程里面,使用了socket编程没有关闭链接等导致。如果使用C++IO库,创建的stream对象在生命周期结束后会自动关闭文件描述符。
这个我也直接在这讲解了:
首先我们给一个fd泄露的代码
cpp
#include<thread>
#include<sys/types.h>
#include<sys/socket.h>
using namespace std;
int main(){
while(true){
this_thread::sleep_for(chrono::milliseconds(1000));
int fd = socket(AF_INET,SOCK_DGRAM,0);
}
return 0;
}我们可以直接通过/proto/<pid>/fd来查看
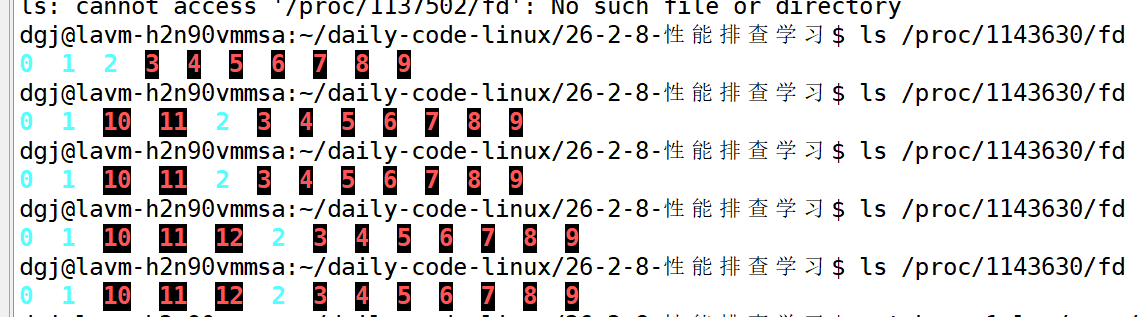
此时发现有异常的fd。我们就可以知道有fd泄露了。
线程栈泄露
我们创建线程后,没有最后使用join导致线程栈迟迟未被回收,此时就会导致内存泄露
这个多发生于pthread库使用。
