前沿
在数据库技术日新月异的今天,天翼云开源的 OpenTeleDB 无疑是一匹黑马。对于深受 PostgreSQL 高并发连接瓶颈和膨胀问题困扰的架构师来说,它提供了一套令人眼前一亮的解决方案。本文不谈虚的,我将直接基于 PostgreSQL 17 内核,重点剖析 OpenTeleDB 的两大核心组件:XProxy(高性能代理)与 XStore(存储引擎)。接下来,请跟随我的视角,通过实际部署与拆解,看看它是否真的如传说中那样,能成为解决数据库性能瓶颈的"银弹"。

一、抛开光环看本质:OpenTeleDB 的定位与家底
很多朋友第一次看到 OpenTeleDB,可能会问:这和市面上那么多 PG 发行版有啥区别?
简单来说,你可以把它看作是 PostgreSQL 17 的"高性能进化版" 。它没有去搞那些花里胡哨的时序或列存概念,而是死磕 OLTP(在线事务处理) 场景。
它的核心逻辑非常清晰:针对 PostgreSQL 那个让人又爱又恨的 MVCC 机制,OpenTeleDB 拿出了一个"杀手锏"------基于原位更新(In-place Update)技术的 XStore 引擎 。这一改动,直接从根源上缓解了 PG 著名的表膨胀问题,让数据库在高并发写入下也能保持"身材苗条",不再因为频繁的垃圾回收(Vacuum)而引发性能抖动。
1.1 初看架构:它给我的第一印象是'克制'
- 定位"人间清醒",不乱蹭热点 很多开源项目喜欢什么火蹭什么,但 OpenTeleDB 很诚实------明确表示自己不是 云原生分布式。由于其默认未加载时序插件,在处理极大规模时序指标时,我更倾向于将其定位为高性能的数据落地层。它老老实实基于 PostgreSQL 17 开发,这就意味着它继承了 PG 强大的生态,不搞那些让开发者重新学习一套语法的"伪创新"。
- 专治"疑难杂 症",刀刀见血它的改进非常有针对性。PostgreSQL 用户最怕什么?怕连接数爆了,怕 Vacuum 跑不过来导致表膨胀。OpenTeleDB 没有去堆砌花哨的功能,而是通过 XStore 存储引擎 引入了 原位更新(In-place Update)。这一招直接废掉了 PG 传统的 Append-only 机制带来的副作用,属于典型的"架构级外科手术"。
