目录
[1. 项目整体定位与框架设计](#1. 项目整体定位与框架设计)
[2. 各核心环节思路详解](#2. 各核心环节思路详解)
[3. 项目优化核心思路](#3. 项目优化核心思路)
[1. 打包失败的核心问题](#1. 打包失败的核心问题)
[2. 思维误区与破局思路](#2. 思维误区与破局思路)
[3. 解决方案的核心逻辑](#3. 解决方案的核心逻辑)
[1. 大模型的正确定位:助手而非答案](#1. 大模型的正确定位:助手而非答案)
[2. 解决问题的关键:拒绝死磕,学会"推翻重来"](#2. 解决问题的关键:拒绝死磕,学会“推翻重来”)
[3. 项目开发的核心:先搭框架,再填细节,重视落地](#3. 项目开发的核心:先搭框架,再填细节,重视落地)
[4. 优化的本质:贴合需求,而非追求复杂](#4. 优化的本质:贴合需求,而非追求复杂)
在计算机视觉的实用化探索中,手势识别因其在智能家居控制、人机交互等场景的广泛潜力,成为新手入门的优质实践方向。本次手势识别优化项目,核心目标是实现一套低成本、易落地的端到端解决方案------无需深厚的深度学习功底,通过简单的技术组合,完成从手势数据采集到实时预测,再到可独立运行的软件部署,全程以"落地性"为核心,同时借助大模型辅助提升开发效率,过程中既有思路的梳理,也有踩坑后的深刻感悟,在此复盘分享,后续将附上完整代码及效果展示,供大家参考交流。
引言
本次手势识别优化项目,是一次"借助大模型、聚焦落地性"的实战探索,核心流程围绕"数据采集→模型训练→实时预测→部署打包"展开,全程以新手友好、低成本落地为目标,梳理出了清晰的项目思路,也在踩坑中收获了宝贵的思维提升。
项目的核心价值,不仅是实现了手势识别的功能,更是让我掌握了借助大模型辅助开发的正确方式,明白了"拒绝死磕、灵活变通"的重要性,也深刻体会到了项目落地的意义。后续将附上本次项目的完整代码及效果展示,供大家参考交流,也希望我的思路和感悟,能为正在入门计算机视觉、尝试项目开发的小伙伴提供一些帮助,少走弯路、高效成长
一、代码及效果展示
效果展示:
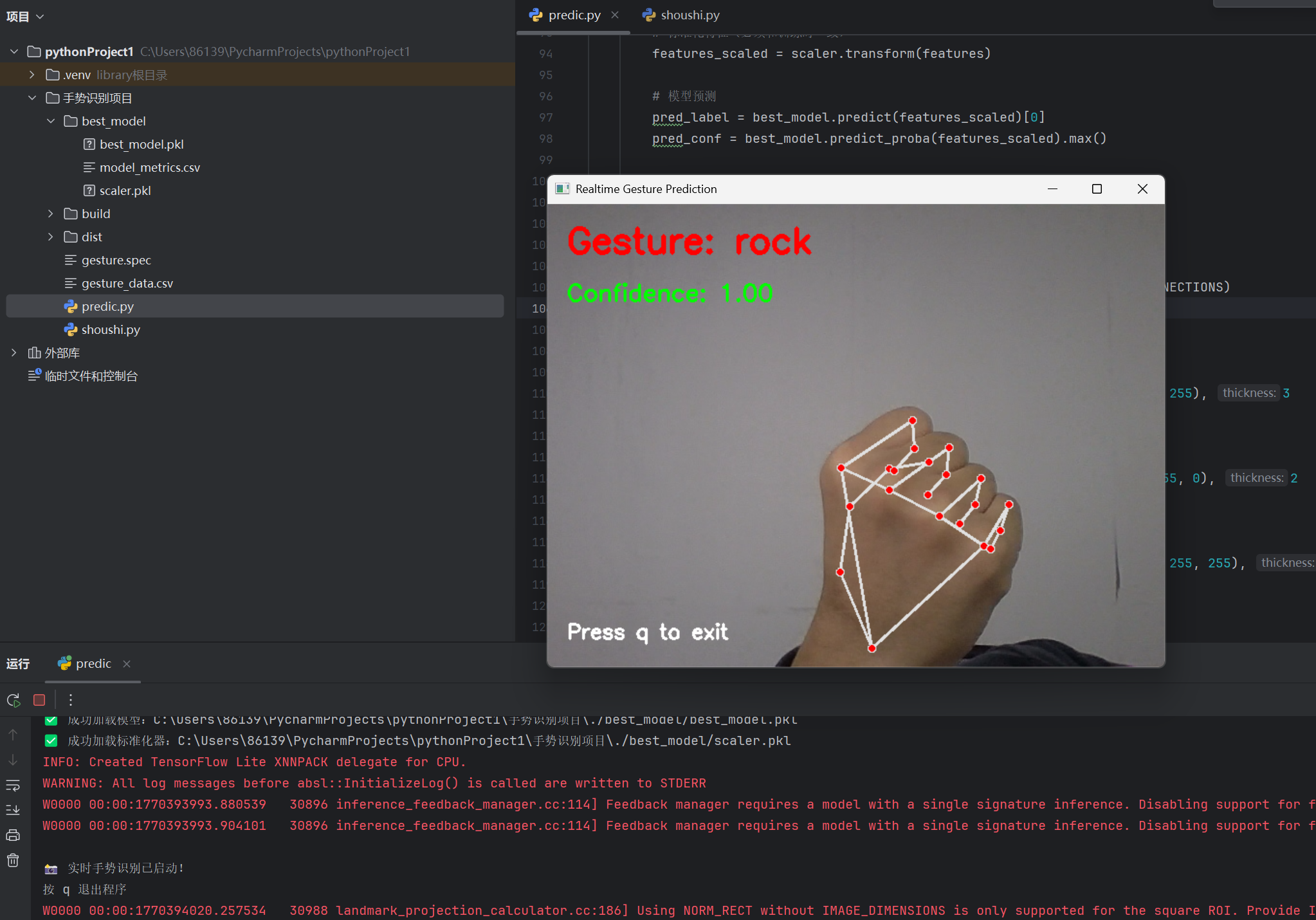
代码:
1、从收集数据,训练模型,保存最优参数到预测:
python
# -*- coding: utf-8 -*-
import cv2
import mediapipe as mp
import csv
import os
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import joblib
# ===================== 自定义配置(可修改) =====================
# 1. 手势标签(5个):名称→数字映射
GESTURE_LABELS = {
"rock": 0, # 石头
"paper": 1, # 布
"scissors": 2, # 剪刀
"ok": 3, # OK手势
"peace": 4 # 比耶
}
# 反向映射:数字→名称
LABEL2NAME = {v: k for k, v in GESTURE_LABELS.items()}
# 2. 文件路径(自定义修改)
DATA_PATH = "./gesture_data.csv" # 采集的数据文件
MODEL_DIR = "./best_model" # 最优模型保存目录
SCALER_PATH = f"{MODEL_DIR}/scaler.pkl" # 标准化器路径
