命名空间的核心概念
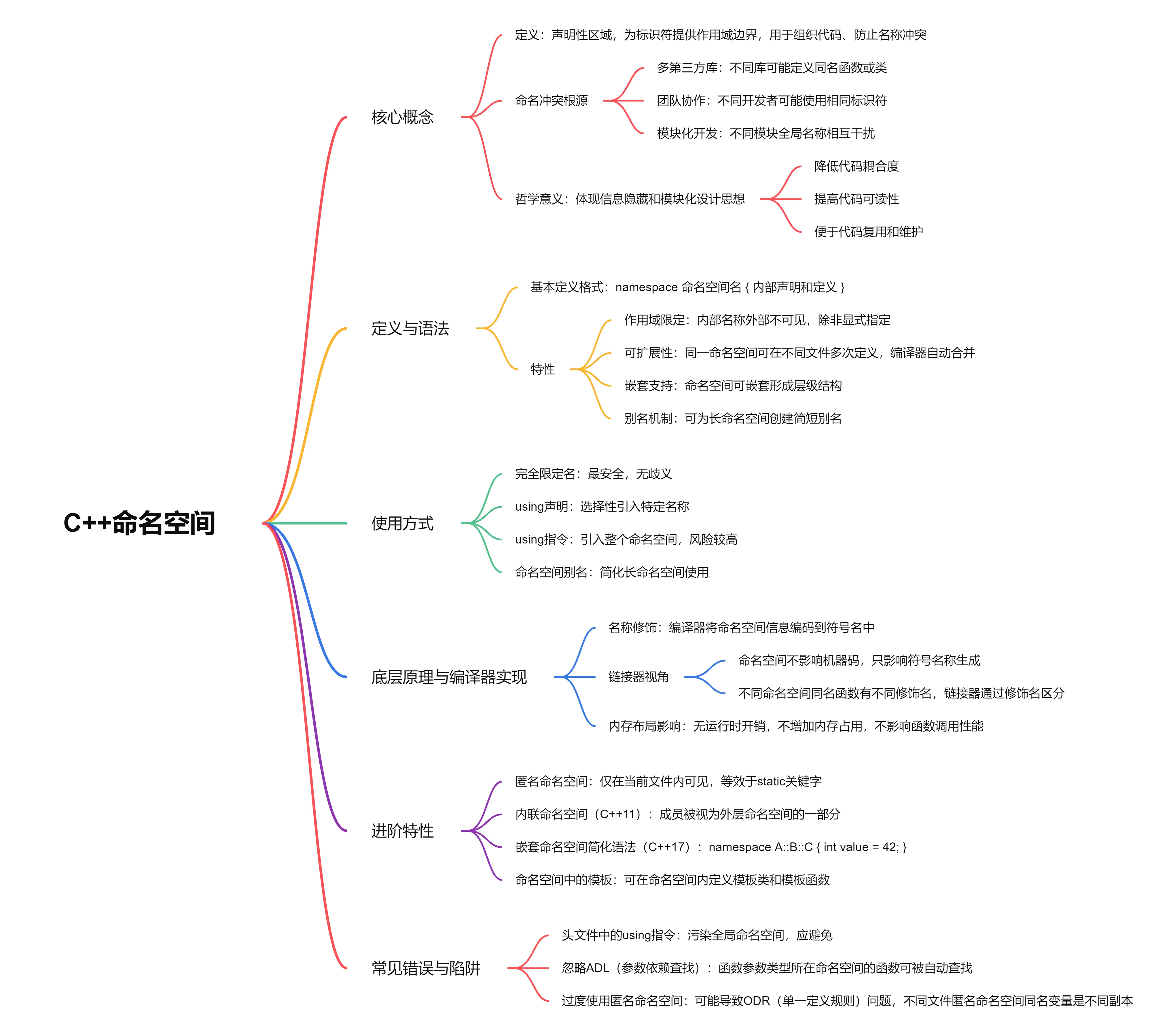
什么是命名空间?
