从云到本地:智能体与工作流在 openJiuwen 中的导入导出设计与工程实践

引言|工作流是否可以归一化?
如果你已经开始搭建自己的智能体平台,那我默认你已经经历过一个阶段:
在云上把 Agent 跑通,把工作流调顺。
这个阶段很舒服。
模型是现成的,插件是现成的,拖一拖、连一连,一个完整的智能体就能跑起来。很多复杂的逻辑------意图识别、知识库检索、多分支决策------都可以在可视化画布里迅速验证。
但当你真正准备把这些能力迁移到企业本地环境时,问题往往不是出现在"模型效果"上,而是集中爆发在一个看似很基础的环节:
这个工作流,能不能被稳定地带走?
openJiuwen 官方已经提供了非常清晰的能力说明:
工作流可以导出为 JSON 文件,也可以再导入恢复,适用于版本管理、协作和跨域分享。从平台功能层面看,这个能力是完整且必要的。
但在真实工程实践中,只要你把"导入导出"用于跨环境迁移(尤其是云 → 本地),你很快就会发现一件事:
官方描述解决的是**"同一语义体系内的恢复",
而我们要面对的,是"不同语义体系之间的迁移"**。
这篇文章不是讲"怎么点导出按钮",而是围绕一个更现实的问题展开:
当工作流不再只用于保存和回滚,而是作为"智能体能力迁移的载体"时,我们应该如何设计导入与导出?
在进入正文之前,也简单介绍一下我自己。
我是 Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,
热衷于分享大模型、Agentic AI 以及企业级智能系统的真实落地实践。
如果你对大模型的创新应用、AI 技术发展,尤其是"从 Demo 到工程化落地"这一阶段的问题感兴趣,欢迎关注 Fanstuck。
第一部分|为什么智能体 / 工作流不能"直接拷贝"

在讨论"怎么迁移"之前,必须先把一个误区彻底说清楚:
智能体和工作流,天然就不是可直接拷贝的资产。
这不是 openJiuwen 的问题,也不是某个云平台的问题,而是智能体系统本身的特性决定的。
平台语义差异:看起来都是工作流,其实表达的不是同一层东西
在大多数云平台中,工作流的核心目标是:
让用户在一个平台内,把能力快速拼出来并跑起来。
因此,工作流里往往混合了多种语义:
- 节点的业务逻辑
- 平台默认提供的运行能力
- UI 层为了可视化而存在的结构
- 以及大量"平台帮你兜底"的隐式行为
这些东西在同一个平台里是高度自洽的,但一旦离开原环境,就会出现问题。
而 openJiuwen 的工作流导出格式,本质上解决的是另一件事:
如何把一个已经建好的工作流,完整地还原回 openJiuwen 的执行模型中。
这两件事的目标不同,决定了它们对"工作流"的理解也不同。
所以当我们尝试把"某个平台的工作流"直接导入 openJiuwen 时,本质上是在做一件非常危险的事:
试图让 openJiuwen 理解一个并不是为它设计的语义体系。
失败并不是意外,而是必然。

举一个很常见的例子,之前我在云上创建使用很好的一个智能客服工作流:
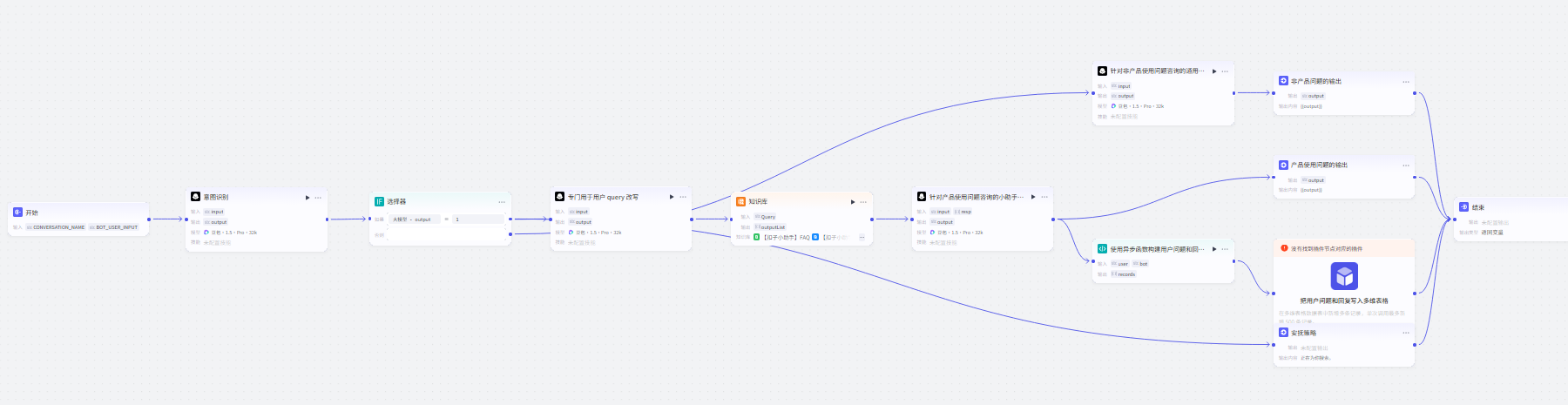
现在我打算本地来部署这个工作流,用openjiuwen来实现,我们复制这个工作流,得到的JSON格式一般为:
json
"type": "workflow-clipboard-data",
"source": { "workflowId": "...", "spaceId": "...", "host": "www.xx.cn" }几乎一眼就能看出它的"平台属性"。再看节点结构,最明显的区别有三点:
A. 输出/输入不是 schema,而是 list 结构
json
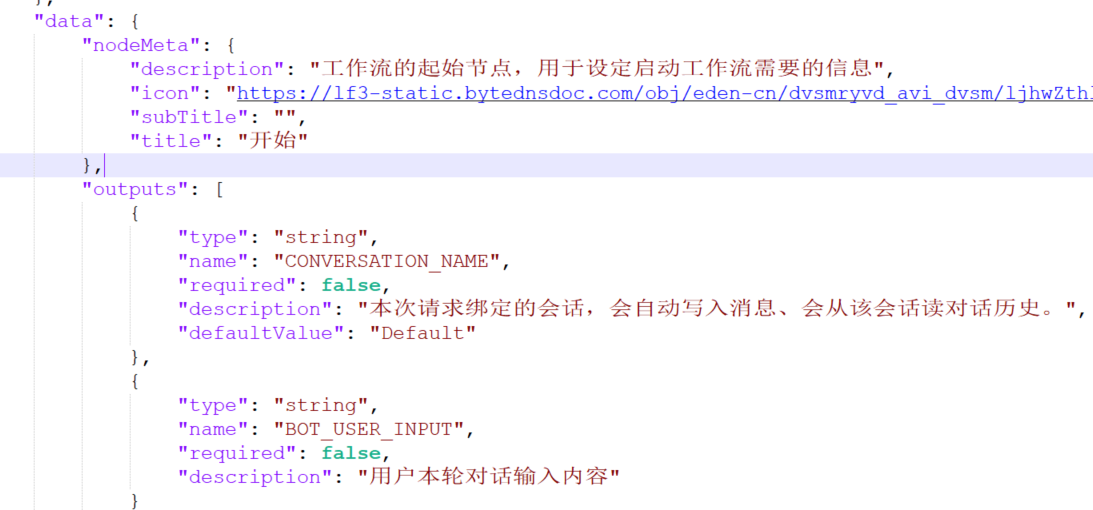
[
{"type":"string","name":"CONVERSATION_NAME"},
{"type":"string","name":"BOT_USER_INPUT"}
]它表达的是"平台会话机制里的变量",而不是业务参数。
