PrefixQuant:基于前缀token消除离群值的大语言模型量化方法
-
- 一、论文概述
- 二、关键背景与相关工作
-
- [1. 量化基础](#1. 量化基础)
- [2. 离群值相关研究](#2. 离群值相关研究)
- 三、PrefixQuant核心设计
-
- [1. 令牌级离群值的特征与定义](#1. 令牌级离群值的特征与定义)
- [2. 核心模块一:前缀离群值隔离(Prefixed Outliers)](#2. 核心模块一:前缀离群值隔离(Prefixed Outliers))
- [3. 核心模块二:块级微调(Block-wise Fine-tuning)](#3. 核心模块二:块级微调(Block-wise Fine-tuning))
- [4. 量化配置对比](#4. 量化配置对比)
- 四、实验设置与结果
-
- [1. 实验配置](#1. 实验配置)
- [2. 核心实验结果](#2. 核心实验结果)
- [3. 消融实验:验证核心模块有效性](#3. 消融实验:验证核心模块有效性)
- 五、优势与局限
-
- [1. 核心优势](#1. 核心优势)
- [2. 主要局限](#2. 主要局限)
- 六、结论
一、论文概述
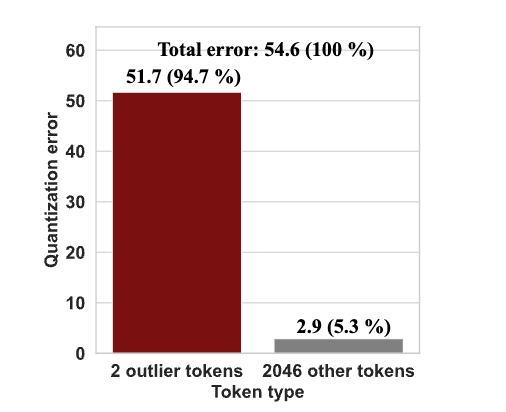
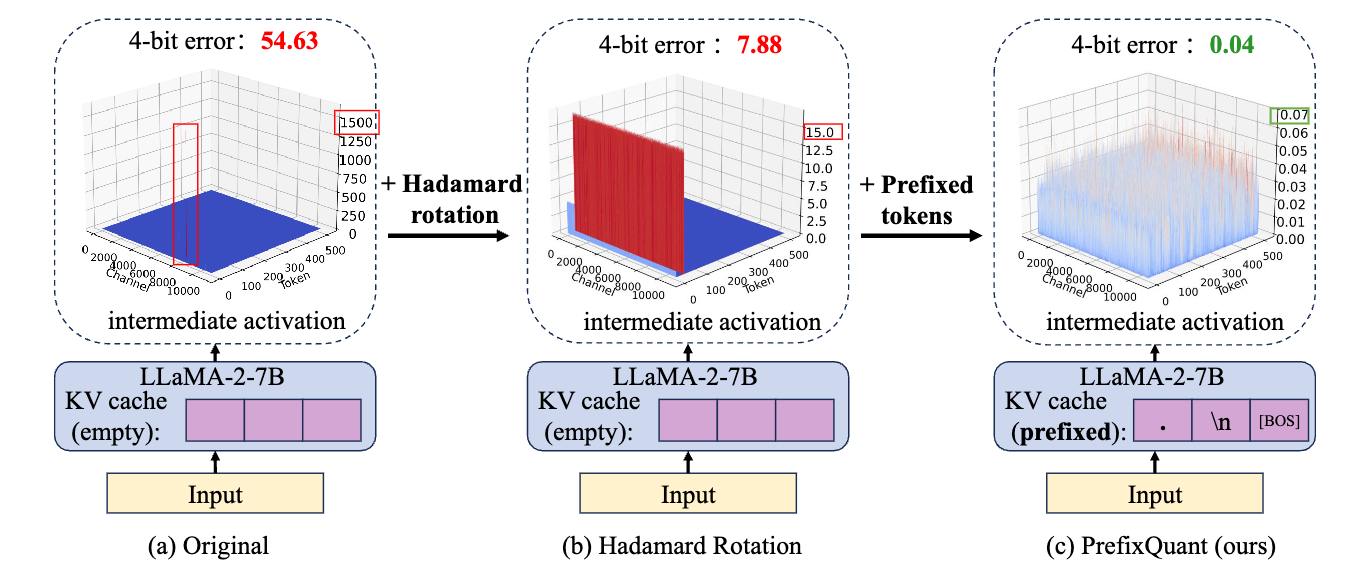
- 核心问题:现有大语言模型(LLMs)权重-激活量化方法多聚焦于通道级离群值(channel-wise outliers),却忽视了令牌级离群值(token-wise outliers),导致量化模型精度受限。例如,2048个令牌中仅2个离群令牌就贡献了94.7%的量化误差,极端值超1000,引发54.63的量化误差。
- 提出方法:PrefixQuant,一种通过在KV缓存中前缀化离群令牌(prefixed tokens)有效隔离令牌级离群值的量化方案,支持动态/静态两种量化粒度(O1/O2配置),兼容W4A4KV4、W4A8KV4等主流精度。
- 核心优势:无需额外训练(前缀令牌检测高效)、精度超现有SOTA方法、推理速度显著提升(预填充2.74×加速、解码2.16×加速)。
- 代码开源:https://github.com/ChenMnZ/PrefixQuant
二、关键背景与相关工作
1. 量化基础
- 量化目的:降低LLMs内存占用、加速推理,核心是将全精度张量(FP16)转换为低比特整数(如4比特),转换公式为:
-
X I N T = c l a m p ( ⌊ X s ⌉ + z , 0 , 2 N − 1 ) \] \[X_{INT}=clamp\\left(\\left\\lfloor\\frac{X}{s}\\right\\rceil+z, 0,2\^{N}-1\\right)\] \[XINT=clamp(⌊sX⌉+z,0,2N−1)
其中, ( s ) (s) (s)(步长)、(z)(零点)为量化参数,( g a m m a gamma gamma)、( b e t a beta beta)为裁剪因子。 - 量化类型:
- 动态量化:推理时在线计算(s)和(z),适应性强但有额外开销;
- 静态量化:离线通过校准数据集预计算(s)和(z),推理效率更高,支持算子融合。
2. 离群值相关研究
| 离群值类型 | 现有解决方法 | 局限性 |
|---|---|---|
| 通道级离群值 | 通道缩放(SmoothQuant)、混合精度量化(Atom)、哈达玛旋转(QuaRot) | 未处理令牌级离群值 |
| 令牌级离群值 | 修改SoftMax行为(Quantizable Transformers)、网格搜索前缀令牌(CushionCache) | 需训练依赖、耗时久(如CushionCache处理Llama-3-8B需12小时) |
