前言❤️❤️
hello hello💕,这里是洋不写bug~😄,欢迎大家点赞👍👍,关注😍😍,收藏🌹🌹
首先提醒下铁汁们,这部分知识在整个数据库基础和进阶当中,算是比较复杂的了,初学的铁汁可以慢慢看🐵
索引就是一种数据结构,可以帮助数据库高效的查询,更新表中的数据。
索引就是通过一定的规则来排列数据表中的内容,使得对表的查询可以通过对索引的搜索来加快速度
索引确定了数据组织的方式,不同的索引类型组织数据的方式不同
🎇个人主页:洋不写bug的博客
🎇所属专栏:数据库
🎇mysql8.0和navicate的安装:mysql安装教程
🎇铁汁们对于MySQL数据库的各种常用核心语法,都可以在上面的数据库专栏学习,专栏正在持续更新中🐵🐵,有问题可以写在评论区或者私信我哦~

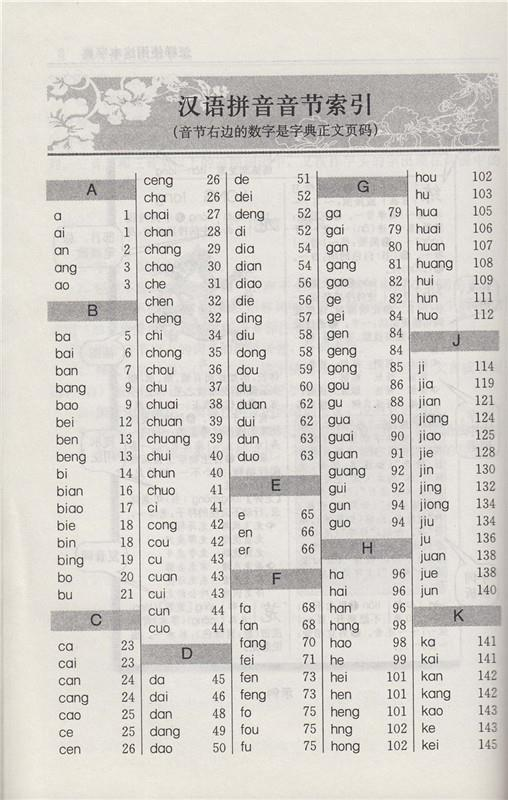
字典中有汉语拼音音节索引和部首索引,笔画索引(如下图所示),能够帮我们快速找到汉字
当字典中要收录一个字的时候,不但要把字放到字典的合适位置,同样也要更新这三个地方的索引
如果创建的索引比较多(字典中就创建了三种索引),虽然可以提高查询效率,但是在更新,删除时,要修改的地方就比较多


1,索引应该使用哪种数据结构
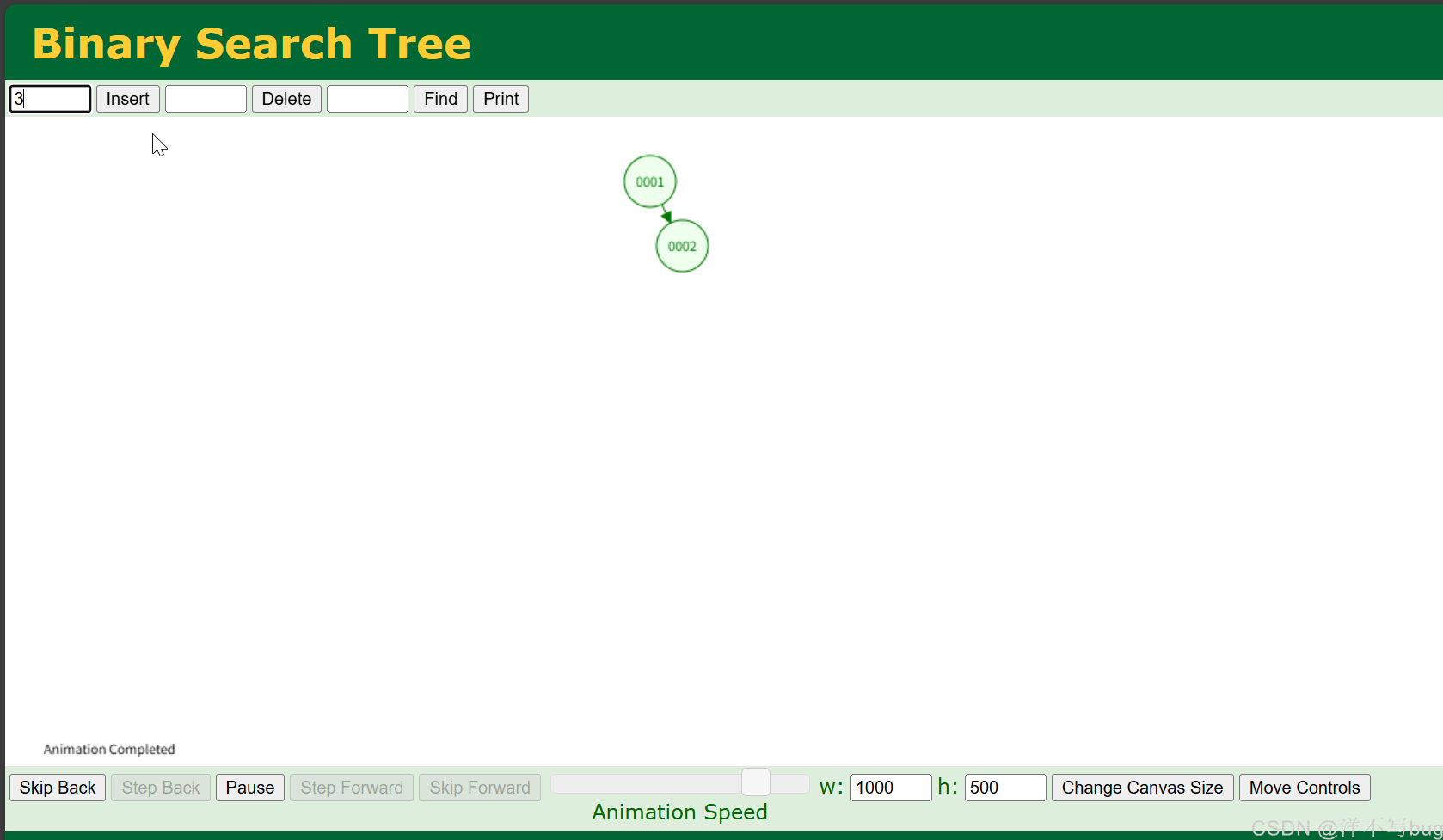