如果是C++的并发库则不会,如果没有join程序跑起来会直接报错终止。而且C++20加入了jthread析构时自动join线程。
new了没delete
这个是我们最常见的错误,导致堆区内存迟迟不释放。排查方式下面统一讲。
避免方式就是使用智能指针。
mmap了没munmap
这个也是比较容易出错的,导致共享区内存不释放。排查方式下面统一讲。
避免方式还是智能指针
shared_ptr循环引用
这个是智能制造使用是出现的循环引用问题,这个下面单独讲
内存可能短时间内不会带来什么影响,如果内存泄露,最后内存不足,就会导致大量的内存进行swap交换,造成严重的性能下降。最后内存swap交换区也塞不下,导致服务器被杀掉。这是很严重的事情。因此我们需要相关工具来排查。
我们先来写一个内存泄露的代码:
cpp
#include<thread>
#include<vector>
#include<sys/mman.h>
using namespace std;
int main(){
vector<void*>vec;
unsigned long long gap=0;
while(true){
this_thread::sleep_for(chrono::milliseconds(100));
void* arr = mmap(nullptr,4*1024,PROT_READ|PROT_WRITE,MAP_ANON|MAP_PRIVATE,-1,0);
if(gap&3)munmap(arr,4*1024);
++gap;
}
return 0;
}每四次我们就不回收一次内存。这样就会出现内存泄露
top/htop
top
是比较轻量级的查看动态资源的工具。他也可以用于CPU等资源占比的查看,这里我们先介绍内存的
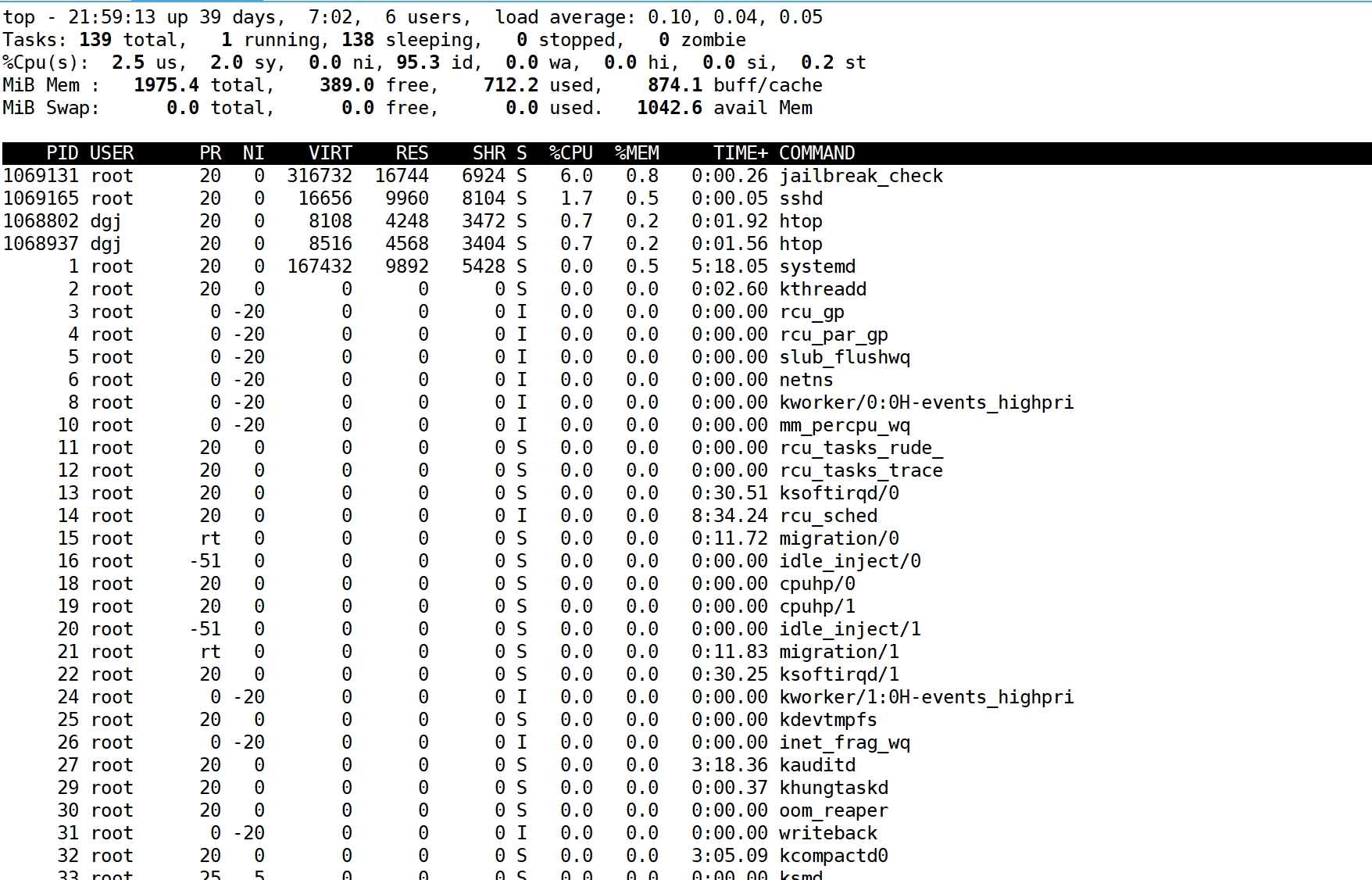
top是黑白的,界面不是特别友好,但是还是可以看出内存占比高低

通过这些选项可以进行不同的操作
htop
htop是比top更高级的工具,界面更加可视化
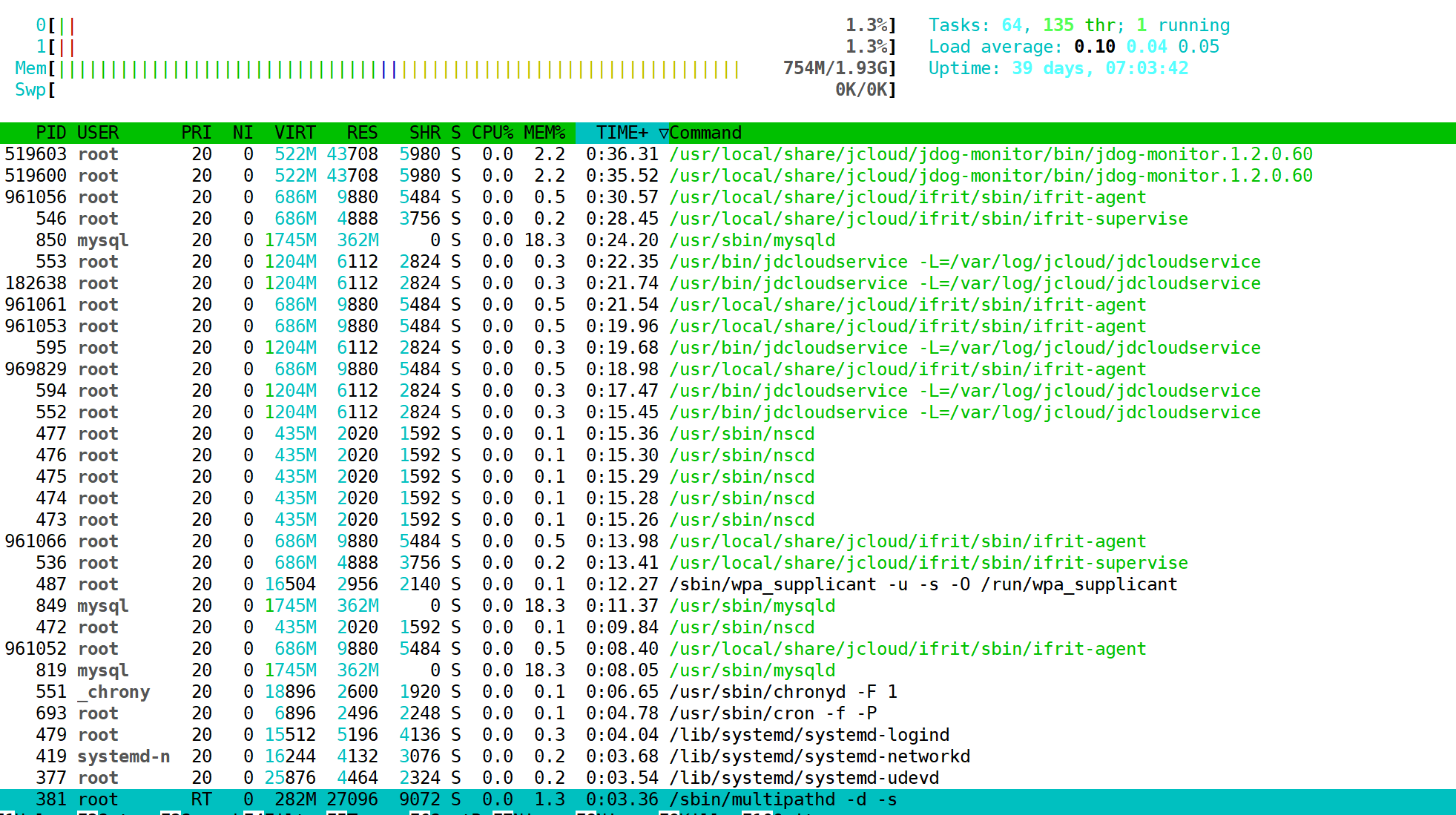

不需要手动输指令选项,通过FN来操作。大家可以自行尝试,这里不做详解了,因为大家只要按一遍就知道怎么操作了。
通过top/htop我们就可以看到内存占比比较大的进程了,如果内存持续上升我们就要重点关注某些进程了。
