核心概念介绍
微服务架构⻛格,就像是把⼀个单独的应⽤程序开发为⼀套⼩服务,每个⼩服务运⾏在⾃⼰的进程
中,并使⽤轻量级机制通信,通常是 HTTP API。这些服务围绕业务能⼒来构建, 并通过完全⾃
动化部署机制来独⽴部署。这些服务使⽤不同的编程语⾔书写,以及不同数据存储技术,并保持最
低限度的集中式管理。
简⽽⾔之:拒绝⼤型单体应⽤,基于业务边界进⾏服务微化拆分,各个服务独⽴部署运⾏。

远程调用
在分布式系统中,各个服务可能处于不同主机,但是服务之间不可避免的需要互相调⽤,我们称为
远程调⽤。 SpringCloud 中使⽤ HTTP+JSON 的⽅式完成远程调⽤
负载均衡
分布式系统中,A 服务需要调⽤ B 服务,B 服务在多台机器中都存在,A 调⽤任意⼀个服务器均
可完成功能。 为了使每⼀个服务器都不要太忙或者太闲,我们可以负载均衡的调⽤每⼀个服务
器,提升⽹站的健壮性。
常⻅的负载均衡算法:
轮询:为第⼀个请求选择健康池中的第⼀个后端服务器,然后按顺序往后依次选择,直到最后
⼀个,然后循环。
最⼩连接:优先选择连接数最少,也就是压⼒最⼩的后端服务器,在会话较⻓的情况下可以考
虑采取这种⽅式。
散列:根据请求源的 IP 的散列(hash)来选择要转发的服务器。这种⽅式可以⼀定程度上保
证特定⽤户能连接到相同的服务器。如果你的应⽤需要处理状态⽽要求⽤户能连接到和之前相
同的服务器,可以考虑采取这种⽅式。
服务注册/发现---注册中⼼
A 服务调⽤ B 服务,A 服务并不知道 B 服务当前在哪⼏台服务器有,哪些正常的,哪些服务已经
下线。解决这个问题可以引⼊注册中⼼;如果某些服务下线,我们其他⼈可以实时的感知到其他服务的状态,从⽽避免调⽤不可⽤的服务
配置中⼼
每⼀个服务最终都有⼤量的配置,并且每个服务都可能部署在多台机器上。我们经常需要变更配
置,我们可以让每个服务在配置中⼼获取⾃⼰的配置。
服务熔断&服务降级
在微服务架构中,微服务之间通过⽹络进⾏通信,存在相互依赖,当其中⼀个服务不可⽤时,请求积压有可 能会造成雪崩效应。要防⽌这样的情况,必须要有容错机制来保护服务。
服务熔断
设置服务的超时,当被调⽤的服务经常失败到达某个阈值,我们可以开启断路保护机制,后来的请
求不再去调⽤这个服务。本地直接返回默认的数据
服务降级
在运维期间,当系统处于⾼峰期,系统资源紧张,我们可以让⾮核⼼业务降级运⾏。降级:某些服
务不处理,或者简单处理【抛异常、返回 NULL、调⽤ Mock 数据、调⽤ Fallback 处理逻辑】
API ⽹关
在微服务架构中,API Gateway 作为整体架构的重要组件,它 抽象了微服务中都需要的公共功
能 ,同时提供了客户端负载均衡,服务⾃动熔断,灰度发布,统⼀认证,限流流控,⽇志统计等丰
富的功能,帮助我们解决很多 API 管理难题。 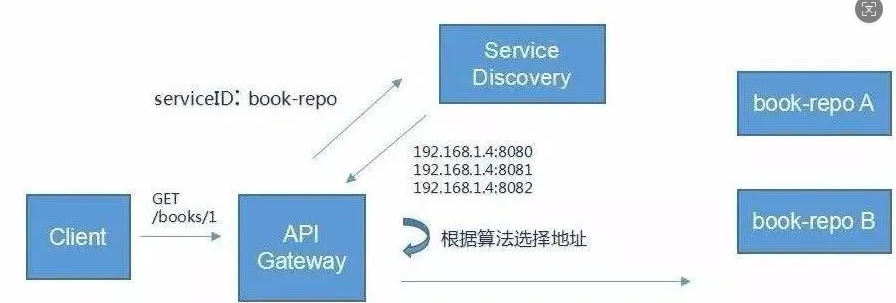
接下来我们讲解以下核心内容
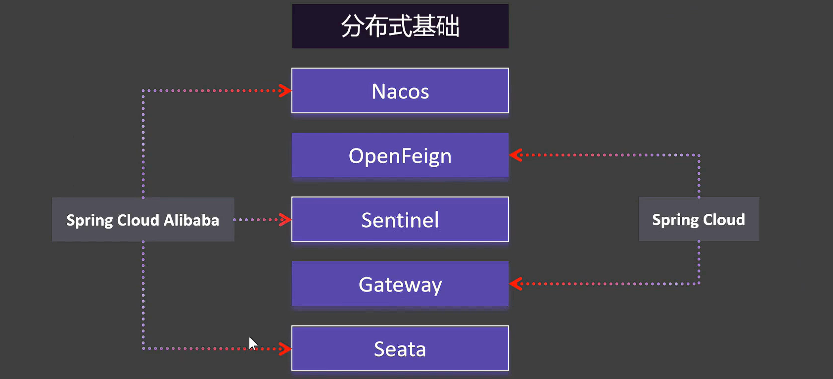
Nacos
Nacos 是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
安装
Nacos 的安装非常简单,推荐使用 standalone 模式进行本地开发和测试。
-
准备环境:确保您的机器已安装 JDK 17+ 及 Maven 3.2.x+。
-
下载安装包 :从 Nacos GitHub Release 页面下载最新的稳定版 zip 或 tar 包。
-
解压并启动 :
bash# 解压 unzip nacos-server-$version.zip cd nacos-server-$version # Linux/Mac sh startup.sh -m standalone # Windows 在bin目录下 cmd startup.cmd -m standalone #docker安装启动 docker run --name nacos-standalone -e MODE=standalone -p 8848:8848 -d nacos/nacos-server:latest -
访问控制台 :启动成功后,打开浏览器访问
http://localhost:8848/nacos。默认的用户名和密码都是nacos。
注册中心
注册中心是微服务架构的"通讯录",负责管理所有服务的实例信息。
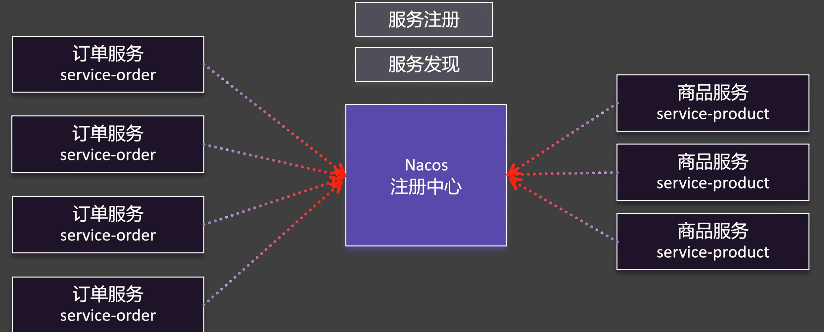
服务注册
服务注册就是将服务的信息(如服务名、IP、端口)注册到 Nacos。
-
创建服务提供者 :创建一个 Spring Boot 项目,例如
service-provider。 -
添加依赖 :在
pom.xml中引入nacos-discovery依赖。XML<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> -
配置文件 :在
application.yml中配置 Nacos 服务地址。bashserver: port: 8081 spring: application: name: service-provider # 服务名称,重要 cloud: nacos: discovery: server-addr: localhost:8848 # nacos地址 -
开启服务注册 :在主启动类上添加
@EnableDiscoveryClient注解(新版本中可省略)。
启动项目后,在 Nacos 控制台的"服务管理 -> 服务列表"中,就能看到名为 service-provider 的服务了。
服务发现
服务发现是指消费者从 Nacos 获取到服务提供者的实例列表,从而进行调用。
- 创建服务消费者 :创建另一个 Spring Boot 项目,例如
service-consumer。 - 添加依赖和配置 :与服务提供者类似,添加
nacos-discovery依赖,并配置application.yml。
bash
server:
port: 8080 # 服务消费者端口
spring:
application:
name: service-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
编写微服务API
java
@RestController
public class EchoController {
@GetMapping("/echo/{string}")
public String echo(@PathVariable String string) {
return "Hello Nacos Discovery: " + string;
}
}DiscoveryClient
java
@Autowired
DiscoveryClient discoveryClient;
@Test
void discoveryClientTest(){
for (String service : discoveryClient.getServices()) {
System.out.println("service = " + service);
//获取ip+port
List<ServiceInstance> instances = discoveryClient.getInstances(ser
vice);
for (ServiceInstance instance : instances) {
System.out.println("ip:"+instance.getHost()+";"+"port = " +
instance.getPort());
}
}
}NacosServiceDiscovery
java
@Autowired
NacosServiceDiscovery nacosServiceDiscovery;
@Test
void nacosServiceDiscoveryTest() throws NacosException {
for (String service : nacosServiceDiscovery.getServices()) {
System.out.println("service = " + service);
List<ServiceInstance> instances = nacosServiceDiscovery.getInstanc
es(service);
for (ServiceInstance instance : instances) {
System.out.println("ip:"+instance.getHost()+";"+"port = " +
instance.getPort());
}
}
}远程调用基本实现
-
配置 RestTemplate :
java@Bean public RestTemplate restTemplate() { return new RestTemplate(); } -
编写调用逻辑 :
java@RestController public class ConsumerController { @Autowired private RestTemplate restTemplate; @GetMapping("/test") public String test() { // 硬编码URL,存在单点问题,无法负载均衡 String url = "http://localhost:8081/echo/2025"; return restTemplate.getForObject(url, String.class); } }
负载均衡API测试与@LoadBalanced注解
-
改造 RestTemplate :只需在 Bean 上添加一个注解。
java@Bean @LoadBalanced // 关键注解 public RestTemplate restTemplate() { return new RestTemplate(); } -
改造调用逻辑 :将 IP 和端口替换为服务名。
java@GetMapping("/test") public String test() { // 使用服务名进行调用,Ribbon(或Spring Cloud LoadBalancer)会自动进行负载均衡 String url = "http://service-provider/echo/2025"; return restTemplate.getForObject(url, String.class); }
为了验证负载均衡,我们可以启动多个 service-provider 实例。
在 Nacos 控制台,你会看到 service-provider 下有两个实例。此时,多次访问 http://localhost:8080/test,你会发现请求被轮询分发到了 8081 和 8082 两个端口上,证明负载均衡生效。
经典面试题
-
Nacos、Eureka、Consul 的区别是什么?