BEST_MODEL_PATH = f"{MODEL_DIR}/best_model.pkl" # 最优模型路径
MODEL_METRICS_PATH = f"{MODEL_DIR}/model_metrics.csv" # 模型评估结果
# 3. 模型列表(轻量配置,默认参数)
MODELS = {
"KNN": KNeighborsClassifier(),
"SVM": SVC(probability=True), # 开启概率输出,用于置信度显示
"MLP": MLPClassifier(hidden_layer_sizes=(32,), max_iter=200), # 轻量隐藏层
"RandomForest": RandomForestClassifier(n_estimators=20), # 减少树数量,轻量
"LogisticRegression": LogisticRegression(max_iter=200)
}
# 4. 摄像头配置(轻量分辨率,提升速度)
CAM_WIDTH = 640
CAM_HEIGHT = 480
# ==============================================================
def collect_data():
"""
数据采集函数:按数字键1-5采集对应手势,按q退出
数字对应:1=rock, 2=paper, 3=scissors, 4=ok, 5=peace
"""
# 创建数据文件(初始化表头)
if not os.path.exists(DATA_PATH):
with open(DATA_PATH, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
# 表头:x0,y0,z0...x20,y20,z20,label(21个关键点×3维度=63特征)
header = [f"{axis}{i}" for i in range(21) for axis in ['x', 'y', 'z']] + ['label']
writer.writerow(header)
print(f"✅ 初始化数据文件:{DATA_PATH}")
else:
print(f"ℹ️ 数据文件已存在,将追加采集数据:{DATA_PATH}")
# 初始化MediaPipe手部检测
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1, # 仅采集单只手,避免干扰
min_detection_confidence=0.8
)
mp_drawing = mp.solutions.drawing_utils
# 初始化摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAM_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAM_HEIGHT)
# 采集提示
print("\n========== 数据采集开始 ==========")
print("手势对应按键:")
print("1 → rock(石头) | 2 → paper(布) | 3 → scissors(剪刀)")
print("4 → ok(OK手势) | 5 → peace(比耶) | q → 退出采集")
print("注意:按数字键时请确保手部在画面中,仅检测到手部才会保存数据!")