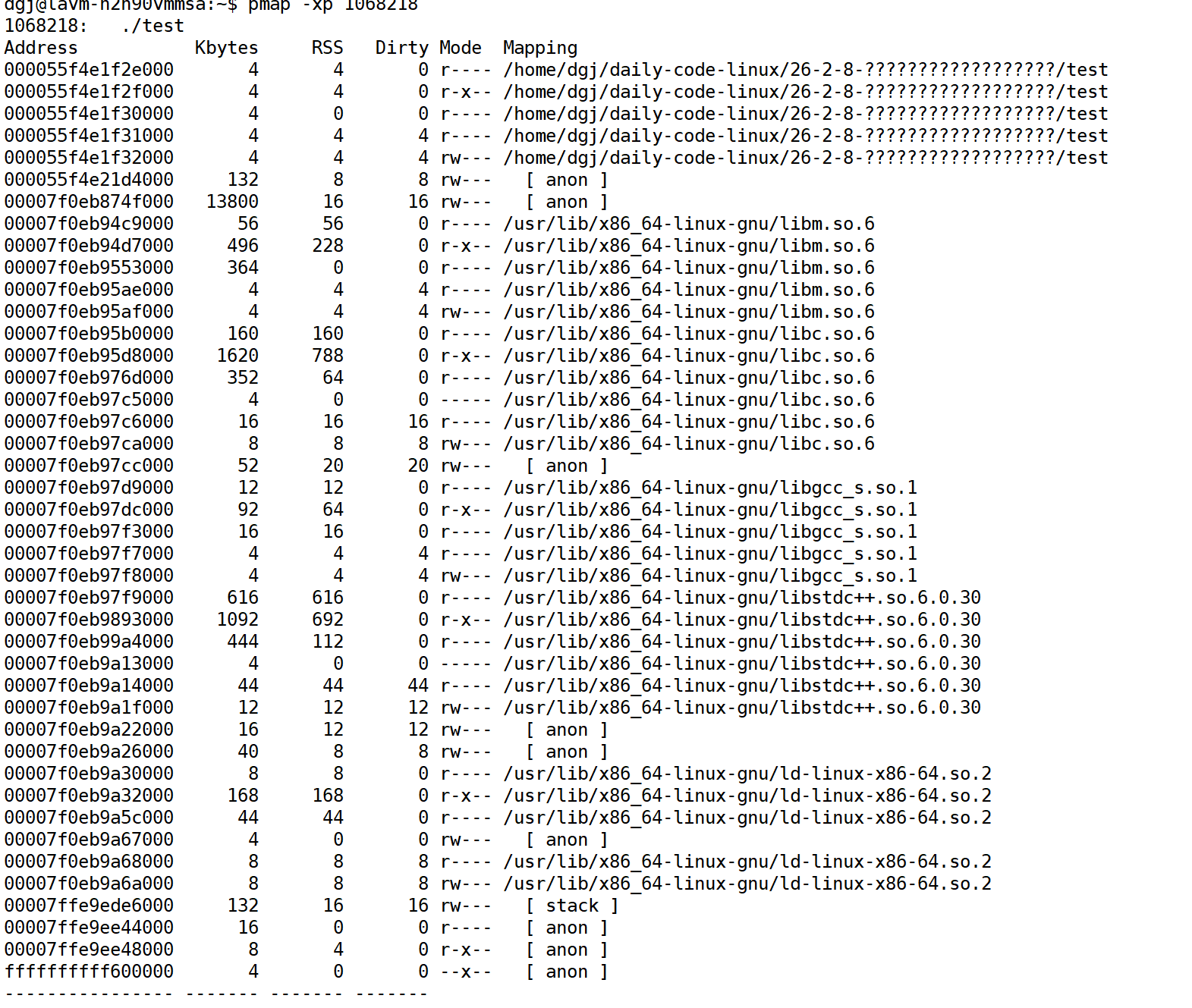
pmap -x
通过这个可以查看进程的内存分布,判断是哪个内存区域在暴涨内存。至于为什么加上-x,因为加上-x才能显示全部内存信息。不加看不全
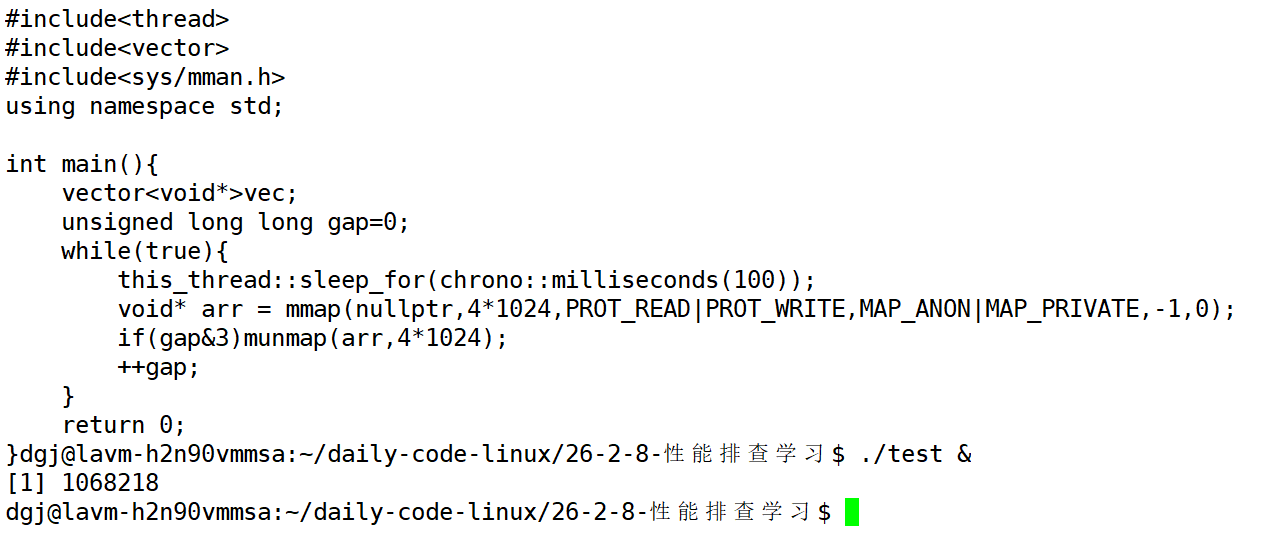
这里我们启动这个内存泄露的进程,并在后续监控中发现它内存的异常。此时我们开始对其进行更加细致的监测
-p选项可以指定要监视进程的pid
然后就可以得到内存排布图,但是这样的静态图标是发现不到端倪的。
watch
通过watch -n t(t时间间隔更新) 要执行的指令
通过这个我们就可以动态监测了:
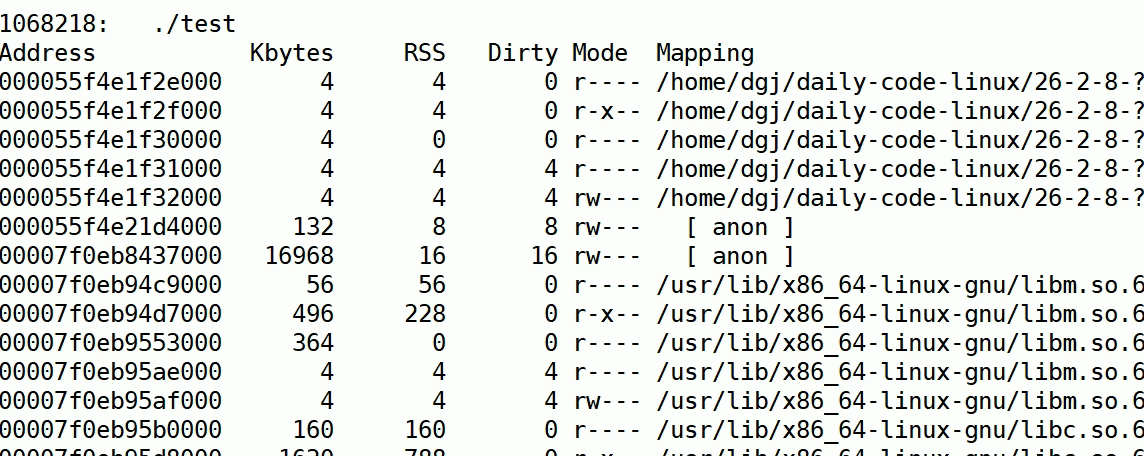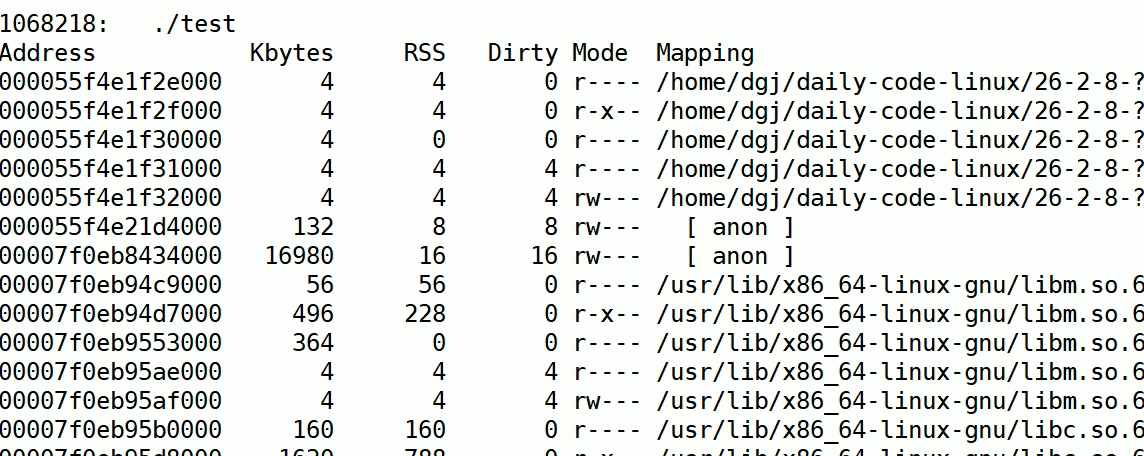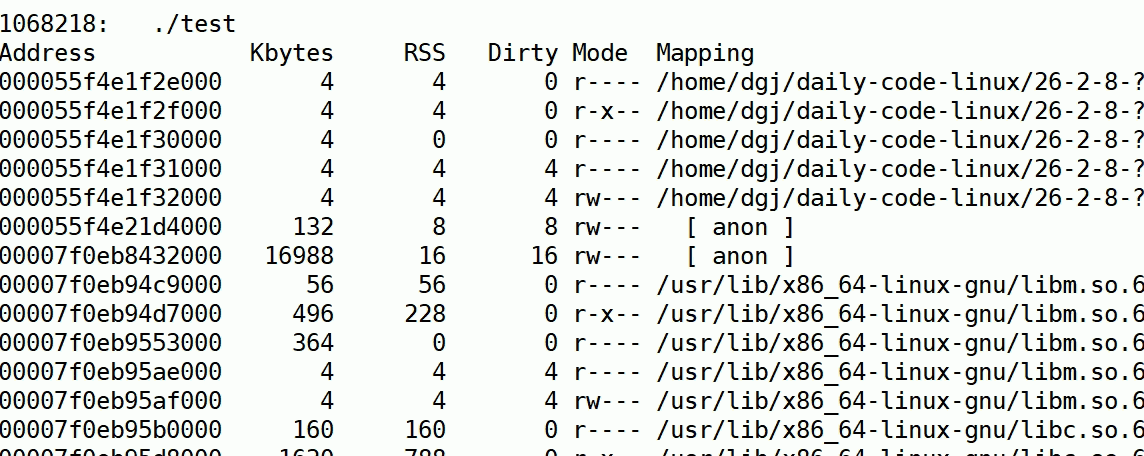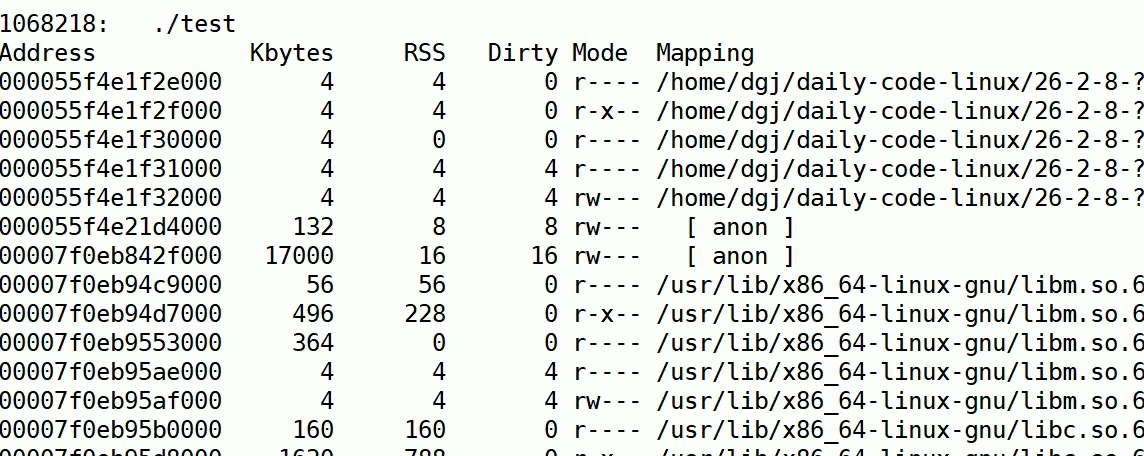
