深度学习网络从入门到入土 卷积神经网络lenet
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
- [深度学习网络从入门到入土 卷积神经网络lenet](#[深度学习网络从入门到入土] 卷积神经网络lenet)
- 个人导航
- 参考资料
- 背景
- 架构(公式)
-
-
-
- 1.输入层
- 2.卷积层(Convolution)
- 3.下采样层(Pooling)
- [4.全连接层(Fully Connected)](#4.全连接层(Fully Connected))
- 5.激活函数
-
-
- 创新点
-
-
-
- [1. LeNet 第一次完整定义了 CNN 的结构模板](#1. LeNet 第一次完整定义了 CNN 的结构模板)
- [2. 从"人工特征"到"特征学习"](#2. 从“人工特征”到“特征学习”)
-
-
- 代码实现
- 项目实例
参考资料
Gradient-based learning applied to document recognition
背景
在 LeNet 出现之前,图像任务基本是"手工特征 + 传统分类器":
- 边缘检测(Edge Detection)
- 人工特征(HOG / SIFT)
- 降维PCA / 投影LDA
- 最后接 SVM / KNN
这些方法有一个致命问题:特征是人为设计的,模型本身不会"学特征"
LeNet:第一次系统性地证明了:神经网络可以端到端地从原始图像中学习特征并完成分类
- 手写数字识别(MNIST)
- 支票 / 邮政编码识别
但尚未跑赢传统方法
架构(公式)
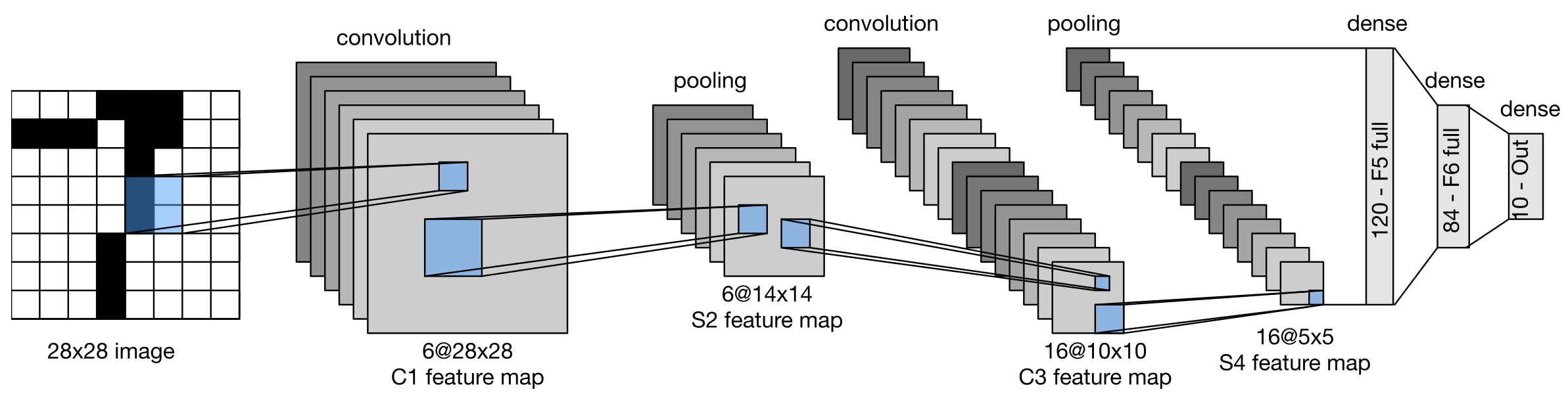
1.输入层
输入通常为灰度图像(channel=1):
X ∈ R 1 × 32 × 32 X \in \mathbb{R}^{1 \times 32 \times 32} X∈R1×32×32
- MNIST 原始是 28 × 28 28\times28 28×28 -> LeNet 里通常 padding 到 32 × 32 32\times32 32×32
2.卷积层(Convolution)
卷积的本质不是"滑窗",而是局部连接 + 权值共享。
对单通道输入,卷积可写为:
Y k ( i , j ) = ∑ c ∑ u , v W k , c ( u , v ) X c ( i + u , j + v ) + b k Y_{k}(i,j) = \sum_{c}\sum_{u,v} W_{k,c}(u,v)\,X_c(i+u,j+v) + b_k Yk(i,j)=c∑u,v∑Wk,c(u,v)Xc(i+u,j+v)+bk
LeNet 中的特点:
- 小卷积核( 5 × 5 5\times5 5×5)
- 通道数逐步增加
- 没有 padding(尺寸会缩小)
3.下采样层(Pooling)
LeNet 使用的是 平均池化(Average Pooling) :
Y ( i , j ) = 1 ∣ R ∣ ∑ ( u , v ) ∈ R X ( u , v ) Y(i,j) = \frac{1}{|R|}\sum_{(u,v)\in R} X(u,v) Y(i,j)=∣R∣1(u,v)∈R∑X(u,v)
这里和现代 CNN 有明显区别:
- 没有 MaxPool
- 平均池化 + 可学习参数(早期版本)
作用只有一个:降维 + 平移不变性
4.全连接层(Fully Connected)
经过两次 Conv + Pool 后,特征图被拉平成向量:
z = v e c ( X ) \mathbf{z} = \mathrm{vec}(X) z=vec(X)
再经过多层线性映射:
h = σ ( W z + b ) \mathbf{h} = \sigma(W\mathbf{z} + b) h=σ(Wz+b)
最终输出类别概率。
5.激活函数
LeNet 使用的是 tanh / sigmoid :
σ ( x ) = tanh ( x ) \sigma(x) = \tanh(x) σ(x)=tanh(x)
这是时代局限:
- ReLU 当时还没流行
- 梯度消失问题在那时并未被系统性认识
创新点
1. LeNet 第一次完整定义了 CNN 的结构模板
- 局部感受野
- 权值共享
- 多层特征抽象
- 端到端训练
2. 从"人工特征"到"特征学习"
LeNet 的核心思想不是网络多深,而是特征不再由人设计,而是由数据驱动学习得到
这是现代深度学习的思想源头
代码实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledTanh(nn.Module):
"""
原论文常用的缩放版 tanh
