系列内容:OpenCV概述与环境配置,OpenCV基础知识和绘制图形,图像的算数与位运算,图像视频的加载和显示,图像基本变换,滤波器,形态学,图像轮廓,图像直方图,车辆统计项目,特征检测和匹配,图像查找和拼接,虚拟计算器项目,信用卡识别项目,图像的分割与修复,人脸检测与车牌识别,目标追踪,答题卡识别判卷与文档ocr扫描识别,光流估计
(一)特征检测的基本概念
特征检测是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征检测的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。
特征检测包括边缘检测, 角检测, 区域检测和脊检测.
特征检测应用场景:
- 图像搜索, 比如以图搜图
- 拼图游戏
- 图像拼接
- ...
以拼图游戏为例来说明特征检测的应用流程.
寻找特征
- 特征是唯一的
- 特征是可追踪的
- 特征是能比较的
忍者神龟拼图,如图11.1所示:
 11.1-忍者神龟拼图
11.1-忍者神龟拼图
平面,边界,角点,如图11.2所示:
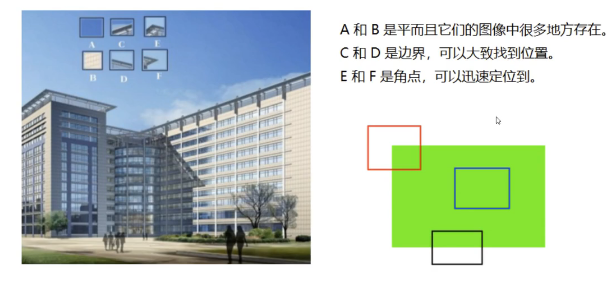 11.2-平面,边界,角点
11.2-平面,边界,角点
我们发现:
- 平坦部分很难找到它在原图中的位置
- 边缘相比平坦要好找一些,但是也不能一下确定
- 图像特征就是值有意义的图像区域,具有独特性,易于识别性,比较角点,斑点以及高密度区域
在图像特征中最重要的就是角点,哪些是角点呢?
- 灰度梯度最大值对应的像素
- 两条线的交点
- 极值点(一阶导数最大,二阶导数为零)
(二)Harris角点检测
角点检测示意图,如图11.3所示:
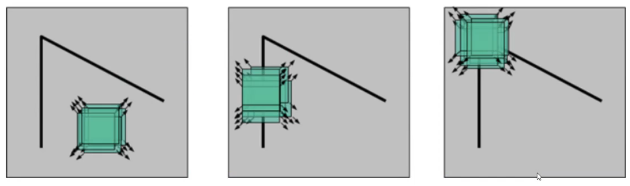 11.3-角点检测示意图
11.3-角点检测示意图
Harris角点检测原理
图像I(x,y)\|(x,y),当在点(x,y)(x,y)处平移(\\Delta{x},\\Delta{y})后的自相似性:
W(x,y)W(x,y)是以点(x,y)(x,y)为中心的窗口,即加权函数,例如高斯加权函数,高斯加权函数如图11.4所示:
 11.4-高斯加权函数
11.4-高斯加权函数
基于泰勒展开,对图像I(x,y)\|(x,y)在平移(\\Delta{x},\\Delta{y})后进行一阶近似:
其中,\|x,\|y\|x,\|y,是\|(x,y)\|(x,y)的偏导数
近似可得:
其中M:
化简可得:
二次项函数本质上就是一个椭圆函数,椭圆方程为:
椭圆函数的变化率,如图11.5所示:
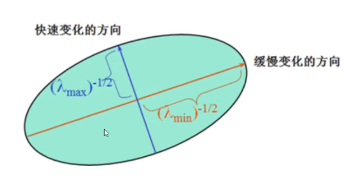 11.5-椭圆函数的变化率
11.5-椭圆函数的变化率
边界,平面,角点的特征值划分,如图11.6所示:
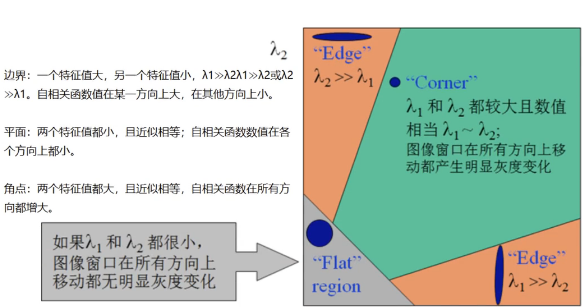 11.6-边界,平面,角点的特征值划分
11.6-边界,平面,角点的特征值划分
角点响应:
其中:
检测窗口在图像上移动,上图对应着三种情况:
- 在平坦区域,无论向哪个方向移动,衡量系统变换不大。
- 边缘区域,垂直边缘移动时,衡量系统变换剧烈。
- 在角点处,往哪个方向移动,衡量系统都变化剧烈。
cornerHarris(src, blockSize, ksize, k, dst\[, borderType]),参数:
- blockSize: 检测窗口大小
- ksize: sobel的卷积核
- k: 权重系数,即上面公式中的α,是个经验值,一般取0.04~0.06之间,一般默认0.04
示例代码:
python
import cv2
import numpy as np
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#角点检测
#blackSize没有要求必须是奇数
#返回角点响应
dst=cv2.cornerHarris(gray,blockSize=2,ksize=3,k=0.04)
print(gray.shape)
print(dst)
print(dst.shape)
print(type(dst))
#显示角点
#设定阈值,dat.max()
img[dst>(0.01*dst.max())]=[0,0,255]
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()关键代码:
imgdst\>(0.01\*dst.max())=0,0,255
权重系数为0.01时角点检测结果,运行结果:
如图11.7所示:
 11.7-权重系数为0.01时角点检测结果
11.7-权重系数为0.01时角点检测结果
权重系数为0.1时角点检测结果,出现失真,运行结果:
如图11.8所示:
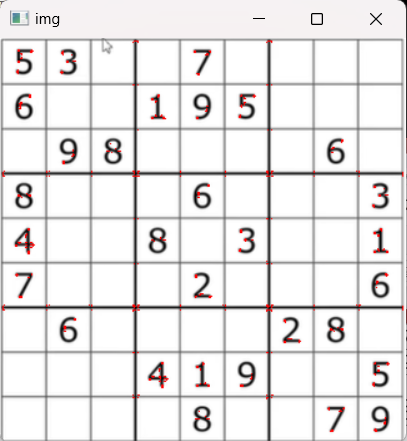 11.8-权重系数为0.1时角点检测结果
11.8-权重系数为0.1时角点检测结果
(三)Shi-Tomasi角点检测
Shi-Tomasi是Harris角点检测的改进。
Harris角点检测计算的稳定性和K有关,而K是一个经验值,不太好设定最佳的K值。
Shi-Tomasi发现,角点的稳定性其实和矩阵M的较小特征值有关,于是直接用较小的那个特征值作为分数。这样就不用调整K值了。
Shi-Tomasi将分数公式改为如下形式:
R=min(λ1,λ2)
和Harris一样,如果该分数大于设定的阈值,我们就认为它是一个角点.
goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance, corners, mask, blockSize, useHarrisDetector, k])))
- maxCorners: 角点的最大数,值为0表示无限制
- qualityLevel: 角点质量,小于1.0的整数,一般在0.01 - 0.1之间。
- minDistance: 角之间最小欧式距离,忽略小于此距离的点。
- mask: 感兴趣的区域。
- blockSize: 检测窗口大小
- useHarrisDetector: 是否使用Harris算法.
- k: 默认是0.04
示例代码:
python
#shi-tomasi角点检测
import cv2
import numpy as np
#img=cv2.imread('./table.jpg',flags=cv2.IMREAD_GRAYSCALE)
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#shi-Tomasi角点检测
