㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~
㊙️本期爬虫难度指数:⭐⭐⭐
🉐福利: 一次订阅后,专栏内的所有文章可永久免费看,持续更新中,保底1000+(篇)硬核实战内容。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract) 📝](#1️⃣ 摘要(Abstract) 📝)
- [2️⃣ 背景与需求(Why)🔍](#2️⃣ 背景与需求(Why)🔍)
- [3️⃣ 合规与注意事项(必写)🛡️](#3️⃣ 合规与注意事项(必写)🛡️)
- [4️⃣ 技术选型与整体流程(What/How)🎨](#4️⃣ 技术选型与整体流程(What/How)🎨)
- [5️⃣ 环境准备与依赖安装(可复现)📦](#5️⃣ 环境准备与依赖安装(可复现)📦)
- [6️⃣ 核心实现:HTML 模板设计 (The Template) 📝](#6️⃣ 核心实现:HTML 模板设计 (The Template) 📝)
- [7️⃣ 核心实现:采样与渲染逻辑 (The Generator) 📡](#7️⃣ 核心实现:采样与渲染逻辑 (The Generator) 📡)
- [8️⃣ 关键代码解析(Expert Analysis)🧐](#8️⃣ 关键代码解析(Expert Analysis)🧐)
- [9️⃣ 结果展示与验收技巧 🖥️](#9️⃣ 结果展示与验收技巧 🖥️)
- [🔟 进阶优化:更硬核的质量指标 🚀](#🔟 进阶优化:更硬核的质量指标 🚀)
- [1️⃣1️⃣ 总结与延伸阅读 📝](#1️⃣1️⃣ 总结与延伸阅读 📝)
- [🌟 文末](#🌟 文末)
-
- [✅ 专栏持续更新中|建议收藏 + 订阅](#✅ 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
- [✅ 免责声明](#✅ 免责声明)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅专栏👉《Python爬虫实战》👈,一次订阅后,专栏内的所有文章可永久免费阅读,持续更新中。
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract) 📝
本文将引入 QA(Quality Assurance) 流程,利用 Jinja2 模板引擎将抓取到的结构化数据(SQLite/CSV)反向渲染为可读性极强的 HTML 网页报告。
读完你将获得:
- 掌握 Python 自动化生成 HTML 报告的核心技术(无需前端基础)。
- 学会"随机分层抽样"逻辑,确保验收样本的代表性。
- 拥有一套标准化的爬虫交付物,显著提升项目的专业度。
2️⃣ 背景与需求(Why)🔍
为什么要搞抽样验收?
- 肉眼可见的错误: 数据库里的
或乱码在 HTML 界面上一眼就能看出来。 - 字段对齐检查: 确保"标题"里抓到的是书名,而不是"价格"或"分类"。
- 沟通成本: 给老板看一个
books.db文件,不如发一个report.html链接。
验收标准:
- 随机性: 不能只看前 50 条,必须覆盖不同类目。
- 直观性: 必须包含图片预览、点击链接、以及高亮显示的数值。
3️⃣ 合规与注意事项(必写)🛡️
- 敏感信息脱敏: 如果抓取的是个人隐私数据(如手机号),在生成报告时必须进行掩码处理(如
138****5678)。 - 静态资源引用: 报告中的图片建议引用原始 URL。如果担心原始图片失效,可以使用 Base64 嵌入(但会增加报告文件体积)。
- 仅限内部使用: 验收报告仅用于内部质量审查,严禁将其作为产品公开展示,以防侵权风险。
4️⃣ 技术选型与整体流程(What/How)🎨
技术栈:
- 数据源:
sqlite3(从我们之前的数据库取数) - 模板引擎:
Jinja2(Python 最流行的 HTML 渲染器,类 Flask 语法) - 样式:
Bootstrap 5(通过 CDN 引入,让报告秒变高大上)
**流程图tstrap 5` (通过 CDN 引入,让报告秒变高大上)
流程图:
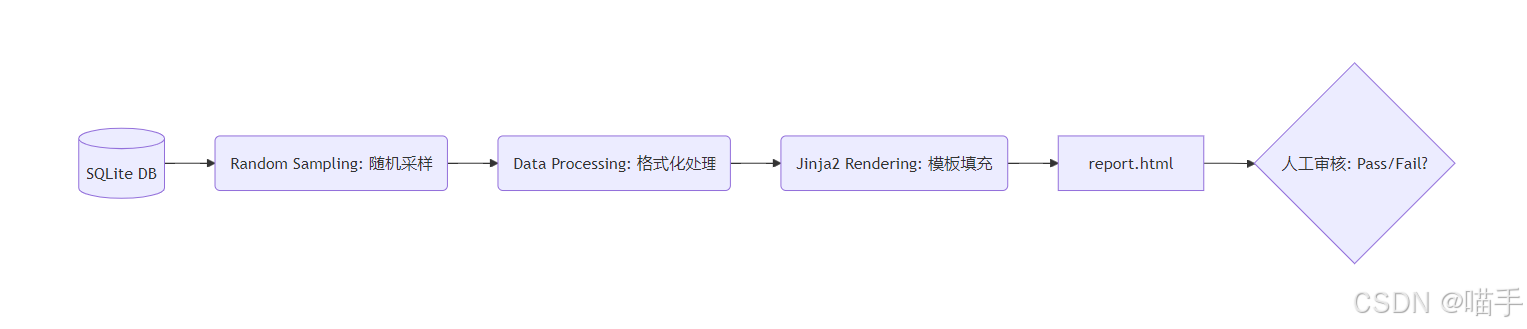
5️⃣ 环境准备与依赖安装(可复现)📦
bash
pip install jinja2项目目录建议:
text
qa_system/
├── templates/
│ └── report_template.html # HTML 骨架
├── generator.py # 生成逻辑
└── books.db # 爬虫产出的数据库6️⃣ 核心实现:HTML 模板设计 (The Template) 📝
在 `templates/report_template.html中编写。我们使用 Bootstrap 的表格和卡片样式。
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>爬虫数据验收报告 (Sampling)</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css" rel="stylesheet">