首先给铁汁们推荐一个画树的网站,这是一个由美国旧金山大学计算机系的 David Galles 教授开发的免费在线工具网站(铁汁们在Indexing中选择要画的树,比如要创建一个二叉搜索树,就点击Indexing中的第二行 Binary Search Tree)
网站链接

例如要创建一个二叉搜索树,就在insert框中输入一个数字,再按enter键,就会把这个节点插入到树中,下面的Animation Speed指的是节点判断插入位置的速度,可以拖到最大
1,HASH表
HASH表查找数据的平均时间复杂度是O(1)(哈希表就是通过哈希函数,进行取模运算,把数据存到对应的下标中)
但是HASH表有个坏处,哈希函数是取模确定位置,HASH表存的数据是分散且混乱的,因此哈希表不支持范围查找
补充:
范围查找(比如 "查找所有大于 5 且小于 10 的键")的核心需求是:
-
能快速定位到范围的起始边界(比如第一个大于 5 的键)
-
能沿着连续的顺序区间遍历所有符合条件的键
因此HASH表就PASS掉了
2,二叉搜索树
这时候可能有的铁汁就会想到二叉搜索树,二叉搜索树中序遍历是一个有序序列,因此是支持范围查找的
但是二叉搜索树也存在一个问题,就是可能会退化为单边树(如下所示),这时候查找数据的时间复杂度就是O(N)

