目录
[2.1 网络结构](#2.1 网络结构)
[2.2 代码实现](#2.2 代码实现)
[3.1 网络结构](#3.1 网络结构)
[3.2 Pad尺寸对齐](#3.2 Pad尺寸对齐)
[3.3 转置卷积与双线性插值](#3.3 转置卷积与双线性插值)
[3.4 代码实现](#3.4 代码实现)
一、Unet
语义分割 与传统图像分类存在本质区别。图像分类关心这张图是什么,而语义分割要求对每一个像素 进行判别,不仅需要理解目标是什么,还要准确回答它在什么位置 、边界在哪里。
经典卷积神经网络在结构设计上常依赖逐层下采样来扩大感受野、提取高层语义特征。这种方式在分类任务中非常有效,但在语义分割任务中,下采样过程中大量精细的空间位置信息被不可逆地丢失。即便通过上采样操作恢复分辨率,也难以重新找回清晰的边界与局部结构,分割结果轮廓粗糙、定位不准。
U-Net通过结构上的重新组织,在提取高层语义信息的同时,尽可能保留并利用高分辨率的空间特征。整体上,U-Net 采用了一种对称的编码器--解码器 结构:左侧为逐步下采样的编码 路径,用于提取多尺度语义特征;右侧为逐步上采样的解码路径,用于恢复空间分辨率并生成像素级预测结果。在网络最底部,两条路径通过一个瓶颈层相连。
在每层中,网络将编码器尚未经过下采样的高分辨率特征,直接拼接到解码器对应层中,这种跳跃连接方式,使 U-Net 能够在保持强表达能力的同时,实现对目标边界和细节结构的定位。
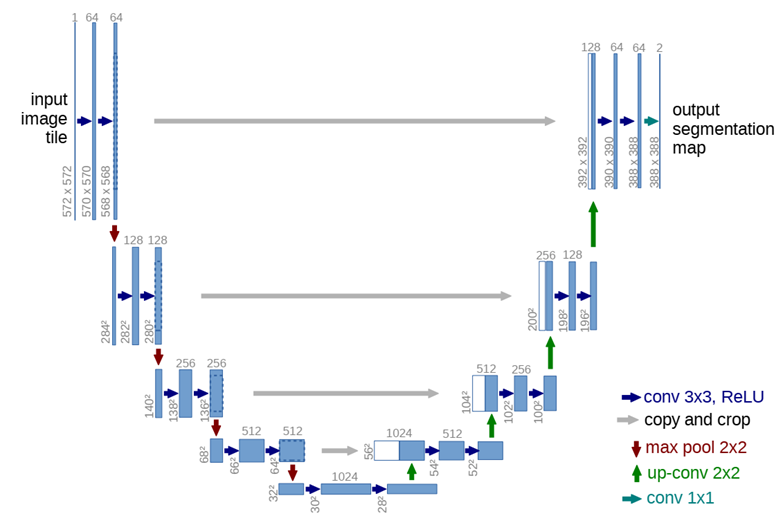
二、编码器
2.1 网络结构
编码器开始先做一次双卷积增加原始图像的通道数,随后重复 4 次下采样+双卷积。下采样用 2×2 最大池化将分辨率减半;双卷积用两次 3×3 卷积(padding=1, stride=1)在该尺度上提取特征。具体参数如下:
初始DoubleConv:
输入256×256×1,经过两次 3×3×64 卷积核(stride=1, padding=1)卷积,空间尺寸不变,通道变为 64。
down1:
输入256×256×64,先做 2×2 最大池化(stride=2)输出128×128×64;DoubleConv经过 两次 3×3×128 卷积不改变空间尺寸,通道变为128,输出特征图128×128×128
down2:
输入128×128×128, 2×2 最大池化输出64×64×128;DoubleConv经过两次 3×3×256卷积,通道变为256,输出特征图64×64×256
down3:
输入64×64×256, 2×2 最大池化输出32×32×256;DoubleConv经过两次 3×3×512卷积,通道变为512,输出特征图32×32×512
down4:
输入32×32×512, 2×2 最大池化输出16×16×512;DoubleConv 的输出仍为 512 通道。输出16×16×512,是后续解码器开始上采样的起点。
2.2 代码实现
具体到代码中,编码器用到的基础模块只有DoubleConv 和 Down。
DoubleConv 是两层 3×3 卷积,每层后接 BN 和 ReLU。由于 kernel_size=3, stride=1, padding=1,所以每次卷积都不改变空间尺寸 H、W,只改变通道数 C。实现如下
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)Down 下采样模块中,先 MaxPool2d(2, stride=2) 把 H、W 各减半,再接一个 DoubleConv 在新尺度上继续提特征
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)在下采样的同时,编码器每一级的输出特征都会被保留下来,后面解码器用跳跃连接把这些高分辨率信息送回去
三、跳跃连接与解码器
3.1 网络结构
解码器整体结构与编码器对称,从最深层特征 x5出发,连续做 4 次上采样+拼接+双卷积,每上采样一次,H、W 乘 2;同时通道数逐层下降,最终回到与 x1 相同尺度,再用 1×1 卷积输出类别
up1:
输入特征图16×16×512,经过双线性插值上采样输出32×32×512;与x4进行拼接,通道数翻倍,最后经3×3卷积核(stride=1, padding=1)双层卷积DoubleConv,空间尺寸不变,通道被压到 256,最终输出特征图为32×32×256;
Up2:
输入特征图32×32×256,经过双线性插值输出64×64×256;与x3通道数翻倍(64×64×512),经双层卷积输出特征图(512→128, mid=256)为64×64×128;
Up3:
输入特征图64×64×128,经过双线性插值输出128×128×128;与x2通道数翻倍(128×128×256),经双层卷积(256→64, mid=128)输出特征图为128×128×64;
Up4:
输入特征图128×128×64,经过双线性插值输出256×256×64;与x1通道数翻倍(256×256×128),经双层卷积(128→64, mid=64)输出特征图为256×256×64;
输出层out_conv:
最后 OutConv 是一个 1×1 卷积(stride=1, padding=0),不改变空间尺寸,只做通道映射。
输入256×256×64,输出通道数num_classes=2,256×256×2
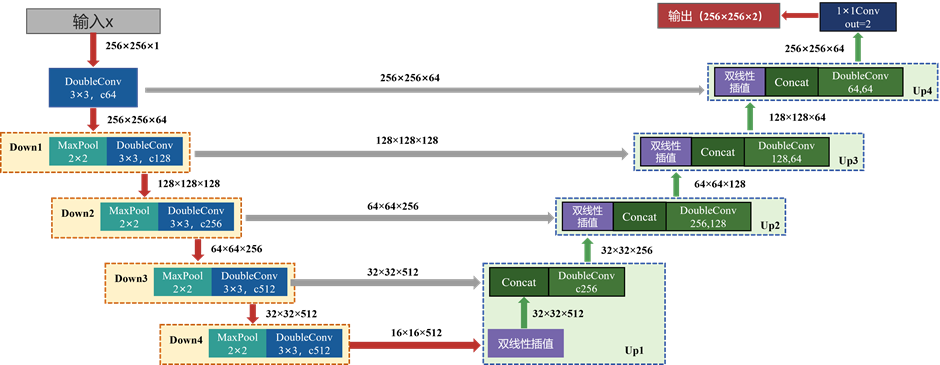
3.2 Pad尺寸对齐
如果输入 H、W 不是 16 的整数倍,多次 /2 再 ×2 会出现差 1 的尺寸误差,导致无法 concat。因此在实际实现中,使用diff_x/y 计算skip 分支与上采样分支的尺寸差,F.pad 把上采样分支在四周补零,补到完全一致再拼接。
在理想的 H、W 为 2^k 整数倍时(如 256、512),diff 通常为 0,pad 等于不做
3.3 转置卷积与双线性插值
转置卷积
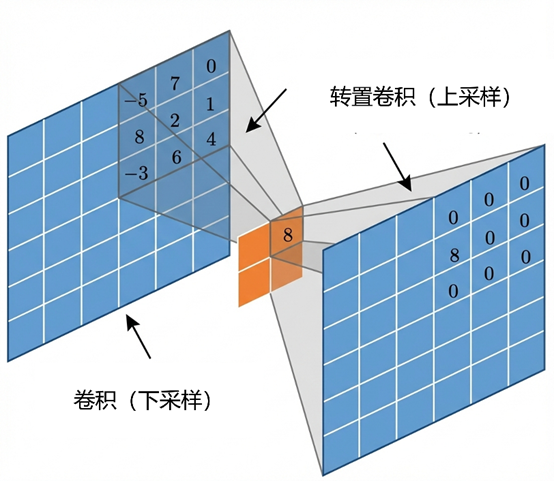
普通卷积将较大的输入通过卷积核映射为较小的输出。转置卷积反其道而行之。设一个步长为 1、无填充的普通卷积表示为:
要从 y的尺寸恢复到 x的尺寸,最直接的方法就是乘转置矩阵C^T
这不能还原 x的具体数值,但能还原维度关系,且 C^T的卷积核权重是可以梯度下降更新的。
对于输入尺寸Hi,转置卷积后的输出尺寸Ho公式如下
S: 步长 Stride、P: 填充 Padding、K:卷积核大小Kernel size、Adj: 输出补偿
双线性插值上采样
一元线性插值中推算落在 x_1 和 x_2 之间的x,公式为
距离谁越近,权重越大。
双线性插值是在两个方向上分别进行一次线性插值。假设目标点 P(x, y) 位于四个已知像素点 构成的矩形中。首先在 x方向上对上下两对点进行线性插值,
第二步在y 方向上对 线性插值,得到最终的 P
相较转置卷积,它计算复杂度较低,但学习能力弱
3.4 代码实现
Up 模块中默认 bilinear=True采用双线性插值上采样,而不是转置卷积;上采样后用 F.pad 做尺寸对齐;再把编码器的 skip 特征与上采样特征在通道维拼接,最后用 DoubleConv 融合
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
...
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
def forward(self, x1, x2):
x1 = self.up(x1) # 上采样:H,W 各乘2,C不变
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1) # 通道拼接