我们可以看到有一个anon类型的内存在持续上涨(Mapping是页面类型,有stack,库内存,anon等)
anon是私有内存,如堆区、共享内存、线程栈等。
此时我们确实找到了有异常的内存增长,因此我们要具体判断到底是谁在泄露内存,没有内存回收。
我们知道了有内存泄露了,我们此时要开始调查具体是是什么类型的泄露了。
首先线程栈我们直接可以通过使用C++并发库避免,这里就不说了。
/proc/<pid>/smaps
然后是如果区分共享内存和堆区内存,我们通过查看/proc/<pid>/smaps来看相关信息
它存储了已经申请内存的信息,通过这个可以查看哪个区域内存已经占据了特别多

strace命令检测系统调用
strace -e -trace=(系统调用名字,系统调用名字) -p <PID>
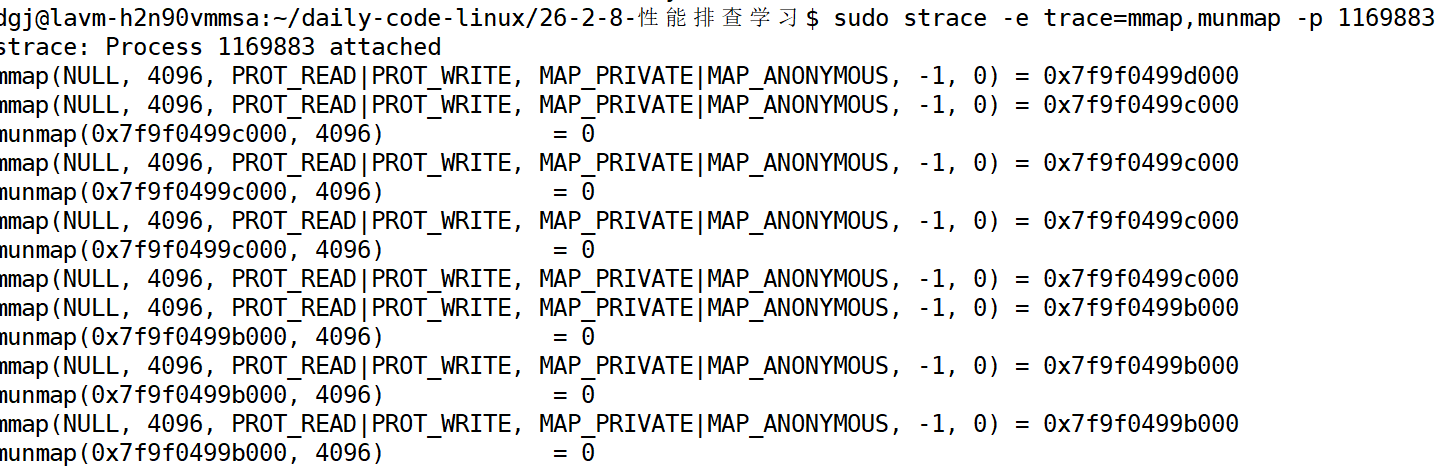
通过查看统计(这里没有统计,真正项目里面调用十分混乱,要通过相应统计系统调用此时来判断)这里我们就可以看到是munmap没有正确调用导致的内存泄露。
当然我们也可以通过这个检测brk的堆内存申请,来判断是否是堆内存的问题。
valgrind
