【爬取目标】
目标网站:胡润百富 - U30创业先锋榜
在创业趋势分析、青年企业家研究、行业赛道洞察等场景中,胡润U30创业先锋榜是重要的参考数据源。手动整理榜单中的青年创业者信息(姓名、所属企业、行业、企业总部等)耗时且易出错,本文将教你使用 Python 编写爬虫程序,批量爬取胡润U30创业先锋榜数据并自动保存到 Excel 文件,快速搭建专属青年创业者信息库!
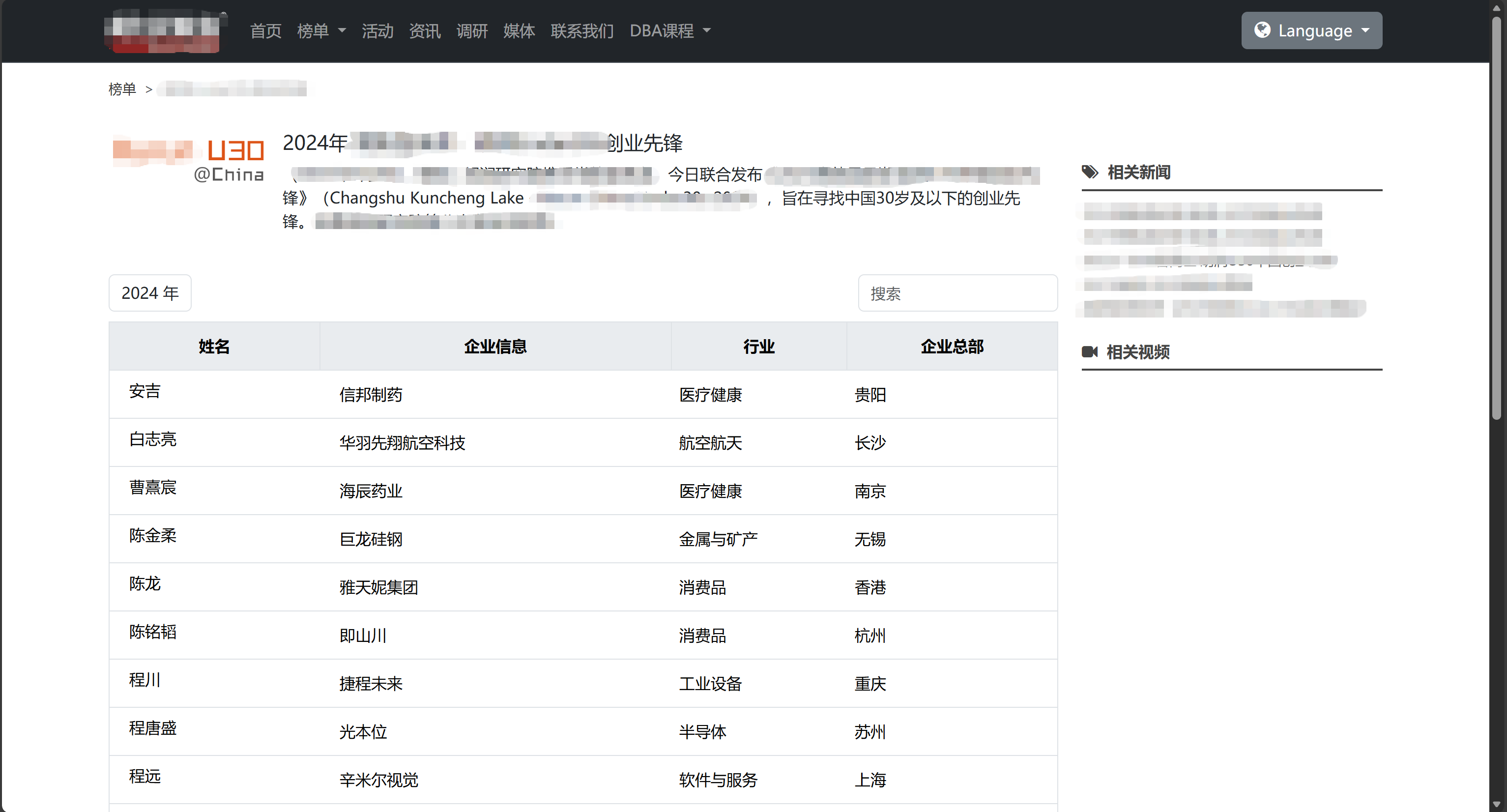
【实现效果】
代码实现批量爬取胡润U30创业先锋榜榜单数据,整理结构化信息后存放到 Excel 文件中,包含姓名、企业信息、行业、企业总部等核心字段:
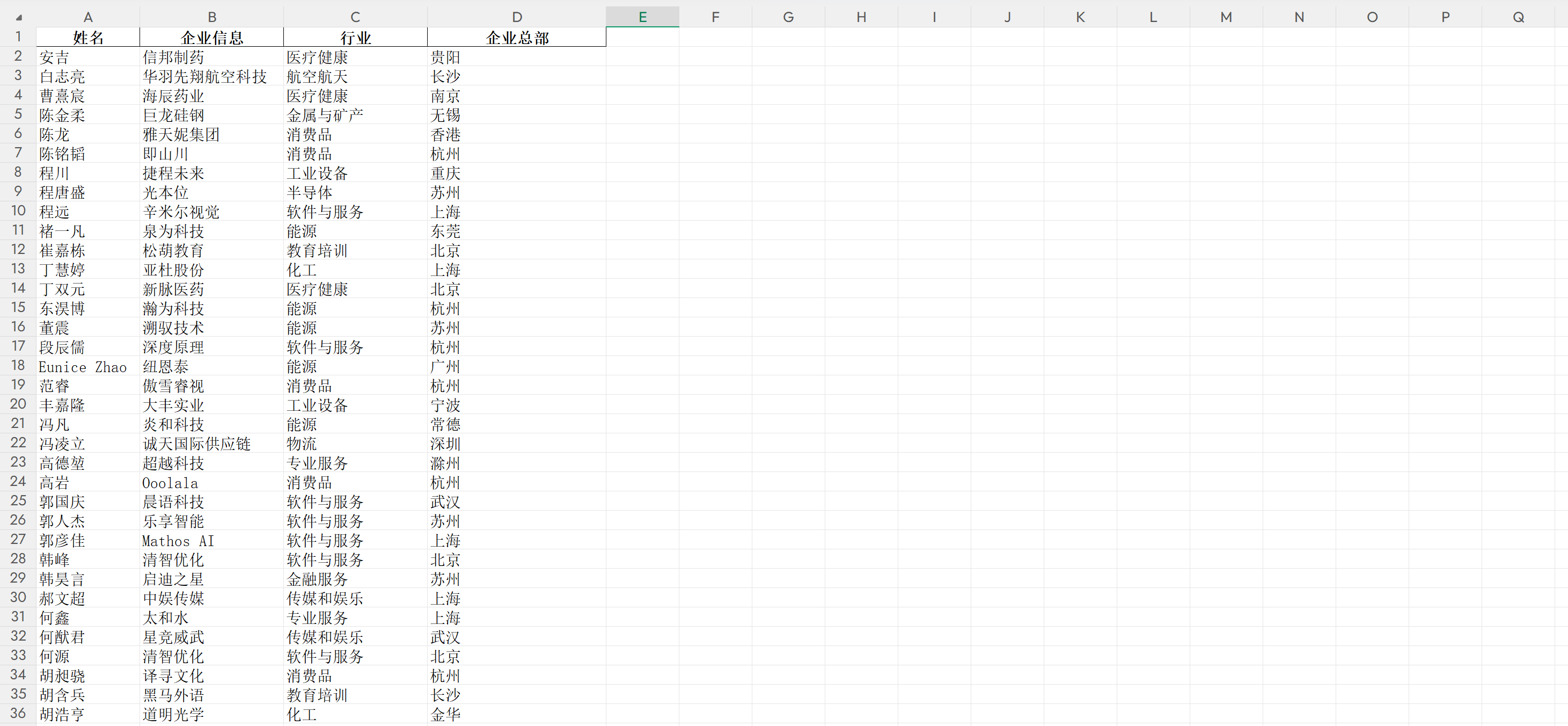
文章目录
- 一、技术栈和环境版本
- 二、爬虫实战分析
-
- [2.1 导入模块](#2.1 导入模块)
- [2.2 分析网页](#2.2 分析网页)
- [2.3 发送请求,获取网页源码](#2.3 发送请求,获取网页源码)
- [2.4 解析数据](#2.4 解析数据)
- [2.5 存储数据](#2.5 存储数据)
- [2.6 主函数启动程序](#2.6 主函数启动程序)
- 三、完整爬虫代码
- 四、总结
- 五、专栏说明
一、技术栈和环境版本
Python:3.12.3
编辑器:PyCharm
第三方模块,自行安装:
bash
pip install requests==2.32.5 # 接口数据请求
pip install pandas==2.3.3 # 数据结构化与Excel保存
pip install openpyxl==3.1.5 # Excel文件写入引擎二、爬虫实战分析
2.1 导入模块
python
import requests
import json
import pandas as pd2.2 分析网页
