该研究构建的DA-ML 区域玉米估产模型,核心是将数据同化(DA) 的物理机制约束与机器学习(ML) 的高效非线性拟合能力结合,解决传统纯物理模型计算成本高、纯机器学习模型缺乏物理解释性的问题,最终实现高效、物理一致的区域玉米产量估算。模型以山东省为研究区,基于 SWAP 作物生长模型、迭代集合光滑器(IES)数据同化算法和 4 类机器学习模型构建,以下从核心原理、分步构建流程、关键模型细节三方面详细解析,兼顾原理理解和实操逻辑。

一、核心基础原理
1. 作物生长模型(SWAP):物理机制
SWAP(Soil-Water-Atmosphere-Plant) 是基于过程的农业水文模型,能模拟土壤水分运移、作物生长的关键物理过程(如光合作用、蒸腾、叶片衰老、干物质积累),通过数学方程来看玉米从出苗到成熟的生长规律,最终输出产量模拟值。
核心优势:基于物理定律,模拟结果具有物理解释性,能反映环境因子(气象、土壤)对玉米生长的真实影响。
核心缺陷:区域尺度下,模型参数(土壤、作物)空间异质性大,且逐像元模拟的计算成本极高,无法直接应用于大区域估产。
2. 数据同化(DA-IES)
数据同化是将卫星遥感观测数据(如 LAI 叶面积指数、SSM 表层土壤水分)融合到物理模型中,通过算法优化模型的参数和状态变量,让模型模拟结果更贴合实际观测,同时保留物理机制。本研究采用迭代集合光滑器(IES) 算法(集合卡尔曼滤波 EnKF 的改进版),相比传统 DA 算法,IES 能迭代更新所有观测数据,更好地提取多源数据的非线性信息,且保证模拟结果的时间一致性。
核心作用:为机器学习提供 **"虚拟" 高质量标签 **------ 通过 IES 优化 SWAP 模型,生成兼具物理一致性和观测贴合性的玉米产量 / 参数模拟值,解决纯机器学习缺乏高质量训练标签的问题;
核心缺陷:逐像元执行 IES-SWAP 同化的计算量呈指数级增长,大区域下不可行。
3. 机器学习(ML) (借蛋生鸡)
选择 常见的机器学习模型(FTT、ANN、XGBoost、RF),以遥感 / 气象数据为输入、DA 优化后的 SWAP 输出为标签进行训练,让 ML 模型 "学习" 物理模型的非线性规律,最终替代物理模型完成区域逐像元估产。
核心优势:训练完成后,区域估产的计算成本极低,且能拟合复杂的非线性关系;
核心改进:通过 DA 输出的物理一致标签训练,让 ML 模型具备物理约束,避免纯数据驱动 ML 的过拟合、泛化性差、结果违背物理规律的问题。
4. DA-ML 融合的逻辑
用 DA 解决 ML 的 "物理无约束" 问题,用 ML 解决 DA 的 "计算成本高" 问题:
仅对少量随机采样像元 执行 DA-SWAP,大幅降低 DA 的计算量;
用 ML 学习采样像元上 "输入特征 - DA 标签" 的关系,将 ML 作为 DA-SWAP 的代理模型(Emulator)
**将训练好的 ML 模型应用于全区域所有像元,实现高效区域估产。**二、模型构建全步骤
研究将模型构建分为3 个核心步骤,从基础数据处理到模型训练,再到区域验证,形成闭环
步骤 1:SWAP 模型校准与敏感参数筛选