由于数据保存在磁盘上,每一次通过父节点去找子节点,就会发生一次磁盘IO(磁盘IO是制约数据库性能甚至是应用程序性能的主要因素)
磁盘 IO是计算机与磁盘存储设备(机械硬盘 HDD、固态硬盘 SSD)之间进行 数据读取(Input)和数据写入(Output) 的操作,磁盘 IO 是计算机系统的慢速环节,延迟远高于内存、CPU 操作(内存纳秒级,磁盘毫秒级),极易成为系统性能瓶颈。
因此,二叉搜索树就也PASS掉了
3,B树 (N叉树)
B树是进阶数据结构的部分,可能大部分铁汁是没学过的,这个暂时不用深究
B 树就是通过增大节点容量降低树高,进而减少磁盘的IO次数,提升效率
Max.Degree就是最大度,也就是每个节点最多能拥有的子节点数量,这里选择4
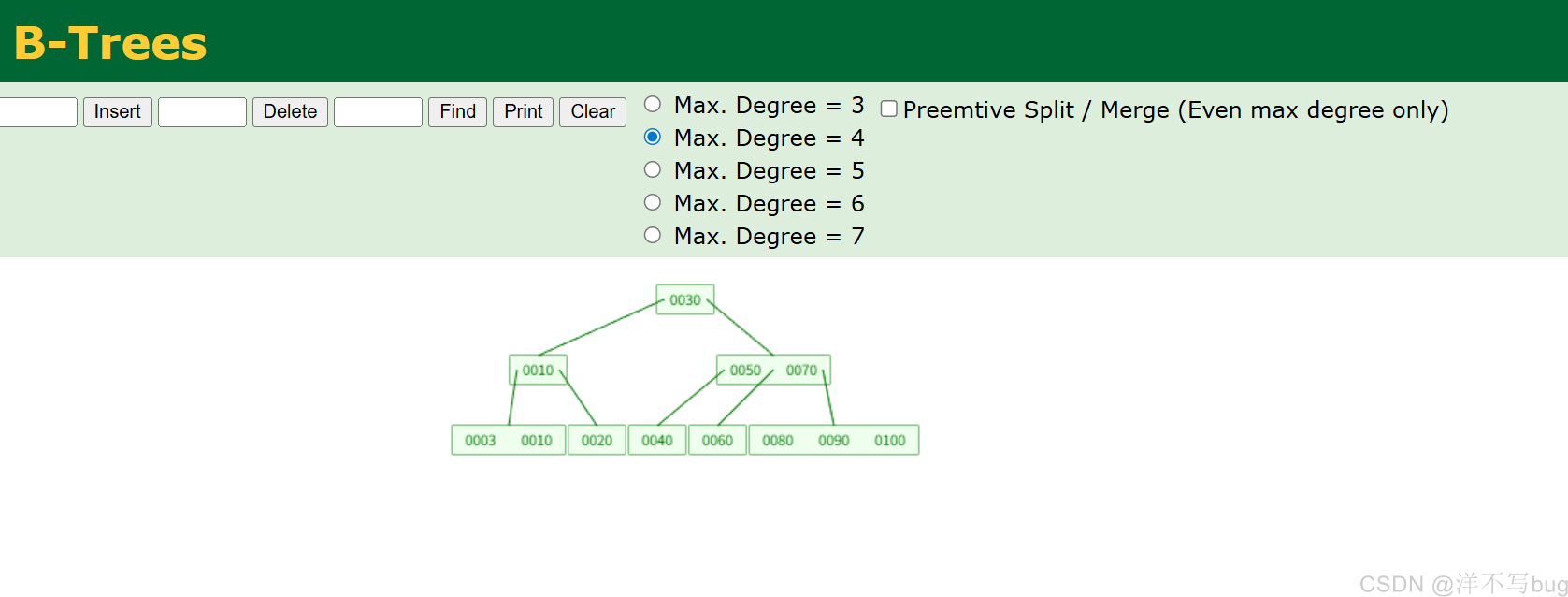
B树查找的时间复杂度是O(logN),有效的降低了树高,可以支持范围查询
但是B树也有个缺点,查询30的时候,经过一次IO就可以了,查询100时,要经过三次IO,IO次数是不稳定的,因此MySQL也没有使用B树
4,B+树
B+树跟B树是比较相似的,但是还是有区别的(铁汁们可以自己创建一个B+树,看一下)
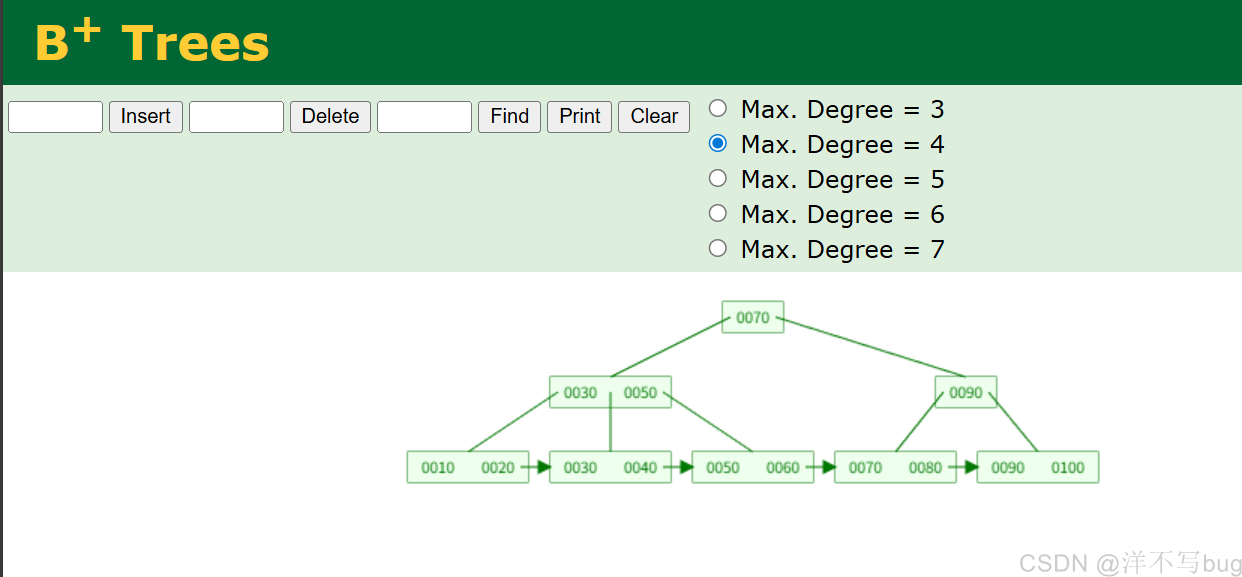
B树和B+树区别如下:
- 叶子节点之间有一个相互连接作用,可以通过一个叶子节点找到与他相邻的兄弟节点,MySQL在组织叶子节点时,使用的是双向循环链表(如下图所示)
- 非叶子节点的值都包含在叶子节点中(B+树的非叶子节点中只包含对子节点的引用,没有保存真实的数据,所有真实数据都保存在叶子节点中)
- 对于B+树而言,在相同树高的情况下,查找任意元素的时间复杂度都一样,行呢个均衡
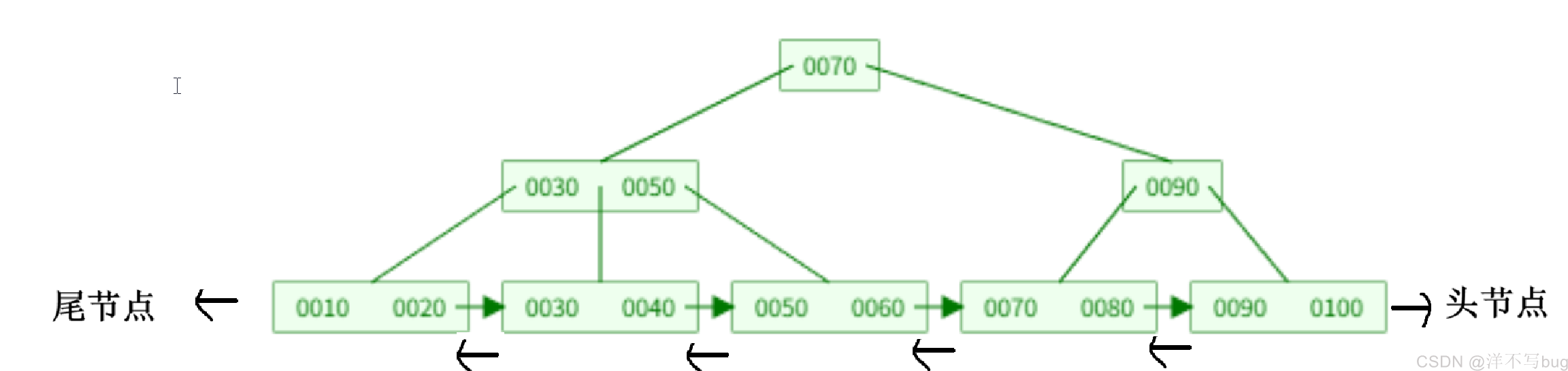
综上,MySQL组织数据使用的就是B+树
注:上面这个问题可能会出现在面试中,回答时把问题从头到尾说一遍,说下前面三种数据结构的缺点,以及B+树的优点,基本上就是个满分回答🐵💪
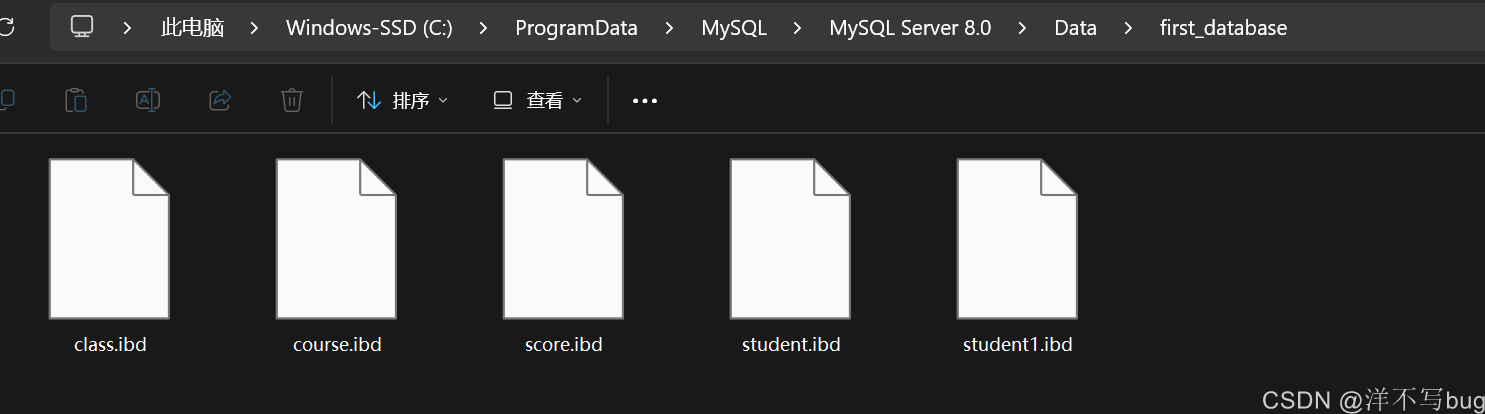
2,MySQL中的页
页是存储在 .ibd文件中的,按照这个路径,打开到Data,点开个之前创建的数据库,会发现我们创建的表就是以.ibd文件的形式存储的,每个.ibd文件中就有很多的页
在.ibd 文件中最重要的结构体就是Page (页),页是内存与磁盘交互的最小单元,默认大小为 16KB (在Windows系统中每页默认是4kb,因此在MySQL中页的内存还是比较大的),每次内存与磁盘的交互至少读取一页
