一、背景
推荐系统典型pipeline
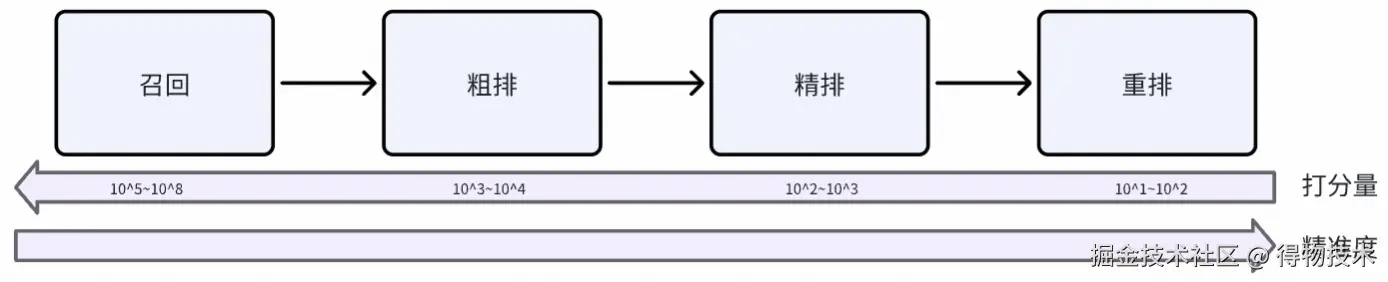
在推荐系统多阶段Pipeline(召回→粗排→精排→重排)中,重排作为最终决策环节,承担着将精排输出的有限候选集(通常为Top 100--500个Item)转化为最优序列的关键职责。数学定义为在给定候选集 C={x1,x2,......,xn}与目标列表长度 L,重排的目标是寻找一个排列 π∗∈P(C,L),使得全局收益函数最大化。
在推荐系统、搜索排序等AI领域,Pointwise 建模是精排阶段的核心方法,即对每个 Item 独立打分后排序,pointwise 建模范式面临挑战:
- 多样性约束:精排按 item 独立打分排序 → 高分 item 往往语义/类目高度同质(如5个相似短视频连续曝光)。
- 位置偏差:用户注意力随位置显著衰减,且不同item对位置敏感度不同。
- 上下文建模:用户决策是序列行为,而非独立事件。
二、重排架构演进:生成式模型实践
我们的重排系统采用G-E两阶段协同框架:
- 生成阶段(Generation):高效生成若干高质量候选排列。
- 评估阶段(Evaluation):对候选排列进行精细化打分,选出全局最优结果。
不考虑算力和耗时的情况下,通过穷举所有排列 P(C,L)。
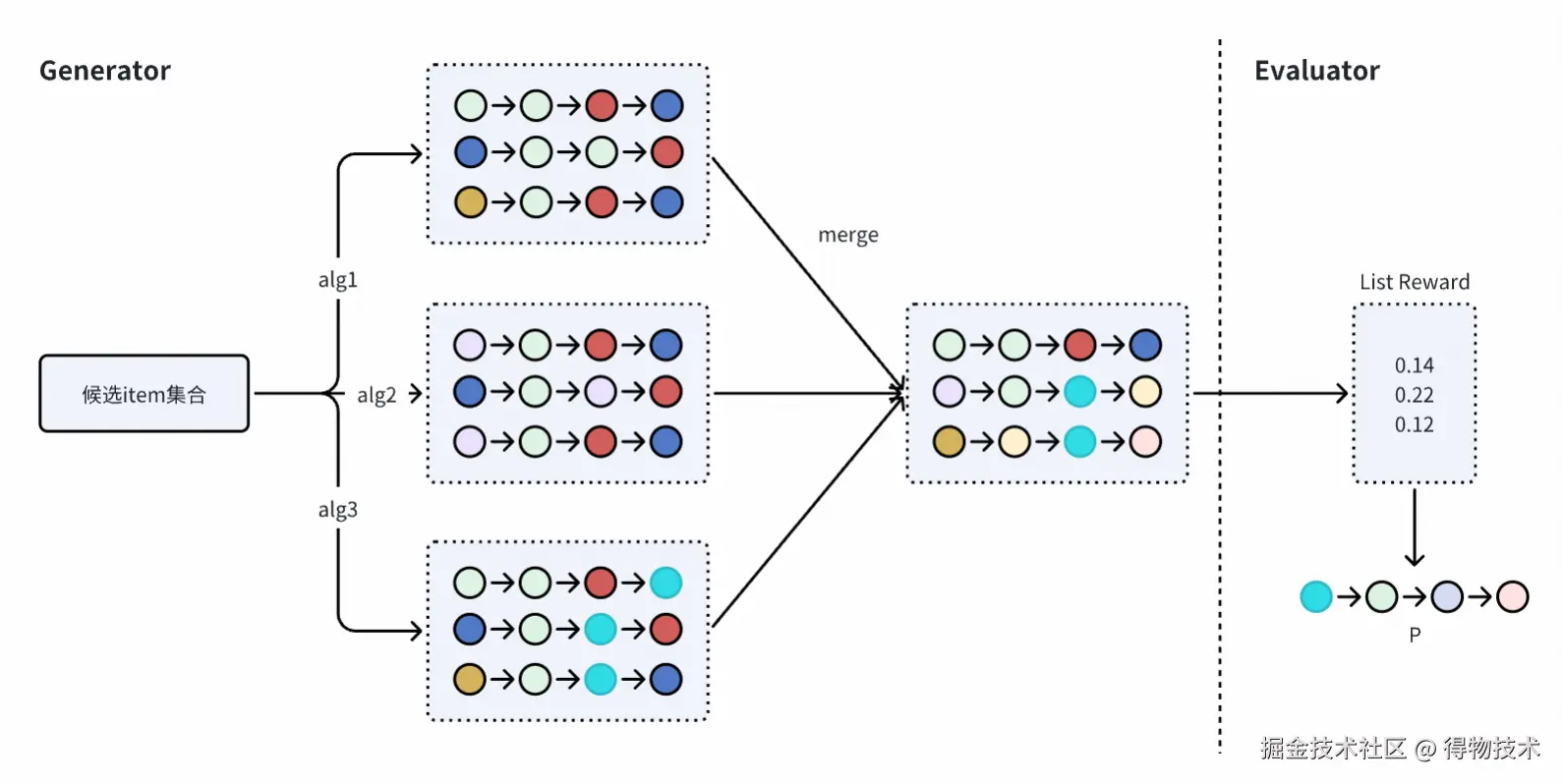
生成阶段主要依赖启发式规则、随机扰动 + beamSearch算法生成候选list,双阶段范式存在显著的痛点:
- 质量-延迟-多样性的"不可能三角":在实践中,增加生成候选list数一般可以提升最终list的质量,但边际收益递减;优化过程中,我们通过增加多目标、多样性等策略都取得了消费指标的提升,但在候选list达到百量级时,单纯增加候选集对指标的提升,同时还有:
-
增加beam width,系统耗时增加,DCG@K提升逐渐减少。
-
增加通道数,通道间重叠度逐渐增加,去重list增加逐渐减少。
- 阶段间目标不一致:
-
分布偏移:启发式生成Beam Search输出的Top排列中,20%被评估模型否定,生成阶段搜索效率浪费。
-
梯度断层:Beam Search含argmax操作,双阶段无法端到端优化;生成模型无法感知评估反馈,优化方向偏离全局最优。
生成模型优化
生成分为启发式方法和生成式模型方法, 一般认为生成式模型方法要好于启发式方法。生成式模型逐渐成为重排主流范式,主要分为两类:自回归生成模型、非自回归生成模型。
- 自回归生成:按位置顺序逐个生成物品,第 t 位的预测依赖前 t-1 位已生成结果。
- 优点:
