
笔记整理:杨再润,浙江大学硕士生,研究方向大语言模型后训练
论文链接:https://arxiv.org/pdf/2511.14256
发表会议:AAAI 2026
1. 动机
知识图谱推理(KGR)旨在通过对知识图谱进行逻辑推断来推导出新知识。知识图谱(KGs)以结构化形式表示实体与关系,为推理提供基础。然而,现实中的 KGs 往往大规模且不完整,导致推理不可靠。近年来,大型语言模型(LLMs)在复杂推理任务中表现出色,其强大的泛化能力和自然语言理解能力为 KGR 带来了新机遇。现有 LLM-based KGR 方法主要分为检索增强(retrieval-augmented)和协同增强(synergy-augmented)两类。前者从 KGs 中检索相关三元组或多跳路径,并将其转化为 LLM 提示;后者将 LLM 视为Agent,通过迭代与 KGs 交互探索推理路径。尽管这些方法取得了进展,但仍存在两大局限:
(1)检索增强方法往往无差别提取推理路径,无法评估路径重要性,可能引入无关噪声误导 LLM,例如在查询"Amazon 在全球市场上的竞争对手是哪家公司?"时,路径 Amazon → invest_in → Retail → invest_by → Walmart 明确表示竞争,而 Amazon → partner → Google → partner → Walmart 可能暗示合作,造成误导;