- 一致性协议:Nacos 支持 AP(默认)和 CP 模式切换;Eureka 是 AP 模式;Consul 是 CP 模式。
- 健康检查:Nacos/Consul 支持主动检查(TCP/HTTP)和客户端心跳;Eureka 仅支持客户端心跳。
- 功能集成:Nacos 集成了服务发现和配置中心;Eureka 仅负责服务发现;Consul 功能丰富,包括服务网格支持。
- 易用性:Nacos 提供了非常友好的控制台和中文文档,对国内开发者更友好。
-
Nacos 如何保证服务的可用性(AP模式)?
Nacos 默认采用 AP 模式。每个服务实例会定期向 Nacos Server 发送心跳,证明自己"存活"。Nacos Server 会将实例信息存储在内存中,并定时将数据同步给其他节点。如果一个实例在规定时间内未发送心跳,Nacos 不会立即将其剔除,而是标记为不健康,等待一段时间后仍未恢复才剔除。这种设计优先保证了服务的可用性(即使部分节点宕机,注册中心依然可用),牺牲了数据的强一致性。
配置中心
Nacos 的另一大核心功能是作为配置中心,实现配置的统一管理和动态刷新。
基本用法
在项目中引入 nacos-config 依赖
XML
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>创建 bootstrap.yml :配置中心的配置需要优先于 application.yml 加载,因此必须放在 bootstrap.yml(或 bootstrap.properties)中。
bash
# 指定配置中⼼地址
spring.cloud.nacos.server-addr=localhost:8848
spring.config.import=nacos:service-order.properties spring:
application:
name: service-consumer # 必须与 Nacos Data Id 中的前缀匹配
cloud:
nacos:
config:
server-addr: localhost:8848
file-extension: yaml # 配置文件的后缀
# group: DEFAULT_GROUP # 配置分组,默认为 DEFAULT_GROUP
在 Nacos 控制台添加配置:
-
进入"配置管理 -> 配置列表"。
-
点击"+"新增配置。
-
Data ID :
service-consumer.yaml(规则:${spring.application.name}.${file-extension}) -
Group :
DEFAULT_GROUP -
配置格式 :
YAMLbashuser: name: "Nacos-User" age: 25 -
在代码中使用配置 :
java@RestController @RefreshScope // 动态刷新的关键注解 public class ConfigController { @Value("${user.name}") private String userName; @Value("${user.age}") private int userAge; @GetMapping("/config") public String getConfig() { return "User Name: " + userName + ", Age: " + userAge; } }
动态刷新
这是 Nacos 配置中心最强大的功能之一。
- 在上面的代码中,我们添加了
@RefreshScope注解。 - 现在,去 Nacos 控制台修改
user.age的值为30,然后点击"发布"。 - 无需重启应用,再次访问
http://localhost:8080/config,你会发现返回的年龄已经变成了30。
配置监听
除了 @RefreshScope 的自动刷新,你还可以通过编程式的方式监听配置变更。
java
@Component
public class NacosConfigListener {
@NacosConfigListener(dataId = "service-consumer.yaml")
public void onMessage(String newContent) {
System.out.println("配置发生变更!新内容为:" + newContent);
// 在这里可以执行更复杂的逻辑,比如更新缓存、通知其他组件等
}
}
java
//⽆需 @RefreshScope,⾃动绑定配置,动态更新
@Component
@ConfigurationProperties(prefix = "order") //配置批量绑定在nacos下,可以⽆需@R
efreshScope就能实现⾃动刷新
@Data
public class OrderProperties {
String timeout;
String autoConfirm;
String dbUrl;
}经典面试题
-
Nacos 配置中心是如何实现动态刷新的?
Nacos 客户端在启动时会从 Nacos Server 拉取一次全量配置,并开启一个长轮询任务。这个任务会向服务端发起一个请求,如果服务端的配置在 30 秒内没有变化,请求会阻塞直到超时。一旦配置发生变化,服务端会立即响应,客户端收到响应后,会再次拉取最新的配置,然后刷新 Spring 上下文中的 Bean。这是一种 Client Pull + Server Push 结合的优化模式,既保证了实时性,又降低了服务端压力。
-
如果 Nacos Server 宕机,客户端应用还能读取到配置吗?