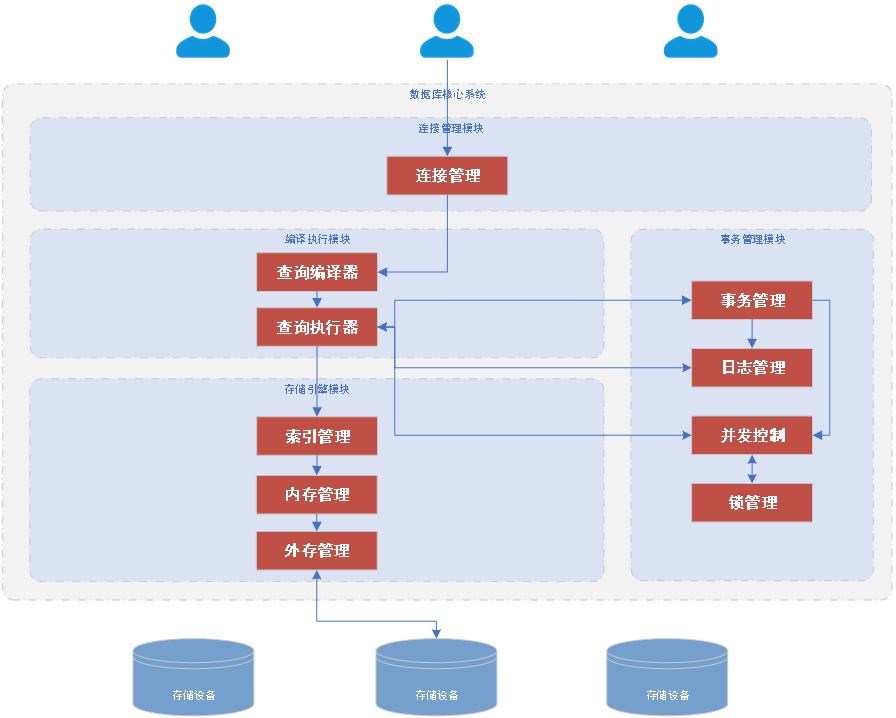
- 架构回归本源 看它的架构图,从连接管理到查询执行,再到底层的存储管理,逻辑非常清晰。它没有为了"分布式"而把简单问题复杂化,而是专注于在单机 OLTP 场景下把性能榨干。
1.2 OpenTelDB应用场景
- 核心交易系统 ( OLTP) 最典型的就是订单、支付、计费系统。
-
- 理由:这些场景更新(Update)特别频繁,OpenTeleDB 的"原位更新"正好能扛住,不会因为垃圾回收(Vacuum)导致系统卡顿。
- 物联网数据接入 (IoT) 用来接收海量设备发来的数据。
-
- 注意 :它写入速度确实快,但它不是专门的时序数据库(默认没带那个插件),单纯拿来做高并发的数据落地存储是没问题的。
- 地图与位置服 务 (GIS) 做城市规划、物流调度、地图应用。
-
- 理由:它完美继承了 PostGIS 的能力,处理空间数据一直都是 PG 系的强项。
- 企业复杂系统 (ERP/CRM) 处理财务报表、供应链这种复杂逻辑。
-
- 理由:基于 PostgreSQL 17 内核,SQL 兼容性好,跑复杂查询和长事务比较稳。
1.3 硬核拆解:OpenTeleDB 的"双引擎"秘密
在开始压测前,必须先看懂 OpenTeleDB 最核心的两个"黑科技"。如果把数据库比作高速公路,XProxy 解决了"入口拥堵",而 XStore 解决了"路面坑洼"。
XProxy:连接风暴的"防洪堤"
- 痛点:原生 PostgreSQL 采用"多进程模型",每一个客户端连接都需要消耗独立的进程资源。一旦并发数过千,CPU 光是处理上下文切换就得累趴下。
- 解法 :XProxy 是一个内置的高性能连接复用层。它像一个智能网关,在前端接收海量并发请求(如 10,000+),在后端仅需维护少量的数据库长连接。
- 价值 :它实现了连接多路复用,让数据库彻底告别了"连接数爆炸"的风险,且对业务代码完全透明,无需修改驱动。
XStore:给存储内核做"减法"