while True:
ret, frame = cap.read()
if not ret:
print("❌ 摄像头读取失败!")
break
# 镜像翻转+颜色转换
frame = cv2.flip(frame, 1)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
# 绘制手部关键点
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
frame, hand_landmarks, mp_hands.HAND_CONNECTIONS
)
# 键盘交互
key = cv2.waitKey(1) & 0xFF
# 退出采集
if key == ord('q'):
print("\n✅ 采集结束!")
break
# 采集对应手势(数字1-5对应5个手势)
if 49 <= key <= 53: # ASCII:1=49,5=53
gesture_key = int(chr(key))
label = gesture_key - 1 # 1→0(rock), 2→1(paper)...5→4(peace)
# 仅检测到手部时保存数据
if results.multi_hand_landmarks:
hand_landmarks = results.multi_hand_landmarks[0]
# 提取21个关键点的x/y/z坐标(扁平化为63维特征)
features = []
for lm in hand_landmarks.landmark:
features.extend([lm.x, lm.y, lm.z])
# 写入CSV
with open(DATA_PATH, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(features + [label])
# 统计当前样本数
total_samples = sum(1 for _ in open(DATA_PATH, encoding='utf-8')) - 1
print(f"📌 已采集【{LABEL2NAME[label]}】样本,累计样本数:{total_samples}")
else:
print("⚠️ 未检测到手部,跳过本次采集!")
# 显示提示文字
cv2.putText(
frame, "按数字键采集 | q退出", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2
)
cv2.imshow("Gesture Data Collection", frame)
# 释放资源
cap.release()
cv2.destroyAllWindows()
# 输出采集统计
df = pd.read_csv(DATA_PATH, encoding='utf-8')
print("\n📊 采集数据统计:")
for label, name in LABEL2NAME.items():
count = len(df[df['label'] == label])
print(f"{name}:{count} 个样本")
def process_data():
"""
修复后的数据处理:
1. 仅过滤x/y坐标的0-1异常值(z坐标允许负数)
2. 保留有效样本,避免清洗后样本数为0
"""
print("\n========== 数据处理开始 ==========")
# 加载数据
if not os.path.exists(DATA_PATH):
raise FileNotFoundError(f"❌ 数据文件不存在:{DATA_PATH},请先运行数据采集!")
