一 导出全部已发布文章
首先,需要在本地安装3.8版本以上的python,安装python步骤
检查是否安装成功
bash
pip3 --version安装后执行
bash
pip3 install requests beautifulsoup4 markdownify新建脚本,脚本名字随意,这里是:csdn_downloader.py
脚本内容如下:
python
# -*- coding: utf-8 -*-
import os
import re
import requests
import time
from bs4 import BeautifulSoup
from markdownify import markdownify as md
from urllib.parse import urlparse, unquote
import hashlib
from pathlib import Path
# ================== 配置区 ==================
CSDN_USERNAME = "qq_33417321" # ←←← 修改为你想下载的用户名
SAVE_DIR = Path("csdn_articles") # 文章保存根目录(自动跨平台)
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Referer": "https://blog.csdn.net/"
}
def sanitize_filename(name: str) -> str:
"""清理文件名,移除 Windows 非法字符和'原创'字样"""
name = name.replace("原创", "").strip()
# 移除 Windows 非法字符
name = re.sub(r'[\\/*?:"<>|\r\n]', "_", name)
return name or "untitled"
def get_article_list(username):
"""获取博主文章列表(标题和URL)"""
url = f"https://blog.csdn.net/{username}/article/list"
articles = []
page = 1
while True:
response = requests.get(f"{url}/{page}", headers=HEADERS)
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.select(".article-list .article-item-box")
if not items:
break
for item in items:
title_elem = item.select_one("h4 a")
if not title_elem:
continue
title = title_elem.text.strip()
link = title_elem["href"]
articles.append({"title": title, "url": link})
page += 1
time.sleep(1)
return articles
def download_image(img_url, save_path: Path):
"""下载单张图片到本地"""
try:
img_headers = HEADERS.copy()
img_headers["Accept"] = "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8"
response = requests.get(img_url, headers=img_headers, stream=True, timeout=30)
if response.status_code == 200:
save_path.parent.mkdir(parents=True, exist_ok=True)
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
return True
else:
print(f"图片下载失败(状态码:{response.status_code}):{img_url}")
return False
except Exception as e:
print(f"图片下载异常:{img_url},错误:{str(e)}")
return False
def get_image_extension(img_url):
"""从URL中获取图片扩展名"""
parsed_url = urlparse(img_url)
path = parsed_url.path.lower()
extensions = ['.jpg', '.jpeg', '.png', '.gif', '.webp', '.bmp', '.svg']
for ext in extensions:
if ext in path:
return ext
return '.jpg'
def process_images_in_content(content, article_title):
"""处理内容中的图片,下载并替换为本地路径"""
soup = BeautifulSoup(content, 'html.parser')
img_tags = soup.find_all('img')
if not img_tags:
return content
# 清理文章标题用于路径
safe_title = sanitize_filename(article_title)
global_image_dir = SAVE_DIR / "images"
article_image_dir = global_image_dir / safe_title
for img in img_tags:
img_url = img.get('src', '')
if not img_url:
continue
# 处理协议相对路径
if img_url.startswith('//'):
img_url = 'https:' + img_url
elif not img_url.startswith(('http://', 'https://')):
continue # 跳过无法处理的相对路径
try:
img_hash = hashlib.md5(img_url.encode()).hexdigest()[:8]
img_ext = get_image_extension(img_url)
img_filename = f"{img_hash}{img_ext}"
local_img_path = article_image_dir / img_filename
# Markdown 中使用正斜杠(/),兼容所有平台
md_img_path = f"./images/{safe_title}/{img_filename}"
if not local_img_path.exists():
print(f" 下载图片:{img_filename}")
if download_image(img_url, local_img_path):
img['src'] = md_img_path
else:
print(f" 图片下载失败,保留原链接:{img_url}")
else:
img['src'] = md_img_path
except Exception as e:
print(f" 处理图片时出错:{img_url},错误:{str(e)}")
continue
return str(soup)
def download_article(url, article_title):
"""下载单篇文章,处理图片后转为Markdown"""
try:
response = requests.get(url, headers=HEADERS, timeout=30)
soup = BeautifulSoup(response.text, 'html.parser')
content = soup.select_one("article")
if not content:
print(f" 未找到文章内容")
return None
processed_content = process_images_in_content(str(content), article_title)
markdown_content = md(processed_content)
return markdown_content
except Exception as e:
print(f" 下载文章时出错:{str(e)}")
return None
def save_to_markdown(title, content, save_dir: Path):
"""保存Markdown文件"""
save_dir.mkdir(parents=True, exist_ok=True)
safe_title = sanitize_filename(title)
filename = save_dir / f"{safe_title}.md"
with open(filename, "w", encoding="utf-8") as f:
f.write(f"# {title}\n\n")
f.write(content)
print(f" 已保存:{filename}")
return filename
if __name__ == "__main__":
print("开始获取文章列表...")
