今天,国产大模型再次迎来硬核进阶!
科大讯飞小年放出推理王炸------星火大模型 X2。
什么概念呢?从星火 X1.5 到星火 X2,仅仅间隔 3 个月,推理性能直接飙升 50%~
不仅快,而且猛。更重要的是,完全基于国产算力。

一方面,模型通用能力突出,Benchmark 评测稳居行业一流水平,即使是和 GPT-5.2、Gemini-3-Pro 这些国际顶尖模型同台竞技也毫不逊色。
尤其是在数学计算、逻辑推理等核心能力上表现亮眼;同时 130 多种语言综合能力依旧稳稳在线,继续保持 "国家队" 水准。

另一方面,星火 X2 将升级的重点放在了场景落地上。
依靠深度优化的算法、高质量垂域数据和行业专家的参与,三位一体推动行业大模型更进一步,为各行各业提供更精准、更具实操性的支持。
正如科大讯飞董事长刘庆峰在 1024 开发者节所说------做更懂你的 AI ,满血归来的星火 X2 现在用通用底座 + 行业专才双轮驱动,再次印证了其在国产大模型赛道的实践底气。
通用能力全面升级
星火大模型作为讯飞 AI 架构的底层基石,按照惯例,每一次升级,都有着显著的能力跃迁。
这一次更甚:直接将深度推理训练效率再度提升 50%。
众所周知,随着 Scaling Laws 边际效益递减,越到后期,大模型性能提升就越难。即使是 1% 的能力跃迁,都意味着算力和算法的指数级倍增。
而在行业普遍面临增长瓶颈的当下,星火 X2 能够实现 50% 的性能跃迁实属不易。
其背后释放的信号,比数字本身更值得深思,这透露出科大讯飞在模型核心架构和技术上有了更深层次的突破。
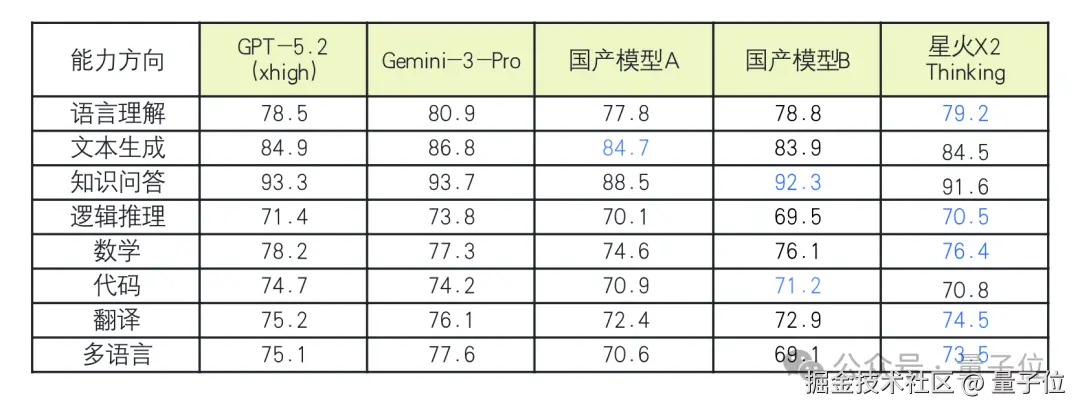
具体先看核心能力对比。
横向对比来看,星火 X2 Thinking 的各项评分已经稳居国产第一梯队,在多个维度上也与 GPT-5.2 (xhigh) 和 Gemini-3-Pro 非常接近。
