🌰回顾
前面几篇分别分享了AI大模型是怎么理解人类词汇和语言的,也分析了大模型为啥每次回答得不一样。那么大模型到底是怎么得出答案的呢?
同样,我们回到之前提到的一个经典的Case:
输入:我有一个苹果,它很好...
如果是人,可能怎么续写呢?
- 张三:我有一个苹果,它很好吃,特别甜
- 李四:我有一个苹果,它很好用,流畅又丝滑
这又是为什么呢?
- 张三这样答是因为他的苹果是水果,能吃的水果
- 李四这样答是因为他的苹果是电子设备,日常使用的设备
或者我们从另一个角度分析:
- 任何人续写都有自己的备选词
- 张三家里只有吃的苹果,所以他的备选词库里 "吃"的概率较大
- 李四家里可能也有苹果但可能不爱吃不关注,同时他刚好有台苹果手机,所以他的备选词库里 "用"的概率较大
那么,AI大模型的思路是否也是如此? 没错,答案是肯定的。AI也是类似的思维(通俗地讲):
-
AI大模型在之前训练的时候对每个词汇都有相应的向量矩阵
-
AI在续写时根据每个词汇的向量矩阵之间的相关性理解语义
-
AI在续写下一个词汇时,分析哪个词汇与整个句子的语义相关性最大,即判为出现概率最大。最终将被选为续写的词汇
Transformer专业解释
前面讲过词向量和Attention机制, 我们可以再看看Transformer架构中关于AI大模型得出答案的分析。
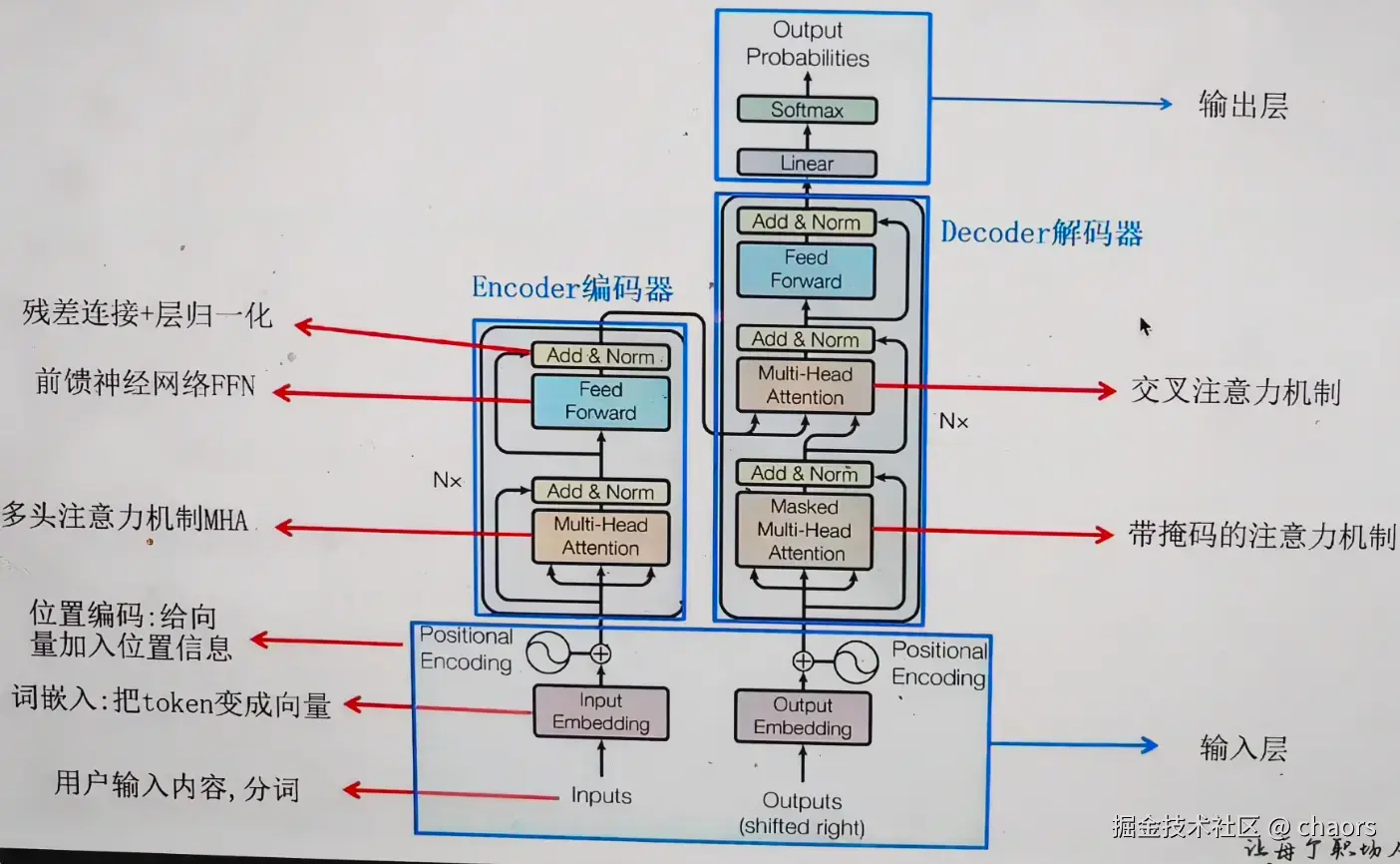
Input负责信息输入和位置编码,Encoder负责语义理解。Decoder负责答案和续写。
几个注意力机制
首先再回顾一下之前讲到的注意力机制的概念:
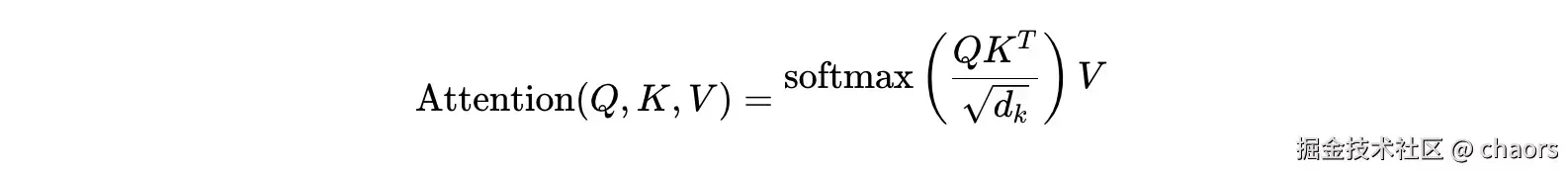
在Transformer架构中,我们发现有3个地方使用到了注意力机制:
-
Encoder Self-Attention:
- Q, K, V 都来自 Encoder 自己。