这意味着: 工作流默认绑定"会话/消息"体系,而不是纯粹的数据流 DAG。
B. 引用表达是 block-output + blockID + name
云上智能体平台的ref 一般是:
json
{
"source": "block-output",
"blockID": "100001",
"name": "BOT_USER_INPUT"
}它不是"节点输出字段引用",而是"平台 block 的输出引用"。
这会导致迁移时必须先回答:
在 openJiuwen 里,是否存在等价的"block 输出命名空间"?
如果没有,那就不是字段映射能解决的,而是语义重建。
C. 节点里塞进大量平台默认能力
随便看一个 LLM 节点,它不仅有 prompt/systemPrompt,甚至还导出了:
- modelType(一个平台内部枚举)
- modleName(拼写还带 modleName)
- enableChatHistory / chatHistoryRound(平台的对话记忆策略)
- settingOnError(timeout/retry)
- fcParamVar(知识库相关参数容器)
再看知识库节点 datasetList,直接是 datasetID 数组:
"datasetList": "7517...","7517..."
这就是典型的"平台绑定资源"。在 云上这些 ID 有意义,在 openJiuwen 私有化环境里它们必然没有意义。所以 云平台的导出,更像*运行快照(snapshot),里面混合了:UI 信息、平台内部 ID、默认运行策略、以及资源绑定。
运行环境差异:云平台默认成立的前提,在本地全部需要重建
在云平台上,我们很少会关心、模型服务是否可达、工具调用是否允许访问外部系统、会话上下文如何保存、异常重试、超时、并发由谁负责。
因为这些问题,平台已经替你解决过了。
但当你把工作流迁移到本地环境,这些"默认前提"会被一一拆开,变成需要你自己回答的工程问题。
如果工作流的导出内容里隐含了这些前提,而导入时你并没有意识到它们的存在,那么最终表现出来的就是行为不一致和执行不稳定,甚至在关键业务节点出现不可控风险。
这也是为什么在企业环境里,"能跑"远远不够,"可控"才是底线。
Tool 与资源绑定差异:ID 从来都不是可迁移资产
在所有迁移问题里,最容易踩坑的一类,是资源绑定。
云平台里的工作流,几乎一定会绑定模型标识、插件或工具实例或知识库或数据集。
这些绑定在原平台中是通过内部 ID 或配置完成的。但这些 ID 一旦脱离原环境,就没有任何实际意义。
真正可迁移的,从来不是某个 ID,而是:
"这个节点需要哪一类能力"
而不是"它在云平台里用的是哪一个实例"。
到这里,其实可以得出一个非常明确的结论:
智能体迁移失败,往往不是技术问题,而是一开始就选错了迁移对象。
我们试图迁移的是"平台产物",而不是"可执行语义"。
因此,真正可行的路径不是"直接导入导出",而是:
把工作流当成一种需要被重新解释、重新绑定、重新执行的工程资产。
这也正是为什么,接下来必须重新思考"导出阶段到底应该设计成什么样子",以及:
openJiuwen 应该如何作为一个"导入执行平台",承接这些被迁移过来的工作流能力。
第二部分|导出阶段的正确设计思路

导入导出这件事,很多团队第一反应是"先能导出来再说"。但只要你的目标是从云到本地的迁移,导出阶段就必须先想清楚:你到底要带走什么。因为工作流一旦跨平台,真正决定成败的不是 JSON 是否能解析,而是导出的内容是否还保留了"可执行语义"。
2.1 导出阶段的核心目标:保留可执行语义,剥离平台上下文
迁移场景里,导出文件必须回答两类问题:
- 这条工作流在运行时"做什么"(语义)
- 它依赖什么才能跑起来(依赖)
除此之外的内容------例如画布位置、空间 ID、账号信息、平台内资源标识------对"迁移"来说反而是负担,因为这些信息在本地环境大概率不可用,甚至会误导导入端做错误绑定。
因此导出阶段要遵循一个非常硬的工程原则:
导出文件应该是"可执行规格(spec)",不是"平台快照(snapshot)"。
2.2 用 openJiuwen 的工作流导出格式拆解

openJiuwen 导出 JSON(start → llm → llm → plugin → end)可以用一个工程视角拆成三层信息:
第一层:拓扑结构(Topology)
- nodes 表示节点集合
- edges 表示连接关系(sourceNodeID → targetNodeID)
这部分回答:"数据从哪里来,经过哪些步骤,最后到哪里去"。
第二层:节点类型与行为(Node Semantics)
每个节点都有 type,并且在 data 内携带该类型对应的关键配置。
例如:
- LLM 节点:llmParam.systemPrompt、llmParam.prompt、llmParam.model
- Plugin 节点:pluginParam(插件身份)+ inputParameters(入参绑定)+ outputs(出参 schema)
- Start/End 节点:输入输出 schema、最终输出绑定关系等
这部分回答:"每一步到底做什么,输入是什么,输出是什么"。
第三层:数据依赖(Data Binding)
openJiuwen 的数据绑定集中体现在两块:
- inputParameters 里用 type: "ref" 指向上游节点输出(形如 "llm_J1r1U","output")
- 节点自身的 outputs 用 JSON Schema 描述出参结构
这部分回答:"这条链路的变量传递规则是什么"。
你会发现:导出文件里真正关键的,恰恰是这三层------拓扑、节点语义、数据依赖。它们组合起来才构成"能被另一个运行系统理解的工作流"。
2.3 问题不在字段多,而在语义层级不同
很多第三方云平台的导出(包括剪贴板 JSON、下载 JSON)往往会混入大量"平台上下文"。通常也会包含这些特征:
- spaceId / workflowId / host / isXXX 这类租户与环境字段
- 节点内嵌大量 nodeMeta、icon、颜色、bounds 等 UI 信息
- 知识库、插件、模型往往绑定为平台内部的资源 ID
- 同一个"输入/输出"的表达方式可能是平台专用的引用协议(例如 block-output、rawMeta 等)
这类导出文件在原平台上非常有用,因为它的目标是"恢复编辑态"。但迁移时它会遇到三个硬障碍:
- 引用协议不兼容:上游输出引用方式不是 openJiuwen 的 ref 结构
- 资源身份不可复用:知识库 ID、插件 ID、模型类型在本地无意义
- 语义被平台策略隐式化:很多运行规则并不在 JSON 里,而在平台默认策略里
所以迁移的正确结论不是"写个转换脚本把字段改名",而是:
必须把第三方导出内容"提炼成语义",再转译成 openJiuwen 的语义表达。
2.4 导出阶段"该导什么 / 不该导什么":给迁移链路定边界

为了让后续导入阶段能完成"重绑定",导出阶段必须有明确取舍。可以把导出内容分为四类资产:
A. 必须导出:工作流语义资产
- 节点拓扑(nodes + edges)
- 节点类型(LLM/Plugin/Condition/Start/End...)
- Prompt / System Prompt(这是行为定义的一部分)
- 输入输出 schema(决定变量契约)
- 引用关系(inputParameters 的 ref 链接)
B. 允许导出但必须可替换:运行依赖清单
- 模型配置:导出"模型能力需求"或"模型别名",不要导出只能在云平台生效的实例 ID
- 插件配置:导出"工具名/接口契约",不要把某个云端插件实例当成可移植资产
- 知识库配置:导出"知识集合逻辑",不要把云端 datasetId 当成可迁移主键
C. 不导出:平台快照信息
- UI 元信息(位置、bounds、icon、颜色、nodeMeta)
- 租户信息(spaceId、workflowId、host、is...)