x = self.conv(x) # DoubleConv 融合
return x输出层只用一层卷积改变通道数
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)四、代码封装
完成DoubleConv、Down、Up、OutConv等模块的封装后,将它们按U-Net 的结构装配起来
初始化定义网络的输入/输出接口和通道。in_channels 表示输入图像通道数;num_classes 是分割类别数,决定最后输出 logits 的通道数;bilinear 决定上采样方式;由于上下采样参数量成倍变化,可以定义一个基础通道数base_c
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear之后按顺序配置各层参数,默认 base_c=64 时,编码器通道按 64→128→256→512 递增,空间分辨率按 H→H/2→H/4→H/8→H/16 递减;解码器则相反
class UNet(nn.Module):
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)完整代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out": logits}五、训练
使用DRIVE视网膜血管分割数据集,DRIVE由原始图像及其对应的二值分割标注组成,数据集被划分为训练集和验证集两部分。分割任务要区分背景区域和前景区域,输出类别数为2
https://drive.grand-challenge.org/
环境
python=3.10
numpy==1.22.0
pandas==1.4.4
matplotlib==3.5.3
Pillow
torch==1.13.1
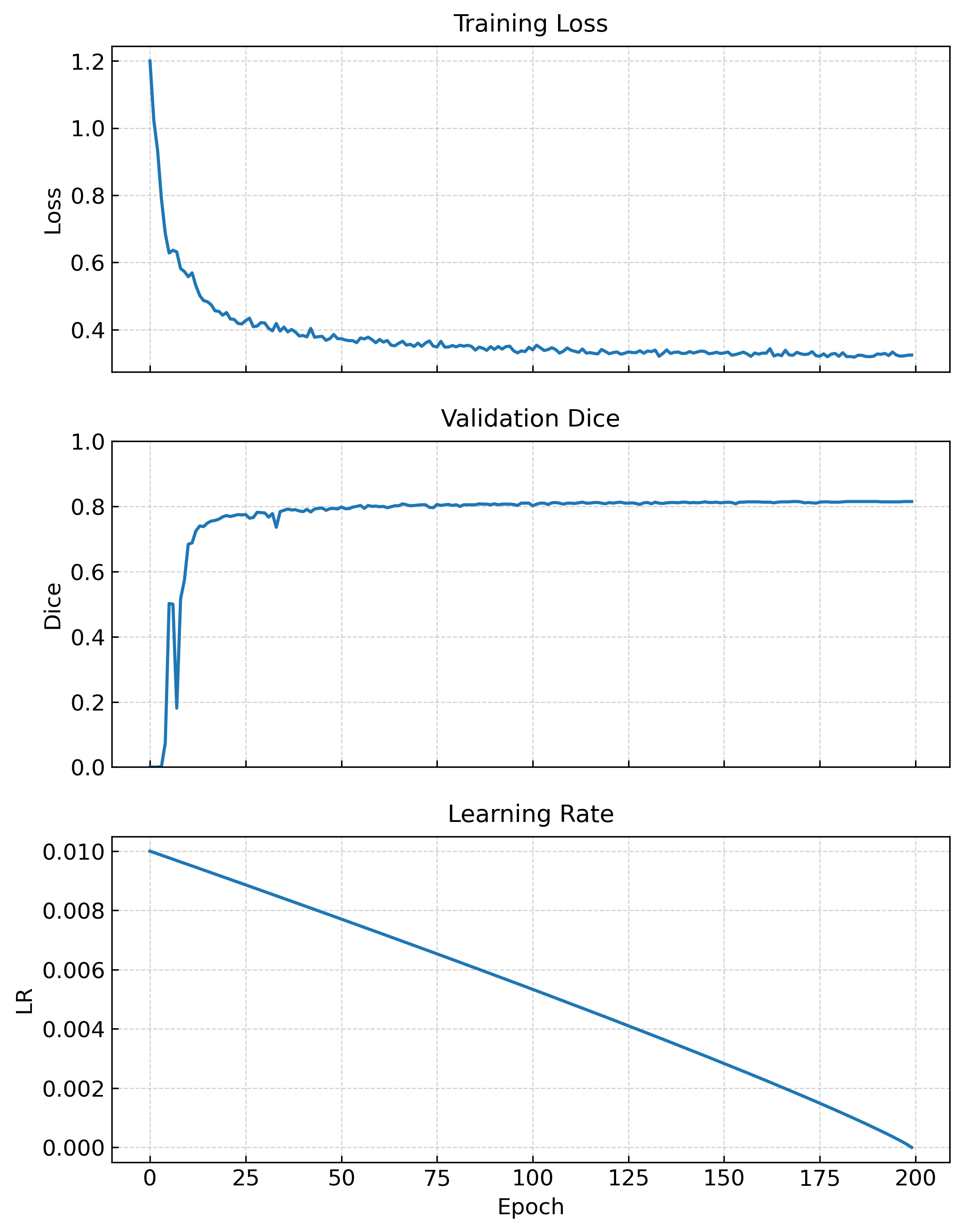
torchvision==0.14.1评价指标
用Dice来衡量预测区域和真实区域的重叠程度。设A代表真值,B代表预测值,Dice系数定义为
转化为混淆矩阵中的基本统计量为:
TP 为正确预测的像素,FP 为错误地将背景预测为前景的像素,FN为漏掉的前景像素
像素准确率PA 表示分类正确的像素占总像素的比例,类别平均准确率MPA针对每个类分别计算准确率,再取平均值
IoU衡量的是交集与并集的比值,它也用来度量重叠度
平均交并比mIoU计算每一个类别的 IoU,然后求平均
点击运行,模型训练并输出对应参数