文末附有 HAProxy 核心配置速记+vim进入文件后文件编辑常用快捷键总结表
一. Haproxy简介
1.1 背景
HAProxy 是法国开发者威利塔罗(Willy Tarreau)在 2000 年用 C 语言写的一款开源软件,主打高并发(万级以上)和高性能,既能做 TCP 负载均衡,也能做 HTTP 负载均衡,还支持基于 cookie 的会话保持、自动故障切换、正则表达式和 Web 状态统计等功能,有社区版和企业版两个版本。
1.2 原理
HAProxy 就像一个 "智能流量管家",它站在客户端和后端服务器中间,先接住所有进来的请求,再根据预设的规则(比如轮询、最小连接数,或者看 URL、Cookie 等),把请求转发给最合适的后端服务器去处理,同时还能监控后端服务器的健康状态,发现哪个服务器挂了就自动把流量切到别的服务器上。
1.3 目的
扛住更多并发请求,不让单台服务器被压垮;保证服务不中断,某台服务器出问题也不影响用户使用;让用户访问更稳定、响应更快,体验更好;方便后续扩展,加服务器不用改太多配置。
二.环境设定
2.1 环境流程图
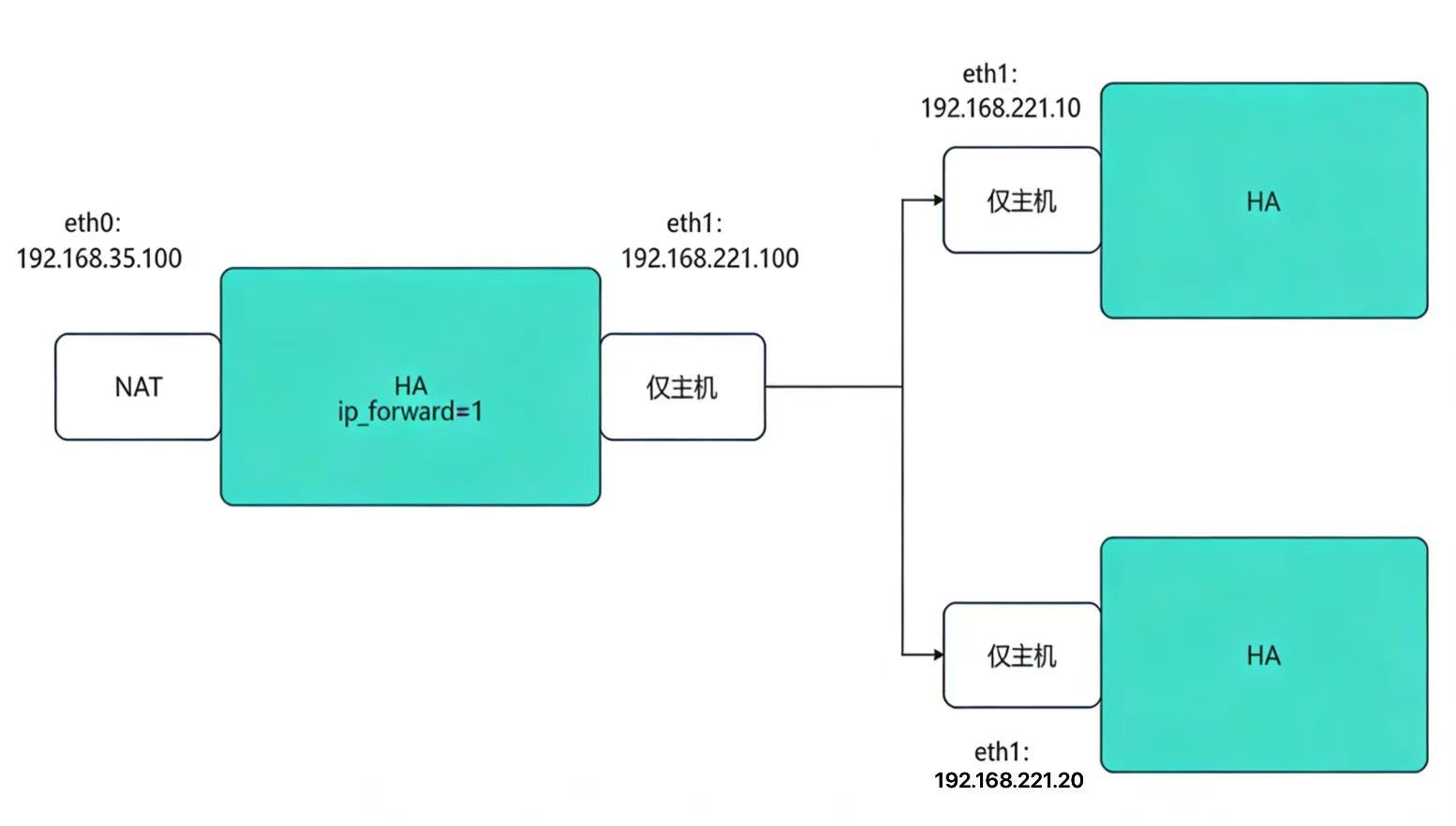
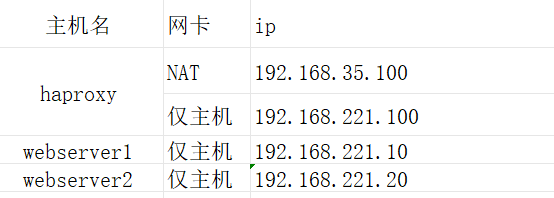
2.2 实验环境
2.3 环境配置
2.3.1创建并开启虚拟机
(注意对应的网卡数量及类型)
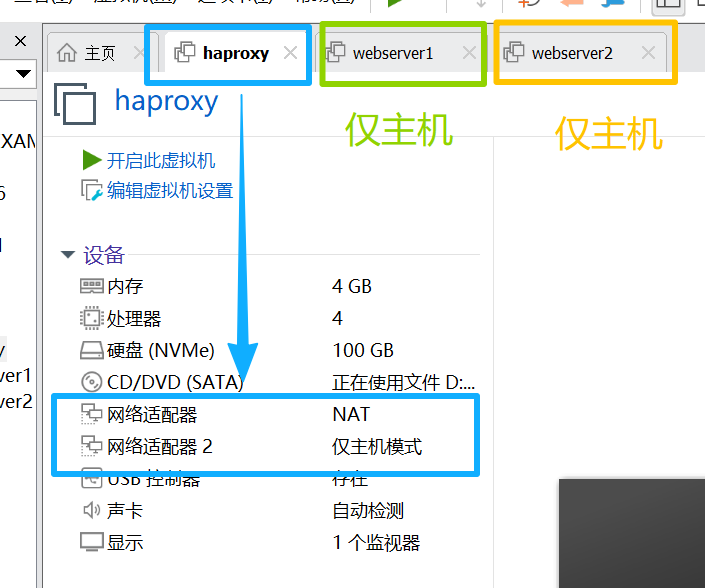
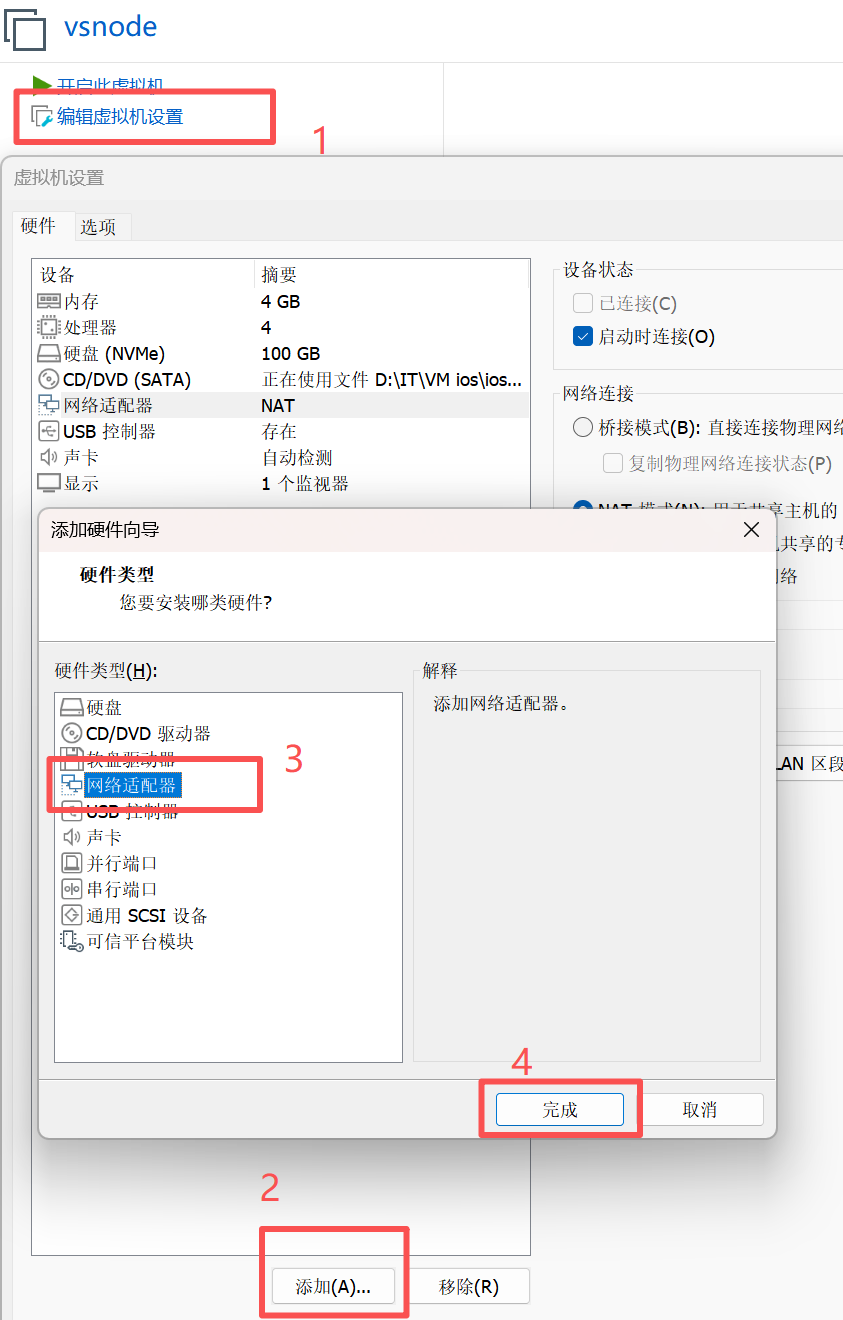
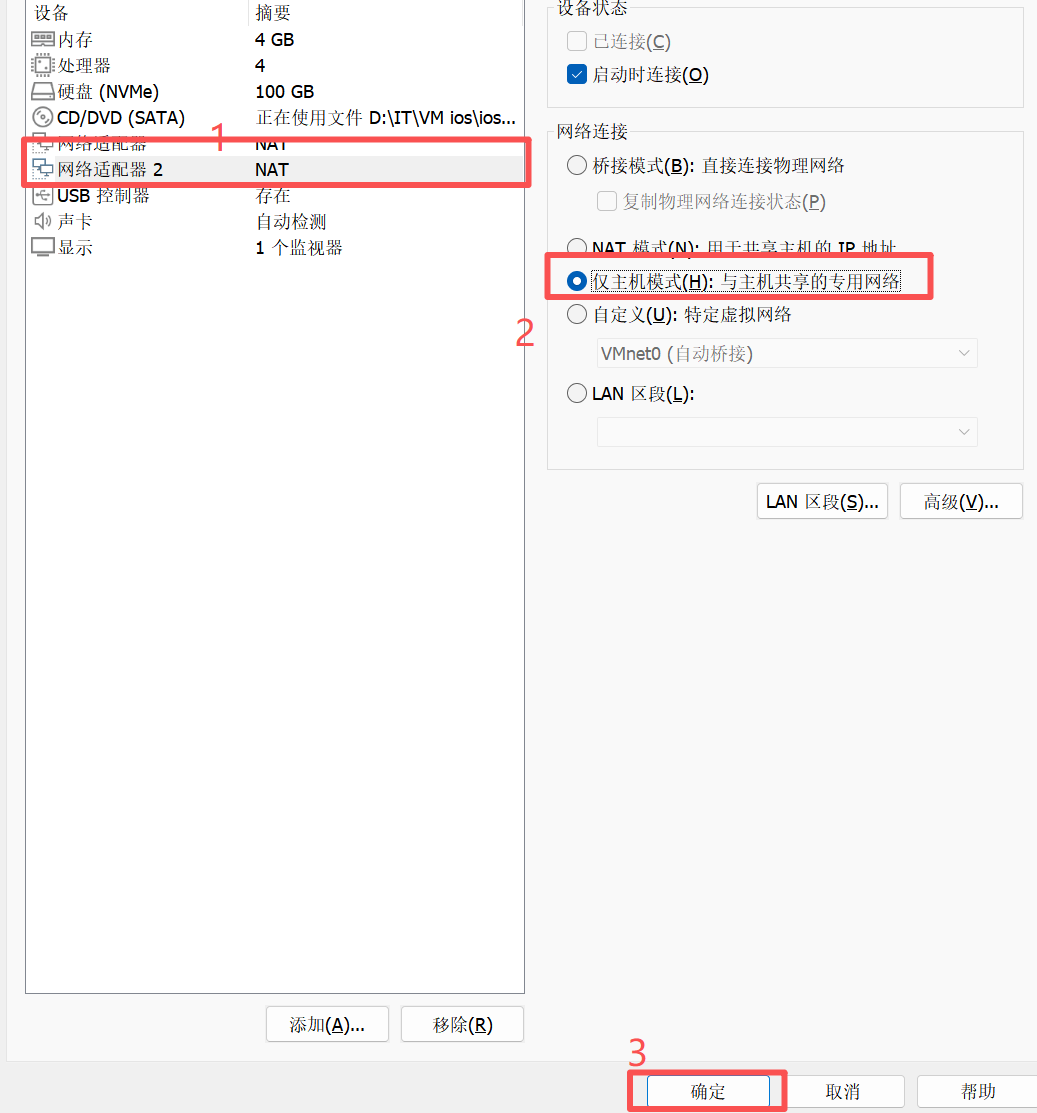