df = pd.read_csv(DATA_PATH, encoding='utf-8')
print(f"ℹ️ 原始数据样本数:{len(df)}")
# 数据清洗(修复核心)
# 1. 去除缺失值
df = df.dropna()
print(f"ℹ️ 去除缺失值后样本数:{len(df)}")
# 2. 仅过滤x/y坐标的异常值(0-1),z坐标不过滤
x_y_cols = [col for col in df.columns[:-1] if col.startswith(('x', 'y'))] # 只选x/y列
for col in x_y_cols:
df = df[(df[col] >= 0) & (df[col] <= 1)]
print(f"ℹ️ 过滤x/y异常值后样本数:{len(df)}")
# 3. 去除重复样本(可选,若重复少可注释)
df = df.drop_duplicates()
print(f"ℹ️ 去除重复样本后样本数:{len(df)}")
# 检查样本是否为空
if len(df) == 0:
raise ValueError("❌ 清洗后无有效样本!请检查采集的数据是否正常,或暂时注释重复值过滤步骤。")
# 检查样本平衡
print("\n📊 清洗后各手势样本数:")
for label, name in LABEL2NAME.items():
count = len(df[df['label'] == label])
print(f"{name}:{count} 个样本")
# 分离特征和标签
X = df.iloc[:, :-1].values # 63维特征
y = df.iloc[:, -1].values # 标签
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 分层划分训练集(80%)和测试集(20%)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\n✅ 数据划分完成:")
print(f"训练集:{len(X_train)} 样本 | 测试集:{len(X_test)} 样本")
return X_train, X_test, y_train, y_test, scaler
def train_and_select_best_model():
"""
训练所有指定模型,评估准确率,选择最优模型保存
"""
print("\n========== 多模型训练开始 ==========")
# 数据处理
X_train, X_test, y_train, y_test, scaler = process_data()
# 创建模型保存目录
if not os.path.exists(MODEL_DIR):
os.makedirs(MODEL_DIR)
print(f"✅ 创建模型保存目录:{MODEL_DIR}")
# 训练并评估每个模型
model_metrics = {}
for model_name, model in MODELS.items():
print(f"\n🔧 训练 {model_name} 模型...")
# 训练
model.fit(X_train, y_train)
# 预测并计算准确率
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
model_metrics[model_name] = accuracy
print(f"📈 {model_name} 测试集准确率:{accuracy:.4f}")
# 选择最优模型(准确率最高)
best_model_name = max(model_metrics, key=model_metrics.get)
best_model = MODELS[best_model_name]
best_accuracy = model_metrics[best_model_name]
print(f"\n🏆 最优模型:{best_model_name}(准确率:{best_accuracy:.4f})")
# 保存最优模型和标准化器
joblib.dump(best_model, BEST_MODEL_PATH)
joblib.dump(scaler, SCALER_PATH)
print(f"✅ 最优模型保存至:{BEST_MODEL_PATH}")
print(f"✅ 标准化器保存至:{SCALER_PATH}")
# 保存所有模型评估结果
metrics_df = pd.DataFrame({
"Model": model_metrics.keys(),
"Accuracy": model_metrics.values()
})
metrics_df.to_csv(MODEL_METRICS_PATH, index=False, encoding='utf-8')
print(f"✅ 模型评估结果保存至:{MODEL_METRICS_PATH}")
return best_model_name, best_accuracy
def realtime_predict():
"""
增强版实时预测:
1. 显示最优模型名称+预测置信度
2. 显示所有模型的预测结果对比
3. 仅显示置信度>0.7的结果(避免低置信度错误)
"""
print("\n========== 实时预测开始 ==========")
# 加载最优模型、标准化器、模型评估结果
if not os.path.exists(BEST_MODEL_PATH) or not os.path.exists(SCALER_PATH):
raise FileNotFoundError(f"❌ 最优模型/标准化器不存在,请先运行模型训练!")
best_model = joblib.load(BEST_MODEL_PATH)
scaler = joblib.load(SCALER_PATH)
metrics_df = pd.read_csv(MODEL_METRICS_PATH, encoding='utf-8')
best_model_name = metrics_df.loc[metrics_df['Accuracy'].idxmax(), 'Model']
best_accuracy = metrics_df['Accuracy'].max()
# 初始化MediaPipe手部检测
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.8
)
mp_drawing = mp.solutions.drawing_utils
# 初始化摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAM_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAM_HEIGHT)
# 预测提示
print(f"ℹ️ 当前最优模型:{best_model_name}(训练准确率:{best_accuracy:.4f})")
print("按 q 退出实时预测!")
print("置信度阈值:0.7(低于阈值显示为unknown)")
while True:
ret, frame = cap.read()
if not ret:
print("❌ 摄像头读取失败!")