corners=cv2.goodFeaturesToTrack(gray,maxCorners=0,qualityLevel=0.01,minDistance=10)
print(corners)
print(corners.shape)
# print(type(corners))
#img[dst>0.01*dst.max()]
corners=np.int0(corners)
#画出角点
for i in corners:
#i相当于corners中的每一行数据
#ravel()把二维变一维,即角点的坐标点
x,y=i.ravel()
cv2.circle(img,(x,y),3,(0,0,255),-1)
cv2.imshow('Shi-Tomasi',img)
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果:
corners=cv2.goodFeaturesToTrack(gray,maxCorners=0,qualityLevel=0.01,minDistance=10)
(1)maxCorners=0(默认值)时
运行结果如图11.9所示:
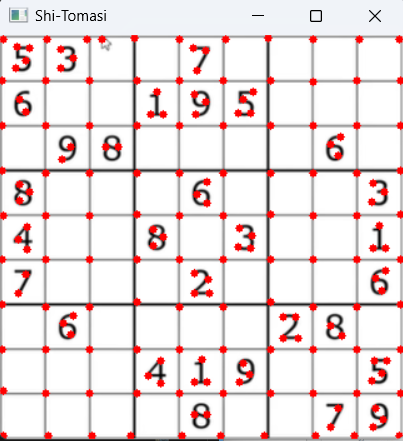 11.9-(1)maxCorners=0(默认值)时
11.9-(1)maxCorners=0(默认值)时
(2)maxCorners=100时
运行结果如图11.10所示:
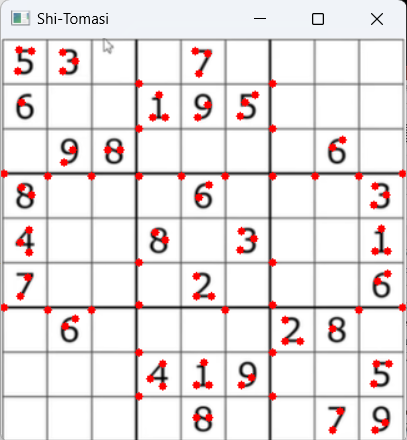 11.10-maxCorners=100
11.10-maxCorners=100
(四)SIFT关键点检测
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
Harris角点具有旋转不变的特性,但是缩放后,原来的角点有可能就不是角点了。
Harris角点的缩放改变性如图11.11所示:
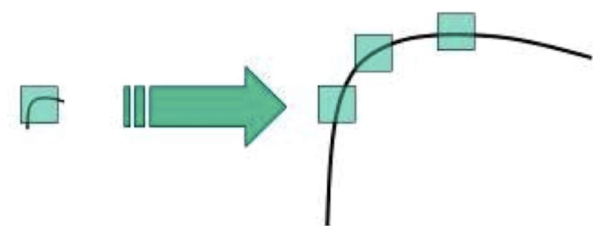 11.11-Harris角点的缩放改变性
11.11-Harris角点的缩放改变性
SIFT原理
(1)图像尺度空间
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点。
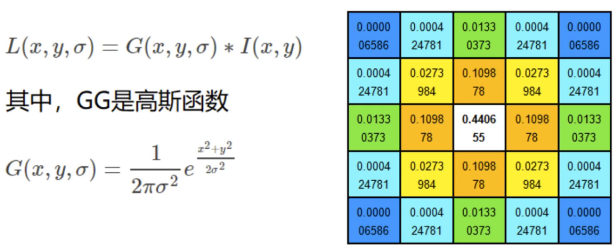
尺度空间的获取通常使用高斯模糊来实现。
不同的高斯函数决定了对图像的平滑程度,越大的σ值对应的图像越模糊。
高斯模糊实现尺度空间的获取,如图11.12所示:
 11.12-高斯模糊实现尺度空间的获取
11.12-高斯模糊实现尺度空间的获取
高斯模糊的过程,如图11.13所示:
 11.13-高斯模糊的过程
11.13-高斯模糊的过程
多分辨率金字塔,如图11.14所示:
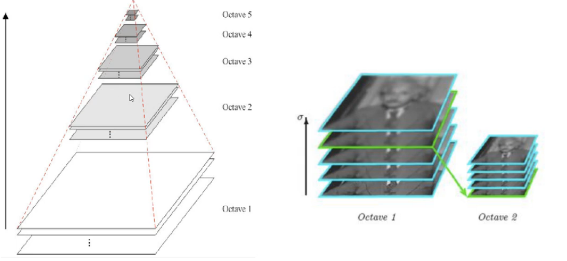 11.14-多分辨率金字
11.14-多分辨率金字
高斯差分金字塔(DOG),如图11.15所示:
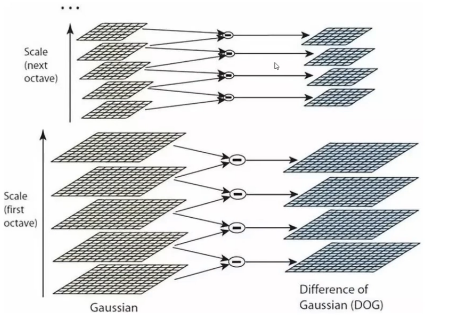 11.15-高斯差分金字塔(DOG)
11.15-高斯差分金字塔(DOG)
DoG空间极值检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。