- 痛点 :PostgreSQL 的 MVCC 机制采用 Append-only(追加更新) 策略。简单说,更新一行数据 = 标记旧行删除 + 插入新行。这导致表空间不断膨胀,必须依赖
Vacuum进程在后台不停"扫地",极易引发性能抖动。 - 解法 :XStore 引入了类似 Oracle/MySQL 的Undo 回滚段 机制,实现了原位更新(In-place Update)。
- 价值 :新数据直接覆盖旧数据,旧版本移入 Undo Log。这种设计从根源上消灭了死元组(Dead Tuples),让表空间在频繁更新下依然能保持"身材苗条",同时消除了 Vacuum 带来的 I/O 冲击。
二、数据库系统实践:OpenTeleDB 环境部署手册
2.1 依赖安装
|----------------|------------|
| | |
| 所属软件 | 建议版本 |
| gcc | 4.8 及以上 |
| gcc-c++ | 4.8 及以上 |
| make | 3.82 及以上 |
| bison | 3.0 及以上 |
| flex | 2.5.31 及以上 |
| readline-devel | 6.0 及以上 |
| zstd-devel | 1.4.0 及以上 |
| lz4-devel | 1.8.0 及以上 |
| openssl-devel | 1.1.1 及以上 |
2.2 部署数据库
2.2.1 源码获取:克隆官方仓库
源码地址:https://gitee.com/teledb/openteledb
暂时无法在飞书文档外展示此内容

2.2.2 依赖就绪:核心组件安装与版本核验
- 安装依赖
暂时无法在飞书文档外展示此内容
- 写一个脚本检查结果
2.2.3 核心构建:自动化编译与安装
配置环境变量并执行编译,建议将安装目录与数据目录分开管理:
暂时无法在飞书文档外展示此内容
- 开始编译和安装
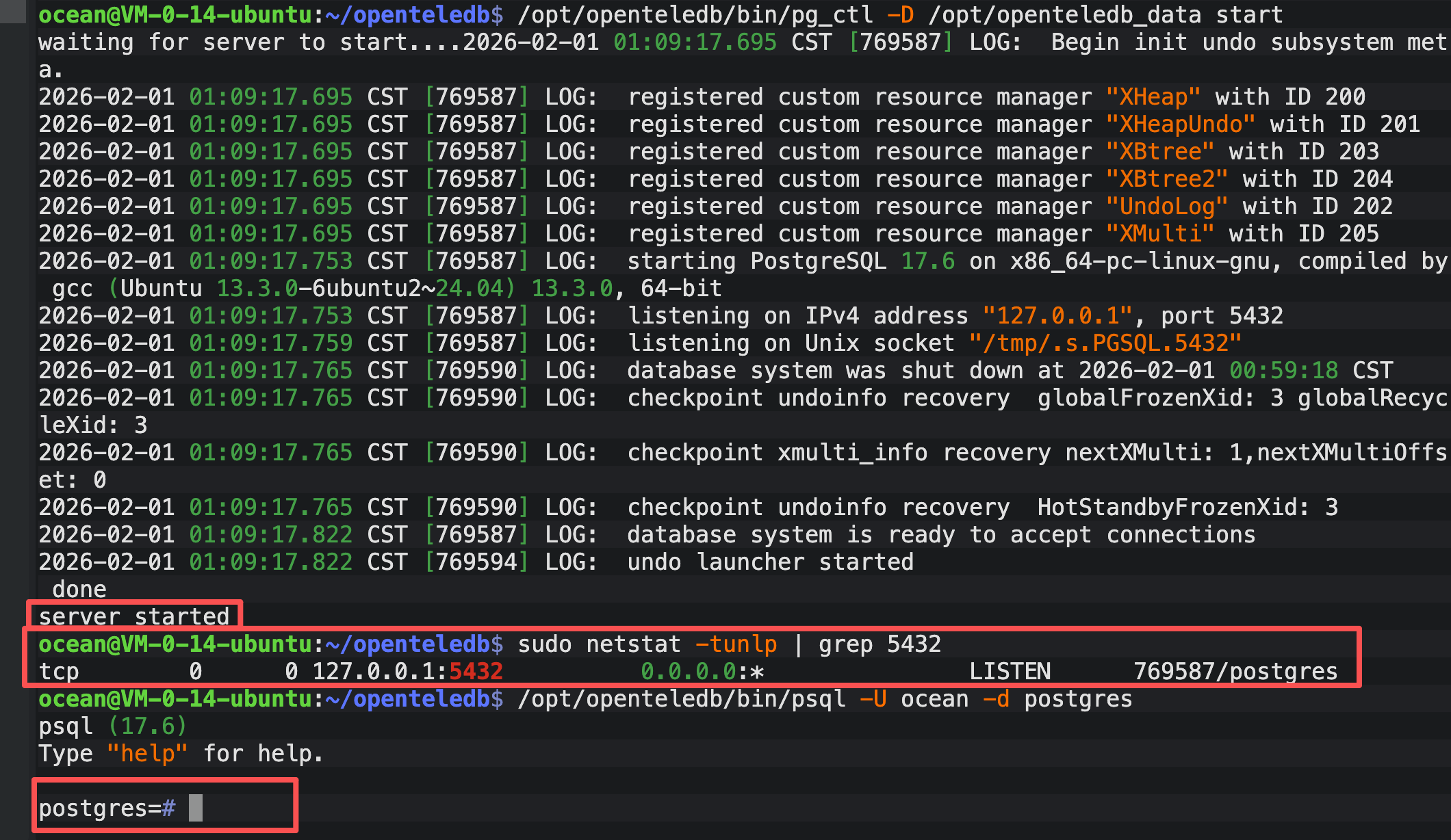
2.2.4 实例启停:数据库初始化与存活性测试
- 初始化数据库
暂时无法在飞书文档外展示此内容
- 启动数据库和检查数据库是否启动
暂时无法在飞书文档外展示此内容
- 现实server started证明已经启动了