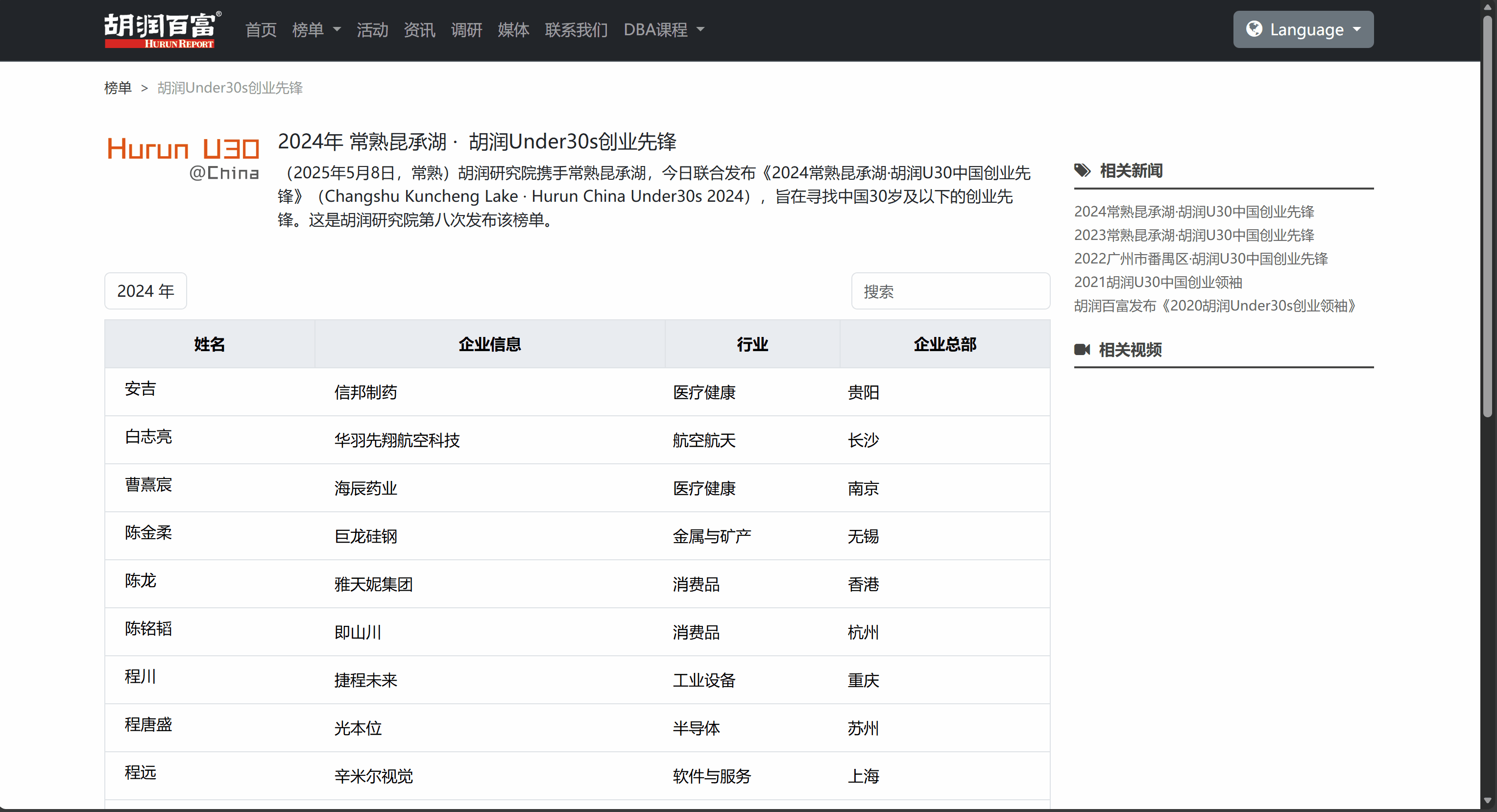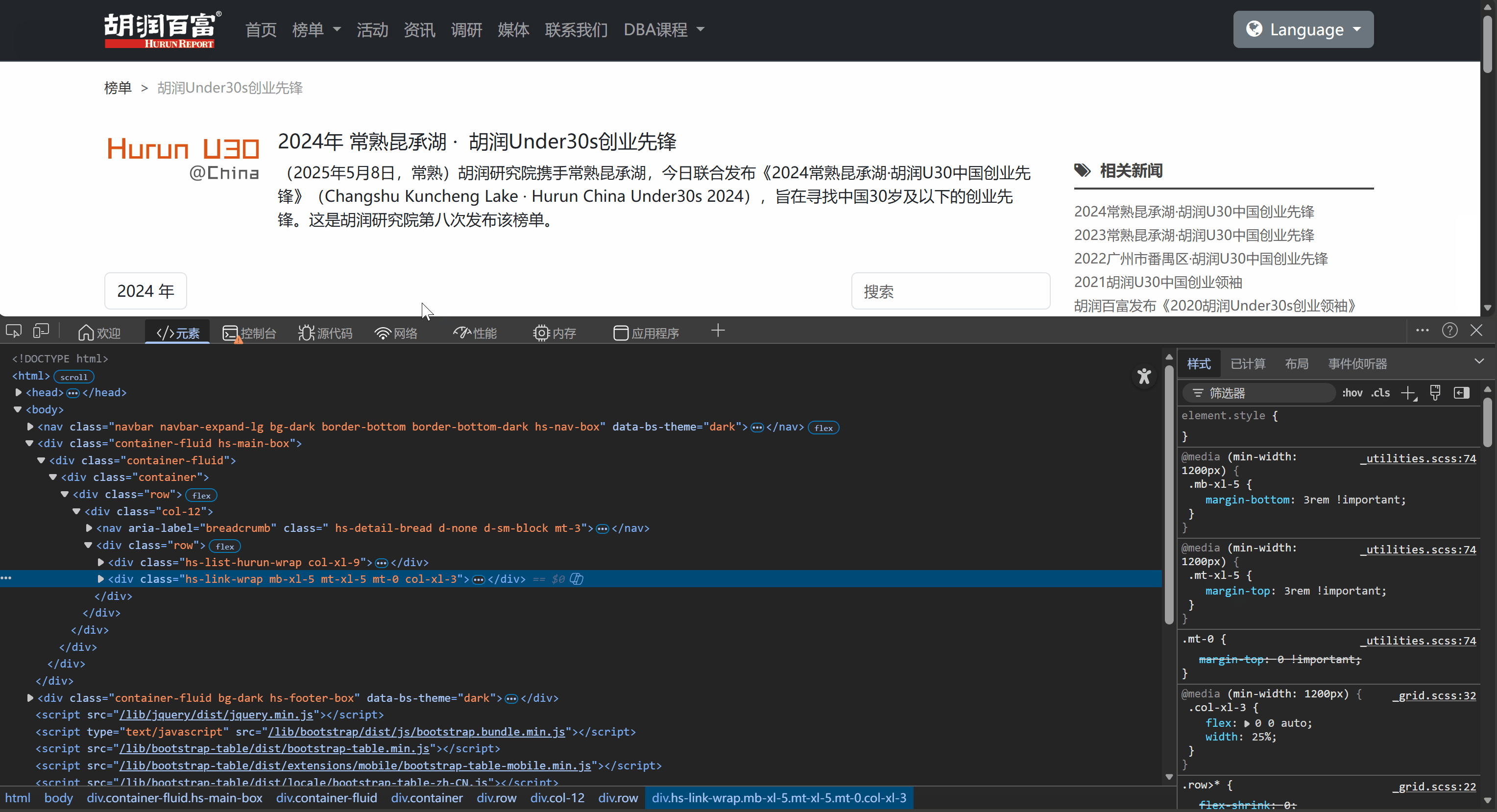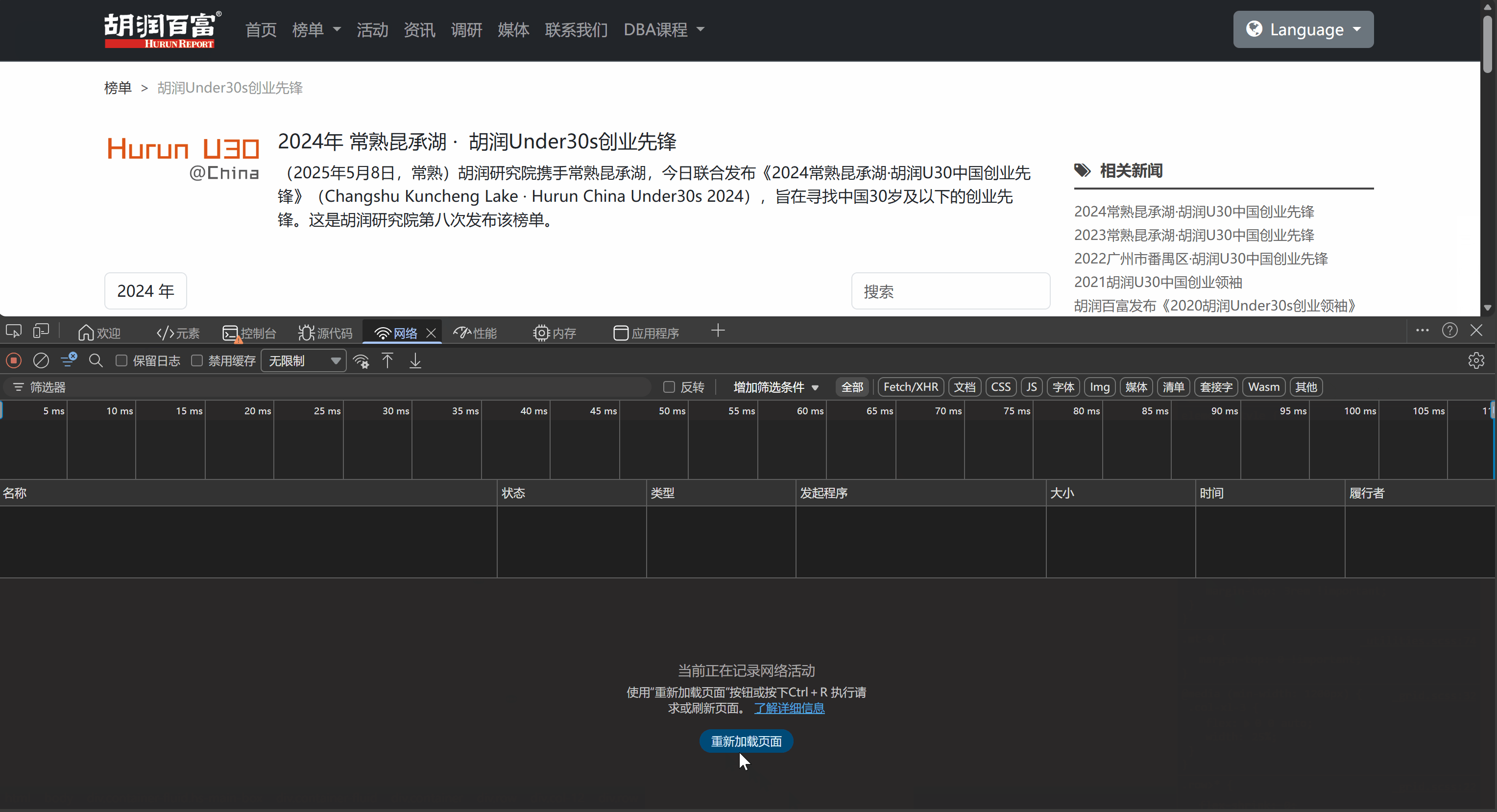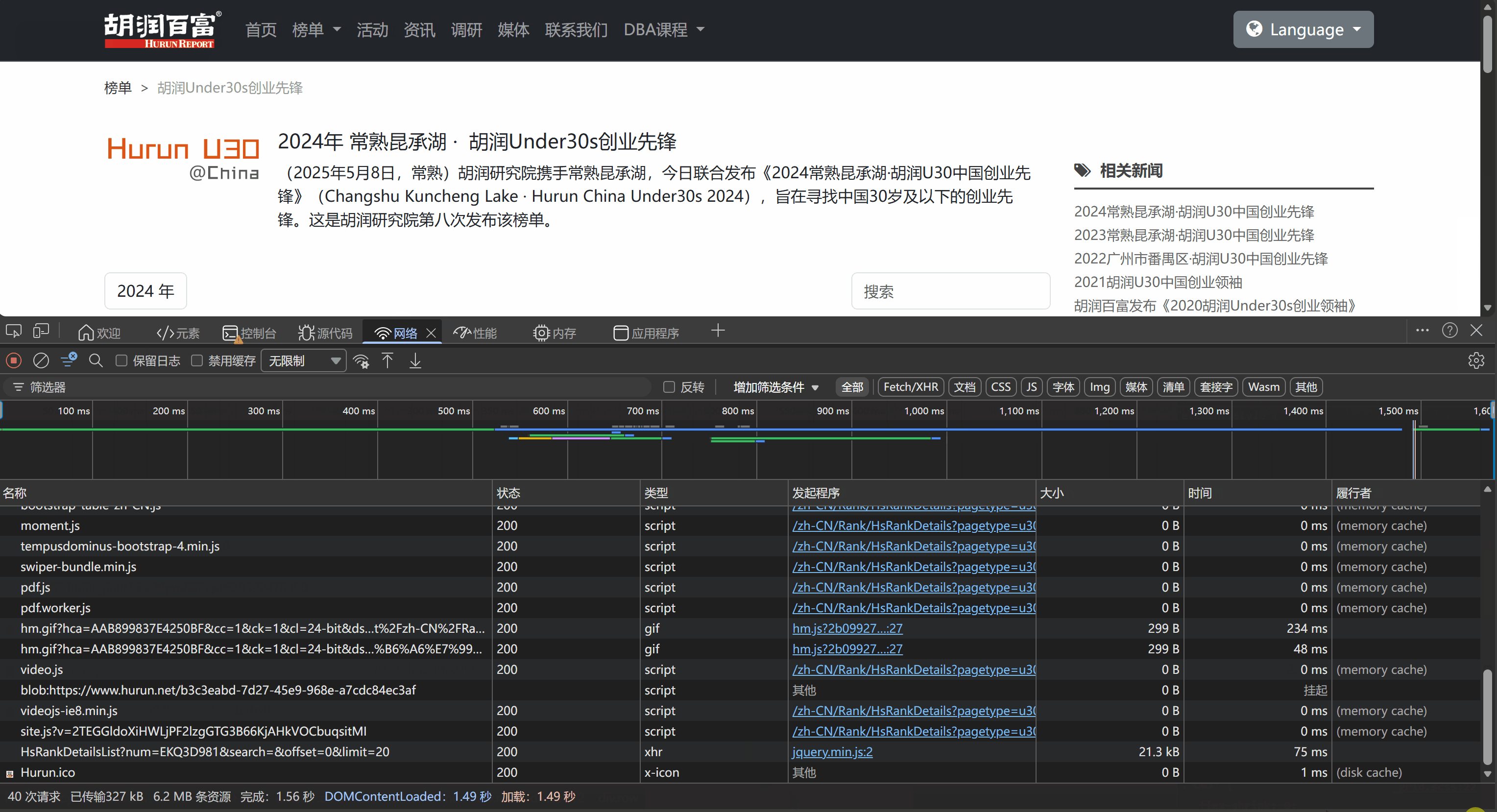
我们按以下步骤获取U30创业先锋信息存储的API接口:
- 右击网页空白处选择检查;或者按F12,打开开发者工具;
- 在控制面板点击Network(网络);
- 清空之前的抓包记录;
- 按网页刷新按钮;或者F5刷新;
- Network(网络)中就是最新的抓包记录,可找到创业者信息相关数据:
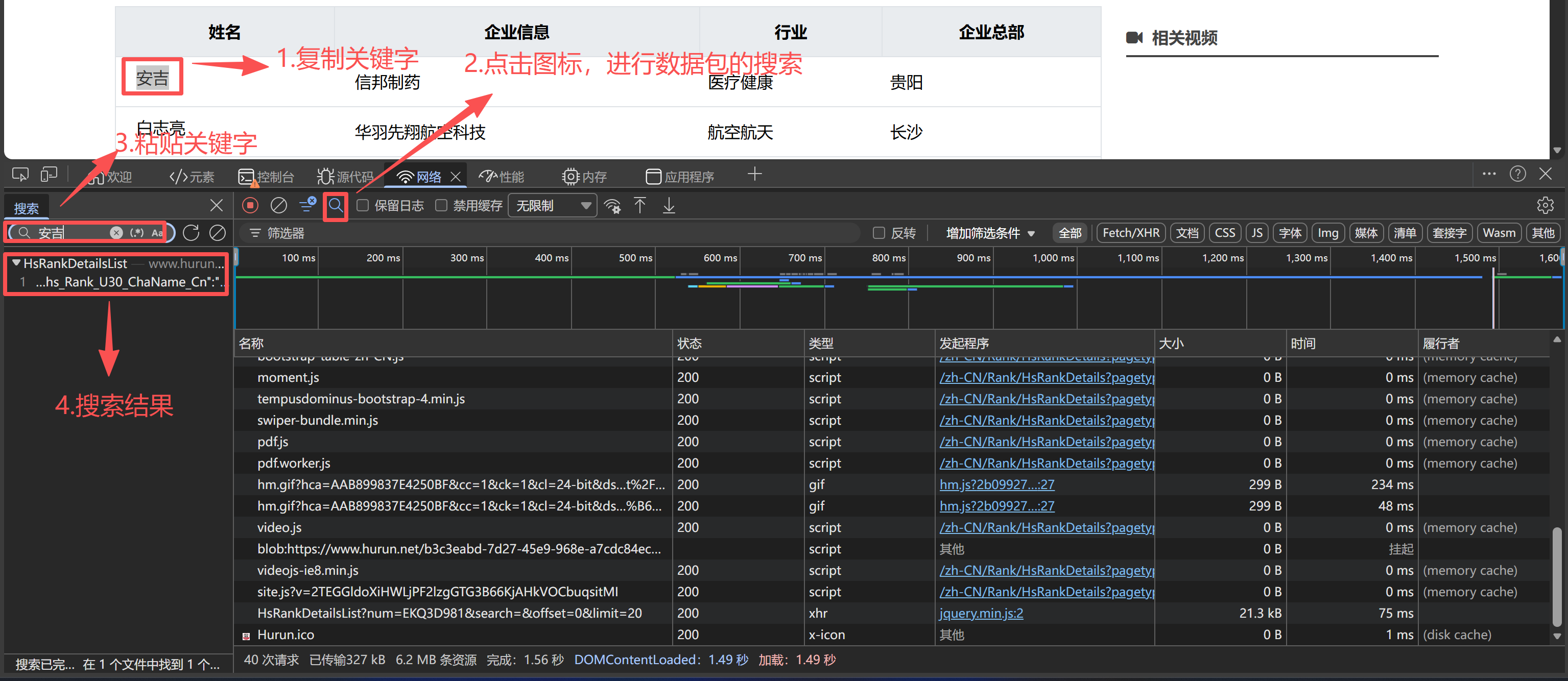
然后利用关键字的搜索,定位存储核心数据的数据包:
- 点击搜索图标,打开搜索面板;
- 粘贴"创业先锋""企业名称""行业"等关键字;
- 回车进行搜索数据包:
页面结构分析:
- 观察页面结构,发现数据通过异步请求加载(AJAX),而非直接嵌入HTML;
- 分析抓包记录,发现核心数据存储在
HsRankDetailsList接口的JSON响应中; - 该接口返回结构化的JSON数据,包含所有U30创业先锋榜单信息,需分页请求,但是这里进行了一个巧妙的方式,后续会讲到;
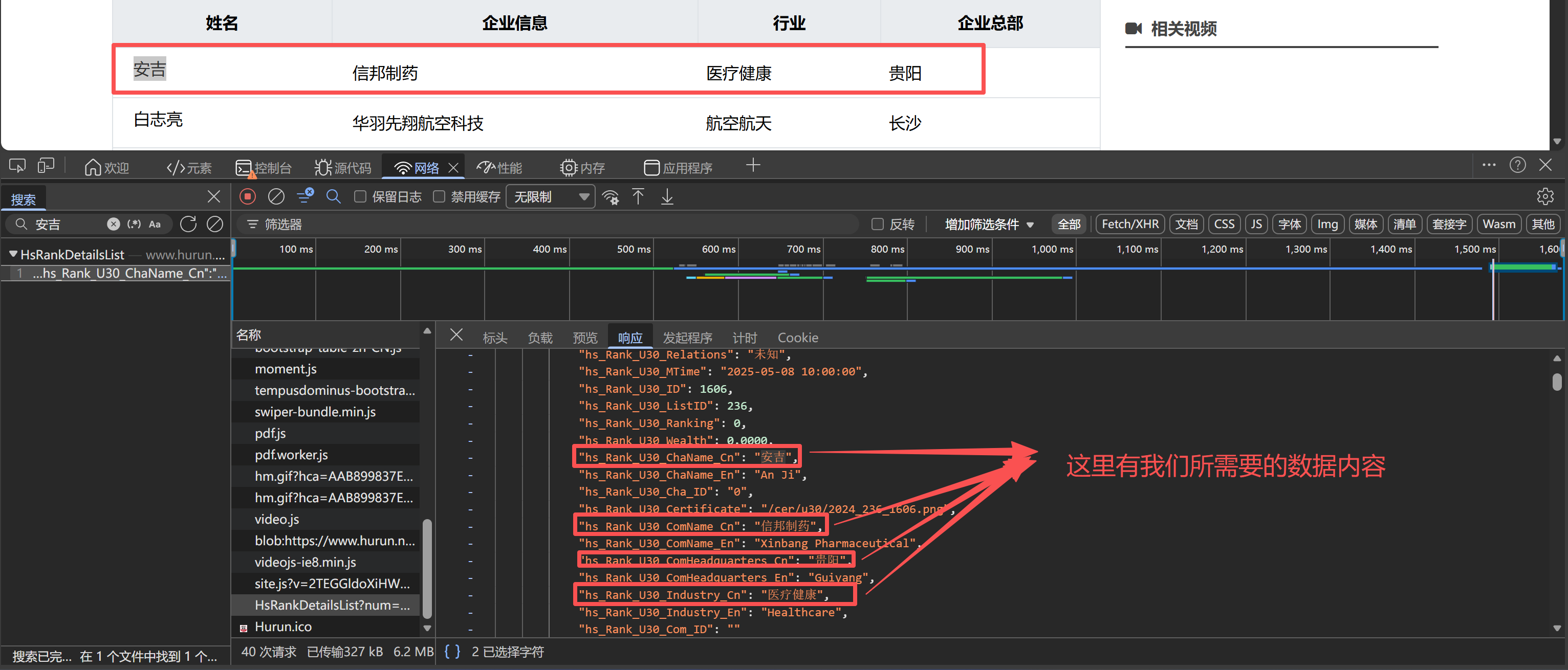
数据结构特点:
- 接口返回数据包含
rows字段,存储所有创业者的详细信息列表;

- 每条记录包含人物信息(姓名)和企业信息(企业名称、行业、总部等);
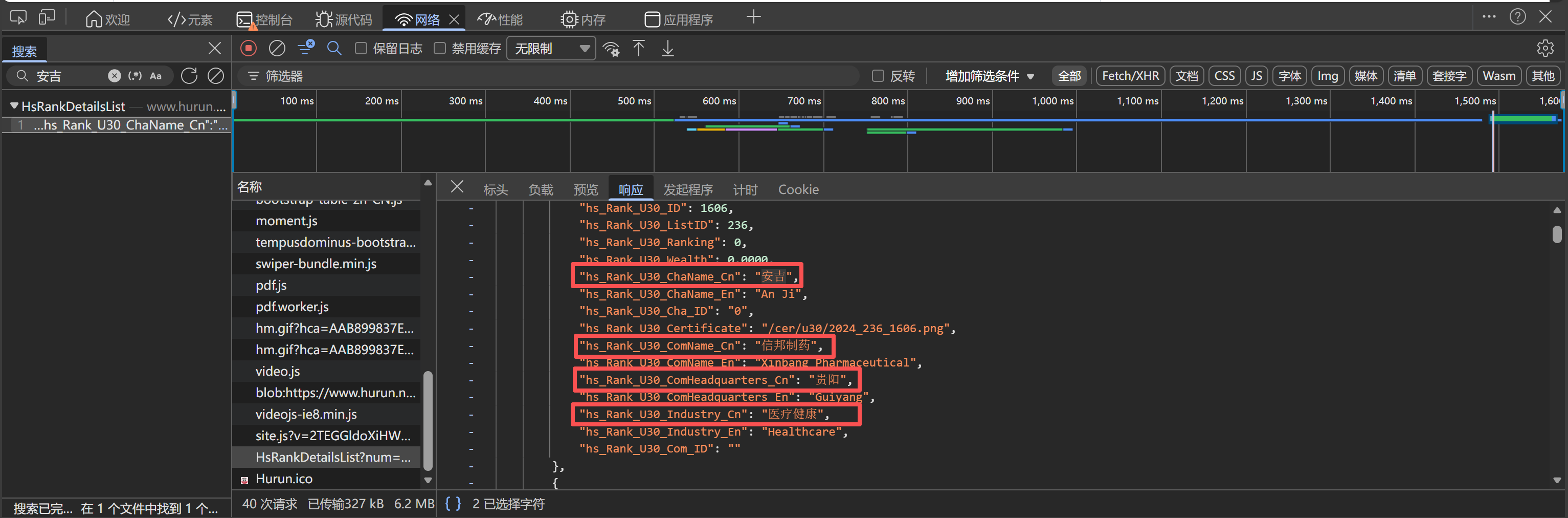
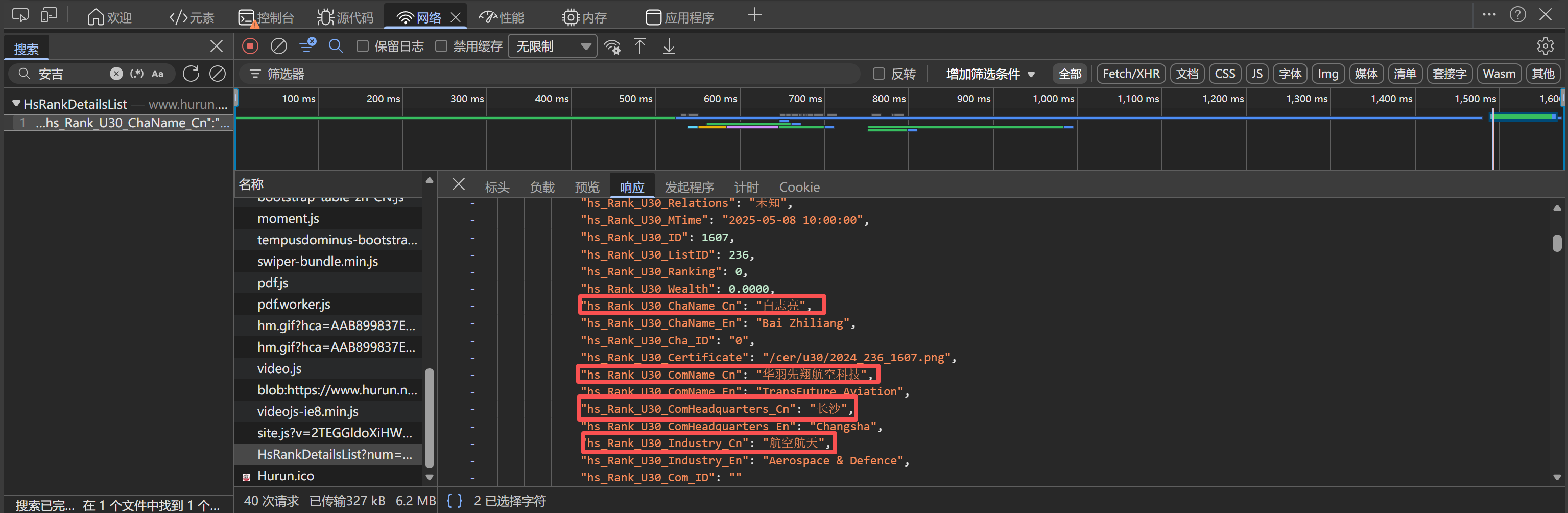
- 可通过调整
limit参数控制单次获取的数据量,覆盖全部榜单数据;
【分页处理】
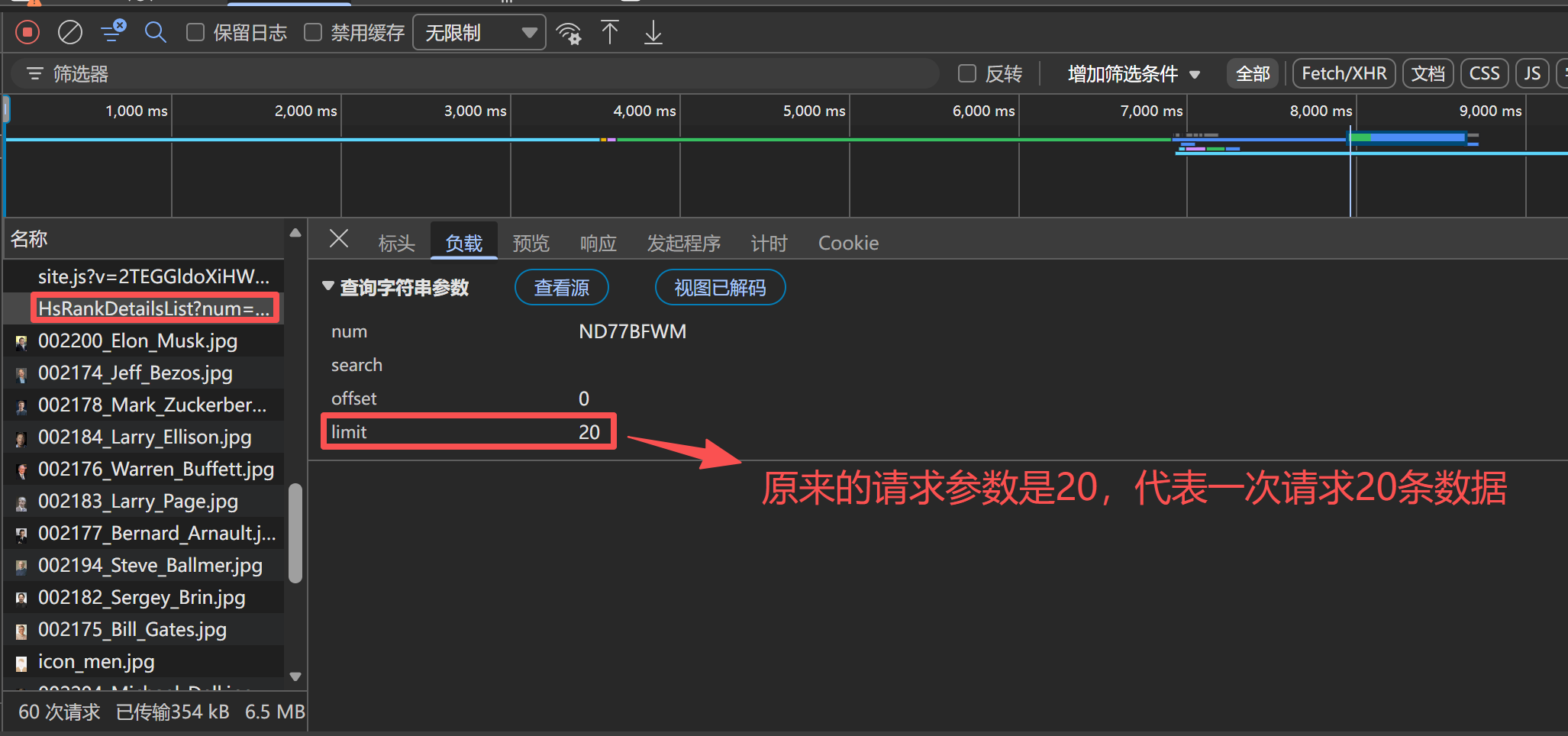
为了能完整获取胡润 U30 创业先锋榜的全量数据,我们需要先分析接口的分页请求规则,先通过请求第二页数据,观察接口请求参数的变化规律,以此掌握常规的分页处理方式:
