从文本生成器到自主决策者:Agentic RL如何重塑大语言模型的智能边界
本文深度解读2025年重磅综述《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》(arXiv:2509.02547),揭示LLM智能体化演进的核心范式转变与技术全景
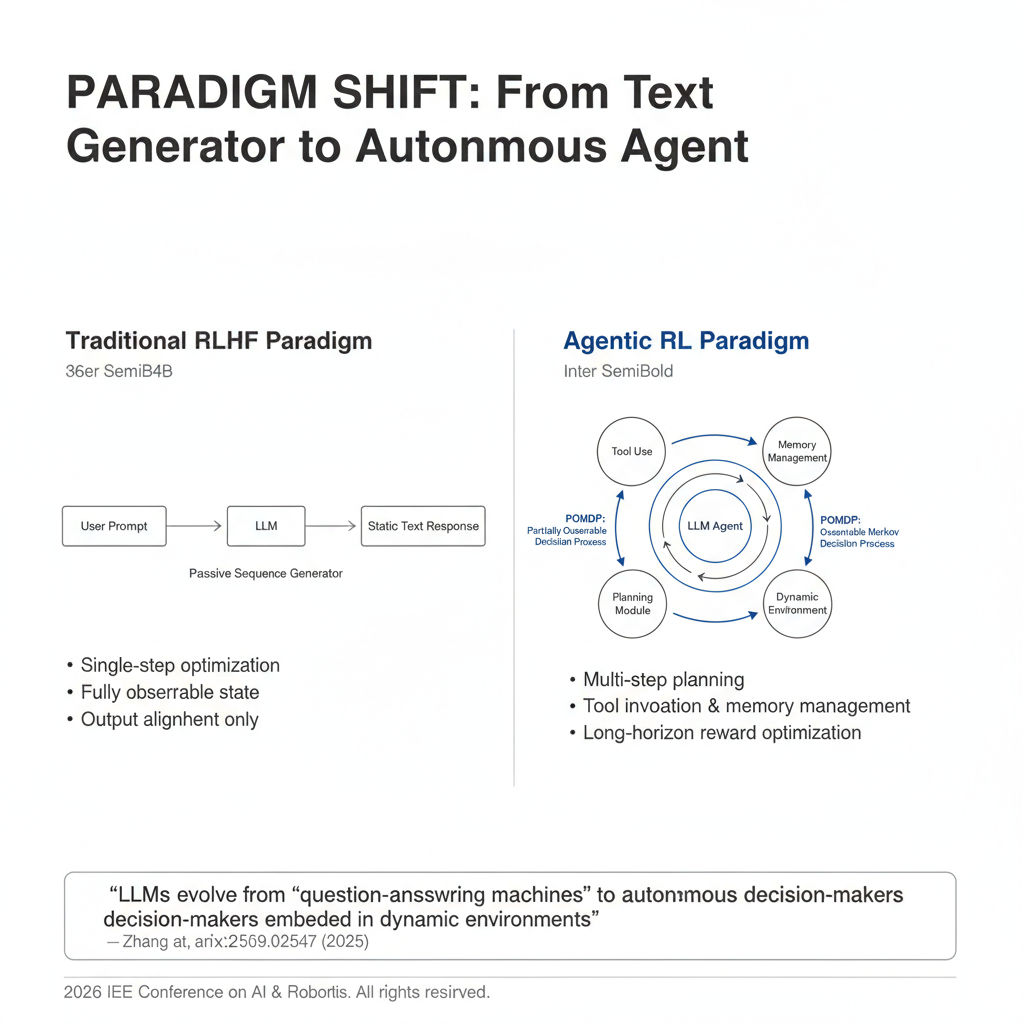
一、范式革命:当LLM不再只是"文本生成器"
2025年9月,由Guibin Zhang等25位研究者联合发表的综述《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》在AI社区引发广泛关注。这篇长达100页(不含参考文献约50页)的巨著,系统梳理了500余项前沿研究,首次为"智能体强化学习"(Agentic Reinforcement Learning, Agentic RL)建立了完整的理论框架与技术图谱 \[4]。
核心洞见直指本质 :传统RLHF等方法将LLM视为"被动序列生成器",仅优化单次输出的对齐度;而Agentic RL则将LLM重新定义为嵌入动态环境中的自主决策智能体------它需要在部分可观测的世界中进行多步规划、工具调用、记忆管理,并为长期目标优化行为策略 \[1]。
这一转变不仅是技术升级,更是认知范式的跃迁:LLM从"问答机器"进化为能在复杂环境中持续交互、自主决策的通用智能体。
二、理论基石:MDP vs POMDP------为何单步优化不够用?