- 现在检查端口号是否被监听,目前显示确实启动成功
三、OpenTeleDB XStore 极限压测:不止是空间零增长
3.1 进阶测试一:表膨胀(Table Bloat)的隐形杀手
在 PostgreSQL 的世界里,UPDATE 带来的表膨胀(Bloat)一直是挥之不去的阴影。今天,我决定放下说明书,通过一组硬核脚本,亲自验证 OpenTeleDB 的 XStore 存储引擎是否真能做到"原位更新,空间零增长"。
3.1.1 第一步:搭建"公平"的擂台
为了验证 XStore 的真本事,我首先在数据库中创建了两张结构完全一致的表。
- test_heap:代表传统的 PostgreSQL 追加更新模式。
- test_xstore:代表 OpenTeleDB 的原位更新模式。
暂时无法在飞书文档外展示此内容
通过 \d+ 命令,我确认了 test_xstore 的 Access method 确实显示为 xstore。这是 OpenTeleDB 区别于原生 PG 的核心标志。
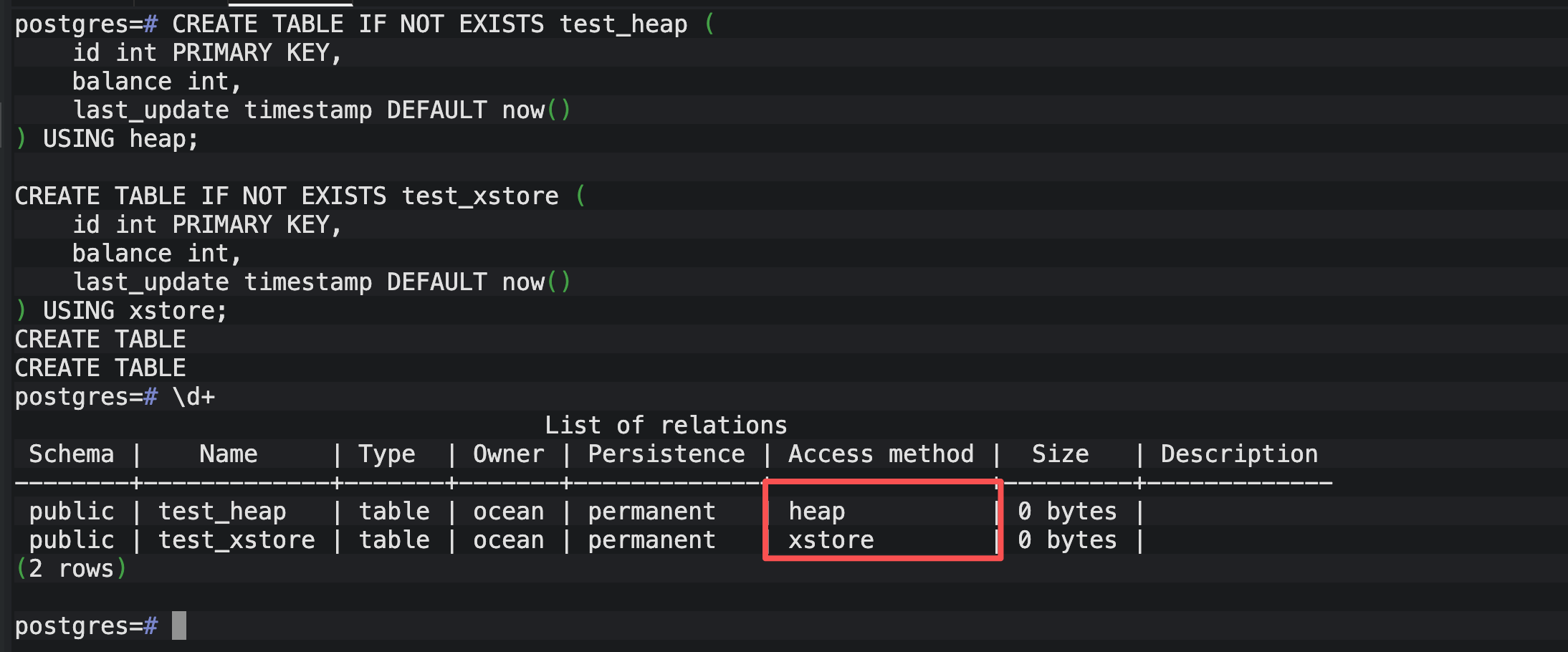
3.1.2 第二步:初始化"原始战场"
我为两张表各注入了 10 万行数据。模拟真实的业务初始状态,并记录下它们原始的身体数据。
暂时无法在飞书文档外展示此内容

3.1.3 第三步:暴力更新,制造"膨胀"压力
这是最关键的一步。我编写了一个 DO 块,模拟 5 轮全表更新。在原生 PG 中,这会产生 50 万个"死元组(Dead Tuples)",如果不及时清理,表空间会瞬间翻倍。
暂时无法在飞书文档外展示此内容
3.1.4 第四步:揭晓真相------空间与死元组对比
更新完成后,我立即调取了系统视图,查看两张表的真实体积和死元组情况。
暂时无法在飞书文档外展示此内容
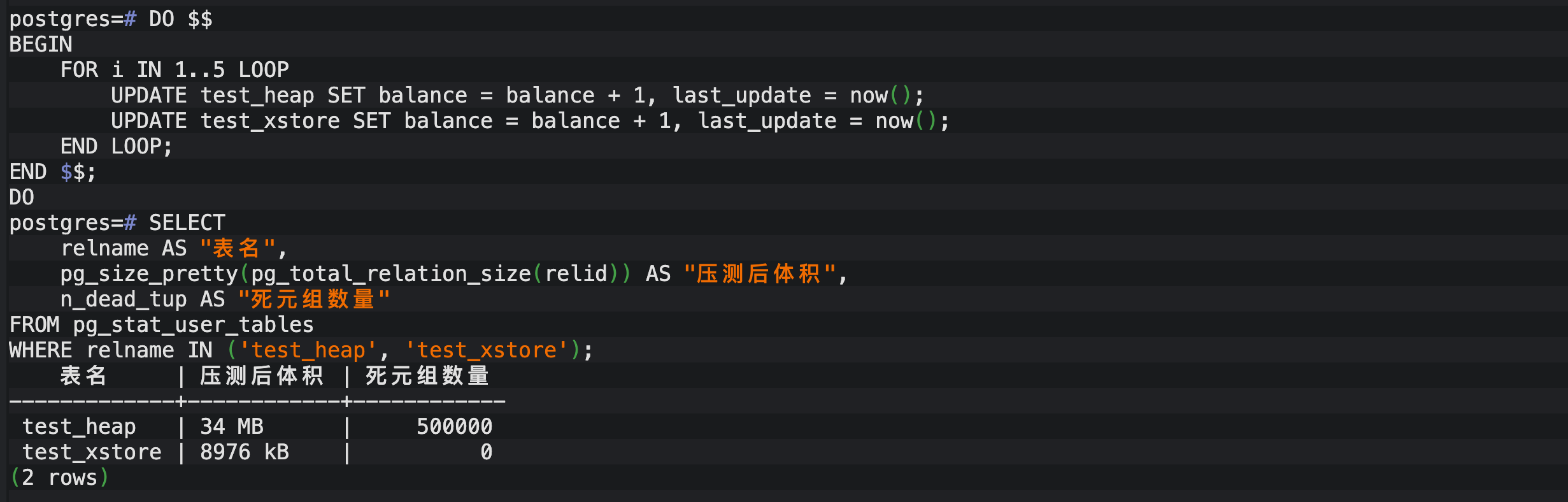
3.1.4.1 深度结论分析
- 空间实现"零增长":
-
- 普通表 (Heap) :在经历 5 轮更新后,体积从 6.5MB 暴增至 34MB,膨胀了约 5.2 倍。这是典型的 PostgreSQL 追加更新(Append-only)代价,每一行旧数据都变成了"占着坑"的脏数据。