- 平台内部版本与埋点字段(不参与运行)
D. 单独导出:安全与治理配置(建议拆文件)
- 权限与密钥
- 访问控制
- 审计开关与日志策略
这些内容不应跟"工作流语义"揉在一起,否则迁移会在安全审计上卡死。
这一套边界一旦定下来,导出文件就从"能保存"变成"能迁移"。
2.5 Export Spec 的工程化写法:让导出文件天然支持"导入编译"

如果希望迁移链路长期可用,导出规范最好在结构上就为"导入编译"服务。一个实用的写法是把导出文件抽象成两块:
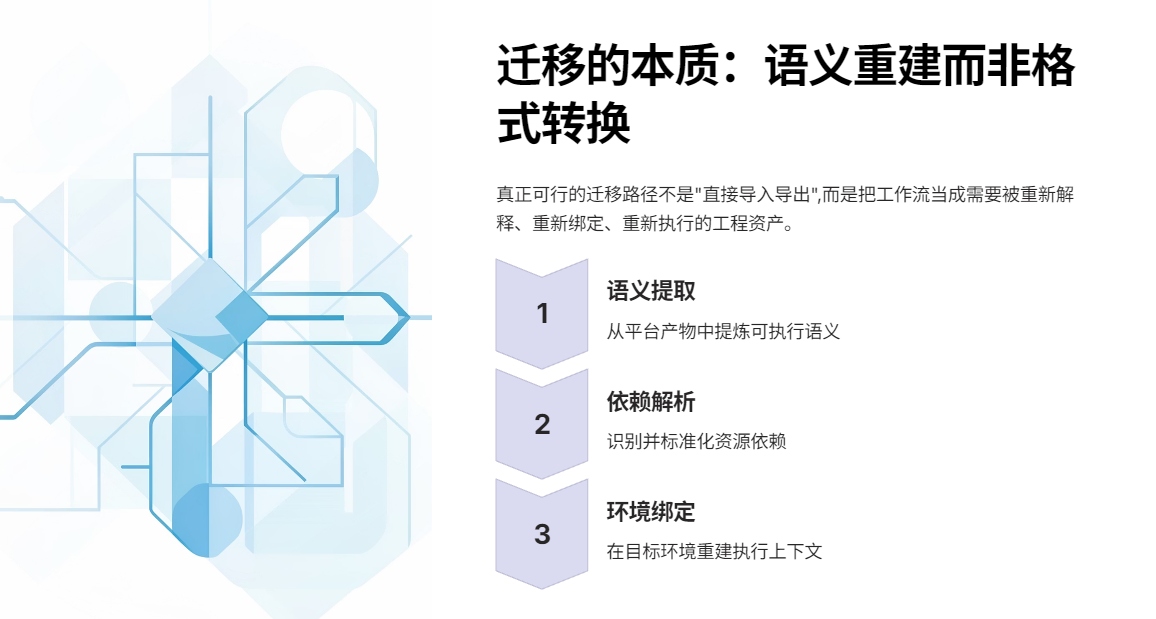
- Workflow Spec(语义):节点、边、schema、prompt、ref
- Bindings(依赖映射):模型别名 → 本地模型;工具名 → 本地插件;知识库逻辑 → 本地数据集
这样做的好处是:
同一份 Workflow Spec 在不同环境里可以复用,而 Bindings 可以按环境分别维护(dev/staging/prod、本地/云上)。
第三部分|openJiuwen 如何作为"导入执行平台":导入不是读取,而是编译
如果把"跨平台迁移"当成一个工程问题,openJiuwen 的角色其实很清晰:它不是要理解第三方平台的全部实现细节,而是要把外部工作流的语义编译成 openJiuwen runtime 能执行的图。
"读取 JSON"解决的是语法层(parse),但迁移真正卡的点在语义层(semantics):

- 第三方平台的 LLM 节点,在 openJiuwen 里要落到 type=3,并且要把"输入引用、prompt 模板、systemPrompt、模型信息"整理成 openJiuwen 的 llmParam + inputParameters(ref) 结构。
- 第三方平台的 Tool/Plugin 节点,在 openJiuwen 里要落到 type=19,但更关键的是:pluginParam 里的 pluginID/toolID 必须在本地存在,否则就只能"先占位,后重绑"。
- 第三方平台的"引用协议",经常不是 "nodeId","field" 这种二维 ref,而是各种 block-output/object_ref 形式。导入侧必须把它归一。
所以第三部分讲的"导入",本质就是一个小型编译器:
Source JSON(第三方 AST) → IR(中间表示) → Target JSON(openJiuwen DAG)
并在编译阶段完成:语义映射 + 依赖重绑 + 结构校验。
接下来我用一个可复现的例子把这件事写透。
3.1 构建SQL查询工作流
这个例子模拟的是一个很常见的链路:
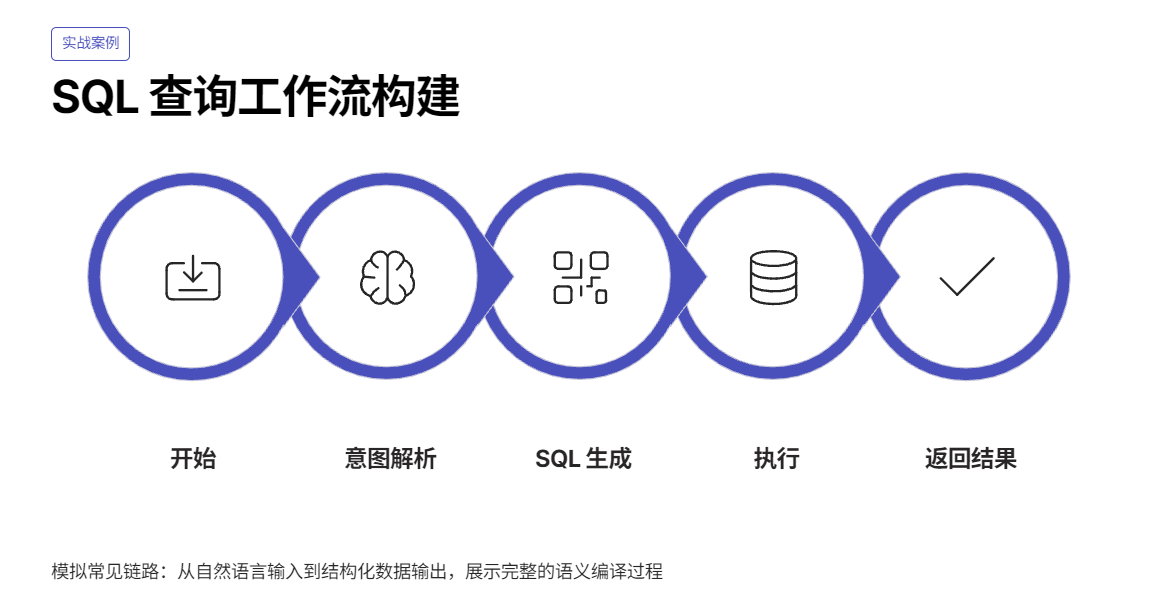 Start(用户输入) → LLM(意图/QuerySpec) → LLM(SQL 生成) → Tool(SQL 执行) → End(返回结果)
Start(用户输入) → LLM(意图/QuerySpec) → LLM(SQL 生成) → Tool(SQL 执行) → End(返回结果)
json
{
"platform": "third_party",
"nodes": [
{
"id": "n_start",
"type": "Start",
"outputs": [
{ "name": "query", "type": "string", "default": "你好,帮我查最近最贵的品牌" }
]
},
{
"id": "n_llm_1",
"type": "LLM",
"inputs": [
{ "name": "input", "valueFrom": { "node": "n_start", "field": "query" } }
],
"llm": {
"model": "qwen3-max",
"systemPrompt": "你是 QuerySpec Builder,只输出JSON...",
"prompt": "{{input}}",
"temperature": 0.2
},
"outputs": [{ "name": "output", "type": "string" }]
},
{
"id": "n_llm_2",
"type": "LLM",
"inputs": [
{ "name": "input", "valueFrom": { "node": "n_llm_1", "field": "output" } }
],
"llm": {
"model": "qwen3-max",
"systemPrompt": "你是SQL生成器,只输出MySQL SQL...",
"prompt": "{{input}}",
