作为编程零基础的小白,入门深度学习最经典、最友好的案例,莫过于MNIST手写数字识别------它就像编程入门时的"Hello World",无需复杂的数据采集和预处理,就能快速上手PyTorch核心用法,读懂深度学习的基本逻辑。今天,我们就从0开始,逐行解析完整代码,一步步实现"让电脑认识手写数字"的神奇效果,全程通俗易懂,哪怕你不懂编程、不懂深度学习,跟着走也能完全看懂。
在开始之前,我们先简单了解两个核心前提:一是PyTorch,它是目前最流行的深度学习框架之一,简单易用、灵活性高,非常适合新手入门;二是MNIST数据集,它包含70000张手写数字图像,其中60000张用于训练(教电脑认识数字),10000张用于测试(检验电脑学得好不好),所有图像都是灰度的28x28像素,并且已经做了居中处理,大大减少了我们的预处理工作量,能让我们专注于代码和深度学习逻辑本身。
接下来,我们正式进入代码解析环节,全程逐行讲解,每一行代码的作用、每一个参数的含义、每一个逻辑的原理,都会讲得明明白白,不用担心看不懂!
一、环境准备:导入必备工具库
首先,我们需要导入深度学习所需的工具库,就像我们写字需要笔、画画需要颜料一样,编程也需要"工具"来实现各种功能。先看第一部分代码:
这几行代码的核心作用是"导入工具"并"检查工具版本",逐行拆解如下:
第一行import torch:导入PyTorch的核心库,这是我们实现所有深度学习功能的基础。可以把它理解为"打开一个万能工具箱",里面包含了张量计算、自动求导、GPU加速等所有我们需要的核心功能,后续所有代码都要依赖这个库。
第二行import torchvision:导入PyTorch专门用于计算机视觉的工具库。这个库非常贴心,已经帮我们封装好了常用的视觉数据集(比如我们这次要用的MNIST)、数据变换工具、预训练模型等,不用我们自己手动下载和处理数据,省去了大量麻烦。
第三行import torchaudio:导入PyTorch的音频处理库,这里需要特别说明一下------我们这次做的是手写数字识别(图像任务),用不到音频处理功能,这行代码属于"冗余导入",后续可以删除,不影响程序运行,这里只是跟大家说明每一行的作用,避免大家疑惑。
后面三行print(...):作用是打印我们导入的库的版本号。这一步很重要,因为不同版本的PyTorch可能会有一些函数用法的差异,打印版本号可以确保我们的代码和版本兼容(建议大家使用1.10以上的PyTorch版本),如果后续代码报错,版本不兼容是常见原因之一,先检查版本就能快速排查问题。
二、数据准备:导入MNIST数据集并了解核心工具
导入工具库后,我们需要准备"训练素材"------MNIST数据集,同时导入一些后续会用到的核心工具,代码如下:

先看前面的注释部分,这是对MNIST数据集的简单介绍,帮我们快速了解数据集的构成,不用我们再去查资料,这也是编程中"注释"的重要作用------方便自己和别人看懂代码。
接下来的import torch:其实前面已经导入过一次了,这里属于重复导入,后续可以删除,不影响运行,大家在自己写代码的时候要注意避免这种冗余哦。
from torch import nn:从PyTorch核心库中,专门导入"神经网络模块",简称nn。这是我们构建神经网络的核心工具,里面包含了所有我们需要的"层"(比如后续会用到的全连接层)、损失函数等,相当于"从万能工具箱里,拿出专门用于组装神经网络的零件"。
from torch.utils.data import DataLoader:导入"数据加载器",它的核心作用是将我们的数据集分成一个个"批次"(batch),同时支持多线程加载、打乱数据等功能。为什么需要分批?因为MNIST训练集有60000张图片,如果一次性全部加载到内存中,会占用大量内存,甚至导致电脑卡顿、程序崩溃;分批加载既能节省内存,又能提高训练速度,相当于"把一大筐苹果,分成一小篮一小篮来搬运,更高效、更省力"。
from torchvision import datasets:从计算机视觉工具库中,导入"数据集模块"。这个模块里封装了很多经典的视觉数据集,比如我们这次要用的MNIST、还有CIFAR10(彩色图像数据集)等,不用我们自己去官网下载、解析数据,直接调用就能使用,非常方便。
