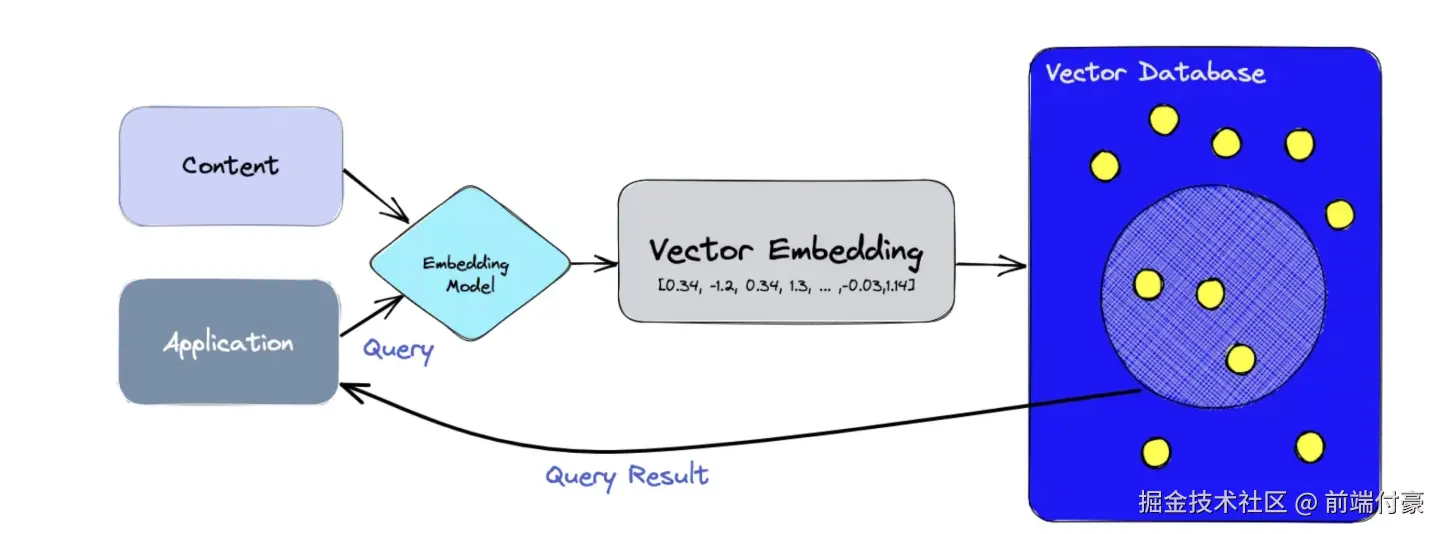
问答系统框架
整个框架分为这样三个部分。
•数据源(DataSources):数据可以有很多种,包括PDF在内的非结构化的数据(Unstructured Data) s SQL在内的结构化的数据(Structured Data),以及Python、Java之类的代码(Code) o在这个示例中,我们 聚焦于对非结构化数据的处理。
•大模型应用(Application,即LLM App):以大模型为逻辑引擎,生成我们所需要的回答。 •用例(Use-Cases):大模型生成的回答可以构建出QA/聊天机器人等系统。
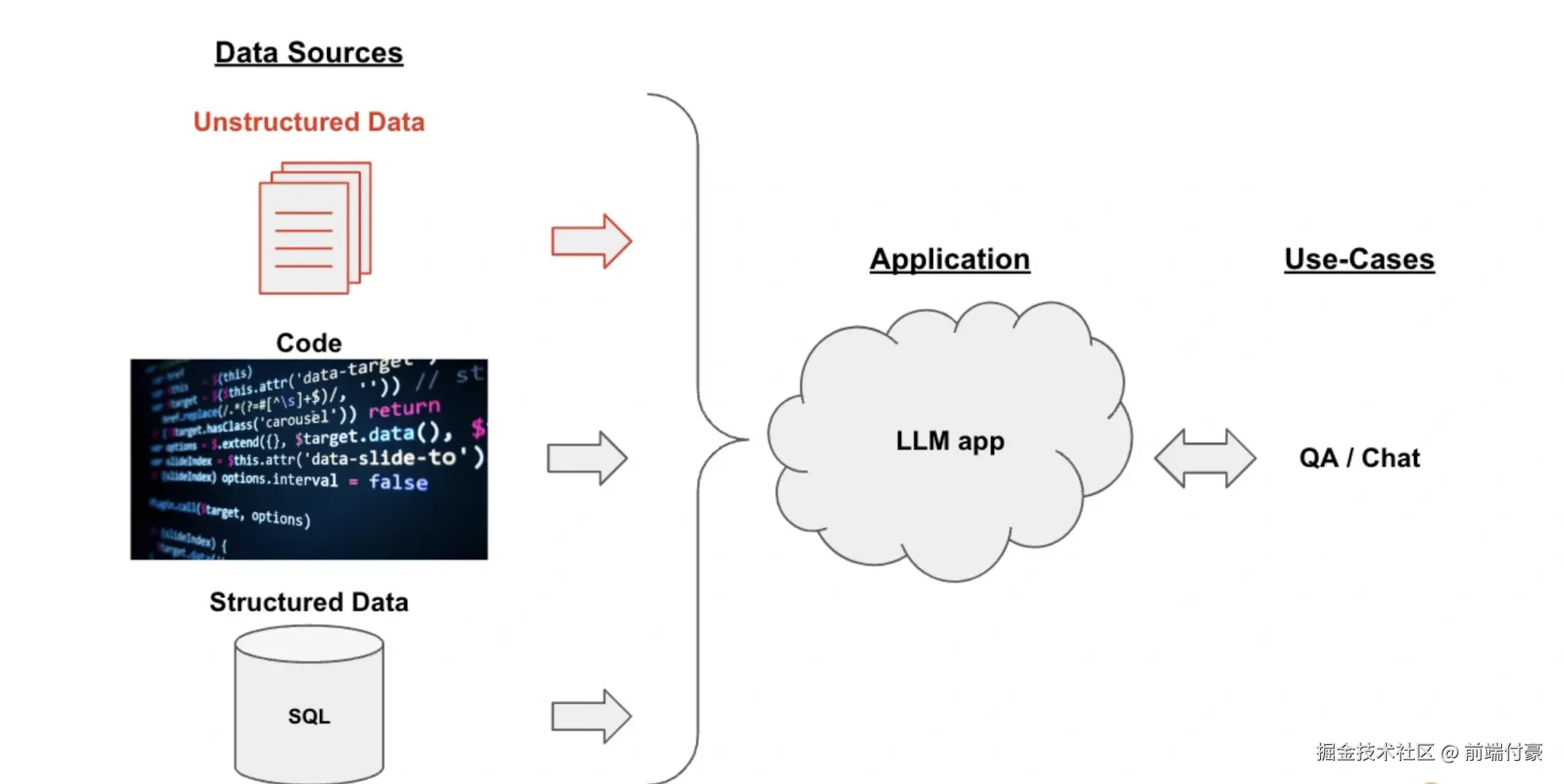
核心实现机制:这个项目的核心实现机制是下图所示的数据处理管道(Pipeline)。
问答系统数据处理管道
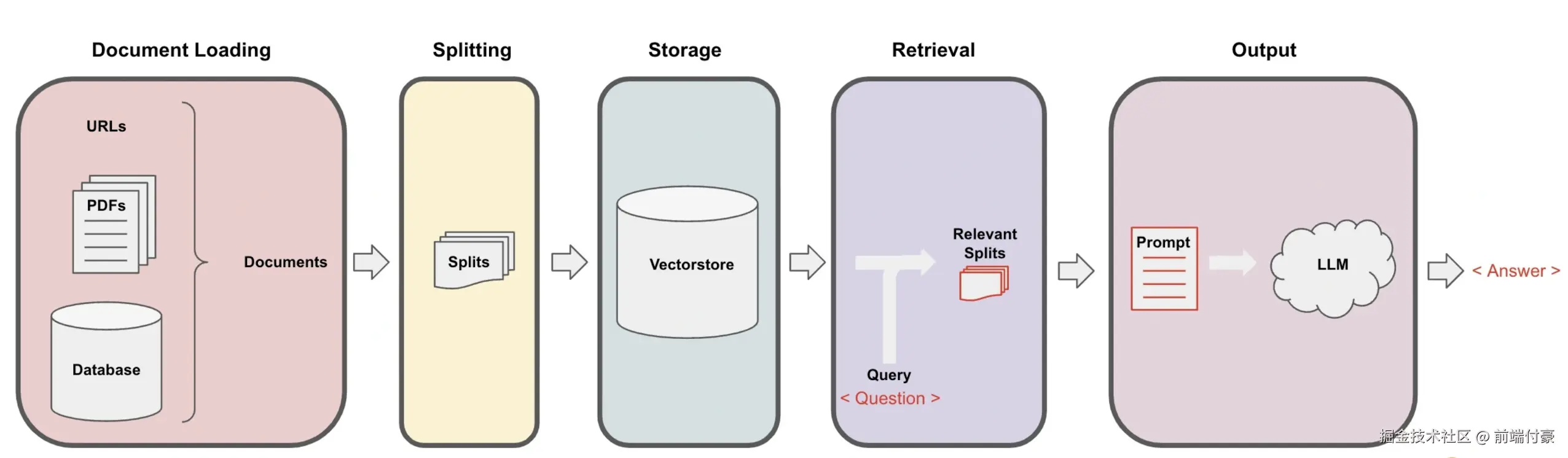
在这个管道的每一步中,LangChain都为我们提供了相关工具,让你轻松实现基于文档的问答功能。 具体流程分为下面5步。
- Loading:文档加载器把Documents加载为以LangChain能够读取的形式。
- Splitting:文本分割器把Documents切分为指定大小的分割,我把它们称为"文档块"或者"文档片"。
- Storage:将上一步中分割好的"文档块"以"嵌入"(Embedding) 的形式存储到向量数据库(Vector DB) 中,形成一个个的"嵌入片"。 4. Retrieval :应用程序从存储中检索分割后的文档(例如通过比较余弦相似度,找到与输入问题类似的嵌入片)。