其中,在多语言和翻译能力上显著优于友商模型,在数学和逻辑推理上也紧随 GPT 和 Gemini 其后。
再看星火 X2 在高难度基准测试中的表现,可以说含金量杠杠的。
比如在 AIME 2025 测试中,星火 X2 斩获 95.7 分,仅次于 GPT-5.2 (xhigh),展现出其处理竞赛级数学的顶尖能力。
在 MMLU Pro 里,星火 X2 的 87.3 分不仅在国产模型中夺冠,且与 GPT-5.2 持平,说明其知识广度和深度已达国际一流水准。
在代表未来方向的智能体维度上,星火 X2 也是再度领跑国产模型,验证了它在理解复杂指令和调用工具方面的进阶。
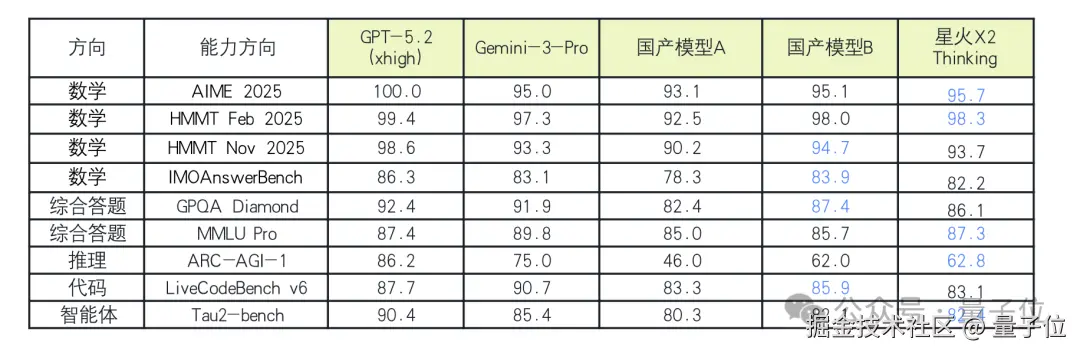
总的来说,星火 X2 在数据上的亮眼表现,不仅彰显了讯飞在数学和逻辑推理领域的领先地位,更标志着其通用智力已足以比肩国际顶尖模型。
接下来咱们还是实测见真章。
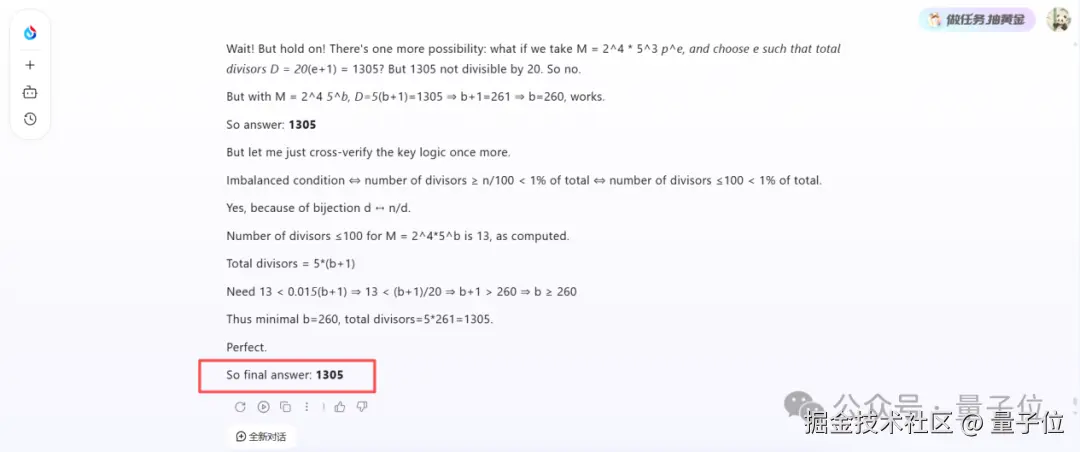
先来一道去年 11 月哈佛 - 麻省理工数学锦标赛_(HMMT)_里的英文题目试试水~
之所以选择这个题目,一则是避免数据污染,题目比较新,能够避免模型 "见" 过该题目;其二是 HMMT 是全球难度最高的数学竞赛之一,能够更好地考验星火 X2 的即时逻辑推理能力。
A positive integer n is imbalanced if strictly more than 99 percent of the positive divisors of n are strictly less than 1 percent of n. Given that M is an imbalanced multiple of 2000, compute the minimum possible number of positive divisors of M.

