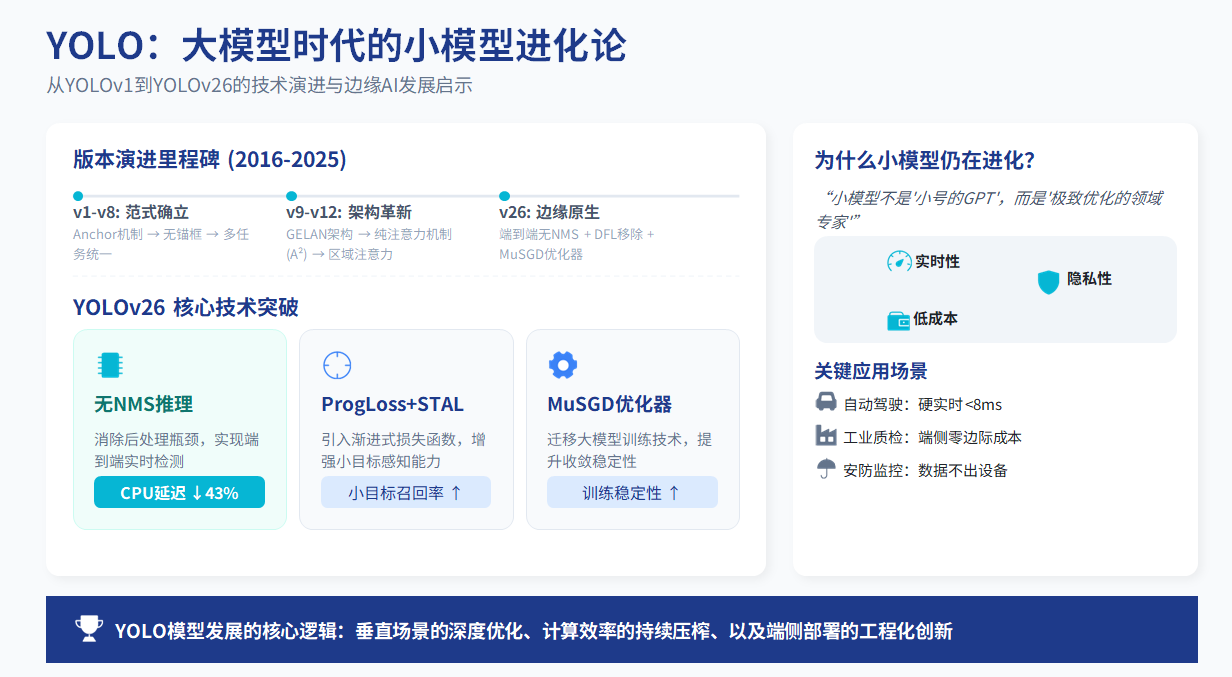
快速了解YOLO(You Only Look Once)目标检测模型从2016年诞生至2025年迭代至YOLOv26的完整技术演进路径。在大模型(LLM)主导AI发展 discourse 的背景下,YOLO系列持续保持快速迭代,最新版本YOLOv26于2025年9月发布,专为边缘计算场景优化,实现了CPU推理速度提升43%、端到端无NMS推理等突破性进展。这一现象揭示了小模型发展的核心逻辑:垂直场景的深度优化、计算效率的持续压榨、以及端侧部署的工程化创新。
一、YOLO版本迭代全览与技术演进图谱
1.1 版本发展时间轴与关键节点
| 版本 | 发布时间 | 核心贡献机构 | 标志性技术突破 |
|---|---|---|---|
| YOLOv1 | 2016年 | Joseph Redmon (UW) | 开创单阶段检测范式,将检测视为回归问题 |
| YOLOv2/v3 | 2017-2018年 | Joseph Redmon & Ali Farhadi | 引入Anchor机制、Darknet-53骨干网络、多尺度预测 |
| YOLOv4 | 2020年 | Alexey Bochkovskiy | 系统整合Bag of Freebies/Specials优化技巧 |
| YOLOv5 | 2020年 | Ultralytics | PyTorch原生实现,工程化部署友好 |
| YOLOv6-v7 | 2022年 | 美团/旷视等 | 工业界针对性优化,重参数化设计 |
| YOLOv8 | 2023年 | Ultralytics | 解耦检测头、无锚框预测、多任务统一框架 |
| YOLOv9 | 2024年2月 | 王晨耀等 (Academia Sinica) | GELAN架构 + PGI可编程梯度信息 |
| YOLOv10 | 2024年5月 | 清华大学 | 无NMS训练 + 效率驱动架构 |
| YOLOv11 | 2024年 | Ultralytics | 跨任务性能优化,GPU效率提升 |
| YOLOv12 | 2025年2月 | 纽约州立大学/中国科学院 | 纯注意力机制引入 (R-ELAN, A²注意力) |
| YOLOv13 | 2025年 | 清华大学等 | 超图增强 + 高阶语义建模 |
| YOLOv26 | 2025年9月 | Ultralytics | 边缘原生设计、无NMS推理、MuSGD优化器 |
1.2 核心技术演进维度分析
维度一:检测范式演进------从后处理依赖到端到端
- 传统阶段(v1-v8):依赖NMS(非极大值抑制)作为后处理步骤,通过IoU阈值过滤重复框,引入额外延迟和超参数调优复杂性。
- 突破阶段(v10/v26) :YOLOv10由清华大学首次实现无NMS训练,YOLOv26进一步发展为原生端到端架构,模型直接输出最终预测,消除后处理瓶颈,CPU推理延迟降低43%。
维度二:损失函数进化------从简单回归到分布感知
- 早期:标准L2/L1回归损失,边界框坐标直接预测。
- 中期(v8-v11) :引入分布焦点损失(DFL),预测边界框坐标的概率分布以提升定位精度,但增加计算开销和导出复杂性。
- YOLOv26 :完全移除DFL ,回归任务简化为直接坐标预测,结合渐进损失平衡(ProgLoss)与小目标感知标签分配(STAL),在简化架构的同时提升小目标检测精度。
维度三:骨干网络迭代------从CNN到注意力融合
- v1-v4:Darknet系列纯CNN架构,追求特征提取效率。
- v9 :GELAN(广义高效层聚合网络),结合CSPNet与梯度流优化。