注:添加并更改网卡教程
添加
更改
2.3.2 环境配置命令
1.设定网络
在haproxy中
[root@haproxy ~]# vmset.sh eth0 192.168.35.100 haproxy
[root@haproxy ~]# vmset.sh eth1 192.168.221.100 haproxy noroute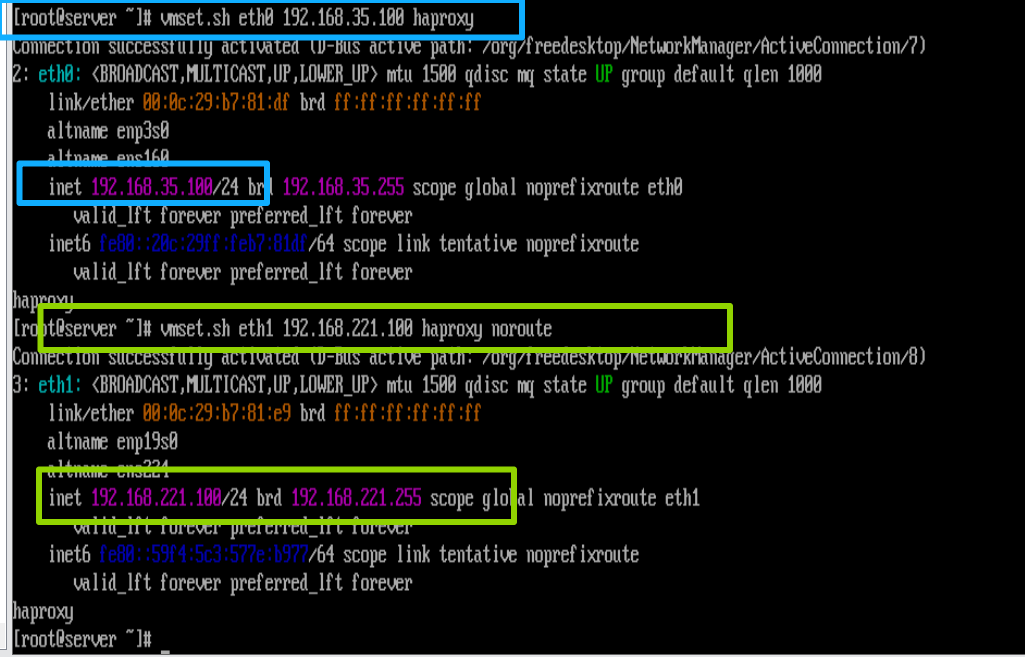
在webserver1中
[root@webserver1 ~]# vmset.sh eth0 192.168.221.10 webserver1 noroute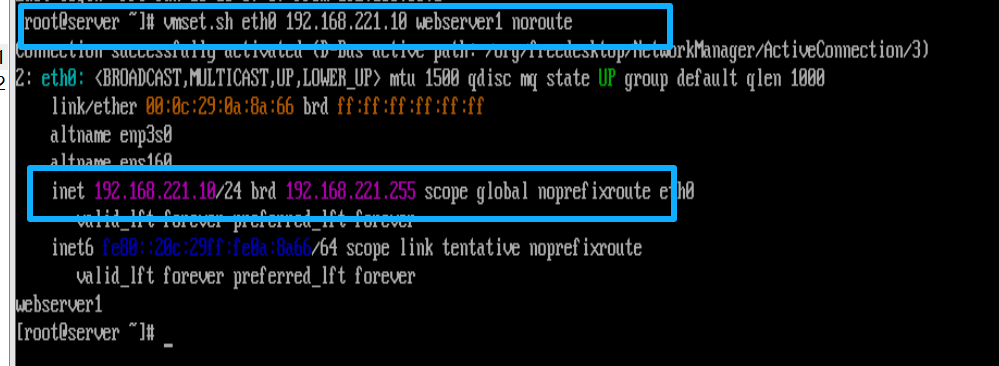
在webserver2中
[root@webserver2 ~]# vmset.sh eth0 192.168.221.20 webserver2 noroute
2.配置内核路由功能
让运行 HAProxy 的服务器具备转发 IP 数据包的能力 ------ 简单说,就是允许服务器把接收到的客户端请求数据包,转发给后端不同网段的真实服务器;同时也能把后端服务器的响应数据包,再转发回客户端。
在haproxy中
[root@haproxy ~]# echo net.ipv4.ip_forward=1 > /etc/sysctl.conf
#把开启内核 IP 转发的配置写入系统永久配置文件,确保服务器重启后依然生效
[root@haproxy ~]# sysctl -p
#立即加载 /etc/sysctl.conf 中的内核参数,让 ip_forward=1 无需重启服务器就能生效