f(x) = 1.7159 * tanh((2/3) * x)
"""
def __init__(self, A=1.7159, S=2.0/3.0):
super().__init__()
self.A = A
self.S = S
def forward(self, x):
return self.A * torch.tanh(self.S * x)
class SubsamplingLayer(nn.Module):
"""
原论文的 S 层(subsampling layer)
不是纯 AvgPool,而是:
y = a * avgpool(x) + b
其中 a,b 对每个通道(feature map)可学习
输入: (N, C, H, W)
输出: (N, C, H/2, W/2) (当 kernel=2, stride=2)
"""
def __init__(self, channels, kernel_size=2, stride=2):
super().__init__()
# 平均池化:负责下采样
self.pool = nn.AvgPool2d(kernel_size=kernel_size, stride=stride)
# 每个通道一个可学习的缩放系数 a 和偏置 b
# 形状是 (C,) ,forward 时会 reshape 成 (1,C,1,1) 以便广播
self.a = nn.Parameter(torch.ones(channels))
self.b = nn.Parameter(torch.zeros(channels))
def forward(self, x):
# 先做下采样
x = self.pool(x) # (N,C,H/2,W/2)
# 做通道级的仿射变换:a * x + b
a = self.a.view(1, -1, 1, 1)
b = self.b.view(1, -1, 1, 1)
x = a * x + b
return x
class B_LeNet5_Paper(nn.Module):
"""
输入: (N, 1, 32, 32)
注意:
- 这里把 S2/S4 改成论文里的 subsampling(avgpool + 可学习 a,b)
- 激活用论文常用的 scaled tanh
- C3 的"部分连接表"(partial connectivity) 这里仍使用现代全连接卷积(更常见的复现做法)
如果你要严格复刻 C3 的连接表,我也可以再给一版
工作流(形状):
(N,1,32,32)
-> conv5x5 -> (N,6,28,28) [可学习]
-> tanh
-> paper-sub -> (N,6,14,14) [可学习 a,b]
-> conv5x5 -> (N,16,10,10) [可学习]
-> tanh
-> paper-sub -> (N,16,5,5) [可学习 a,b]
-> conv5x5 -> (N,120,1,1) [可学习]
-> tanh
-> flatten -> (N,120)
-> linear -> (N,84) [可学习]
-> tanh
-> linear -> (N,10) [可学习]
"""
def __init__(self, num_classes=10):
super().__init__()
# 论文风格激活
self.act = ScaledTanh()
# C1: 1 -> 6
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0)
# S2: 6 通道的论文风格下采样(avgpool + 可学习 a,b)
# 是否在 S 层后再接激活:这里先不接(更保守、也更常见)
self.pool2 = SubsamplingLayer(channels=6, kernel_size=2, stride=2)
# C3: 6 -> 16
self.conv3 = nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0)
# S4: 16 通道的论文风格下采样
self.pool4 = SubsamplingLayer(channels=16, kernel_size=2, stride=2)
# C5: 16 -> 120,输入正好是 5x5,所以输出 1x1
self.conv5 = nn.Conv2d(16, 120, kernel_size=5, stride=1, padding=0)
# F6
self.fc6 = nn.Linear(120, 84)
# F7
self.fc7 = nn.Linear(84, num_classes)
def forward(self, x):
