如果你是一名计算机视觉的研究者,过去几年大概已经习惯了这样一种节奏:ImageNet分类准确率又涨了0.1%,某个新Backbone在COCO上刷了新高,某个Transformer变体能更好地理解图片上下文。这些进展当然重要,但它们都有一个共同点------所有的"理解",最终都止步于理解本身。
模型看懂了图片,然后呢?然后就没有然后了。
这就像一个学生把教科书背得滚瓜烂熟,却从来没有动笔写过一道题。OpenClaw的出现,正在以一种近乎粗暴的方式提醒这个领域:视觉的终点,从来不是"看懂",而是"做对" 。
一个让CV界坐不住的AI代理

先说说OpenClaw到底是什么。它不是又一个刷榜的视觉模型,而是一个能真正操作电脑的AI代理。你可以让它"帮我订一张下周五去上海的机票",然后它就自己打开浏览器,搜索航班,填写信息,直到最后按下确认键。
听起来像是自动化脚本的升级版?区别在于,OpenClaw面对的是一个和你眼中完全一样的世界------像素组成的屏幕,而不是结构化的代码或API。这意味着它必须拥有真正的视觉理解能力:找到那个藏在页面角落的"筛选"按钮,区分哪个是广告哪个是真正的航班信息,读懂日历上那些密密麻麻的日期数字,甚至在页面加载失败时识别出那个"刷新"图标。
换句话说,OpenClaw把计算机视觉从实验室的"看图说话",直接拽进了真实世界的"动手干活"。这对CV领域来说,不亚于一场地震。
传统CV,被OpenClaw一脚踩碎
不妨拆解一下,当OpenClaw执行一个简单的"帮我买张票"任务时,它的视觉系统需要同时翻越多少座大山。

首先是细粒度目标检测。这不是在COCO数据集里找出"人、车、猫、狗"那种级别的检测。它需要在密密麻麻的网页元素中,精准定位那个字号只有10像素、颜色还是浅灰色的"出发日期"输入框。这种检测精度,已经逼近人类视觉的极限。