articles = get_article_list(CSDN_USERNAME)
print(f"找到 {len(articles)} 篇文章")
success_count = 0
fail_count = 0
for i, article in enumerate(articles, 1):
title = article["title"]
url = article["url"]
print(f"\n[{i}/{len(articles)}] 处理文章:{title}")
content = download_article(url, title)
if content:
save_to_markdown(title, content, SAVE_DIR)
success_count += 1
else:
print(f" 文章下载失败:{title}")
fail_count += 1
time.sleep(2)
print(f"\n处理完成!成功:{success_count}篇,失败:{fail_count}篇")
print(f"文章保存在:{SAVE_DIR.resolve()}")
print("图片保存在:./images/ 目录下,Markdown文件可离线查看")其中,脚本里CSDN_USERNAME的值,改为你要获取的csdn的用户名
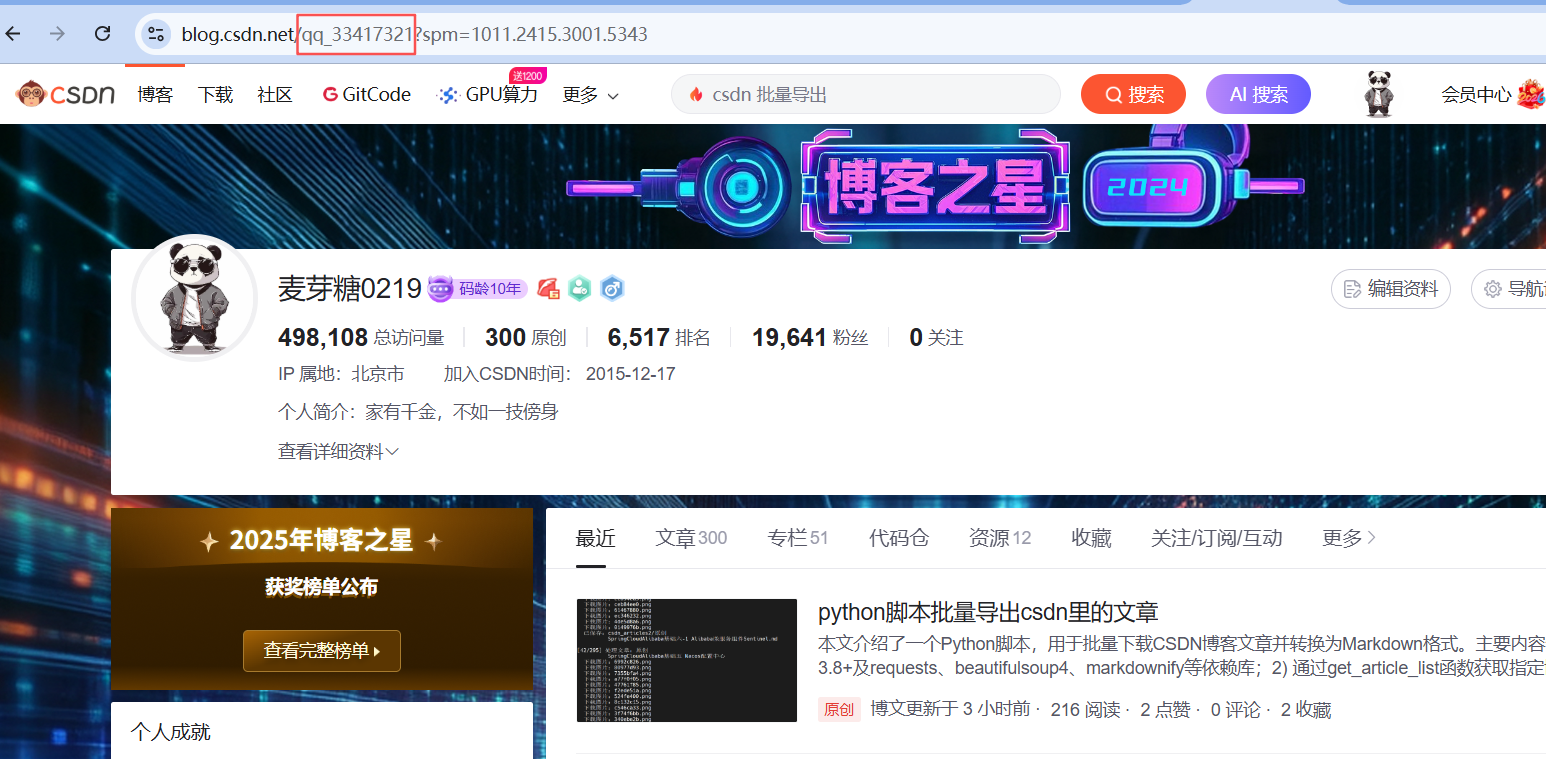
获取用户名:点击作者头像后,链接里的这个值就是用户名(红框里的内容)
执行脚本
bash
python csdn_downloader.py执行日志入下:
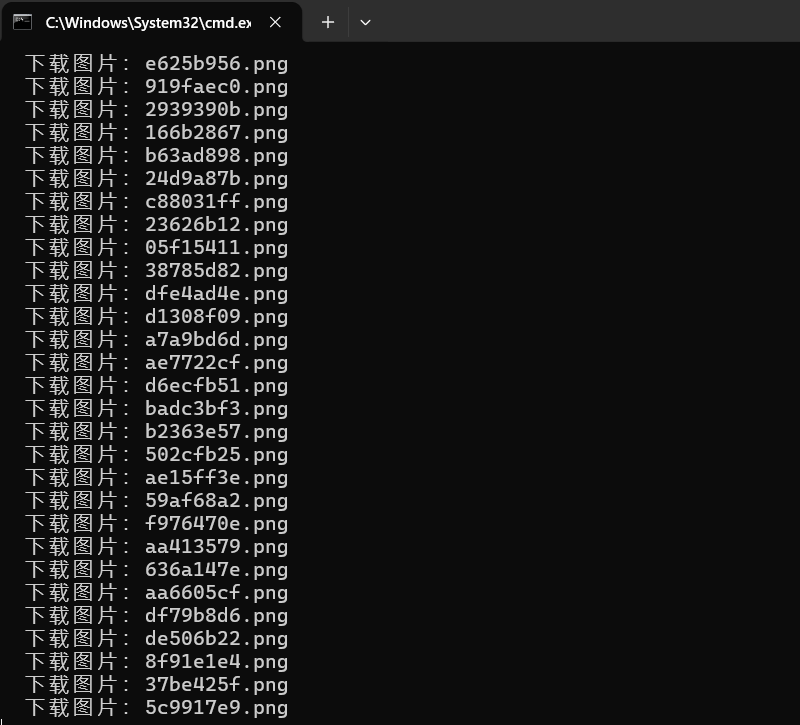
由于要下载csdn文章里的图片,所以很慢,静静等待即可。下载过程中,会在脚本所在目录生成一个csdn_articles文件夹,里边是md文件以及存md里的图片的文件夹。
二 导出指定日期后的文章
上边的脚本,一次性导出了所有已发布的文章,但是有时候我们的文章太多,每次备份不需要全部导出,只导出指定时间以后的文章,那么使用如下脚本即可,如脚本名为new.py,内容如下
python
# -*- coding: utf-8 -*-
import os
import re
import requests
import time
from bs4 import BeautifulSoup
from markdownify import markdownify as md
from urllib.parse import urlparse, unquote
import hashlib
from pathlib import Path
from datetime import datetime
# ================== 配置区 ==================
CSDN_USERNAME = "qq_33417321" # ←←← 修改为你想下载的用户名
SAVE_DIR = Path("csdn_articles") # 文章保存根目录(自动跨平台)
# ⬇️ 新增:设置最小发布日期(含)
MIN_PUBLISH_DATE = datetime(2026, 2, 7) # 只下载 2026年2月1日及之后的文章
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Referer": "https://blog.csdn.net/"
}
def sanitize_filename(name: str) -> str:
"""清理文件名,移除 Windows 非法字符和'原创'字样"""
name = name.replace("原创", "").strip()
name = re.sub(r'[\\/*?:"<>|\r\n]', "_", name)
return name or "untitled"