命名空间(Namespace)是C++提供的一种机制,用于组织代码、防止名称冲突,并提高代码的可维护性。它本质上是一个声明性区域,为其内部的标识符(变量、函数、类、模板等)提供一个作用域边界。
命名冲突的根源
在大型C++项目中,命名冲突通常源于:
- 多个第三方库:不同库可能定义相同名称的函数或类
- 团队协作:不同开发者可能无意中使用相同标识符
- 模块化开发:不同模块中的全局名称相互干扰
命名空间的哲学意义
命名空间体现了信息隐藏 和模块化设计的编程思想。它将相关的代码实体组织在一起,同时对外隐藏实现细节,只暴露必要的接口。这种设计模式:
- 降低代码耦合度
- 提高代码可读性
- 便于代码复用和维护
命名空间的定义与语法
基本定义格式
命名空间的定义非常灵活,可以在头文件或源文件中进行,也可以分散在多个文件中定义同一命名空间(编译器会自动合并)。这种设计支持渐进式开发和代码分块管理。例如,一个大型库的各个组件可以在不同的文件中实现,只要它们属于同一个命名空间,最终就能被整合在一起。命名空间内可以包含变量、函数、类、结构体、枚举、模板等几乎所有C++实体。
cpp
// 基础命名空间定义
namespace MyNamespace {
// 可以包含各种声明和定义
int value = 42;
void function() {
// 函数实现
}
class MyClass {
// 类定义
};
template<typename T>
T templateFunction(T param) {
// 模板函数
return param;
}
}命名空间的特性
- 作用域限定:命名空间内的名称在该命名空间外不可见,除非显式指定
- 可扩展性:同一命名空间可以在不同文件中多次定义,编译器会自动合并
- 嵌套支持:命名空间可以嵌套,形成层级结构
- 别名机制:可以为长命名空间名称创建简短别名
代码示例:基础命名空间
cpp
// 示例1:基础命名空间定义与使用
namespace Physics {
const double GRAVITY = 9.8;
double calculateForce(double mass) {
return mass * GRAVITY;
}
}
namespace Math {
const double PI = 3.1415926;
double circleArea(double radius) {
return PI * radius * radius;
}
}
int main() {
// 使用作用域解析运算符访问
double force = Physics::calculateForce(10.0);
double area = Math::circleArea(5.0);
return 0;
}命名空间的多种使用方式
完全限定名(推荐方式)
完全限定名是最安全、最明确的访问方式。它直接指明了标识符所在的命名空间,没有任何歧义。虽然输入稍长,但在大型项目或团队协作中,这种明确性带来的好处远大于输入上的不便。许多编码规范(如Google C++ Style Guide)都推荐使用完全限定名,特别是在头文件中,以避免命名污染和潜在冲突。
cpp
// 清晰明确,无歧义
std::vector<int> numbers;
Physics::calculateForce(10.0);using声明(选择性引入)
using声明是一种折中方案,它在当前作用域内引入特定的命名空间成员,而不是整个命名空间。这样做既减少了输入,又控制了命名污染的范围。在函数内部使用using声明是相对安全的,因为其影响仅限于该函数。这种方式特别适合频繁使用某个命名空间中的少数几个标识符的场景。
cpp
// 只引入特定名称
using std::cout;
using std::endl;
int main() {
cout << "Hello" << endl; // 无需前缀
std::vector<int> v; // 其他std成员仍需前缀
return 0;
}using指令(谨慎使用)
using指令会将整个命名空间的所有成员引入当前作用域,这可能导致严重的命名冲突问题。在头文件中使用using指令是绝对禁止的,因为它会污染所有包含该头文件的源文件。在实现文件(.cpp)中,如果确信不会发生冲突,可以谨慎使用,但通常建议使用更安全的方式。对于 std 这样的标准库命名空间,许多项目都明确禁止使用 using namespace std;。
cpp
// 引入整个命名空间
using namespace std;
// 风险:可能导致名称冲突
// 建议:仅在自己控制的源文件中使用,不在头文件中使用命名空间别名
命名空间别名主要用于简化长命名空间名称或解决命名冲突。当使用深层嵌套的命名空间(如 Boost::Asio::ip::tcp)时,可以为其创建别名以提高代码可读性。别名在版本控制中也很有用,例如可以为不同版本的API创建统一的别名,方便切换实现。
cpp
namespace VeryLongNamespaceName {
void importantFunction() {}
}