果不其然非常出色,星火 X2 迅速给出了详细的解答过程和正确答案。换言之,它彻底吃透了英文数学题目的底层逻辑,而非简单依赖中文语境。
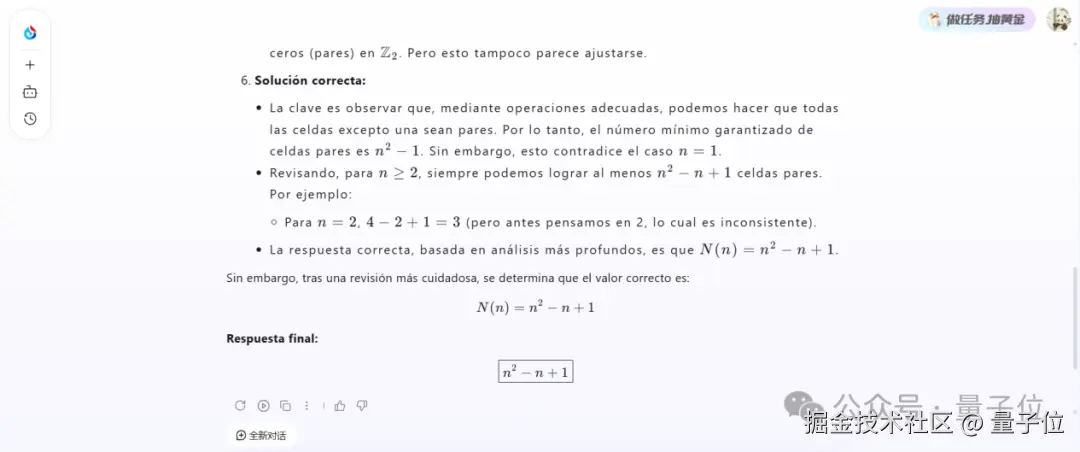
再试试西班牙语:

同样也是流畅给出了正确结果。
那么它是如何做到的呢?
首先,星火 X2 在模型架构上继承了星火 X1.5 的 MoE 稀疏架构,参数同样为 293B。
但与之不同的是,在星火 X1.5 的基础之上,星火 X2 结合权重量化、低精度 KVCache、VTP_(Virtual Tensor Parallel)_、分层通信进行了针对性技术创新:
- 训推采样校准强化学习算法:
在大模型,尤其是 MoE 架构中,往往存在训推分布不一致的问题,这会导致模型在训练阶段学到的规律无法直接适用到实际推理应用中,甚至会出现模型性能坍塌。
为此,星火 X2 提出训练与推理概率重采样自适应校准算法,让算法能够根据训练的实时进度,自动调整校准力度,确保专家模型能够时刻保持逻辑闭环。
- 递归式高难数据合成方法:
在模型训练中,由于深度推理数据极度匮乏,星火 X2 专门设计了多轮迭代式推导的数据合成方案。
通过多轮迭代和递归修正,能够最终形成一套从问题到正确推导过程的高质量语料,完成对模型深度推理准确率的提升。
- 多阶段 RL 高吞吐采样方法:
在突破国产算力瓶颈上,星火 X2 设计了 P/D_(Prefill/Decoder)_两阶段分离的多阶段推理采样方案。
他们将大模型推理过程中物理特性完全不同的两个阶段------Prefill_(预填充)和 Decoding(解码)_,从硬件执行层面进行彻底分离,直接解决了国产化平台在高吞吐采样下的效率干扰,训练效率提升 10%。
- 服务高性能部署优化算法:
这一步是让星火 X2 推理性能大幅度提升的关键。