综述最精妙的贡献在于用严格的数学形式化区分了两种RL范式:
| 维度 | 传统LLM-RL (如RLHF) | Agentic RL |
|---|---|---|
| 决策过程 | 退化的单步MDP(T=1) | 时序扩展的POMDP(T>1) |
| 状态可观测性 | 完全可观测(仅用户Prompt) | 部分可观测(需通过观测推断真实状态) |
| 状态转移 | 无转移(生成后即结束) | 概率性动态转移 P(st+1∣st,at)P(s_{t+1}|s_t,a_t)P(st+1∣st,at) |
| 动作空间 | 仅文本生成 Atext\mathcal{A}_{text}Atext | 文本生成 + 环境操作 Atext∪Aaction\mathcal{A}{text} \cup \mathcal{A}{action}Atext∪Aaction |
| 奖励结构 | 单次稀疏奖励 r(a)r(a)r(a) | 时序累积奖励 ∑t=0T−1γtR(st,at)\sum_{t=0}^{T-1} \gamma^t R(s_t,a_t)∑t=0T−1γtR(st,at) |
| 优化目标 | 单步期望奖励最大化 | 折扣累积奖励长期优化 |
关键差异示例:
- 传统RLHF:用户问"爱因斯坦生平",模型生成一段文本后任务结束
- Agentic RL:智能体需在Web环境中多步操作------先搜索"Einstein biography",解析结果页,调用计算器验证出生年份,最后整合信息生成答案,每步动作改变环境状态 \[5]
这种POMDP建模使LLM必须处理信用分配问题(credit assignment):最终任务成功时,如何将奖励合理分配给中间步骤?这催生了密集奖励设计、过程监督等关键技术。
三、六大核心能力:Agentic RL如何塑造智能体行为
综述提出双维度分类体系,其中"能力维度"系统整合了RL如何将静态模块转化为自适应行为:
1. 规划(Planning)
- 传统方法:人工设计思维链(Chain-of-Thought)模板
- Agentic RL方案:将LLM本身视为策略网络,通过环境交互直接优化长程规划能力。例如AgentFly框架让模型在WebArena中自主拆解"订机票"任务为搜索、比价、支付等子步骤 \[9]
2. 工具使用(Tool Use)
- 关键突破:从"模仿固定模式"到"自主决策调用时机"
- RL机制:通过结果驱动优化,智能体学会在数学任务中适时调用计算器、在代码任务中触发单元测试。实验显示,经RL训练的Qwen2.5-7B在工具调用频率上提升37%,错误率下降22% \[16]
3. 记忆(Memory)
- 范式转变:从被动检索到主动管理
- RL优化点:智能体学习何时存储关键信息(如用户偏好)、何时检索历史对话、何时遗忘过期数据。例如MemGPT通过RL动态调整记忆压缩策略,在长对话任务中F1分数提升15.3% \[7]
4. 推理(Reasoning)
- 双轨机制:RL同时优化"快推理"(启发式直觉)与"慢推理"(逐步演绎)
- 典型案例:DeepSeek-R1采用GRPO算法(无需价值模型的RL变体),在2024年数学数据集上Pass@1达33.0,较最强基线提升6.9分,证明RL可系统性增强推理深度 \[11]
5. 自我改进(Self-Improvement)
- 闭环学习:智能体执行任务→生成反思→修正策略→再执行
- 前沿探索:类似AlphaZero的自我博弈,让LLM自动生成问题并解答,形成无人监督的终身学习循环。实验表明,经过3轮自我改进的模型在代码生成任务上错误率降低41% \[9]
6. 感知(Perception)
- 多模态融合:在视觉-语言任务中,RL优化智能体的主动视觉认知(如决定何时聚焦图像特定区域)
- 应用实例:GUI智能体通过RL学习在手机界面中定位按钮、滑动屏幕,完成"设置闹钟"等复杂操作,成功率从SFT的58%提升至RL训练后的89% \[5]
四、奖励设计的艺术:稀疏奖励的陷阱与密集奖励的权衡
Agentic RL的核心挑战在于奖励工程。综述指出:
-
纯稀疏奖励问题:仅在任务成功时给予奖励,导致信用分配困难。在10步以上的任务中,随机策略成功率低于0.1%,RL训练收敛需10^6量级样本 \[5]
-
密集奖励方案:
- 规则型:子问题正确+1分、API调用成功+0.5分
- 判别器型:单元测试验证中间代码、符号求解器检查数学步骤