- v12 :区域注意力机制(A²)+ 残差高效聚合网络(R-ELAN),首次在YOLO系列中全面引入注意力机制,COCO数据集达到58.9% mAP@208FPS。
- v13 :超图增强(Hypergraph Enhancement),建模高阶语义关系。
- v26:回归精简CNN设计,针对边缘设备量化(INT8/FP16)稳定性优化。
维度四:优化器创新------跨领域技术迁移
YOLOv26引入MuSGD优化器,这是大模型训练技术向计算机视觉迁移的典型案例:
- 技术渊源:受Moonshot AI的Kimi K2大模型训练优化启发,结合SGD与Muon优化技术。
- 效果:训练稳定性显著提升,收敛速度加快,解决了小模型训练中的震荡问题。
二、YOLOv26架构深度解析:边缘AI的范式重构
2.1 四大核心架构创新
创新1:DFL移除与边界框回归简化
- 动机:DFL模块虽提升精度,但引入固定回归限制,使ONNX/TensorRT/CoreML导出复杂化,限制边缘硬件兼容性。
- 方案:直接坐标回归 + ProgLoss动态平衡分类与回归损失权重。
- 收益:模型导出成功率提升,跨平台部署延迟降低,大目标检测可靠性增强(消除DFL的分布截断问题)。
创新2:端到端无NMS推理
- 技术实现:在检测头内部集成冗余框抑制逻辑,通过网络学习直接生成非重叠预测。
- 性能对比:相比YOLOv11,nano模型在CPU上推理时间减少43%;相比RT-DETR系列,保持竞争力的同时显著降低延迟。
- 工程价值:消除部署时的后处理代码依赖,降低系统集成脆弱性。
创新3:ProgLoss + STAL训练策略
- ProgLoss(渐进损失平衡):动态调整训练过程中不同损失分量的权重,早期侧重定位稳定性,后期优化分类精度。
- STAL(小目标感知标签分配):针对小目标(<16×16像素)优化正样本分配策略,解决IoU-based分配对小目标召回不足的问题。
- 联合效果:在VisDrone等无人机小目标数据集上,YOLOv26较YOLOv11 mAP提升显著,同时保持更低推理延迟。
创新4:MuSGD优化器
- 算法本质:SGD的动量更新与Muon的二阶信息近似相结合,自适应调整参数更新方向。
- 稳定性提升:在边缘模型的小批量(batch size)训练场景下,减少梯度噪声影响,支持更大学习率快速收敛。
2.2 多任务支持与部署生态
YOLOv26延续并扩展了Ultralytics的多任务框架:
- 任务类型:目标检测、实例分割、姿态估计(关键点)、定向边界框(OBB,适用于遥感)、图像分类、目标跟踪。
- 导出格式:ONNX(通用)、TensorRT(NVIDIA GPU)、CoreML(Apple生态)、OpenVINO(Intel)、TFLite(移动端)。
- 量化支持:原生支持FP16/INT8量化,在Jetson Orin等边缘设备上精度损失可控,显著优于Transformer-based检测器(如RT-DETRv3在INT8下性能急剧下降)。
三、大模型时代YOLO持续进步的内在逻辑
3.1 需求侧:实时性场景的刚性约束
大模型(如GPT-4、Kimi K2)虽在通用视觉理解上展现潜力,但面临根本性限制:
| 约束维度 | 大模型局限 | YOLO优势 |
|---|---|---|
| 延迟 | 云端推理网络传输+计算延迟通常>100ms | 边缘部署端到端延迟可<8ms(YOLOv26-tiny on Jetson AGX Orin) |
| 成本 | API调用成本随流量线性增长 | 边缘一次性部署,零边际推理成本 |
| 隐私 | 数据上传云端存在合规风险 | 端侧处理,数据不出设备 |
| 可靠性 | 网络中断导致服务不可用 | 离线运行,确定性响应 |
