
🍃 予枫 :个人主页
📚 个人专栏 : 《Java 从入门到起飞》《读研码农的干货日常》
💻 Debug 这个世界,Return 更好的自己!
在使用 Redis 时,
String是我们最常用的数据类型。无论是缓存用户信息、计数器,还是存储 Session,SET和GET命令无处不在。但你是否想过:Redis 是用 C 语言写的,而 C 语言本身就有字符串(以
\0结尾的字符数组),为什么 Redis 的作者 Antirez 还要特意发明一种叫 SDS(Simple Dynamic String)的数据结构来替代它?在这篇文章中,我们将深入 Redis 7.0 源码,揭开 String 背后的 SDS 和 RedisObject 的面纱。
文章目录
-
- [一、 痛点:原生 C 语言字符串的"三宗罪"](#一、 痛点:原生 C 语言字符串的“三宗罪”)
- [二、 解法:SDS (简单动态字符串)](#二、 解法:SDS (简单动态字符串))
-
- [1. SDS 的核心结构](#1. SDS 的核心结构)
- [2. SDS 的三大优势](#2. SDS 的三大优势)
- [三、 进阶:RedisObject 与 SDS 的关系](#三、 进阶:RedisObject 与 SDS 的关系)
-
- [1. redisObject 结构体](#1. redisObject 结构体)
- [2. String 的三种"变身"(Encoding)](#2. String 的三种“变身”(Encoding))
- [四、 源码实战:SDS 的扩容策略](#四、 源码实战:SDS 的扩容策略)
- [五、 总结](#五、 总结)
一、 痛点:原生 C 语言字符串的"三宗罪"
Redis 是一个追求极致性能的内存数据库,而 C 语言原生的字符串(char*)在性能和安全性上存在三个致命缺陷:
- 获取长度太慢 :
C 语言通过遍历直到遇到\0来计算长度。如果键值对有 100 MB,获取长度就需要遍历 1 亿个字节,这对于单线程的 Redis 是不可接受的。 - 缓冲区溢出(Buffer Overflow) :
如果你在这个字符串后面拼接内容,但忘记重新分配内存,就会直接覆盖相邻内存的数据,导致系统崩溃。 - 二进制不安全 :
C 字符串以\0作为结束符。如果你想存一张 JPEG 图片或一段视频流(里面可能包含0x00字节),C 语言会误以为字符串结束了,导致数据截断。
二、 解法:SDS (简单动态字符串)
为了解决上述问题,Redis 设计了 SDS (Simple Dynamic String) 。它不仅仅是一个字符串,更像是一个 Java 中的 ArrayList。
1. SDS 的核心结构
在 Redis 源码 sds.h 中,SDS 并不是一个简单的 char 数组,而是一个带"头部元数据"的结构体。
为了极致节省内存,Redis 定义了 sdshdr5, sdshdr8, sdshdr16, sdshdr32, sdshdr64 五种结构。以最常用的 sdshdr8 为例:
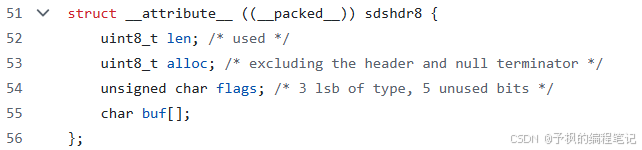
c
// 定义在 sds.h
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 当前已使用的字节数(解决 O(N) 长度问题)
uint8_t alloc; // 当前分配的总内存大小(不含头和 \0)
unsigned char flags; // 低3位表示类型,高5位保留
char buf[]; // 柔性数组,真正存数据的地方
};注意:
__attribute__ ((__packed__))是 GCC 的扩展语法,告诉编译器 不要进行字节对齐,按照变量实际大小紧凑排列。这是为了节省每一个字节的内存。
2. SDS 的三大优势
- 获取长度 :直接读取
len字段即可,无需遍历。 - 二进制安全 :SDS 通过
len判断字符串结束,而不是\0。这意味着你可以放心地把序列化对象、图片存入 Redis。 - 杜绝溢出 & 内存预分配 :在修改字符串前,SDS API 会检查
alloc - len是否足够。如果不够,它会自动扩容。
三、 进阶:RedisObject 与 SDS 的关系
这是一个高频面试题:String 类型和 SDS 是一回事吗?