def parse_publish_date(date_str: str) -> datetime | None:
"""尝试解析 CSDN 日期字符串,支持 '2025-06-15 10:30:00' 或 '2025-06-15' 等"""
date_str = date_str.strip()
for fmt in [
"%Y-%m-%d %H:%M:%S", # 带秒,如 2025-06-15 10:30:09
"%Y-%m-%d %H:%M", # 不带秒,如 2025-06-15 10:30
"%Y-%m-%d" # 只有日期,如 2025-06-15
]:
try:
return datetime.strptime(date_str, fmt)
except ValueError:
continue
print(f" 无法解析日期:{date_str}")
return None
def get_article_list(username, min_date=None):
"""获取博主文章列表(标题、URL、发布时间),可选按 min_date 过滤"""
url = f"https://blog.csdn.net/{username}/article/list"
articles = []
page = 1
early_stop = False
while not early_stop:
print(f" 正在抓取第 {page} 页...")
response = requests.get(f"{url}/{page}", headers=HEADERS)
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.select(".article-list .article-item-box")
if not items:
break
current_page_has_valid = False # 当前页是否有满足条件的文章
for item in items:
title_elem = item.select_one("h4 a")
date_elem = item.select_one(".date") # CSDN 通常用 .date 类表示发布时间
if not title_elem:
continue
title = title_elem.text.strip()
link = title_elem["href"]
pub_date = None
if date_elem:
raw_date = date_elem.text.strip()
pub_date = parse_publish_date(raw_date)
# 如果设置了最小日期,且文章发布时间早于该日期,则跳过
if min_date and pub_date and pub_date < min_date:
continue
# 如果发布时间未知但设置了 min_date,保守起见也跳过(或可选择保留)
if min_date and not pub_date:
print(f" 警告:无法获取文章 [{title}] 的发布时间,跳过(因设置了日期过滤)")
continue
articles.append({
"title": title,
"url": link,
"publish_date": pub_date
})
current_page_has_valid = True
# 如果当前页没有任何有效文章(全部早于 min_date),可提前终止
if min_date and not current_page_has_valid and page > 1:
print(" 后续页面文章均早于指定日期,停止翻页。")
early_stop = True
page += 1
time.sleep(1)
return articles
# ========== 以下函数保持不变 ==========
def download_image(img_url, save_path: Path):