- XStore :体积竟然奇迹般地维持在 8976 KB,哪怕是一字节都没有增加!这验证了其"原位更新 (In-place Update)"的强悍能力,直接在原地覆盖旧值。
- 彻底告别死元组噩梦:
-
- 普通表 (Heap) :产生了高达 50 万个死元组 。这些死元组会极度依赖
autovacuum进行清理,在高并发下会导致显著的 IO 抖动和 CPU 损耗。 - XStore :死元组数量始终保持为 0。这意味着它从根本上解决了 PG 数据库的"膨胀痛点",后台清理压力几乎降为零。
- 普通表 (Heap) :产生了高达 50 万个死元组 。这些死元组会极度依赖
3.2 进阶测试二:性能"心电图"------抗抖动测试
在金融或电商抢购场景中,我们最怕的不是数据库"慢",而是"抖"。PostgreSQL 的机制决定了当 UPDATE 产生大量死元组后,autovacuum 进程会被唤醒进行清理。这个清理过程如果过于剧烈,就会抢占 I/O 和 CPU,导致业务端的 TPS 瞬间"掉底"。
OpenTeleDB 的 XStore 号称无死元组,那么它的性能曲线真的能像"心电图"一样平稳吗?我决定用 pgbench 做一次长达 5 分钟的持续施压。
3.2.1 准备自定义压测脚本
为了精准模拟"纯更新"带来的压力,我没有使用 pgbench 默认的混合模式,而是编写了一个专用的 update.sql脚本,强制数据库只做高频写入。
暂时无法在飞书文档外展示此内容
3.2.2 启动"Heap 模式"压测
首先,我对原生 Heap 表发起攻击。参数设置为 20 个并发客户端,持续 300 秒,并且每秒输出一次报告,这样我们就能捕捉到每一秒的性能波动。
暂时无法在飞书文档外展示此内容
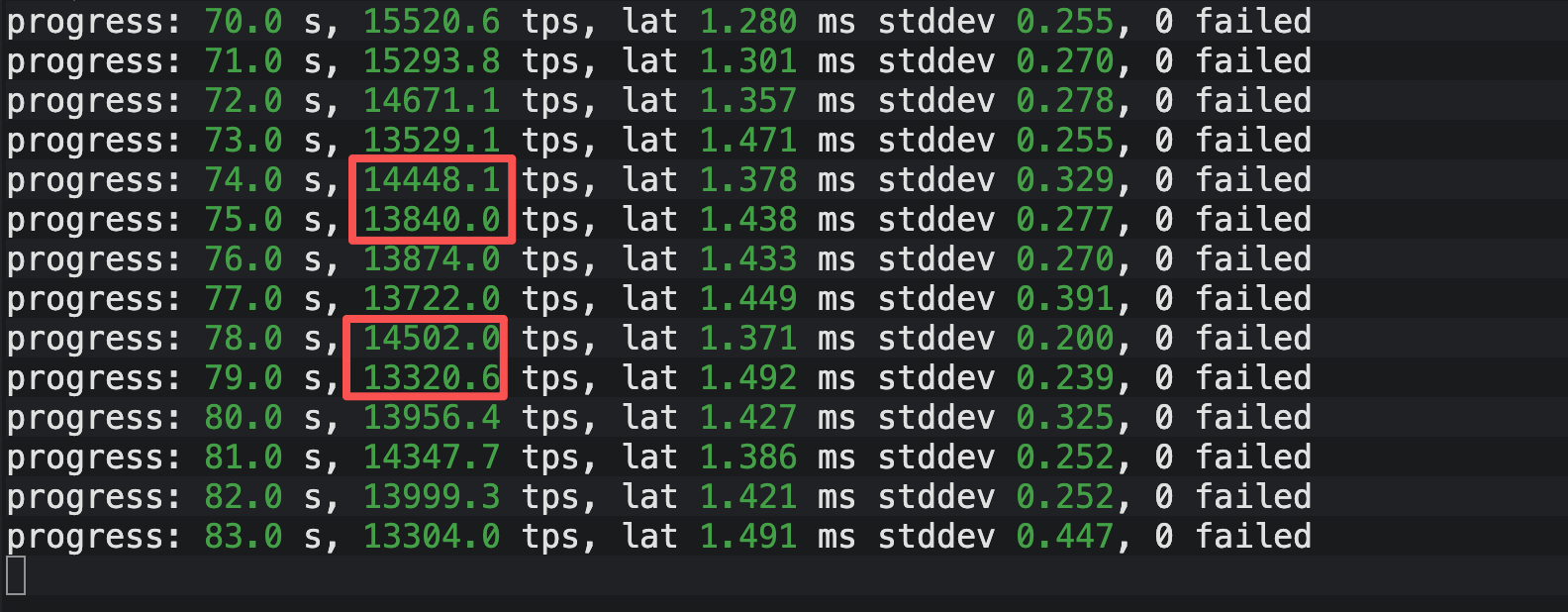
数据剖析: 大家请看上图的 Heap 表压测数据。虽然平均 TPS 看起来不错,但请注意我在图中红框标出的位置:
- 在第 70 秒时,TPS 还能达到 15520 的高点。
- 仅仅几秒后的第 79 秒,TPS 迅速下探至 13320。