PrefixQuant的创新点:正交于通道级方法,无需训练即可隔离令牌级离群值,同时覆盖极大/极小值离群令牌,检测耗时仅12秒-1分钟。
三、PrefixQuant核心设计
1. 令牌级离群值的特征与定义
- 定义 :设令牌序列绝对值张量为 ( X ∈ R T × C ) (X \in \mathbb{R}^{T×C}) (X∈RT×C)((T)为令牌数,(C)为维度),计算每个令牌的最大值 ( M i ) (M_i) (Mi),通过离群度 ( R i = M i m e d i a n ( M ) ) (R_i = \frac{M_i}{median(M)}) (Ri=median(M)Mi)判定:
- 上离群令牌: ( R i > 64 ) (R_i > 64) (Ri>64)(极值远大于中位数);
- 下离群令牌: ( R i − 1 > 8 ) ( (R_i^{-1} > 8)( (Ri−1>8)(极值远小于中位数)。
- 特征 :
- 数量少:仅占输入序列的极小比例(如Llama-2-7B仅2个);
- 位置集中:多分布在序列开头(初始令牌+低语义令牌如
./\n); - 影响大:即使哈达玛旋转将极值从1000+降至15,仍导致7.88的量化误差。
2. 核心模块一:前缀离群值隔离(Prefixed Outliers)
- 核心思路:将高频离群令牌作为前缀添加到输入序列,约束所有离群值仅出现在前缀令牌中,其KV缓存离线预计算后复用,避免推理时生成新离群值。
- 具体步骤 :
- 选择前缀令牌:统计校准数据集的高频离群令牌,结合模型特性确定数量和内容(如Llama-2-7B为
. \n [BOS],Llama-3-8B仅[BOS]),所有模型均以[BOS]收尾; - 预填充KV缓存:用全精度模型一次性计算前缀令牌的K/V矩阵( ( k ′ ∈ R o × C ) (k' \in \mathbb{R}^{o×C}) (k′∈Ro×C)、 ( v ′ ∈ R o × C ) ) (v' \in \mathbb{R}^{o×C})) (v′∈Ro×C)),推理时直接复用,前缀令牌保持全精度;
- 分布优化效果:下投影层输入的
top-1/中位数比值从461降至2.4,Q/K的中位数/min-1比值从>9降至<3.5,量化误差从7.88降至0.04。
- 选择前缀令牌:统计校准数据集的高频离群令牌,结合模型特性确定数量和内容(如Llama-2-7B为
3. 核心模块二:块级微调(Block-wise Fine-tuning)
- 目的:补偿量化误差,通过最小化量化模型与全精度模型的块输出MSE损失实现。
- 可训练参数设计:
- O1(动态量化):将张量级裁剪因子(\gamma)、(\beta)设为可训练(避免令牌级裁剪的存储开销);
- O2(静态量化):直接优化量化参数(s)和(z);
- 权重量化:沿用EfficientQAT方案,训练权重与权重量化参数。
4. 量化配置对比
| 配置项 | PrefixQuant-O1(动态量化) | PrefixQuant-O2(静态量化) |
|---|---|---|
| 权重量化 | 逐通道量化(组大小128) | 逐通道量化(组大小128) |
| 激活量化 | 逐令牌动态计算(s)、(z) | 逐张量离线预计算(s)、(z) |
| KV缓存量化 | 逐组动态量化 | 逐头静态量化 |
| 核心优势 | 精度更高 | 推理速度更快(低延迟) |
四、实验设置与结果
1. 实验配置
- 模型:Llama-2/3、Mistral-v0.3-7B、Qwen-2-7B及指令微调模型(Llama-3-Instruct);
- 基线方法:QuaRot、SpinQuant、Atom、DuQuant、QoQ;
- 评估指标:WikiText2困惑度(PPL)、5项零样本推理任务(PIQA/ARC/HellaSwag/WinoGrande/MMLU)准确率、推理速度(预填充/解码);
