文章目录
redis通用命令
我们知道,redis是一个在将数据存储在内存中的中间件,数据的组织形式是键值对
key只能是string,但是它的value可以是很多其它的类型:
如list,bitmap,string等...
每个不同类型的value都有不同的操作,这一点和语言里面实现的容器是一样的
但是,有一些命令是所有类型都能使用的,这种是通用命令
本篇文章,将选取几个常用的通用命令进行学习,以此来初步地上手使用redis。
参考资料:Redis官方文档
set && get
既然是键值对存储,那么很容易就能想到哈希表
所以现在就很容易想到:redis是如何进行插入<key, value>和读取key的
答案就是使用命令set和get Tips:redis的命令不区分大小写:
redis
set key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX]
get key设置先不讲那么多,我们能够学会正常使用即可:
redis
127.0.0.1:6379> set key1 value1
OK
127.0.0.1:6379> set key2 value2
OK
127.0.0.1:6379> set key2 value3
OK
127.0.0.1:6379> get key1
"value1"
127.0.0.1:6379> get key2
"value3"
127.0.0.1:6379> get key
(nil)对于插入而言:
插入成功就显示OK,对同一key进行多次插入,会采取覆盖策略
对于获取而言:
存在就返回对应的value,反之返回nil,也就是空
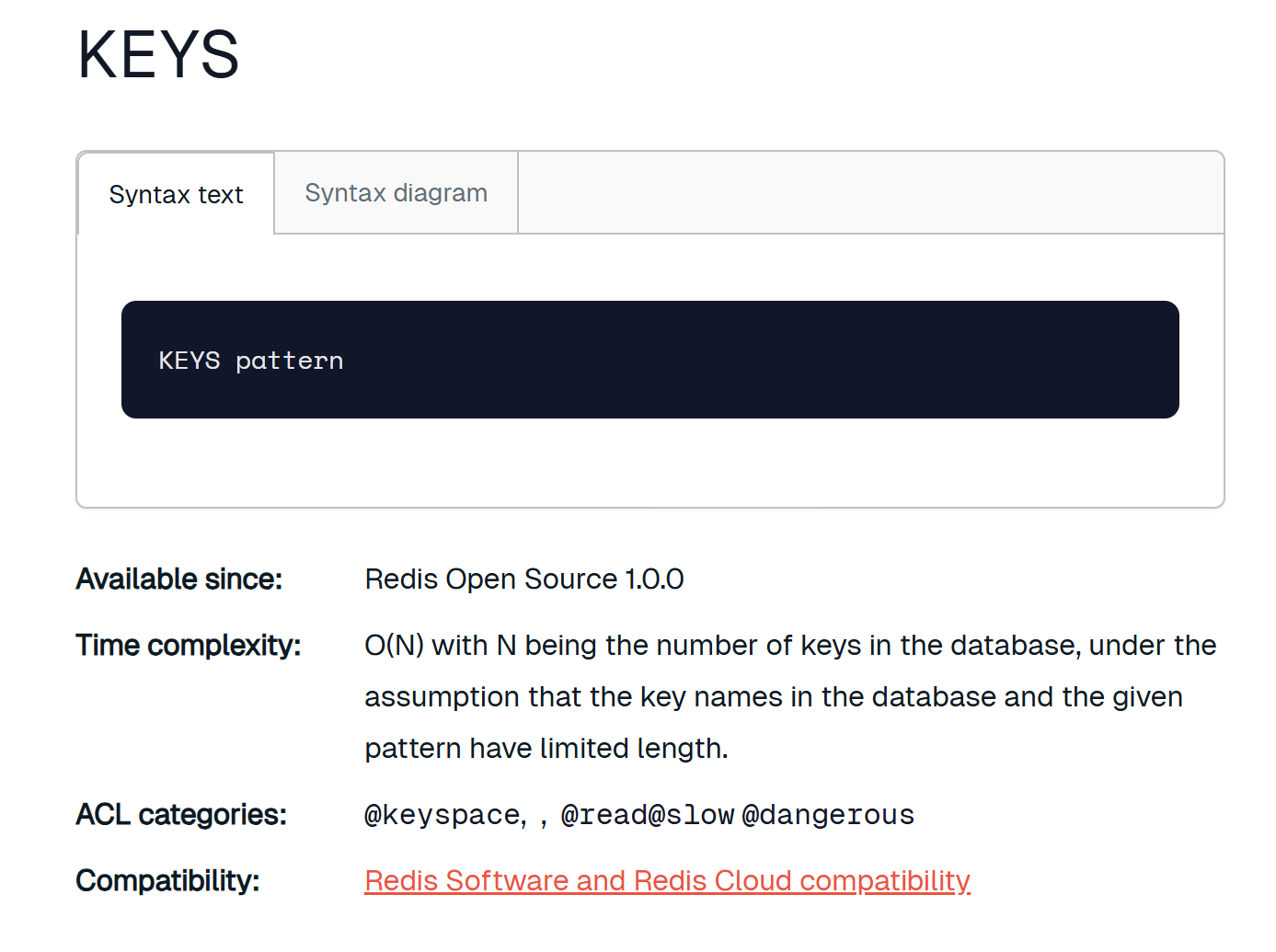
keys
keys命令核心要点:用来查找某个pattern的key是否存在
有点类似于HTTP的正则表达式,即通过某种指定格式来匹配一串序列!