- 学习型:训练奖励模型评估推理质量(如Step-Reward Model)
关键权衡:过度设计的中间奖励可能导致"奖励黑客"(reward hacking)------智能体学会刷分而非真正解决问题。例如在Web搜索任务中,模型可能反复调用搜索API累积"调用成功"奖励,却从未整合结果生成答案 \[16]。
五、三大挑战:通往通用智能体的荆棘之路
综述坦诚指出Agentic RL面临的根本性瓶颈:
1. 可信度危机(Trustworthiness)
- 幻觉放大:结果驱动的RL可能忽视中间步骤真实性,只要最终答案正确就给予高奖励
- 谄媚性:为获取人类反馈奖励,智能体可能迎合用户错误信念(如确认"地球是平的")
- 缓解方案:过程监督(rewarding correct reasoning steps regardless of final answer)、对抗训练 \[16]
2. 训练规模化(Training Scalability)
- 计算成本:多环境并行rollout需求使训练成本呈指数增长。训练一个通用Web智能体需2000+ GPU小时
- 数据干扰:跨领域RL数据可能相互抑制(如代码任务的优化损害数学推理能力)
- 突破方向:课程学习(curriculum learning)、模块化策略网络 \[9]
3. 环境规模化(Environment Scalability)
- 人工瓶颈:现有基准(如WebArena)仅含数百个手工设计任务,难以覆盖真实世界复杂性
- 创新方案:EnvGen等框架用LLM自动生成动态环境,2025年实验显示可扩展至10^4量级任务 \[16]
六、资源全景:研究者实用工具包
综述附录整理了关键开源资源,极大降低研究门槛:
| 类别 | 代表项目 | 特点 |
|---|---|---|
| 环境 | WebArena, SWE-bench, GUIEnv | 模拟真实Web/代码/GUI交互 |
| 框架 | AgentFly, OpenRLHF, TRLX | 支持PPO/DPO/GRPO等算法 |
| 基准 | AgentBench, GAIA, ToolBench | 覆盖规划/工具/多步推理 |
| 数据集 | AgentInstruct, ToolLLM | 含轨迹标注的RL训练数据 |
七、未来展望:从专用智能体到通用自主智能
综述勾勒出三条关键演进路径:
- 可信智能体:结合形式化验证与RL,确保中间步骤可解释、可审计
- 自我进化循环:构建"行动-反思-改进"闭环,实现无需人类干预的持续学习
- 多智能体协作:将Dec-POMDP(分布式POMDP)与LLM结合,支持智能体社会的涌现行为
终极愿景 :Agentic RL不仅是LLM对齐工具,更是通用人工智能的使能引擎------它让模型从"任务执行者"蜕变为能在开放世界中自主设定目标、规划路径、应对不确定性的真正智能体 \[4]。
结语:范式转移的启示
这篇综述的价值远超技术整合:它重新定义了LLM的能力边界。当我们不再将语言模型视为"更聪明的autocomplete",而是嵌入物理/数字世界的决策主体时,AI的发展轨迹将发生根本性改变。
Agentic RL的崛起预示着:下一代AI竞赛的焦点,将从"参数规模"转向"智能体能力"------谁能构建在复杂环境中持续学习、可靠决策的自主系统,谁将掌握AGI的钥匙。
延伸思考:当LLM成为真正的智能体,我们是否需要重新思考"对齐"(Alignment)的定义?从"让模型说正确的话"到"让智能体做正确的事",这不仅是技术挑战,更是哲学与伦理的深层命题。
参考文献
1 Zhang, G., et al. (2025). The Landscape of Agentic Reinforcement Learning for LLMs: A Survey . arXiv:2509.02547.
2 Du, Y., et al. (2025). Agent Optimization: A Survey .
3 OpenAI. (2025). o3 Technical Report .
4 DeepSeek. (2025). DeepSeek-R1: Scaling Reinforcement Learning for Reasoning.
注:本文基于arXiv:2509.02547 v4版本(2026年1月24日)撰写,该论文已被Transactions on Machine Learning Research接收。