能。Nacos 客户端在获取到配置后,会在本地生成一个快照文件。当与 Nacos Server 的连接断开时,客户端会从本地快照中加载配置,保证了应用的容错能力。
数据隔离
在实际开发中,我们通常需要区分开发、测试、生产等不同环境的配置。Nacos 提供了 Namespace 来实现数据隔离。
Namespace区分多环境
Nacos 通过 Namespace(命名空间) 和 Group(组) 实现配置隔离:
- Namespace :用于区分不同环境(如 dev、test、prod)。

- Group :用于区分不同微服务或业务模块,⼀般可以⽤微服务的名字作为⾃⼰的组。
- Data ID :具体配置文件名,完整写法: 名字.后缀 如: common.properties,支持多配置文件管理。
例如:
- 开发环境:namespace=dev, group=USER_GROUP, data-id=user-service.yaml
- 生产环境:namespace=prod, group=USER_GROUP, data-id=user-service.yaml
bash
spring:
cloud:
nacos:
discovery:
namespace: ${spring.profiles.active:dev}
config:
namespace: ${spring.profiles.active:dev}步骤:
-
创建 Namespace :在 Nacos 控制台的"命名空间"页面,新建一个命名空间,例如
dev,系统会自动生成一个 ID(如a1b2c3d4-e5f6-g7h8-i9j0-k1l2m3n4o5p6)。 -
在 dev Namespace 下创建配置 :在新增配置时,选择刚刚创建的
dev命名空间。 -
修改客户端配置 :在
bootstrap.yml中指定要使用的 Namespace ID。bashspring: cloud: nacos: config: server-addr: localhost:8848 file-extension: yaml namespace: a1b2c3d4-e5f6-g7h8-i9j0-k1l2m3n4o5p6 # 指定命名空间ID
动态切换环境
我们可以在启动应用时,通过 JVM 参数动态指定 Namespace,从而实现一套代码、多环境部署。
bash
java -jar -Dspring.cloud.nacos.config.namespace=dev-id your-app.jar
java -jar -Dspring.cloud.nacos.config.namespace=prod-id your-app.jarnacos总结

OpenFeign
OpenFeign是一个声明式的Web服务客户端,它使得编写HTTP客户端变得更加简单。通过简单的接口定义和注解配置,就可以完成对远程服务的调用。
核心优势:
- 声明式:通过接口和注解定义调用,无需手动拼接 URL 和处理参数。
- 可插拔:支持多种编码器(如 Jackson)、解码器和拦截器。
- 集成 Ribbon/LoadBalancer:原生集成了客户端负载均衡,只需提供服务名即可。
远程调用
声明式实现

- 第一步:添加依赖
XML
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>- 第二步:启用 Feign 客户端
在 Spring Boot 启动类上添加 @EnableFeignClients 注解:
java
@SpringBootApplication
@EnableFeignClients // 开启 Feign 客户端功能
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}- 第三步:创建并使用 Feign 客户端
-
定义一个接口 ,使用
@FeignClient注解指定要调用的服务名称。java// UserClient.java @FeignClient(name = "user-service") // name 指向服务注册中心的服务名 public interface UserClient { // 定义一个 GET 请求,路径为 /users/{id} @GetMapping("/users/{id}") User getUserById(@PathVariable("id") Long id); // 定义一个 POST 请求 @PostMapping("/users") User createUser(@RequestBody User user); }
-
在业务代码中注入并使用 ,就像调用本地方法一样简单
java// OrderService.java @Service public class OrderService { @Autowired private UserClient userClient; // 注入 Feign 客户端 public Order createOrder(Long userId, String productName) { // 1. 通过 Feign 远程调用用户服务,获取用户信息 User user = userClient.getUserById(userId); if (user == null) { throw new RuntimeException("用户不存在"); } // 2. 创建订单逻辑... Order order = new Order(); order.setUserId(userId); order.setProductName(productName); // ... 其他逻辑 System.out.println("为用户 " + user.getName() + " 创建订单成功!"); return order; } }
第三方API
OpenFeign 不仅能调用微服务集群内的服务,也能轻松调用任何外部的第三方 REST API。这时,我们只需要使用 url 属性代替 name。
java
@FeignClient(name = "weather-api", url = "https://api.openweathermap.org/data/2.5") // 直接指定 URL
public interface WeatherClient {
@GetMapping("/weather")
String getWeather(@RequestParam("q") String city, @RequestParam("appid") String apiKey);
}进阶配置
生产环境中,网络波动、服务延迟是常态。OpenFeign 提供了丰富的配置来增强调用的健壮性。
超时配置
为了避免长时间等待导致服务雪崩,配置超时至关重要。OpenFeign 有两个超时设置:
connectTimeout:连接超时,指建立 TCP 连接的时间。readTimeout:读取超时,指连接建立后,等待服务器返回数据的时间。
在 application.yml 中配置:
bash
feign:
client:
config:
# 全局默认配置
default:
connectTimeout: 5000 # 5秒
readTimeout: 10000 # 10秒
# 针对特定服务的配置(优先级更高)
user-service:
connectTimeout: 3000
readTimeout: 6000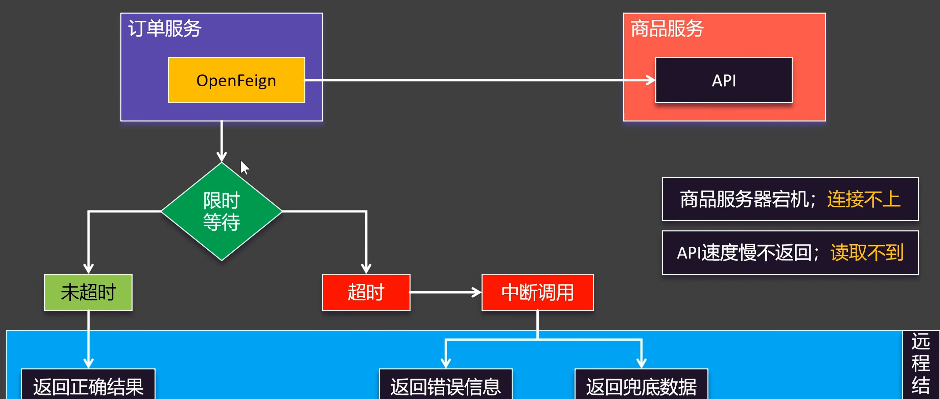
重试机制
对于瞬时的网络抖动,自动重试可以有效提高成功率。OpenFeign 默认是关闭重试的,我们可以自定义一个 Retryer Bean 来开启它。
java
@Bean
public Retryer feignRetryer() {
// 初始间隔100ms,最大间隔1s,最大重试次数3次(总共会尝试4次)
return new Retryer.Default(100, SECONDS.toMillis(1), 3);
}拦截器
拦截器可以在请求发送前执行通用逻辑,最常见的场景就是统一添加认证头(如 JWT Token)。
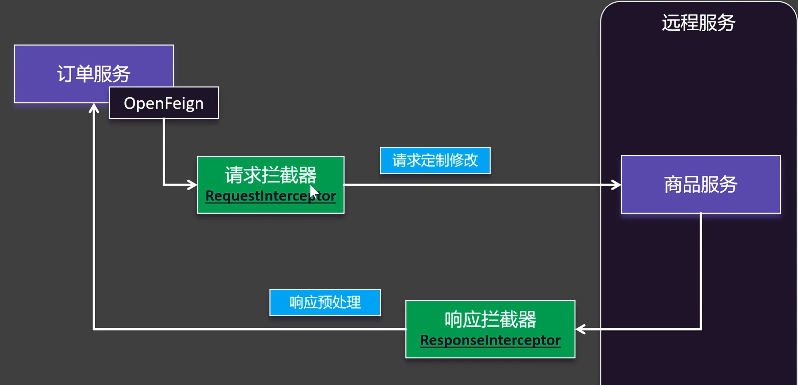
-
实现
RequestInterceptor接口javapublic class AuthRequestInterceptor implements RequestInterceptor { @Override public void apply(RequestTemplate template) { // 从上下文或其他地方获取 Token String token = "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."; // 为所有请求添加 Authorization 头 template.header("Authorization", token); } } -
注册拦截器
java@Bean public AuthRequestInterceptor authRequestInterceptor() { return new AuthRequestInterceptor(); }这样,所有通过 Feign 发出的请求都会自动带上
Authorization头。
Fallback兜底回调
当服务提供者不可用或调用失败时,为了不让整个流程崩溃,我们需要一个兜底方案,这就是服务降级。OpenFeign 提供了两种方式实现 Fallback。
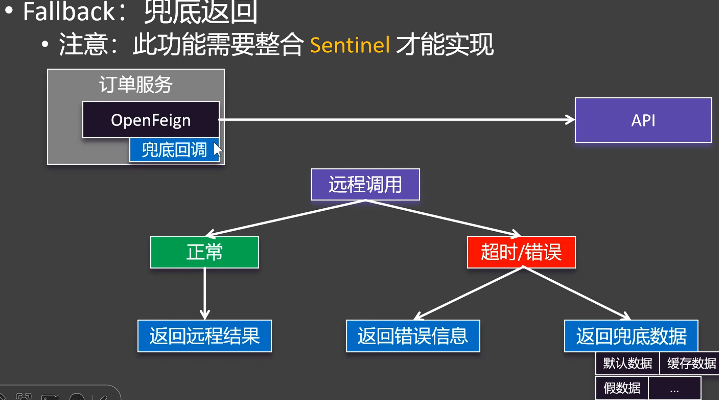
方式一:fallback 属性(简单但功能有限)
-
创建一个 Fallback 类 ,实现 Feign 客户端接口。
java@Component // 注意:需要被 Spring 容器管理 public class UserClientFallback implements UserClient { @Override public User getUserById(Long id) { // 返回一个兜底的默认用户或空对象 User defaultUser = new User(); defaultUser.setId(-1L); defaultUser.setName("默认用户"); return defaultUser; } @Override public User createUser(User user) { return null; } } -
在
@FeignClient中指定java@FeignClient(name = "user-service", fallback = UserClientFallback.class) public interface UserClient { // ... }缺点:这种方式无法获取到具体的异常信息。
方式二:fallbackFactory 属性(推荐,功能强大)
FallbackFactory 允许你创建一个工厂类,在 Fallback 逻辑中可以捕获到导致调用失败的异常。
-
创建一个 FallbackFactory
java@Component public class UserClientFallbackFactory implements FallbackFactory<UserClient> { @Override public UserClient create(Throwable cause) { return new UserClient() { @Override public User getUserById(Long id) { // 在这里可以记录详细的错误日志 System.err.println("调用 user-service 失败,原因: " + cause.getMessage()); // 返回兜底数据 User defaultUser = new User(); defaultUser.setId(-1L); defaultUser.setName("服务降级-默认用户"); return defaultUser; } // ... 其他方法实现 }; } } -
在
@FeignClient中指定java@FeignClient(name = "user-service", fallbackFactory = UserClientFallbackFactory.class) public interface UserClient { // ... }
远程调用小技巧&面试题
日志
OpenFeign 支持以下几种日志级别:
| 日志级别 | 说明 |
|---|---|
NONE |
不记录任何日志(默认) |
BASIC |
仅记录请求方法、URL、响应状态码和执行时间 |
HEADERS |
记录 BASIC 信息+请求和响应头信息 |
FULL |
记录请求和响应的 headers、body 和元数据 |

性能优化
-
连接池 :Feign 默认使用 JDK 的
HttpURLConnection,性能不高。可以替换为Apache HttpClient或OkHttp,它们支持连接池,性能更优。 -
GZIP 压缩 :开启请求和响应的 GZIP 压缩,可以减少网络传输数据量。
bashfeign: compression: request: enabled: true response: enabled: true
面试题1:Feign 的底层实现原理是什么?