pattern的匹配规则如下:
h?llo matches , and hellohallohxllo
h*llo matches and hlloheeeello
haello matches and but not hellohallo,hillo
h\^ello matches , , ... but not hallohbllohello
ha-bllo matches and hallohbllo
这里大概意思就是:
?:匹配任意一个字符
*:匹配任意的多个字符
[]:匹配[]内部的任意一个字符
[^]:匹配[]内部之外的任意一个字符
[a-b]:匹配a, b左闭右闭区间内的任意一个字符
时间复杂度说明:
如果我们想查询当前redis中所有存储的键值对,简单粗暴的做法就是:keys *
但是,官方文档中说:这个命令的时间复杂度是O(N),也就是会去遍历整个redis
在生产环境下,如果直接keys *,和mysql下直接select * from table没啥区别
而redis一般是做缓存用的,是挡在数据库的前面一关,防止数据库突然被请求打满
如果生产环境下,直接遍历redis,那么会导致其他请求被阻塞住redis是单线程
那样的话,redis的请求失败,就去请求数据库了
这个时候,如果一瞬间的访问打到数据库,数据库的服务会很不稳定,甚至是进程崩溃
所以,生产环境下千万不要直接做keys *的操作!
exists
这个指令是用来查询key是否存在的
时间复杂度依旧是O(N),但是这个O(N)的N,取决于一次性查询的个数
因为哈希思想:本身就是通过一个映射关系找到一个位置去存放
这样的一次操作是O(1)的,但是查找N个那就是O(N)
简单使用如下:
redis
127.0.0.1:6379> exists key1
(integer) 0
127.0.0.1:6379> exists hello
(integer) 1
127.0.0.1:6379> exists hello hallo h*llo
(integer) 2返回值:返回存在的key的个数
补充:
exists命令支持一次查询多个key,这和redis本身的设计架构是有关系的:
首先redis是一个单线程的模型,是客户端-服务端架构
我们在命令行上的操作,其实是在redis的命令行客户端redis-cli做的
这一点和mysql很像,最终的操作都是要向服务端请求,然后服务端返回结果
而且:客户端和服务端之间是通过网络 来进行通信的!
使用网络,就必须走完网络协议栈那一套,这代价是很大的!
所以,这就是为什么redis要提供查询多个key的能力,而且也不只是exists这一个指令这么做
本质就是因为redis的本身架构特性导致的!
所以,能一次处理完的,就不要多次来处理
因为redis的快,只是相对于数据库操作磁盘的快!使用网络传输也是会有效率损耗的!
del
del就是delete的简写,就是删除某个key对应的键值对
返回值是删除成功的个数
时间复杂度是O(N),道理和exists是一样的
redis
127.0.0.1:6379> keys *
1) "hello"
2) "heeeeeeeeeeeeeeeeeeello"
3) "heeeeeeeeeeeeeeeeeeeallo"
4) "hcllo"
5) "hallo"
6) "hxllo"
127.0.0.1:6379> del hello hcllo hallo
(integer) 3
127.0.0.1:6379> keys *
1) "heeeeeeeeeeeeeeeeeeello"
2) "heeeeeeeeeeeeeeeeeeeallo"
3) "hxllo"这里也是一样的道理,能一次删除的就尽量不要拖到下一次!
expire
expire的作用就是给某个key设置过期时间,时间一到就自动地删除 默认单位为:second
还有一个是pexpire,对应的时间单位是:milliseconds(ms)
redis
127.0.0.1:6379> expire key1 5
(integer) 0
127.0.0.1:6379> expire hxllo 10
(integer) 1
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
"1"
127.0.0.1:6379> get hxllo
(nil)
127.0.0.1:6379> get hxllo
(nil)如果key不存在,设置就是失败的,返回0;成功就返回1
如果多次对一个key进行设置过期时间,那么时间会重复的刷新!
说到过期时间这个话题,就必须得聊一下redis下的过期策略
------即redis是如何检测到某个key是否已经过期了?