break
# 镜像翻转+颜色转换
frame = cv2.flip(frame, 1)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
# 初始化预测结果
best_pred_name = "unknown"
best_pred_conf = 0.0
all_models_pred = {} # 所有模型的预测结果
# 检测到手部时进行预测
if results.multi_hand_landmarks:
hand_landmarks = results.multi_hand_landmarks[0]
# 提取特征(63维)
features = []
for lm in hand_landmarks.landmark:
features.extend([lm.x, lm.y, lm.z])
features = np.array(features).reshape(1, -1)
# 标准化
features_scaled = scaler.transform(features)
# 1. 最优模型预测(带置信度)
best_pred_label = best_model.predict(features_scaled)[0]
best_pred_conf = best_model.predict_proba(features_scaled).max()
# 置信度>0.7才显示,否则为unknown
if best_pred_conf > 0.7:
best_pred_name = LABEL2NAME[best_pred_label]
# 2. 所有模型预测(用于对比)
for model_name, model in MODELS.items():
pred_label = model.predict(features_scaled)[0]
pred_name = LABEL2NAME[pred_label]
all_models_pred[model_name] = pred_name
# 绘制手部关键点
mp_drawing.draw_landmarks(
frame, hand_landmarks, mp_hands.HAND_CONNECTIONS
)
# ========== 绘制增强版预测信息 ==========
# 1. 最优模型信息
cv2.putText(
frame, f"Best Model: {best_model_name} (Acc: {best_accuracy:.2f})",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2
)
# 2. 最优模型预测结果+置信度
cv2.putText(
frame, f"Pred: {best_pred_name} (Conf: {best_pred_conf:.2f})",
(10, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3
)
# 3. 所有模型预测结果对比(分行显示)
y_offset = 120
cv2.putText(frame, "All Models Predict:", (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
for idx, (model_name, pred_name) in enumerate(all_models_pred.items()):
y_pos = y_offset + 30 * (idx + 1)
cv2.putText(
frame, f"{model_name}: {pred_name}",
(20, y_pos), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 1
)
# 显示画面
cv2.imshow("Enhanced Realtime Gesture Recognition", frame)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
print("\n✅ 实时预测结束!")
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
def main():
"""
主函数:按顺序执行 数据采集→模型训练→实时预测
"""
# 步骤1:数据采集
collect_data()
# 步骤2:多模型训练+最优模型选择
train_and_select_best_model()
# 步骤3:增强版实时预测
realtime_predict()
if __name__ == "__main__":
main()2、调用保存参数实现预测:
python
import cv2
import mediapipe as mp
import joblib
import numpy as np
import sys # 保留你新增的这行
import os # 新增:用于路径处理
# ===================== 新增:适配打包的资源路径函数 =====================
def resource_path(relative_path):
"""
获取资源的绝对路径,适配 PyInstaller 打包后的环境
- 开发时:使用当前脚本所在目录
- 打包后:使用 PyInstaller 生成的临时资源目录
"""
try:
# PyInstaller 打包后会自动设置 sys._MEIPASS 指向临时资源目录
base_path = sys._MEIPASS
except Exception:
# 未打包时,使用当前文件所在的目录
base_path = os.path.abspath(os.path.dirname(__file__))
return os.path.join(base_path, relative_path)
# ===================== 配置(修改路径为适配打包的方式) =====================
# 1. 手势标签映射(和你的项目保持一致)
LABEL2NAME = {
0: "rock", # 石头
1: "paper", # 布
2: "scissors", # 剪刀
3: "ok", # OK手势
4: "peace" # 比耶
}
# 2. 已保存模型/标准化器的路径(改用resource_path适配打包)
MODEL_PATH = resource_path("./best_model/best_model.pkl") # 修改:使用适配函数
SCALER_PATH = resource_path("./best_model/scaler.pkl") # 修改:使用适配函数
# 3. 摄像头配置(轻量分辨率)
CAM_WIDTH = 640
CAM_HEIGHT = 480
# 4. 置信度阈值(低于此值显示为unknown)
CONF_THRESHOLD = 0.7
# ===================== 加载模型和标准化器 =====================
try:
best_model = joblib.load(MODEL_PATH)
scaler = joblib.load(SCALER_PATH)
print(f"✅ 成功加载模型:{MODEL_PATH}")
print(f"✅ 成功加载标准化器:{SCALER_PATH}")
except FileNotFoundError as e:
print(f"❌ 模型/标准化器文件不存在:{e}")
print("💡 提示:打包时需确保 best_model 文件夹和脚本在同一目录,且打包命令包含该文件夹")
sys.exit()
# ===================== 初始化MediaPipe手部检测 =====================
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1, # 仅识别单只手
min_detection_confidence=0.8
)
mp_drawing = mp.solutions.drawing_utils
# ===================== 实时预测主循环 =====================
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAM_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAM_HEIGHT)
print("\n📸 实时手势识别已启动!")