在磁盘中,每个页内部的地址都是连续的,之所以这样做,是因为在使用数据的过程中,根据局部性原理,将来要使用的数据大概率与当前访问的数据在空间上是临近的,所以一次从磁盘中读取一页的数据放入内存中,当下次查询的数据还在这个页中时就可以从内存中直接读取,从而减少磁盘 I/O 提高性能。(就算只查询一行数据,一次也是从磁盘中读取一页)
局部性原理:
-
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问
-
空间局部性(Spatial Locality):将来要用到的信息大概率与正在使用的信息在空间地址上是临近的。
-
局部性原理就类似于我们喜欢找谁玩,那下次出去玩可能还是找这个人,很好理解
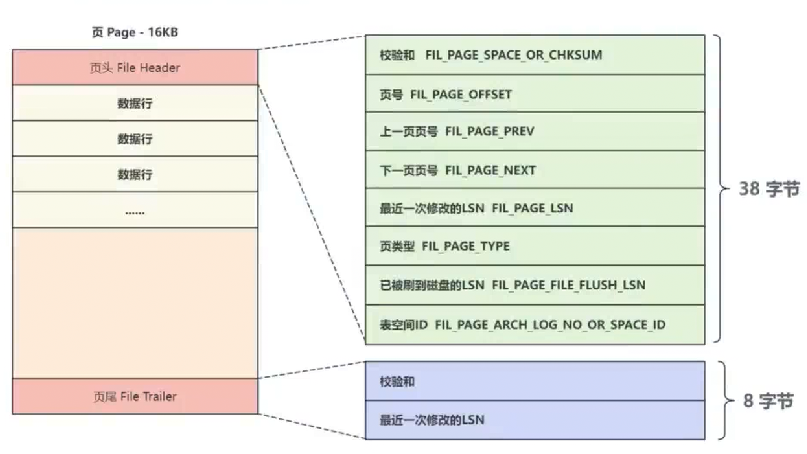
MySQL中有很多类型的页,最常用的页就是索引页(又称为数据页),数据页的基本结构如下所示(所有类型的页都包含页头和页尾):
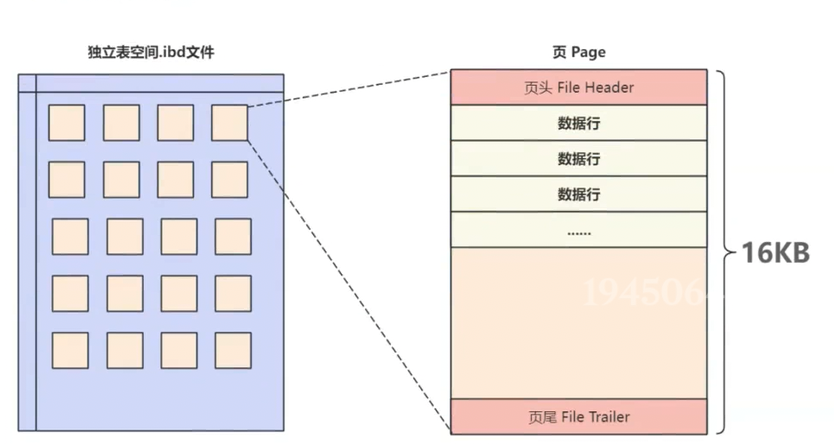
页头和页尾内部存储结构如下,这里只需要关注页头里面的上一页页号和下一页页号部分,这两个属性就可以把页和页连接起来,形成一个双向链表,B+树中的每个节点就是一个页,这就跟前面说的索引数据结构联系了起来