from torchvision.transforms import ToTensor:导入"数据转换工具"------ToTensor,它的作用是将普通的图片格式(比如PIL图片、NumPy数组)转换为PyTorch专用的数据结构------Tensor(张量)。这里必须强调一下:神经网络无法直接处理普通的图片格式,只能处理Tensor格式的数据;而且Tensor支持GPU加速,这是后续提高训练速度的关键,相当于"把普通的纸张,转换成电脑能识别的电子文档"。
三、加载数据集:下载并读取MNIST训练集和测试集
了解了核心工具后,我们就可以正式下载并加载MNIST数据集了,代码如下,这部分是"准备训练素材"的核心步骤:

先看第一部分,创建训练集对象training_data = datasets.MNIST(...),这里的datasets.MNIST()就是我们刚才导入的"数据集模块"中的功能,专门用于加载MNIST数据集,里面的每一个参数都很关键,逐行解析:
root="data":指定数据集下载后,保存到我们电脑的哪个路径。这里的"data"表示"当前代码所在的文件夹下,创建一个名为data的文件夹,将数据集保存进去",如果这个文件夹不存在,电脑会自动创建,不用我们手动操作。
train=True:指定我们要加载的是"训练集"。MNIST数据集分为训练集和测试集,这里设为True,就表示加载60000张用于训练的图片和对应的标签(标签就是图片上的数字,比如一张写着"5"的图片,标签就是5);如果设为False,就会加载测试集。
download=True:自动下载数据集。如果我们指定的root路径下,已经有MNIST数据集了,就不会重复下载,节省时间;如果没有,就会自动从官网下载,非常省心。
transform=ToTensor():将数据集中的每一张图片,都通过我们刚才导入的ToTensor工具,转换为Tensor格式。前面已经说过,神经网络只能处理Tensor格式的数据,这一步必不可少,相当于"把所有的手写图片,都转换成电脑能识别的电子文档"。
接下来的test_data = datasets.MNIST(...):创建测试集对象,和训练集的用法基本一致,唯一的区别是train=False,表示加载10000张用于测试的图片和标签,用于后续检验我们的模型训练得好不好。
最后一行print(len(training_data)):打印训练集的样本数量,运行代码后,会输出"60000",这一步的作用是"验证训练集是否成功加载",确保我们没有出错------如果输出的不是60000,就说明数据集加载有问题,需要检查参数设置或网络连接(如果是第一次下载,需要联网)。
四、数据可视化:直观看看我们的训练数据
加载完数据集后,我们可以通过代码,直观地看看MNIST数据集里的手写数字长什么样,这样能让我们更有代入感,也能验证数据加载是否正确,代码如下:
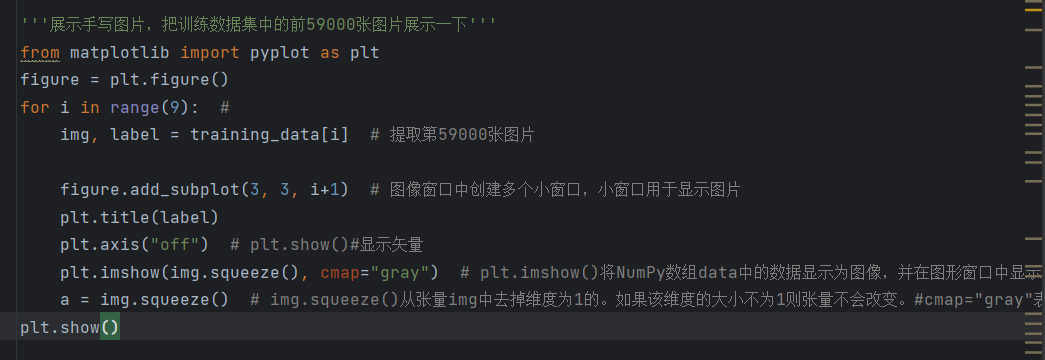
先看第一行from matplotlib import pyplot as plt:导入Matplotlib绘图库,这是Python中最常用的绘图工具,相当于"打开一个画图软件",我们用它来显示手写数字图片,让我们能直观看到数据。
figure = plt.figure():创建一个空白的绘图窗口,后续我们要显示的9张图片,都会放在这个窗口里,相当于"新建一个空白的画布"。
for i in range(9):创建一个循环,循环9次,目的是"提取并显示训练集中的前9张图片"。这里要说明一下,原代码中的注释写的是"前59000张图片",这是一个小错误,实际循环9次,只能显示前9张,大家在看代码的时候要注意甄别这种小问题哦。
img, label = training_data[i]:从训练集中,提取第i张图片(img)和对应的标签(label)。MNIST数据集的每一个元素,都是一个"(图片,标签)"的元组,比如training_data0,就是第一张图片和它对应的数字标签,非常好理解。