- Output:把问题和相似的嵌入片传递给语言模型(LLM) ,使用包含问题和检索到的分割的提示生成答案。
上面5个环节的介绍都非常简单,有些概念(如嵌入、向量存储)是第一次出现,理解起来需要一些背景知识,别着急,我们接下来具体讲解这5步
数据准备和载入
引入三个文件
读取数据内容
ini
import os
from openai import OpenAI
# Moonshot API Key
MOONSHOT_API_KEY = "你的_MOONSHOT_API_KEY"
# 创建客户端(重点:base_url)
client = OpenAI(
api_key=MOONSHOT_API_KEY,
base_url="https://api.moonshot.cn/v1",
)
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
base_dir = r'.\OneFlower'
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
# =========================
# 用 Moonshot 进行总结
# =========================
content = "\n".join([doc.page_content for doc in documents])
resp = client.chat.completions.create(
model="moonshot-v1-8k",
messages=[
{"role": "system", "content": "你是一个文档分析助手"},
{"role": "user", "content": f"请帮我总结以下内容:\n{content[:6000]}"}
],
temperature=0.7,
max_tokens=1000,
)
print(resp.choices[0].message.content)文本分割
ini
# Split 将Documents切分成块以便后续进行嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)向量数据库存储
紧接着,我们将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。在这个例子中,我们使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入(这里需要 pip install qdrant-client)
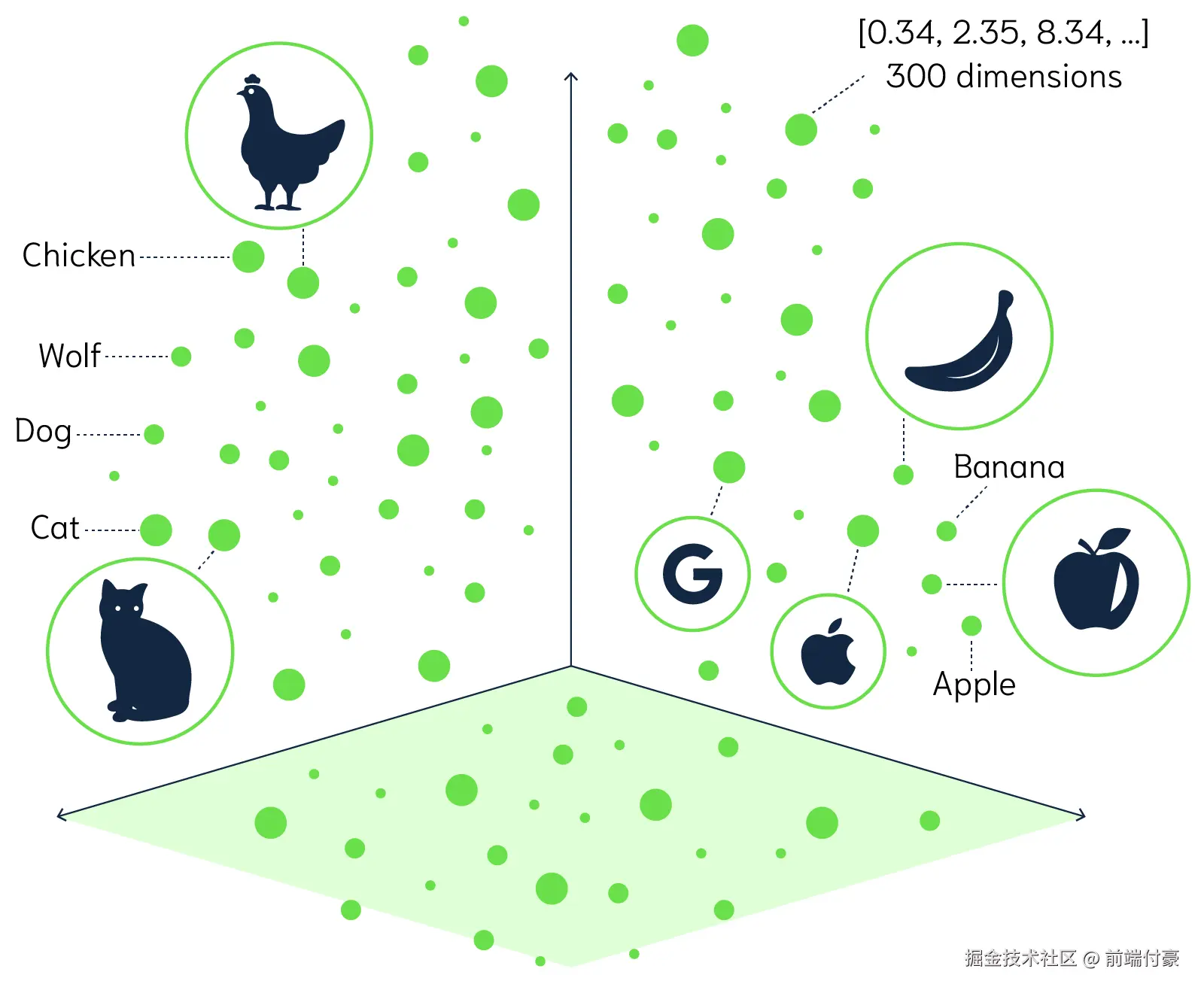
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到:
"国王" -> 1.2, 0.5, 3.1, ...
"皇帝" -> 1.3, 0.6, 2.9, ...
"苹果" -> 0.9, -1.2, 0.3, ...
从这些向量中,我们可以看到"国王"和"皇帝"这两个词的向量在某种程度上是相似的,而与"苹果"这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。 词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等
向量数据库