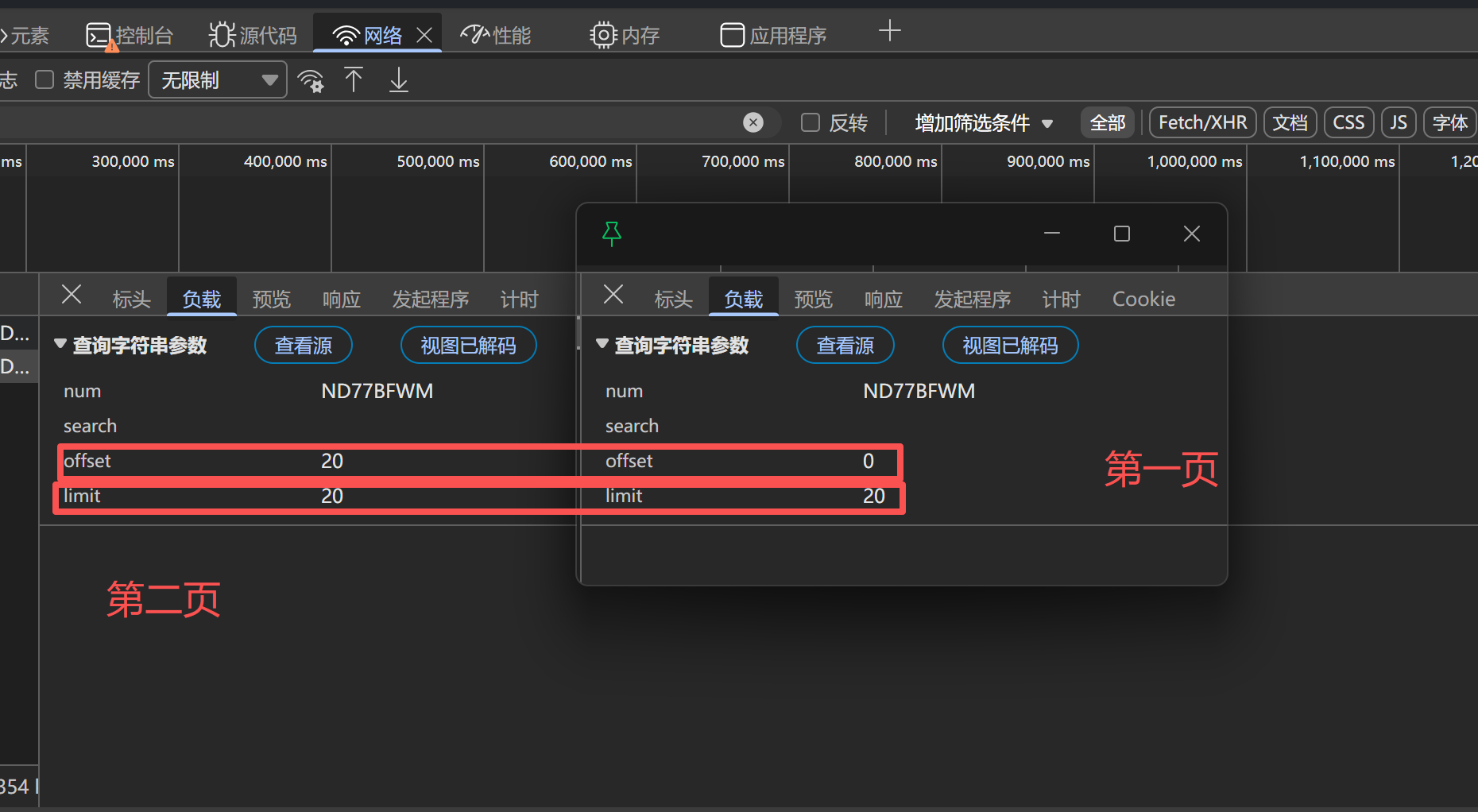
通过上图可以看出,我们请求的参数有两个是进行变化的,第一个是offset(起始数),limit(每页请求数),所以如果我们按照常规的来进行处理,可以总结出结论:
| 页码 | offset | limit |
|---|---|---|
| 第一页 | 0 | 20 |
| 第二页 | 20 | 20 |
| 第三页 | 40 | 20 |
然后按照常规步骤有了这些规律,那么接下来就是构建请求参数,发送请求,并观察是否可以正常获取响应,确实这些都是常规的步骤,但是博主这里要告诉你们一种巧妙的方法,这种方法就是直接修改limit参数,直接修改为100,这样一次请求可以获取100条数据内容,不仅仅可以减少请求的次数,还可以增强我们代码的反爬效果,而且最大的好处就是速度变快了很多,不是快了一点半点,有明显的差距
通过验证不同分页的请求行为,发现目标接口支持通过limit参数一次性返回大量数据(设置为100可覆盖全部榜单),无需多次分页请求,只需一次请求即可获取完整数据。
2.3 发送请求,获取网页源码
按以下步骤创建请求函数,获取API接口的JSON响应内容:
- 定义
get_html_str(url, params)函数;接收目标API链接URL和请求参数params作为参数; - 设置完整的请求头,模拟真实浏览器的AJAX请求(包含
X-Requested-With等关键字段); - 配置接口参数(
num专属编号、offset分页偏移、limit数据量限制等); - 发送GET请求获取响应数据;
- 校验请求状态,返回JSON字符串;
python
def get_html_str(url, params=None):
"""
发送请求获取胡润U30榜单页面内容
Args:
url (str): 目标URL
params (dict): 请求参数
Returns:
str: 页面响应内容(JSON格式)