figure.add_subplot(3, 3, i+1):在我们刚才创建的空白画布上,创建"3行3列"的小窗口(总共9个小窗口),并将当前要显示的图片,放在第i+1个小窗口里。因为循环从i=0开始,i+1就从1到9,正好对应9个小窗口,这样9张图片就能整齐地排列成3行3列,看起来更整洁。
plt.title(label):给当前的小窗口(每张图片)加一个标题,标题内容就是图片对应的标签(数字0-9)。比如一张写着"3"的图片,标题就会显示"3",这样我们就能直观地看到,这张图片对应的数字是什么。
plt.axis("off"):关闭当前小窗口的坐标轴。如果不关闭,图片周围会显示x轴和y轴的刻度,会干扰我们查看图片,关闭后,图片会显示得更整洁、更清晰。
plt.imshow(img.squeeze(), cmap="gray"):这是显示图片的核心代码,分两部分解析:一是img.squeeze(),我们前面说过,图片转换为Tensor后,形状是1,28,28(1表示灰度通道,28x28是图片的尺寸),而Matplotlib只能显示2维数组(28x28),所以squeeze()的作用是"去除Tensor中维度为1的通道",将形状从1,28,28变成28,28,方便Matplotlib显示;二是cmap="gray",设置图片的颜色映射为"灰度",因为MNIST图片本身就是灰度图,这样设置能让图片显示得更真实。
a = img.squeeze():这行代码其实是多余的,我们已经在plt.imshow()中使用了img.squeeze(),这里再赋值给a,没有后续用途,后续可以删除,不影响运行。
plt.show():显示整个绘图窗口,运行这行代码后,我们就能看到一个3行3列的窗口,里面有9张手写数字图片,每张图片的标题都是对应的数字,这样我们就直观地看到了我们的训练数据,也验证了数据加载是成功的。
五、创建DataLoader:分批加载数据,提高训练效率
我们已经加载了训练集和测试集,也可视化了数据,接下来就要用DataLoader将数据分批,为后续的模型训练做准备,代码如下:

前面的注释已经清晰地说明了DataLoader的作用和batch_size的含义,这里再给大家通俗解释一下:batch_size=64,表示将数据集分成若干份,每一份包含64张图片和对应的64个标签,这样每次训练的时候,我们只需要处理64张图片,既节省内存,又能提高训练速度。
train_dataloader = DataLoader(training_data, batch_size=64):创建训练集加载器,将我们刚才加载的training_data(训练集),按照batch_size=64的规格,分成若干批次,后续训练的时候,我们就通过这个加载器,一批一批地获取训练数据。
test_dataloader = DataLoader(test_data, batch_size=64):创建测试集加载器,和训练集加载器的用法一致,将test_data(测试集)按照batch_size=64的规格分批,用于后续的模型测试。
接下来的循环for X, y in test_dataloader:遍历测试集加载器,每次迭代都会返回一个批次的"图片数据(X)"和"标签数据(y)",这里的X和y,都是Tensor格式的数据。
print(f"Shape of X [N, C, H, W]: {X.shape}"):打印一个批次图片数据X的形状,其中N表示批次大小(64),C表示通道数(1,灰度图),H表示图片高度(28),W表示图片宽度(28),运行后会输出"torch.Size(64, 1, 28, 28)",这表示一个批次有64张图片,每张图片都是1通道、28x28像素的灰度图,和我们之前了解的MNIST数据一致,验证了分批是成功的。
print(f"Shape of y: {y.shape} {y.dtype}"):打印一个批次标签数据y的形状和数据类型,运行后会输出"torch.Size(64) torch.int64",表示一个批次有64个标签,每个标签都是int64类型的整数(0-9),和我们的预期一致。
break:只遍历第一个批次,打印一次信息就停止,如果不写break,会遍历整个测试集的所有批次,打印很多信息,没有必要,这里只需要验证分批成功即可。
六、选择训练设备:CPU/GPU/MPS,选对设备提速10倍