3.设定访问业务真实数据
搭建一台可被 HAProxy 调度的后端 HTTP 业务服务器
这组操作的核心是为 HAProxy 负载均衡架构搭建一台可用的后端 Web 业务节点:安装 httpd 服务并创建带专属标识的首页文件,同时启动服务并设置开机自启,既让服务器能提供网页访问服务,也便于验证 HAProxy 的负载均衡调度效果。
在webserver1中
[root@webserver1 ~]# dnf install httpd -y
#安装 Apache HTTP 服务
[root@webserver1 ~]# echo webserver1 - 192.168.221.10 > /var/www/html/index.html
#创建 Web 服务的默认首页文件
[root@webserver1 ~]# systemctl enable --now httpd
#立即启动 httpd 服务,并设置开机自启
在webserver2中
[root@webserver2 ~]# dnf install httpd -y
#安装 Apache HTTP 服务
[root@webserver2 ~]# echo webserver2 - 192.168.221.20 > /var/www/html/index.html
#创建 Web 服务的默认首页文件
[root@webserver2 ~]# systemctl enable --now httpd
#立即启动 httpd 服务,并设置开机自启
4.验证环境
在haproxy中
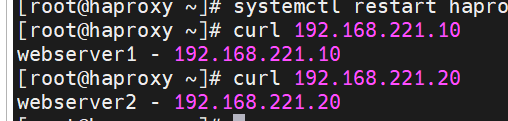