DOG定义公式:
三层的某个点和周围以及上下26个点的比较,如图11.16所示:
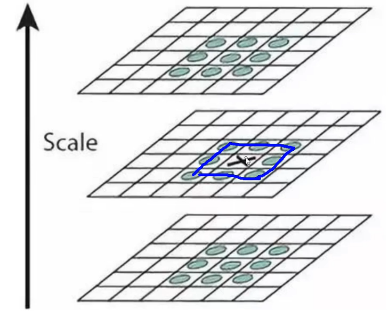 11.16-三层的某个点和周围以及上下26个点的比较
11.16-三层的某个点和周围以及上下26个点的比较
关键点的精确定位
这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间DoG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
泰勒展开得到真正的极值点,如图11.17所示:
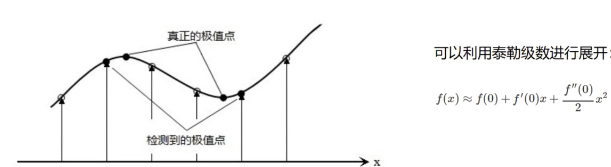 11.17-泰勒展开得到真正的极值点
11.17-泰勒展开得到真正的极值点
消除边界响应
Hessian矩阵:
令\\alpha=\\lambda_{max}为最大的特征值,\\beta=\\lambda_{min}为最小的特征值
Lowe在论文中给出的\\gamma = 10,也就是说对于主曲率比值大于10的特征点将被删除。
特征点的主方向
每个特征点可以得到三个信息(x, y, \\sigma, \\zeta),即位置、尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
每个点L(x,y)的梯度的模m(x,y)以及方向\\zeta(x,y):
每个点有八个方向,用直方图统计最多一个和第二个(占约第一个方向数量的0.8)个方向,即为该点的方向,如图11.18所示:
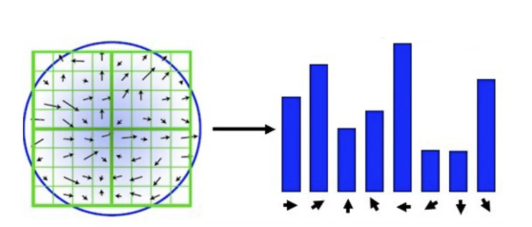 11.18-直方图统计点的方向
11.18-直方图统计点的方向
生成特征描述
为了保证特征矢量的旋转不变性,要以特征点为中心,在附近邻域内将坐标轴旋转θ角度,即将坐标轴旋转为特征点的主方向。如图11.19所示:
旋转之后以特征点为中心取8×8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4×4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征由4个种子点组成,每个种子点有8个方向的向量信息。
论文中建议对每个关键点使用4×4共16个种子点来描述,这样一个关键点就会产生128维的SIFT特征向量。
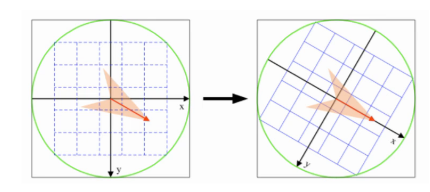 11.19-将坐标轴旋转为特征点的主方向
11.19-将坐标轴旋转为特征点的主方向
坐标变换过程:
通过小区间内向量相加,得到大区域的主方向,如图11.20所示:
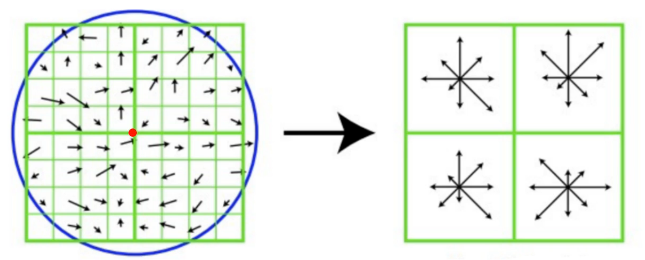 11.20-小区域向量相加,得到大区域的主方向
11.20-小区域向量相加,得到大区域的主方向
16*16个窗口生成128个方向向量,如图11.21所示:
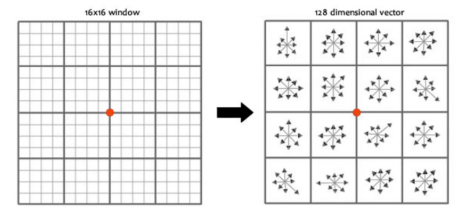 11.21-16*16个窗口生成128个方向向量
11.21-16*16个窗口生成128个方向向量
使用SIFT的步骤
创建SIFT对象:sift = cv2.xfeatures2d.SIFT_create()
进行检测:kp = sift.detect(img, ...)
