最近在做一个项目是关于仿真优化业务的,项目背景是在系统中搭建仿真工作流,工作流会调用各种优化算法进行计算,每个任务的计算会产生大量的中间结果写入数据库中,而且每个任务会多次修改参数重新提交,就会多次大量的更新数据库的数据。
👉 这是一个 UPDATE 远多于 INSERT 的系统
问题:"大量中间数据 + 反复重算 + 高频 UPDATE",可能会出现的问题就是系统经过一段时间的运行,大量的数据导致磁盘被占满的问题。
解决方法:与同事讨论后一致决定,将计算结果数据表与其余业务表分开,并部署到不同的服务器上。这还不能解决根本问题,如果依旧采用PostgreSQL数据库依旧会出现存储空间持续膨胀,以及性能波动问题。这时我们就把目光瞄准了OpenTeleDB,他的Xstore存储引擎完美的解决了这些问题。
OpenTeleDB通过XStore存储引擎对存储层进行全链路重构:通过原位更新与Undo日志管理,从根本杜绝空间膨胀,表空间占用几乎零增长;同时对索引采用原位更新,彻底告别扫表式Vacuum,将执行TPCC模型时性能波动压制在5%以内。
下面是我的一些验证测试流程。
数据库安装
关于OpenTeleDB的安装教程网上有很多,我就不过多赘述了。
数据库安装主要分为以下几步,部署也相对简单:
- 安装一些必要的依赖
- 源码下载
- 编译安装
- 初始化数据库
- 启动数据库
最终通过命令启动数据库,如果出现server started的字样则证明数据库服务启动成功。
bash
安装目录/bin/pg_ctl -D 安装目录/data start
启动之后也可以ps uxf | grep postgres 命令用于查看 OpenTeleDB 数据库相关的所有进程

在测试过程中遇到的问题:
1.OpenTeleDB默认的监听地址是 localhost,只允许本地连接
我的服务和数据库不在同一台服务器,需要修改一下配置允许通过ip访问。
需要修改/openteledb/data/下的postgresql.conf文件中的
ini
listen_addresses = 'localhost' # what IP address(es) to listen on;