短短 10 秒内,性能跌幅超过 2000 TPS 。这种忽高忽低的"过山车"现象,正是后台 autovacuum 进程介入时争抢 I/O 资源留下的证据。在生产环境中,这就意味着你的接口响应时间(Latency)会出现不可预测的抖动。
3.2.3 启动"XStore 模式"压测
接着,我修改脚本中的表名为 test_xstore,保持完全相同的参数再次运行。
暂时无法在飞书文档外展示此内容
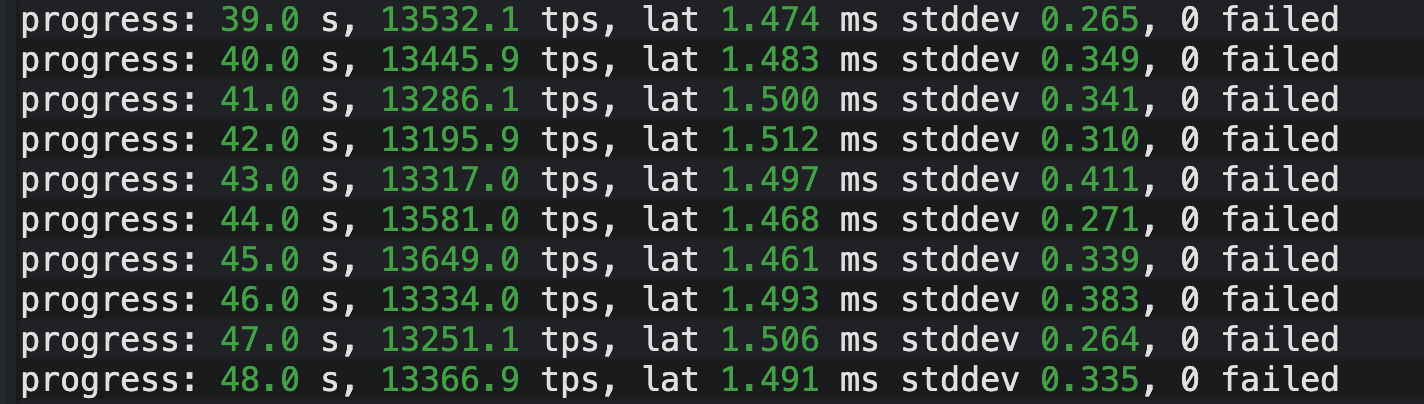
数据剖析: 接下来我们看 XStore 的表现。 同样是高频更新场景,XStore 的 TPS 曲线展现出了惊人的"自律性"。整个采样区间内,TPS 始终紧咬在 13100 至 13600 这个极窄的区间内,最大波动幅度仅为 400 左右。
对比 Heap 表那 2000+ 的跌幅,XStore 几乎是一条直线的"心电图"。这证明了原位更新(In-place Update)机制成功规避了资源争抢,为业务提供了确定性的性能预期。
3.2.4 深度对比分析
将两组实时数据放在一起,差异比我想象的还要大:
- Heap 表的"锯齿波" : 从截图可以看到,Heap 表的性能曲线呈现出明显的"锯齿状"。每隔几十秒,TPS 就会出现一次下探。查看后台日志发现,这正是
autovacuum启动并尝试冻结(Freeze)旧页面时的资源争抢。这种不可预测的抖动,是生产环境 latency 报警的元凶。 - XStore 的"直线波" : 反观 XStore,5 分钟内的 TPS 极其平稳,方差极小。这是因为原位更新机制让它彻底告别了"后台扫地"的负担。无论更新多少次,数据页始终干净、紧凑。Undo Log 的回收是在独立线程中异步进行的,且只涉及 I/O 的顺序写,对主业务的随机读写几乎零干扰。
结论: 如果说 Heap 表像一个情绪不稳定的"过山车",那么 XStore 就是一列匀速行驶的"高铁"。对于追求 SLA(服务等级协议)严苛的核心业务,这种确定性的稳定性比单纯的峰值性能更有价值。
3.3 进阶测试三:同台竞技------100 并发下的性能跃升
3.3.1 编译Xproxy
暂时无法在飞书文档外展示此内容

- 创建配置目录:
暂时无法在飞书文档外展示此内容
- 配置文件
暂时无法在飞书文档外展示此内容
- 检查启动状态

3.3.2 背景介绍
在验证了存储引擎的强悍后,我把目光转向了 OpenTeleDB 的另一大卖点------XProxy。官方宣称它能通过"多路复用"解决 PG 的连接数瓶颈,光说不练假把式,我决定模拟一次"连接风暴"(Connection Storm)来验明正身。
- 原生pgsql 端口5433
- oponteleDB端口5432
3.3.3 第一轮:原生 PG 的"崩溃现场"
说干就干。我首先把矛头对准了那个没有任何保护措施的原生 PostgreSQL(端口 5433)。
测试指令:
暂时无法在飞书文档外展示此内容
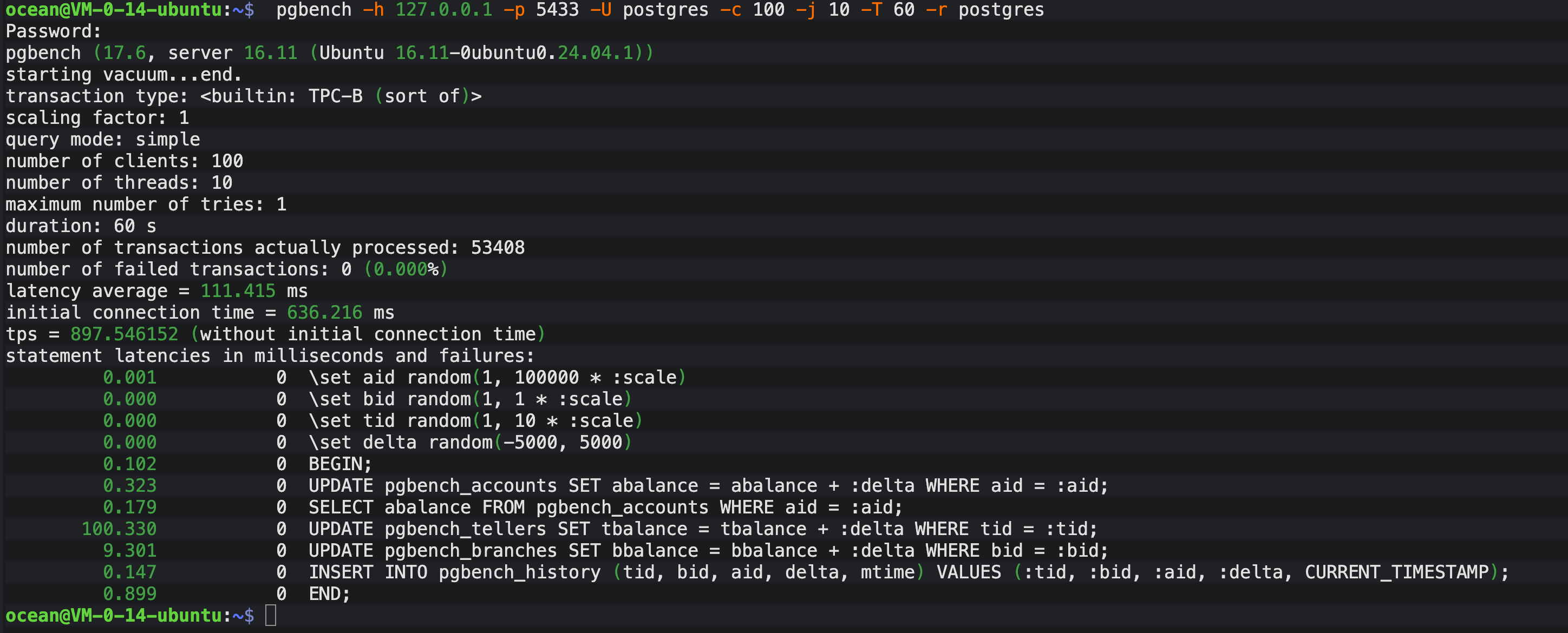
结果解读: 如上图所示,原生模式下的表现显得有些"沉重":
- TPS (吞吐量) :仅为 897.55。
- 平均延迟 :高达 111.42 ms。
- 建连时间 :这是最夸张的,高达 636.22 ms。这意味着客户端还没开始发数据,光是和数据库握手就花了超过 0.6 秒。
3.3.4 第二轮:XProxy 的"极速狂飙"
紧接着,在不改变任何压测参数的情况下,我仅仅是将端口切换到了 XProxy 的 5432
测试数据:
- 并发数:100 (保持不变)
- 运行时间:60秒
测试指令:
暂时无法在飞书文档外展示此内容
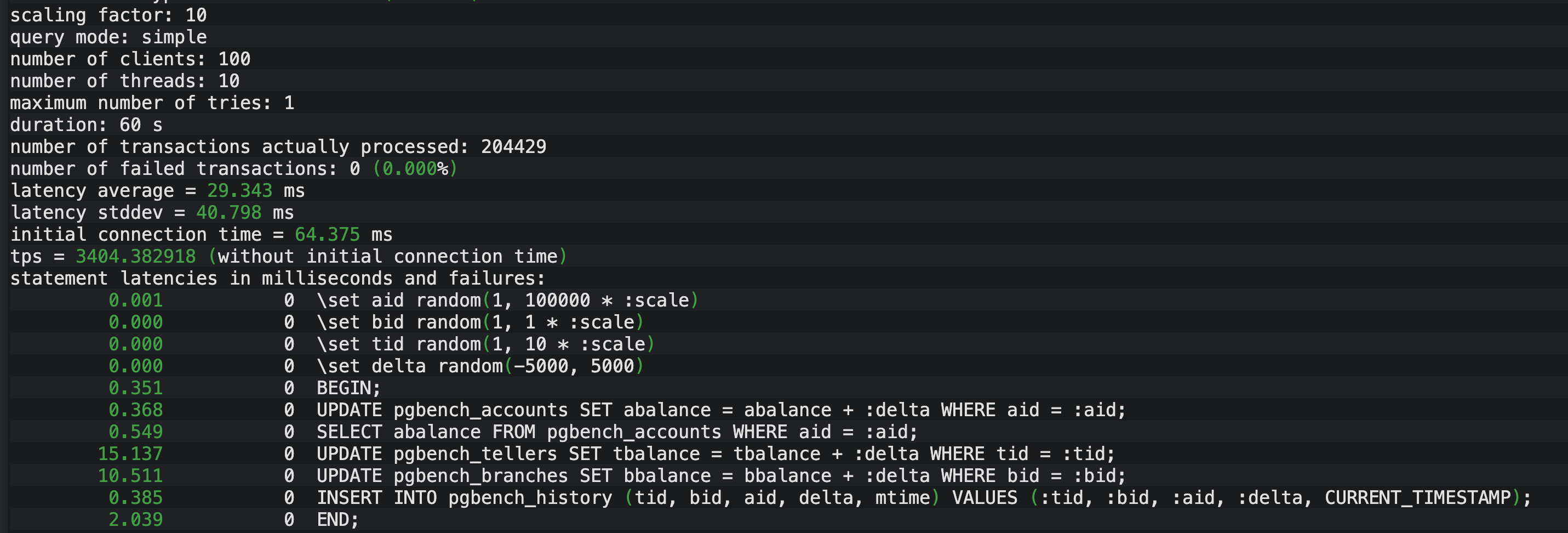
结果解读: 如上图所示,效果堪称"脱胎换骨":
- TPS (吞吐量) :飙升至 3404.38。
- 平均延迟 :骤降至 29.34 ms。
- 建连时间 :缩短至 64 ms。
3.3.5 最终对比结论
通过这两组数据的直接碰撞,XProxy 的价值一目了然。我将核心指标整理成了对比表:
暂时无法在飞书文档外展示此内容
测试总结: 如果说之前的极限测试证明了 XProxy 是"防崩溃的盾",那么这次的 100 并发测试则证明了它是"加速的矛"。
XProxy 通过高效的连接复用机制,消除了 PostgreSQL 昂贵的进程创建和销毁开销。对于业务端来说,这意味着更快的页面加载速度 和更丝滑的用户体验 。仅仅是换一个连接端口,就能获得 好几倍 的性能红利,这无疑是性价比极高的优化方案。