答: Feign 的核心是动态代理 。当你注入一个 @FeignClient 标记的接口时,Feign 会为这个接口创建一个动态代理对象(基于 JDK 的 Proxy)。当你调用接口方法时,这个代理对象会拦截所有调用。它会将方法名、参数、注解(如 @GetMapping)等信息封装成一个 RequestTemplate,然后经过编码器、拦截器等处理,最终委托给底层的 HTTP 客户端(如 HttpURLConnection)去发起真正的 HTTP 请求。收到响应后,再由解码器将响应数据反序列化成接口方法的返回值
面试题2:@FeignClient 中的 name 和 url 属性有什么区别?
答:
name:用于指定服务名 。当使用name时,Feign 会结合服务发现组件(如 Nacos、Eureka)和客户端负载均衡器(如 Spring Cloud LoadBalancer)来解析该服务的多个实例地址,并从中选择一个进行调用。这是微服务内部调用的标准用法。url:用于指定一个具体的、固定的 URL 。当使用url时,Feign 会直接向这个地址发起请求,不会 经过服务发现和负载均衡。这通常用于调用外部的、固定的第三方 API。
面试题3:Ribbon/LoadBalancer 和 Feign 是什么关系?
答: 它们是协作关系,职责不同。
- Feign :是一个声明式的 HTTP 客户端,负责将 Java 接口调用翻译成 HTTP 请求。它解决了"如何优雅地发起调用"的问题。
- Ribbon/LoadBalancer :是一个客户端负载均衡器(负载均衡发生在客户端) ,负责从服务实例列表中选择一个具体的实例。它解决了"调用哪一个实例"的问题。
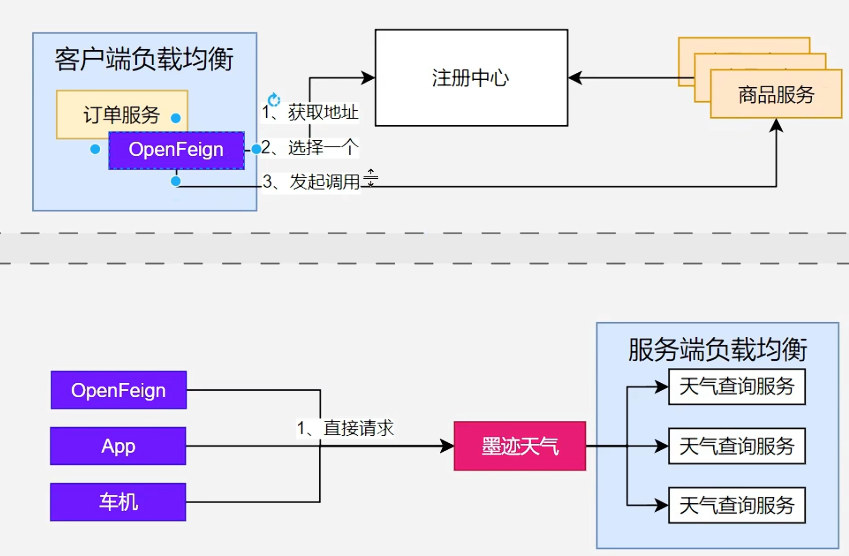
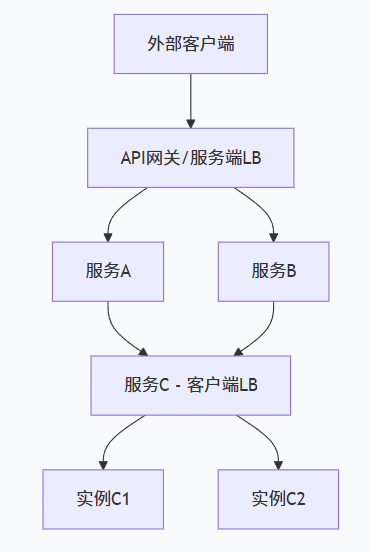 实际开发通常混用两种模式
实际开发通常混用两种模式
在 Spring Cloud 中,Feign 集成了 LoadBalancer。当 Feign 使用 name 属性时,它会自动委托 LoadBalancer 去获取服务实例列表并执行负载均衡算法,然后将选中的实例 IP 和端口交给 Feign 的底层 HTTP 客户端完成请求。
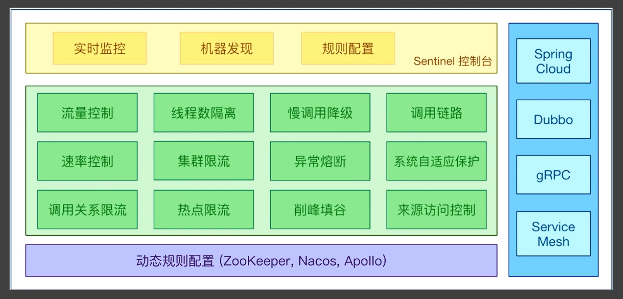
Sentinel
一个服务的故障或延迟,可能会像多米诺骨牌一样,引发整个系统的连锁反应,导致"雪崩效应"。为了保障系统的稳定性和高可用性,流量控制、服务熔断和降级显得至关重要
工作原理
-
资源化 :Sentinel 会将需要保护的逻辑,例如一个方法、一个接口,定义为一个资源。只要通过 Sentinel API 对这个资源进行访问,就可以被 Sentinel 监控和保护。
-
插槽链:这是 Sentinel 的核心设计。当一个请求访问一个资源时,它会经过一系列的插槽,每个插槽都负责一项特定的功能,如限流、降级、系统保护等。这些插槽串联起来,形成了一条责任链。
bash[请求] -> NodeSelectorSlot -> ClusterBuilderSlot -> StatisticSlot -> [其他Slot] -> FlowSlot -> DegradeSlot -> SystemSlot -> [目标资源]* `NodeSelectorSlot` & `ClusterBuilderSlot`:负责构建资源的统计节点(StatisticNode),用于后续的统计。 * `StatisticSlot`:核心统计插槽,用于记录资源的请求响应时间、成功数、失败数等指标,是限流和熔断的基础。 * `FlowSlot`:**流控插槽**。它根据预设的流控规则,检查当前请求是否应该被限流。如果 QPS 或并发线程数超过阈值,就会抛出 `BlockException`。 * `DegradeSlot`:**熔断降级插槽**。它根据熔断规则,检查资源的健康状态。如果满足熔断条件(如错误率过高),则会触发熔断,后续请求将在一段时间内直接被拒绝。 * `SystemSlot`:**系统保护插槽**。它从整体维度(如 CPU 使用率、系统负载等)来保护应用,防止系统被压垮。
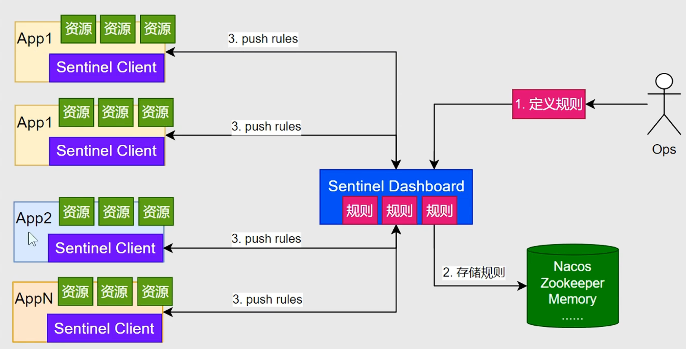
基础场景
Sentinel 的应用场景非常广泛,主要可以归纳为以下三类:
- 流量控制:在流量洪峰来临之际,通过限制请求的通过速率,防止系统被瞬间的高流量冲垮。例如,将某个 API 的 QPS 限制为 100。
- 熔断降级:当某个依赖的服务出现不稳定(响应时间变长或错误率升高)时,暂时切断对它的调用,避免请求堆积,从而保护主服务不受影响。这是一种"丢卒保帅"的策略。
- 系统负载保护:当系统的整体负载(如 CPU、内存)过高时,对进入系统的所有请求进行限流,保证系统不会因过载而崩溃。
异常处理
当 Sentinel 的规则被触发时(如流控或熔断),默认会抛出 BlockException。如果我们不处理这个异常,用户可能会看到一个不友好的错误页面。因此,优雅地处理异常是 Sentinel 应用中至关重要的一环。
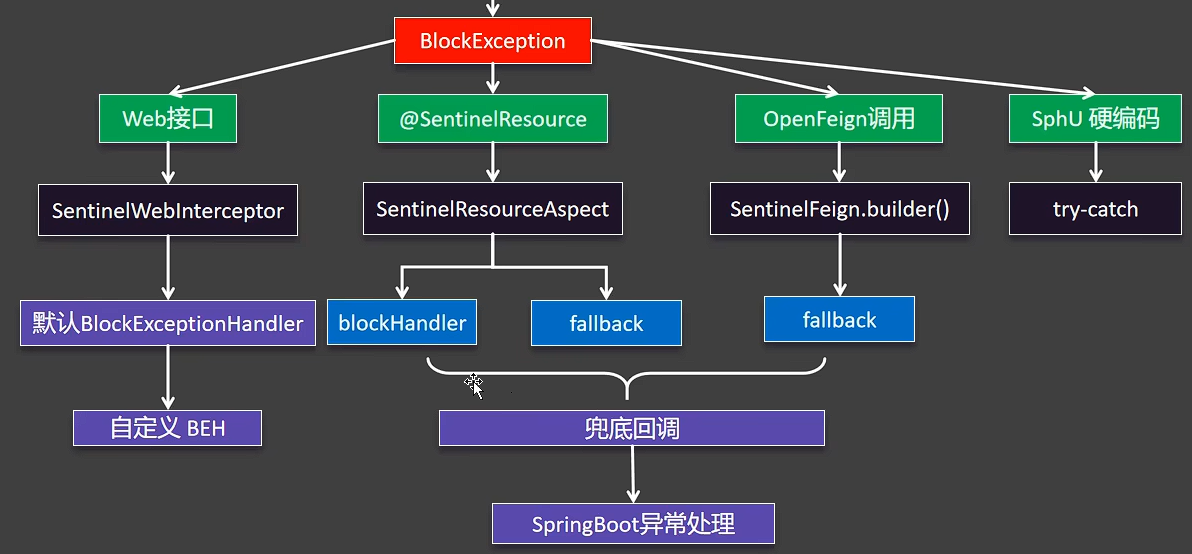
1. Web 接口
对于 Spring MVC 或 WebFlux 应用,我们可以使用全局异常处理器来捕获 BlockException。
java
@ControllerAdvice
public class GlobalBlockExceptionHandler {
@ResponseBody
@ResponseStatus(HttpStatus.TOO_MANY_REQUESTS)