# 修改为
listen_addresses = '*' # what IP address(es) to listen on; 修改完成之后,可以通过ss -lntp | grep 5432验证是否生效,如果是0.0.0.0就代表允许外部ip访问。

2.FATAL: no pg_hba.conf entry for host "192.168.1.102", user "postgres", database "postgres", no encryption
这个错误表明 PostgreSQL 在 pg_hba.conf 配置文件中没有为 IP 地址 192.168.1.102 配置访问权限,导致无法建立数据库连接。
需要修改 pg_hba.conf 配置文件,添加一条允许连接的规则。
css
host all all 192.168.1.102/32 md5修复了上述的两个问题之后,我就可以在另外一台服务器上连接到数据库。
测试过程
现在来模拟一下我的业务场景,通过SQL模拟一个优化算法来生成大量的中间结果数据.为了验证Xstore在表空间膨胀的表现,测试过程中我创建了两张表,一张是正常创建的数据库表(optimization_results_indexed),另外一张是使用Xstore引擎创建的数据库表(optimization_results_indexed_xstore)。
在进行测试过程之前,我们先确认一下Xstore 扩展已正常启用。
sql
\dx
-- 显式启用 xstore 扩展
CREATE EXTENSION IF NOT EXISTS xstore;
生成库表
我首先要做的是实现一个SQL语句,确保数据库中存在一个用于存储优化结果的表。具体来说,下面这段SQL会检查并创建一个名为 optimization_results_indexed 或 optimization_results_indexed_xstore 的表,表结构设计用于存储优化算法的执行结果。表包括以下字段:
algorithm_name:存储算法名称。
execution_index:标识算法执行的编号。
