本文主要目的是协助具备cpp基础的工程师对python中函数参数的传递方式进行了解。
在使用 Python 的过程中,往往会对 Python 中函数传递的形参到底是值传递还是引用传递产生疑惑。不少教程给出的答案都是:对于不可变对象是值传递,对于可变对象是引用传递。这一答案在实践表象层面是成立的,但是却没有给出其背后的原理解答,对于初学者(尤其是习惯了 C/C++ 内存控制的工程师)而言很容易发生混乱。
针对这一问题,本文给出的核心结论是:Python 中函数传递的形参一律是"传对象引用 (Pass-by-Object-Reference)"。更深入地说,Python 中所有变量的赋值本质上都是指针引用的传递。 至于为何可变对象表现出"引用传递"现象,而不可变对象表现出"值传递"现象?这是由对象本身的内部可变性以及操作类型(原地 vs 非原地)决定的,与函数传递形参的机制本身无关。
为了彻底讲清楚这个问题,会对python中一些相关的基础概念进行讲解。
一、Python中的内存模型与变量赋值机制
Python中的变量 与cpp中的变量 不同,cpp中的变量代表一块内存区域,在Python中的变量则相当于是对对象的引用 (类似于cpp中的std::shared_ptr)
- cpp中的内存模型与变量赋值机制
在 C++ 中,当你声明一个变量时,编译器会在内存中划出一块固定大小的区域,并将这个变量名直接与这块内存地址绑定。变量本身就是那个存储数据的"盒子"。
cpp
int a = 10; // 在栈上开辟 4 个字节,命名为 a,里面存入 10
int b = a; // 在栈上【新开辟】 4 个字节,命名为 b,将 a 盒子里的内容【拷贝】过来
b = 20; // 修改 b 盒子里的内容为 20。a 盒子完全不受影响。- python中的内存模型与变量赋值机制
在python中,各个对象(如整数10、列表[1,2])都是被单独创建在堆内存 中的,而我们作为程序员书写的变量名a或b只是贴在这些对象上的标签 ,或者说是指向这些对象的指针
python
a = [1, 2, 3] # 在内存中创建一个列表对象,把标签 'a' 贴上去
b = a # 把标签 'b' 贴到 'a' 所贴的【同一个对象】上!(没有发生拷贝)
b.append(4) # 通过标签 'b' 找到了对象,并修改了它
print(a) # 输出: [1, 2, 3, 4]。因为 'a' 和 'b' 贴在同一个东西上。这段代码翻译成cpp,类似这个样子
cpp
// C++ 模拟 Python 行为
#include <memory>
#include <vector>
// a 是一个智能指针,指向堆上的 vector
auto a = std::make_shared<std::vector<int>>(std::initializer_list<int>{1, 2, 3});
// b 也是一个智能指针,赋值操作仅仅是让指针指向同一个地址,引用计数 +1
auto b = a;
// 通过指针 b 修改了底层对象的数据
b->push_back(4);
// 此时 a->size() 也会是 4,因为它们指向同一个 vector可能有读者会疑惑,为什么这里选择用list来举例,而不是用基本的类型(如int),这是由于int是不可变对象,在这里使用不可变对象进行举例可能会产生疑惑。在这一小节中,读者只需要建立一个概念:python中程序员书写的每个变量都类似于cpp中的std::shared_ptr,在已有一个变量A之后,令新变量B=A就相当于cpp中的std::shared_ptr<> B = A 。实际使用过程中遇到的诸如修改B会不会修改A的问题,是由变量的类型决定的(会在下一节中讲到),与python的变量绑定赋值机制无关。
二、可变对象与不可变对象
python中的对象分为可变对象和不可变对象
2.1 不可变对象
- 不可变对象:一旦在内存中创建,其内部的数据就不允许被修改 ,任何试图修改的操作都会在内存中开辟一个新的空间,创建一个新的对象
- 哪些类型的变量属于不可变对象?
- 数值类型: int, float, bool, complex
- 字符串: str
- 元组: tuple
- 不可变集合: frozenset
2.2 可变对象
- 可变对象:可以在不改变自身内存地址的情况下,动态修改其内部的数据
- 哪些类型的变量属于可变对象?