@ExceptionHandler(BlockException.class)
public Response handleBlockException(BlockException e) {
return Response.error(429, "系统繁忙,请稍后再试!"); // 自定义响应
}
}2. @SentinelResource
@SentinelResource 是 Sentinel 提供的核心注解,用于更细粒度地定义资源和处理异常。它提供了两个关键属性:blockHandler 和 fallback。
blockHandler:专门处理Sentinel 规则 (流控、熔断)被触发时抛出的BlockException。fallback:处理代码本身 抛出的所有异常(如RuntimeException、IOException等)。
java
@Service
public class ProductService {
// value: 资源名称
// blockHandler: 处理BlockException的方法
// fallback: 处理Java异常的方法
@SentinelResource(value = "getProduct", blockHandler = "handleBlock", fallback = "handleFallback")
public String getProduct(String id) {
if ("1".equals(id)) {
throw new RuntimeException("商品不存在!");
}
// ... 正常业务逻辑
return "Product-" + id;
}
// BlockException处理函数,参数需与原方法一致,最后多一个BlockException参数
public String handleBlock(String id, BlockException ex) {
return "系统繁忙,请稍后再试 (BlockHandler)";
}
// Fallback处理函数,参数需与原方法一致,可以多一个Throwable参数来接收异常
public String handleFallback(String id, Throwable ex) {
return "服务异常,商品查询失败 (Fallback)";
}
}3. OpenFeign
当 Sentinel 与 OpenFeign 整合时,处理方式更为优雅。我们只需在 Feign Client 的接口上启用 Sentinel,然后实现一个 fallback 类即可。前文有介绍
流控规则
流控规则是 Sentinel 最常用的功能,用于限制访问资源的流量。
阈值类型
- 直接:对资源本身进行限流。当资源的 QPS 或线程数超过阈值时,直接触发流控。
- 链路 :只针对从某个特定入口 进入的流量进行限流。例如,资源
C被入口A和B调用,我们可以只限制从A到C的流量,而不影响B到C的调用。这需要使用@SentinelResource注解的entryType属性配合。 - 关联 :当关联资源 达到阈值时,就限制当前资源 。例如,
read_db和write_db两个资源。当write_db的访问量过大时,可以限制read_db的流量,优先保证写入操作,防止数据库被读请求拖垮。
流控效果
- 直接 :默认效果。一旦达到阈值,直接拒绝后续请求,抛出
BlockException。 - Warm Up(预热) :系统启动后,流量阈值会从一个较小的值(
coldFactor默认为 3,即阈值的 1/3)开始,经过预热时长后,逐渐增长到设定的阈值。这适用于需要预热才能达到最佳性能的系统,如缓存初始化、JIT 编译等。 - 匀速排队:让请求以均匀的速度通过,对应的是"漏桶算法"。当请求超过阈值时,会排队等待。如果等待超时,则请求被拒绝。这种方式适用于处理突发流量,将请求削峰填谷,保证系统以一个稳定的速率处理请求。
熔断规则
熔断是防止故障扩散的核心手段。
断路器工作原理
Sentinel 的熔断器遵循经典的三种状态:
- 闭合:正常状态,允许所有请求通过,并统计调用状态(成功、失败、耗时)。
- 打开:当满足熔断条件时,熔断器打开。在熔断时长内,所有到该资源的请求都会被直接拒绝,触发降级逻辑。
- 半开 :熔断时长结束后,熔断器进入半开状态。它会放行一个 请求,如果该请求成功,则熔断器闭合 ;如果失败,则熔断器重新打开,并重置熔断时长。
熔断策略
- 慢调用比例 :当资源的响应时间大于最大 RT(
maxRt)时,被记为慢调用。如果在统计时长内,请求数大于最小请求数,且慢调用比例大于阈值,则触发熔断。 - 异常比例:在统计时长内,如果请求数大于最小请求数,且异常(抛出异常)的比例大于阈值,则触发熔断。
- 异常数:在统计时长内,如果异常的数量大于阈值,则触发熔断。
热点规则
热点规则是一种特殊的流控规则,它允许我们更精确地对参数化的流量进行控制。
热点参数限流
有时,某个参数的值(如某个商品 ID、用户 ID)可能会成为访问热点,导致系统负载不均。热点规则可以针对这些热点参数值进行单独的限流。
例如,我们可以对 getProduct(id) 方法设置规则:
- 默认 QPS 阈值为 10。
- 但当参数
id的值为hot_product_id时,QPS 阈值限制为 1。
这样就能有效防止个别热点商品访问量过大而影响整个系统
java
@SentinelResource(value = "getProduct", blockHandler = "handleBlock")
public String getProduct(@SentinelResource("id") String id) {
// ...