best_solution:保存算法的最佳解决方案。
best_score:记录最佳解决方案的得分。
iteration_count:表示算法执行的迭代次数。
last_updated:自动记录表中的数据最后更新时间。
sql
CREATE TABLE IF NOT EXISTS optimization_results_indexed (
algorithm_name VARCHAR(50),
execution_index INT,
best_solution TEXT,
best_score DOUBLE PRECISION,
iteration_count INT,
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (algorithm_name, execution_index)
);
//Xstore存储引擎
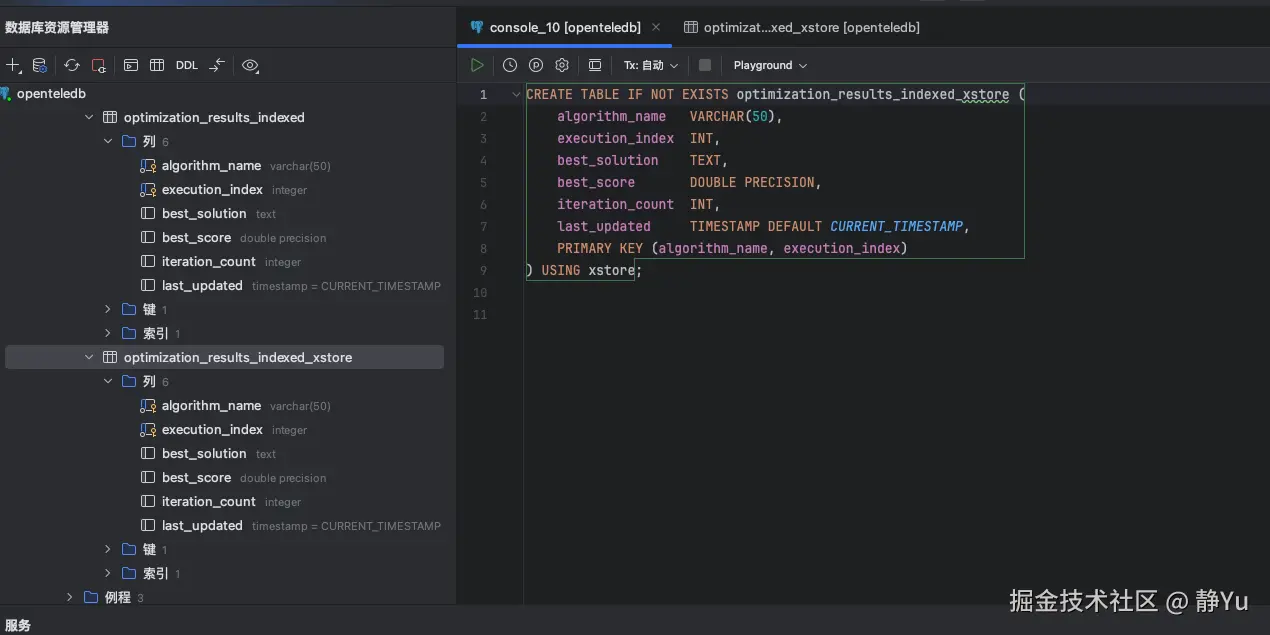
CREATE TABLE IF NOT EXISTS optimization_results_indexed_xstore (
algorithm_name VARCHAR(50),
execution_index INT,
best_solution TEXT,
best_score DOUBLE PRECISION,
iteration_count INT,
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (algorithm_name, execution_index)
) USING xstore;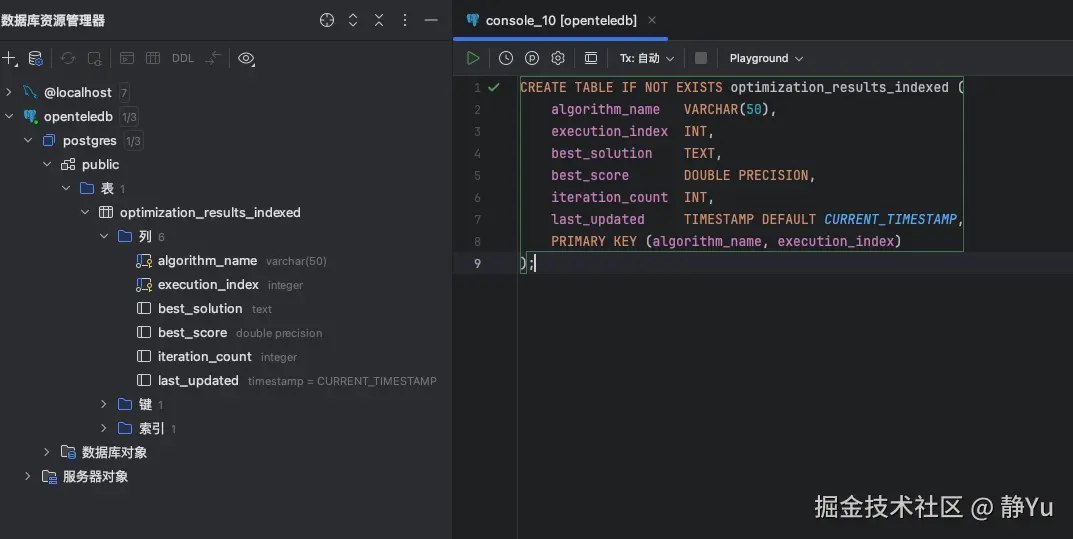
首次插入
生成了数据库表之后,就开始首次插入第一波模拟数据,分别在两张表中插入数据。
这条 SQL 语句的目的是向 optimization_results_indexed 和optimization_results_indexed_xstore表中插入 20,000 条模拟数据记录,模拟一个梯度下降优化算法的执行结果。