[root@haproxy ~]# curl 192.168.221.10
webserver1 - 192.168.221.10
[root@haproxy ~]# curl 192.168.221.20
webserver2 - 192.168.221.20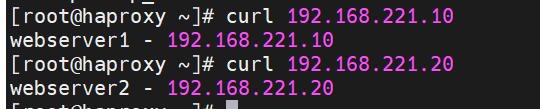
三. Haproxy的安装及配置参数
3.1 安装
在haproxy中
[root@haproxy ~]# dnf install haproxy -y
#通过系统包管理器安装 HAProxy 软件,这是搭建负载均衡服务的基础前提
[root@haproxy ~]# systemctl enable --now haproxy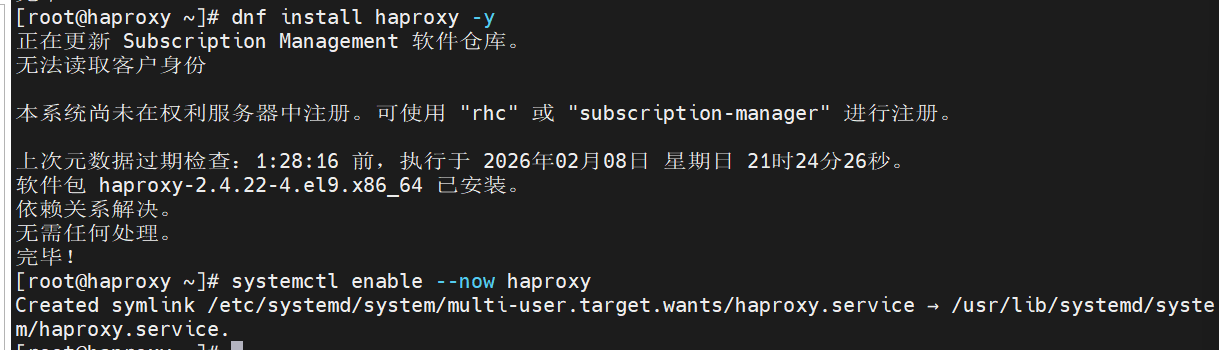
3.2 harpoxy的参数详解实验
Haproxy的配置文件haproxy.cfg由两大部分组成,分别是:
global:全局配置段
(这是 HAProxy 配置里最顶层的部分,用来设置整个 HAProxy 进程生效的全局参数,所有代理相关的配置都会继承这里的基础设置。)
· 进程及安全配置相关的参数 (主要控制 HAProxy 进程的运行方式和安全相关设置)
· 性能调整相关参数 (用于优化 HAProxy 的运行性能)
· Debug参数 (用于调试和排查问题)
proxies:代理配置段(这是 HAProxy 配置里专门负责代理相关逻辑 的部分,用来定义如何接收请求、转发请求到后端服务器。)
· defaults:为 frontend, ...