"temperature": 0.1
},
"outputs": [{ "name": "output", "type": "string" }]
},
{
"id": "n_tool_sql",
"type": "Tool",
"tool": {
"name": "sql_runner",
"args": {
"sql": { "valueFrom": { "node": "n_llm_2", "field": "output" } },
"limit": 100
}
},
"outputs": [{ "name": "data", "type": "object" }]
},
{
"id": "n_end",
"type": "End",
"inputs": [
{ "name": "result", "valueFrom": { "node": "n_tool_sql", "field": "data" } }
]
}
],
"edges": [
{ "from": "n_start", "to": "n_llm_1" },
{ "from": "n_llm_1", "to": "n_llm_2" },
{ "from": "n_llm_2", "to": "n_tool_sql" },
{ "from": "n_tool_sql", "to": "n_end" }
]
}这段 JSON 的"语义"很干净:
每个节点把"输入来自哪里"表达成 {node, field};LLM 节点有 model/prompt/systemPrompt;Tool 节点有 name + args。
接下来我们要做的事情就是:把这种语义编译成 openJiuwen 可导入的 JSON。
3.2 编译目标:生成 openJiuwen 可导入 JSON

下面这段就是"编译产物"。你把它保存为 workflow-export-YYYY-MM-DD.json(名字不重要),在 openJiuwen 工作流编辑页右上角点"导入",就能把图恢复出来(前提:本地已经存在对应模型、插件或你允许先占位再重绑)。
json
{
"nodes": [
{
"id": "start_migrate",
"type": "1",
"meta": { "position": { "x": 180, "y": 32 } },
"data": {
"title": "开始",
"outputs": {
"type": "object",
"properties": {
"query": { "type": "string", "default": "你好,帮我查最近最贵的品牌", "description": "用户问题" }
},
"required": ["query"]
}
}
},
{
"id": "llm_qspec",
"type": "3",
"meta": { "position": { "x": 640, "y": 0 } },
"data": {
"title": "QuerySpec 生成",
"inputs": {
"llmParam": {
"systemPrompt": {
"type": "template",
"content": "你是 QuerySpec Builder,只输出 JSON..."
},
"prompt": { "type": "template", "content": "{{input}}" },
"model": { "id": "1", "name": "千问3M", "type": "qwen3-max" }
},
"inputParameters": {
"input": { "type": "ref", "content": ["start_migrate", "query"], "extra": { "index": 0 } }
}
},
"outputs": {
"type": "object",
"properties": {
"output": { "type": "string", "extra": { "index": 1 } }
},
"required": ["output"]
}
}
},
{
"id": "llm_sql",
"type": "3",
"meta": { "position": { "x": 1100, "y": 0 } },
"data": {
"title": "SQL 生成",
"inputs": {
"llmParam": {
"systemPrompt": {
"type": "template",
"content": "你是SQL生成器,只输出MySQL SQL..."