}补充fallback与blockHander兜底回调
这是对 @SentinelResource 异常处理的再次强调,因为它非常关键且容易混淆。
blockHandler:管规则 。当 Sentinel 的流控、熔断、系统保护等规则生效时,由它来兜底。它的签名必须包含BlockException参数。fallback:管异常 。当你的业务代码本身抛出了任何类型的异常时(RuntimeException、Error等),由它来兜底。它的签名可以包含Throwable参数来获取具体异常。
最佳实践 :通常,我们会同时使用 blockHandler 和 fallback,实现双重保障。blockHandler 用于处理"被保护"的场景,fallback 用于处理"自身出错"的场景。
Sentinel总结
Sentinel 作为一款功能强大的流量防卫兵,为微服务架构提供了坚实的稳定性保障。
-
核心优势:
- 实时监控:提供实时、强大的监控能力,可以秒级观察到应用的健康状况。
- 丰富规则:支持多种流控、熔断、热点、系统保护规则,覆盖了绝大多数应用场景。
- 易于扩展:基于插槽链的设计,使得自定义和扩展功能变得非常简单。
- 无缝集成:与 Spring Cloud、Dubbo、gRPC 等主流框架无缝集成,降低了使用门槛。
-
解决的问题:
- 通过流量控制,防止系统被流量冲垮。
- 通过熔断降级,防止故障扩散,避免雪崩效应。
- 通过系统负载保护,保证应用在高压下依然能稳定运行。
Gateway
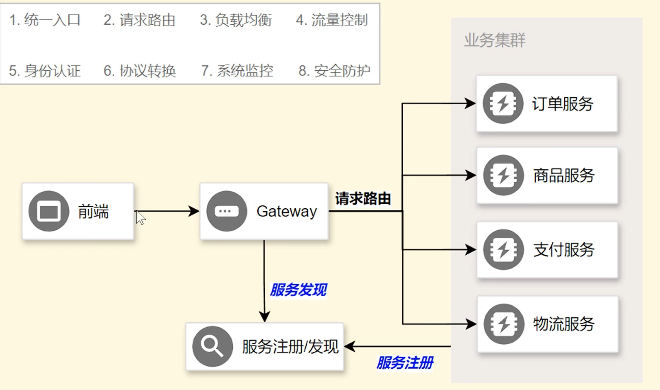
API 网关已经成为了不可或缺的核心组件。它作为所有客户端请求的统一入口,承担着路由转发、安全校验、流量控制、日志监控等重要职责。Spring Cloud Gateway 作为 Spring Cloud 生态系统中的第二代网关,凭借其非阻塞 I/O、强大的路由功能和丰富的扩展性,成为了众多开发者的首选。
网关功能
- 路由: 核心功能,将外部请求根据特定规则(如路径、域名、请求头等)转发到正确的后端微服务。
- 认证与安全: 统一处理身份认证(如 JWT 验证)、权限校验,防止未授权的请求访问后端服务。
- 限流: 保护后端服务免受流量洪峰的冲击,防止系统被拖垮。
- 重试与熔断: 当后端服务出现问题时,提供自动重试和熔断机制,提升系统的健壮性。
- 日志与监控: 记录所有请求的详细信息,为问题排查和系统监控提供数据支持。
- 请求/响应转换: 可以在请求转发前或响应返回前,对报文进行修改,例如添加/删除请求头。
创建网关
第一步:添加依赖
在你的 pom.xml 中添加 spring-cloud-starter-gateway 依赖。
XML
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>第二步:配置文件
在 application.yml 中进行基础配置。
bash
server:
port: 8080 # 网关服务端口
spring:
application:
name: api-gateway
cloud:
gateway:
# 路由配置
routes:
- id: user_service # 路由的唯一标识
uri: http://localhost:8081 # 目标服务地址
predicates: # 断言(条件)
- Path=/user/** # 匹配路径
- id: product_service
uri: http://localhost:8082
predicates:
- Path=/product/**此时访问 http://localhost:8080/user/info 会被转发到 http://localhost:8081/user/info 。
路由
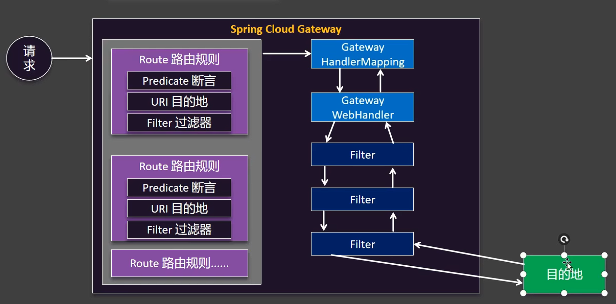
路由是 Gateway 的核心构建块。一个完整的路由包含四个部分:
- ID: 路由的唯一标识符,区别于其他路由。
- URI: 目标服务的地址。可以是具体的 URL(
http://example.com),也可以是服务发现中的服务名(lb://user-service,lb代表 LoadBalancer)。 - Predicates(断言): 一组匹配条件。如果请求满足所有断言,则该路由被匹配。
- Filters(过滤器): 一组过滤器。在请求被转发前后执行,用于修改请求和响应。
规则配置
Gateway 的路由规则主要通过 application.yml 或 Java 配置类来定义。YAML 方式更直观、更常用。
bash
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2023-10-12T17:30:00+08:00[Asia/Shanghai] # 在指定时间之后才匹配
filters:
- AddRequestHeader=X-Request-Foo, Bar # 添加请求头工作原理
- 客户端请求 到达 Gateway。
- Gateway Handler Mapping 接收请求,根据一系列的 断言 判断该请求匹配哪个路由。
- 一旦匹配成功,请求被发送到 Gateway Web Handler。
- Gateway Web Handler 将请求通过一个 过滤器链 。这个链由所有与该路由关联的 GatewayFilter 和全局的 GlobalFilter 组成。
- 过滤器链中的过滤器会按顺序执行,执行前置逻辑(如修改请求),然后发起代理请求。
- 代理请求返回后,过滤器链再反向执行后置逻辑(如修改响应)。
- 最终,处理完成的响应被返回给客户端。
整个流程基于 Spring WebFlux 的非阻塞、响应式模型,使用 Netty 作为服务器,能够以极少的线程处理高并发请求。
断言
断言是 Gateway 的"路由匹配器",它决定了请求是否应该被当前路由处理。Spring Cloud Gateway 内置了多种强大的断言工厂。
长短写法
许多断言支持两种写法:完整名称和简写。
长写法(完整名称):
- name: Path
args:
pattern: /user/**短写法(快捷方式):
- Path=/user/**Query 断言
Query 断言用于检查请求的查询参数。
-
示例1:必须包含
name参数predicates: - Query=name匹配
http://mygateway/user?name=zhangsan,不匹配http://mygateway/user。 -
示例2:
name参数的值必须是正则表达式zhang.*predicates: - Query=name, zhang.*匹配
http://mygateway/user?name=zhangsan,不匹配http://mygateway/user?name=lisi。
自定义断言工厂
当内置断言无法满足需求时,我们可以自定义。
步骤:
- 创建一个类,继承
AbstractRoutePredicateFactory<C>,其中C是配置类。 - 重写
apply方法,实现断言逻辑。 - 将类注册为 Spring Bean(
@Component)。
示例:自定义一个检查请求头 X-Source 是否为 mobile 的断言。
java
// 1. 创建配置类(可选,但推荐)
public static class Config {
// 可以在这里定义配置属性
}
// 2. 创建断言工厂类
@Component
public class MobileSourceRoutePredicateFactory extends AbstractRoutePredicateFactory<MobileSourceRoutePredicateFactory.Config> {
public MobileSourceRoutePredicateFactory() {
super(Config.class);
}
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return exchange -> {
// 3. 实现断言逻辑
String source = exchange.getRequest().getHeaders().getFirst("X-Source");
return "mobile".equalsIgnoreCase(source);
};
}
}在 application.yml 中使用:
bash
spring:
cloud:
gateway:
routes:
- id: mobile_route
uri: http://localhost:8081
predicates:
- MobileSource # 使用自定义断言的名称(去掉RoutePredicateFactory后缀)过滤器
过滤器允许以某种方式修改传入的 HTTP 请求或传出的 HTTP 响应。它分为两种类型:GatewayFilter (路由过滤器)和 GlobalFilter(全局过滤器)。
基本使用
GatewayFilter 应用在单个路由上。
示例:AddRequestHeader 过滤器
spring:
cloud:
gateway:
routes:
- id: add_header_route
uri: http://localhost:8081
predicates:
- Path=/api/**
filters:
- AddRequestHeader=X-Request-Red, Blue 默认 filter
Gateway 提供了大量内置的过滤器工厂,例如:
AddRequestParameter: 添加请求参数。StripPrefix: 转发前去掉路径的前 N 段。例如StripPrefix=1,请求/api/user/info会被转发为/user/info。SetPath: 修改请求路径。Retry: 自动重试。
GlobalFilter
GlobalFilter 不需要在路由上配置,它会自动应用于所有路由。它更适合实现全局性的功能,如认证、日志、限流等。
示例:一个简单的日志 GlobalFilter
java
@Component
@Slf4j
public class SimpleLogGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("请求路径: {}", exchange.getRequest().getPath().value());
return chain.filter(exchange);
}
@Override
public int getOrder() {
// 过滤器的执行顺序,数值越小,优先级越高
return -1;
}
}自定义过滤器工厂
与自定义断言类似,我们也可以创建自定义的 GatewayFilter。
步骤:
- 创建一个类,继承
AbstractGatewayFilterFactory<C>。 - 重写
apply方法。 - 注册为 Spring Bean。
示例:自定义一个打印特定日志的过滤器工厂。
java
@Component
public class PrintLogGatewayFilterFactory extends AbstractGatewayFilterFactory<PrintLogGatewayFilterFactory.Config> {
public PrintLogGatewayFilterFactory() {
super(Config.class);
}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
if (config.isPreLogger()) {
log.info("Pre Log: Request Path = {}", exchange.getRequest().getPath());
}
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
if (config.isPostLogger()) {
log.info("Post Log: Response Status = {}", exchange.getResponse().getStatusCode());
}
}));
};
}
// 配置类,用于接收yml中的参数
public static class Config {
private boolean preLogger;
private boolean postLogger;
// getters and setters...