答案:不是。
- SDS 是底层的 物理存储结构(负责存数据)。
- String 是 Redis 对外暴露的 逻辑对象 ,在源码中叫
redisObject。
1. redisObject 结构体
所有的 Redis 键值对(String, Hash, List, Set, ZSet)都必须包裹在 redisObject 中:

c
// 定义在 server.h
typedef struct redisObject {
unsigned type:4; // 对象类型 (OBJ_STRING)
unsigned encoding:4; // 编码方式 (INT, EMBSTR, RAW)
unsigned lru:LRU_BITS; // 用于 LRU 淘汰算法
int refcount; // 引用计数
void *ptr; // 【关键】指向底层数据的指针
} robj;2. String 的三种"变身"(Encoding)
为了进一步优化内存,Redis 会根据 String 内容的长度和类型,决定 ptr 指针指向哪里,以及 redisObject 如何存储。
| 编码方式 | 场景 | 内存布局结构 | 优势 |
|---|---|---|---|
| INT | 存储整数值 (如 set age 25) |
ptr 直接存储 long 类型的值。 |
只有 redisObject,不需要 SDS,最省内存。 |
| EMBSTR | 字符串长度 44 字节 | redisObject 和 SDS 连在一起,只申请一次内存。 |
减少内存碎片,利用 CPU 缓存行加速。 |
| RAW | 字符串长度 > 44 字节 | redisObject 和 SDS 分开存储,申请两次内存。 |
适合大字符串,修改时只需重分配 SDS 部分。 |
思考题:为什么界限是 44 字节?
CPU 缓存行通常是 64 字节。
redisObject(16字节) +sdshdr8(3字节) +\0(1字节) = 20字节。字节。
结论: 只要内容不超过 44 字节,整个对象就能塞进一个 CPU Cache Line,读写速度起飞!
四、 源码实战:SDS 的扩容策略
如果我们要在代码中模拟 SDS 的扩容逻辑,它大概长这样。这也是为什么 Redis 写操作很快的原因------预分配策略。
c
/* 模拟 SDS 的扩容逻辑伪代码 */
sds sdsMakeRoomFor(sds s, size_t addlen) {
// 1. 获取当前剩余可用空间
size_t free = sdsavail(s);
// 2. 如果剩余空间足够,直接返回,无需扩容
if (free >= addlen) return s;
// 3. 计算新长度
size_t len = sdslen(s);
size_t newlen = (len + addlen);
// 4. 【核心策略】预分配算法
if (newlen < 1024 * 1024) {
// 如果新长度小于 1MB,则成倍扩容 (Greedy)
newlen *= 2;
} else {
// 如果新长度大于 1MB,每次只多给 1MB
newlen += 1024 * 1024;
}
// 5. 调用 realloc 重新分配内存
// 注意:这里可能原地扩展,也可能搬迁内存地址
s = sds_realloc(s, newlen);
return s;
}策略总结:
- 空间换时间:通过多分配内存,避免下次追加数据时再次触发系统调用(malloc/realloc 是昂贵的操作)。
- 惰性释放 :当字符串缩短时(如
TRIM操作),SDS 不会立即归还内存,而是修改len,保留alloc供未来使用。
五、 总结
回到我们最开始的问题:
- SDS 是 Redis 的基石:它解决了 C 语言字符串的不安全和低效问题。
- 对象头
redisObject是管家:它负责管理类型和编码。 - 编码转换是核心优化:
- 存 ID(纯数字):Redis 自动用 INT 编码。
- 存 Token(短字符串):Redis 自动用 EMBSTR 编码(快)。
- 存文章正文(长字符串):Redis 自动用 RAW 编码(稳)。
理解了 SDS,你就理解了为什么 Redis 能在单线程下做到每秒处理数万次读写。这不仅仅是数据结构的设计,更是对操作系统内存管理和 CPU 缓存机制的极致利用。
(本文完)
博主的话:
如果你在面试中被问到"Redis String 的底层实现",千万不要只回答"SDS"。一定要把 redisObject 、3种编码切换 以及 44字节的由来 讲清楚,这才是能让你脱颖而出的亮点。
关注 予枫,带你用 Java 后端的视角看懂底层源码!