可以使用valgrind工具来检测内存泄露,循环引用的问题可以使用它来检测,这个我具体不讲了,太多了。大家自行搜索
- 优点:简单、无需重新编译、通用
- 缺点:性能损耗大(10~100倍),不能线上用
tcmalloc
tcmalloc等内存池项目自带了内存快照,性能损耗极低,可以线上用。
内存泄露避免方式
内存池、智能指针正确使用、做好子进程回收等
CPU爆满排查
top/htop
通过这个查看爆满的进程,这个上面讲过,不多说了
perf
通过perf top -p <PID>进行进程各个函数CPU使用率的检测
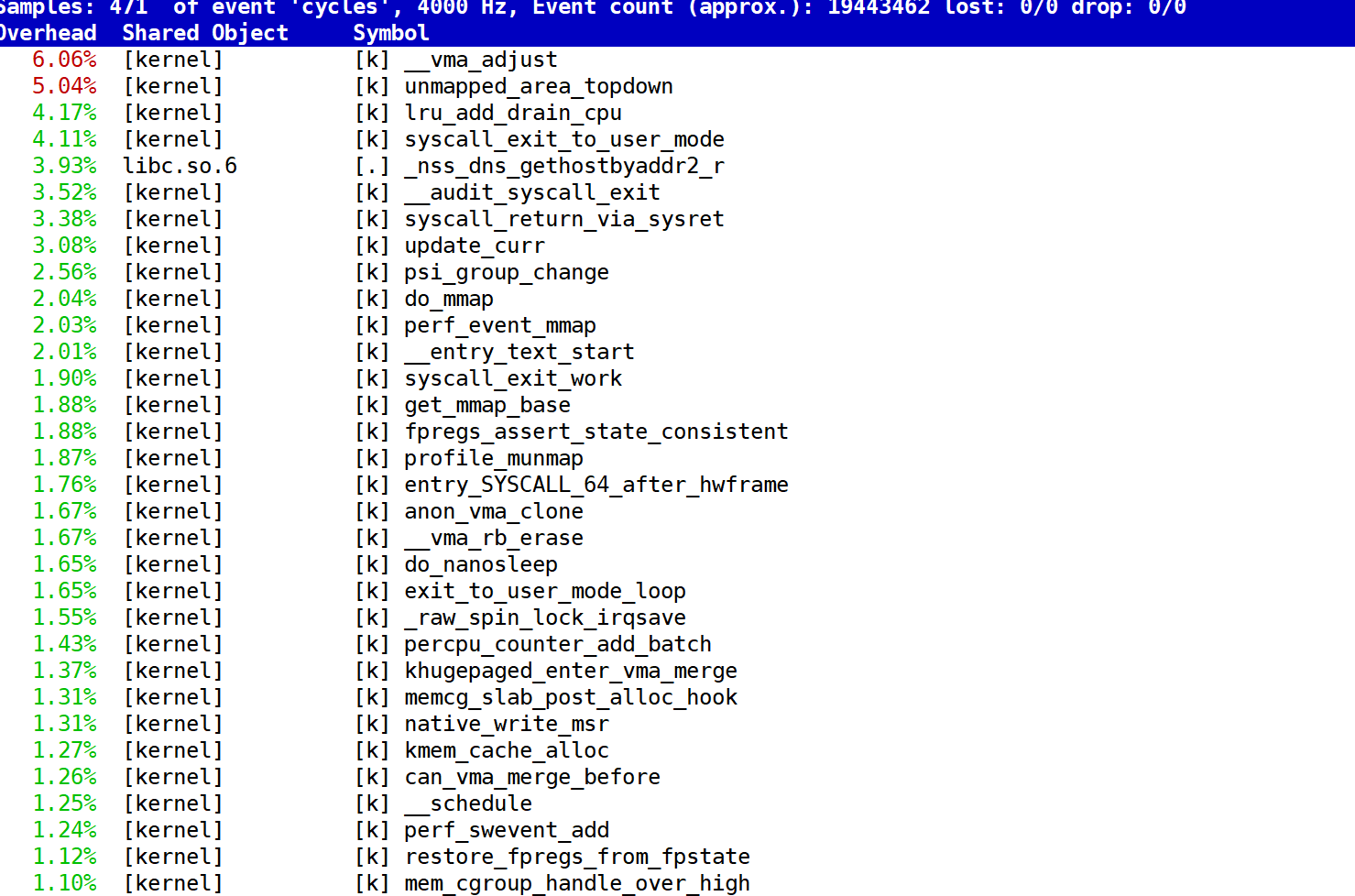
这里我们发现大量的都是kernel内核在占用CPU,说明系统调用占比大。就要做对应优化。
另外,如果是用户级代码CPU占比大,可以看到具体是什么函数使用了这么多。就可以进行对应的函数算法数据结构等优化。
IO高
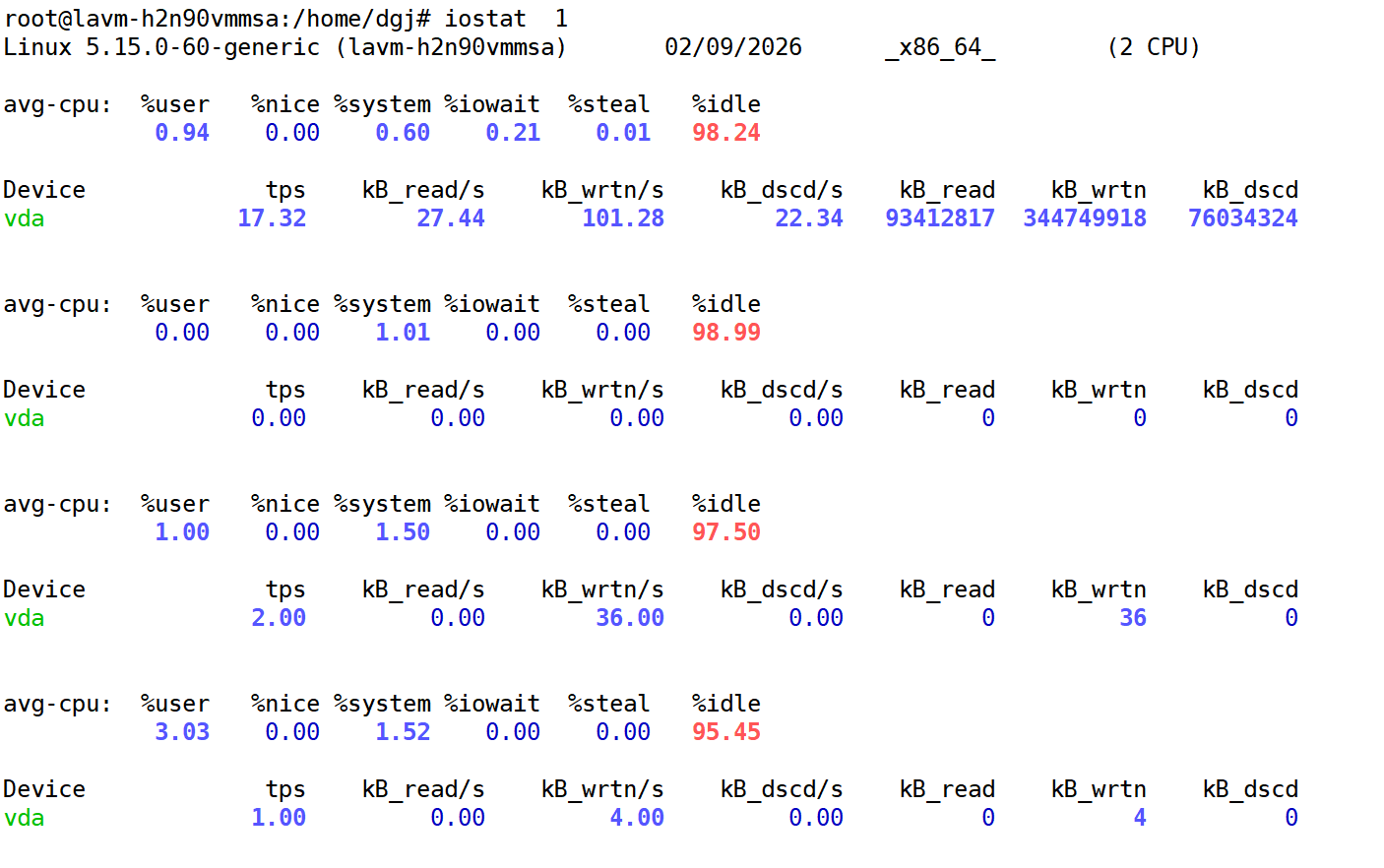
iostat
可以查看磁盘的IO情况
iostat 1 每1s更新一次
iotop
这个就相当于IO届的top/htop