(2)协同增强方法虽能动态发现路径,但需高检索需求和多次 LLM 调用,计算开销大,限制实际应用。
该论文提出 PathMind 框架,采用"Retrieve-Prioritize-Reason"范式,通过选择性引导 LLM 使用重要推理路径,提升推理的忠实度和可解释性。
2. 贡献
(1)引入 PathMind 框架,利用重要推理路径有效引导 LLM 进行准确逻辑推理,提升推理的忠实度和可解释性。
(2)提出路径优先级机制,通过同时建模累积成本和未来成本估计来识别重要推理路径,并通过任务特定指令微调和路径偏好对齐进一步提升 LLM 性能。
(3)在广泛使用的 KGR 基准数据集上进行实验,结果显示 PathMind 在复杂推理任务中优于强基线,尤其在输入token更少的情况下,通过识别关键推理路径实现高效推理。
3. 方法
PathMind 框架的核心思想是提出一种"Retrieve-Prioritize-Reason"的范式,它通过子图检索、路径优先级机制和知识推理模块来提升逻辑一致性与可解释性。与传统方法相比,PathMind 不再依赖无差别的路径检索,也避免了多次调用模型带来的高昂计算成本,而是以一种更精炼的方式完成推理。
3.1 子图检索模块
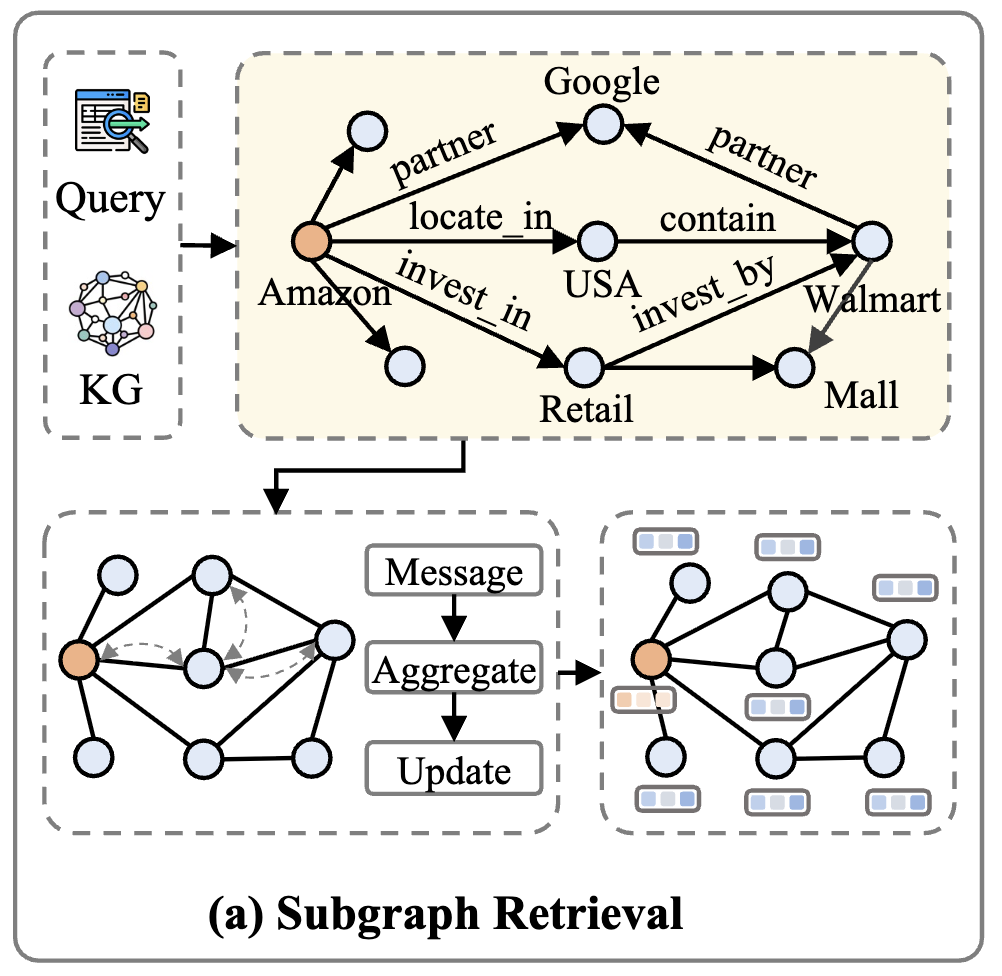