},
"prompt": { "type": "template", "content": "{{input}}" },
"model": { "id": "1", "name": "千问3M", "type": "qwen3-max" }
},
"inputParameters": {
"input": { "type": "ref", "content": ["llm_qspec", "output"], "extra": { "index": 0 } }
}
},
"outputs": {
"type": "object",
"properties": {
"output": { "type": "string", "extra": { "index": 1 } }
},
"required": ["output"]
}
}
},
{
"id": "plugin_sql_runner",
"type": "19",
"meta": { "position": { "x": 1560, "y": 10 } },
"data": {
"title": "sql_runner",
"inputs": {
"inputParameters": {
"sql": { "type": "ref", "content": ["llm_sql", "output"], "extra": { "index": 0 } },
"limit": {
"type": "constant",
"content": 100,
"schema": { "type": "number" },
"extra": { "index": 1 }
}
},
"pluginParam": {
"toolID": "REPLACE_WITH_LOCAL_TOOL_ID",
"toolName": "sql_runner",
"pluginID": "REPLACE_WITH_LOCAL_PLUGIN_ID",
"pluginName": "sql_runner",
"pluginVersion": "v0.0.1"
}
},
"outputs": {
"type": "object",
"properties": {
"data": { "type": "object", "extra": { "index": 3 } }
},
"required": ["data"]
}
}
},
{
"id": "end_migrate",
"type": "2",
"meta": { "position": { "x": 2020, "y": 32 } },
"data": {
"title": "结束",
"inputs": {
"inputParameters": {
"result": { "type": "ref", "content": ["plugin_sql_runner", "data"], "extra": { "index": 0 } }
}
},
"streaming": false
}
}
],
"edges": [
{ "sourceNodeID": "start_migrate", "targetNodeID": "llm_qspec" },
{ "sourceNodeID": "llm_qspec", "targetNodeID": "llm_sql" },
{ "sourceNodeID": "llm_sql", "targetNodeID": "plugin_sql_runner" },
{ "sourceNodeID": "plugin_sql_runner", "targetNodeID": "end_migrate" }
]
}
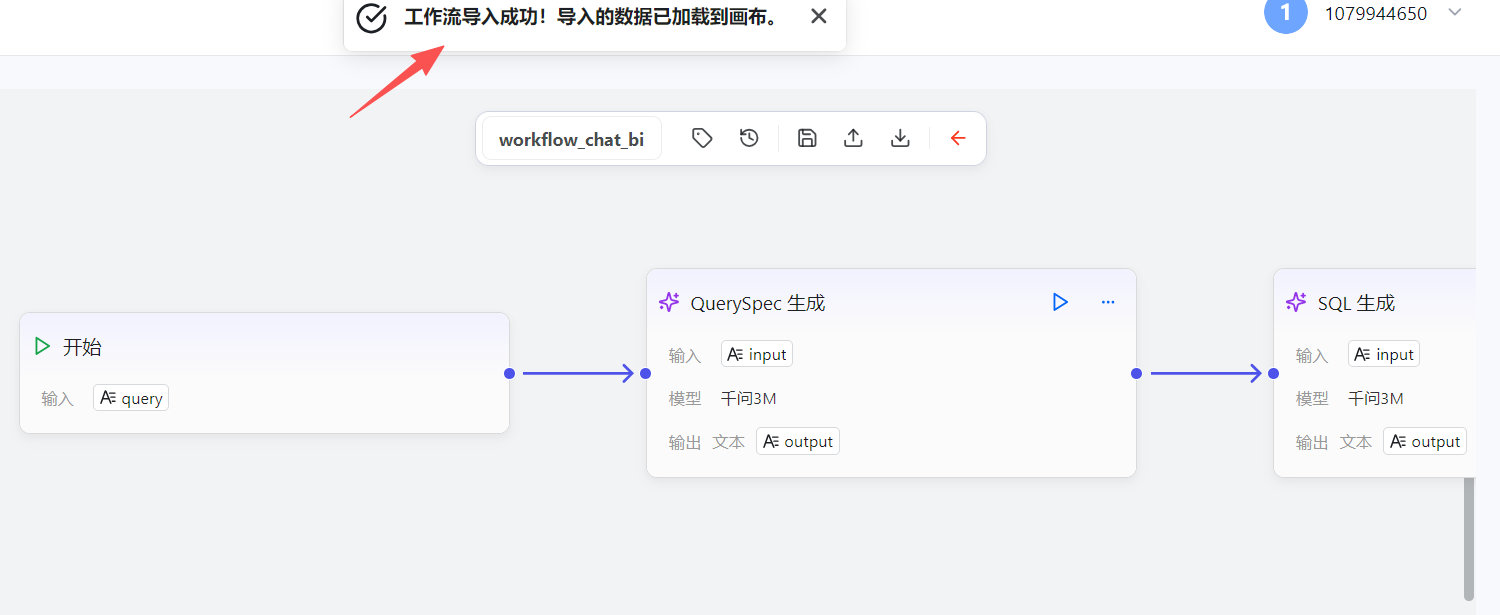
你会注意到这里有两个"编译器需要介入"的点:
- 模型绑定:第三方写 model: qwen3-max,openJiuwen 这里是 {id,name,type}。type 你可以直接落 qwen3-max,但 id/name 通常来自你本地模型列表。
- 插件绑定 :pluginParam.toolID/pluginID 在迁移时无法凭空知道------这就是为什么我一直说"导入不是读取,是编译 + 重绑"。迁移工具必须支持两种模式:
- 严格模式:找不到就拒绝导入
- 宽松模式:先写占位符,导入后在 UI 里人工重绑(或者再跑一次自动重绑)
3.3 "迁移转换智能体"怎么做:让 openJiuwen 变成你的工作流编译器

在本地 openJiuwen 里我们可以做一个"迁移助手",输入第三方 JSON,输出 openJiuwen JSON(可导入)。
这里最稳的做法不是让 LLM 直接"凭感觉改 JSON",而是给它一个明确的编译任务:先提炼 IR,再吐目标格式。IR 不用很复杂,够表达"节点类型、输入引用、prompt、工具参数"就行。
3.3.1 定义一个最小 IR
建议 IR 长这样:
json
{
"ir_version": "0.1",
"nodes": [
{
"id": "n_llm_1",
"kind": "llm|tool|start|end|condition",
"inputs": { "input": { "ref": ["n_start", "query"] } },
"llm": { "model": "qwen3-max", "system": "...", "prompt": "{{input}}", "temperature": 0.2 },