<style>
.book-img { width: 60px; height: 80px; object-fit: cover; border-radius: 4px; }
.rating-star { color: #ffc107; }
.status-pass { color: #198754; font-weight: bold; }
</style>
</head>
<body class="bg-light">
<div class="container py-5">
<div class="d-flex justify-content-between align-items-center mb-4">
<h1>📊 数据采集质量验收报告</h1>
<span class="badge bg-secondary">生成时间: {{ timestamp }}</span>
</div>
<div class="row mb-4">
<div class="col-md-4">
<div class="card text-white bg-primary mb-3">
<div class="card-body">
<h5 class="card-title">总样本数</h5>
<p class="card-text fs-2">{{ total_samples }}</p>
</div>
</div>
</div>
</div>
<table class="table table-hover bg-white shadow-sm">
<thead class="table-dark">
<tr>
<th>ID</th>
<th>书籍名称</th>
<th>价格</th>
<th>评分</th>
<th>类目</th>
<th>详情页</th>
</tr>
</thead>
<tbody>
{% for book in books %}
<tr>
<td>{{ book.id }}</td>
<td><strong>{{ book.title }}</strong></td>
<td><span class="text-danger">£{{ book.price }}</span></td>
<td class="rating-star">{{ "★" * book.rating }}</td>
<td><span class="badge bg-info text-dark">{{ book.category }}</span></td>
<td><a href="{{ book.link }}" target="_blank" class="btn btn-sm btn-outline-primary">直达链接</a></td>
</tr>
{% endfor %}
</tbody>
</table>
<div class="alert alert-info mt-4">
<strong>验收说明:</strong> 请检查上述随机抽取的 50 条数据。若发现书名截断、价格为 0 或评分异常,请打回重爬。
</div>
</div>
</body>
</html>7️⃣ 核心实现:采样与渲染逻辑 (The Generator) 📡
python
import sqlite3
import datetime
from jinja2 import Environment, FileSystemLoader
def get_random_samples(db_path, limit=50):
"""从数据库随机抽取样本"""
conn = sqlite3.connect(db_path)
# 使用 row_factory 让结果以字典形式返回,方便模板调用
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
# 使用 SQL 的 RANDOM() 函数进行随机采样
query = f"SELECT * FROM books ORDER BY RANDOM() LIMIT {limit}"
cursor.execute(query)
samples = cursor.fetchall()
conn.close()
return samples
def generate_report(samples):
"""使用 Jinja2 渲染 HTML"""
# 1. 设置模板环境
env = Environment(loader=FileSystemLoader('templates'))
template = env.get_template('report_template.html')
# 2. 准备渲染数据
render_data = {
"books": samples,
"total_samples": len(samples),
"timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
# 3. 执行渲染并保存文件
output_html = template.render(render_data)
filename = "Sample_Validation_Report.html"
with open(filename, "w", encoding="utf-8") as f:
f.write(output_html)
return filename
if __name__ == "__main__":
# 假设你已经有了 books.db
try:
data = get_random_samples("books.db")
report_file = generate_report(data)
print(f"🎉 验收报告已生成: {report_file}")
except Exception as e:
print(f"❌ 生成报告失败: {e}")8️⃣ 关键代码解析(Expert Analysis)🧐
- SQL
ORDER RANDOM():
这是 SQLite(以及大多数 SQL 数据库)中进行随机采样的最简便方法。它确保了我们的验收报告不是每次都看那几本书。 conn.row_factory = sqlite3.Row:
这是一个专家级小技巧。默认情况下,cursor.fetchall()返回的是元组列表(1, 'Title', ...)。设置Row后,它返回类似字典的对象,你在 HTML 模板中就可以直接用{``{ book.title }}而不是{``{ book[1] }},极大增强了代码可读性。
3*Jinja2 过滤器与逻辑:**
我们在模板中使用了{``{ "★" * book.rating }},这直接利用了 Python 字符串乘法的特性,将数字评分转为了直观的星星图标,非常优雅。
9️⃣ 结果展示与验收技巧 🖥️
生成的 Sample_Validation_Report.html 在浏览器打开后:
- 视觉自检: 检查标题是否有奇怪的特殊字符。
- 逻辑检查: 点击"直达链接",看跳转的网页是否真的对应那个书名。
- 数据一致性: 观察 50 条里是否有价格为空的情况,如果有,说明
Clean节点的容错逻辑还需要优化。
🔟 进阶优化:更硬核的质量指标 🚀
如果你想让这份报告更"唬人"(更有专业水准):
- 数据分布图表: 使用
Chart.js在 HTML 头部画一个简单的饼图,显示各分类书籍的占比,或者价格分布的直方图。 - 空值率统计: 在报告顶部增加一个"健康概览",显示:
字段完整率: 99.8%。 - 异常高亮: 在 Jinja2 模板中加一个
if判断:如果book.price > 100,就把这一行背景标红,提醒注意高价异常值。
1️⃣1️⃣ 总结与延伸阅读 📝
复盘:
通过本环节,我们为爬虫流水线装上了"眼睛"。自动化采集虽好,但人机协作的"验收"环节才是确保数据商业价值的关键。
- 自动化: 采集、清洗、存储。
- 可视化: 验收、复核、交付。
下一步:
既然你已经能生成 HTML 报告了,不如考虑配合 smtplib,在爬虫跑完后自动将这份报告作为附件发送到你的邮箱。
这一套流程下来,从 Discover 到 Report ,你已经构建了一个闭环的企业级爬虫系统!恭喜你,Python 专家!🐍💪✨
🌟 文末
好啦~以上就是本期的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
✅ 专栏持续更新中|建议收藏 + 订阅
墙裂推荐订阅专栏 👉 《Python爬虫实战》,本专栏秉承着以"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一期内容都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴 :强烈建议先订阅专栏 《Python爬虫实战》,再按目录大纲顺序学习,效率十倍上升~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】等写成某期实战?
评论区留言告诉我你的需求,我会优先安排实现(更新)哒~
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
✅ 免责声明
本文爬虫思路、相关技术和代码仅用于学习参考,对阅读本文后的进行爬虫行为的用户本作者不承担任何法律责任。
使用或者参考本项目即表示您已阅读并同意以下条款:
- 合法使用: 不得将本项目用于任何违法、违规或侵犯他人权益的行为,包括但不限于网络攻击、诈骗、绕过身份验证、未经授权的数据抓取等。
- 风险自负: 任何因使用本项目而产生的法律责任、技术风险或经济损失,由使用者自行承担,项目作者不承担任何形式的责任。
- 禁止滥用: 不得将本项目用于违法牟利、黑产活动或其他不当商业用途。
- 使用或者参考本项目即视为同意上述条款,即 "谁使用,谁负责" 。如不同意,请立即停止使用并删除本项目。!!!