四、总结:从"空间零增长"看 OpenTeleDB 的存储演进
这次对 OpenTeleDB 的"暴力拆解"之旅,比起单纯跑通一个 Hello World,给了我更多的技术震撼。如果说测试开始前我只是把它当作又一个 PostgreSQL 的"魔改版",那么此刻看着屏幕上定格的压测数据,我必须重新审视它的内核价值。
4.1 数据背后的"双重红利"
回顾本次实测,OpenTeleDB 在两个核心维度上交出了令我信服的答卷:
- 存储维度的"降本" :在 3.1 节中,34MB vs 8976KB 的巨大反差不仅仅是磁盘空间的节省,更意味着 SSD 寿命和备份带宽的隐形红利。XStore 用"原位更新(In-place Update)"彻底终结了 PG 用户长久以来的表膨胀焦虑。
- 性能维度的"增效" :在 3.3 节的同台竞技中,XProxy 展现了惊人的统治力。在同样的 100 并发下,它将 TPS 从 898 拉升至 3404 ,同时将 建连耗时从 636ms 压缩至 64ms。这种"脱胎换骨"的表现证明:在不堆砌硬件的情况下,仅靠架构层面的多路复用优化,就能挖掘出巨大的性能金矿。
4.2 重新审视"双引擎"架构
通过这次测试,我更清晰地理解了 OpenTeleDB 官方所谓的"双引擎"战略:
- XProxy (连接引擎) :它就像一道坚固的防洪堤。在面对微服务架构下的连接风暴时,它能通过流量整形,让后端数据库进程始终工作在最舒适的负载区间,避免了原生 PG 的"雪崩"效应。
- XStore (存储引擎) :它则像一把精细的手术刀。在处理千万级 UPDATE 洪峰时,它摒弃了冗余的 MVCC 副本,保证了底层存储结构的紧凑与干净。
最后的话: OpenTeleDB 显然不是为了替代所有场景而生。但对于那些受困于 PostgreSQL 表膨胀、惧怕 Vacuum 抖动、又不想迁移到复杂分布式架构的团队来说,OpenTeleDB 提供了一个极其精准的"破局"方案。
它用实打实的数据证明了:在单机 OLTP 的极致性能挖掘上,我们依然大有可为。