向量数据库,也称为矢量数据库或者向量搜索引擎,是一种专门用于存储和搜索向量形式的数据的数据库。在众多的机器学习和人工智能应用中,尤其是自然语言处理和图像识别这类涉及大量非结构化数据的领域,将数据转化为高维度的向量是常见的处理方式。这些向量可能拥有数百甚至数千个维度,是对复杂的非结构化数据如文本、图像的一种数学表述,从而使这些数据能被机器理解和处理。然而,传统的关系型数据库在存储和查询如此高维度和复杂性的向量数据时,往往面临着效率和性能的问题。因此,向量数据库被设计出来以解决这一问题,它具备高效存储和处理高维向量数据的能力,从而更好地支持涉及非结构化数据处理的人工智能应用
向量数据库有很多种,比如 Pinecone、Chroma 和 Qdrant,有些是收费的,有些则是开源的。
LangChain 中支持很多向量数据库,这里我们选择的是开源向量数据库 Qdrant。(注意,需要安装 qdrant-client)
ini
# Store 将分割嵌入并存储在矢量数据库Qdrant中
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入
location=":memory:", # in-memory 存储
collection_name="my_documents",) # 指定collection_name相关信息的获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在 -1 到 1 之间,值越接近 1,表示两个向量的方向越相似。
这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景
那么到底什么时候选择欧式距离,什么时候选择余弦相似度呢?