(defaults 段是默认配置段 ,用来给下面的
frontend、backend等提供统一的默认参数,避免重复配置。)· frontend:前端,相当于 nginx
(frontend 是前端入口,负责监听客户端的请求(比如监听某个端口),并根据规则把请求转发到对应的后端,作用类似 Nginx 的 "前端监听 + 路由分发")
· backend:后端,相当于 nginx
(backend 是后端服务池,定义了一组真实的后端服务器,以及负载均衡、健康检查等规则,类似 Nginx 里的 upstream 后端服务器组。)
· listen:同时拥有前端和后端配置
(listen 是一种简化写法,把 frontend 和 backend 合并在一个配置块里,既定义监听端口,又直接指定后端服务器,适合简单的一对一代理场景。)
3.2.1 实现最基本的负载
前后端分开设定和用listen方式书写负载均衡这两种方法,功能完全等价,只是用listen方式写法更简洁

1.前后端分开设定
在haproxy中
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
(注:为了不影响效果,可选择将源文件中目前不需要的配置信息注释掉
快速注释方法在文末)
frontend webcluster #定义前端配置块,frontend负责接收客户端请求,名字叫webcluster(可自定义)
bind *:80 #监听服务器所有网卡的80端口
mode http #工作模式为HTTP模式
use_backend webserver-80 #将接收到的请求转发到名为webserver-80的后端集群
backend webserver-80 #定义后端的配置块,名字要和前端的use_backend对应
server web1 192.168.221.10:80 check inter 3s fall 3 rise 5
server web2 192.168.221.20:80 check inter 3s fall 3 rise 5
#指定了两台后端 Web 服务器(IP 是 192.168.221.10(20)),HAProxy 会默认用轮询方式,把请求交替发给 web1 和 web2,实现负载均衡。
[root@haproxy ~]# systemctl restart haproxy.service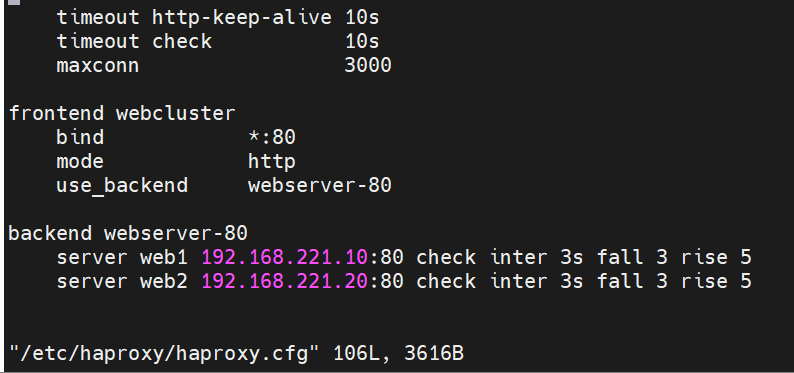
测试:
[root@haproxy ~]# curl 192.168.35.100
webserver1 - 192.168.221.10
[root@haproxy ~]# curl 192.168.35.100
webserver2 - 192.168.221.20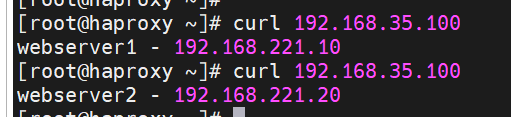
2.用listen方式书写负载均衡
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
listen webcluster # 定义一个listen配置块,名称为webcluster
bind *:80 # 监听服务器所有网卡的80端口
mode http # 工作模式为HTTP模式
server web1 192.168.221.10:80 check inter 3s fall 3 rise 5
server web2 192.168.221.20:80 check inter 3s fall 3 rise 5
#定义两台后端 Web 服务器(web1、web2);开启健康检查,每 3 秒检测一次,连续 3 次失败则剔除,连续 5 次成功则恢复。