关键洞察 :自动驾驶、工业质检、安防监控等场景对延迟的要求是硬实时(Hard Real-time) ,而非大模型的软实时(Soft Real-time) 。YOLO的进化始终围绕速度-精度帕累托前沿的极致优化。
3.2 供给侧:小模型优化的技术纵深
大模型的发展反而为小模型提供了技术溢出:
- 架构设计借鉴:YOLOv12引入注意力机制,吸收Transformer的长程建模能力,但通过**区域注意力(A²)**限制计算复杂度,保持线性增长。
- 训练技术迁移:YOLOv26的MuSGD优化器直接源自大模型训练经验,证明优化算法的跨领域通用性。
- 知识蒸馏应用:YOLOv9的PGI(可编程梯度信息)本质上是一种动态蒸馏策略,利用辅助分支引导主网络学习。
3.3 生态侧:垂直场景的碎片化需求
大模型追求通用性,而YOLO系列通过版本迭代覆盖长尾场景:
- YOLOv10:效率优先,适合高吞吐量服务器端。
- YOLOv12:精度优先,适合研究场景与高精度需求。
- YOLOv13:语义建模增强,适合复杂场景理解。
- YOLOv26:边缘优先,适合物联网、嵌入式设备。
这种场景驱动的差异化演进,是大模型难以替代的。
四、小模型发展道路的启示与展望
4.1 小模型生存法则:从"够用"到"好用"的跨越
YOLO系列26个版本的迭代揭示了小模型发展的三条核心路径:
路径一:计算效率的极限压榨
- 算子优化:深度可分离卷积、重参数化(RepVGG)、通道剪枝。
- 硬件协同设计:针对特定芯片(如NVIDIA Tensor Core、ARM NEON)优化算子融合。
- 量化感知训练:YOLOv26的INT8稳定性证明,小模型可在极低精度下保持可用性。
路径二:任务特性的深度耦合
- 输入感知:STAL机制针对小目标优化,证明损失函数设计应匹配数据分布特性。
- 输出简化:无NMS设计将后处理纳入网络学习,减少系统复杂度。
- 多任务统一:一个骨干网络支撑检测/分割/姿态估计,提升部署性价比。
路径三:工程化能力的体系构建
Ultralytics的成功不仅是算法胜利,更是工程化框架的胜利:
- 统一的Python API降低使用门槛。
- 完善的导出生态(ONNX/TensorRT/CoreML)覆盖95%以上部署场景。
- 活跃的社区与工业反馈闭环(从YOLOv5到v26持续迭代)。
4.2 未来趋势:小模型与大模型的协同演进
- 混合架构 :小模型负责实时感知(YOLOv26),大模型负责高层决策(VLM),形成感知-认知分层系统。
- 神经架构搜索(NAS)自动化:针对特定边缘设备(如某款NPU)自动搜索最优YOLO变体,超越手工设计。
- 持续学习:小模型在边缘端基于大模型生成的伪标签进行增量训练,适应新场景而不回传原始数据。
五、结论
YOLO模型从v1演进至v26的十年历程,是一部小模型在垂直领域持续深耕的技术史诗。在大模型席卷AI话语权的当下,YOLOv26的发布证明:
小模型的价值不在于替代大模型,而在于在资源受限的物理世界中,以确定性延迟、可负担成本、隐私保护的方式,解决真实问题。
YOLOv26通过移除DFL、端到端无NMS设计、MuSGD优化器等创新,将边缘AI的实用性推向新高度。其发展道路揭示:小模型的未来不是成为"小号的GPT",而是成为"极致优化的领域专家"------在特定的计算约束、任务约束、数据约束下,达到理论最优的性能边界。
对于产业界而言,选择YOLOv26等边缘原生模型,不仅是技术决策,更是成本结构、隐私合规、用户体验的综合考量。在大模型与小模型长期共存的AI生态中,YOLO系列将持续定义实时目标检测的技术标准。
报告撰写日期 :2026年2月
主要参考资料:Ultralytics官方技术博客、腾讯云开发者社区技术解析、Roboflow模型对比分析、CSDN/YOLO系列演进梳理