- 作用:理解原文内部的逻辑。比如"苹果"这个词,在"苹果很好吃"和"苹果发布了新手机"里意思不同。Self-Attention 能通过上下文("好吃" vs "手机")来确定"苹果"的含义。
-
Encoder-Decoder Attention/Cross-Attention:
- Q 来自 Decoder(我正在理解的词)。
- K, V 来自 Encoder(原文的所有词)。
- 作用:连接编码器和解码器,让解码器在生成每个目标词时,能够有选择地从编码器的输出中提取相关信息。(eg:读到苹果,回去联系前面所有词确定相关性)。
-
Masked Decoder Self-Attention/Causal Self-Attention:
- Q, K, V 都来自 Decoder 自己。
- Mask(掩码):这是关键!确保在生成序列时,每个位置只能关注它之前的信息,防止"偷看"未来,这是实现自回归生成的关键。
- 实现:把未来的位置设为负无穷大 (− ∞ -\infty−∞),Softmax 之后就变成了 0,相当于强行遮住眼睛。
输入和输出
Add & Norm
-
Add(残差连接) :将子层(如注意力机制或前馈网络)的输入与输出直接相加:
输出 = 输入 + 子层(输入)- 解决梯度消失问题:为反向传播提供"高速公路",让梯度可以直接跨越多个层传播
- 数学本质:当网络层数很深时,梯度需要通过链式法则连续相乘,容易衰减到接近零。残差连接确保梯度路径中始终存在值为1的直连路径
-
Norm(层归一化) :对相加后的结果进行标准化处理,使其均值为0,方差为1
- 稳定每层的输入分布:解决内部协变量偏移问题
- 具体操作:对每个样本的所有特征维度计算均值和方差,然后进行标准化
-
一个🌰:100人传话游戏,每人代表一层网络
-
没有Add:每传一人就失真20%,到最后几乎完全变形(梯度消失)
-
有Add:每人在传话同时,原始信息也直接传给最后一人,确保核心信息不丢失
-