[root@haproxy ~]# systemctl restart haproxy.service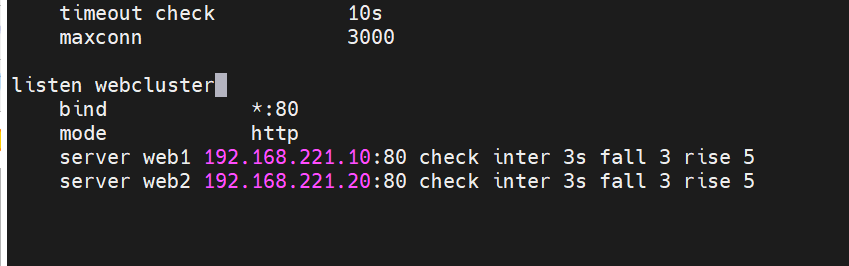
测试:
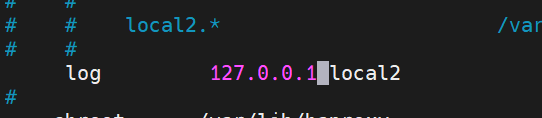
3.2.2 log 127.0.0.1 local2
指定把日志发送到哪里
实验中指定日志发送到192.168.221.10(webserver1)
1.在192.168.0.10 开启接受日志的端口
[root@webserver1 ~]# vim /etc/rsyslog.conf #打开 rsyslog 服务的核心配置文件
module(load="imudp") # needs to be done just once
#开启rsyslog 的 "UDP 输入模块",作用是让 rsyslog 具备通过 UDP 协议接收日志的能力
input(type="imudp" port="514")
#定义rsyslog的日志输入源为UDP模块,监听 UDP 514 端口(514 是 syslog 协议的默认端口)
[root@webserver1 ~]# systemctl restart rsyslog.service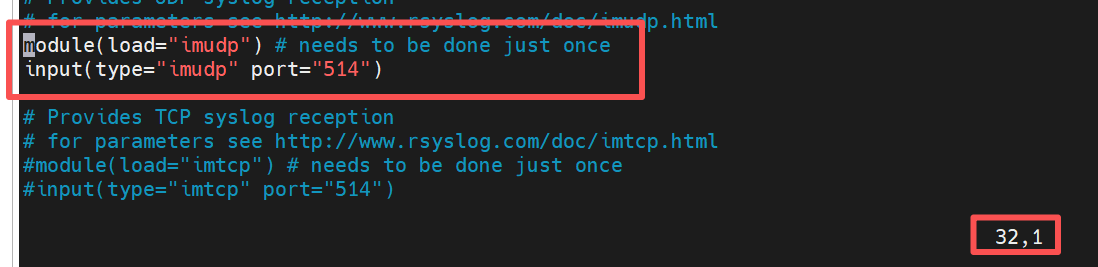
2..测试接受日志端口是否开启
[root@webserver1 ~]# netstat -antlupe | grep rsyslog
-
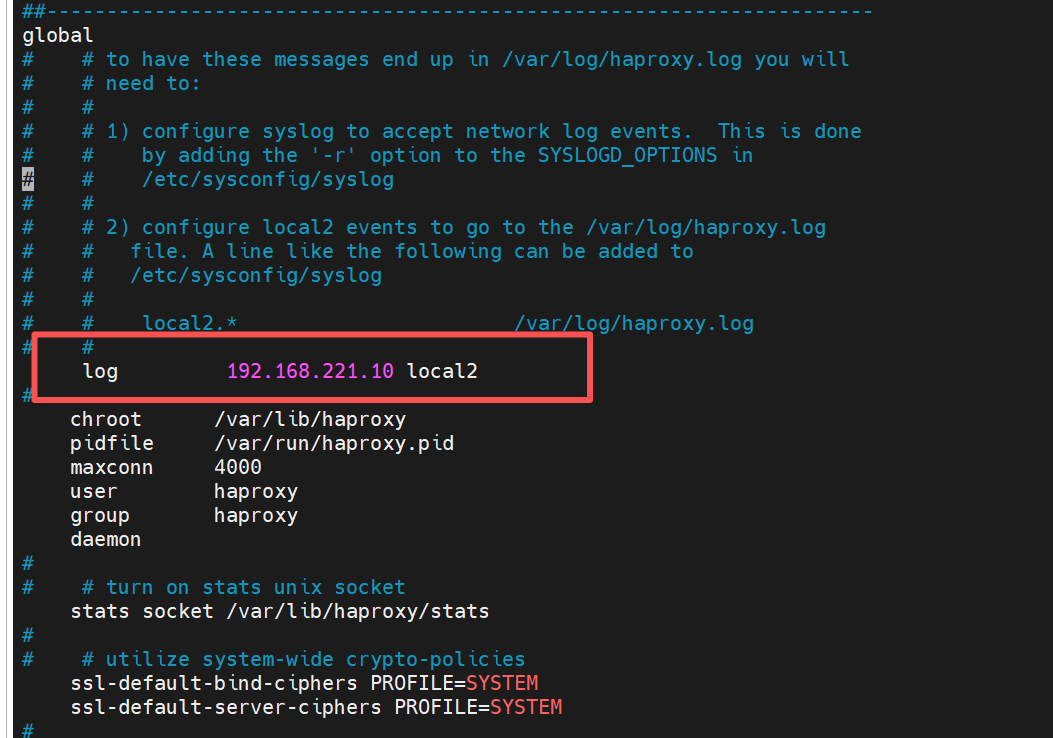
在haproxy主机中设定日志发送信息
[root@haproxy haproxy]# vim haproxy.cfg
log 192.168.221.10 local2
[root@haproxy haproxy]# systemctl restart haproxy.service
- 验证
新开一个shell中

在webserver1中
[root@webserver1 ~]# cat /var/log/messages
注:做完实验后将log 更改回去
3.2.3 实现haproxy的多进程
-
默认haproxy是单进程,现在改为多进程
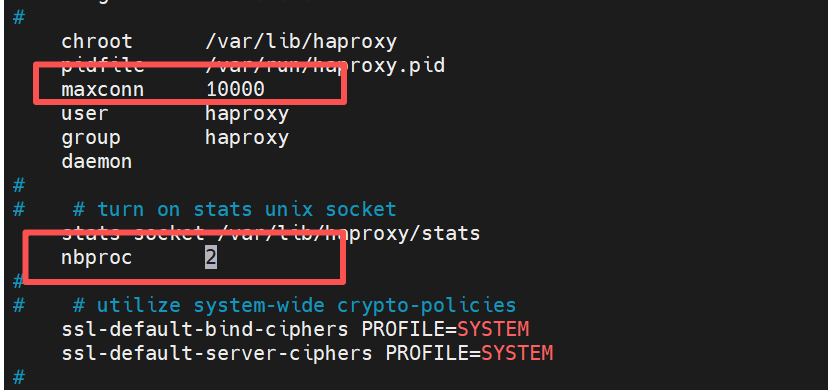
[root@haproxy haproxy]# vim /etc/haproxy/haproxy.cfg
maxconn 10000 #选择性更改最大并发量为多少
user haproxy
group haproxy
daemon# turn on stats unix socket
stats socket /var/lib/haproxy/stats nbproc 2 #设定进程数量为2个[root@haproxy haproxy]# systemctl restart haproxy.service
[root@haproxy haproxy]# pstree | grep haproxy
|-haproxy---2*[haproxy]
验证

- 多进程cpu绑定
为 HAProxy 开启多进程模式,并将不同进程绑定到指定 CPU 核心,提升性能和资源利用效率
注:每个进程独占一个核心,最大化利用多核 CPU 的算力,尤其适合高并发的负载均衡场景
[root@haproxy haproxy]# vim /etc/haproxy/haproxy.cfg
nbproc 2
cpu-map 1 0
#将 HAProxy 的第 1 个进程绑定到服务器的第 0 号 CPU 核心(CPU 核心编号从 0 开始)
cpu-map 2 1