绘制关键点:drawKeypoints(gray, kp, img)
示例代码:
python
#SIFT算法
import cv2
import numpy as np
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建sift对象
#注意:xfeatures2d是opencv的扩展包中的内容,需要安装opencv-contrib-python
sift=cv2.xfeatures2d.SIFT_create()
#进行检测
kp=sift.detect(gray)
#kp是一个列表,里面存放的是封装的KeyPoint对象
#print(kp)
#绘制关键点
cv2.drawKeypoints(gray,kp,img)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()SIFT对象检测,运行结果如图11.22所示.可以发现有许多非角点的特征点:
 11.22-SIFT对象检测
11.22-SIFT对象检测
关键点和描述子
关键点: 位置、大小和方向。
关键点描述子: 记录了关键点周围对其有共享的像素点的一组向量值,其不受仿射变换、光照变换等影响。描述子的作用就是进行特征匹配,在后面进行特征匹配的时候会用到。
python
#SIFT算法
import cv2
import numpy as np
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建sift对象
#注意:xfeatures2d是opencv的扩展包中的内容,需要安装opencv-contrib-python
sift=cv2.xfeatures2d.SIFT_create()
#进行检测
kp=sift.detect(gray)
#检测关键点,并计算描述子
kp,des=sift.compute(img,kp)
#或者一步到位,把关键点和描述子一起检测出来
kp,des=sift.detectAndCompute(img,None)
#print(kp)
print(len(kp))
print(type(des))
print(des)
print(des.shape)
print(des[0])
# 绘制关键点
cv2.drawKeypoints(gray,kp,img)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()print的运行结果,如图11.23所示:
 11.23-print的运行结果
11.23-print的运行结果
(五)SURF特征检测
Speeded Up Robust Features(SURF,加速稳健特征),是一种稳健的局部特征点检测和描述算法。最初由Herbert Bay发表在2006年的欧洲计算机视觉国际会议(Europen Conference on Computer Vision,ECCV)上,并在2008年正式发表在Computer Vision and Image Understanding期刊上。
Surf是对David Lowe在1999年提出的Sift算法的改进,提升了算法的执行效率,为算法在实时计算机视觉系统中应用提供了可能。
SIFT最大的问题就是速度慢, 因此才有了SURF.
如果想对一系列的图片进行快速的特征检测, 使用SIFT会非常慢.
注意:SURF在较新版本的OpenCV中已经申请专利, 需要降OpenCV版本才能使用. 降到3.4.1.15就可以用了.
python
#SURF算法
import cv2
import numpy as np
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建surf对象
surf=cv2.xfeatures2d.SURF_create()
#返回的是列表,里面每一个都是一个keypoint对象
kp=surf.detect(gray)
kp,des=suf.detectAndCompute(img,None)
# print(type(kp))
# print(type(kp[0]))
# print(kp[0])
print(type(des))
print(des.shape)
#检测关键点,并计算描述子(描述符)
surf.computer(img,kp)
#绘制关键点
cv2.drawKeypoints(gray,kp,img)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()由于专利保护,受限,运行结果和SIFT差不多,不再赘述.
(六)ORB特征检测
ORB(Oriented FAST and Roted BRIEF)是一种快速特征点提取和描述的算法。这个算法是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年一篇名为"ORB: An Efficient Alternative to SIFTor SURF"
(http://www.willowgarage.com/sites/default/files/orb\\_final.pdf )的文章中提出。ORB算法分为两部分,分别是特征点提取和特征点描述。特征提取是由FAST(Features from Accelerated Segment Test)算法发展来的,特征点描述是根据BRIEF(Binary Robust IndependentElementary Features)特征描述算法改进的。
- ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。
- ORB算法最大的特点就是计算速度快。这首先得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再次是使用BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
- ORB最大的优势就是可以做到实时检测
- ORB的劣势是检测准确性略有下降.
- ORB还有一个优势是ORB是开源的算法, 没有版权问题, 可以自由使用.SIFT和SURF都被申请了专利.
python
#SURF算法
import cv2
import numpy as np
img=cv2.imread('./table.jpg')