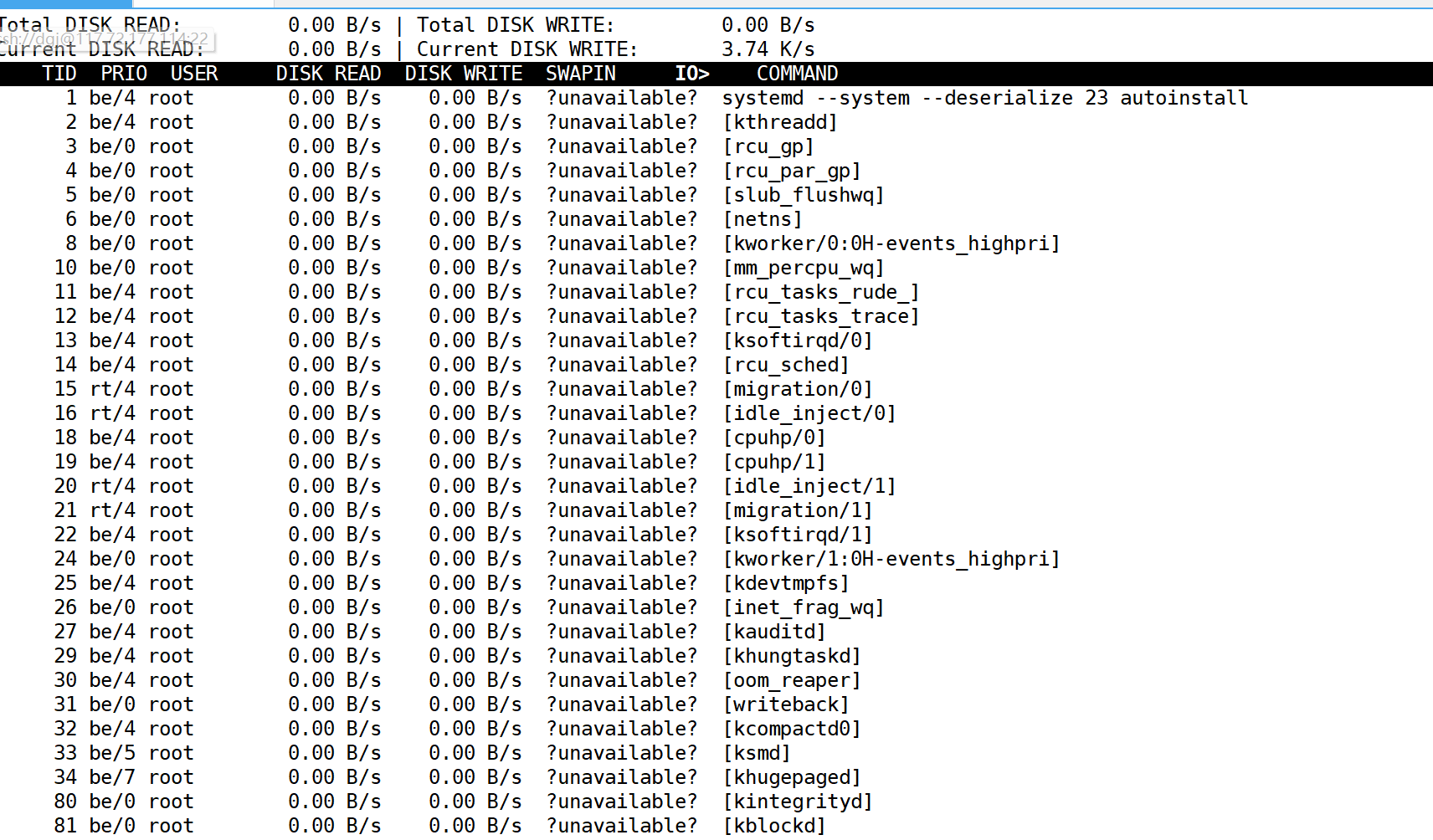
通过iotop -p <PID>指定监视对象
锁冲突
cpp
#include<iostream>
#include<mutex>
#include<thread>
#include<vector>
#include<sys/mman.h>
#include<sys/types.h>
#include<sys/socket.h>
using namespace std;
int main(){
vector<void*>vec;
unsigned long long gap=0;
mutex lock;
while(true){
for(int x=0;x<100;++x){
lock.lock();
lock.unlock();
}
this_thread::sleep_for(chrono::milliseconds(100));
void* arr = mmap(nullptr,4*1024,PROT_READ|PROT_WRITE,MAP_ANON|MAP_PRIVATE,-1,0);