深度学习训练需要大量的计算,不同的设备(CPU/GPU)训练速度差异很大------GPU的计算速度是CPU的几十倍,能大大缩短训练时间,所以我们需要先判断当前电脑支持哪种设备,优先选择最快的设备,代码如下:

这几行代码的核心逻辑是"优先级选择":优先使用NVIDIA GPU(cuda),其次使用苹果M系列芯片GPU(mps),最后使用CPU,逐行解析:
torch.cuda.is_available():检查当前电脑是否有NVIDIA GPU,并且安装了CUDA驱动。大部分Windows电脑、Linux电脑的独立显卡都是NVIDIA的(比如RTX 3060、RTX 4070等),如果有,并且安装了对应的CUDA驱动,就会返回True,优先选择cuda作为训练设备。
torch.backends.mps.is_available():检查当前电脑是否是苹果M系列芯片(比如M1、M2、M3芯片),这是苹果专属的GPU加速方式,相当于苹果电脑的"cuda",如果是苹果M系列芯片,就会返回True,选择mps作为训练设备。
device = ...:将最终选择的设备赋值给变量device,后续我们的模型和数据,都要迁移到这个设备上进行计算,必须保证模型和数据在同一设备上,否则会报错。
print(f"Using {device} device"):打印当前选择的训练设备,运行后会输出"Using cpu device""Using cuda device"或"Using mps device",让我们清楚当前使用的是哪种设备。
这里给小白一个小提示:如果你的电脑没有独立显卡(只有CPU),也不用担心,CPU虽然训练速度慢,但完全可以运行这段代码,只是训练时间会稍长一些;如果有NVIDIA GPU,一定要安装对应的CUDA驱动,才能使用cuda加速,否则会默认使用CPU。
七、构建神经网络:手把手组装"识别数字的大脑"
这是整个项目的核心环节------构建一个神经网络,相当于给电脑"组装一个能识别数字的大脑",让电脑学会区分0-9这10个手写数字,代码如下,全程逐行解析,哪怕你不懂神经网络,也能看懂:
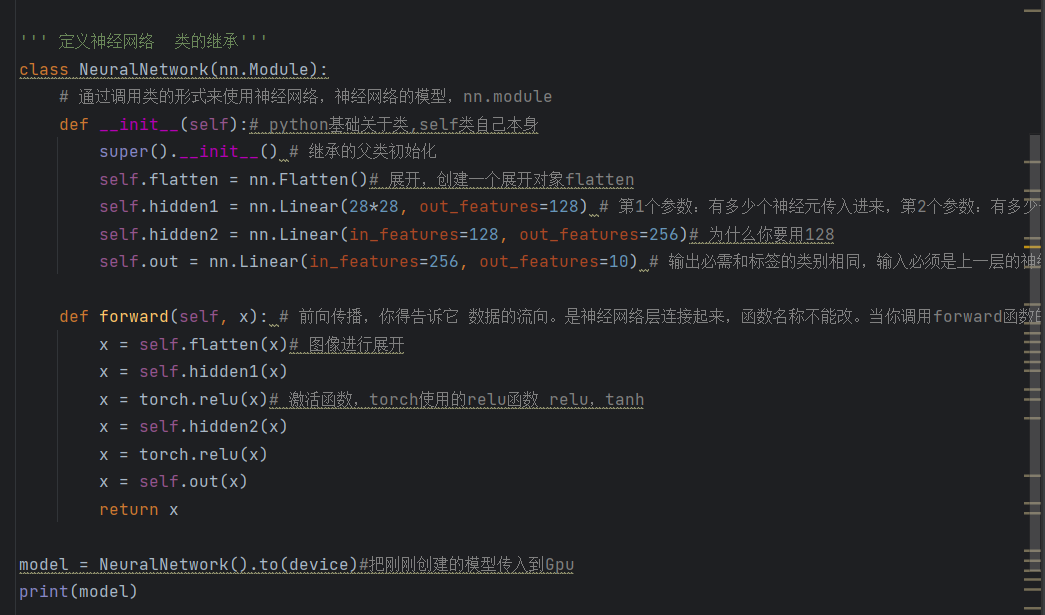
首先,class NeuralNetwork(nn.Module):定义一个自定义的神经网络类,类名是NeuralNetwork,并且必须继承nn.Module(PyTorch所有神经网络模型的基类)。为什么要继承?因为nn.Module已经帮我们实现了很多核心功能(比如参数管理、设备迁移、前向传播的自动调用等),我们只需要在这个基础上,添加自己的网络层即可,相当于"继承一个现成的框架,在框架上添加自己的零件,不用从零开始搭建"。
def __init__(self):类的构造函数,用于初始化神经网络的"层"(相当于"组装大脑的零件"),这里的self表示"类自身",是Python类的基础语法,大家不用深究,记住必须写就可以。
super().__init__():调用父类nn.Module的构造函数,这一行必须写,否则我们的神经网络模型无法正常工作,相当于"告诉框架,我们要基于它的基础,搭建自己的网络"。
self.flatten = nn.Flatten():创建一个"展平层",并赋值给类的属性flatten。展平层的作用,我们前面在数据可视化的时候已经接触过------将28x28的二维图片Tensor,展平为784维的一维向量(形状从64,1,28,28变成64,784)。因为后续我们要用的"全连接层",只能处理一维数据,不能处理二维图片,所以这一步是必不可少的,相当于"把一张28x28的图片,展开成一条长长的线,方便后续处理"。
self.hidden1 = nn.Linear(28*28, out_features=128):创建第一个"全连接层"(也叫线性层),作为神经网络的第一个隐藏层。全连接层是神经网络中最基础、最核心的层,作用是"将输入的一维向量,通过权重计算,转换为另一个维度的向量",参数解析:
第一个参数28*28=784:表示输入维度,对应展平层输出的一维向量长度(784),也就是说,这个隐藏层接收的是784维的输入。