在插入的过程中,首先为每一条记录指定了一个静态的算法名称 'gradient_descent',并通过 generate_series(1, 20000) 函数生成从 1 到 20,000 的整数序列,用作每条记录的 execution_index。接着,为 best_solution 字段设置了一个固定的 JSON 格式字符串 {"x": 1.23, "y": 4.56},代表每次优化算法得到的最佳解决方案。在 best_score 字段中,使用 random() * 100 生成一个介于 0 到 100 之间的随机分数,模拟每次优化过程中的得分。iteration_count 字段则通过 (random() * 1000)::INT 生成一个介于 0 到 1000 之间的随机整数,代表每次优化算法的迭代次数。最后,last_updated 字段被赋予当前时间戳 CURRENT_TIMESTAMP,表示每条记录的更新时间。整个查询语句将这 20,000 条记录插入到表中,用于模拟大量的优化算法执行结果和测试。
vbnet
INSERT INTO optimization_results_indexed (
algorithm_name,
execution_index,
best_solution,
best_score,
iteration_count,
last_updated
)
SELECT
'gradient_descent' AS algorithm_name,
gs AS execution_index,
'{"x": 1.23, "y": 4.56}' AS best_solution,
random() * 100 AS best_score,
(random() * 1000)::INT AS iteration_count,
CURRENT_TIMESTAMP
FROM generate_series(1, 20000) AS gs;
//Xstore存储引擎
INSERT INTO optimization_results_indexed_xstore (
algorithm_name,
execution_index,
best_solution,