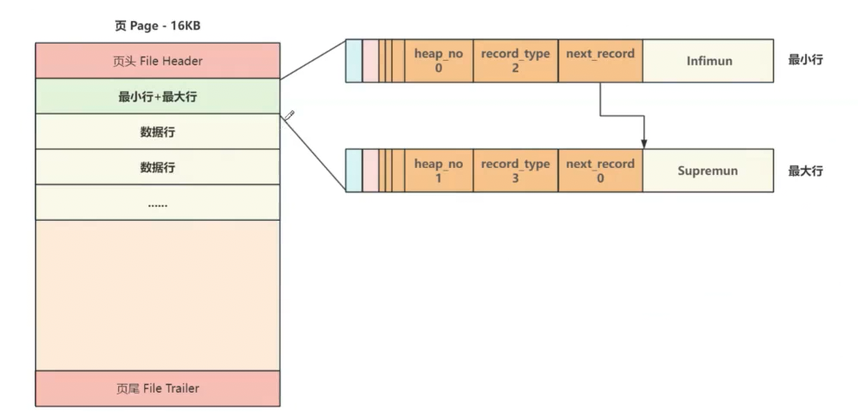
页主体部分是保存真实数据的主要区域,每当创建一个新页,都会自动分配两个行,一个是页内最小行 Infimum,另一个是页内最大行 Supremum,这两个行并不存储任何真实信息,而是做为数据行链表的头和尾
第一个数据行有一个记录下一行的地址偏移量的区域 next_record 将页内所有数据行组成了一个单向链表,此时新页的结构如下所示:
当按主键或索引查找某条数据时,最直接简单的方法就是从头行 infimum 开始,沿着链表顺序逐个比对查找,但一个页有 16KB,通常会存在数百行数据,每次都要遍历数百行,这显然效率是很低的
为了提高查询效率,InnoDB 采用二分查找来解决查询,这就用到了页目录,将页内的所有行(包括头行和尾行)进行分组 ,如下图所示具体分组规则:头行为单独一组,其他组最多每组8条数据 (可以少一些,如下图,槽1和槽2的组分别有4条和5条数据),页目录中的每个位置称为一个槽,每个槽都对应着一个分组,一旦分组中的数据行超过分组的上限 8 个时,就会分裂出一个新的分组;
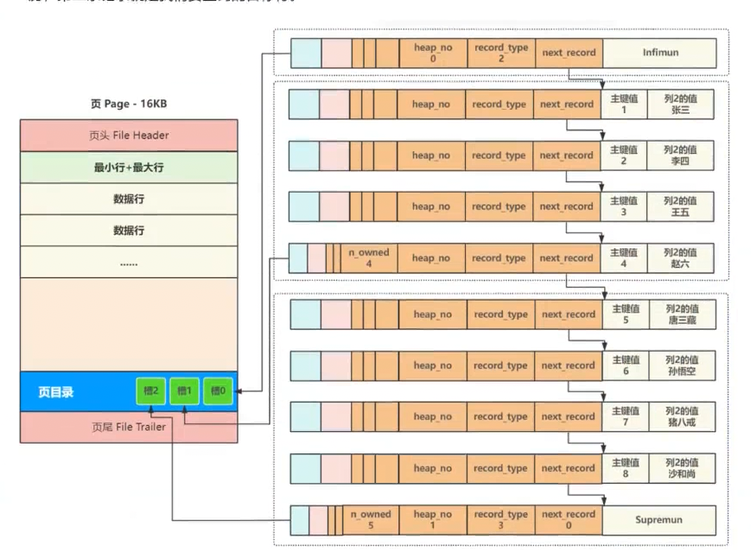
后续在查询某行时,就可以通过二分查找,先找到对应的槽,然后在槽内的几行数据中进行遍历即可 ,从而大幅提高了查询效率,