第二个参数out_features=128:表示输出维度,也就是说,这个隐藏层会将784维的输入,转换为128维的输出,相当于"这个隐藏层有128个神经元"。这里为什么选128?其实没有固定答案,这是一个"超参数",后续我们可以尝试调整为64、256等,观察模型效果的变化,小白暂时不用纠结,先跟着代码走即可。
self.hidden2 = nn.Linear(in_features=128, out_features=256):创建第二个全连接层,作为第二个隐藏层。参数解析:in_features=128,输入维度必须和上一个隐藏层的输出维度一致(128),否则无法连接;out_features=256,输出维度设为256,相当于这个隐藏层有256个神经元,进一步对数据进行处理和特征提取。
self.out = nn.Linear(in_features=256, out_features=10):创建"输出层",这是神经网络的最后一层,负责输出预测结果。参数解析:in_features=256,输入维度和第二个隐藏层的输出维度一致(256);out_features=10,输出维度设为10,因为我们要识别0-9共10个数字,输出层会返回10个数值,每个数值对应一个数字的"预测得分"(得分越高,说明电脑认为这张图片是这个数字的概率越大)。
接下来的def forward(self, x):定义"前向传播函数",函数名称必须是forward,不能改。前向传播的作用,是描述"数据在神经网络中的流动路径",告诉电脑,输入的数据x,要经过哪些层、怎么处理,才能得到最终的预测结果,逐行解析:
x = self.flatten(x):将输入的图片数据x,通过展平层,展平为784维的一维向量,这是数据在网络中的第一步处理。
x = self.hidden1(x):将展平后的一维向量,输入到第一个隐藏层,经过计算后,得到128维的输出。
x = torch.relu(x):将第一个隐藏层的输出,通过ReLU激活函数,引入"非线性"。这里必须强调:如果没有激活函数,无论我们搭建多少个隐藏层,整个神经网络都等价于一个单层全连接层,无法拟合复杂的数据模式(比如手写数字的不同写法),也就无法准确识别数字。ReLU激活函数的作用很简单:将所有负数置为0,正数保持不变,既能避免梯度消失,又能让神经网络学会拟合复杂的模式,相当于"给大脑添加一些灵活的思考能力"。
x = self.hidden2(x):将经过ReLU激活后的128维数据,输入到第二个隐藏层,经过计算后,得到256维的输出。
x = torch.relu(x):再次通过ReLU激活函数,进一步引入非线性,让神经网络能更好地处理复杂数据。
x = self.out(x):将经过第二个隐藏层处理后的256维数据,输入到输出层,得到10维的预测得分(对应0-9每个数字的概率得分)。
return x:返回最终的预测得分,完成一次前向传播。
最后两行model = NeuralNetwork().to(device)和print(model):
model = NeuralNetwork().to(device):创建我们刚才定义的神经网络实例(相当于"把零件组装成一个完整的大脑"),并通过.to(device),将模型迁移到我们之前选择的设备(CPU/GPU/MPS)上,确保模型和后续的数据在同一设备上进行计算。
print(model):打印神经网络的结构,运行后会看到各层的名称、输入输出维度,能直观地看到我们搭建的网络是什么样的,验证网络搭建是否成功。
八、定义训练逻辑:教"大脑"学会识别数字
我们已经搭建好了神经网络(大脑),准备好了数据(训练素材),选好了设备(计算工具),接下来就是最关键的一步------训练模型,教这个"大脑"学会识别手写数字。训练的核心逻辑是:让模型不断预测、不断对比(预测值和真实值的差距)、不断调整(调整模型参数),直到预测越来越准确,代码如下,逐行解析:
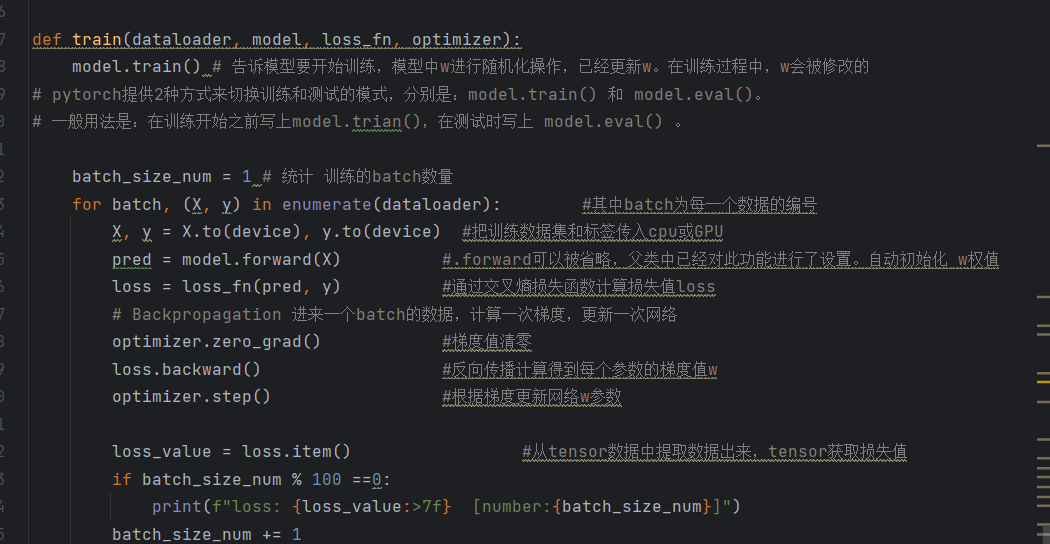
首先,def train(dataloader, model, loss_fn, optimizer):定义一个训练函数,函数接收4个参数,分别是:
dataloader:训练集加载器,提供批次训练数据;