在面对一个查询时,PathMind 首先会在知识图谱中构建与该查询相关的子图。它以查询中的主题实体为起点,检索其多跳邻域,并将这些邻域节点合并为子图节点集,再提取这些节点之间的边和三元组。为了让这些结构信息能够被模型有效利用,系统使用图神经网络对节点和关系进行编码。通过逐层的消息传递和聚合,节点表示不断更新,最终形成包含丰富语义和结构的子图表示。这一步骤的意义在于缩小搜索空间,同时保留与问题最相关的上下文信息。
3.2 路径优先级模块
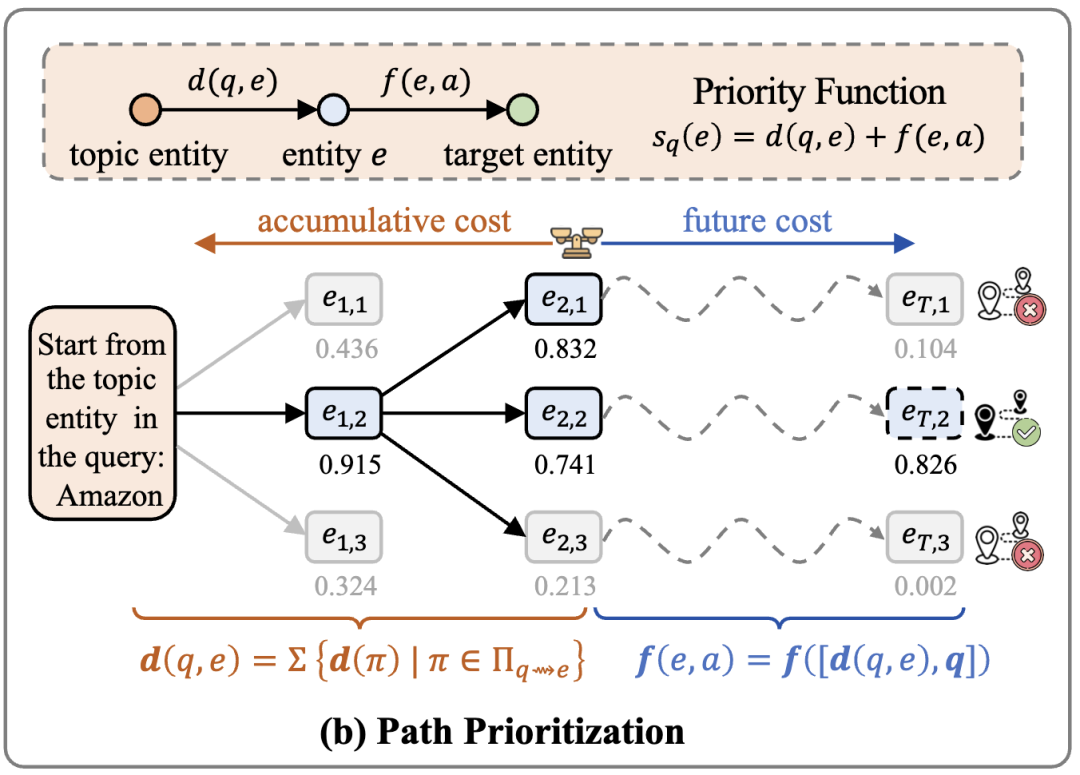
在子图中可能存在大量的推理路径,但并非所有路径都对回答问题有帮助。PathMind 的创新之处在于引入语义感知的路径优先级机制。它借鉴了 A* 搜索的思想,将路径的重要性分为两部分:一是累积成本,用来衡量从查询实体到当前节点的路径语义相关性;二是未来成本,用来估计从当前节点到目标答案的潜在距离。通过神经网络建模,这两部分被结合为一个优先级分数。在训练过程中,模型会被监督去识别哪些路径更可能通向正确答案。这样,在推理时系统只选择最重要的路径,而不是无差别地使用所有路径,从根本上减少了噪声的干扰。
累积成本定义为:
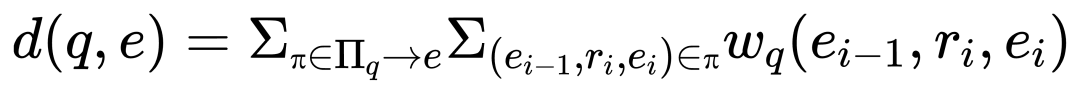
其中,三元组的语义权重为:
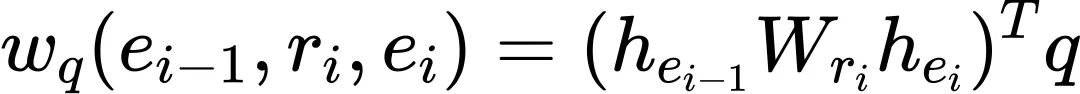
未来成本通过前馈神经网络估计:
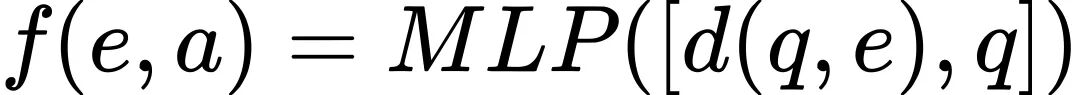
最终的优先级分数为:
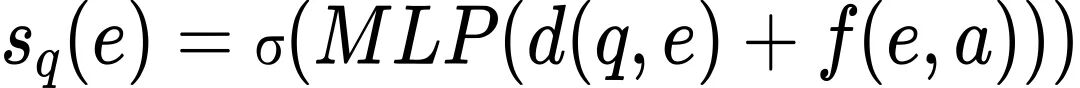
在训练过程中,模型通过监督学习优化路径选择,损失函数为:
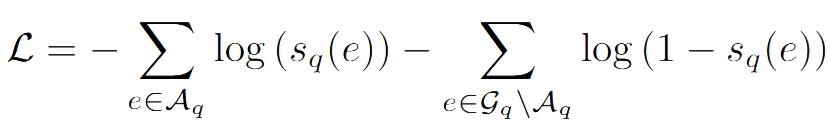
3.3 知识推理模块
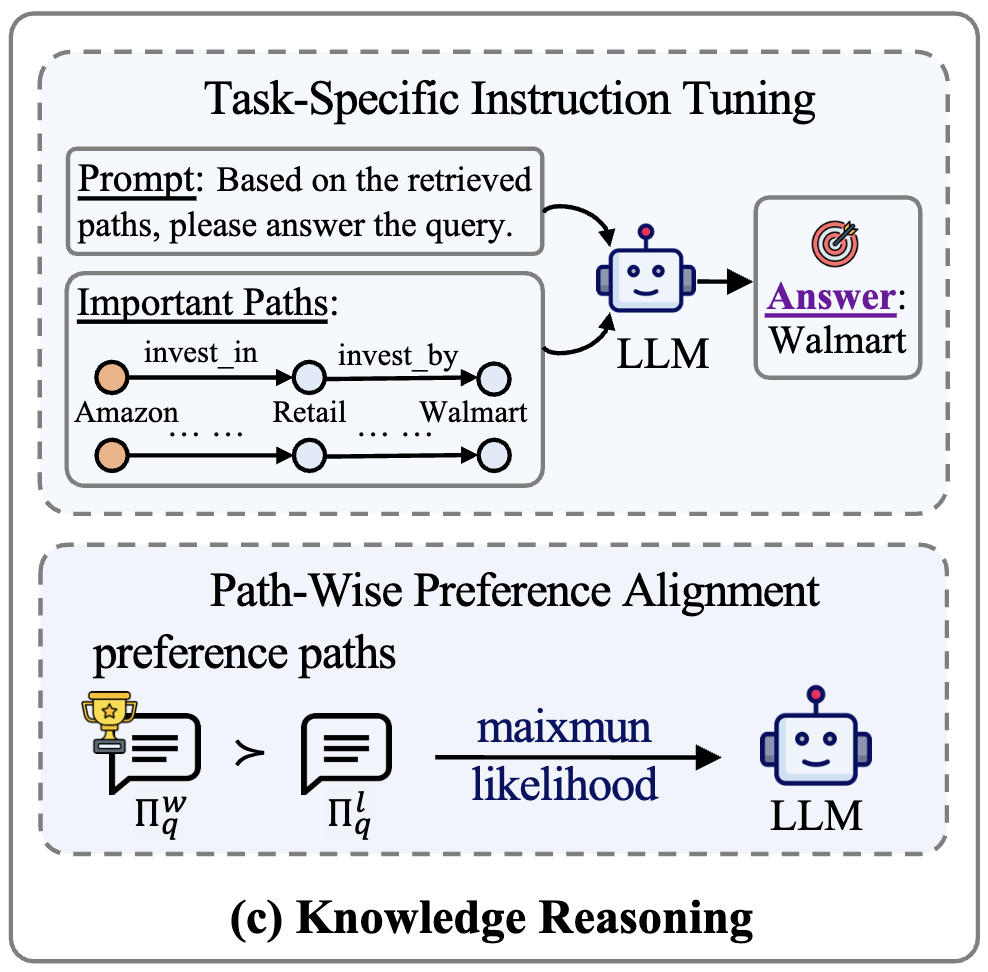
在获得重要路径之后,PathMind 通过双阶段训练来引导大语言模型进行推理。第一阶段是任务特定指令微调,它将查询和重要路径转化为文本提示,输入到模型中,让模型学习在这些提示下生成正确答案。第二阶段是路径偏好对齐,它通过构造偏好对来优化模型的响应质量:重要路径作为正例,随机或次优路径作为负例。经过这样的训练,模型不仅能够回答问题,还能保持逻辑一致性,更倾向于依赖真正有价值的路径进行推理。最终,PathMind 能够在一次调用中生成准确答案,避免了传统协同增强方法中多次调用模型的高成本。
4. 实验
4.1 实验设置
在 WebQuestionSP (WebQSP) 和 Complex WebQuestions (CWQ) 数据集上评估,使用 Hits@1 和 F1 指标。基线包括传统 KGR 方法(如 KVMem, NSM)和 LLM-based 方法(如 Qwen2-7B, RoG, GNN-RAG)。