a. 序列依赖建模强,天然捕获物品间的顺序依赖。
b. 训练简单稳定,每步使用真实前序作为输入,收敛快。
c. 生成质量高,逐步细化决策,适合长序列精细优化。
- 缺点:
a. 推理延迟高,生成 L 个物品需 L 次前向传播,线上服务难以满足毫秒级要求。
b. 局部最优风险,早期错误决策无法回溯修正,影响整体序列质量。
- 非自回归生成:一次性预测整个推荐序列的所有位置,各位置预测相互独立。
- 优点:
a. 推理速度极快:生成整个序列仅需1次前向传播。
2.缺点:
b.条件独立性假设过强:各位置并行预测,难以显式建模物品间复杂依赖关系。
非自回归模型
为了对齐双阶段一致性,同时考虑线上性能,我们推进了非自回归模型的上线。模型结构如下图:
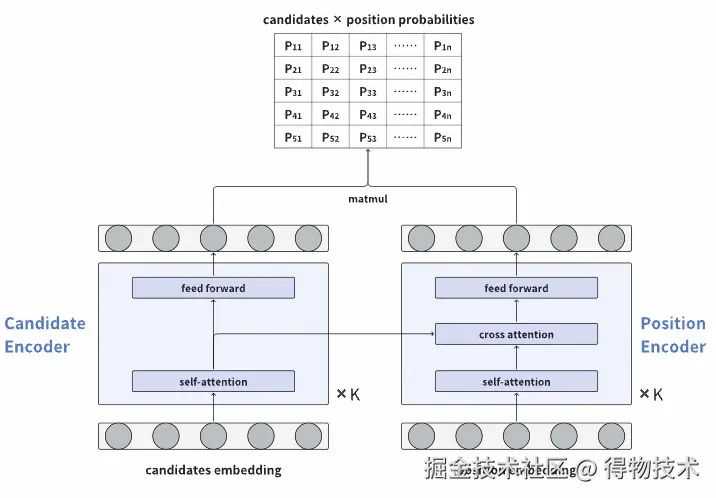
模型包括Candidates Encoder和Position Encoder,Candidates Encoder是标准的Transformer结构, 用于获取item间的交互信息;Position Encoder额外增加了Cross Attention,期望Position序列同时关注Candidate序列。
- 模型特征:用户信息、item特征、位置信息、上游精排打分特征。
- 模型输出:一次性输出 n×L 的位置-物品得分矩阵(n 为候选 item 数,L 为目标列表长度),支持高效并行推理
p^ij=∑i=1nexp(xi⊤tj)exp(xi⊤tj)
- 位置感知建模:引入可学习位置嵌入,显式建模"同一 item 在不同位置表现不同"的现象(如首屏效应、位置衰减)。
- 训练目标:模型使用logloss,让正反馈label序列的生成概率最大, 同时负反馈label序列的生成概率最小:
Llog=−i∑pijyilog(pij\^)+pij(1−yi)log(1−pij\^)
其中, pij表示位置i上是否展示物品j, yi表示位置i上的label。
线上实验及收益:
- 一期新增了非自回归生成通道,pvctr +0.6%,时长+0.55%。
- 二期在所有通道排序因子中bagging非自回归模型,pvctr +1.0%,时长+1.13%。
自回归模型
由于条件独立性假设, 非自回归模型对上下文信息建模是不够的,近期我们重点推进了自回归模型的开发。
模型通过Transformer架构建模list整体收益,我们使用单向transformer模拟用户浏览行为的因果性,同时解决自回归生成的暴露偏差问题,保持训练和推理的一致性。结构如下:
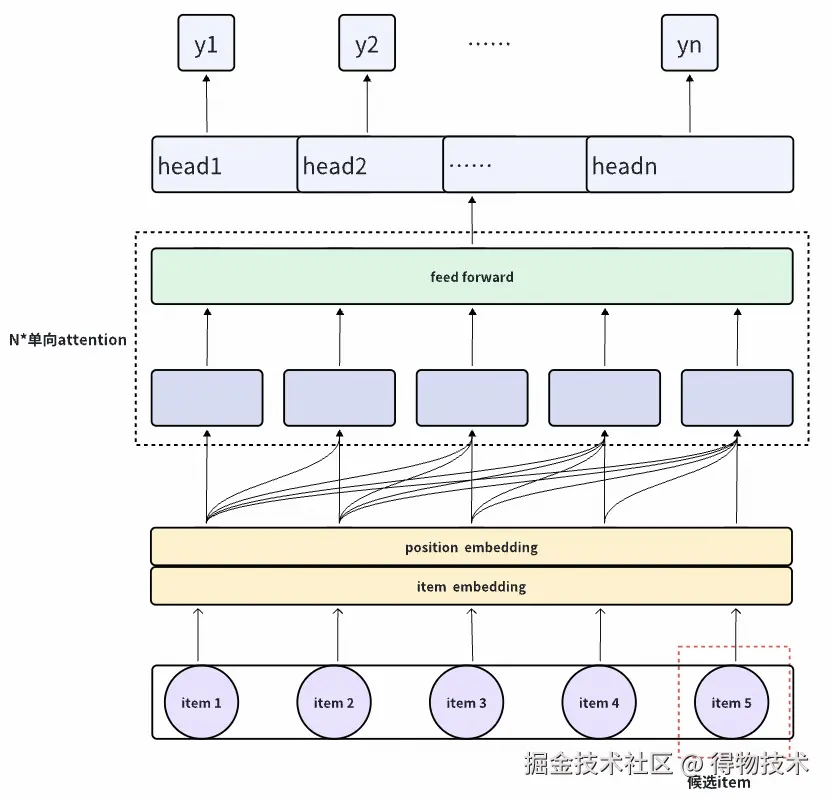
- 模型特征:用户信息、item特征、位置信息、上游精排打分特征。