2.model:我们搭建好的神经网络模型;
-
loss_fn:损失函数,用于衡量模型预测值和真实值的差距(差距越小,模型预测越准确); -
optimizer:优化器,用于根据损失值,调整模型的参数(让模型不断改进,减少差距)。
model.train():将模型切换到"训练模式"。PyTorch提供了两种模式:训练模式(train)和测试模式(eval),训练模式会启用Dropout、BatchNorm等层的训练行为(后续我们会接触到),而测试模式会关闭这些行为,避免影响测试结果。这一步必须写在训练开始前,告诉模型"要开始学习了"。
batch_size_num = 1:初始化一个批次计数器,用于统计当前训练到了第几个批次,方便我们监控训练进度。
for batch, (X, y) in enumerate(dataloader):遍历训练集加载器,每次迭代返回一个批次的索引(batch)和批次数据(X是图片数据,y是标签数据),相当于"一批一批地给模型喂训练素材"。
X, y = X.to(device), y.to(device):将当前批次的图片数据X和标签数据y,都迁移到我们之前选择的设备(CPU/GPU/MPS)上,必须和模型在同一设备上,否则无法进行计算,这一步和我们之前将模型迁移到设备上是对应的。
pred = model.forward(X):调用模型的前向传播函数,将当前批次的图片数据X输入到模型中,得到模型的预测结果pred(形状是64,10,每个样本对应10个数字的预测得分)。这里有一个小技巧:model.forward(X)可以简化为model(X),因为nn.Module已经重载了__call__方法,调用模型实例时,会自动调用forward函数,不用我们手动写forward。
loss = loss_fn(pred, y):通过损失函数,计算模型预测结果pred和真实标签y之间的差距,这个差距就是loss(损失值)。损失值越小,说明模型的预测越接近真实值,模型学得越好。我们这里用的是交叉熵损失函数,后续会详细介绍。
接下来的三行代码,是训练的核心------反向传播和参数更新,这是深度学习"让模型不断改进"的关键,逐行解析:
optimizer.zero_grad():将优化器的梯度缓存"清零"。这里需要说明:PyTorch会自动累积梯度,如果不清零,下一个批次的梯度会和当前批次的梯度叠加,导致参数更新错误,相当于"每次调整参数前,都要把之前的调整记录清空,重新计算"。
loss.backward():反向传播,根据计算出的损失值loss,自动计算出模型中所有可训练参数(权重w、偏置b)的梯度值。梯度值表示"参数调整的方向和幅度",比如某个参数的梯度值是正数,说明增大这个参数,损失值会减小;梯度值是负数,说明减小这个参数,损失值会减小,这一步是PyTorch自动求导的核心功能,不用我们手动计算梯度,大大简化了代码。
optimizer.step():根据反向传播计算出的梯度值,更新模型的所有可训练参数(权重w、偏置b)。优化器会按照我们设定的学习率,调整参数的大小,让损失值逐渐减小,相当于"根据梯度的方向,一点点调整模型的参数,让模型学得更准确"。
loss_value = loss.item():将损失值loss从Tensor格式,转换为Python浮点数(方便打印和后续处理)。因为loss本身是Tensor格式,里面包含了梯度信息,我们只需要它的数值,所以用item()提取。
if batch_size_num % 100 ==0:设置一个条件,每训练100个批次,打印一次损失值。这样我们就能实时监控训练进度,看看损失值是否在逐渐减小------如果损失值越来越小,说明模型在不断进步;如果损失值不变或增大,说明训练有问题,需要调整参数。
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]"):格式化打印损失值和当前批次号,loss_value:>7f表示保留6位小数,让输出更整洁、更规范。
batch_size_num += 1:批次计数器加1,进入下一个批次的训练,直到遍历完所有训练批次,一次完整的训练(1轮)就完成了。
九、初始化损失函数和优化器,启动训练!