使用 Llama3.1-8B 作为 LLM 骨干,子图检索采样 3 跳邻域,路径优先级使用 GNN 学习表示,top-K=3,迭代 T=2 (WebQSP) 或 4 (CWQ)。训练 3 轮,学习率 2e-5 (SFT) 或 5e-6 (DPO)。
4.2 整体比较
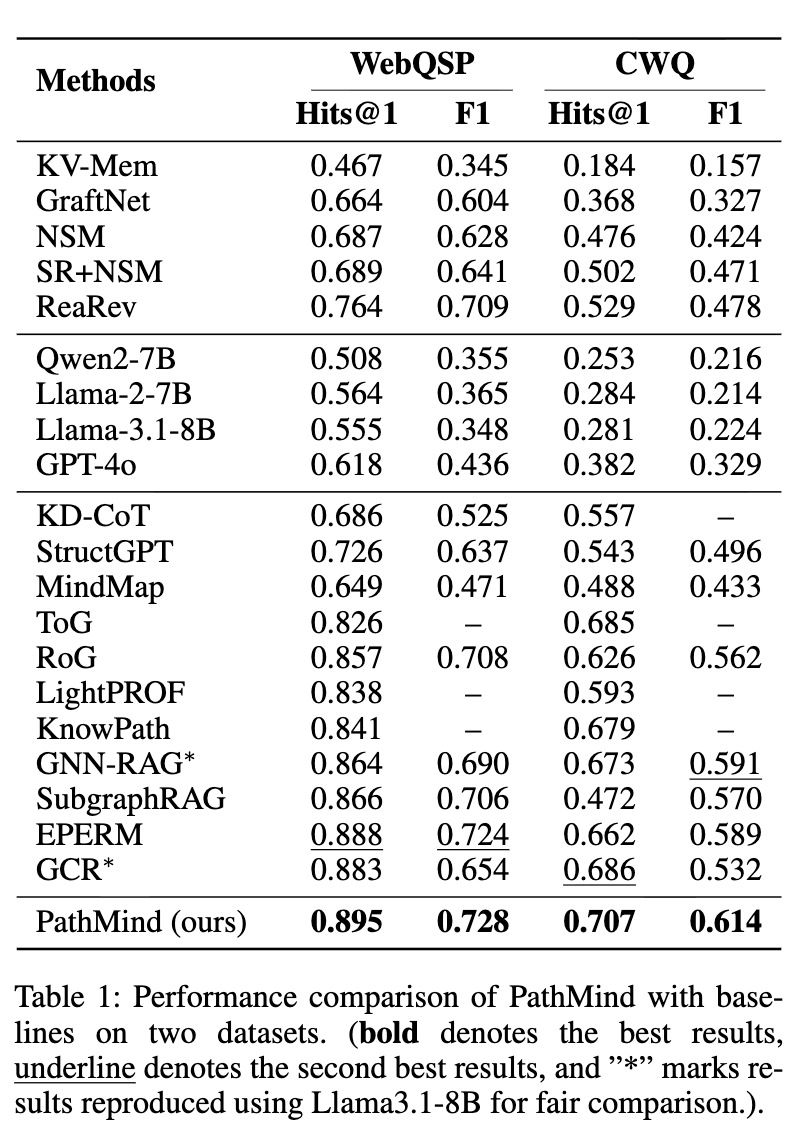
表 1 显示 PathMind 在 WebQSP 上 Hits@1 达 0.895 (提升 0.8% over EPERM),F1 达 0.728 ;在 CWQ 上 Hits@1 达 0.707 (提升 5.1% over GNN-RAG),F1 达 0.614 (提升 3.9%)。PathMind 在复杂多跳任务中表现优异,优于检索增强(如 GCR)和协同增强(如 ToG)方法。传统方法中,检索-based 优于 embedding-based。
结果(表 1)显示,PathMind 在节点分类、链路预测、图分类等任务上均取得一致提升。
4.3 消融研究
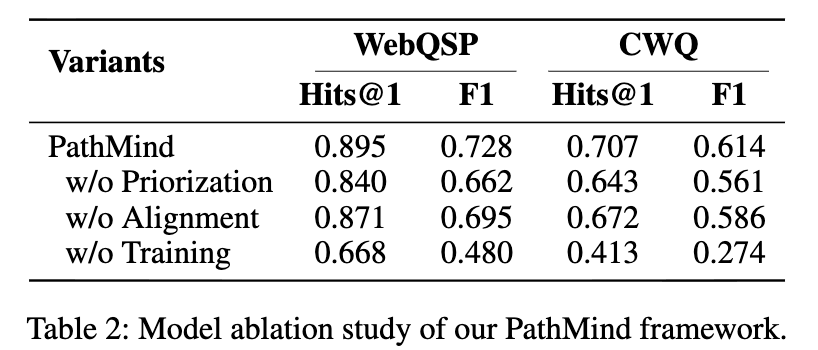
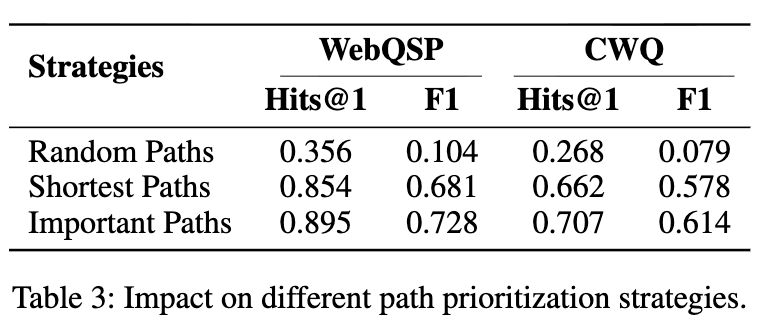