- 训练目标:模型使用有序回归loss,在评估多个回合中不同长度的子列表时,能够很好地体现出序列中的增量价值。是用于判断长度为j的子列表是否已经达到i次点击或转化的损失函数。
Li,j(θj)=−k=1∑N(yk\
线上模型推理效率优化及实验效果:
自回归生成模型推理延迟高,生成 L 个物品需 L 次前向传播,线上服务难以满足毫秒级要求。因此,我们在传统自回归生成模型的基础上增加MTP(multi token prediction)结构,突破生成式重排模型推理瓶颈。其核心思想是将传统自回归的单步预测扩展为单步多token联合预测,显著减少生成迭代次数。
自回归生成模型在社区推荐已完成了推全,实验中我们新增了自回归生成模型通道,但不是完全体,仅部分位置生成调用了模型:
- 一期调用两次模型,每次预测4个位置,pvctr +0.69%,有效vv +0.58%。
- 二期调用两次模型,每次预测5个位置,pvctr +0.54%,有效vv +0.40%。
三、推理性能优化:端到端生成的效率保障
工程架构
为解决CPU推理模型延迟高、制约业务效果的问题,我们对DScatter模型服务进行升级,引入高性能GPU推理能力,具体方案如下:
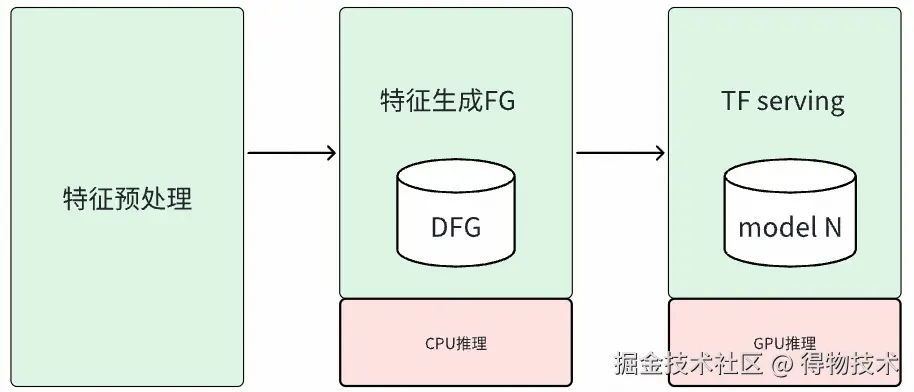
- GPU推理框架集成与升级:
-
框架升级:将现有依赖的推理框架升级为支持GPU的高性能服务框架。
-
硬件资源引入:引入 NVIDIA L20 等专业推理显卡,为当前的listwise评估模型及自回归生成模型提供专用算力,实现模型推理的硬件加速。
- DScatter模型服务独立部署与容量提升:
- 为解决模型部署效率低与资源竞争问题,将DScatter的模型打分逻辑从现有重排服务中完全解耦,构建并部署独立的 DScatter-Model-Server 集群,从根本上消除与重排服务在CPU、内存等关键资源上的竞争。
模型优化
- 模型格式转换与加速:
导出为 ONNX 格式,使用 TensorRT 进行量化、层融合、动态张量显存等技术加速推理。
- Item Embedding缓存:
预计算item静态网络,线上直接查询节省计算量。
- 自回归生成模型核心优化,KV Cache 复用:
缓存已生成token的KV和attention值,仅计算增量token相关值,避免重复计算。
- 其他LLM推理加速技术应用落地,例如GQA
四、未来规划:迈向端到端序列生成的下一代重排架构