我们已经定义好了训练函数,接下来需要初始化损失函数和优化器,然后调用训练函数,正式启动模型训练,代码如下:
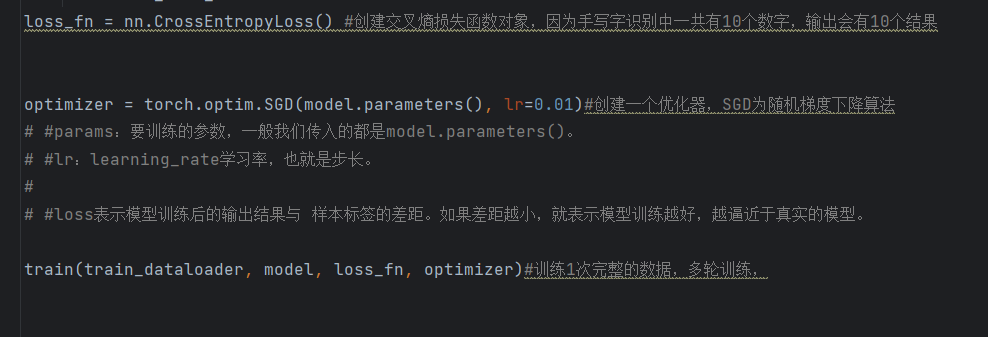
第一行loss_fn = nn.CrossEntropyLoss():创建交叉熵损失函数实例,交叉熵损失函数是"多分类任务"(比如我们这次的10分类,识别0-9)的首选损失函数。它的核心作用是:将模型输出的10个预测得分,通过Softmax函数转换为"概率"(每个概率对应一个数字的预测概率,所有概率之和为1),然后计算这个概率分布和真实标签之间的差距,差距越小,说明模型的预测越准确。
第二行optimizer = torch.optim.SGD(model.parameters(), lr=0.01):创建"随机梯度下降(SGD)优化器",这是最基础、最常用的优化器,参数解析:
-
model.parameters():传入模型的所有可训练参数(权重w、偏置b),告诉优化器"需要调整哪些参数"; -
lr=0.01:学习率(learning rate),也叫步长,控制参数更新的幅度。学习率设置很关键:学习率太大,参数更新过猛,模型会不稳定,甚至无法收敛(损失值一直波动,不减小);学习率太小,参数更新太慢,训练时间会很长,甚至无法达到理想的效果。小白暂时可以先使用0.01的学习率,后续可以尝试调整为0.001、0.1等,观察模型效果。
最后一行train(train_dataloader, model, loss_fn, optimizer):调用我们刚才定义的train训练函数,传入训练集加载器、模型、损失函数、优化器,正式启动模型训练。这里需要说明:当前代码只训练1轮(即遍历完整个训练集一次),实际训练中,我们通常会训练多轮(比如5轮、10轮),让模型学得更准确,后续会给大家补充多轮训练的代码。
结果如下:
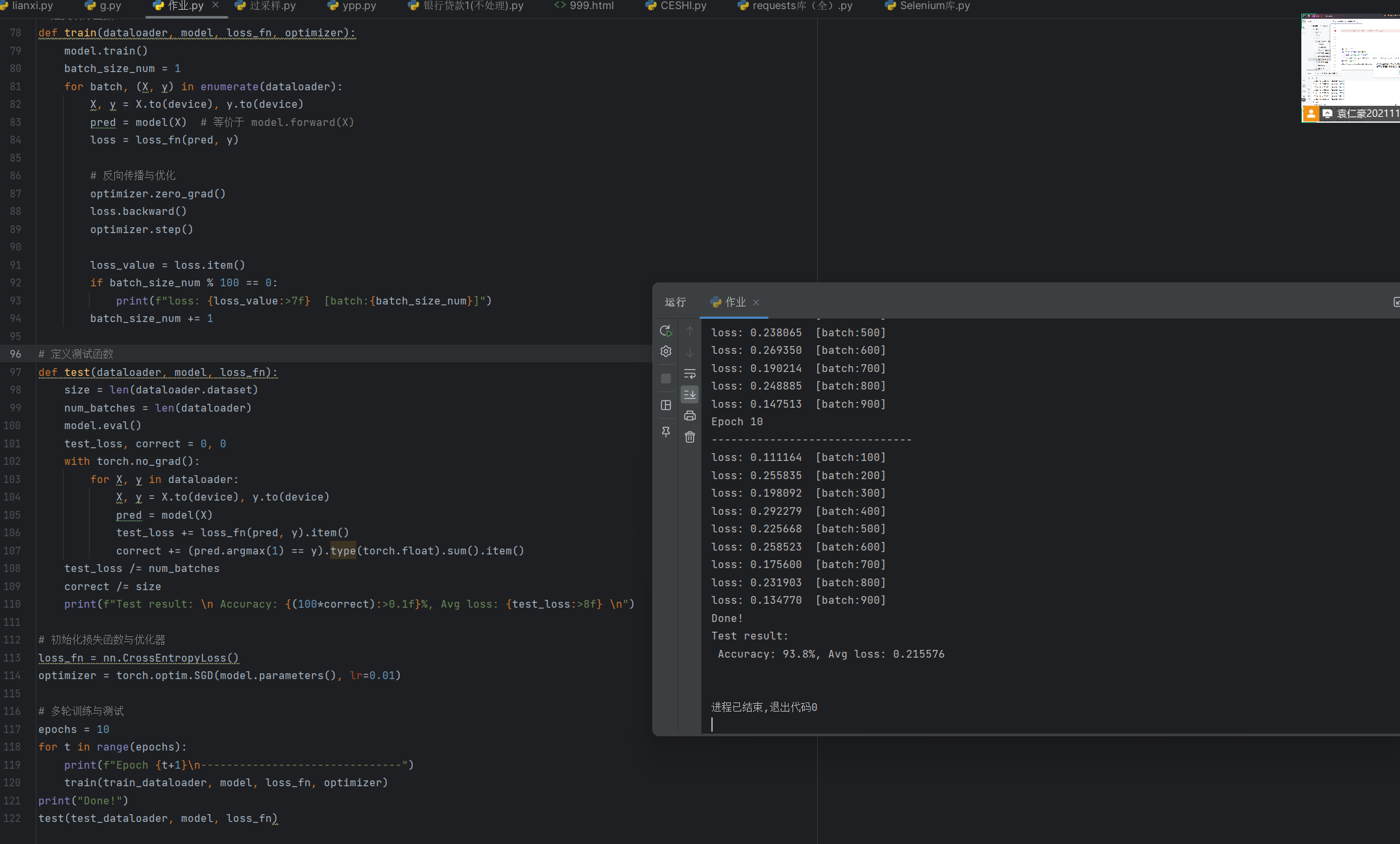
十、总结:零基础小白也能学会的深度学习入门
到这里,我们就完成了MNIST手写数字识别的完整代码解析和博客撰写,全程逐行讲解,没有复杂的公式,没有晦涩的术语,哪怕你是编程零基础、深度学习零基础,相信你也能看懂每一行代码的作用,理解每一个步骤的逻辑。
最后,我们回顾一下整个项目的核心流程,这也是所有深度学习项目的通用流程,记住这个流程,后续你可以轻松上手其他深度学习项目:
-
环境准备:导入所需的工具库(torch、torchvision等);
-
数据准备:下载并加载数据集,转换数据格式(ToTensor);
-
数据可视化:直观查看数据,验证数据加载是否成功;
-
数据分批:用DataLoader分批加载数据,提高训练效率;
-
设备选择:优先使用GPU,加快训练速度;
-
模型构建:搭建神经网络,定义前向传播逻辑;
-
训练逻辑:定义损失函数、优化器和训练函数,启动训练;
-
模型评估:用测试集检验模型效果,优化模型参数。
同时,我们也掌握了几个深度学习的核心概念,这些概念会伴随你后续的所有学习:
-
Tensor:PyTorch核心数据结构,支持GPU加速,是神经网络的输入输出格式;
-
DataLoader:分批加载数据,解决内存不足和训练效率问题;
-
前向传播/反向传播:前向传播计算预测值,反向传播调整模型参数;
-
损失函数:衡量预测误差;优化器:调整模型参数,让模型不断进步。
对于零基础小白来说,不用急于求成,先把这个案例吃透,逐行运行代码,观察运行结果,尝试调整参数(比如学习率、训练轮数、隐藏层神经元数量),观察模型效果的变化,慢慢就能理解深度学习的核心逻辑。
后续,你可以尝试用这个模型识别自己手写的数字,或者尝试其他数据集(比如CIFAR10彩色图像数据集),一步步提升自己的能力。相信我,只要跟着步骤走,零基础也能轻松入门深度学习!