}
}在 application.yml 中使用:
bash
spring:
cloud:
gateway:
routes:
- id: custom_filter_route
uri: http://localhost:8081
predicates:
- Path=/**
filters:
- name: PrintLog
args:
preLogger: true
postLogger: true全局跨域
在前后端分离的项目中,跨域(CORS)是常见问题。Spring Cloud Gateway 提供了非常便捷的全局跨域配置方案。
在 application.yml 中配置:
bash
spring:
cloud:
gateway:
# 全局跨域配置
globalcors:
cors-configurations:
'[/**]': # 匹配所有路径
allowedOriginPatterns: "*" # 允许所有来源,生产环境建议指定具体域名
allowedMethods:
- GET
- POST
- PUT
- DELETE
allowedHeaders: "*"
allowCredentials: true # 允许携带 Cookie
maxAge: 3600 # 预检请求的有效期这段配置会为所有经过网关的请求添加 CORS 相关的响应头,从而解决跨域问题。
Gateway总结
Spring Cloud Gateway 是一个功能强大且高度可扩展的 API 网关。它的核心优势在于:
- 性能卓越: 基于 WebFlux 和 Netty,非阻塞 I/O 模型使其能够轻松应对高并发场景。
- 功能丰富: 内置了路由、断言、过滤器等一套完整的机制,满足绝大多数网关需求。
- 易于集成: 与 Spring Cloud 生态(如服务发现、熔断器)无缝集成。
- 高度可定制: 支持自定义断言和过滤器,可以灵活地扩展其功能
Seata
将单体应用拆分为一系列独立的服务。这带来了灵活性和可扩展性,但也引入了一个棘手的难题:分布式事务。当一个业务操作需要跨越多个服务、多个数据库时,如何保证数据的一致性?
阿里巴巴开源的 Seata (Simple Extensible Autonomous Transaction Architecture) 正是为了解决这一痛点而生。它提供了一套高性能、易于使用的分布式事务解决方案。
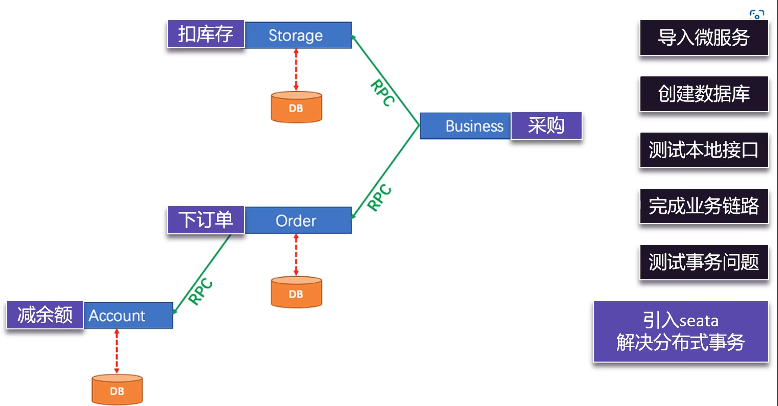
环境搭建
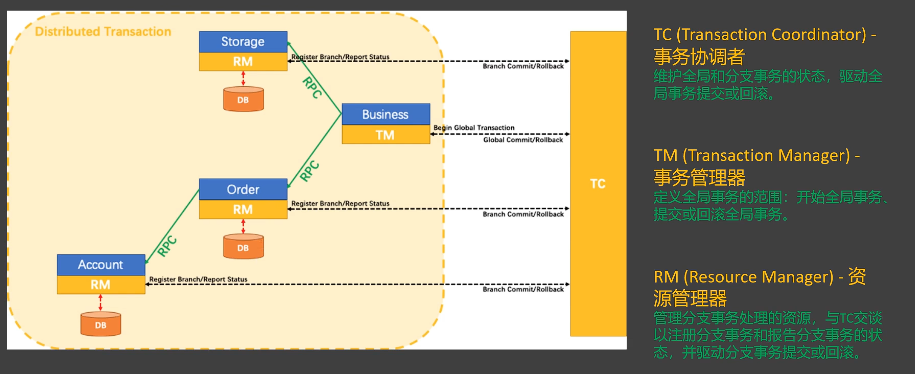
我们先来搭建 Seata 的运行环境。Seata 的核心架构包含三个角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围,开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与 TC 通信以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
我们的搭建步骤也将围绕这三者展开。
第一步:搭建 TC (Seata Server)
-
下载 Seata Server
从 Seata 官方 GitHub 仓库下载最新版的 Seata Server 压缩包并解压。
-
配置存储模式
Seata Server 需要存储全局事务会话信息,支持文件(
file)和数据库(db)。生产环境推荐使用db。修改
conf/file.conf文件:
java
store {
## store mode: file、db、redis
mode = "db"
## database store property
db {
datasource = "druid"
dbType = "mysql"
driverClassName = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata_server?rewriteBatchedStatements=true"
user = "mysql"
password = "mysql"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}-
初始化数据库
在你的 MySQL 中创建一个名为
seata_server的数据库,并运行 Seata 源码或脚本包中的script/server/db/mysql.sql文件,创建所需的global_table、branch_table、lock_table等表。 -
配置注册中心
Seata Server 需要向注册中心注册自身,以便 TM 和 RM 能够发现它。这里我们以 Nacos 为例。
修改
conf/registry.conf文件:
java
registry {
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
}
}- 启动 Seata Server
运行bin/seata-server.bat(Windows) 或bin/seata-server.sh(Linux/Mac) 即可启动 TC。
第二步:整合 TM & RM (业务微服务)
假设我们有两个微服务:order-service(订单服务)和 storage-service(库存服务)。
-
添加依赖
在两个服务的pom.xml中都添加 Seata 客户端依赖:XML<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency>
-
配置数据源代理
Seata 通过代理数据源来实现分支事务的管理。确保你的 Spring Boot 应用中,数据源是自动配置的,Seata 会自动完成代理。
-
配置 Seata 客户端
在
application.yml中配置 Seata 客户端,连接到 TC 和 Nacos。
bash
seata:
# 事务组,自定义即可
tx-service-group: my_tx_group
service:
# 事务组与集群的映射关系
vgroup-mapping:
my_tx_group: default
# Seata Server 所在的集群
grouplist:
default: 127.0.0.1:8091
registry:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
namespace: ""
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
namespace: ""
bash
tx-service-group 是关键,它定义了你的服务属于哪个事务组。这个配置需要和 Nacos 中的配置保持一致(如果使用 Nacos 配置中心的话)。接口与事务测试
环境搭好后,我们通过一个经典的"下单扣库存"场景来测试。
本地事务测试
在 order-service 中,我们先不进行远程调用,只测试本地事务。
java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Override