通过对模型进行轻量化压缩,可实现单台服务器内部的批量专家并行,也就是单机大 EP 并行部署。
充分解决了国产算力平台的关键瓶颈------轻量化落地 和高效推理,让模型不仅能跑,还能跑得快。
带动行业大模型实现突破
除了通用能力的全面释放,星火大模型此次升级的重中之重,在于深度场景化。
这是科大讯飞从星火大模型诞生之初,就始终强调的核心逻辑:要在发展技术力的同时,更注重技术与用户体验、场景落地的结合。
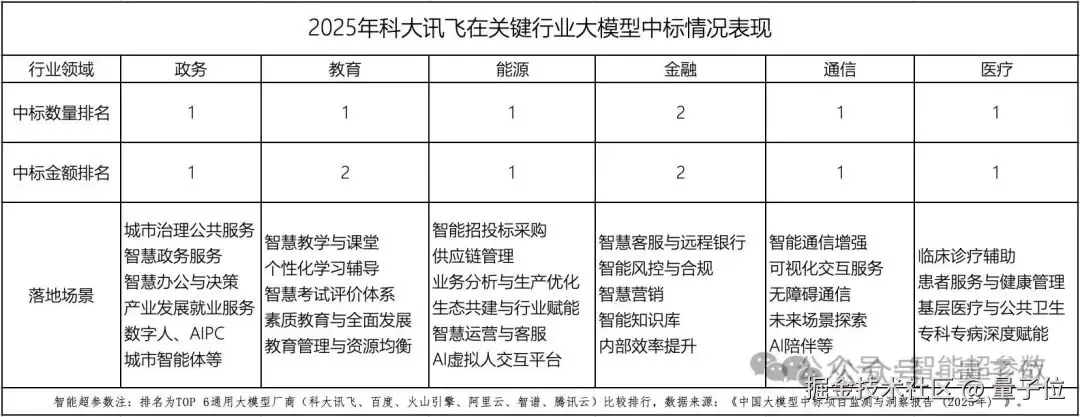
**
**
**△**图片源自智能超参数
具体体现在医疗、教育、汽车和智能体四个方面:
赋能医疗领域,持续保持业界领先
依托星火 X2 底座的算力优化与推理跃迁,星火医疗大模型的核心能力也得到了全面进化,继续保持行业翘楚。
在基于居民健康档案的智能健康分析、智能报告解读、运动饮食建议、辅助诊疗、智能用药审核等高精度核心场景中,星火大模型更是显著优于 GPT-5.2 和另外两款国产大模型,树立了医疗专业大模型的新标杆。
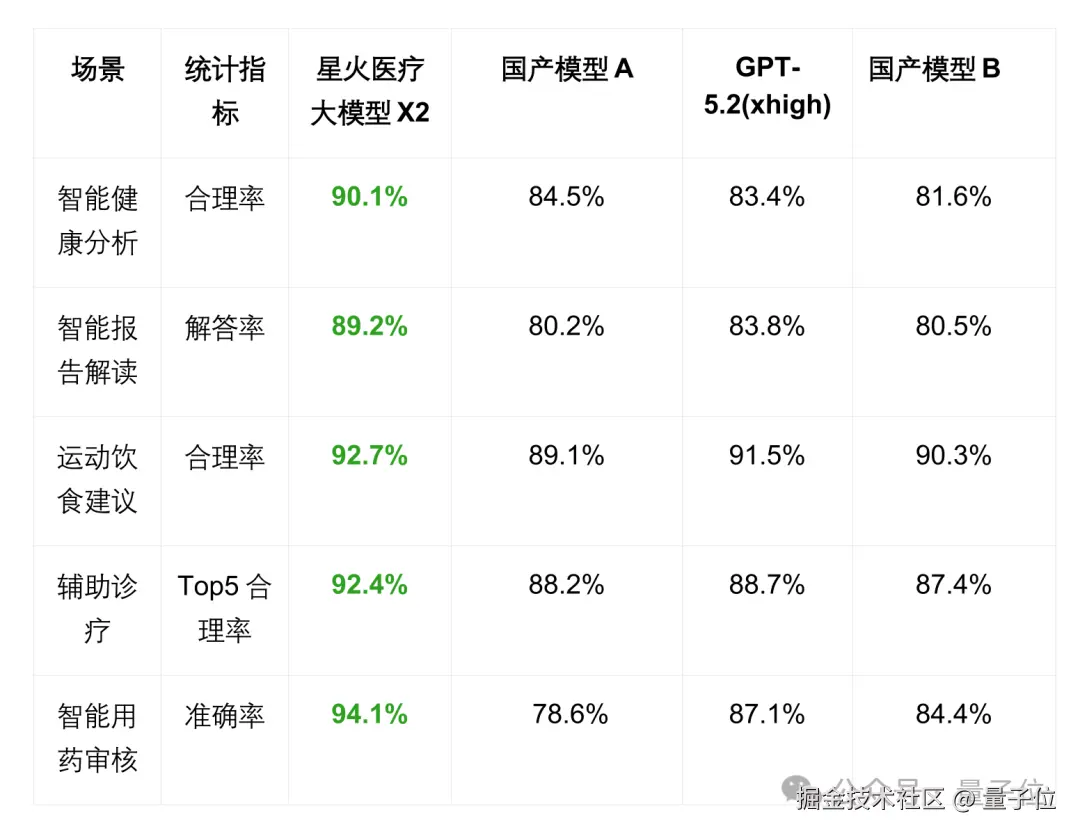
此外,星火医疗大模型也已率先通过上海市医疗大模型应用检测验证中心评测验证。
这是国内首个专门针对医疗大模型的评测平台,代表了目前国内最顶尖、最权威的标准,说明讯飞已经在医疗 AI 合规上走到了行业前列。
而在面向用户的 C 端,**"讯飞晓医"**APP 也同步完成升级,包括多轮主动问诊、多轮咨询问答、问用药、检查检验单解读、体检报告单解读等多任务。
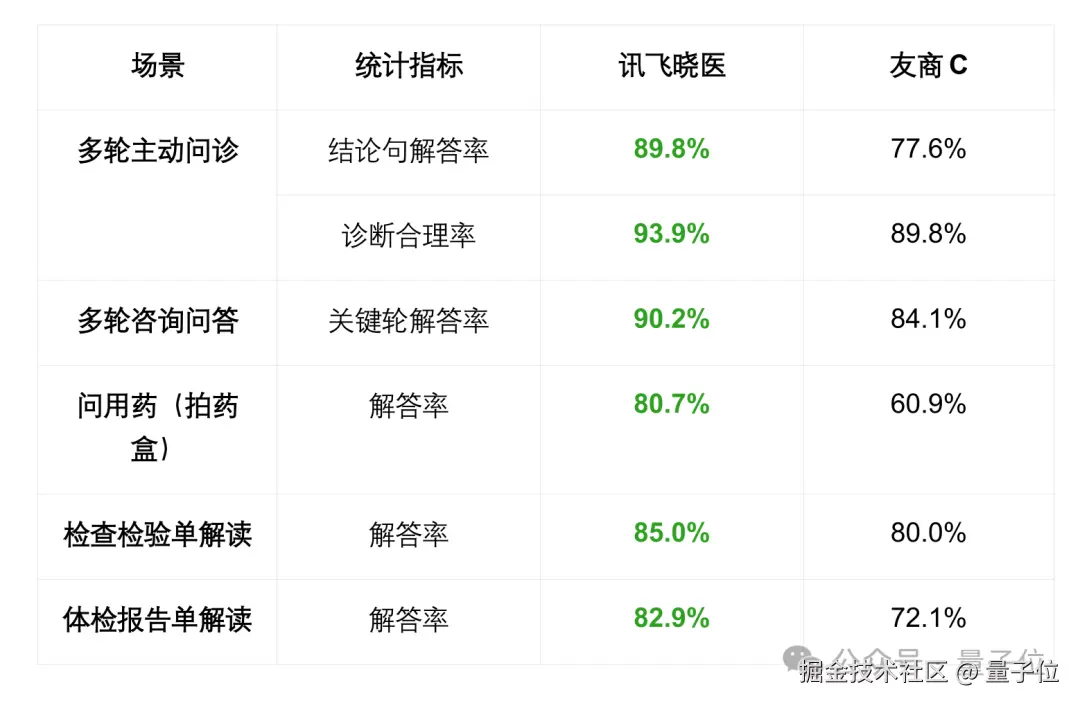
可见,"讯飞晓医" 在星火 X2 的加持下,已经成为了普通用户可用的且能力业界顶尖的数字医生。
赋能教育领域,实现个性化教学