best_score,
iteration_count,
last_updated
)
SELECT
'gradient_descent' AS algorithm_name,
gs AS execution_index,
'{"x": 1.23, "y": 4.56}' AS best_solution,
random() * 100 AS best_score,
(random() * 1000)::INT AS iteration_count,
CURRENT_TIMESTAMP
FROM generate_series(1, 20000) AS gs;执行完上面的代码后,打开数据库可视化操作工具,确认一下数据是否成功插入。可以看到,数据库中已经有了模拟生成的中间数据了。
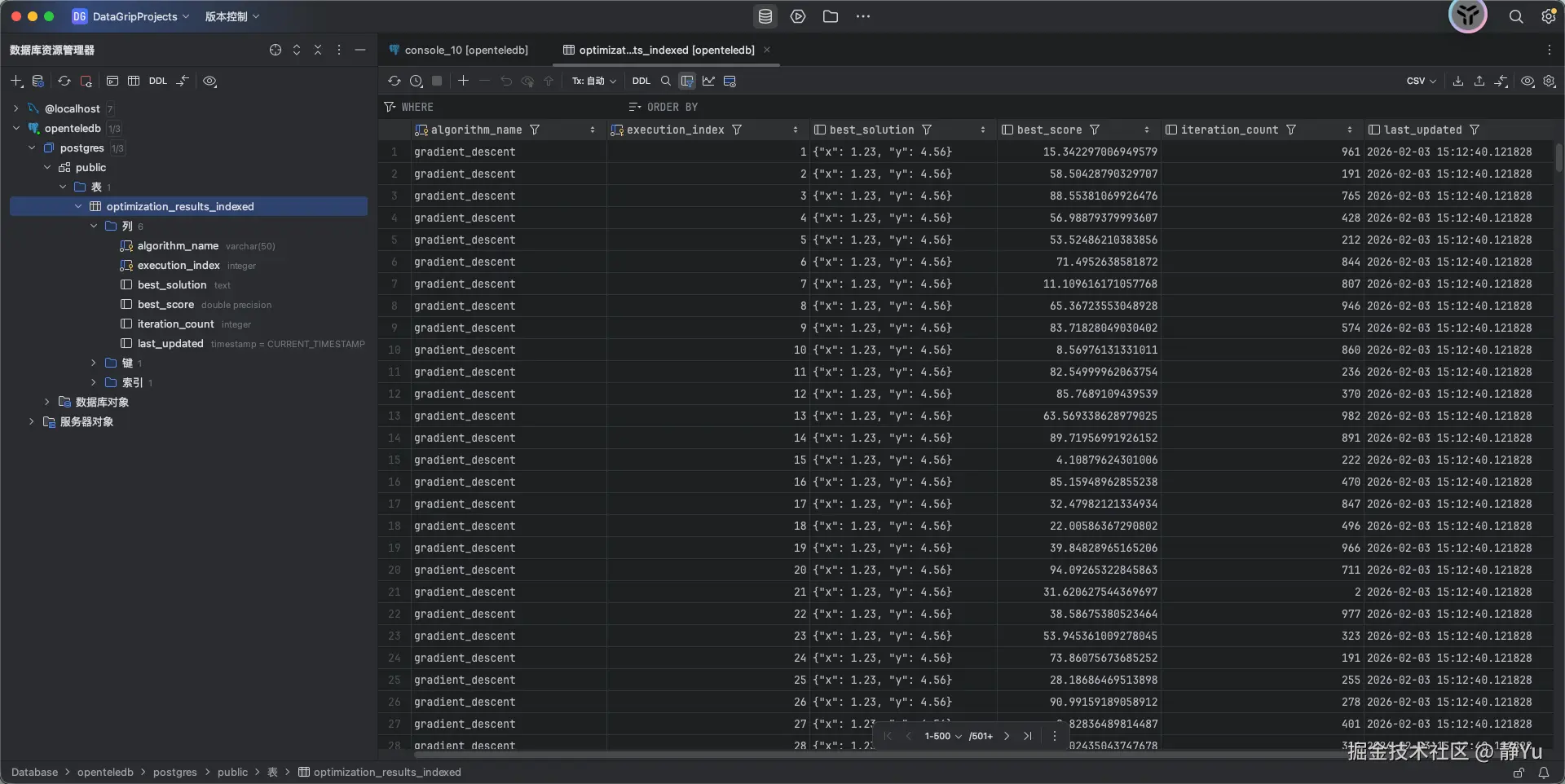
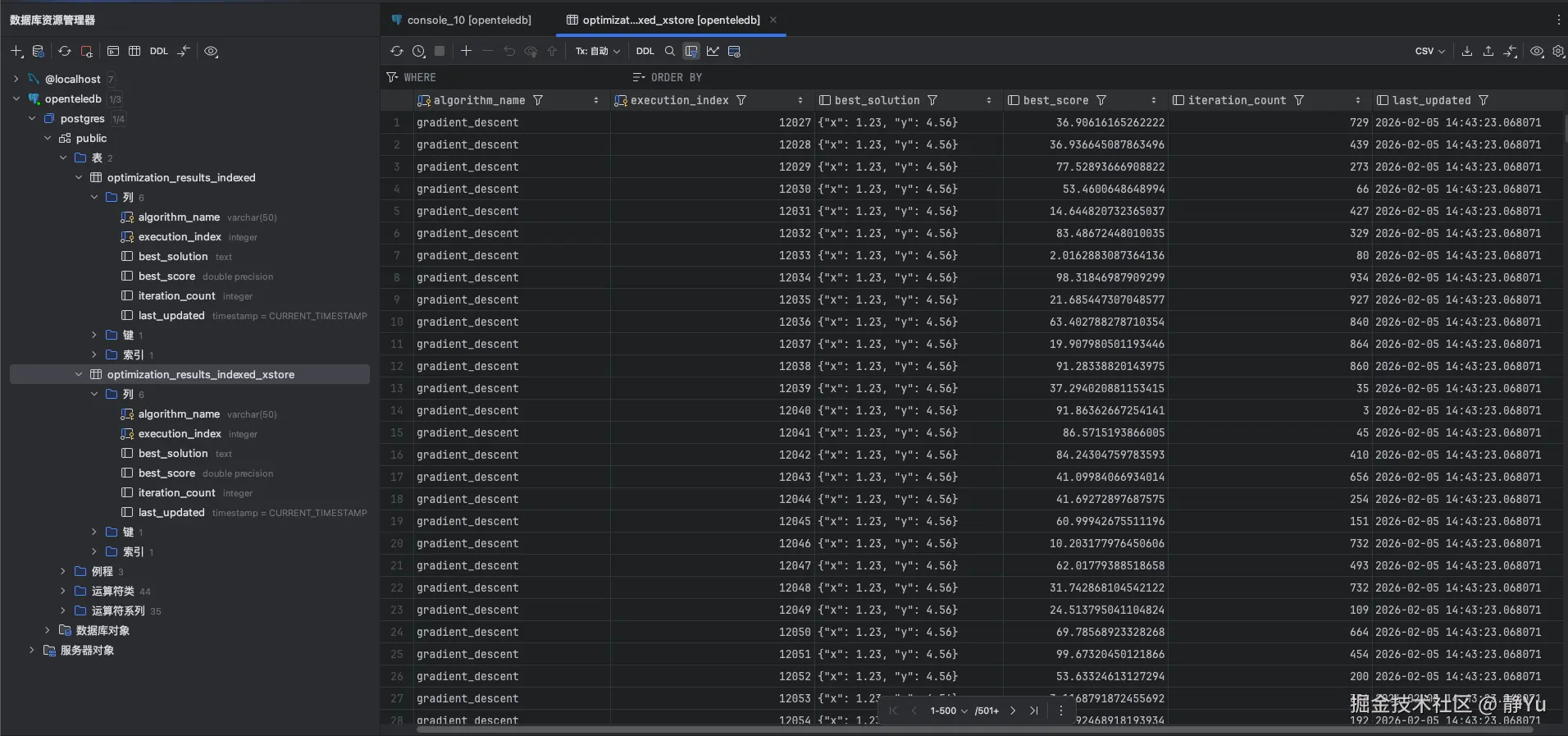
通过SELECT语句查询了一下表中的数据总条数。
sql
SELECT COUNT(*) FROM optimization_results_indexed;
SELECT COUNT(*) FROM optimization_results_indexed_xstore;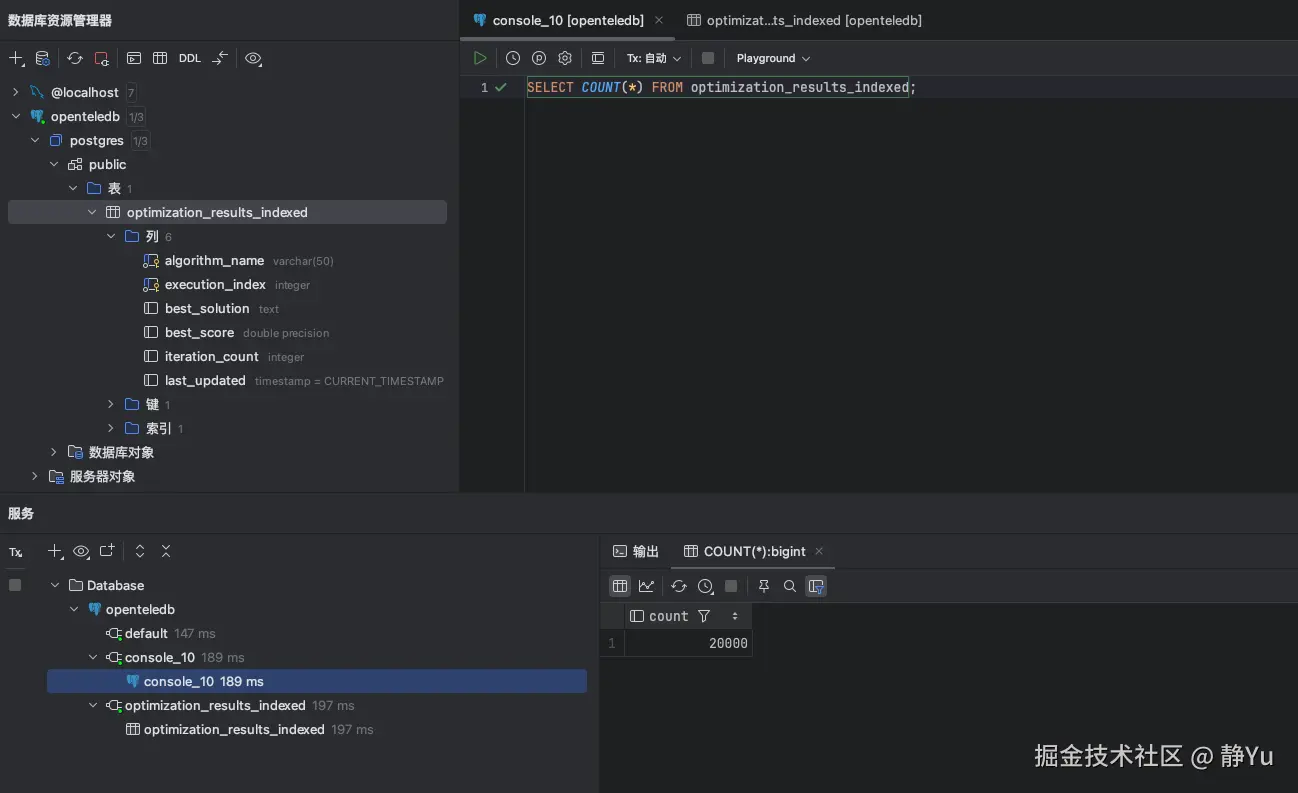
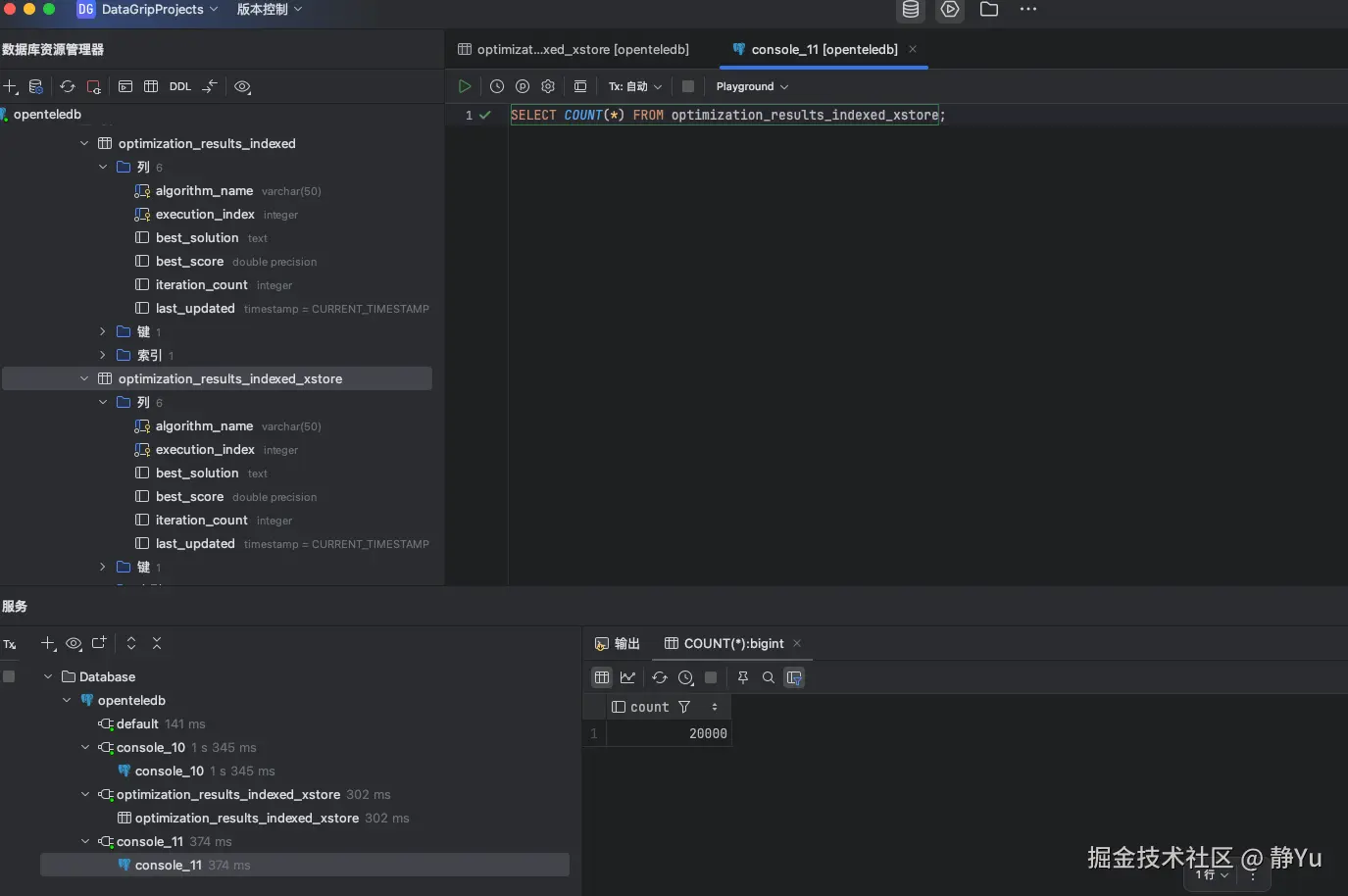
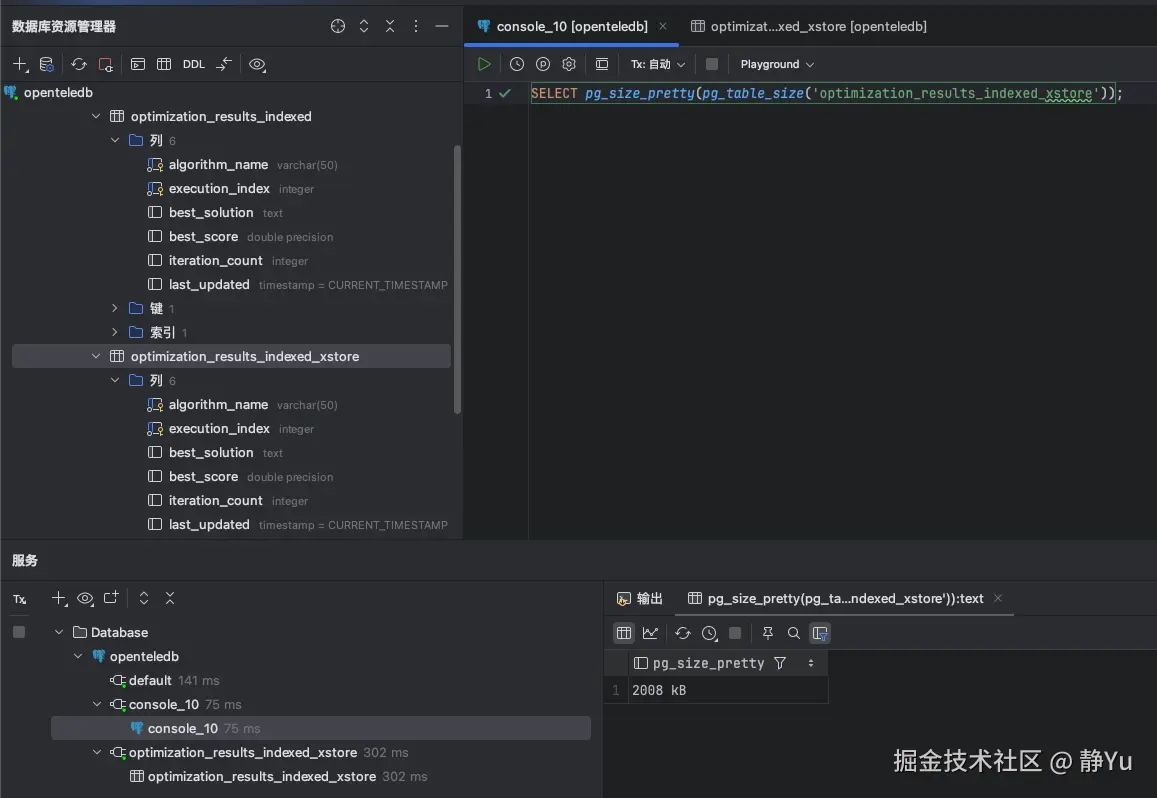
我的目的是为了验证多次更新海量数据,Xstore存储引擎在表空间膨胀方面的表现。所以执行完第一次优化算法之后,先去查一下两张表所占存储大小。
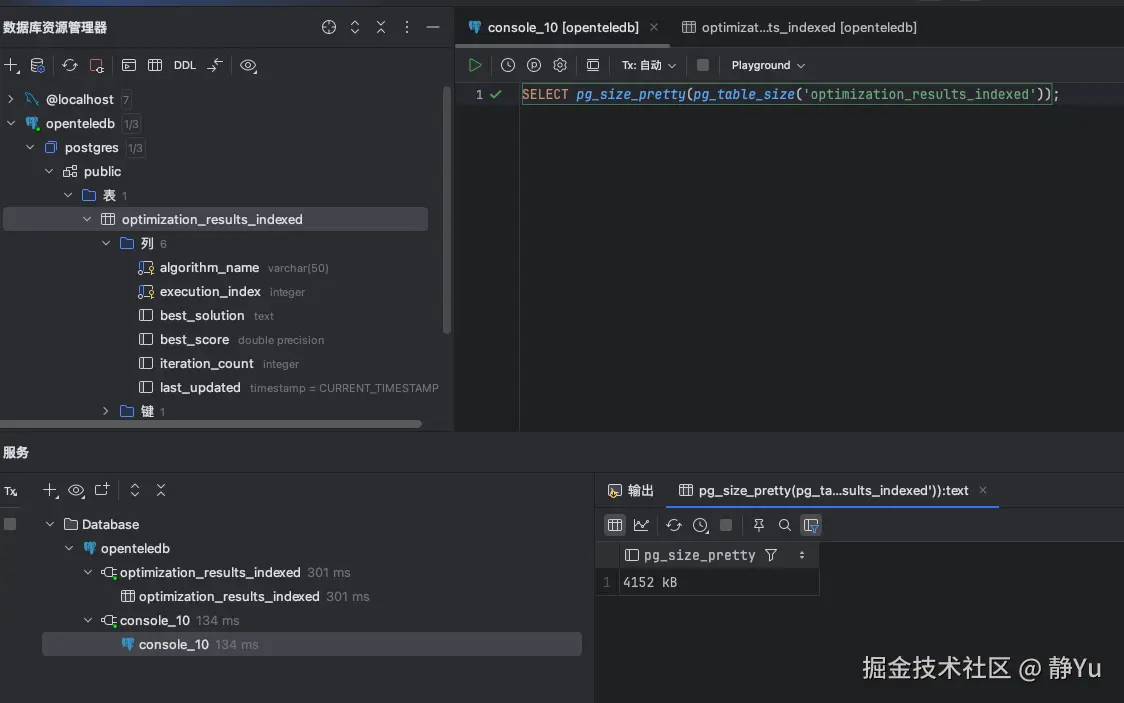
然后再通过命令查询一下optimization_results_indexed和optimization_results_indexed_xstore这两张表的存储大小,我们可以清晰的看到20000条数据分别所占用2016kB、2008kB大小,相差不大。
arduino