简单来说,关心数量等大小差异时用欧氏距离,关心文本等语义差异时用余弦相似度。
在这一步的代码部分,我们会创建一个聊天模型。然后需要创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在 RetrievalQA 链中有下面两大重要组成部分。
LLM 是大模型,负责回答问题。
retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的"嵌入片"。这些"嵌入片"对应的"文档块"就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为从互联网信息中训练而来的大模型不可能拥有"易速鲜花"作为一个私营企业的内部知识。
ini
# Retrieval 准备模型和Retrieval链
import logging
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.chains import RetrievalQA
# 设置Logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
# Moonshot:兼容 OpenAI 协议(关键:openai_api_base)
llm = ChatOpenAI(
model="moonshot-v1-8k", # 可换 moonshot-v1-32k
temperature=0,
openai_api_key="你的_MOONSHOT_API_KEY",
openai_api_base="https://api.moonshot.cn/v1",
)
# 实例化 MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm,
)
# 实例化 RetrievalQA 链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever_from_llm,
)现在我们已经为后续的步骤做好了准备,下一步就是接收来自系统用户的具体问题,并根据问题检索信息,生成回答
生成回答并展示
这一步是问答系统应用的主要 UI 交互部分,这里会创建一个 Flask 应用(需要安装 Flask 包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上
ini
# Output 问答系统的UI实现
from flask import Flask, request, render_template
app = Flask(__name__) # Flask APP
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
# 接收用户输入作为问题
question = request.form.get('question')
# RetrievalQA链 - 读入问题,生成答案
result = qa_chain({"query": question})
# 把大模型的回答结果返回网页进行渲染
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)相关 HTML 网页的关键代码如下
xml
<body>
<div class="container">
<div class="header">
<h1>本地文档问答</h1>
<img src="{{ url_for('static', filename='flower.png') }}" alt="flower logo" width="200">
</div>
<form method="POST">
<label for="question">Enter your question:</label><br>
<input type="text" id="question" name="question"><br>
<input type="submit" value="Submit">
</form>
{% if result is defined %}
<h2>Answer</h2>
<p>{{ result.result }}</p>
{% endif %}
</div>
</body>结合起来
python
import os
from pathlib import Path
from dotenv import load_dotenv
# =========================
# 0. Env
# =========================
BASE_PATH = Path(__file__).resolve().parent
load_dotenv(BASE_PATH / ".env")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise RuntimeError("未读取到 OPENAI_API_KEY:请在脚本同级 .env 中设置 OPENAI_API_KEY=xxx")
# =========================
# 1. Load 文档加载
# =========================
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader
base_dir = BASE_PATH / "datas"
if not base_dir.exists() or not base_dir.is_dir():
raise RuntimeError(f"找不到数据目录:{base_dir}(请在脚本同级创建 datas 文件夹)")
documents = []
for file in os.listdir(base_dir):
file_path = base_dir / file
lower = file.lower()
if lower.endswith(".pdf"):
documents.extend(PyPDFLoader(str(file_path)).load())
elif lower.endswith(".docx"):
documents.extend(Docx2txtLoader(str(file_path)).load())
elif lower.endswith(".txt"):
documents.extend(TextLoader(str(file_path), encoding="utf-8").load())
if not documents:
raise RuntimeError(f"datas 目录下没有可加载文件(支持 pdf/docx/txt):{base_dir}")
# =========================
# 2. Split 文档切分
# =========================
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=600,
chunk_overlap=80,
)
chunked_documents = text_splitter.split_documents(documents)
# =========================
# 3. Store 向量存储(Chroma)
# =========================
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
persist_dir = str(BASE_PATH / "chroma_db")
vectorstore = Chroma.from_documents(
documents=chunked_documents,