Feed Forward
作为大模型"信息聚合"到"信息升华"的关键一步,其核心框架图如下:
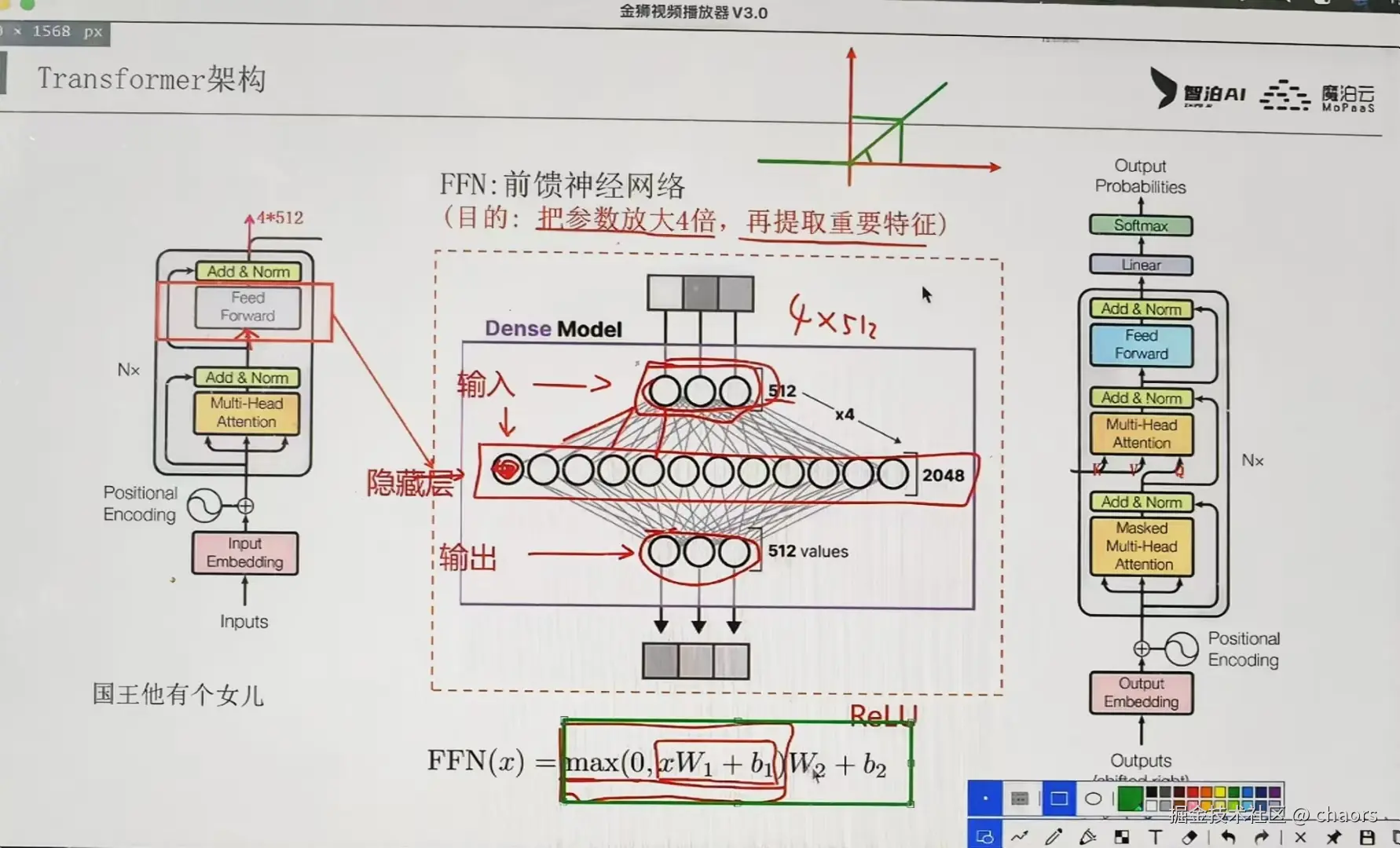
Attention就像一个团队会议让AI理解输入,而FFN就像会后的独立思考与加工 ,对每个词融合了上下文信息后的表示进行深度非线性变换和提升。
-
【核心】:输入向量先通过一个线性层扩展到更高维度(通常4倍),经过非线性激活函数,再投影回原始维度
-
【流程】:
- 升维-第一层线性变换:模式探测器 (Key层)。其庞大的参数矩阵中,不同的神经元单元专门负责检测输入信息中是否存在其学习过的特定"模式"。
- 🌰:当输入一个带有"水果"语境信息的 "苹果" 这个词向量时,FFN内部某个专门负责探测 "食物+水果" 模式的神经元就会被强烈激活,产生一个很高的数值。
- 激活函数 (如ReLU, GELU):智能筛选器。根据探测器信号的强弱,决定让多少信息通过。对重要的模式特征"开绿灯"放行甚至放大;对不重要或负面的特征则进行抑制或完全"关闭"。
- 🌰:紧接着,激活函数(如ReLU或GELU)会扮演筛选器 的角色。它会根据信号的强弱来决定信息的去留和强度。比如,ReLU会直接将所有负值置零(弱化),而只保留正值(强化)。eg:负责探测 "国家"、"交通" 等模式的神经元会被过滤
- 降维-第二层线性变换:知识提取器 (Value层)。接收经过筛选的特征信号,并从其参数中组合出对应的"知识"或"答案",贡献到最终输出中。
- 🌰:经过筛选后的激活信号会传递到第二层线性变换(降维层)。这一层的作用类似于一个知识库或答案库 。它与第一层探测到的模式是紧密绑定的。最终答案就会更接近于 "苹果" 本身的语义
- 升维-第一层线性变换:模式探测器 (Key层)。其庞大的参数矩阵中,不同的神经元单元专门负责检测输入信息中是否存在其学习过的特定"模式"。
-
【作用】:
-