print("按 q 退出程序")
while True:
ret, frame = cap.read()
if not ret:
print("❌ 摄像头读取失败")
break
# 镜像翻转+颜色空间转换
frame = cv2.flip(frame, 1)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
# 初始化预测结果
pred_name = "unknown"
pred_conf = 0.0
# 检测到手部时进行预测
if results.multi_hand_landmarks:
hand_landmarks = results.multi_hand_landmarks[0]
# 提取21个关键点的x/y/z坐标(转为63维特征)
features = []
for lm in hand_landmarks.landmark:
features.extend([lm.x, lm.y, lm.z])
features = np.array(features).reshape(1, -1) # 转为模型需要的形状
# 标准化特征(必须和训练时一致)
features_scaled = scaler.transform(features)
# 模型预测
pred_label = best_model.predict(features_scaled)[0]
pred_conf = best_model.predict_proba(features_scaled).max()
# 仅当置信度足够时显示结果
if pred_conf >= CONF_THRESHOLD:
pred_name = LABEL2NAME[pred_label]
# 绘制手部关键点和连线
mp_drawing.draw_landmarks(frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# ===================== 绘制预测结果 =====================
cv2.putText(
frame, f"Gesture: {pred_name}",
(20, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3
)
cv2.putText(
frame, f"Confidence: {pred_conf:.2f}",
(20, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2
)
cv2.putText(
frame, "Press q to exit",
(20, 450), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2
)
# 显示画面
cv2.imshow("Realtime Gesture Prediction", frame)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# ===================== 释放资源 =====================
cap.release()
cv2.destroyAllWindows()
print("✅ 程序已退出")二、项目核心思路梳理
本次项目未追求复杂的深度学习模型,而是聚焦"轻量、易落地、可复用",整体遵循"数据采集→模型训练→实时预测→部署打包"的闭环思路,全程借助大模型辅助搭建框架,再结合自身需求优化细节,具体思路拆解如下:
1. 项目整体定位与框架设计
项目核心定位是"新手友好型手势识别优化方案",避开了从零搭建神经网络、复杂调参的高门槛,选择经典机器学习模型结合成熟的计算机视觉工具,降低开发与落地难度。在动手前,我并未直接编写代码,而是先向大模型明确核心需求,让其输出完整的流程设计与方案框架,而非直接生成最终代码------重点让大模型梳理"数据层、训练层、预测层、部署层"的逻辑关联,明确每个环节的核心任务、所需工具及注意事项,以此为基础搭建项目框架,避免"想到哪写到哪"的混乱,确保各环节衔接流畅、逻辑严密。