- 列表: list (高度对应 C++ 的 std::vector,可以动态扩容)
- 字典: dict (对应 std::unordered_map)
- 集合: set (对应 std::unordered_set)
- 自定义类的实例 (默认情况下): 大部分用户通过 class 定义的实例都是可变的
- NumPy Arrays / PyTorch Tensors: 这两个成熟库的对象都是可变对象,支持高效的原地内存操作
2.3 简单代码验证
可以通过如下代码进行简单验证
python
# --- 不可变对象 ---
x = 10
print(id(x)) # 假设输出: 14073...112
x += 1 # 尝试修改
print(id(x)) # 输出一个全新的地址: 14073...144。旧的整数 10 并没有被修改,而是创建了 11
# --- 可变对象 ---
v = [1.0, 2.0, 3.0] # 模拟一个 3D 向量
print(id(v)) # 假设输出: 20056...800
v[0] = 5.0 # 原地修改元素
v.append(4.0) # 原地扩容
print(id(v)) # 地址依然是: 20056...800。这是在原内存上操作的。2.4 可变\不可变对象与变量赋值机制的关系
在能够区分可变、不可变对象之后,我们就可以更深入地理解python中的变量赋值机制了。
- 对于不可变对象(以
int类型为例),给出如下例程
注:id()函数的作用是打印该变量的地址
python
# Step 1
a = 2
print(id(a)) # 结果为9097968
b = a
print(id(b)) # 结果为9097968
# Step 2
a = 10
print(id(a)) # 结果为9098000
print(id(b)) # 结果为9097968Step 1:我们首先创建了一个int类型的变量a = 10,然后我们声明一个新的对象b = a,并打印二者的地址,发现二者的地址是一样的。这说明python中的变量赋值就是传引用,这一步骤类似于cpp中的:
cpp
std::shared_ptr<int> A = std::make_shared<int>(2);
std::shared_ptr<int> B = A;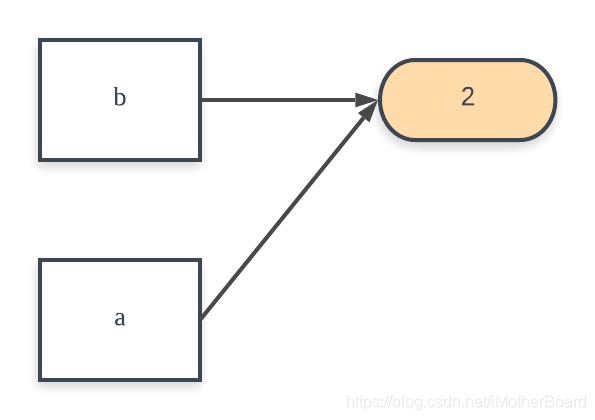
Step 2: 我们将变量a重新赋值为11,**由于a是int类型,是不可变类型,所以a=10这句话相当于新开辟了一块内存,这块内存中的数据是10,然后让a重新指向这块内存。**因此,此时再打印变量a的地址,会发现已经发生变化;而打印变量b的地址,没有发生变化,因为b并不是完全等于a,b = a只是让b指向了该语句执行时a所指的内存
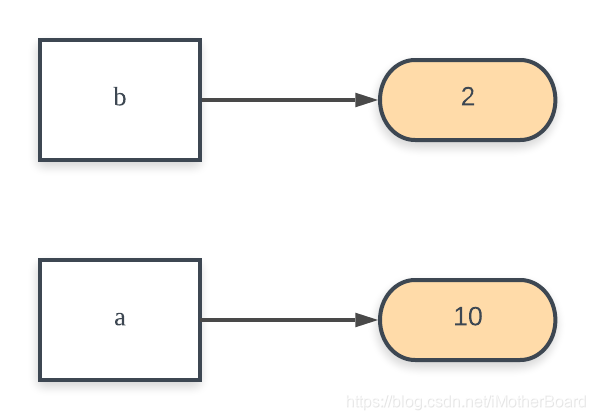
该图片参考自深度好文! Python函数参数传递:到底是值传递还是传用传递?
- 对于可变对象(以
list为例),给出如下例程
python
# Step 1
lista = [1,2,3]
listb = lista
print(id(lista)) # 140433391343744
print(id(listb)) # 140433391343744
print("lista:", lista) # [1, 2, 3]
print("listb:", listb) # [1, 2, 3]
# Step 2
lista.append(4)
print(id(lista)) # 140433391343744
print(id(listb)) # 140433391343744
print("lista:", lista) # [1, 2, 3, 4]
print("listb:", listb) # [1, 2, 3, 4]Step 1:新建一个列表A并赋值,新建一个列表B = A,可以看到A和B内容一致,指向同一块内存
Step 2:修改列表A,并打印A、B的内容和地址,发现A、B的内容一致,地址也一致。因为list是可变对象,可以在不改变自身内存地址的情况下,动态修改其内部的数据。
截至这里,读者应该对python中的变量赋值机制以及可变、不可变对象有了一定的了解。然而,在coding的过程中,我们有时会遇到:在对可变对象进行操作时,其内存地址也会发生改变 。这是因为对可变对象的操作分为原地操作 与非原地操作。
三、可变对象的原地操作与非原地操作
原地操作(inplace操作)指的是直接在原对象所在的内存地址上修改其数据,而不分配新的内存空间去创建新对象。
典型的inplace操作有:
- 列表: list.append(), list.extend(), list.sort(), list.clear()
- 字典: dict.update(), dict.setdefault()
- NumPy
a += b (注意:a = a + b 不是原地操作,它会创建新数组。a += b 是原地修改 a)
np.add(a, b, out=a) (显式指定输出到原有内存)
切片赋值: a0:5 = 0 - PyTorch: 所有带有下划线 _ 结尾的方法都是原地操作。例如 tensor.add_(b), tensor.zero_(), tensor.copy_(other)。
典型的非原地操作有
- 绝大多数算术运算符: c = a + b,string3 = string1 + string2 总是创建新对象。
- 内置返回新对象的方法: sorted(list) (返回新列表,区别于 list.sort())。
- 对不可变对象的所有操作: 字符串的方法如 str.replace(),或整数的自增。
以list类型为例,运行一个例程:
python
lista = [1,2,3]
listb = lista
print(id(lista)) # 139630020089984
print(id(listb)) # 139630020089984
print("lista:", lista) # [1, 2, 3]
print("listb:", listb) # [1, 2, 3]
lista = lista + [4]
print(id(lista)) # 139630022248896
print(id(listb)) # 139630020089984
print("lista:", lista) # [1, 2, 3, 4]
print("listb:", listb) # [1, 2, 3]此时现象就和刚刚讲过的不可变对象相似了,因为=是一个非原地操作,所以让lista指向了一块新的内存
四、函数的传参机制
讲到这里,其实读者应该已经明晰为什么python的传参机制有时像值传递,有时像地址传递:在函数传参的过程中,其实都是传引用,这是由python的变量赋值机制决定的;而修改函数内部的形参到底会不会影响函数外的实参,是由形参的类型(可变or不可变)、以及在函数内部进行的操作类型(原地or非原地)决定的