# 兼容 MNIST 原始 28x28:先 pad 到 32x32
if x.shape[-2:] == (28, 28):
x = F.pad(x, (2, 2, 2, 2)) # left,right,top,bottom
# conv + act
x = self.conv1(x) # (N,6,28,28)
x = self.act(x)
# pool
x = self.pool2(x) # (N,6,14,14)
# conv + act
x = self.conv3(x) # (N,16,10,10)
x = self.act(x)
# pool
x = self.pool4(x) # (N,16,5,5)
# conv + act
x = self.conv5(x) # (N,120,1,1)
x = self.act(x)
# flatten
x = x.view(x.size(0), -1) # (N,120)
# linear + act
x = self.fc6(x) # (N,84)
x = self.act(x)
# linear
logits = self.fc7(x) # (N,10)
return logits
if __name__ == '__main__':
net = B_LeNet5_Paper(num_classes=2)
a = torch.randn(50, 1, 28, 28)
result = net(a)
print(result.shape)项目实例
库环境:
numpy==1.26.4
torch==2.2.2cu121
byzh-core==0.0.9.21
byzh-ai==0.0.9.48
byzh-extra==0.0.9.12
...LeNet5训练MNIST数据集:
py
import torch
from byzh.ai.Btrainer import B_Classification_Trainer
from byzh.ai.Bdata import B_Download_MNIST, b_get_dataloader_from_tensor
from byzh.ai.Bmodel.study_cnn import B_LeNet5_Paper
from byzh.ai.Butils import b_get_device
##### data #####
downloader = B_Download_MNIST(save_dir='D:/study_cnn/datasets/MNIST')
data_dict = downloader.get_data()
X_train = data_dict['X_train_standard']
y_train = data_dict['y_train']
X_test = data_dict['X_test_standard']
y_test = data_dict['y_test']
num_classes = data_dict['num_classes']
train_dataloader, val_dataloader = b_get_dataloader_from_tensor(X_train, y_train, X_test, y_test)
##### model #####
model = B_LeNet5_Paper(num_classes=num_classes)
##### else #####
epochs = 10
lr = 1e-3
device = b_get_device(use_idle_gpu=True)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
##### trainer #####
trainer = B_Classification_Trainer(
model=model,
optimizer=optimizer,
criterion=criterion,
train_loader=train_dataloader,
val_loader=val_dataloader,
device=device
)
trainer.set_writer1('./runs/log.txt')
##### run #####
trainer.train_eval_s(epochs=epochs)
##### calculate
trainer.draw_loss_acc('./runs/loss_acc.png', y_lim=False)
trainer.save_best_checkpoint('./runs/lenet5_best.pth')
trainer.calculate_model()