1.1 研究区与数据准备
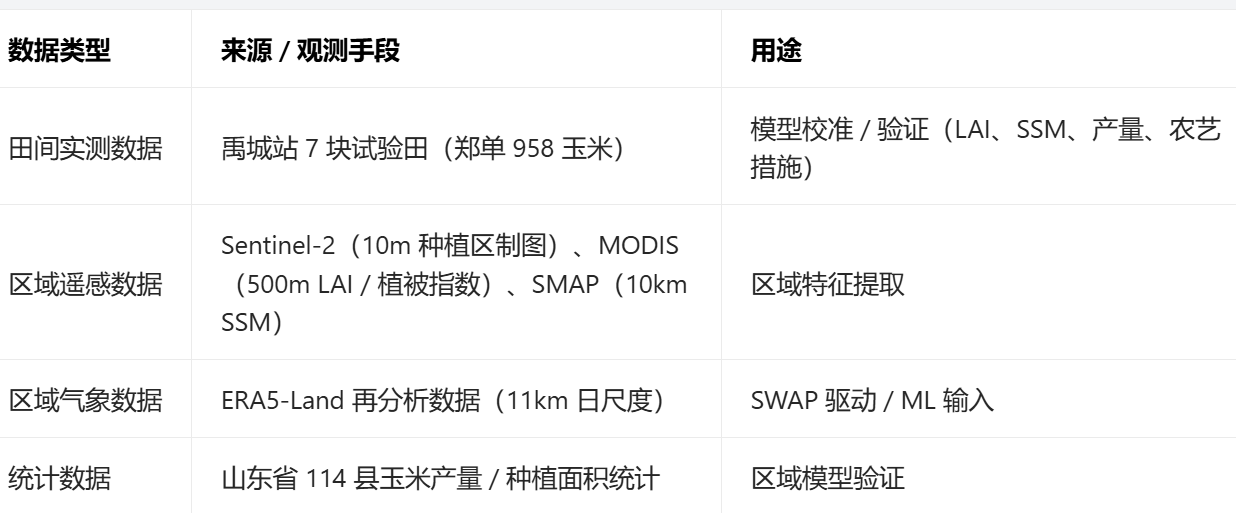
关键:将所有区域数据统一至 1km 空间分辨率(MODIS 500m 聚合、ERA5/SMAP 10km 最近邻降尺度),并制作玉米纯度图(1km 像元内玉米种植比例)1.2 全局敏感性分析
通过Morris 方法(全局敏感性分析)筛选出对LAI(叶面积指数) 和SSM(表层土壤水分) 最敏感的参数
1.3 SWAP 模型校准与验证
田间实测数据校准筛选出的敏感参数,让 SWAP 模型能准确模拟田间尺度的玉米 LAI、SSM 和产量。
步骤 2:采样像元的 DA-SWAP 同化与 ML 训练数据生成
对少量随机采样的玉米像元执行IES-SWAP 数据同化,为 ML 模型训练提供标签。
2.1 采样像元选择
筛选条件:选择玉米纯度>50% 的 1km 像元(减少其他地物的干扰,保证像元内玉米为主要作物)。采样数量:随机选择100 个像元(后续验证表明,增加至 500 个像元并不能提升 ML 模型精度,100 个已足够)
# 仅对少量采样像元执行 DA,大幅降低计算成本,同时保证采样像元的代表性。2.2 IES-SWAP 数据同化执行
将MODIS LAI和校准后的 SMAP SSM遥感观测数据,通过 IES 算法融合到校准后的 SWAP 模型中,迭代更新 5 个敏感参数,让 SWAP 的模拟值贴合遥感观测,最终输出每个采样像元的玉米产量模拟值和参数(TDWI/SPAN)模拟值。
2.3 机器学习模型的输入特征构建
构建能全面反映玉米生长状况的多维特征集,作为 ML 模型的输入,特征集融合遥感特征 、气象特征,并考虑玉米不同生育期的环境差异(生育期划分是作物估产的关键,不同阶段的环境因子对产量影响不同)。
输入特征:遥感特征:MODIS LAI(不同日期)、Mean SSM(全生育期平均表层土壤水分)、Mean NDVI/EVI/NDWI(全生育期平均植被指数,反映植被活力 / 水分);气象特征:每个生育期的平均辐射、最高 / 最低 / 平均温度、露点温度、风速、降雨量(共 3 个生育期 ×7 个气象指标 = 21 个)。
2.4 机器学习模型训练与优选
对比模型性能,筛选出最优模型。
步骤 3:区域估产与模型验证(DA-ML 模型的应用与评估)
将训练好的最优 ML 模型(RF)应用于山东省全区域 189401 个 1km 像元,实现玉米产量 / 参数的区域估算,并通过县级统计数据验证模型精度,同时分析模型的计算效率和特征重要性。
3.1 区域逐像元估产
核心处理:考虑玉米纯度的影响,将 ML 模型输出的像元产量 × 像元玉米纯度,得到实际玉米产量(消除混合像元的干扰);
3.2 模型计算效率验证(DA-ML vs 传统纯 DA)
3.3 区域模型精度验证
以山东省 114 个县级行政区的官方统计产量为真实值,验证 ML 模型估算的县级总产量精度:校准年(2020):RF 模型 R²=0.62,RMSE=1.19×10⁵ t,NRMSE=18%;验证年(2019):RF 模型 R²=0.49,RMSE=1.28×10⁵ t,