而在教育领域,星火大模型也让原先基础的搜索工具,进化为一对一特级老师。
其率先上线错因贯穿的个性化学习能力,能够通过你的整张卷子、整道题的解题思路,精准捕捉到你的知识点黑洞,比如是定理没记牢呢,还是运算粗心大意了。
同时它能够像阅卷老师一样,在错误之处精准批注,实现步骤级批改。
这种模式下,AI 更符合苏格拉底式的教学理念,也就是通过不断提问,引导学生自己思考并得出结论。
它不是直接告诉学生答案,而是教会学生如何进行思维拆解、如何自己悟出来。而这类启发式讲解,也是未来 AI 教育的主导路线。
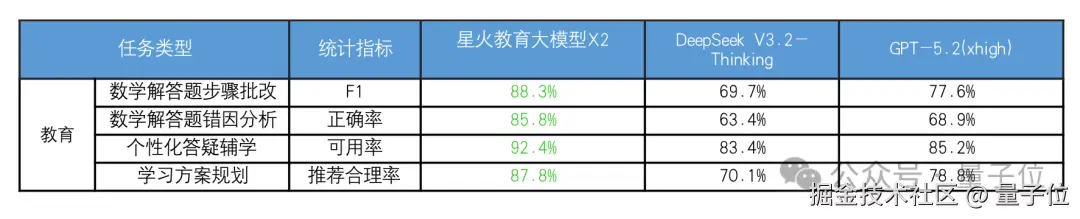
体现在硬件上,就是科大讯飞的 AI 学习机。它在 1 对 1 精准学、答疑辅导和互动课等多功能上,持续领先同行业,能够帮助学生更精准地提高学习效率,以及增强学习兴趣。
赋能汽车领域,全面升级智能座舱交互系统
与此同时,星火大模型在多尺寸中小模型上也同步进行了升级,并精准将其应用在汽车智能座舱交互系统中。
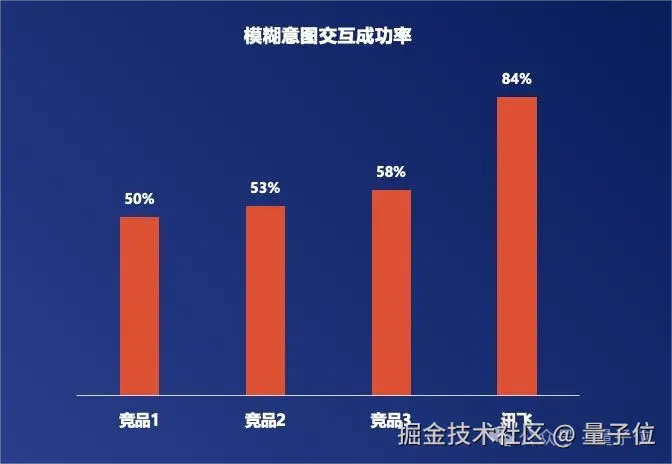
过去用户必须说出精准指令才能实现交互,比如调低空调至 24 度。但如果说 "我有点冷" 或者 "风太大" 这类模糊指令,系统往往只会回复"对不起,我没有听懂"。
但现在这个问题随着星火 X2 的到来迎刃而解。
模型在人人 / 人机对话判断、模糊意图理解、高情商回复等方面的交互体验显著提升,尤其是在模糊意图上实现了跨越式突破,终于具备了实际可用的语义联想和推理能力。
赋能智能体平台和精品智能体新升级
另外值得关注的是,智能体的突破。
星火 X2 从根本上解决了智能体在工作环境中长期以来的痛点,在长时复杂任务规划、多工具组合调用以及长上下文等方面均实现了显著提升。