#变成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建ORB对象
orb=cv2.ORB_create()
#进行检测
kp=orb.detect(gray)
#一步到位,把关键点和描述子一起检测出来
kp,des=orb.detectAndCompute(img,None)
print(type(kp))
print(type(kp[0]))
print(kp[0])
print(type(des))
print(des.shape)
#绘制关键点
cv2.drawKeypoints(gray,kp,img)
cv2.imshow('ORB',img)
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果:
python
<class 'list'>
<class 'cv2.KeyPoint'>
<KeyPoint 000001E15F02E270>
<class 'numpy.ndarray'>
(500, 32)ORB检测结果,如图11.24所示:
 11.24-ORB检测结果
11.24-ORB检测结果
各种匹配结果对比:
- SIFT最慢,准确率最高
- SURF速度比SIFT快些,准确率低一些
- ORB速度最快,可以实时检测,准确率最差
(七)暴力特征匹配
我们获取到图像特征点和描述子之后,可以将两幅图像进行特征匹配。
BF(Brute - Force)暴力特征匹配方法,通过枚举的方式进行特征匹配。
暴力匹配器很简单。它使用第一组(即第一幅图像)中一个特征的描述子,并使用一些距离计算将其与第二组中的所有其他特征匹配。并返回最接近的一个。
(1)BFMatcher(normType, crossCheck)
- normType计算距离的方式。
- NORM_L1,L1距离,即绝对值,SIFT和SURF使用。
- NORM_L2,L2距离,默认值,即平方,SIFT和SURF使用。
- HAMMING汉明距离,ORB使用。
- crossCheck:是否进行交叉匹配,默认False。
(2)使用match函数进行特征点匹配,返回的对象为DMatch对象。该对象具有以下属性:
- DMatch.distance - 描述符之间的距离。越低,它就越好。
- DMatch.trainIdx - 训练描述符中描述符的索引
- DMatch.queryIdx - 查询描述符中描述符的索引
- DMatch.imgIdx - 训练图像的索引
示例代码:
python
#暴力特征匹配
import cv2
import numpy as np
img1=cv2.imread('./search01.png')
img2=cv2.imread('./orgin01.png')
#变成灰度图片
gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测对象
sift=cv2.xfeatures2d.SIFT_create()
#计算描述子
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)
#进行暴力匹配
bf=cv2.BFMatcher(cv2.NORM_L1)
#进行匹配
match=bf.match(des1,des2)
print(match)
print(len(match))
print(type(match))
print(match[0].distance)
#图1的queryIdx和图2的trainIdx对应
print(match[0].queryIdx)
print(match[0].trainIdx)
#绘制特征匹配
result=cv2.drawMatches(img1,kp1,img2,kp2,match,None)
cv2.imshow('result',result)
cv2.waitKey(0)
cv2.destroyAllWindows()对于bf=cv2.BFMatcher(cv2.NORM_L1):
(1)L1(绝对距离)匹配结果,如图11.25所示:
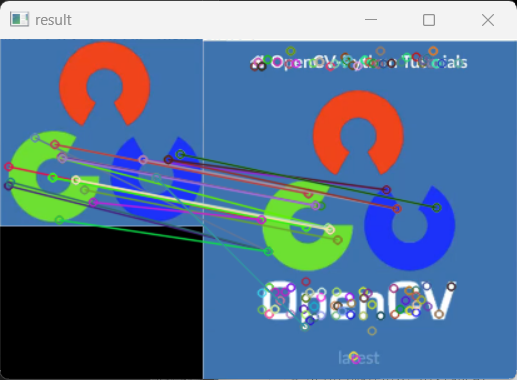 11.25-L1(绝对距离)匹配结果
11.25-L1(绝对距离)匹配结果
print输出结果:
python
[<DMatch 000001788C411E50>, <DMatch 000001788C239E70>, <DMatch 000001788C22BC70>, <DMatch 000001788C234290>, <DMatch 000001788C234B10>, <DMatch 000001788C2342F0>, <DMatch 000001788C234550>, <DMatch 000001788C2345B0>, <DMatch 000001788C2346B0>, <DMatch 000001788C234190>, <DMatch 000001788C234C70>, <DMatch 000001788C234FB0>, <DMatch 000001788C2348F0>, <DMatch 000001788C234590>, <DMatch 000001788C234CD0>, <DMatch 000001788C234370>, <DMatch 000001788C2342B0>, <DMatch 000001788C234C30>, <DMatch 000001788C234430>, <DMatch 000001788C234570>, <DMatch 000001788C2342D0>, <DMatch 000001788C234E90>, <DMatch 000001788C269E50>, <DMatch 000001788C269ED0>, <DMatch 000001788C269DF0>]
25
<class 'list'>
838.0
0
9(2)L2(欧式距离)匹配结果,如图11.26所示:
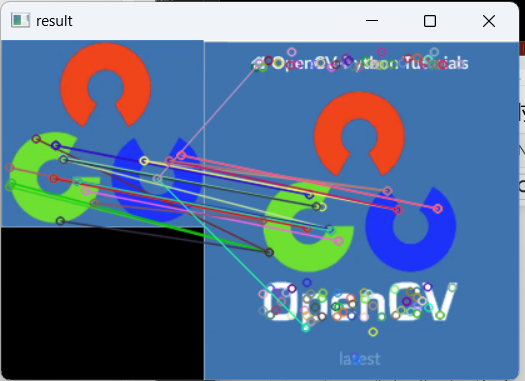 11.26-L2(欧式距离)匹配结果
11.26-L2(欧式距离)匹配结果
print输出结果:
python