核心结论:DA-ML 模型的区域估产精度与同类研究相当,且大幅优于纯数据驱动 ML 模型,实现了精度与效率的平衡。
3.4 特征重要性分析(揭示 ML 模型的物理学习能力)
原理:利用 RF 模型的特征重要性输出功能,分析哪些输入特征对玉米产量估算的影响最大,验证 ML 模型是否 "学习" 到了玉米生长的物理规律。
核心结果:
拔节期的辐射、土壤水分、降雨量是最核心的影响因子(拔节期是玉米营养生长向生殖生长过渡的关键期,光、水直接决定穗数和穗粒数);
其次是生殖期的风速、空气湿度、温度(生殖期是玉米灌浆结实的关键期,微气候影响粒重);出苗期的环境因子(如降雨量)、早期 LAI 对产量的影响极小;
关键结论:RF 模型的特征重要性与玉米生长的物理规律完全一致,说明通过 DA-SWAP 的物理标签训练,ML 模型具备了物理解释性,避免了纯数据驱动 ML 的 "黑箱" 问题。
关键模型细节与实操注意事项
1. 数据同化的核心技巧
选择IES 而非传统 EnKF:IES 能迭代更新所有观测数据,更适合多源遥感数据(LAI+SSM)的融合,且对非线性系统的拟合效果更好;
2. 机器学习模型的选择与训练技巧
小样本下优先选择 RF:本研究仅 100 个采样像元,属于小样本,复杂深度学习模型(FTT/ANN)易过拟合,而 RF 的集成特性使其更稳健;
特征构建需结合作物生育期:作物不同生育期对环境因子的响应不同,按生育期划分气象特征,能大幅提升模型精度;
必须考虑混合像元:区域遥感中混合像元不可避免,通过玉米纯度修正 ML 模型输出,是提升区域估产精度的关键。
3. 尺度统一的关键
所有区域数据必须统一空间分辨率(本研究为 1km),否则会因尺度不匹配导致特征与标签的对应关系混乱;
不同分辨率数据的重采样方法需合理:精细分辨率(500m)用聚合,粗分辨率(10km)用最近邻降尺度,保证数据的空间一致性。
模型的创新点与可迁移性
1. 核心创新点
DA-ML 的高效融合:首次将 IES-SWAP 与 RF 结合,实现计算成本降低 99.8%,同时保留物理机制。
小样本的物理学习:仅用 100 个采样像元训练,就让 ML 模型具备了物理解释性,解决了大区域下 DA 计算量高的问题。
多参数同步估算:不仅估算产量,还能同步估算玉米生长关键参数(TDWI/SPAN),为农业管理提供更多支撑。
2. 可迁移性
该模型框架可直接迁移至其他作物(如小麦、水稻)和其他区域,仅需做 3 点调整:
替换作物生长模型(如小麦用 WOFOST,水稻用 ORYZA2000);
重新筛选该作物的敏感参数(通过 Morris 方法);
重新划分该作物的生育期,构建适配的输入特征集。
收获
注重物理规律结合:机器学习模型的特征构建和结果分析,必须结合作物生长的物理规律,避免纯数据驱动的 "唯精度论";
关注混合像元与尺度问题:区域遥感估产中,混合像元和尺度不匹配是核心难点,需掌握像元纯度计算、尺度转换的方法。
该模型是物理模型与机器学习融合的典型案例,既解决了传统农业模型的计算问题,又解决了机器学习的物理解释性问题,是当前区域作物估产的主流研究方向,掌握其构建逻辑,可快速入门农业遥感与智慧农业的相关研究。