"tool": { "name": "sql_runner", "args": { "sql": { "ref": ["n_llm_2", "output"] }, "limit": 100 } }
}
],
"edges": [["n_start", "n_llm_1"], ["n_llm_1", "n_llm_2"]]
}IR 的价值在于:把第三方平台的引用协议、字段噪音、UI 信息全部剥离掉。只要能得到 IR,后面生成 openJiuwen JSON 就稳定很多。
3.3.2 迁移智能体的 System Prompt

你可以在 openJiuwen 里建一个"LLM 节点",systemPrompt 写成下面这样:
你是一个"工作流迁移编译器",任务是把第三方智能体平台导出的工作流 JSON 编译成 openJiuwen 可导入的工作流 JSON。
输入:一个 JSON(第三方导出),字段可能包含 nodes/edges,节点类型可能是 Start/End/LLM/Tool/Condition 等,且存在平台特有字段。
输出:只输出一个 JSON,格式必须符合 openJiuwen 工作流导入结构:
json
{
"nodes":[ { "id": "...", "type": "1|2|3|19|8|13", "meta": {"position": {...}}, "data": {...} } ],
"edges":[ { "sourceNodeID": "...", "targetNodeID": "..." } ]
} 编译规则:
- 节点类型映射:
- Start -> type "1"
- End -> type "2"
- LLM -> type "3"
- Tool/Plugin -> type "19"
- Condition/Selector -> type "8"(如果输入里出现条件分支)
- Output/Message -> type "13"(如果输入里出现中间输出节点)
- 输入引用统一为 openJiuwen 的 ref 结构:{ "type":"ref", "content":上游节点ID, 上游字段名 }
- LLM 节点:
- systemPrompt 变成 {type:"template", content:"..."}
- prompt 变成 {type:"template", content:"..."}
- model 输出为 { "id":"1","name":"本地模型","type":"<原始model字符串>" }
- Tool/Plugin 节点:
- pluginParam 中的 toolName/pluginName 从输入 tool.name 填充
- toolID/pluginID 使用占位符:REPLACE_WITH_LOCAL_TOOL_ID / REPLACE_WITH_LOCAL_PLUGIN_ID
- args 映射到 inputParameters;常量用 {type:"constant", content:...}
- meta.position:按默认布局给出递增 x 坐标即可(不需要完全还原画布)
- 只输出 JSON,不要输出解释、标题、markdown、代码围栏。
现在开始:读取输入 JSON,生成 openJiuwen 可导入 JSON。
这其实就是一个"规则编译器",而不是"帮我改一下 JSON"。
第四部分|适用场景与边界:哪些智能体值得迁,哪些不值得
在前面的三部分里,我们已经把"导入导出"这件事拆得足够细了:
从不能直接拷贝,到导出要导什么,再到导入其实是一次编译。
但到了真正落地的时候,还有一个绕不开的问题:
是不是所有云上的智能体、工作流,都值得迁到本地?
答案很明确:不是。
如果你在企业里推动过一次以上的平台落地,就会很清楚,迁移失败,往往不是技术做不到,而是一开始就选错了迁移对象。
4.1 非常适合迁移到 openJiuwen 的智能体类型
第一类,结构清晰、目标明确的"功能型 Agent"。
典型代表就是我们搭建的 ChatBI / 问数工作流:
- 输入是自然语言
- 中间是明确的意图结构(QuerySpec)
- 再往下是 SQL / API / 内部系统调用
- 输出是可验证的数据结果
这类 Agent 有一个共同特点: 它们的"智能"不是来自自由对话,而是来自稳定流程。
对这种 Agent 来说,Prompt 是规则的一部分,Tool 调用是能力边界的一部分,成功与否是可判断的。
一旦从云上试错阶段走到"要给业务部门长期用",迁到 openJiuwen 这种本地可控的 Agent Runtime,反而是一个自然演进。
第二类,依赖企业内部系统或私有数据的 Agent。
只要 Agent 涉及到下面任意一点,本地化几乎是迟早的事:内部数据库、内网 API、私有文件系统、权限分级访问。在第三部分里写的 sql_runner 插件,其实就是一个非常标准的例子。
在云平台上,这类能力往往只能"模拟";而在 openJiuwen 里,它可以变成一等公民插件,直接跑在你的服务器里。
第三类,会长期演进、需要版本管理的 Agent 工作流。
当一个 Agent 开始出现下面这些需求时:"这版改动为什么效果变差了?","能不能回滚到上周那版?","A 部门用 v1,B 部门用 v2,可以吗?"。那它已经不再是 Demo,而是系统组件。
而一旦进入这个阶段,导入导出 + 本地版本管理,就不再是锦上添花,而是刚需。
4.2 不适合直接迁移的智能体类型
同样重要的是:哪些 Agent 不值得现在就迁?