[<DMatch 000001788C24A550>, <DMatch 000001788C2396F0>, <DMatch 000001788C239ED0>, <DMatch 000001788C22B050>, <DMatch 000001788C22BD50>, <DMatch 000001788C22BE10>, <DMatch 000001788C22B830>, <DMatch 000001788C22B950>, <DMatch 000001788C22B8B0>, <DMatch 000001788C22B770>, <DMatch 000001788C2345F0>, <DMatch 000001788C2344B0>, <DMatch 000001788C234C10>, <DMatch 000001788C234BF0>, <DMatch 000001788C2349D0>, <DMatch 000001788C234410>, <DMatch 000001788C2348B0>, <DMatch 000001788C234D10>, <DMatch 000001788C269F30>, <DMatch 000001788C269E70>, <DMatch 000001788C269EF0>, <DMatch 000001788C269E30>, <DMatch 000001788C269E90>, <DMatch 000001788C269490>, <DMatch 000001788C269DB0>]
25
<class 'list'>
175.52777099609375
0
9(3)KnnMatch
示例代码:
python
#暴力特征匹配(Knn)
import cv2
import numpy as np
img1=cv2.imread('./search01.png')
img2=cv2.imread('./orgin01.png')
#变成灰度图片
gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测对象
sift=cv2.xfeatures2d.SIFT_create()
#计算描述子
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)
#进行暴力匹配
bf=cv2.BFMatcher(cv2.NORM_L1)
#进行匹配
# match=bf.match(des1,des2)
#除了match可以进行匹配,还有knnMatch
#一般k=2
match=bf.knnMatch(des1,des2,k=2)
print(match)
print(len(match))
print(type(match))
print(match[0][0].distance)
#图1的queryIdx和图2的trainIdx对应
print(match[0][0].queryIdx)
print(match[0][0].trainIdx)
#绘制特征匹配
# result=cv2.drawMatches(img1,kp1,img2,kp2,match,None)
#专用knnMatch的匹配结果
result=cv2.drawMatchesKnn(img1,kp1,img2,kp2,match,None)
cv2.imshow('result',result)
cv2.waitKey(0)
cv2.destroyAllWindows()print运行结果:
python
[[<DMatch 000001788C22B850>, <DMatch 000001788C389A70>], [<DMatch 000001788C389990>, <DMatch 000001788C389F70>], [<DMatch 000001788C389910>, <DMatch 000001788C389FB0>], [<DMatch 000001788C389970>, <DMatch 000001788C3898F0>], [<DMatch 000001788C389930>, <DMatch 000001788C3899B0>], [<DMatch 000001788C389B30>, <DMatch 000001788C389A50>], [<DMatch 000001788C389B70>, <DMatch 000001788C389A10>], [<DMatch 000001788C389AB0>, <DMatch 000001788C389AD0>], [<DMatch 000001788C389F30>, <DMatch 000001788C389A30>], [<DMatch 000001788C389AF0>, <DMatch 000001788C389B10>], [<DMatch 000001788C3899D0>, <DMatch 000001788C389B90>], [<DMatch 000001788C389BB0>, <DMatch 000001788C389BD0>], [<DMatch 000001788C389BF0>, <DMatch 000001788C389C10>], [<DMatch 000001788C389C30>, <DMatch 000001788C389C50>], [<DMatch 000001788C389C70>, <DMatch 000001788C389C90>], [<DMatch 000001788C389CB0>, <DMatch 000001788C389CD0>], [<DMatch 000001788C389CF0>, <DMatch 000001788C389D10>], [<DMatch 000001788C389D30>, <DMatch 000001788C389D50>], [<DMatch 000001788C389D70>, <DMatch 000001788C389D90>], [<DMatch 000001788C389DB0>, <DMatch 000001788C389DD0>], [<DMatch 000001788C389DF0>, <DMatch 000001788C389E10>], [<DMatch 000001788C389E30>, <DMatch 000001788C389E50>], [<DMatch 000001788C389E70>, <DMatch 000001788C389E90>], [<DMatch 000001788C389EB0>, <DMatch 000001788C389ED0>], [<DMatch 000001788C389EF0>, <DMatch 000001788CC715D0>]]