例如要查找主键为 6 的行,先比对槽中记录的主键值,定位到最后一个槽 2,再从最后一个槽中的第一条记录遍历,第二条记录就是我们要查询的目标行。(是不是效率高多了🐵)
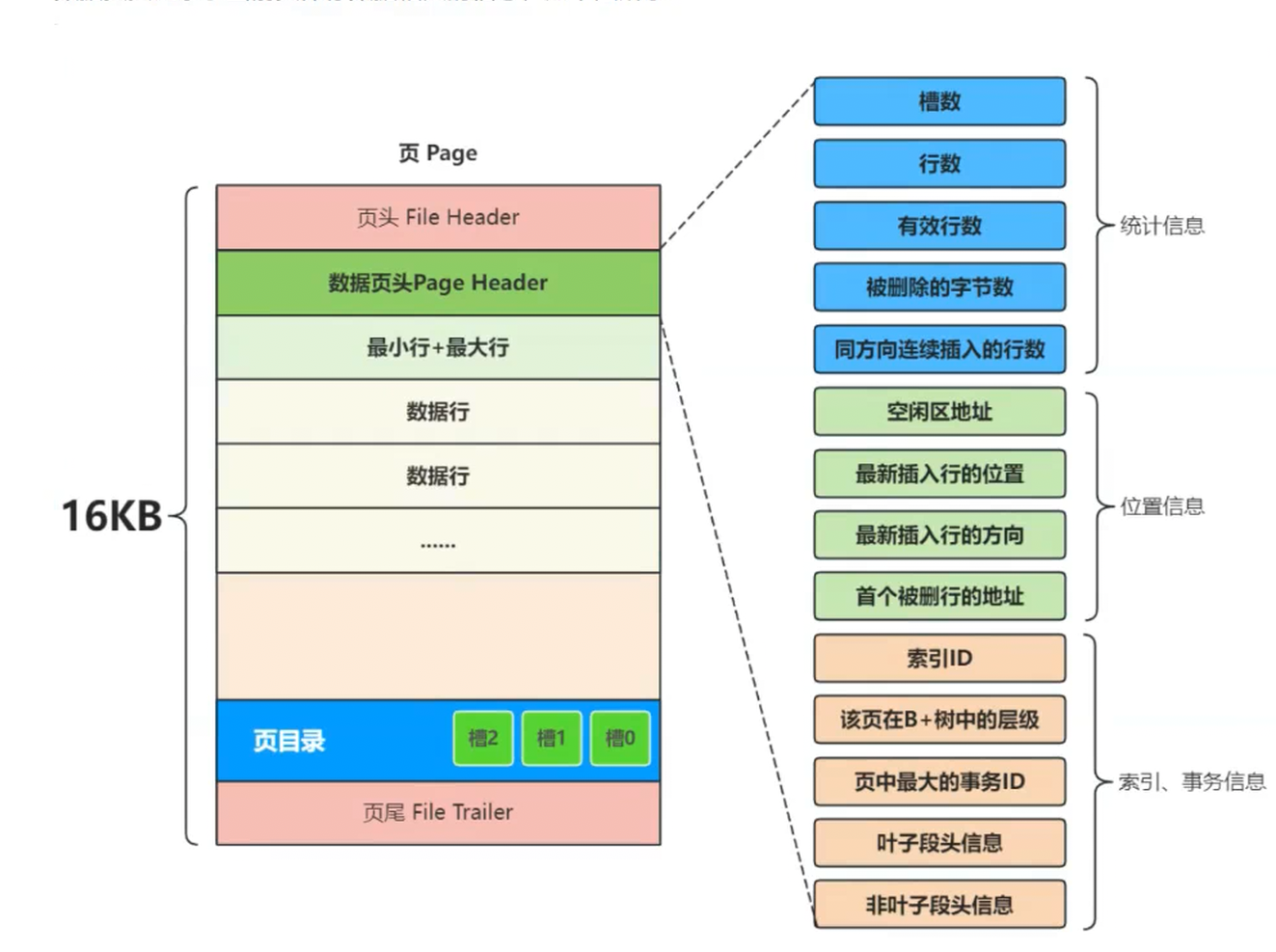
每页中还有个数据页头(数据页头里面存的是一些具体的信息,这里铁汁们大概了解下即可)
3,B+树在MySQL索引中的引用
在B+树中,非叶子节点保存索引数据,叶子节点保存真实数据(如下图所示)
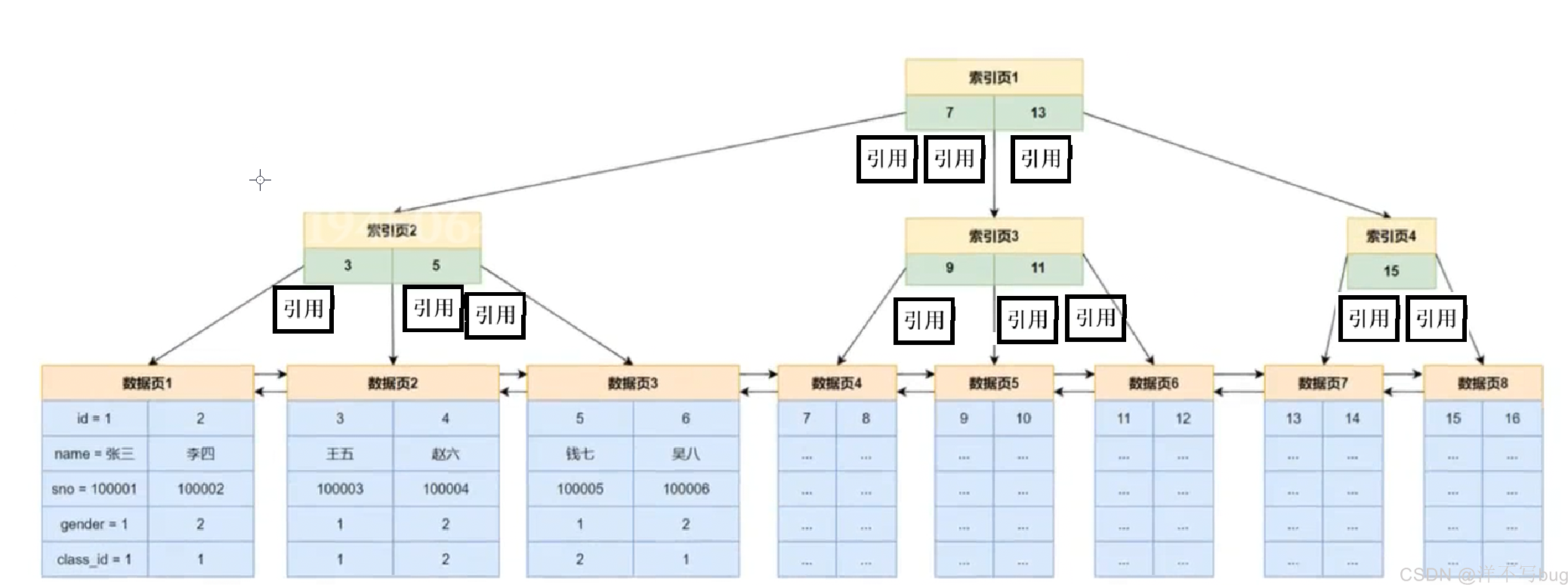
索引页里面保存的有键值,用于划分数据范围,例如例如索引页中的7和16就是键值,表示整个数据划分为三个区间:id < 7、7 <= id < 13 和 id >= 13
还有引用,指向每个区间,2个键值会把数据分成三个部分,所以引用比键值要多一个
以查找id为5的数据为例,分为三步:
- 首先判断B+树中根节点的索引记录,此时5<7,应访问左孩子节点,找到索引页2
- 加载索引页2,在索引页2中判断id的大小,找到与5相等的记录
- 加载对应的数据页
以上的例子经过3次磁盘IO就可以找到数据行,还可以把索引页缓存到内存,进一步提升效率
可能有的铁汁到现在还没有感受到B+树有多牛,那下面就计算下三层高的B+树中可以存放多少数据?