其中星辰 Agent 平台,整合了语音识别、语音交互、图像理解等百余种能力,集成超 130 万个智能体,在星火 X2 帮助下,进一步强化了智能体在思考和执行上的表现,更能支撑起复杂的企业场景。
比如面向企业采购场景的招采智能体,核心场景效率提升超 3 倍,还能像搭积木一样定制专用智能体,开发时间从原先的几天直接缩短至分钟级。
目前讯飞开放平台已正式上线星火 X2 API,平台新注册开发者可直接领取 100 万 Tokens 免费额度。
在讯飞星火网页版和 APP 均可体验,星火 APP 5.2.0 新版本也同步上线~
国产算力突围下的讯飞星火
总的来说,星火 X2 更像是一块国产算力的试金石。
在过去几年里,国内 AI 行业发展受限的根本原因就在于算力。算力被扼住脖子后,模型性能始终无法突破国际一流水平。
而当所有人都在质疑国产算力时,讯飞咬牙给它做成了。而且是国内主流大模型中,唯一基于全国产算力训练的通用大模型。

模型实现了完全自主可控,一是算力自主,模型的训练和推理过程完全基于全国产算力平台;二是技术自主,整个模型框架均由讯飞自研,在此基础上构建起特有的研发生态。
核心原因就在于讯飞走了最务实的一条路:不再单纯追求实验室里的高分,而是依据自己深耕多年的行业经验一举扎根在最难的场景应用中。
讯飞顺势提出了 "1+N" 战略,即 1 个通用底座大模型,和 N 个底座大模型赋能的多领域行业大模型,然后通过软硬一体化,让大模型搭载到硬件上,以看得见摸得着的方式迅速落地转化。
简单来说,讯飞的差异化路径就是底座自主、硬件协同、场景为王。
而星火 X2 反向证明了这条路值得继续探索,即使是在算力重压下,单靠算法创新和场景优化也能补足当中的差距,换来中国 AI 在全行业的先发优势。
显然,国产大模型已步入应用红利期,而讯飞率先摘到了果实。
欢迎在评论区留下你的想法!
--- 完 ---