[root@haproxy haproxy]# systemctl restart haproxy.service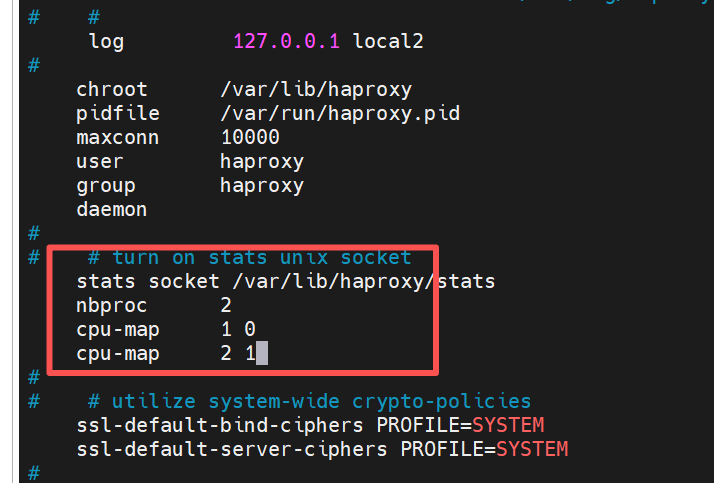
3.为不同进程准备不同套接字
[root@haproxy ~]# systemctl stop haproxy.service
[root@haproxy ~]# rm -fr /var/lib/haproxy/stats
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
stats socket /var/lib/haproxy/haproxy1 mode 600 level admin process 1
stats socket /var/lib/haproxy/haporxy2 mode 660 level admin process 1
# stats socket /var/lib/haproxy/haproxy1 定义统计套接字的文件路径,
mode 600 设置套接字文件的权限:- 600:仅文件所有者(haproxy 用户)可读写;
level admin 设置套接字的操作权限级别为 "管理员"
process 1 指定该套接字仅关联 HAProxy 的第 1 个进程
[root@haproxy ~]# systemctl restart haproxy.service
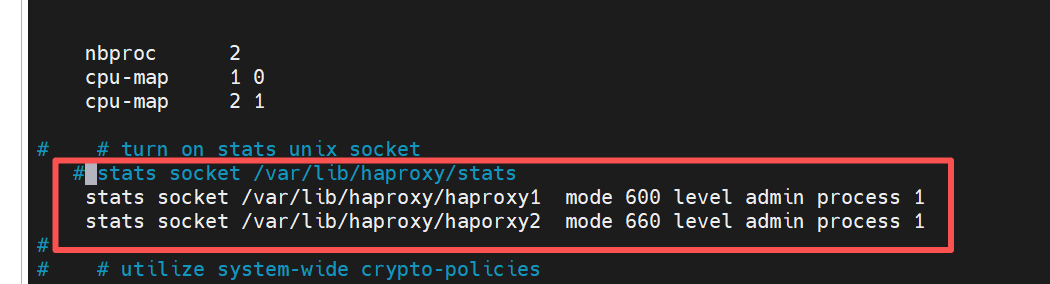
效果:

3.2.4 haproxy实现多线程
注意多线程不能和多进程同时启用
1.查看当前haproxy的进程信息
[root@haproxy ~]# pstree -p | grep haproxy #查看 HAProxy 进程树
|-haproxy(32313)-+-haproxy(32315)
| `-haproxy(32316)
#输出含义
32313 是管理进程,只做管控不处理业务;
32315/32316 是业务进程,专门处理请求转发,数量由nbproc 2决定。
[root@haproxy ~]# cat /proc/32315/status | grep Threads #查看指定进程的线程数
Threads: 1
2.启用多线程
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
#nbproc 2
#cpu-map 1 0
#cpu-map 2 1
nbthread 2
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#stats socket /var/lib/haproxy/haproxy1 mode 600 level admin process 1
#stats socket /var/lib/haproxy/haporxy2 mode 660 level admin process 1
[root@haproxy ~]# systemctl restart haproxy.service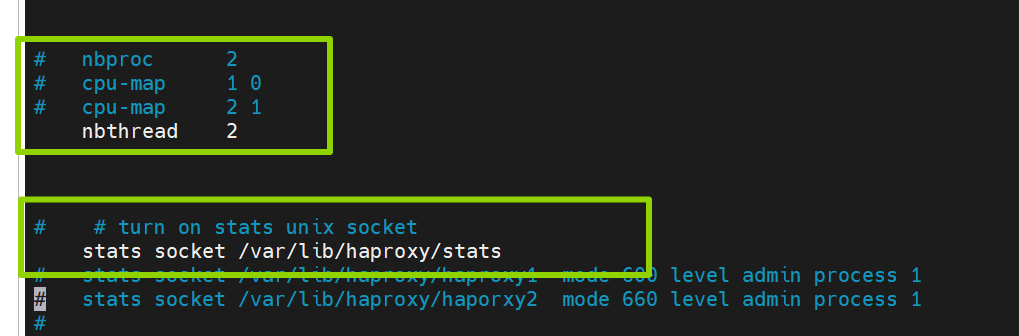
3.效果
[root@haproxy ~]# pstree -p | grep haproxy
|-haproxy(32333)---haproxy(32335)---{haproxy}(32336)
[root@haproxy ~]# cat /proc/32335/status | grep Threads
四. 常见问题
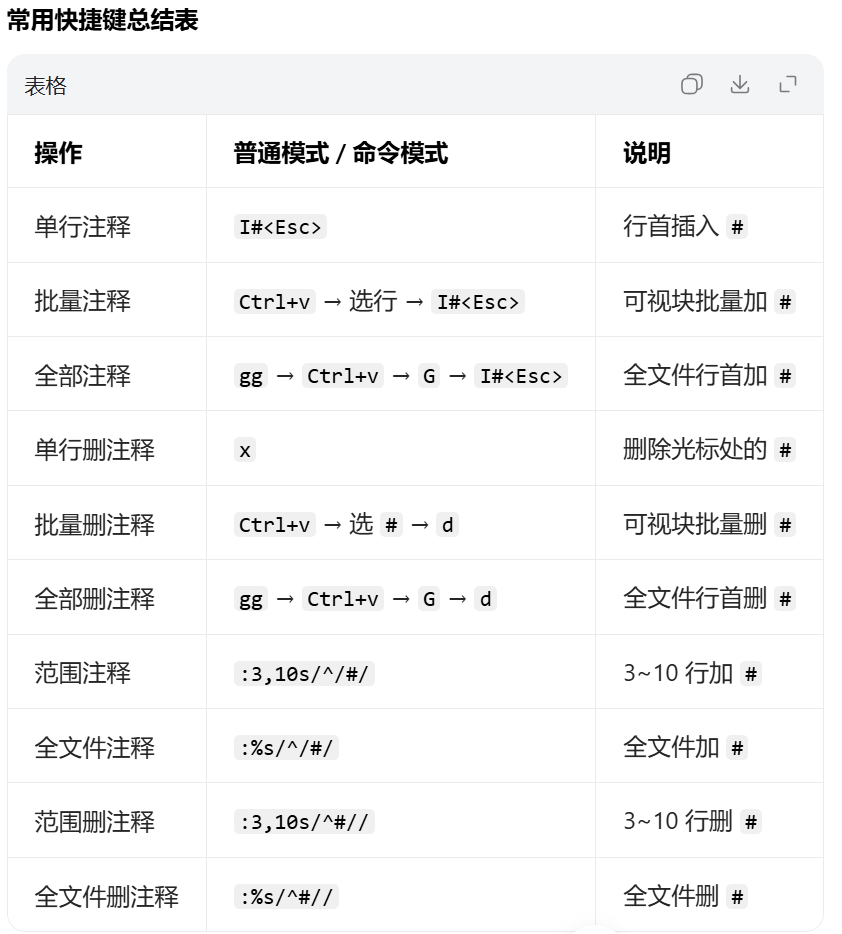
Q1:如何设定vim中tab键的空格个数?