这部分稍微优点抽象
- 数据页和索引页的大小都是16kb,假设一个数据行大小为1kb,那一个数据页中就能存16条数据
- 接下来看索引页,就拿索引页二来说,里面有3和5这两个主键值,还有三个引用P1,P2,P3(这里只是演示图,实际上会有很多主键和很多引用),那P1和3就能组成第一条索引记录,P2和5组成第二条索引记录
主键值是使用bigint来存的,大小为8byte,引用大小是6byte,故一个索引记录的大小就是14byte
还有个单独的指针P3,这个单独的指针只占用 6 字节。在一个 16KB(16384 字节)的索引页中,这 6 字节的空间占比极小,就忽略不计了 - 一个索引页的大小是16kb,1024 * 16/14 = 1170 也就是一个索引页能有1170个子节点,子节点指针数 = 索引记录数加1 ,也就是1171
- 那么理论上一个三层高的B+树能存1171 * 1171 * 16 = 21939616 条记录,两千多万条记录
在2000W+的记录中,通过三次IO就可以找到数据,而且性能均衡,因此B+树是非常强大的🐵
4,索引的分类
1,主键索引
-
当在一个表上定义一个主键 PRIMARY KEY 时,会自动创建主键索引,InnoDB 使用它作为聚集索引。
-
推荐为每个表定义一个主键。如果没有逻辑上唯一且非空的列可以作为主键,则添加一个自增列
2,普通索引
普通索引只负责为查询提速,不会对索引列的数值做「必须唯一、不能重复」的强制约束 ------索引列中可以出现重复的值,也可以出现多个 NULL 值
例如将用户的age作为普通索引,age是可以重复的
组合索引(复合索引)也属于普通索引,例如用class_id和name这两个列创建一个复合索引,如果先创建class_id,那排序就是先按class_id来排序,class_id相同再按name来排序
复合索引就类似于拼音表,先按声母排序,再按韵母排序
3,全文索引
全文索引是对大文本数据进行索引
- 基于文本列(CHAR、VARCHAR 或 TEXT 列)上创建,以加快对这些列中包含的数据查询和 DML 操作。
- 用于全文搜索,仅 MyISAM 和 InnoDB 引擎支持。
- 有专门的文档类型的数据库(mongodb),可以高效处理文档的检索
4,聚集索引(聚簇索引)
-
如果没有为表定义 PRIMARY KEY,InnoDB 使用第一个 UNIQUE 和 NOT NULL 的列作为聚集索引。自动选择
-
如果表中没有 PRIMARY KEY 或合适的 UNIQUE 索引,InnoDB 会为新插入的行生成一个行号并用 6 字节的 ROW_ID 字段记录,ROW_ID 单调递增,并使用 ROW_ID 做为索引
-
一个表中是一定会有一个聚集索引的,没有会自动生成
5,非聚集索引
聚集索引外的索引都称为非聚集索引或二级索引
像前面提到的普通索引就是非聚集索引
非聚集索引的存储也导致了回表查询的产生(如下图所示)
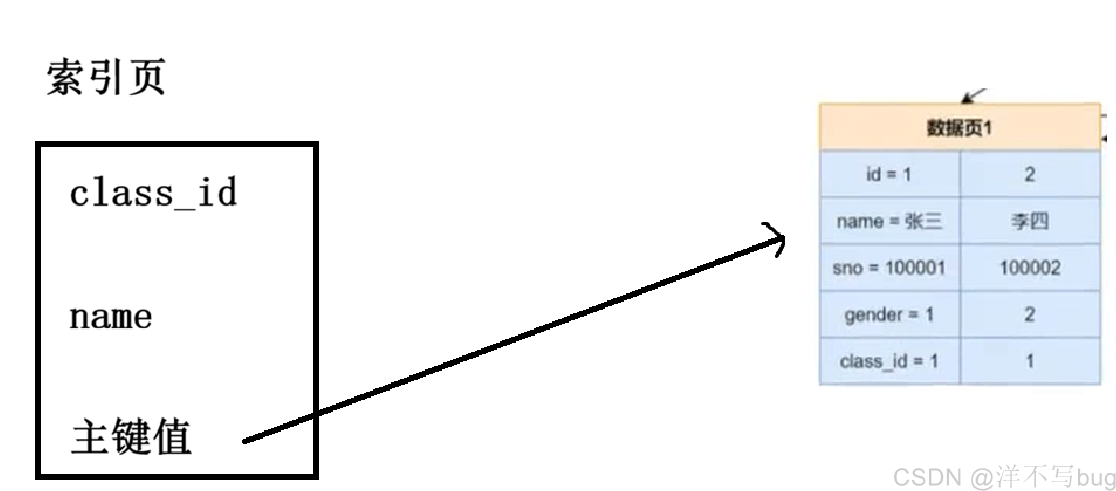
比如class_id和name组成普通索引,这就是非聚集索引
select * from student where class_id = 1 and name = '张三';
这里就会先通过第一个索引class_id找到范围的起点,再通过第二个索引在范围内进一步筛选,这时候在索引页中拿到的记录时class_id + name + 主键值,但是查询的是所有的数据,这时候就需要拿到主键值,到主表中再进行查询,再得到所有的列
这种拿着主键值去主表中进一步查找的行为,就叫主键查询这里再补充一种情况,就是索引的覆盖
当一个select语句中使用了普通索引,且创建查询列表中的列刚好是创建普通索引时的所有部分列,这时候就可以直接返回数据,而不用回表查询,这样的查询就称为索引覆盖

结语💕💕
可能有的铁汁从学习到现在,是第一次接触与索引相关的概念,这部分知识看起来可能比较复杂,但是认真梳理下,应该并没有什么特别难的地方
以上就是今天的所有内容啦~完结撒花~🥳🎉🎉