// 创建别名
namespace VLN = VeryLongNamespaceName;
int main() {
VLN::importantFunction(); // 使用别名
return 0;
}代码示例:使用方式对比
cpp
#include <iostream>
#include <vector>
namespace LibraryA {
void process() {
std::cout << "LibraryA processing" << std::endl;
}
}
namespace LibraryB {
void process() {
std::cout << "LibraryB processing" << std::endl;
}
}
// 方式1:完全限定(最安全)
void method1() {
LibraryA::process();
LibraryB::process();
}
// 方式2:using声明(较安全)
void method2() {
using LibraryA::process;
process(); // 调用LibraryA::process
LibraryB::process(); // 需要完全限定
}
// 方式3:using指令(风险较高)
void method3() {
using namespace LibraryA;
process(); // 如果有冲突,这里会出错
// 如果有另一个process在全局作用域
// ::process(); // 可以使用全局作用域运算符访问
}
int main() {
method1(); // 明确,无歧义
method2(); // 部分简化,仍然清晰
method3(); // 可能有问题,不推荐
return 0;
}命名空间的底层原理与编译器实现
命名空间本质上是一种编译期的符号组织机制,而不是运行时的实体。它通过为标识符添加前缀信息,在编译器符号表中创建唯一的符号名称,从而解决命名冲突问题。
名称修饰(Name Mangling)
C++编译器通过名称修饰技术实现命名空间。当编译器遇到命名空间中的符号时,它会将命名空间信息编码到符号名中。
名称修饰是C++编译器实现重载、命名空间、模板等特性的关键技术。编译器会将命名空间、类名、函数名、参数类型等信息编码到一个唯一的内部符号名中。这个过程对开发者是透明的,但在调试或分析二进制文件时很重要。不同的编译器(如GCC、Clang、MSVC)有不同的修饰规则,这也是C++二进制接口兼容性复杂的原因之一。
cpp
// 源代码
namespace MyApp {
int calculate(int x, int y);
}
// 编译器可能生成的修饰名(示例):
// _ZN5MyApp9calculateEii
// 分解:
// _Z: C++修饰开始标记
// N: 嵌套名称开始
// 5MyApp: 长度5的名称"MyApp"
// 9calculate: 长度9的名称"calculate"
// E: 参数列表开始
// ii: 两个int参数链接器视角
从链接器的角度看,命名空间只是改变了符号的名称,并没有改变符号的本质。链接器按照修饰后的符号名进行解析和链接,因此不同命名空间中的同名函数会被视为完全不同的符号。这也是为什么C++的命名空间机制不会带来运行时开销的原因------所有工作都在编译期完成。
从链接器的角度看:
- 命名空间不影响最终生成的机器码
- 它只影响符号名称的生成方式
- 不同命名空间中的同名函数会有不同的修饰名
- 链接器通过修饰名区分不同命名空间的相同函数名
内存布局影响
命名空间纯粹是编译期机制,不会影响运行时内存布局、函数调用约定或性能。这与类的成员函数不同(后者有隐含的this指针)。命名空间函数与普通全局函数在二进制级别上没有区别,只是名称不同。这意味着使用命名空间不会带来任何性能损失,可以放心使用。
命名空间本身不引入运行时开销:
- 不增加内存占用
- 不影响函数调用性能
- 纯粹是编译期的组织机制
代码示例:查看修饰名
cpp
// 可以通过工具查看修饰名
namespace Alpha {
void function() {}
}
namespace Beta {
void function() {}
}
// 使用g++编译并查看符号表:
// g++ -c demo.cpp
// nm demo.o
// 输出可能包含:
// _ZN5Alpha8functionEv
// _ZN4Beta8functionEv命名空间的进阶特性
匿名命名空间
匿名命名空间提供了一种比 static 关键字更现代的限定文件作用域的方式。在C++中,推荐使用匿名命名空间代替 static 来定义文件局部变量和函数。匿名命名空间内的所有内容都具有内部链接属性,对其他文件不可见。这对于实现文件内部的辅助函数和变量非常有用,可以避免与其他文件中的同名标识符冲突。
cpp
// 匿名命名空间:仅在当前文件内可见
namespace {
int fileLocalVariable = 42;
void helperFunction() {