第一类,高度依赖平台生态能力的对话型 Agent。
比如:
- 强依赖平台内置知识库
- 使用平台特有的 Memory / Persona
- 对话风格和策略大量依赖平台调参
这类 Agent 的"行为",本身就和平台深度耦合。如果强行迁移,你得到的往往不是一个"可用的本地 Agent",而是一堆无法复现原效果的 Prompt 碎片。这不是 openJiuwen 的问题,而是迁移目标本身选错了。
第二类,纯试验性质、生命周期很短的 Agent。
如果一个 Agent只为了验证一个想法,用完一周就可能被废弃,而且还在频繁推翻重写那它非常适合留在云平台上。云平台负责"试错速度",本地平台负责"稳定交付"------这是一个非常健康的分工。
4.3 推荐的一条现实路径:云上试 → 本地稳 → 再演进
结合前面的所有讨论,其实可以总结出一条非常现实、也非常可操作的路径:
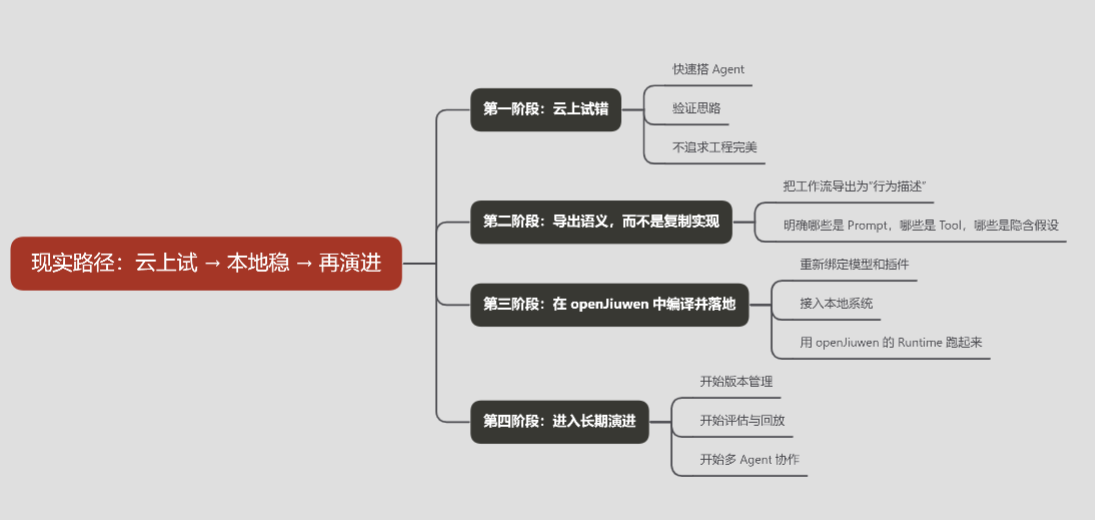
在这条路径里,openJiuwen 并不是"替代云平台",而是承接"已经被验证过的智能体语义",让它们以工程化的方式长期存在。
写在最后:智能体迁移,终究是一场系统设计问题
回过头来看这篇文章,其实我们一直在刻意回避一个词:"一键迁移"。
不是因为做不到,而是因为------
真正成熟的智能体系统,本来就不该存在"一键拷贝"这种幻想。
从云到本地、从试验到生产、从单个 Agent 到一套工作流体系,
你面对的从来不是"JSON 格式对不对",而是这个 Agent 的能力边界是什么,它依赖了哪些平台语义,哪些能力是"智能",哪些其实是"工程假设"。
也正因为如此,我们在文章里反复强调:
导入不是读取文件,而是一次"编译"
导出不是备份,而是一次"语义抽取"
当你接受了这一点,很多之前看似复杂的问题,反而开始变得清晰。
openJiuwen 在这条链路中的真实位置
如果一定要给 openJiuwen 在这条链路里一个定位,那它并不是:"又一个云上智能体平台",也不是"某个平台的国产/私有化替代品"。它更像是一个 Agent 的执行与治理底座。
它关心的是这个工作流在本地能不能稳定跑,插件和模型能不能被明确绑定,工作流结构能不能被版本化、回放、演进。
当你把智能体当成系统组件而不是一次性能力展示时,openJiuwen 的价值才真正显现出来。
写给真正会用到这套机制的人
如果你只是偶尔搭几个 Agent 玩一玩,那这篇文章的大部分内容,可能显得有些"过重"。
但如果你正在做的是:企业内部 Agent 平台、私有化 / 本地化部署或者是多部门、多业务长期使用的智能体系统
那么你大概率已经意识到一件事:
智能体不是越快搭出来越好,
而是越"可控、可解释、可演进"越值钱。
而"工作流导入导出"这件事,本质上就是你是否愿意为智能体的长期存在负责。
最后一句
如果你能把这篇文章完整读完,并且在某一段停下来点了点头,
那说明你大概率已经走在一条相似的路上。
这篇文章来自我fanstuck在真实工程场景中的反复踩坑与拆解思考。
如果它能帮你少走一段弯路,那它的价值就已经实现了。