当前"生成-评估"双阶段范式虽在工程落地性上取得平衡,但其本质仍是局部优化:生成阶段依赖启发式规则或浅层模型生成候选,评估阶段虽能识别优质序列,却无法反向指导生成过程,导致系统能力存在理论上限。为突破这一瓶颈,我们规划构建端到端序列生成(End-to-End Sequence Generation) 架构,将重排从"候选筛选"升级为"序列创造",直接以全局业务目标(如用户停留时长、互动深度、内容生态健康度)为优化目标。
核心架构设计:
- 统一生成器:以 Transformer 为基础架构,搭建自回归序列建模能力,采用分层混合生成策略:
-
粗粒度并行生成:首层预测序列骨架(如类目分布、内容密度)等。
-
细粒度自回归精调:在骨架约束下,自回归生成具体 item,确保局部最优。
- 序列级Reward Modeling:
-
构建多目标 reward 函数:xtr、多样性。
-
Engagement:基于用户滑动轨迹建模序列累积收益(如滑动深度加权CTR)。
-
Diversity:跨类目/创作者/内容形式的分布熵。
4.Fairness:冷启内容、长尾创作者曝光保障。
训练范式升级:强化学习与对比学习融合
推进自回归生成模型的架构升级与训练体系重构,引入强化学习微调(PPO/DPO)与对比学习机制,提升序列整体效率。
- 搭建近线系统,生成高质量list候选,提升系统能力上限:
1.基于 DCG 的列表质量打分:
a. 对每个曝光列表L,计算其 DCG@K作为质量分数:
DCG(L)=j=1∑Klog2(j+1)gain(itemj)
其中 gain(item)可定义为:
若点击:+1.0
若互动(点赞/收藏):+1.5
若观看 >5s:+0.8
否则:0
2.构造偏好对:
a.对同一用户在同一上下文下的两个列表 Lw(win)和 Ll(lose)。
b.若 DCG(Lw)>DCG(Ll)+δ(δ 为 margin,如 0.1),则构成一个有效偏好对。
- 引入强化学习微调(PPO/DPO)与对比学习机制,提升序列整体效率:
- 模型结构:
a.使用当前自回归生成模型作为策略模型。
b.固定预训练模型作为参考策略 (即 DPO 中的"旧策略")。
2.DPO损失:
LDPO(θ)=−E(x,yw,yl)∼Dlogσ(β(logπref(yw∣x)πθ(yw∣x)−logπref(yl∣x)πθ(yl∣x)))
- 技术价值:
-
突破"质量-延迟-多样性"不可能三角:通过序列级优化,在同等延迟下实现质量与多样性双提升。
-
为AIGC与推荐融合铺路:端到端生成器可无缝接入AIGC内容,实现"内容生成-序列编排"一体化。
参考文献:
- Gloeckle F, Idrissi B Y, Rozière B, et al. Better & faster large language models via multi-token predictionJ. arXiv preprint arXiv:2404.19737, 2024.
- Ren Y, Yang Q, Wu Y, et al. Non-autoregressive generative models for reranking recommendationC//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024: 5625-5634.
- Meng Y, Guo C, Cao Y, et al. A generative re-ranking model for list-level multi-objective optimization at taobaoC//Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2025: 4213-4218.
- Zhao X, Xia L, Zhang L, et al. Deep reinforcement learning for page-wise recommendationsC//Proceedings of the 12th ACM conference on recommender systems. 2018: 95-103.
- Feng Y, Hu B, Gong Y, et al. GRN: Generative Rerank Network for Context-wise RecommendationJ. arXiv preprint arXiv:2104.00860, 2021.
- Pang L, Xu J, Ai Q, et al. Setrank: Learning a permutation-invariant ranking model for information retrievalC//Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 2020: 499-508.
往期回顾
1.Flink ClickHouse Sink:生产级高可用写入方案|得物技术
2.服务拆分之旅:测试过程全揭秘|得物技术
3.大模型网关:大模型时代的智能交通枢纽|得物技术
4.从"人治"到"机治":得物离线数仓发布流水线质量门禁实践
5.AI编程实践:从Claude Code实践到团队协作的优化思考|得物技术
文 /张卓
关注得物技术,每周一、三更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。