SELECT pg_size_pretty(pg_table_size('optimization_results_indexed'));
SELECT pg_size_pretty(pg_table_size('optimization_results_indexed_xstore'));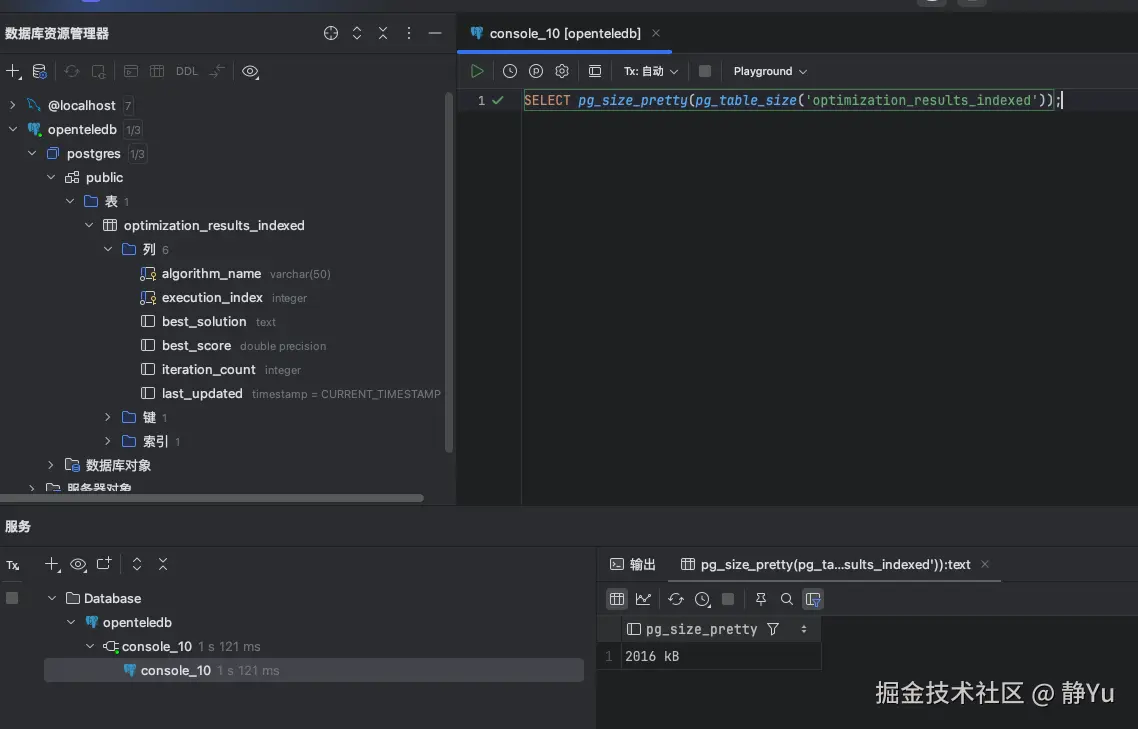
更新数据
为了验证OpenTeleDB的Xstore存储引擎在原位更新和表膨胀两个点的表现,现在实现一个更新SQL。
这条 SQL 语句用于更新 optimization_results_indexed 或optimization_results_indexed_xstore 表中 algorithm_name 为 'gradient_descent' 且 execution_index 在 1 到 20,000 之间的记录。更新内容包括:将 best_solution 字段设置为新的随机值(以 JSON 格式表示的 x 和 y 坐标),best_score 字段更新为一个新的随机分数(0 到 100 之间),iteration_count 字段增加一个随机整数(0 到 10 之间),并且将 last_updated 字段设置为当前时间戳。
ini
UPDATE optimization_results_indexed
SET
best_solution = format('{"x": %s, "y": %s}',
to_char(random(), 'FM999999999.0000'),
to_char(random(), 'FM999999999.0000')),
best_score = random() * 100,
iteration_count = iteration_count + (random() * 10)::INT,
last_updated = CURRENT_TIMESTAMP
WHERE algorithm_name = 'gradient_descent'
AND execution_index IN (
SELECT generate_series(1, 20000)