"""
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/json",
"priority": "u=1, i",
"referer": "https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=u30",
"sec-ch-ua": "\"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"144\", \"Microsoft Edge\";v=\"144\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36 Edg/144.0.0.0",
"x-requested-with": "XMLHttpRequest"
}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.text
except Exception as e:
print(f"获取数据失败: {e}")
return None按以下步骤验证响应数据有效性:
- 运行函数;打印返回的JSON字符串;
- 按住Ctrl+F打开搜索框;输入"创业先锋""科技""北京"等关键词查找数据;
- 确认搜索结果中存在目标数据;说明响应获取成功:
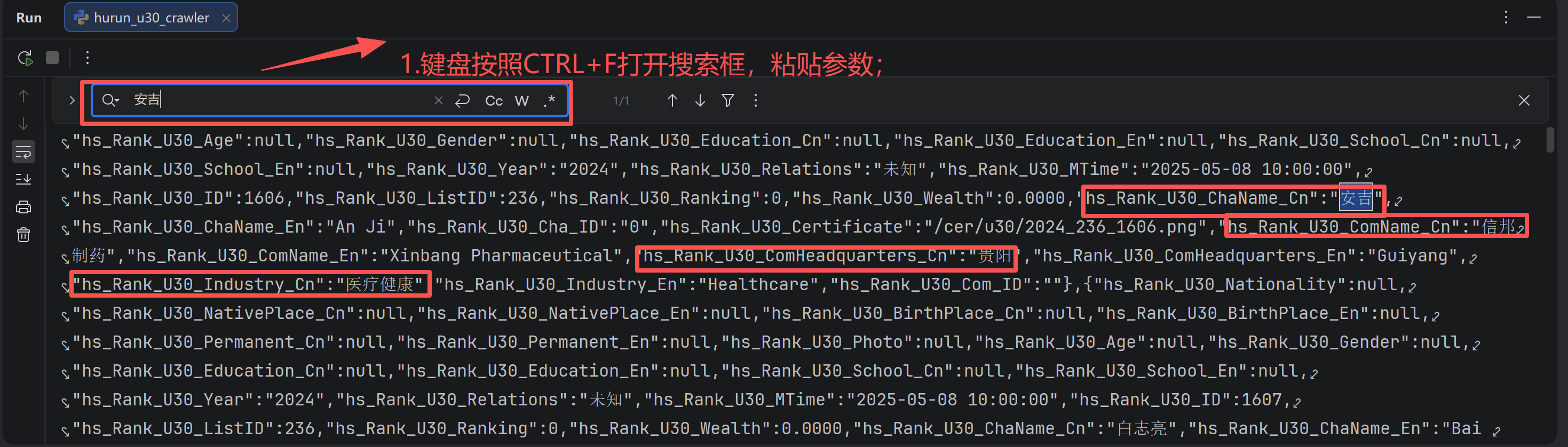
2.4 解析数据
按以下步骤创建数据提取函数,从JSON响应中提取创业者详细信息:
- 定义
get_data(json_content)函数,接收JSON字符串作为参数; - 解析JSON数据,定位存储核心信息的
rows字段; - 遍历每条记录,分别提取人物信息(姓名)和企业信息(企业名称、行业、总部等);
- 处理空值和数据格式,确保字段完整性;
- 将提取的信息封装为字典,添加到数据列表中;
- 返回创业者信息字典列表;
python