- 微调参数:Pile数据集512样本(序列长度1024),W4A8KV4训练10轮、W4A4KV4训练20轮。
2. 核心实验结果
(1)精度性能:全面超越SOTA
| 模型 | 量化精度 | 方法 | PPL | 零样本准确率(Avg.) |
|---|---|---|---|---|
| Llama-3-8B | W4A4KV4 | SpinQuant | 7.36 | 68.23% |
| PrefixQuant-O1 | 7.26 | 71.31%(+3.08%) | ||
| PrefixQuant-O2 | 7.43 | 71.08%(+2.85%) | ||
| Llama-3-8B | W4A8KV4 | QoQ | 6.89 | 71.35% |
| PrefixQuant-O1 | 6.59 | 72.57%(+1.22%) | ||
| Llama-3-8B(MMLU) | W4A4KV4 | SpinQuant | - | 51.93% |
| PrefixQuant-O1 | - | 56.00%(+4.07%) |
(2)推理速度:显著提升
在RTX 3090 GPU、Llama-2-7B W4A4配置下:
| 方法 | 预填充耗时(2048令牌) | 解码速度(token/s) |
|---|---|---|
| FP16(全精度) | 489ms | 43 |
| PrefixQuant-O1 | 183ms(2.67×加速) | 91(2.11×加速) |
| PrefixQuant-O2 | 178ms(2.74×加速) | 93(2.16×加速) |
(3)泛化能力:适配多场景
- 长上下文(8192序列长度):仍优于基线方法,Llama-3-8B W4A4KV4的PPL为6.58(DuQuant为7.27);
- 纯权重量化:W2A16配置下,Llama-3-70B的平均准确率比EfficientQAT高4.73个点;
- 其他模型:在Mistral、Qwen及指令微调模型上均保持稳定精度提升。
3. 消融实验:验证核心模块有效性
以Llama-3-8B W4A4KV4为例:
| 模块组合 | PPL | 关键结论 |
|---|---|---|
| 基础(RTN+旋转+网格搜索) | 11.70 | 无前缀隔离时精度较差 |
| + 前缀离群值隔离 | 7.53 | 隔离模块使PPL降低36% |
| + 块级微调 | 7.23 | 微调进一步补偿量化误差 |
五、优势与局限
1. 核心优势
- 精度领先:首次实现静态量化(O2)超越动态量化基线,令牌级离群值隔离效果显著;
- 效率极高:前缀令牌检测耗时0.2-1分钟,推理速度2.16-2.74×加速,额外存储可忽略;
- 兼容性强:可与哈达玛旋转等通道级方法结合,适配权重-激活联合量化/纯权重量化,支持多模型;
- 低改造成本:无需重训模型,块级微调数据需求少(512×1024令牌)。
2. 主要局限
- 前缀令牌需定制:不同模型的高频离群令牌不同,需针对模型+校准数据集统计;
- 超大模型微调耗时:Llama-3-70B微调需17小时(W4A4KV4);
- 极端长上下文适配待验证:当前仅验证8192序列长度,更长序列下离群值位置可能偏移;
- 小众模型/架构适配不足:未验证1B以下模型及非Transformer架构(如MoE)。
六、结论
PrefixQuant通过"前缀令牌隔离令牌级离群值+块级微调补偿误差"的核心设计,在多模型、多精度、多粒度量化场景下实现了精度与速度的双重突破。其创新点在于首次系统性解决令牌级离群值问题,打破了"静态量化精度低于动态量化"的固有认知,且具备低改造成本、强兼容性的特点,为LLMs的高效部署提供了新方案。未来可进一步优化极端长上下文适配性及小众模型兼容能力。