// 只能在当前文件中使用
}
}
// 等效于:
// static int fileLocalVariable = 42;
// static void helperFunction() { ... }内联命名空间(C++11)
内联命名空间主要用于库的版本管理。通过将不同版本的API放在不同的内联命名空间中,库开发者可以在保持向后兼容的同时引入新API。最新版本通常设为内联,这样用户可以直接访问而不需要指定版本号。旧版本则保留为非内联,供需要兼容旧代码的用户使用。这是一种优雅的版本控制策略。
cpp
// 内联命名空间:其成员被视为外层命名空间的一部分
namespace Library {
namespace v1 {
void oldAPI() {}
}
inline namespace v2 {
void newAPI() {}
}
}
int main() {
Library::newAPI(); // 直接访问
Library::v1::oldAPI(); // 需要指定版本
// 默认使用v2版本
using namespace Library;
newAPI(); // 调用v2::newAPI
return 0;
}嵌套命名空间简化语法(C++17)
C++17引入的嵌套命名空间简化语法大大减少了深层命名空间定义的代码冗余。这种语法糖使代码更加简洁,特别是在定义多层次命名空间结构时。它反映了C++语言发展的一个趋势:在保持向后兼容的同时,通过简化语法提高开发者的生产效率。
cpp
// C++17之前的写法
namespace A {
namespace B {
namespace C {
int value = 42;
}
}
}
// C++17简化语法
namespace A::B::C {
int value = 42;
}命名空间中的模板
命名空间可以包含模板,这为组织泛型代码提供了极大的灵活性。模板类、模板函数都可以定义在命名空间中,使得泛型编程也能享受命名空间带来的组织性和隔离性。当结合ADL(参数依赖查找)时,命名空间中的模板函数可以基于模板参数类型自动查找,这是C++模板元编程中的重要特性。
cpp
namespace Container {
template<typename T>
class Box {
private:
T content;
public:
Box(T value) : content(value) {}
T get() const {
return content;
}
};
template<typename T>
Box<T> makeBox(T value) {
return Box<T>(value);
}
}
int main() {
auto box = Container::makeBox(100);
return 0;
}常见错误与陷阱
头文件中的using指令
在头文件中使用using指令是一种不良实践,因为它会将命名空间的所有成员暴露给所有包含该头文件的源文件,可能导致难以调试的命名冲突。头文件应该尽可能自包含且不影响包含它的文件的命名环境。如果需要在头文件中使用某个命名空间的成员,应该使用完全限定名或函数包装的方式。
cpp
// 错误示例
// utils.h
#include <vector>
using namespace std; // 污染全局命名空间!
// 正确做法
// utils.h
#include <vector>
// 不使用using指令忽略ADL(参数依赖查找)
ADL是C++中一个强大但容易忽略的特性。当调用函数时,编译器不仅会在当前作用域查找,还会在函数参数类型所属的命名空间中查找。这使得操作符重载和模板编程更加自然。理解ADL对于正确使用命名空间和模板非常重要,尤其是在编写泛型代码或重载操作符时。
cpp
namespace MyNS {
class MyClass {};
void process(MyClass obj) {
// 处理MyClass
}
}
int main() {
MyNS::MyClass obj;
process(obj); // 正确:ADL允许找到MyNS::process
// 即使没有using namespace MyNS
// 也能通过参数类型找到正确的函数
return 0;
}过度使用匿名命名空间
虽然匿名命名空间有用,但过度使用可能导致每个源文件都有自己独立的变量副本,造成内存浪费或逻辑错误。真正需要在多个文件间共享的变量应该放在普通命名空间中。此外,匿名命名空间中的函数无法在单元测试中直接访问,这也是需要考虑的因素。合理使用匿名命名空间,区分"文件局部"和"模块共享"是关键。
cpp
// 过度使用匿名命名空间可能导致ODR(单一定义规则)问题
// file1.cpp
namespace {
int sharedValue = 1; // 实际上每个文件有自己的副本
}
// file2.cpp
namespace {
int sharedValue = 2; // 不同的变量!
}
// 如果需要真正的共享,应该在一个普通命名空间中定义