解决方法:
在对应主机中,进入 vim ~/.vimrc这个文件,输入set ts=4 ai 即为设定vim中tab键的空格个数为4个
Q2:如何将文件中的内容进行注释或删除?
解决方法:
以文件/etc/haproxy/haproxy.cfg为例,通过命令"vim /etc/haproxy/haproxy.cfg"进入文件之后,
逐行注释(单行)
在 普通模式 下:
- 光标移到要注释的行,按
I(大写 i)进入行首插入模式 - 输入
#,按Esc退出 - 重复操作可注释多行,或用
.重复上一次操作
-
批量选中区域注释
-
按
Ctrl + v进入 可视块模式(Visual Block) -
用上下方向键选中要注释的多行的行首
-
按
I(大写 i)进入行首插入模式 -
输入
# -
按
Esc,选中的所有行首都会自动加上#
二、全部注释(整个文件)
- 按
gg跳转到文件首行 - 按
Ctrl + v进入可视块模式 - 按
G(大写 g)选中从首行到末行的所有行首 - 按
I→ 输入#→ 按Esc整个文件所有行都会被加上#注释
三、部分删除注释(逐行或选中区域)
- 单行删除注释
普通模式下,光标移到 # 所在位置,按 x 删除单个 #
-
批量删除注释
-
按
Ctrl + v进入可视块模式 -
选中所有行首的
#字符(确保只选中#) -
按
d,即可一次性删除选中区域内的所有#
小技巧:如果
#前面有空格,可先按0跳行首,再按l右移到#位置,再用可视块选中
四、全部删除注释(整个文件)
- 按
gg跳转到首行 - 按
Ctrl + v进入可视块模式 - 按
G选中所有行首的# - 按
d删除所有选中的#
Q3:假设有多台haproxy主机,如何将所有主机的日志都集中在同一haproxy主机中?
五. 结论
HAProxy 就像餐厅里的 "智能领位员":
- 背景:这家餐厅生意太好,单靠一个服务员(单台服务器)忙不过来,于是请了个专业领位(HAProxy)来帮忙。
- 原理:客人来了,领位先问清楚想吃什么、几个人,再根据各个包间(后端服务器)的空闲情况,把客人安排到最合适的包间,要是某个包间的厨师请假了(服务器故障),领位就再也不把客人往那儿带。
- 目的:让客人不用等太久,也不会因为某个包间忙不过来而吃不上饭,餐厅也能轻松接待更多客人。
- 实际效果:不管是周末高峰还是平时,客人都能快速入座,体验一直很稳定,餐厅也能放心地多开几个包间(扩展服务器),不用怕客人找不到位置。
附录
HAProxy 核心配置速记
全局配置(global)- 基础环境
global
log /dev/log local0 # 日志输出位置
maxconn 10240 # 最大并发连接数
user haproxy # 运行用户
group haproxy # 运行用户组
daemon # 后台运行
nbthread 4 # 工作线程数(建议等于CPU核心数)默认配置(defaults)- 通用规则(继承给后端 / 前端)
defaults
log global # 继承global的日志配置
mode http # 模式:http(七层)/tcp(四层)
option httplog # 记录HTTP详细日志
option dontlognull # 不记录空连接日志
retries 3 # 后端服务器重试次数
timeout connect 5s # 连接后端服务器超时时间
timeout client 30s # 客户端连接超时时间
timeout server 30s # 后端服务器响应超时时间
maxconn 2048 # 该配置组最大并发后端服务器池(backend)- 定义真实服务节点
backend web_server # 后端池名称(前端需关联)
mode http # 匹配七层/四层模式
balance roundrobin # 调度算法:轮询(常用)
# 调度算法可选:leastconn(最小连接)、source(源IP哈希-会话粘滞)
server node1 192.168.221.10:80 check inter 2s rise 2 fall 3 # 节点1+健康检查
server node2 192.168.221.20:80 check inter 2s rise 2 fall 3 # 节点2+健康检查
# check:开启健康检查;inter:检查间隔;rise:恢复上线次数;fall:故障下线次数前端监听(frontend)- 接收客户端请求并转发
frontend web_listen
bind 192.168.221.200:80 # 监听VIP+端口(对外提供服务的地址)
mode http # 匹配七层/四层模式
default_backend web_server # 转发到指定后端池(核心关联)快捷整合配置(frontend+backend 合并:listen)
适合简单场景,替代单独的 frontend+backend,更简洁
listen web_service
bind 192.168.221.200:80
mode http
balance roundrobin
server node1 192.168.221.10:80 check
server node2 192.168.221.20:80 check
timeout connect 5s核心常用配置 - 按需添加
1.会话粘滞(source 哈希):同一客户端固定转发到同一后端
balance source # 替换backend中的roundrobin2.四层 TCP 转发(如 443 / 数据库):仅需修改 mode 为 tcp
mode tcp # global/default/frontend/backend 统一改为tcp,关闭httplog3.健康检查关闭 :后端节点后去掉check即可
4.节点权重:给性能好的节点分配更多流量(weight 默认 1)
server node1 192.168.221.10:80 check weight 2 # 权重2,占比更高配置后必执行命令
haproxy -c -f /etc/haproxy/haproxy.cfg # 检查配置语法(核心,先检查再重启)
systemctl restart haproxy # 重启生效
systemctl enable haproxy # 开机自启
ss -tnl | grep 80 # 验证监听端口是否开启常用快捷键总结表