自注意力本质是加权求和(线性操作),即使堆叠多层,整体仍近似线性变换。FFN通过激活函数(ReLU/GELU)引入关键非线性 ,使模型能够拟合复杂函数,强化重要信息 (如"电子产品"、"市场需求"),过滤或削弱次要或无关的联想(比如"苹果"的水果属性)。实验表明,移除FFN会导致模型性能下降15-30%。
-
FFN的"扩展-压缩"策略极具智慧:当维度从512扩展到2048时,模型获得了更大的特征组合空间。
- 🌰:摄影师先用广角镜头捕捉全景,再聚焦关键细节------在高维空间中进行特征交互后,再精炼回核心信息
-
在大语言模型中,FFN通常占据60-70%的参数总量 。以GPT-3为例,其FFN层参数规模达到数百亿,成为模型的"知识存储器"。这种参数分布不是偶然,而是设计上的必然选择。
- FFN的参数主要存在于那两个线性层的巨大权重矩阵中,特别是当它把维度从
d_model(如1024维)扩展到d_ff(如4096维)时,参数量会急剧增长
- FFN的参数主要存在于那两个线性层的巨大权重矩阵中,特别是当它把维度从
-
与自注意力不同,FFN对每个位置独立处理,这种设计实现了极致并行化。在GPU集群上,所有token的FFN计算可以同时进行,极大提升训练效率
-
FFN 和 Attention
-
Attention是线性变换 的, 就像简单的复制粘贴或按比例缩放 。比如,把 "苹果" 这个词的信息放大两倍,得到的只是 "苹果苹果",并没有产生新的、更深刻的理解。自注意力机制本质上就是一种复杂的加权平均(线性组合),它能把"苹果"和"公司"的信息组合起来,但组合方式依然是线性的。
-
FFN是非线性变换 ,也正是这种非线性变化给Transformer带来了 创造性 。 就好比是烹饪或化学反应。我们把西红柿(信息A)和鸡蛋(信息B)放进锅里(FFN),经过加热(激活函数),生成了一道全新的菜------西红柿炒鸡蛋(新信息C)。这个过程是创造性的,不是简单的线性叠加。