);
//Xstore存储引擎
UPDATE optimization_results_indexed_xstore
SET
best_solution = format('{"x": %s, "y": %s}',
to_char(random(), 'FM999999999.0000'),
to_char(random(), 'FM999999999.0000')),
best_score = random() * 100,
iteration_count = iteration_count + (random() * 10)::INT,
last_updated = CURRENT_TIMESTAMP
WHERE algorithm_name = 'gradient_descent'
AND execution_index IN (
SELECT generate_series(1, 20000)
);
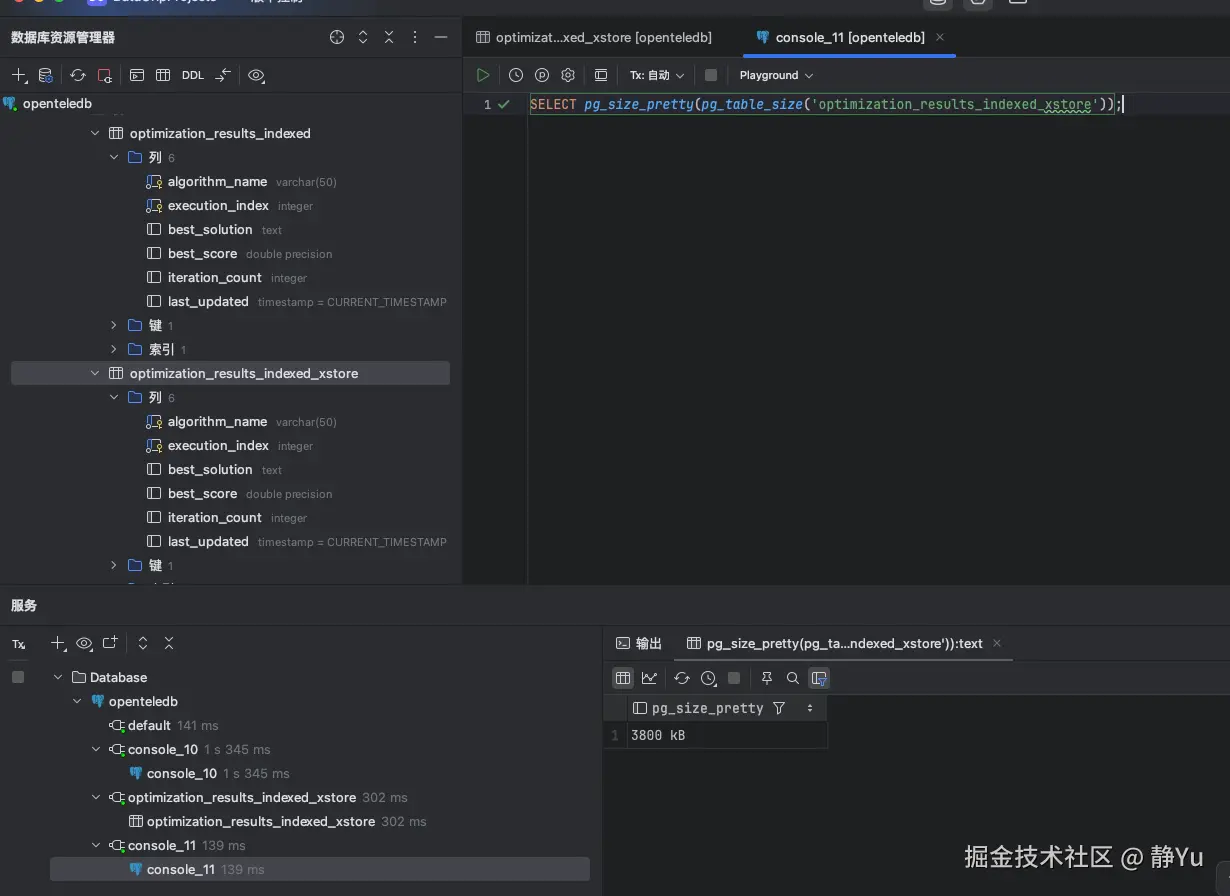
首先进行一次之后,我又重新查询了表空间的大小。可以看到两张表的空间都有一定的增加。其中每次优化算法产生的数据完全不一致,这很可能也是导致表增长的原因。
这只更新了一次,并不能说明什么问题,我要验证的是高频UPDATE。现在我再执行几次更新看看效果。
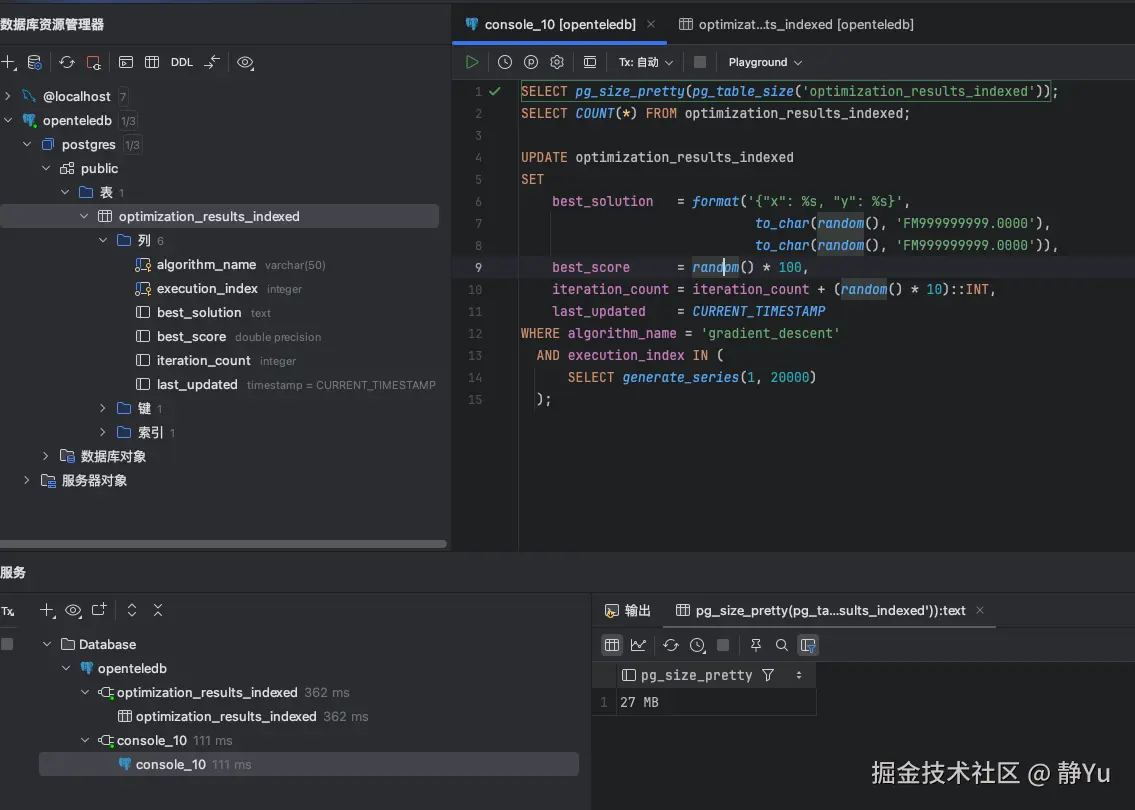
可以发现正常方式创建的表,表空间还是会一直增长的,然后我就一直执行一直执行,直到执行了三十次之后,数据表空间竟然达到了27MB。
然后我又用同样的方式对optimization_results_indexed_xstore执行了同样的三十次覆盖式更新操作。我惊喜的发现,表空间依旧是第一次更新之后的3800kB。
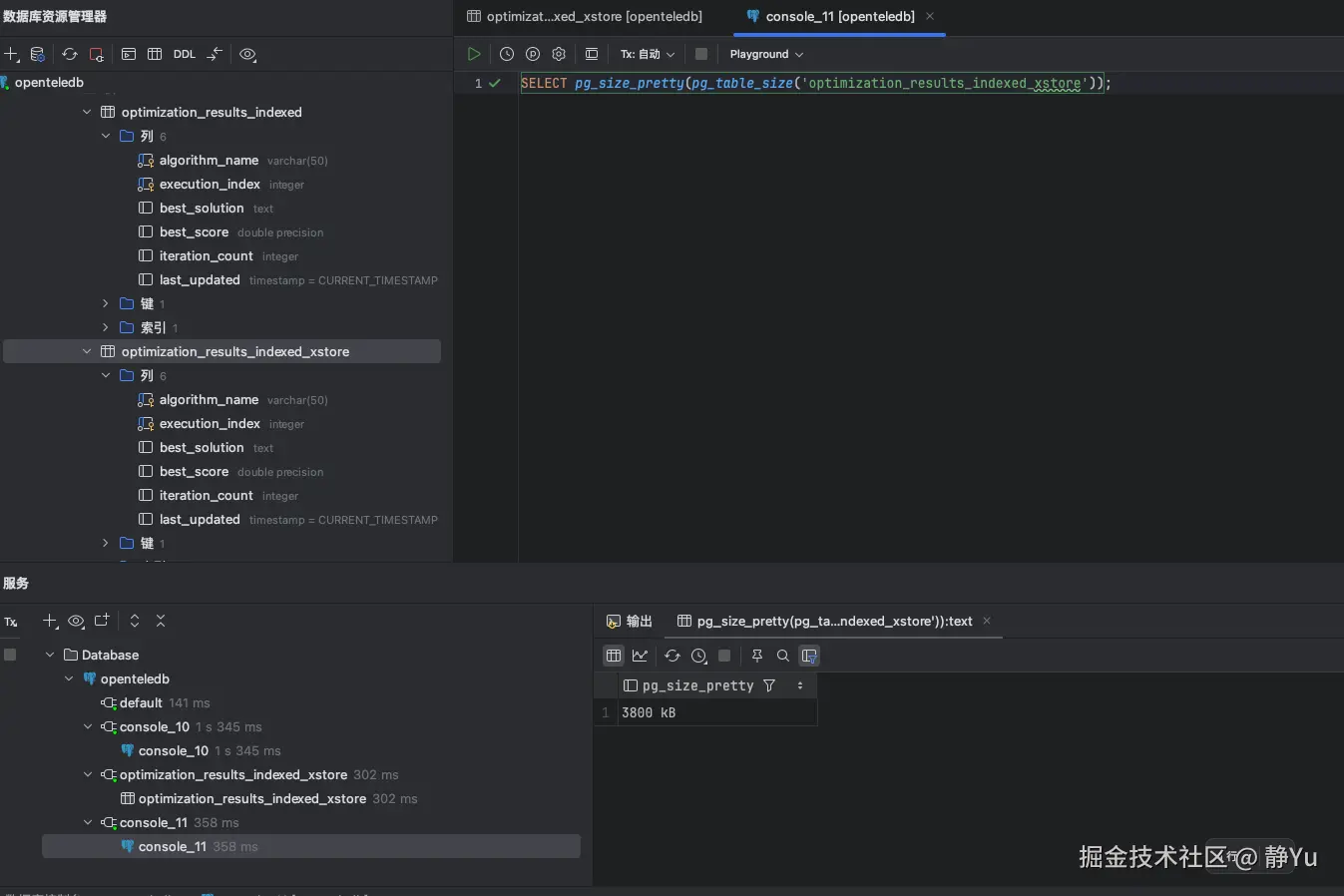
经过真实测试,答案已经显而易见了,Xstore存储引擎的原位更新真的做到了表空间几乎零增长。
optimization_results_indexed |
optimization_results_indexed_xstore |