25
<class 'list'>
838.0
0
9Knn运行结果,发现当match=bf.knnMatch(des1,des2,k=2)中k=2时,出现多对一,的情况如图11.27所示:
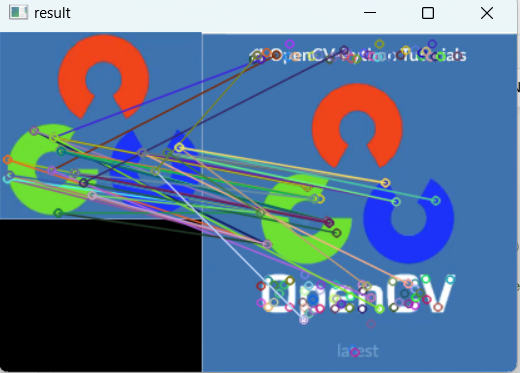 11.27-Knn运行结果(k=2)
11.27-Knn运行结果(k=2)
KNN优化(设置0,8倍的distance限制):
示例代码:
python
#暴力特征匹配(Knn)优化
import cv2
import numpy as np
img1=cv2.imread('./search01.png')
img2=cv2.imread('./orgin01.png')
#变成灰度图片
gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测对象
sift=cv2.xfeatures2d.SIFT_create()
#计算描述子
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)
#进行暴力匹配
bf=cv2.BFMatcher(cv2.NORM_L1)
#进行匹配
# match=bf.match(des1,des2)
#除了match可以进行匹配,还有knnMatch
#一般k=2
match=bf.knnMatch(des1,des2,k=2)
print(match)
print(len(match))
print(type(match))
print(match[0][0].distance)
#图1的queryIdx和图2的trainIdx对应
print(match[0][0].queryIdx)
print(match[0][0].trainIdx)
#绘制特征匹配
# result=cv2.drawMatches(img1,kp1,img2,kp2,match,None)
#专用knnMatch的匹配结果
good=[]
for m,n in match:
#设定阈值,距离小于对方距离的0.8倍,我们认为是好的匹配点
if m.distance<0.8*n.distance:
good.append(m)
result=cv2.drawMatchesKnn(img1,kp1,img2,kp2,[good],None)
cv2.imshow('result',result)
cv2.waitKey(0)
cv2.destroyAllWindows()KNN优化(设置0,8倍的distance限制),如图11.28所示:
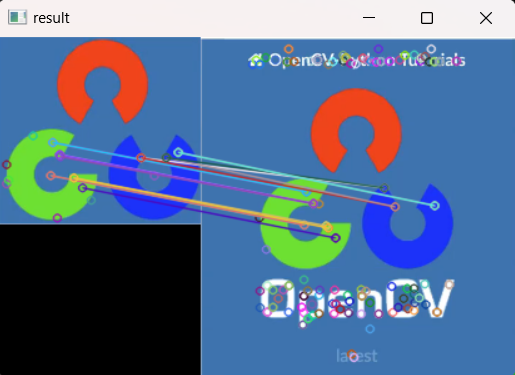 11.28-KNN优化(设置0,8倍的distance限制)
11.28-KNN优化(设置0,8倍的distance限制)
(八)FLANN特征匹配
FLANN是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors)的简称。它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集是它的效果要好于BFMatcher。
特征匹配记录下目标图像与待匹配图像的特征点(KeyPoint),并根据特征点集合构造特征量(descriptor),对这个特征量进行比较、筛选,最终得到一个匹配点的映射集合。我们也可以根据这个集合的大小来衡量两幅图片的匹配程度。
FlannBasedMatcher(index_params)
index_params字典:匹配算法KDTREE, LSH, SIFT和SURF使用KDTREE算法,OBR使用LSH算法.
设置示例: index_params=dict(algorithm=cv2.FLANN_INDEX_KDTREE, tree=5)
FLANN_INDEX_LSH = 6index_params= dict(algorithm = FLANN_INDEX_LSH, table_number = 6, #12 key_size = 12, # 20 multi_probe_level = 1#2)
search_params字典: 指定KDTREE算法中遍历树的次数.经验值, 如KDTREE设为5, 那么搜索次数设为50.
search_params = dict(checks=50)
Flann中除了普通的match方法,还有knnMatch方法.
多了个参数--k, 表示取欧式距离最近的前k个关键点.
FLANN用法,示例代码:
python
#FLANN
import cv2
import numpy as np
img1=cv2.imread('./search01.png')
img2=cv2.imread('./orgin01.png')
#变成灰度图片
gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
#创建特征检测对象
sift=cv2.xfeatures2d.SIFT_create()
#计算描述子
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)
#创建FLANN特征匹配对象
index_params=dict(algorithm=1,tree=5)
#根据经验,kdtree设置5个tree,那么checks一般设置为50
search_params=dict(checks=50)
flann=cv2.FlannBasedMatcher(index_params,search_params)
matches=flann.match(des1,des2)
print(len(matches))
result=cv2.drawMatches(img1,kp1,img2,kp2,matches,None)
cv2.imshow('result',result)
cv2.waitKey(0)
cv2.destroyAllWindows()FLANN算法运行结果,如图11.29所示:
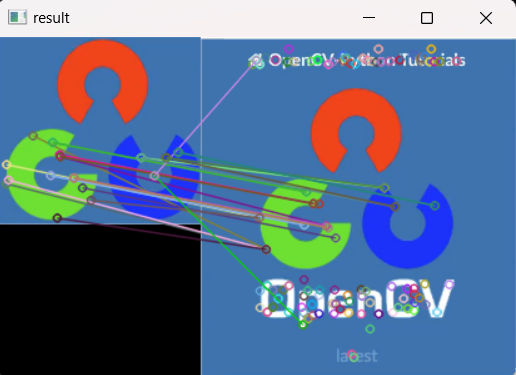 11.29-FLANN算法运行结果
11.29-FLANN算法运行结果