正常来说,我们的想法肯定是:
1.用一个小根堆(过期时间最少的在堆顶)
2.用一个时间轮,走到哪里就尝试释放哪里key当然还得进行时间检测,因为可能过期时间比时间轮的一轮还要长
但是,这种做法肯定是不能同步做的,要不然就不精准了,所以肯定是异步做的!
但是,redis是一个单线程模型,它的设计者在设计之初就没有使用着一些做法
那么,我们需要了解一下redis是如何做的呢?
主要是以下两点:
1.定期删除
2.惰性删除
定期删除 :redis为了保证效率,不会一直检测哪些key是否过期。而是采用定期抽取的方式,每个一定的时间,去抽取一部分的key做检测,如果过期就删除
惰性删除:这种惰性思想很常见。比如单例模式下的lazy load,用到才生成/获取。这里也是一样的,使用某个key的时候,会检查这个key是否过期了。如果过期了就删除,然后返回nil
redis主要就是通过这两种方式执行过期删除策略的
但是:虽然有了这两种方式,但是整体的效果肯定还是比较一般的。因为偶然性很大,很可能导致内存中还存留有大量过期的key没有被释放。
而redis操作的就是内存,这势必大大影响整体的工作效率!
所以,redis还提供了一系列的内存淘汰策略:
| 策略名称 | 核心逻辑 | 适用场景 |
|---|---|---|
noeviction(默认) |
不淘汰任何 key,内存满时拒绝所有写操作 (读操作正常),返回 OOM 错误 |
不允许丢失数据的场景(如核心业务缓存) |
allkeys-lru |
从所有 key 中淘汰最近最少使用(LRU)的 key | 冷热数据区分明显的场景(如普通业务缓存) |
volatile-lru |
仅从设置了过期时间的 key 中淘汰最近最少使用的 key | 部分 key 需永久保留,部分可淘汰的场景 |
allkeys-random |
从所有 key 中随机淘汰 key | 数据访问分布均匀,无明显冷热的场景 |
volatile-random |
仅从设置了过期时间的 key 中随机淘汰 key | 需保留永久 key,且冷热数据不明显的场景 |
volatile-ttl |
仅从设置了过期时间的 key 中淘汰剩余 TTL(过期时间)最短的 key | 优先淘汰快过期的临时数据(如验证码缓存) |
volatile-lfu(Redis4+) |
仅从设置了过期时间的 key 中淘汰最不常用(LFU)的 key | 访问频率比访问时间更重要的场景 |
allkeys-lfu(Redis4+) |
从所有 key 中淘汰最不常用(LFU)的 key | 高频访问数据需保留,低频可淘汰的场景 |
这些策略我们做一个了解即可,其实很容易理解的
这些策略是可以支持配置的:
1.通过redis.conf文件进行配置
2.通过动态命令配置当前会话有效
ttl
expire是用来设置key的过期时间的
ttl的功能与expire相反,它是来查询过期时间的:
返回值的含义如下:
| 返回值 | 数据类型 | 含义 |
|---|---|---|
> 0 |
整数 | key 存在且已设置过期时间,返回值为剩余过期时间(单位:秒) |
-1 |
整数 | key 存在,但未设置过期时间(永久有效) |
-2 |
整数 | key 不存在(已被删除、过期自动清理,或从未创建) |
还有个命令是pttl,这个查询的单位是ms,和expire那里很像
type
type命令就是来查询,某个key对应的value是什么类型的
在使用之前,先来了解一下redis下支持哪些类型的value:
| 序号 | 类型名称 | 底层依赖 | 核心用途 |
|---|---|---|---|
| 1 | 字符串(String) | 独立 | 缓存、计数器、分布式锁 |
| 2 | 哈希(Hash) | 独立 | 存储用户信息、商品属性 |
| 3 | 列表(List) | 独立 | 消息队列、最新评论、分页数据 |
| 4 | 集合(Set) | 独立 | 点赞、抽奖、交集/并集计算 |
| 5 | 有序集合(ZSet) | 独立 | 排行榜、延时队列、权重排序 |
| 6 | 流(Stream) | 独立 | 可靠消息队列、事件日志(Redis 5.0+) |
| 7 | 位图(Bitmap) | String | 签到、用户在线状态、精准计数 |
| 8 | 地理空间(Geospatial) | ZSet | 附近的人、距离计算、地理围栏 |
| 9 | 基数统计(HyperLogLog) | String | UV统计、海量数据去重计数(低精度) |
| 10 | 布隆过滤器(BloomFilter) | 模块/Set | 防缓存穿透、海量数据存在性判断 |
这些类型的具体使用,在后续的学习中都会提及
这里先做了解即可