def get_data(json_content):
"""
从JSON内容中提取胡润U30榜单所需字段
Args:
json_content (str): JSON格式的响应内容
Returns:
list: 提取的数据列表
"""
try:
# 解析JSON数据
data_json = json.loads(json_content)
data_list = []
print(f"解析的数据类型: {type(data_json)}")
print(f"数据键列表: {list(data_json.keys()) if isinstance(data_json, dict) else '不是字典类型'}")
# 根据返回的JSON结构提取数据
# 实际数据在'rows'字段中
items = []
if isinstance(data_json, dict) and 'rows' in data_json:
items = data_json['rows']
print(f"找到 {len(items)} 个数据项")
elif isinstance(data_json, list):
items = data_json
print(f"直接获取到 {len(items)} 个数据项")
else:
print("返回的数据结构不符合预期")
print(f"实际数据结构: {data_json}")
return []
for item in items:
# 提取指定字段
hs_Rank_U30_ChaName_Cn = item.get('hs_Rank_U30_ChaName_Cn', '') # 姓名
hs_Rank_U30_ComName_Cn = item.get('hs_Rank_U30_ComName_Cn', '') # 企业信息
hs_Rank_U30_Industry_Cn = item.get('hs_Rank_U30_Industry_Cn', '') # 行业
hs_Rank_U30_ComHeadquarters_Cn = item.get('hs_Rank_U30_ComHeadquarters_Cn', '') # 企业总部
# 创建数据条目,只使用中文字段名
item_data = {
'姓名': hs_Rank_U30_ChaName_Cn,
'企业信息': hs_Rank_U30_ComName_Cn,
'行业': hs_Rank_U30_Industry_Cn,
'企业总部': hs_Rank_U30_ComHeadquarters_Cn
}
data_list.append(item_data)
print(item_data)
return data_list
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
return []
except Exception as e:
print(f"解析数据失败: {e}")
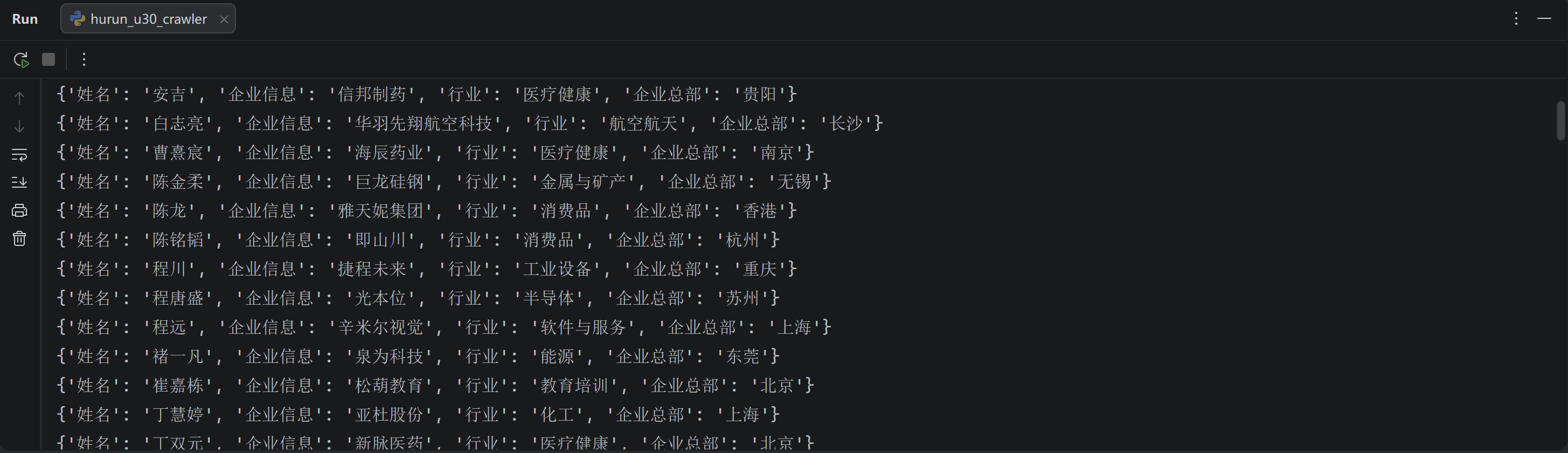
return []按以下步骤验证数据提取有效性:
- 运行函数;观察控制台打印的字典数据;
- 核对打印的信息与网页显示的创业者信息是否一致;
- 确认字段完整、无乱码;说明数据提取成功:
控制台示例:
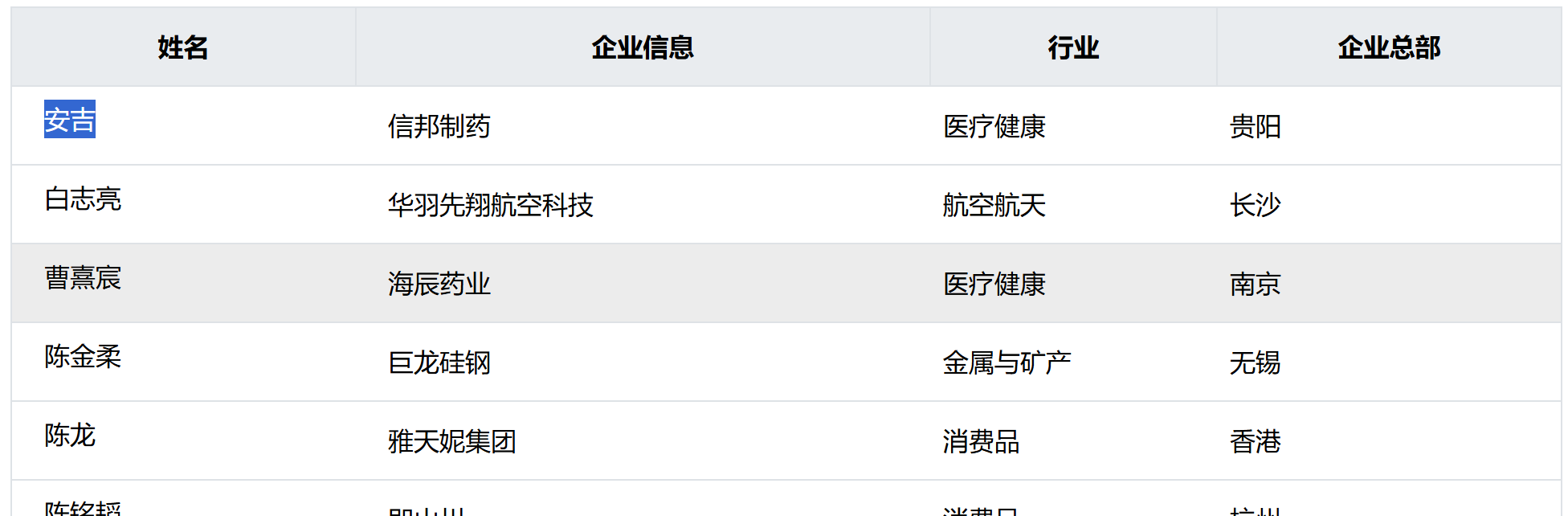
网页对照:
2.5 存储数据
将提取的结构化数据保存到Excel文件,步骤如下:
- 定义
save_data(data_list, filename)函数,接收创业者信息字典列表和文件名作为参数; - 将字典列表转换为DataFrame格式;
- 使用pandas的
to_excel方法保存为Excel文件,指定openpyxl引擎; - 添加异常捕获,处理库缺失、保存失败等情况;
- 打印保存成功提示;
python
def save_data(data_list, filename='胡润U30创业先锋数据.xlsx'):
"""
保存数据到Excel文件
Args:
data_list (list): 数据列表
filename (str): 保存的文件名,默认为'胡润U30创业先锋数据.xlsx'
"""
try:
df = pd.DataFrame(data_list)
df.to_excel(filename, index=False, engine='openpyxl')
print(f"数据已成功保存到 {filename}")
except ImportError:
print("缺少openpyxl库,请运行: pip install openpyxl")
except Exception as e:
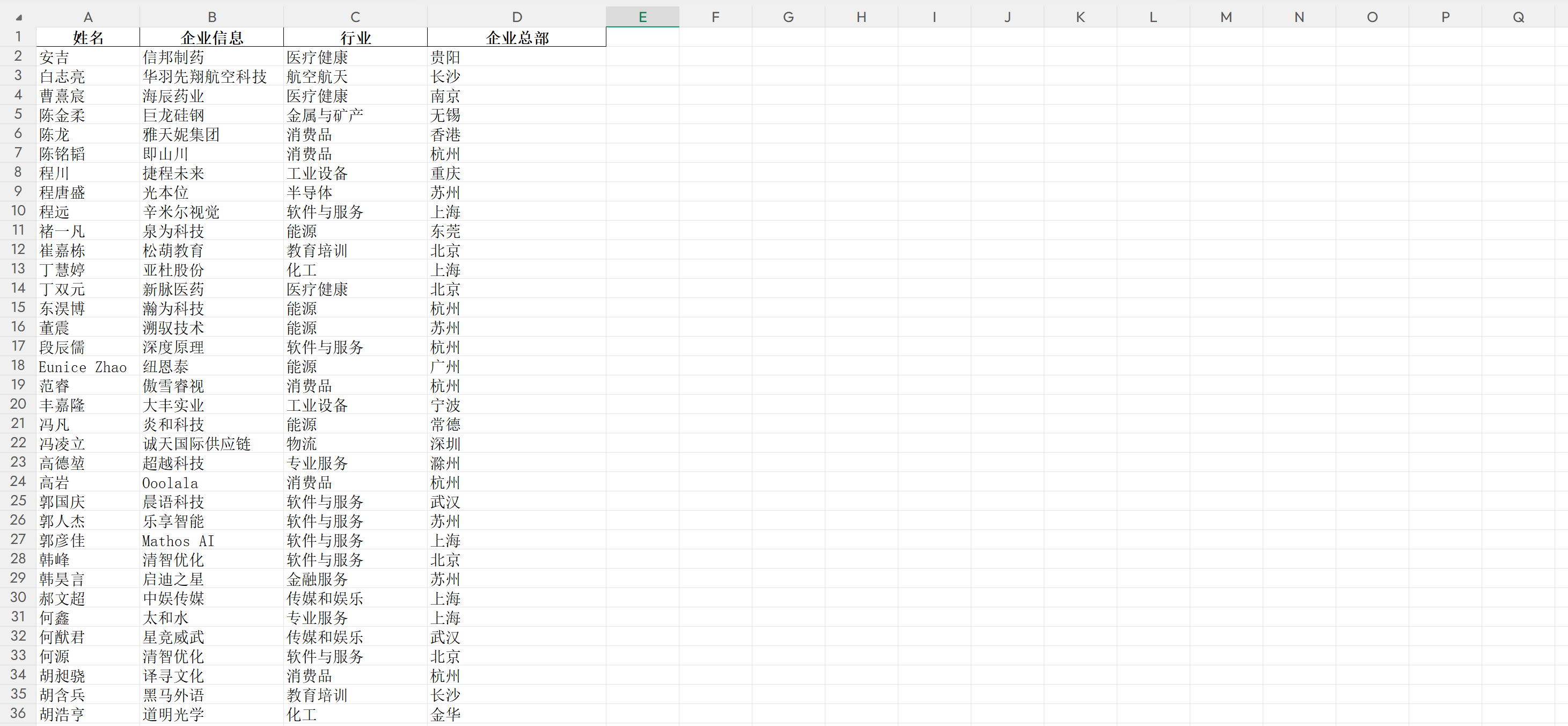
print(f"保存数据失败: {e}")验证数据保存结果:
- 打开本地目录;
- 确认存在"胡润U30创业先锋数据.xlsx"文件,打开后字段完整、数据准确;说明保存成功:
2.6 主函数启动程序
主函数main()是爬虫流程的调度中心,协调接口请求、数据解析、Excel保存三大核心环节:
- 定义目标API接口地址;
- 配置U30榜单专属请求参数(
num编号、limit数据量等); - 调用
get_html_str()获取JSON响应; - 调用
get_data()解析创业者信息; - 调用
save_data()保存数据到Excel; - 增加关键节点的日志提示,提升程序易用性;
python
def main():
# 胡润U30榜单API接口
url = "https://www.hurun.net/zh-CN/Rank/HsRankDetailsList"
# 设置请求参数,limit设置为100以一次性获取全部数据
params = {
"num": "EKQ3D981", # U30榜单的编号
"search": "",
"offset": "0",
"limit": "100" # 修改为100,一次性获取全部数据
}
print("正在获取胡润U30创业先锋数据...")