|
|---|---|---|
| 第一次插入数据 | 2016kB | 2008kB |
| 第一次更新数据 | 4152kB | 3800kB |
| 更新30次数据 | 27MB | 3800kB |
结尾
说白了,这次测试一圈下来,Xstore 确实挺能"扛"的。我们这种反复更新、数据量大的业务,最怕的就是表一直膨胀,最后磁盘爆满、性能下滑。用 Xstore 之后,第一次更新虽然也会涨一点,但后面不管怎么频繁改数据,表大小基本就稳住了,再也没往上跑。对我们来说,这就是最实在的解决方案------不用总担心空间问题,也不用老想着扩容服务器。
如果你也在做仿真优化、实时计算、频繁迭代这类"写多改多"的系统,并且被 PostgreSQL 的:
- 表空间不断膨胀
- VACUUM 压力大、性能波动
- 磁盘很快被中间数据占满
这类问题困扰,那么 OpenTeleDB + Xstore 存储引擎 是一个值得认真考虑的选项。 它不是"魔法",但通过原位更新和优化的 UNDO 管理,实实在在地解决了高频更新场景下的存储膨胀问题。
如果你打算尝试,可以顺着这个思路走:
-
判断是否适用 如果你的业务是:UPDATE 远多于 INSERT、中间数据多、同一批数据反复重算、不想频繁清理或拆表。 如果你的痛点是:表膨胀快、VACUUM 影响性能、存储成本增长明显。 那 Xstore 很可能对你有用。
-
使用很简单,就两步
- 建表时加一句
USING xstore - 确保数据库里启用了
xstore扩展(CREATE EXTENSION IF NOT EXISTS xstore;) 其他代码、查询基本不用改,对应用透明。
- 建表时加一句
-
没必要全库换 只针对那种更新极度频繁的表使用 Xstore,其他普通表还是用原来的存储方式。这样既能解决痛点,也不引入不必要的复杂度。
技术选型没有最好的,但如果有某个特性正好对准你的业务痛点,那就值得一试。
Xstore 对我们这种"反复算、反复写"的场景来说,真的算是"对症下药"了。
如果你也遇到了类似的数据膨胀困扰,不妨搭个测试环境跑一跑,用真实数据验证一下,毕竟适合自己的才是最好的。