// 使用 @GlobalTransactional 开启分布式事务
@GlobalTransactional(name = "create-order", rollbackFor = Exception.class)
public void createOrder(String userId, String commodityCode, int orderCount) {
// 本地创建订单
Order order = new Order();
order.setUserId(userId);
order.setCommodityCode(commodityCode);
order.setCount(orderCount);
orderMapper.insert(order);
// 模拟异常,测试回滚
if (commodityCode.equals("error")) {
throw new RuntimeException("模拟业务异常");
}
}
}调用此接口,当 commodityCode 为 "error" 时,订单插入操作会被回滚。
打通远程调用链路
现在,我们让 order-service 远程调用 storage-service 扣减库存。
- 在
storage-service中提供扣减库存接口
java
@RestController
public class StorageController {
@Autowired
private StorageService storageService;
@RequestMapping("/deduct")
public Boolean deduct(@RequestParam String commodityCode, @RequestParam int count) {
storageService.deduct(commodityCode, count);
return true;
}
}- 在
order-service中发起远程调用
java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate; // 用于远程调用
@Override
@GlobalTransactional(name = "create-order-with-storage", rollbackFor = Exception.class)
public void createOrder(String userId, String commodityCode, int orderCount) {
// 1. 本地创建订单
// ... (代码同上)
// 2. 远程调用扣减库存
String url = "http://storage-service/deduct?commodityCode=" + commodityCode + "&count=" + orderCount;
restTemplate.getForObject(url, Boolean.class);
// 3. 模拟异常,测试全局回滚
if (commodityCode.equals("error")) {
throw new RuntimeException("模拟业务异常,触发全局回滚");
}
}
}接口测试
使用 Postman 或其他工具调用 order-service 的创建订单接口。
- 成功场景 :
commodityCode为正常值。你会发现order-service的订单表和storage-service的库存表都发生了预期的变化。 - 失败场景 :
commodityCode为 "error"。你会发现,即使库存已经扣减,由于后续异常,订单创建失败,最终订单表和库存表的数据都会被回滚,保证了数据一致性。
架构原理
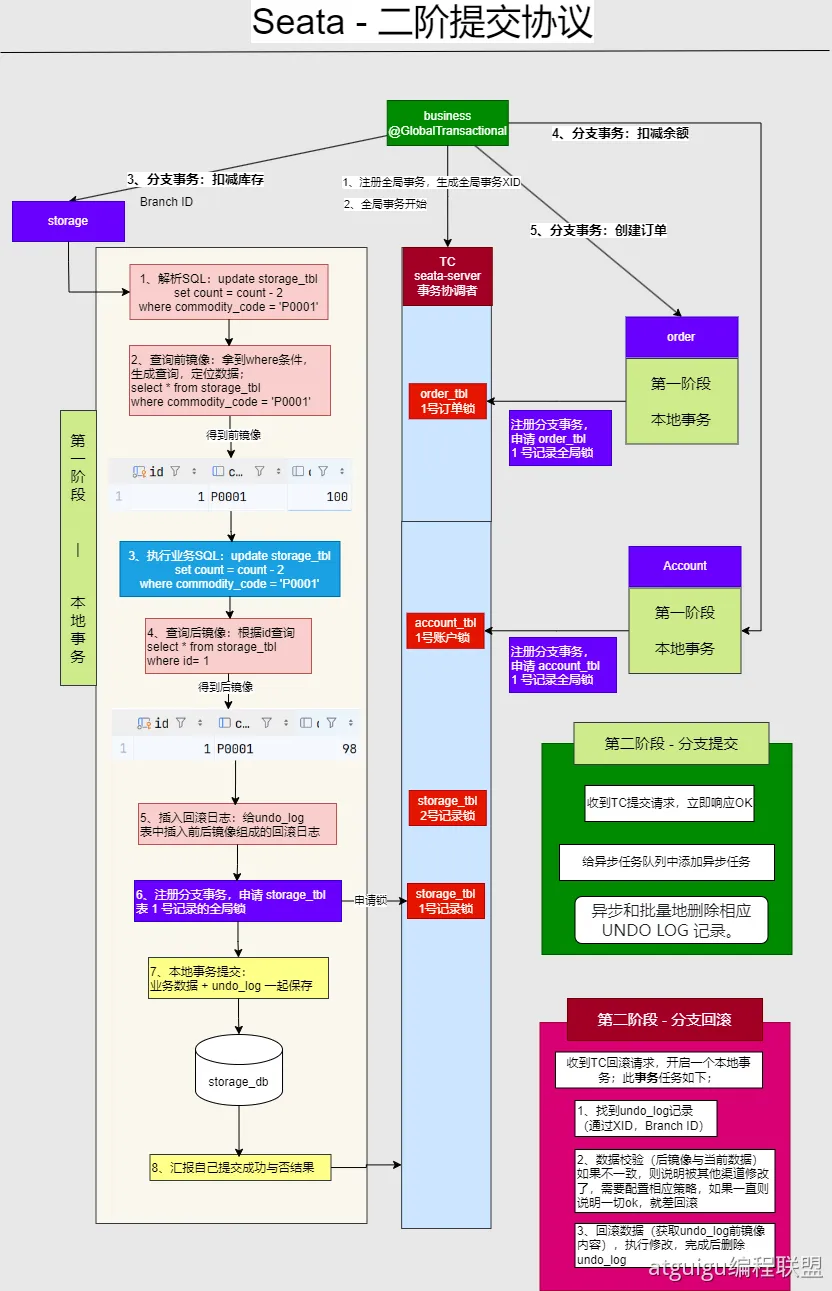
Seata 的核心思想是如何在不侵入业务逻辑的前提下,实现分布式事务。以最常用的 AT 模式为例:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:异步化,快速提交。
整合 Seata 的关键在于 DataSourceProxy。Seata 会自动代理你的数据源,当你执行 SQL 时,它会:
- 解析 SQL:获取 SQL 类型(UPDATE/INSERT/DELETE)、表名、条件等。
- 查询前镜像:执行 SQL 前,先查询出被修改数据的原始状态。
- 执行业务 SQL:执行你写的业务 SQL。
- 查询后镜像:执行 SQL 后,再查询出被修改数据的新状态。
- 插入回滚日志:将前后镜像信息组装成回滚日志(undo_log),与业务 SQL 在同一个本地事务中提交。
二阶协议提交流程
- 开启全局事务:TM 向 TC 申请开启一个全局事务,TC 生成一个全局事务 ID (XID)。
- 注册分支事务:TM 调用微服务 A,微服务 A 作为 RM,在执行业务 SQL 前,向 TC 注册一个分支事务,并绑定到 XID。
- 执行并记录 Undo Log:RM 执行业务 SQL,并如上所述生成 Undo Log,与业务数据一起提交。
- 报告分支状态:RM 向 TC 报告分支事务执行成功。
- 重复步骤 2-4:TM 调用微服务 B、C...,所有分支事务都执行并报告成功。
- 全局提交决议:TM 收到所有分支的成功响应后,向 TC 发起全局提交请求。
- 异步删除 Undo Log:TC 通知所有 RM 异步删除对应的 Undo Log。至此,事务完成。
如果任何一步发生失败,TM 会向 TC 发起全局回滚请求。
二阶提交可视化
四种事务模式
Seata 提供了四种事务模式,以适应不同的业务场景。
| 模式 | 一阶段动作 | 二阶段动作 | 一致性 | 侵入性 | 性能 | 适用场景 |
|---|---|---|---|---|---|---|
| AT | 自动生成Undo Log,提交本地事务 | 异步删除Undo Log 或 根据Undo Log回滚 | 最终一致 | 无 | 较高 | 大多数基于关系型数据库的分布式事务场景,简单易用。 |
| TCC | 调用业务Try接口(资源预留和检查) |
调用业务Confirm或Cancel接口 |
最终一致 | 高(需实现三个接口) | 高 | 对性能要求高、需要资源预留、或非数据库资源的场景。 |
| SAGA | 调用正向服务 | 调用补偿服务 | 最终一致 | 高(需提供补偿方法) | 高 | 业务流程长、涉及多个系统、需要补偿机制的复杂场景。 |
| XA | 执行XA prepare,锁定资源 |
执行XA commit或rollback |
强一致 | 无(依赖数据库) | 低 | 对数据一致性要求极高,能接受性能开销的场景。 |
模式选择建议:
- 首选 AT 模式:对于大多数业务,AT 模式提供了最好的易用性和性能平衡。
- 性能敏感场景选 TCC:如金融领域的核心交易,需要快速响应和资源锁定。
- 长流程选 SAGA:如旅行预订,涉及机票、酒店、租车等多个独立服务。
- 强一致要求选 XA:如银行转账,不能容忍任何不一致。