try:
img_headers = HEADERS.copy()
img_headers["Accept"] = "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8"
response = requests.get(img_url, headers=img_headers, stream=True, timeout=30)
if response.status_code == 200:
save_path.parent.mkdir(parents=True, exist_ok=True)
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
return True
else:
print(f"图片下载失败(状态码:{response.status_code}):{img_url}")
return False
except Exception as e:
print(f"图片下载异常:{img_url},错误:{str(e)}")
return False
def get_image_extension(img_url):
parsed_url = urlparse(img_url)
path = parsed_url.path.lower()
extensions = ['.jpg', '.jpeg', '.png', '.gif', '.webp', '.bmp', '.svg']
for ext in extensions:
if ext in path:
return ext
return '.jpg'
def process_images_in_content(content, article_title):
soup = BeautifulSoup(content, 'html.parser')
img_tags = soup.find_all('img')
if not img_tags:
return content
safe_title = sanitize_filename(article_title)
global_image_dir = SAVE_DIR / "images"
article_image_dir = global_image_dir / safe_title
for img in img_tags:
img_url = img.get('src', '')
if not img_url:
continue
if img_url.startswith('//'):
img_url = 'https:' + img_url
elif not img_url.startswith(('http://', 'https://')):
continue
try:
img_hash = hashlib.md5(img_url.encode()).hexdigest()[:8]
img_ext = get_image_extension(img_url)
img_filename = f"{img_hash}{img_ext}"
local_img_path = article_image_dir / img_filename
md_img_path = f"./images/{safe_title}/{img_filename}"
if not local_img_path.exists():
print(f" 下载图片:{img_filename}")
if download_image(img_url, local_img_path):
img['src'] = md_img_path
else:
print(f" 图片下载失败,保留原链接:{img_url}")
else:
img['src'] = md_img_path
except Exception as e:
print(f" 处理图片时出错:{img_url},错误:{str(e)}")
continue
return str(soup)
def download_article(url, article_title):
try:
response = requests.get(url, headers=HEADERS, timeout=30)
soup = BeautifulSoup(response.text, 'html.parser')
content = soup.select_one("article")
if not content:
print(f" 未找到文章内容")
return None
processed_content = process_images_in_content(str(content), article_title)
markdown_content = md(processed_content)
return markdown_content
except Exception as e:
print(f" 下载文章时出错:{str(e)}")
return None
def save_to_markdown(title, content, save_dir: Path):
save_dir.mkdir(parents=True, exist_ok=True)
safe_title = sanitize_filename(title)
filename = save_dir / f"{safe_title}.md"
with open(filename, "w", encoding="utf-8") as f:
f.write(f"# {title}\n\n")
f.write(content)
print(f" 已保存:{filename}")
return filename
# ========== 主程序入口 ==========
if __name__ == "__main__":
print("开始获取文章列表...")
articles = get_article_list(CSDN_USERNAME, min_date=MIN_PUBLISH_DATE)
print(f"找到 {len(articles)} 篇符合条件的文章(发布日期 ≥ {MIN_PUBLISH_DATE.strftime('%Y-%m-%d')})")
success_count = 0
fail_count = 0
for i, article in enumerate(articles, 1):
title = article["title"]
url = article["url"]
pub_date = article.get("publish_date")
date_str = pub_date.strftime("%Y-%m-%d") if pub_date else "未知"
print(f"\n[{i}/{len(articles)}] 处理文章:{title} (发布于 {date_str})")
content = download_article(url, title)
if content:
save_to_markdown(title, content, SAVE_DIR)
success_count += 1
else:
print(f" 文章下载失败:{title}")
fail_count += 1
time.sleep(2)
print(f"\n处理完成!成功:{success_count}篇,失败:{fail_count}篇")
print(f"文章保存在:{SAVE_DIR.resolve()}")
print("图片保存在:./images/ 目录下,Markdown文件可离线查看")记得修改MIN_PUBLISH_DATE 里的开始日期。之后执行脚本后,下载下来就是指定日期后的文章了。