embedding=embeddings,
persist_directory=persist_dir,
)
vectorstore.persist()
# =========================
# 4. LLM(Moonshot,OpenAI 兼容)
# =========================
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
llm = ChatOpenAI(
model="moonshot-v1-8k",
temperature=0,
openai_api_key=OPENAI_API_KEY,
openai_api_base="https://api.moonshot.cn/v1",
)
from langchain_core.messages import SystemMessage, HumanMessage
# 分数阈值:越小越严格(Chroma 默认是距离,通常越小越相似)
# 你可以先用 0.9 / 1.0 试,感觉太严格再调大一点
MAX_DISTANCE = 0.9
def rag_answer(question: str) -> str:
# 直接用向量库带分数检索
# 返回 [(Document, score), ...];score 为距离(越小越相似)
try:
pairs = vectorstore.similarity_search_with_score(question, k=4)
except Exception as e:
return f"检索失败:{type(e).__name__}: {e}"
if not pairs:
return "不知道(文档里没有相关内容)"
# 过滤低相关(距离太大)
filtered = [(d, s) for (d, s) in pairs if s is not None and s <= MAX_DISTANCE]
if not filtered:
# 这里直接拒答,防止模型自由发挥
return "不知道(文档里没有足够相关的信息)"
# 拼接上下文 + 记录来源
ctx_blocks = []
sources = []
for i, (d, s) in enumerate(filtered, 1):
src = d.metadata.get("source") or d.metadata.get("file_path") or "unknown"
page = d.metadata.get("page", None)
page_info = f" p.{page}" if page is not None else ""
sources.append(f"[{i}] {src}{page_info} (distance={s:.3f})")
text = d.page_content.strip()
ctx_blocks.append(f"[{i}] {text}")
context = "\n\n".join(ctx_blocks)
system = SystemMessage(content=(
"你是一个严格的检索问答助手。"
"只能依据【上下文】回答,不允许使用外部知识或常识补充。"
"如果上下文不足以回答,就只回复:不知道。"
))
human = HumanMessage(content=f"""问题:{question}
【上下文(来自 datas)】
{context}
要求:
1) 只能基于上下文回答
2) 不允许推测/扩写/补全
3) 回答后附上你用到的引用编号(如:引用:[1][2])
""")
try:
resp = llm.invoke([system, human])
answer = getattr(resp, "content", str(resp)).strip()
except Exception as e:
return f"LLM 调用失败:{type(e).__name__}: {e}"
# 为了让你核验:把检索来源也一并展示
return answer + "\n\n---\n检索命中:\n" + "\n".join(sources)
# =========================
# 5. Flask UI(不依赖 templates)
# =========================
from flask import Flask, request, render_template_string
HTML = """
<!doctype html>
<html>
<head><meta charset="utf-8"><title>RAG Demo</title></head>
<body style="max-width:900px;margin:40px auto;font-family:Arial">
<h2>本地文档问答(RAG)</h2>
<p style="color:#666">数据目录:{{ data_dir }}</p>
<form method="post">
<input name="question" style="width:100%;padding:10px"
placeholder="输入问题..." value="{{ question or '' }}"/>
<button style="margin-top:10px;padding:8px 14px">提问</button>
</form>
{% if result %}
<h3>回答</h3>
<pre style="white-space:pre-wrap;background:#f6f6f6;padding:12px;border-radius:8px">{{ result }}</pre>
{% endif %}
</body>
</html>
"""
app = Flask(__name__)
@app.route("/", methods=["GET", "POST"])
def home():
if request.method == "POST":
question = (request.form.get("question") or "").strip()
if not question:
return render_template_string(HTML, result="请输入问题。", question="", data_dir=str(base_dir))
answer = rag_answer(question)
return render_template_string(HTML, result=answer, question=question, data_dir=str(base_dir))
return render_template_string(HTML, result=None, question=None, data_dir=str(base_dir))
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8088, debug=True)安装依赖为 requirements.txt
shell
langchain>=0.1.17
langchain-community>=0.0.36
langchain-openai>=0.1.0
langchain-text-splitters>=0.0.1
chromadb>=0.4.22
sentence-transformers>=2.2.2
flask>=2.3.3
python-dotenv>=1.0.0
pypdf>=3.15.5
docx2txt>=0.8结果

我们先把本地知识切片后做 Embedding,存储到向量数据库中,然后把用户的输入和从向量数据库中检索到的本地知识传递给大模型,最终生成所想要的回答