2. 各核心环节思路详解
整个项目的核心的是"数据驱动模型,模型支撑应用",四个环节层层递进,每个环节均围绕"优化识别精度、提升落地性"展开,具体思路如下:
(1)手势原始数据采集:核心是"精准、全面"。借助摄像头实时捕捉手势画面,搭配计算机视觉工具提取手部关键点------通过工具自带的手部检测能力,定位手掌区域并提取21个手部三维关键点(涵盖指尖、指节、手腕),以此作为手势的核心特征,避免直接处理图像像素带来的冗余计算。采集过程中,为每个自定义手势(如基础的石头、剪刀、布)标注对应标签,确保每个手势采集足够数量的样本(每个手势不少于200条),兼顾不同角度、不同光线条件下的手势,减少数据偏差对后续模型训练的影响,为模型识别精度打下基础。同时参考相关优化技巧,通过简单的图像预处理提升输入质量,减少光照变化、边缘模糊带来的关键点漂移问题。
(2)经典机器学习模型训练:核心是"高效、易落地"。考虑到新手门槛及部署便捷性,未选用复杂的深度学习模型,而是选择经典机器学习模型(如SVM、随机森林)进行训练。思路是先读取采集到的关键点数据,拆分出特征值(手部关键点的三维坐标)与标签(手势类别),划分训练集与测试集,再通过模型训练学习特征与标签的关联,训练完成后评估模型精度,若精度不达标,通过调整模型参数、补充数据样本等方式优化,最终保存训练好的模型,为后续实时预测提供支撑。选择经典模型的核心考量的是其轻量级特性,无需依赖GPU,后续打包部署更便捷,契合项目"低成本落地"的定位。
(3)实时手势预测:核心是"流畅、精准"。思路是加载训练好的模型,借助摄像头实时读取画面帧,重复数据采集环节的关键点提取逻辑,将提取到的手部关键点输入模型,由模型快速输出手势预测结果,再将预测结果实时显示在画面上,实现"摄像头捕捉→关键点提取→模型预测→结果可视化"的实时闭环。同时优化实时性,通过调整工具参数减少检测延迟,加入关键点后处理逻辑,抑制关键点抖动,提升预测结果的稳定性,确保手势切换时预测流畅、无明显卡顿。
(4)项目部署打包:核心是"脱离环境、可独立运行"。为了让项目摆脱Python环境的限制,方便在无Python配置的电脑上使用,计划通过PyInstaller将项目打包成Windows可执行文件(.exe),实现"双击运行"的便捷性。这一环节原本计划采用常规打包命令,快速完成部署,却成为整个项目中最耗时、最需要突破思维定式的环节。
3. 项目优化核心思路
本次项目的"优化",并非追求复杂的技术升级,而是聚焦"新手落地痛点"的优化:一是优化数据采集的规范性,减少样本偏差,提升模型识别精度;二是优化模型选择,兼顾精度与部署便捷性,避开深度学习的高门槛;三是优化实时预测的流畅度,减少延迟与抖动;四是优化部署打包流程,解决第三方库打包失败的问题,实现项目的真正落地。全程围绕"实用、便捷",让新手也能跟随思路完成从0到1的项目搭建与优化。
三、PyInstaller打包踩坑复盘(核心难点突破)
在整个项目流程中,数据采集、模型训练、实时预测三个环节,借助大模型提供的框架的思路,基本顺利落地,未出现太大阻碍,但在PyInstaller打包环节,却多次遭遇失败,陷入了思维误区,最终通过调整思路、更换方案解决问题,这也是本次项目中最具价值的踩坑经历。
1. 打包失败的核心问题
最初采用PyInstaller常规打包命令,试图快速生成.exe文件,却多次运行失败,核心问题集中在两个方面:一是第三方库未完整打包,尤其是sklearn库,出现"模块缺失"报错,推测是常规打包命令无法识别其隐藏依赖;二是计算机视觉工具的相关文件缺失,具体为工具目录下手部检测相关的模型文件未被打包,导致运行时无法加载手部检测功能,出现文件找不到的报错。
深入分析后发现,这类问题的本质是第三方库(sklearn、计算机视觉工具)不仅包含Python代码文件,还包含大量非.py格式的依赖文件(如模型文件、动态链接库),常规打包命令无法批量识别并收集这些文件,手动添加依赖参数又过于繁琐,且容易遗漏,导致打包后的文件无法正常运行。
2. 思维误区与破局思路
面对打包失败,我最初陷入了典型的思维误区------反复修改常规打包命令,不断添加隐藏依赖、补充数据文件的参数,试图通过微调解决问题,却一次次失败,耗费了大量时间。直到多次尝试无果后才意识到:当一个方案反复修改仍无法解决问题时,继续死磕只会浪费时间,此时最高效的方式是推翻原有方案,换一种全新的思路重新尝试,而非在错误的方向上反复内耗。