if(gap&3)munmap(arr,4*1024);
++gap;
}
return 0;
}我们加一个锁
strace
我们依然可以使用stace来查看,因为锁是系统调用,我们通过查看系统调用看其调用次数
perf top
查看对应pthread_mutex_lock/unlock的CPU占比
perf lock
使用 perf lock record -p <PID>来查看锁的上锁解锁时间
根据长短我们需要减少长时间锁,防止其他线程获取不到CPU资源长等待
网络拥塞
netstat/ss
推荐ss比netstat查找更快,两个指令的指令参数是一样的
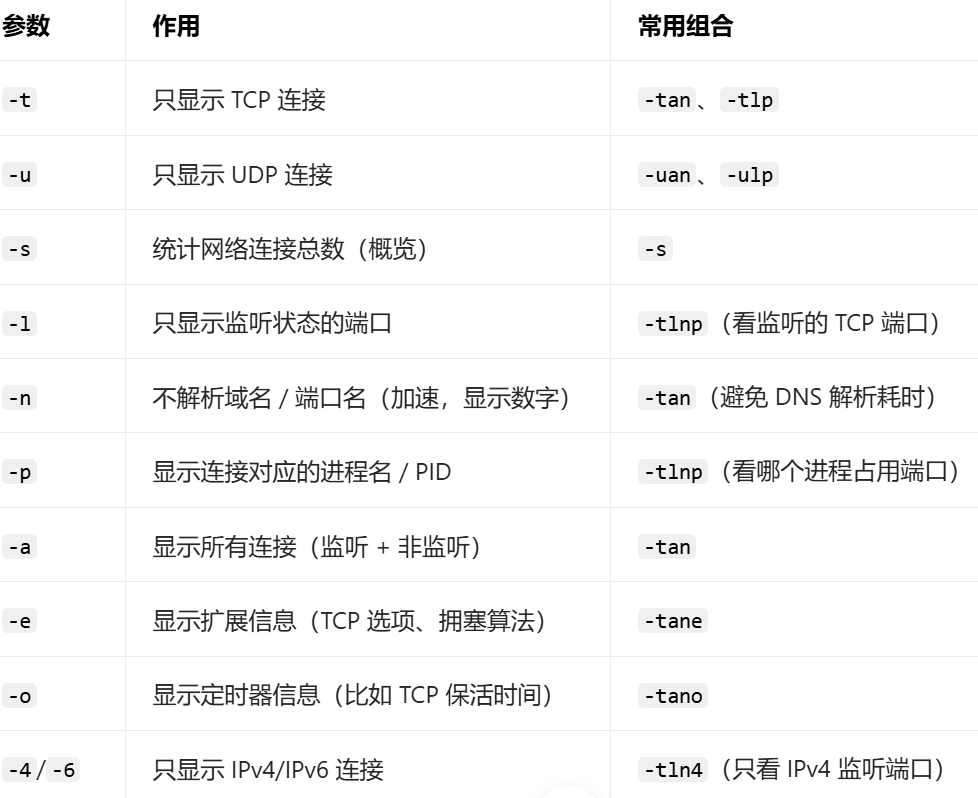
上面没有列完,还有-s统计类型数量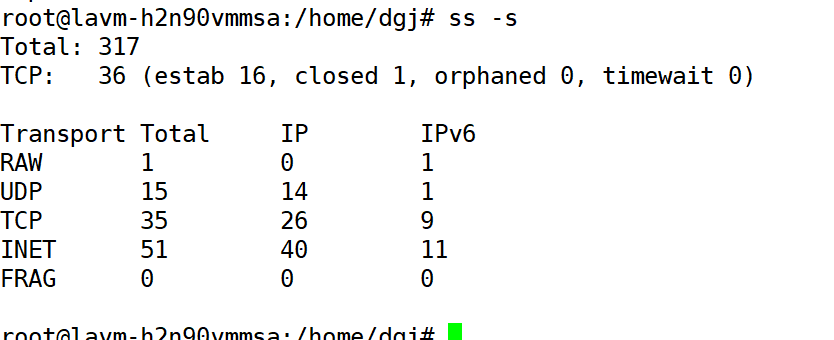
state 加上状态可以查看特殊状态
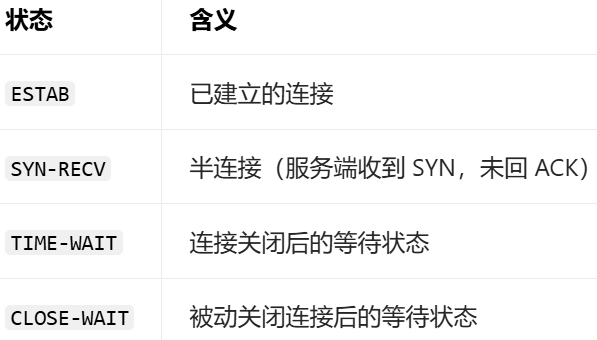

通过ss -nltp 查看tcp监听端口
通过上面操作,我们可以对连接数进行检测,看是否出现了拥塞情况。