# 使用get_html_str函数获取数据
json_content = get_html_str(url, params=params)
if json_content:
print("数据获取成功,正在提取所需字段...")
# 提取数据
data = get_data(json_content)
if data:
print(f"数据提取成功,共提取到 {len(data)} 条记录")
exit()
# 保存数据
save_data(data, '胡润U30创业先锋数据.xlsx')
else:
print("未能从响应中提取到有效数据")
else:
print("未能获取页面内容")三、完整爬虫代码
【免责声明】:本文爬虫思路、相关技术和代码仅用于学习参考,对阅读本文后的进行爬虫行为的用户不承担任何法律责任。
- 使用或者参考本项目即表示您已阅读并同意以下条款:
- 合法使用: 不得将本项目用于任何违法、违规或侵犯他人权益的行为,包括但不限于网络攻击、诈骗、绕过身份验证、未经授权的数据抓取等。
- 风险自负: 任何因使用本项目而产生的法律责任、技术风险或经济损失,由使用者自行承担,项目作者不承担任何形式的责任。
- 禁止滥用: 不得将本项目用于违法牟利、黑产活动或其他不当商业用途。
- 使用或者参考本项目即视为同意上述条款,即 "谁使用,谁负责" 。如不同意,请立即停止使用并删除本项目。
python
# 原文地址:https://blog.csdn.net/yuan2019035055/article/details/157945393
import requests
import pandas as pd
import json
def get_html_str(url, params=None):
"""
发送请求获取胡润U30榜单页面内容
Args:
url (str): 目标URL
params (dict): 请求参数
Returns:
str: 页面响应内容(JSON格式)
"""
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/json",
"priority": "u=1, i",
"referer": "https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=u30",
"sec-ch-ua": "\"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"144\", \"Microsoft Edge\";v=\"144\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36 Edg/144.0.0.0",
"x-requested-with": "XMLHttpRequest"
}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.text
except Exception as e:
print(f"获取数据失败: {e}")
return None
def get_data(json_content):
"""
从JSON内容中提取胡润U30榜单所需字段
Args:
json_content (str): JSON格式的响应内容
Returns:
list: 提取的数据列表
"""
try:
# 解析JSON数据
data_json = json.loads(json_content)
data_list = []
print(f"解析的数据类型: {type(data_json)}")
print(f"数据键列表: {list(data_json.keys()) if isinstance(data_json, dict) else '不是字典类型'}")
# 根据返回的JSON结构提取数据
# 实际数据在'rows'字段中
items = []
if isinstance(data_json, dict) and 'rows' in data_json:
items = data_json['rows']
print(f"找到 {len(items)} 个数据项")
elif isinstance(data_json, list):
items = data_json
print(f"直接获取到 {len(items)} 个数据项")
else:
print("返回的数据结构不符合预期")
print(f"实际数据结构: {data_json}")
return []
for item in items:
# 提取指定字段
hs_Rank_U30_ChaName_Cn = item.get('hs_Rank_U30_ChaName_Cn', '') # 姓名
hs_Rank_U30_ComName_Cn = item.get('hs_Rank_U30_ComName_Cn', '') # 企业信息
hs_Rank_U30_Industry_Cn = item.get('hs_Rank_U30_Industry_Cn', '') # 行业
hs_Rank_U30_ComHeadquarters_Cn = item.get('hs_Rank_U30_ComHeadquarters_Cn', '') # 企业总部
# 创建数据条目,只使用中文字段名
item_data = {
'姓名': hs_Rank_U30_ChaName_Cn,
'企业信息': hs_Rank_U30_ComName_Cn,
'行业': hs_Rank_U30_Industry_Cn,
'企业总部': hs_Rank_U30_ComHeadquarters_Cn
}
data_list.append(item_data)
print(item_data)
return data_list
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
return []
except Exception as e:
print(f"解析数据失败: {e}")
return []
def save_data(data_list, filename='胡润U30创业先锋数据.xlsx'):
"""
保存数据到Excel文件
Args:
data_list (list): 数据列表
filename (str): 保存的文件名,默认为'胡润U30创业先锋数据.xlsx'
"""
try:
df = pd.DataFrame(data_list)
df.to_excel(filename, index=False, engine='openpyxl')
print(f"数据已成功保存到 {filename}")
except ImportError:
print("缺少openpyxl库,请运行: pip install openpyxl")
except Exception as e:
print(f"保存数据失败: {e}")
def main():
# 胡润U30榜单API接口
url = "https://www.hurun.net/zh-CN/Rank/HsRankDetailsList"
# 设置请求参数,limit设置为100以一次性获取全部数据
params = {
"num": "EKQ3D981", # U30榜单的编号
"search": "",
"offset": "0",
"limit": "100" # 修改为100,一次性获取全部数据
}
print("正在获取胡润U30创业先锋数据...")
# 使用get_html_str函数获取数据
json_content = get_html_str(url, params=params)
if json_content:
print("数据获取成功,正在提取所需字段...")
# 提取数据
data = get_data(json_content)
if data:
print(f"数据提取成功,共提取到 {len(data)} 条记录")
exit()
# 保存数据
save_data(data, '胡润U30创业先锋数据.xlsx')
else:
print("未能从响应中提取到有效数据")
else:
print("未能获取页面内容")
if __name__ == "__main__":
main()运行结果:
四、总结
本次案例通过Python爬虫技术,成功实现了对胡润U30创业先锋榜API接口数据的批量爬取与Excel保存。代码采用模块化设计,包含接口请求、JSON解析、数据提取、Excel持久化等完整流程;通过模拟真实浏览器的AJAX请求头,有效规避基础反爬策略,保证请求的稳定性。
整个爬虫逻辑遵循"API请求 → JSON解析 → 数据提取 → 保存到Excel"的标准流程,与异步加载类网站的爬取范式高度一致。学习重点包括:
- AJAX接口抓包与分析 :通过开发者工具定位异步加载的API接口,识别核心参数(
num专属编号、offset/limit)和请求头要求; - JSON数据解析技巧 :使用
json.loads()解析响应字符串,处理不同结构的JSON数据(字典/列表),兼容接口返回的多种数据格式; - 数据提取与字段映射 :精准提取U30榜单专属字段,通过
get()方法处理空值,保证字段完整性; - 参数灵活配置 :针对U30榜单的专属
num参数配置,结合limit参数一次性获取全量数据,简化分页逻辑; - 异常处理机制:覆盖JSON解析失败、请求失败、Excel保存失败等场景,提升程序容错性。
技术亮点:
- 无需解析复杂HTML,直接请求核心API接口,数据提取效率更高;
- 适配U30榜单的专属参数配置,保证数据精准性;
- 兼容不同JSON返回结构(字典/列表),提升程序健壮性;
- 灵活配置
limit参数,一次性获取全量数据,避免分页请求的繁琐;
注意事项:
- API接口的
num参数可能存在时效性,若请求失败需重新抓包更新参数; - 实际使用中建议添加
time.sleep(1)控制请求频率,避免给目标服务器造成压力; - 定期检查接口结构是否变化(如字段名、参数规则),及时调整解析逻辑;
- U30榜单数据量随时间更新,可根据实际需求调整
limit参数值。
本案例难度适中,适合Python爬虫初学者掌握AJAX接口爬取的核心技能,特别是针对不同榜单的专属参数配置和JSON数据兼容解析的应用,为后续应对更复杂的动态网站爬取打下坚实基础。
五、专栏说明
- 🏆作者介绍:Python领域优质创作者,深耕爬虫领域数年,深受 全网100万+ 粉丝喜爱的全栈博主,帮助过数万人编程小白从零基础到学有所成!
- 专栏案例有哪些? 《最新爬虫实战教程》专栏案例包括:入门爬虫、多线程爬虫、分布式爬虫、自动化框架爬虫、验证码识别、反爬虫技术、逆向爬虫、粉丝定制爬虫网站等,专栏地址:https://blog.csdn.net/yuan2019035055/category_13105524.html
- 专栏优点? 本专栏与其他劣质专栏的区别在于:详细爬虫思路截图+抓包过程动图演示+完整爬虫代码+详细代码注释,专栏案例由浅入深,逐渐增加难度,适合零基础和进阶提升的同学。并且订阅之后可以定制案例!
- 文章是永久吗? 一次订阅后,专栏内的所有文章可以永久免费看,还会持续更新,保底100篇文章。
- 有答疑交流群吗? 订阅专栏后有专属的 爬虫答疑群,群里有很多大佬可以抱团取暖, 加入我们一起学习进步,一个人可以走的很快,一群人才能走的更远!
- 进群方式呢? 订阅专栏后私信博主,或者 自行添加博主:https://bbs.csdn.net/topics/613263041
- 没有Python基础怎么办? 可以先订阅博主的《100天精通Python》专栏 ,适合Python零基础和需要进阶的小伙伴,专栏地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
【原创声明】
除本文原文地址以外,如发现同款内容皆为盗版,本文已收录于《最新爬虫实战教程》 ,请勿购买盗版文章和专栏,如购买盗版内容不提供任何服务。原文地址:https://blog.csdn.net/yuan2019035055/article/details/157945393