最终放弃常规打包命令,转而研究PyInstaller的高级配置方式------通过生成.spec文件,自定义打包配置,借助打包工具的内置函数,批量收集第三方库的所有依赖(包括代码文件和非代码文件),一次性解决依赖缺失的问题,最终成功打包出可正常运行的.exe文件。
3. 解决方案的核心逻辑
.spec文件作为PyInstaller的高级配置文件,可自定义打包的各项参数,核心解决思路是:借助打包工具的辅助函数,批量收集sklearn和计算机视觉工具的所有依赖文件、隐藏导入模块,将其统一添加到打包配置中,替代手动添加参数的繁琐操作,确保所有必要的依赖都能被完整打包,从根源上解决模块缺失、文件找不到的问题。这种方式不仅解决了本次打包问题,也为后续打包包含复杂第三方库的项目提供了可复用的思路。
四、项目实战感悟(核心收获)
本次项目的核心收获,并非完成了手势识别的功能开发,而是在借助大模型辅助开发的过程中,梳理出了高效的项目思路,更在踩坑后收获了宝贵的实战经验与思维提升,这些感悟比代码本身更具价值,也能为后续的项目开发提供指引。
1. 大模型的正确定位:助手而非答案
本次项目全程借助大模型辅助搭建框架、梳理思路,深刻体会到:大模型是高效的开发助手,而非完美的解决方案。它能快速输出清晰的流程设计、提供可行的技术思路,帮我们避开"从零开始"的迷茫,大幅提升开发效率,尤其适合新手梳理项目逻辑。但大模型生成的方案和代码,并非完全适配具体场景,尤其是涉及环境配置、打包部署等个性化较强的环节,容易出现问题,此时不能盲目照搬,更不能依赖大模型解决所有问题,需要结合自身项目需求,主动思考、灵活调整,才能真正发挥大模型的价值。
这也契合大模型应用开发的核心逻辑------我们无需去"造轮子"(开发大模型),而是要学会更好地使用这个"超级轮子",结合具体场景优化调整,搭建出符合需求的应用,这也是应用层开发的核心优势。
2. 解决问题的关键:拒绝死磕,学会"推翻重来"
打包环节的踩坑经历,让我深刻明白一个道理:项目开发中,遇到问题不可怕,可怕的是陷入思维定式,死磕单一方案。很多时候,我们之所以被问题困住,不是问题本身太难,而是我们过于执着于自己最初的思路,不愿轻易推翻,导致在错误的方向上浪费时间。
尤其是在借助大模型辅助开发时,大模型提供的方案可能存在局限性,当按照其思路执行出现问题时,更不能盲目迷信,而是要及时止损,推翻原有方案,重新查找资料、调整思路,换一种方式尝试。就像本次打包问题,常规命令行不通,转而使用.spec文件,反而快速解决了问题。这种"灵活变通、拒绝死磕"的思维,不仅适用于打包环节,更适用于整个项目开发过程,甚至是日常学习和工作中。
3. 项目开发的核心:先搭框架,再填细节,重视落地
本次项目能顺利落地,核心得益于前期借助大模型梳理出了清晰的流程框架。新手开发项目,最容易陷入"急于写代码、忽视框架设计"的误区,导致后续环节混乱、衔接不畅,甚至出现返工。正确的思路应该是:先明确项目目标,梳理出完整的流程框架,明确每个环节的核心任务、所需工具及注意事项,再逐步填充细节、完善功能,这样才能确保项目逻辑严密、衔接流畅,提升开发效率。
同时,项目开发不能只关注核心功能的实现,更要重视落地环节。很多新手开发项目,只追求"能运行",却忽视了部署打包,导致项目无法脱离开发环境,无法真正投入使用,失去了项目的实用价值。本次项目中,打包环节虽然耗时,但最终实现了项目的独立运行,让整个项目形成了闭环,也让我意识到:落地性才是衡量一个实用型项目的关键,无论功能多完善,无法部署使用,就失去了其核心意义。
4. 优化的本质:贴合需求,而非追求复杂
本次项目的"优化",并非追求复杂的技术或高精度的模型,而是贴合"新手友好、低成本落地"的需求,选择简单易上手的技术组合,解决新手落地的痛点。这也让我明白:项目优化的核心,是贴合实际需求,提升项目的实用性和便捷性,而非盲目追求技术的复杂性。对于新手而言,先完成"能用",再优化"好用",逐步提升,才是更高效的成长路径;对于实用型项目而言,轻量、易部署、易复用,远比复杂的技术架构更有价值。