其次是场景文本理解与交互。航班列表里,"¥850"和"¥1850"可能只差几个像素的位置。如果视觉模型读错了数字,或者没看懂"剩余2张"旁边的红色感叹号意味着什么,整个任务就会跑偏。OpenClaw必须把OCR识别出的文本,放到整个页面的视觉上下文中去理解------那些红色的数字通常代表警告或限制,绿色的按钮意味着可以点击,灰色的则表示不可用。
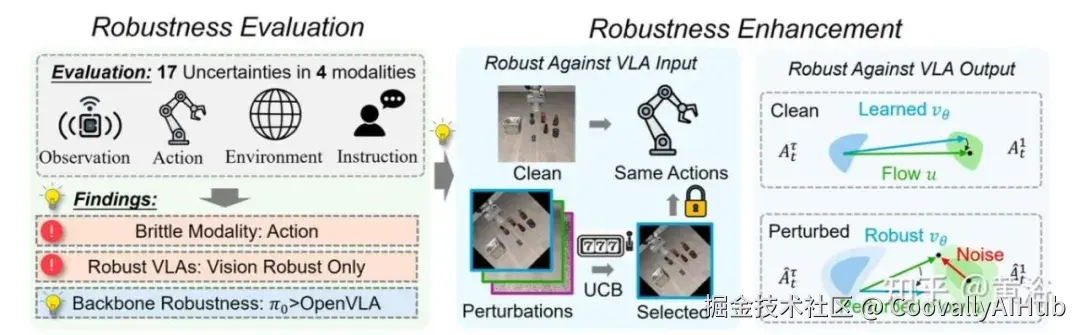
最致命的是动态环境的视觉鲁棒性。网页是会动的。加载转圈、弹窗广告、下拉菜单的异步加载、鼠标悬停时才浮现的提示信息......OpenClaw的视觉系统不能像传统模型那样,假设输入是一张静态的、干净的图片。它必须在一个时刻变化、充满噪声的视觉流里,持续追踪自己的目标。
这三座大山,任何一个单独拎出来,都够一个CV博士生埋头钻研好几年。但OpenClaw给出的答案是:我不要一个个翻越,我要把它们统统踩在脚下,然后继续往前走。 这不是对单一技术点的优化,而是对整个视觉研究范式的挑战。
从"看见"到"看懂",再到"看透"
《2025 AI代理索引》那份报告里,有一个细节让我琢磨了很久。报告将OpenClaw这类浏览器代理的"观察空间"定义为"屏幕像素+HTML结构"的双重输入。这意味着它们的视觉系统不是孤立工作的,而是要和网页的底层代码互为补充。
这其实捅破了一层窗户纸:在真实的应用场景里,视觉从来不是唯一的信息源。 人类浏览网页时,眼睛看到的像素和大脑里对"这个按钮应该能点"的经验判断,是融为一体的。OpenClaw的视觉模块需要学会的,不是替代HTML,而是和HTML对话------当HTML告诉它这里有一个"提交"按钮,视觉系统要确认它在屏幕上的确切位置和当前状态;当HTML没有提供足够信息时,视觉系统要靠"看"来补位。
这种 "视觉+结构化信息" 的融合,正在催生一个新的CV分支。过去我们研究的是"图像识别",后来进化到"场景理解",现在或许该叫它 "界面视觉推理" 。它要求模型不仅要认出物体,还要理解物体的功能、状态和它在交互流程中的角色。那个灰色的"下一步"按钮,在传统的视觉模型眼里只是一个灰色矩形;但在OpenClaw的视觉系统里,它是一个"当前不可用、需要先完成前面步骤"的关键信号。
CV的安全焦虑,在OpenClaw身上提前爆发
报告里那些刺眼的空白数据,也让CV领域不得不直面一个尴尬的问题:我们的视觉模型,准备好被放到真实世界的行动中去考验了吗?
当OpenClaw的视觉系统被一个恶意网站欺骗------比如用视觉上几乎以假乱真的假弹窗覆盖了真正的支付界面------它能不能识破?当它看到一张图片里嵌入了对抗性噪声,这噪声对人类眼睛毫无影响,却能让它的目标检测模型把"确认"按钮识别成"取消",该怎么办?
传统CV研究里的"模型鲁棒性",讨论的通常是"给图片加一点噪声,分类准确率下降多少"。但在OpenClaw的世界里,一次视觉误判的后果可能是:钱付错了,信息填错了,甚至整个系统被恶意操纵。CV的错误成本,从来没有这么高过。
这份报告发现,绝大多数开发者对这类"视觉对抗攻击"的防御手段,要么语焉不详,要么干脆只字不提。这或许不是开发者故意隐瞒,而是整个领域都还没有准备好回答这些问题。我们在ImageNet上把准确率刷到了99%,却可能在一个精心设计的弹窗面前一败涂地。
CV的下一站:为行动而看
说起来很有意思,计算机视觉这个学科,从诞生那天起就带着"模拟人类视觉"的野心。但过去几十年,我们模拟的其实只是人类视觉中很小的一部分------静态的、被动的观看。我们教会了机器认出猫,教会了它看懂视频,教会了它生成图像,唯独没有教会它:看,是为了做。
OpenClaw这类AI代理的出现,正在强行补上这最后一课。它逼着CV研究者重新思考一个根本性的问题:如果你的视觉模型永远不需要动手,那它需要"看懂"到什么程度?反过来,如果它即将动手,它还需要什么额外的视觉能力?
答案或许就在那些报告里没有填写的空白中。我们需要的不再是"更准的分类器",而是"能读懂的界面阅读器";不再是"更鲁棒的识别模型",而是"能在动态干扰中持续追踪目标的视觉跟踪器";不再是"花哨的图像生成器",而是"能预判操作后果的视觉规划器"。
OpenClaw引发的那场关于"代理是否应该绕过robots.txt"的争论,在CV领域有一个镜像版本:视觉模型应该遵守"只准看、不准动"的规则,还是应该为了完成任务而"先看后动"?当内容提供方用验证码、反爬虫策略筑起高墙时,一个真正为"行动"而生的视觉系统,应该绕过去,还是停下来?
这些问题没有标准答案。但有一点可以确定:计算机视觉的教科书,从OpenClaw诞生的那天起,就需要重写了。新的一章或许应该这样开头------
"从前,我们教机器如何看世界。现在,我们要教它们如何为行动而看。因为真正的智能,从来不在旁观中诞生,而在行动中成形。"