表 2 显示移除路径优先级导致 WebQSP Hits@1 降至 0.840 ,移除对齐降至 0.871 ,移除训练降至 0.668 ,验证各模块必要性。表 3 显示重要路径优于随机路径 (Hits@1 0.356 ) 和最短路径 (0.854),在 CWQ 上差距更显著。
4.4 进一步分析
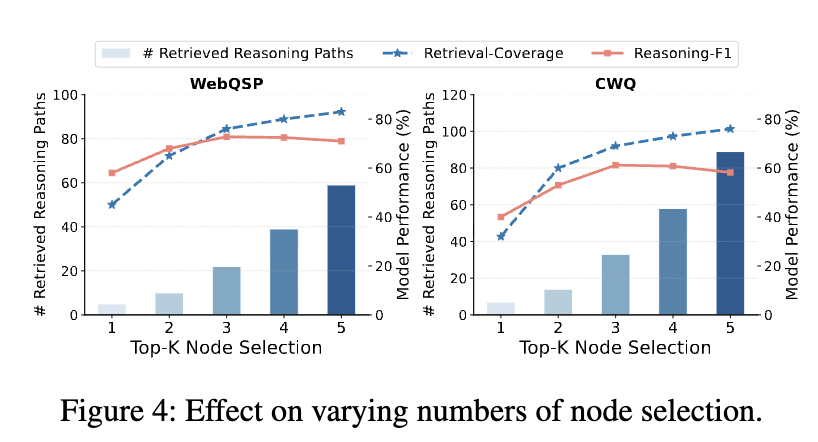
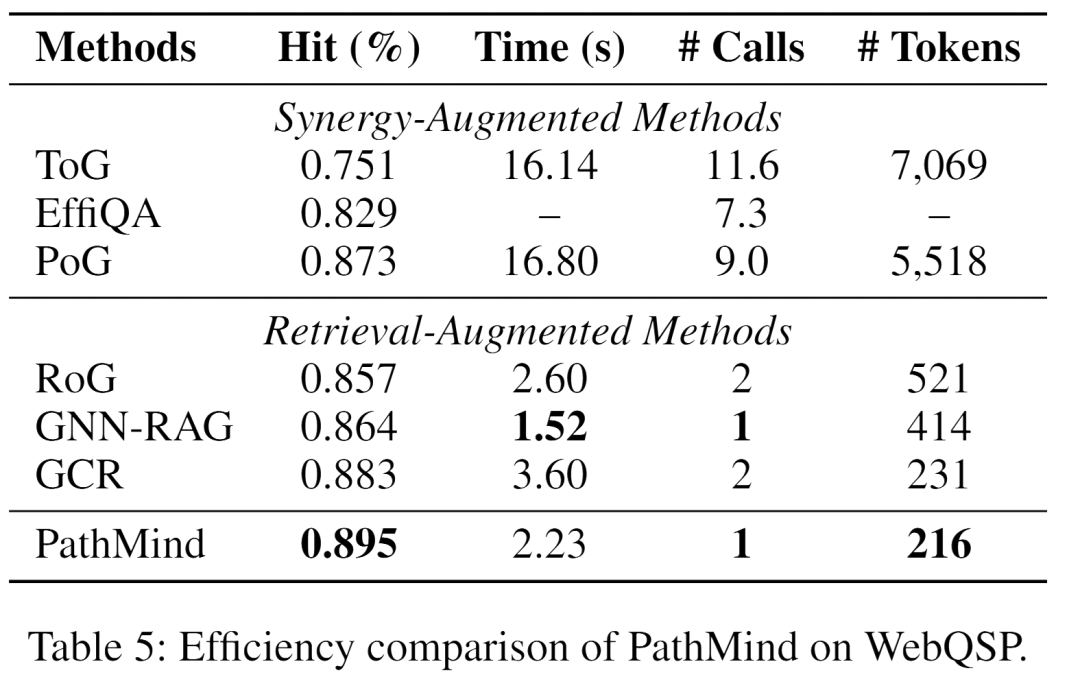
图 4 显示K=3时性能最佳,超过 3 后 F1 下降因引入无关实体。表 5 显示 PathMind 运行时 2.23 s ,LLM 调用 1 次 ,输入token 216,优于协同增强方法(如 PoG 调用 9 次,5,518 token)。
5. 总结
本文提出 PathMind 框架,通过"Retrieve-Prioritize-Reason"范式整合 LLM 和 KG,提升 KGR 的忠实度和可解释性。框架包括子图检索、路径优先级和知识推理模块,前者提取查询相关子图,后者使用语义感知优先级函数识别重要路径,最后通过双阶段训练(指令微调和偏好对齐)引导 LLM 生成准确响应。实验在 WebQSP 和 CWQ 上验证 PathMind 优于基线,尤其在复杂任务和效率上。未来可扩展到更大数据集和多模态场景。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。